







































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u3504/Tencent_Advertising_Data_Analysis_System?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
腾讯广告的数据分析系统
分享
点赞
11
收藏
3
下载 5
腾讯广告的数据分析系统
展开查看详情
1 .20 18 中 国 大 数 据 技 术 大 会 ( BD TC ) 李锐 腾讯广告的数据分析系统
2 . ) TC BD 关于我 ( 会 大 术 11年加入腾讯 技 据 关注分布式存储和计算系统 数 现负责腾讯广告数据系统 大 国 中 18 20
3 .腾讯社交广告 ) TC • 丰富的广告资源 BD ( 会 大 术 技 据 • 精准的定向能力 数 大 国 中 18 20
4 .数据分析 ) TC • 预先聚合 • 查询时聚合 BD ( • 实时+离线 • 预先将数据处理成易 会 大 于查询的格式 术 技 • 灵活性不够 据 • 灵活性高 数 • 查询速度快 大 • 查询时计算量大 国 中 18 20
5 .20 18 中 国 大 数 据 技 术 大 会 ( BD 预先聚合的计算系统 TC )
6 .LAMDA架构 ) TC BD 实时 离线 ( 接入 消息队列 会 yarn TDW 大 storm 术 Timer Hdfs 技 spout spout spout spout spout 据 计算 数 MapReduce 大 Bolt Bolt Bolt 国 中 HBase Hdfs 18 存储 20 实时性 + 可靠性
7 .统一计算框架 ) TC • 问题:任务越来越多,计算资源消耗越来越大 BD ( 会 • 合并原始数据聚合的工作,减少重复IO和数据解析的开销 大 • 多个pig, hive, mapreduce -> 一个mapreduce生成多个聚合结果 术 • 技 一份代码,易于性能优化 据 • 时间均匀分布,提高集群利用率 数 大 国 中 18 20
8 .任务解耦 – 流式计算 ) TC 日志1 1 2 3 4 BD 理想 日志2 1 2 3 4 ( 日志3 1 2 3 4 数据及时到达 时间 会 大 计算任务 1 2 3 4 术 技 日志1 1 2 3 4 据 日志2 1 2 3 4 现实 数 日志3 1 2 3 4 总是有数据晚到 大 时间 国 如何减少MTBF? 计算任务 1 2 3 4 5 6 中 18 平均故障次数= ∑ 每个日志源的故障次数 + 计算系统故障次数 20 任务解耦:只计算已经就绪的数据。某个日志源故障不会影响其他数据。 避免故障时机群空闲,恢复后机群压力过大。
9 .向流式计算系统演进 ) TC BD 一代系统:lambda架构 快 ( •Storm纯内存计算,实时, 不准确 会 •MapReduce离线计算, 大 准确,慢 术 •实时离线两套系统,代 准 技 码实现和环境部署都是两 套 据 数 大 二代系统:流式计算 国 •Spark Streaming同时做到 中 准确实时 •Spark worker常驻进程, 18 避免进程启停开销 快+准 20 •Spark分层调度,减少中 央调度器的压力
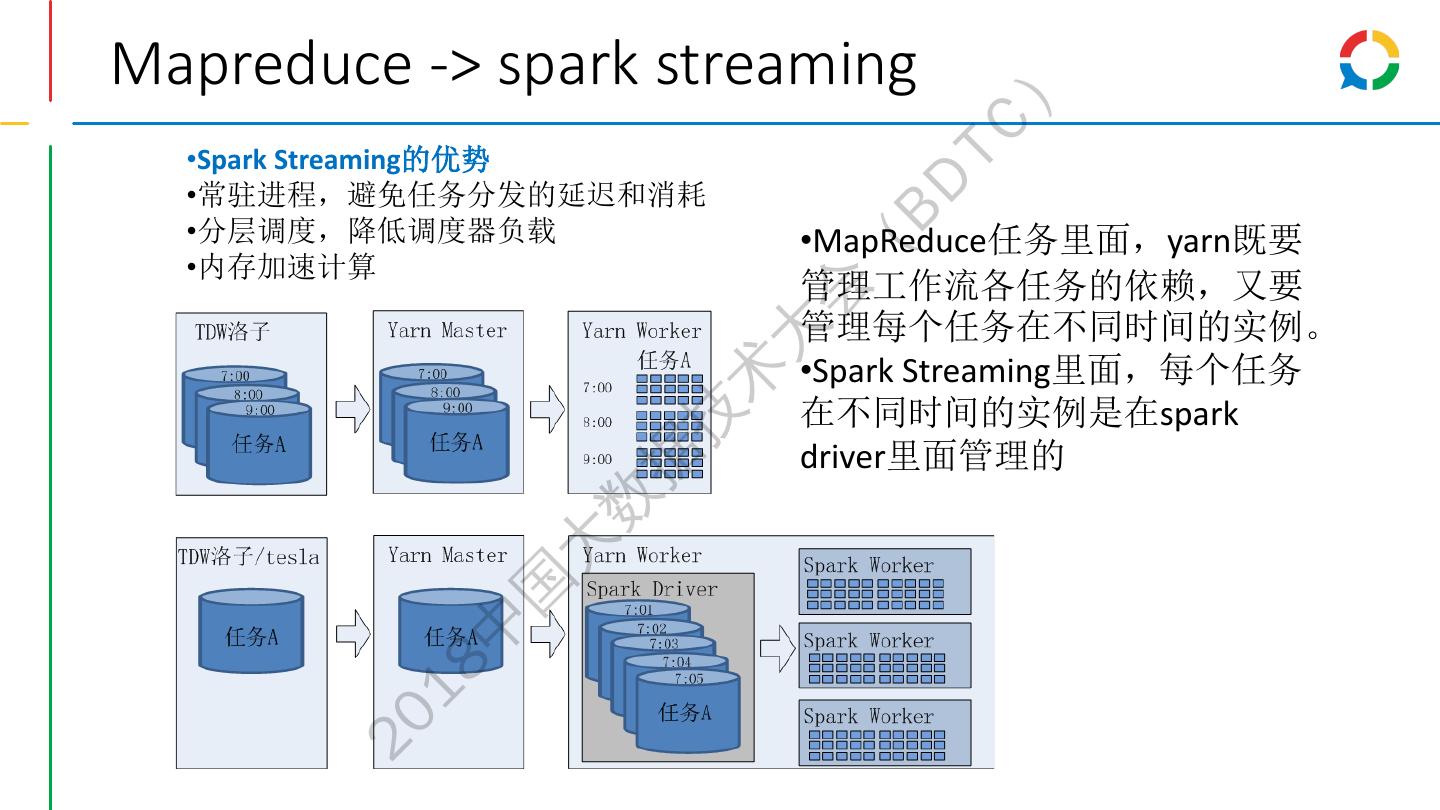
10 .Mapreduce -> spark streaming ) TC •Spark Streaming的优势 BD •常驻进程,避免任务分发的延迟和消耗 •分层调度,降低调度器负载 •MapReduce任务里面,yarn既要 ( •内存加速计算 管理工作流各任务的依赖,又要 会 管理每个任务在不同时间的实例。 大 •Spark Streaming里面,每个任务 术 在不同时间的实例是在spark 技 driver里面管理的 据 数 大 国 中 18 20
11 .计算流程 ) TC BD ( 会 大 术 技 据 数 大 日志切分:数据按最细时间粒度落地到hdfs 国 计算:分粒度聚合,输入输出都在hdfs,相当于用spark调度更小 中 的mapreduce作业 18 将hdfs目录当做checkpoint,不依赖spark的状态 20
12 .输出到hbase ) TC • 需要保证操作幂等 BD ( • 采用put而不是increase 会 • 每次输出的时候,累加过去N个周期的计算结果 大 术 • 与上次周期的输出数据计算diff,减少对hbase压力 技 据 • 不采用spark window,避免输出任务batch之间依赖,在集群抖动时 数 快速恢复 大 国 • 利用hbase version,避免新数据被老数据覆盖 中 18 20
13 .调度优化 ) TC • 推测执行,避免struggle BD ( • 会有很多的推测备份任务被杀掉 会 大 术 技 据 数 大 国 中 18 20
14 .调度优化 ) TC • 优化思路 BD • 利用 streaming周期任务的特点,动态评估每个 executor 的吞吐量 ( • 能力强的节点分配大任务,能力弱的节点分配小任务 会 • 实现 大 术 • a) RDD 及 NewHadoopRDD:获取每个 task 对应的 HDFS 文件的 大小并上报 技 • b) 在每个 batch 结束时,分析 executor 处理任务的情况,动态更新到 driver 端的记录里 据 • c) 按照 executor 的 吞吐量排序在任务列表里选择合适的任务 数 Executor1 (4MB/s) Task (32M) 大 Task (32M) 1 Executor1 (8MB/s) 选择最适合 Task1 (128M) Task2 (120M) 国 executor 3 Executor2 Task Task Executor2 Task3 Task4 执行的任务 中 (1MB/s) (128M) (128M) 2 (4MB/s) (110M) (96M) 18 Executor1 Task Task Executor3 Task5 Task6 3 (4MB/s) (128M) (32M) (2MB/s) ⌊¾ * 5⌋ = 3 (80M) (78M) 20 Executor2 Task Task Executor4 Task7 Task8 4 (1MB/s) (32M) (128M) (1MB/s) (75M) (70M)
15 . 调度优化 ) TC • 性能提升 BD • a) 推测任务减少 86.57% b) 计算延迟降低 20.96% ( 会 大 术 技 据 • c) 少用 1/10 资源 数 大 国 中 18 20
16 . ) TC BD ( 预先聚合的计算系统 会 大 统一计算框架 术 技 Lamda架构->spark streaming 据 数 大 国 中 18 20
17 .20 18 中 国 大 数 据 技 术 大 会 ( BD 查询时聚合的计算系统 TC )
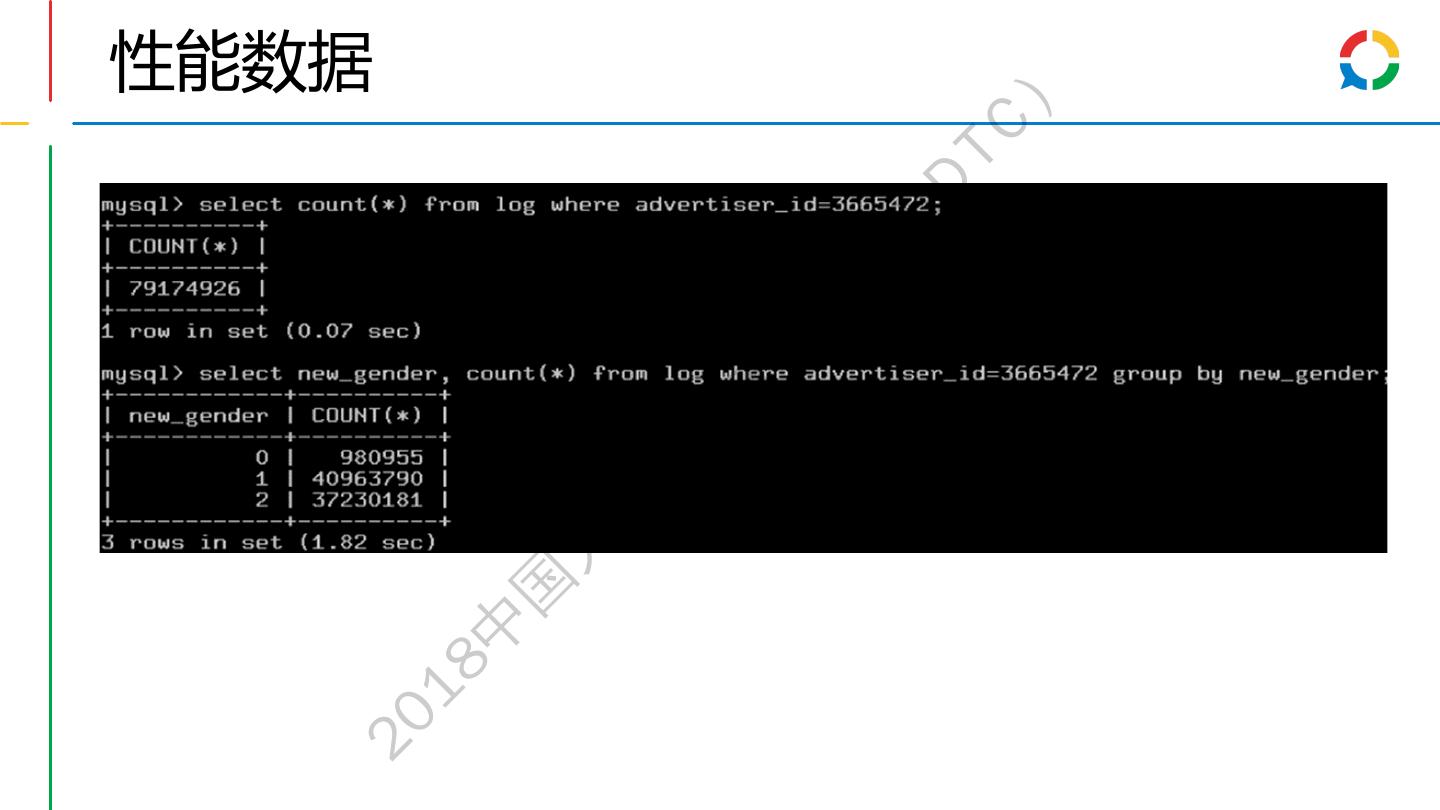
18 .要解决的问题 - SQL举例 ) TC • 从万亿条数据中选择符合条件的数据,计算聚合结果 BD 查询用户年龄性别的分布 ( • 会 SELECT age, gender, COUNT(*) FROM log WHERE advertiser_id=123 group by age, gender; 大 • 查询不同曝光次数的用户的占比、点击率、消耗等 术 SELECT exposure_num, COUNT(*) as user_num, 技 SUM(sum_click) / SUM(exposure_num) as click_rate, SUM(sum_cost) AS total_cost 据 FROM 数 (SELECT user_id, COUNT(*) AS exposure_num, 大 国 SUM(click_count) AS sum_click, SUM(cost) AS sum_cost 中 FROM log 18 GROUP BY user_id) temp_table 20 GROUP BY exposure_num;
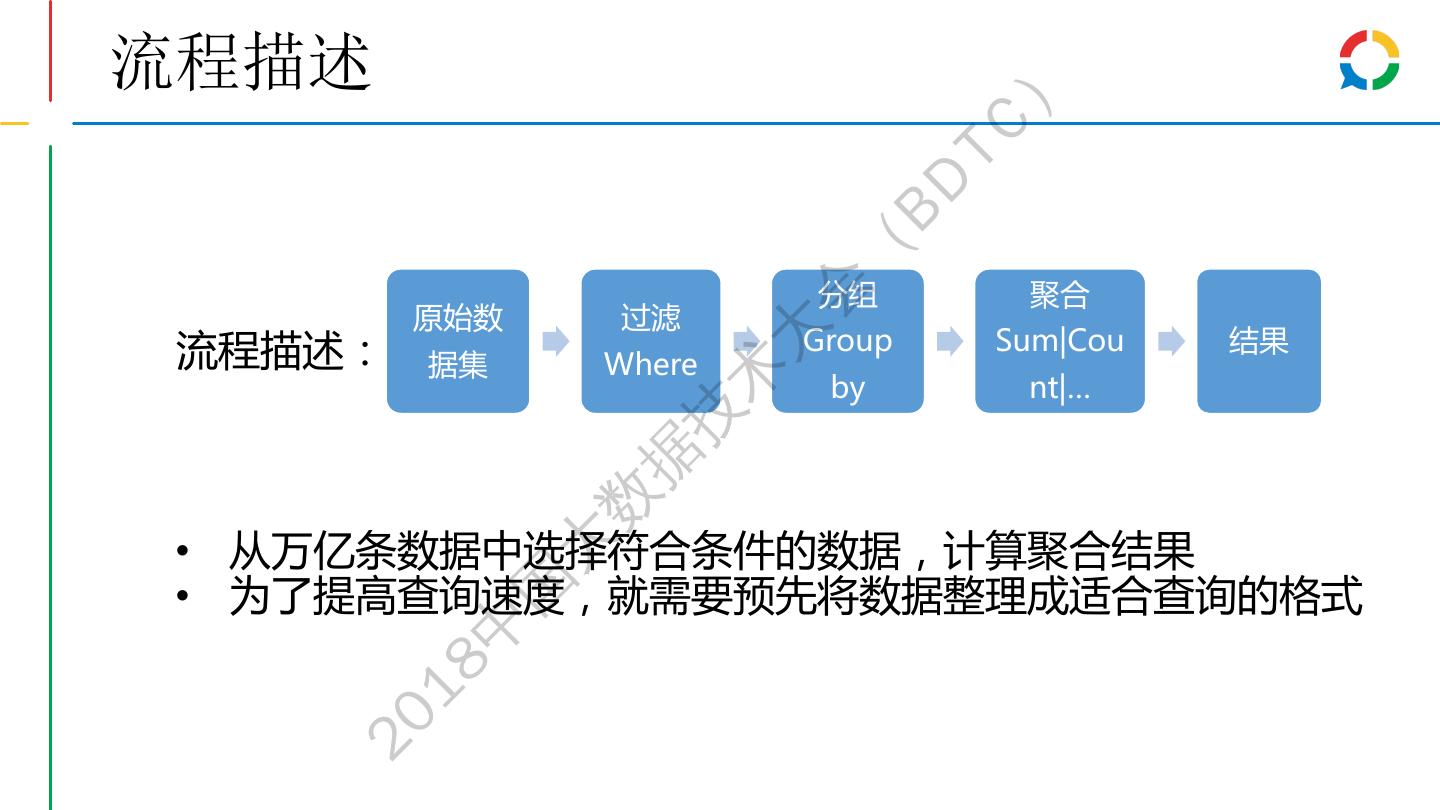
19 .流程描述 ) TC BD ( 分组 聚合 会 原始数 过滤 大 流程描述: Group Sum|Cou 结果 据集 Where 术 by nt|… 技 据 数 • 从万亿条数据中选择符合条件的数据,计算聚合结果 大 • 为了提高查询速度,就需要预先将数据整理成适合查询的格式 国 中 18 20
20 .两种数据模型 ) TC BD 1. 平铺结构:宽表,其中每个cell可以是term list,可以有正排,倒排 ( 2. 嵌套结构:proto buffer,正排存储类似于dremel/parquet,没法倒排 会 Message pageview { 大 optional UserProfile user; 术 repeated Position pos { 技 repeated Impression imps { 据 optional Advertisement ad; 数 大 repeated Click clicks { 国 optional BillInfo bill; 中 } 18 } 20 } }
21 .嵌套结构的列存储格式 dragon ) TC BD • 同列数据连续存储,压缩效率高 ( • 读取数据只需读取需要的列,节省磁盘IO 会 大 术 • 读取数据省去了反序列化整个PB的过程 技 据 • 定义repetition level和definition level 数 大 • 只存储叶子节点的值和rlevel,dlevel 国 中 18 20
22 .Dragon vs parquet ) TC 文件大小(单位:MB) 写入时间(单位:秒) BD 800 700 500 383 ( 600 400 Dragon 300 254 289 会 400 266 271 Dragon 211 parquet 200 138 大 200 153 161 parquet recordio 100 术 0 0 技 请求日志 曝光日志 请求日志 曝光日志 据 数 数据读取耗时(单位:秒) 8 6.7 6.7 大 6.7 国 6 4.5 Dragon 中 4 3.4 2.1 Parquet 18 2 1.6 0.1 0.5 Recordio 20 0 读一列 读三列 读十列
23 .数据特点 ) TC Message pageview { • BD 空节点很多 optional UserProfile user; • Pageview:3000+叶子节点 repeated Position pos { ( • Pos : 3000+叶子节点 repeated Impression imps { 会 • Imps : 2000+ 叶子节点 • Click : 1000+ leaves optional Advertisement ad; 大 • Candidated_ads : 200+ 叶子节点 repeated Ad candidate_ads; 术 repeated Click clicks { 技 optional BillInfo bill; 据 请求日志 曝光日志 } 数 } Empty Columns 2926 大 2868 } } 国 Empty 855 831 中 Groups 18 20
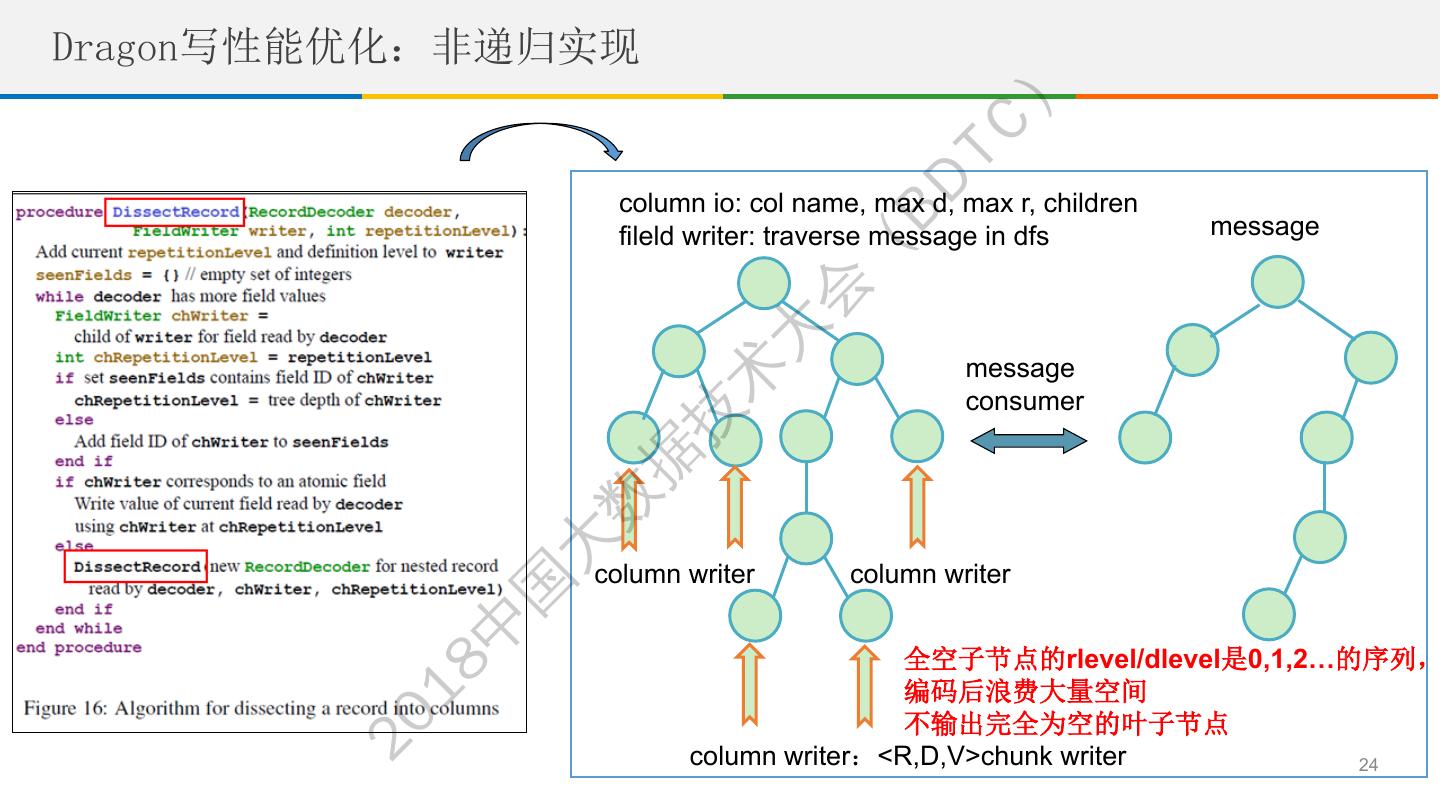
24 .Dragon写性能优化:非递归实现 ) TC BD column io: col name, max d, max r, children fileld writer: traverse message in dfs message ( 会 大 message 术 consumer 技 据 数 大 column writer column writer 国 中 全空子节点的rlevel/dlevel是0,1,2…的序列, 18 编码后浪费大量空间 不输出完全为空的叶子节点 20 column writer:<R,D,V>chunk writer 24
25 .Dragon写性能优化:空节点缓存 ) TC Proto 模板 Group : List<Pair<R,D>> BD message1 message2 ( 会 大 术 技 据 message3 message4 数 大 国 中 遇到空节点,先不 用遍历子树,缓存 18 到有值或文件结束 20 再遍历到子节点 25
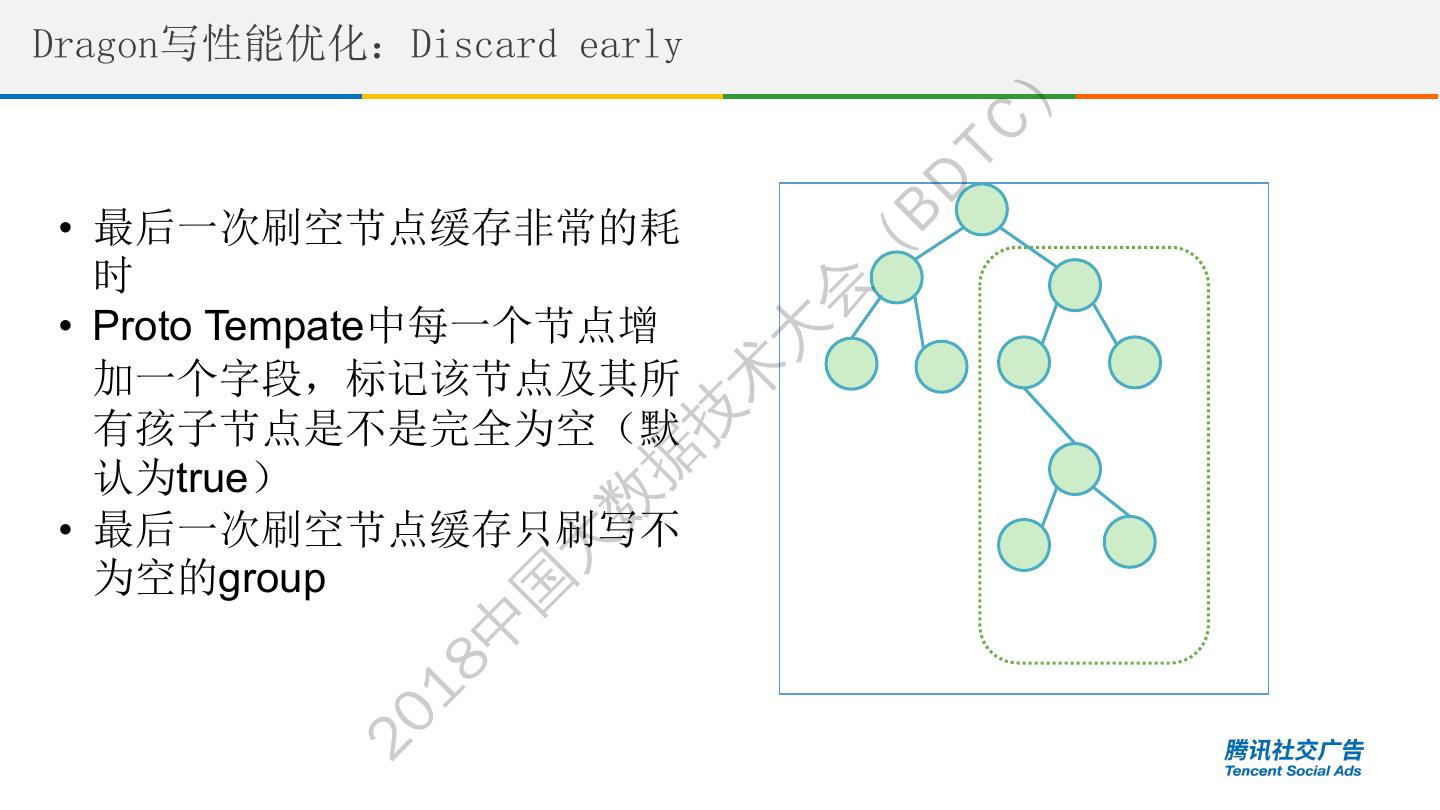
26 .Dragon写性能优化:Discard early ) TC BD • 最后一次刷空节点缓存非常的耗 ( 时 会 • Proto Tempate中每一个节点增 大 加一个字段,标记该节点及其所 术 技 有孩子节点是不是完全为空(默 据 认为true) 数 • 最后一次刷空节点缓存只刷写不 为空的group 大 国 中 18 20
27 .Dragon写性能优化:lazy flush ) TC • 每次刷空节点缓存时,只刷到孩子节点,而不是叶子节点 BD ( Proto 会 优化前 优化后 template 大 术 技 据 数 Total 大 empty 国 中 27 18 20
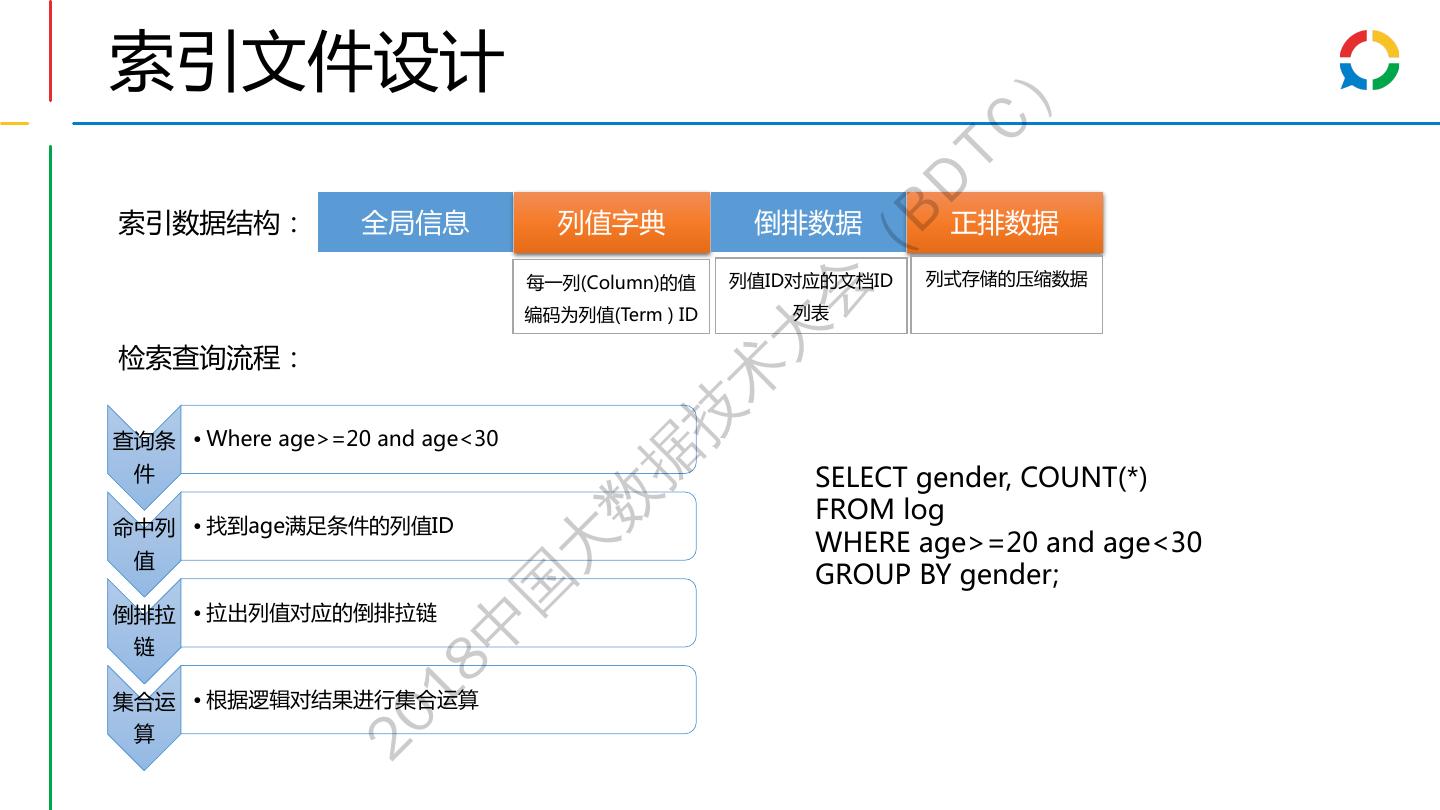
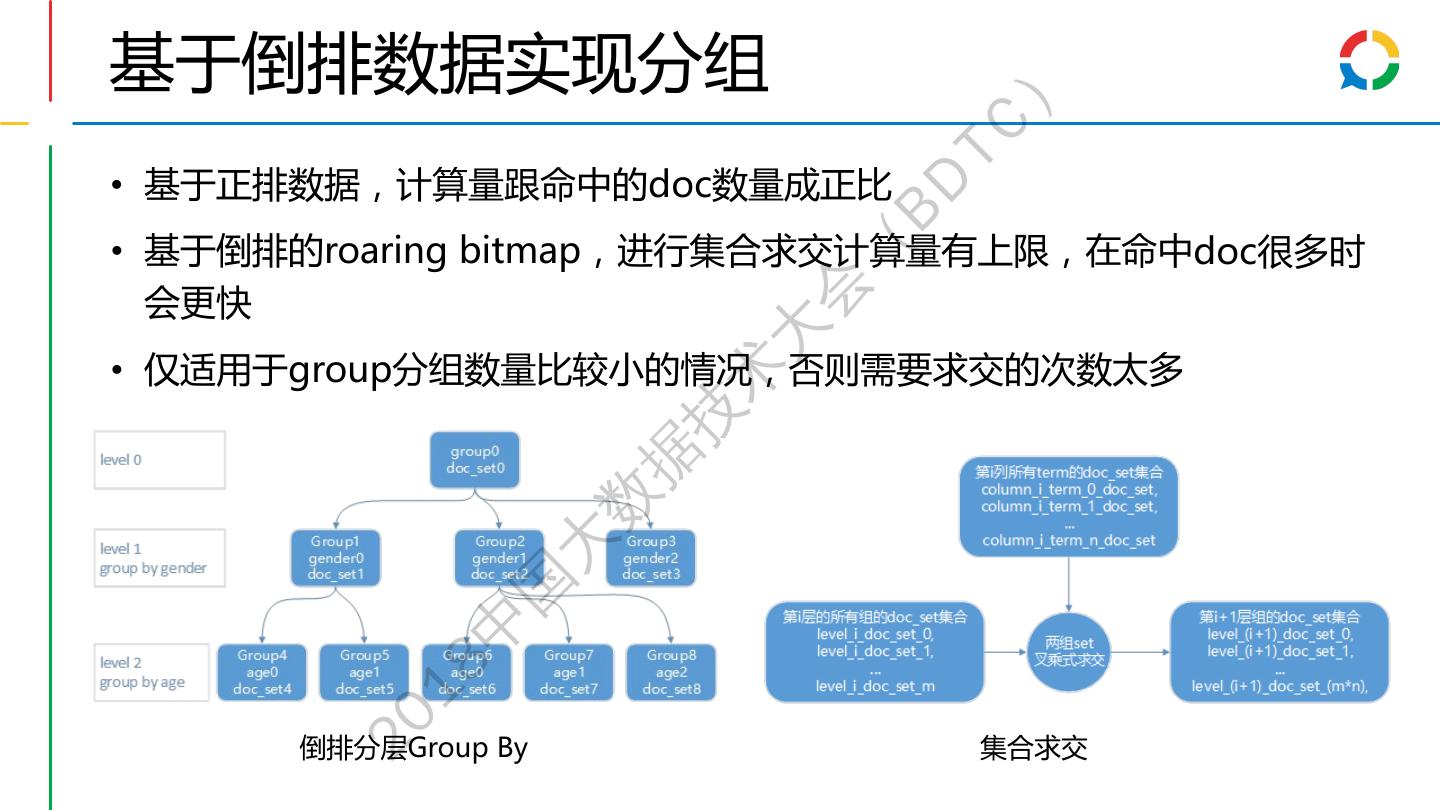
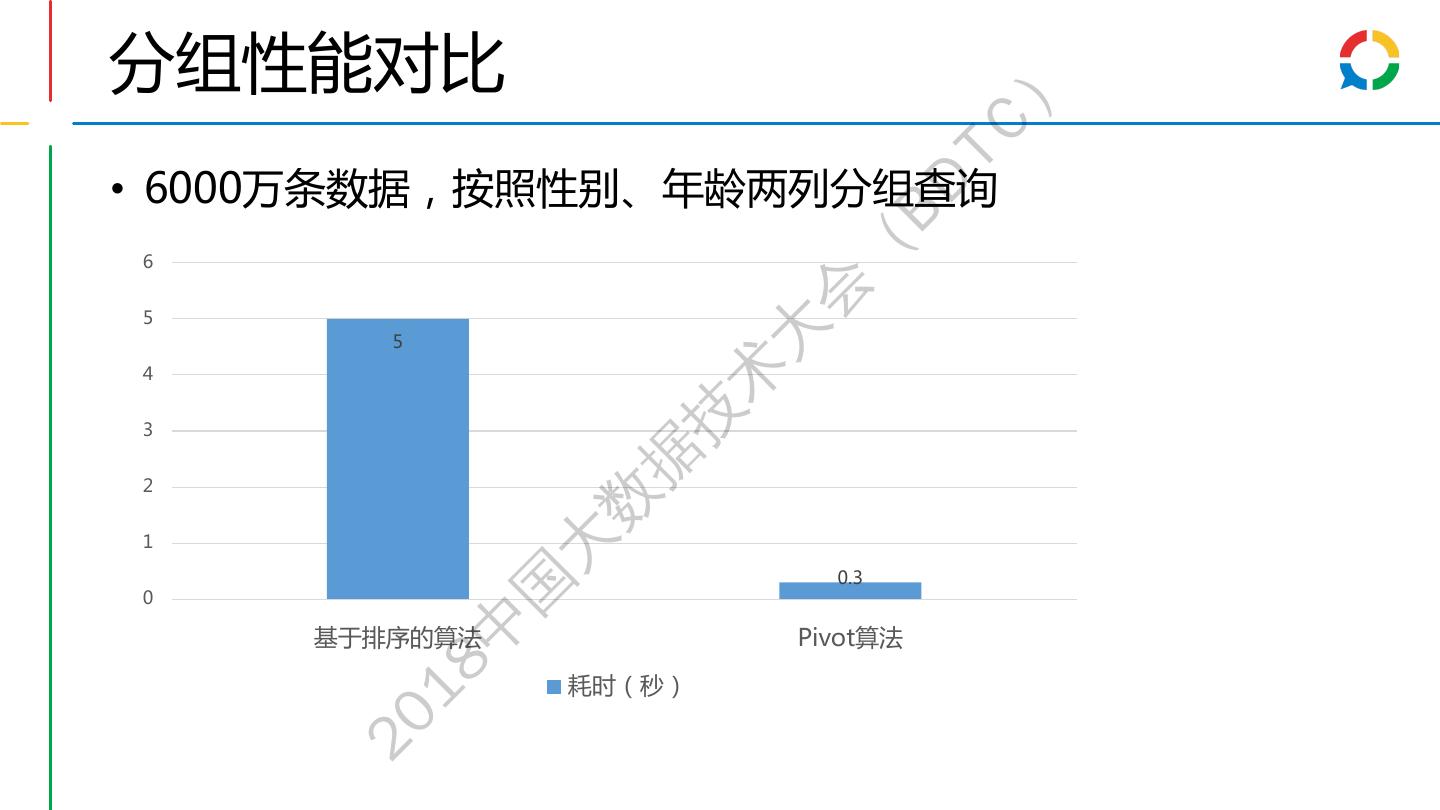
28 .索引文件设计 ) TC BD 索引数据结构: 全局信息 列值字典 倒排数据 正排数据 ( 每一列(Column)的值 列值ID对应的文档ID 列式存储的压缩数据 会 编码为列值(Term ) ID 列表 大 检索查询流程: 术 技 查询条 • Where age>=20 and age<30 据 件 SELECT gender, COUNT(*) 数 FROM log 命中列 • 找到age满足条件的列值ID WHERE age>=20 and age<30 值 大 GROUP BY gender; 国 倒排拉 • 拉出列值对应的倒排拉链 中 链 18 集合运 • 根据逻辑对结果进行集合运算 20 算
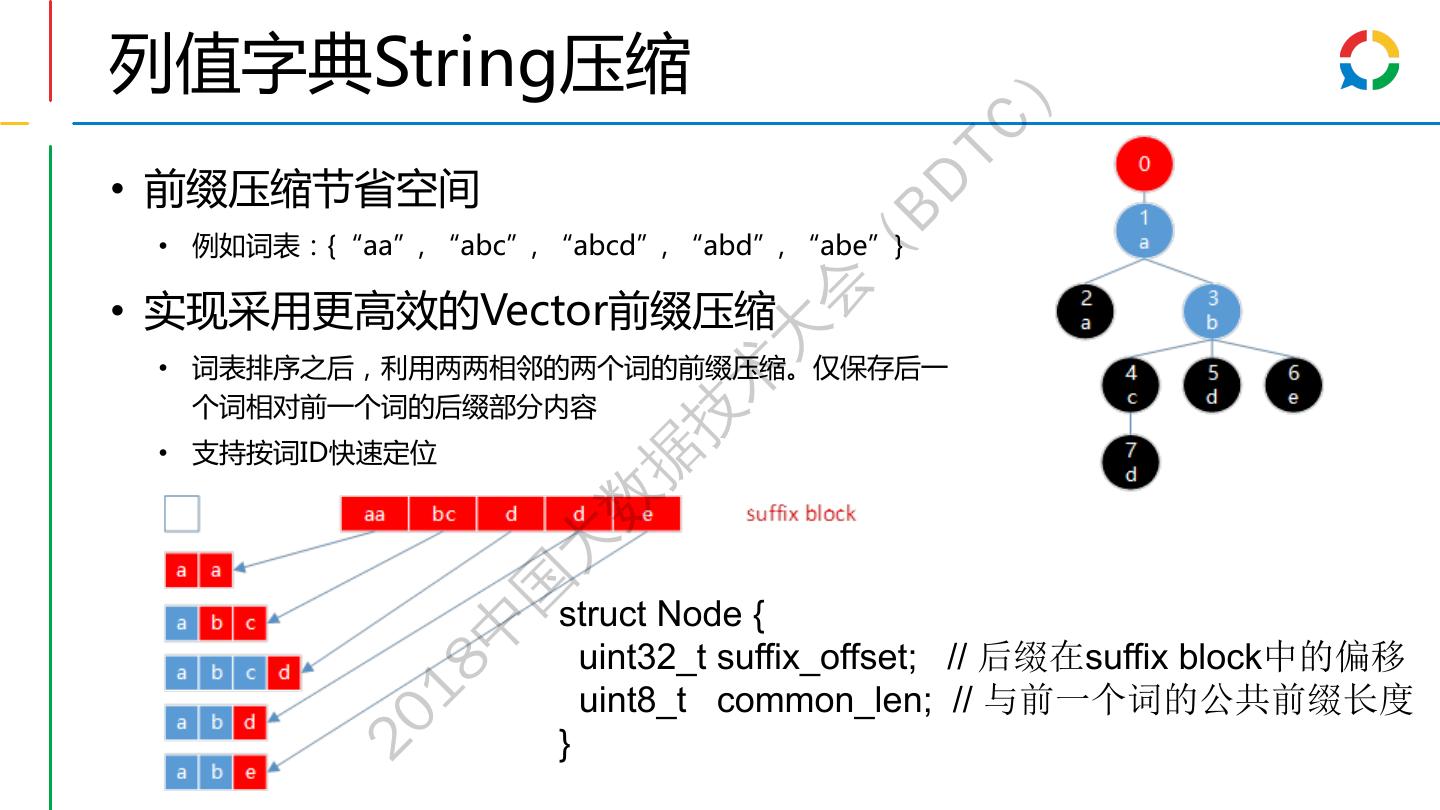
29 .列值字典String压缩 ) TC • 前缀压缩节省空间 BD • 例如词表:{“aa”, “abc”, “abcd”, “abd”, “abe”} ( 会 • 实现采用更高效的Vector前缀压缩 大 • 词表排序之后,利用两两相邻的两个词的前缀压缩。仅保存后一 术 个词相对前一个词的后缀部分内容 技 • 支持按词ID快速定位 据 数 大 国 struct Node { 中 uint32_t suffix_offset; // 后缀在suffix block中的偏移 18 uint8_t common_len; // 与前一个词的公共前缀长度 20 }
相关推荐

加关注
3秒后跳转登录页面
去登陆

