




























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
23-Spark RDD concept
Hadoop used to be slow until a Berkeley project called Spark came up with a clever new caching concept centered on resilient distributed data objects or RDDs. We'll look at how these work, and how they can talk to temporal data from sensors.
展开查看详情
1 .CS5412 / Lecture 23 Apache Spark and RDDs Kishore Pusuku ri, Spring 2019 HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 1
2 .Recap 2 MapReduce For easily writing applications to process vast amounts of data in-parallel on large clusters in a reliable, fault-tolerant manner Takes care of scheduling tasks, monitoring them and re-executes the failed tasks HDFS & MapReduce : Running on the same set of nodes compute nodes and storage nodes same (keeping data close to the computation) very high throughput YARN & MapReduce : A single master resource manager, one slave node manager per node, and AppMaster per application
3 .Today’s Topics 3 Motivation Spark Basics Spark Programming
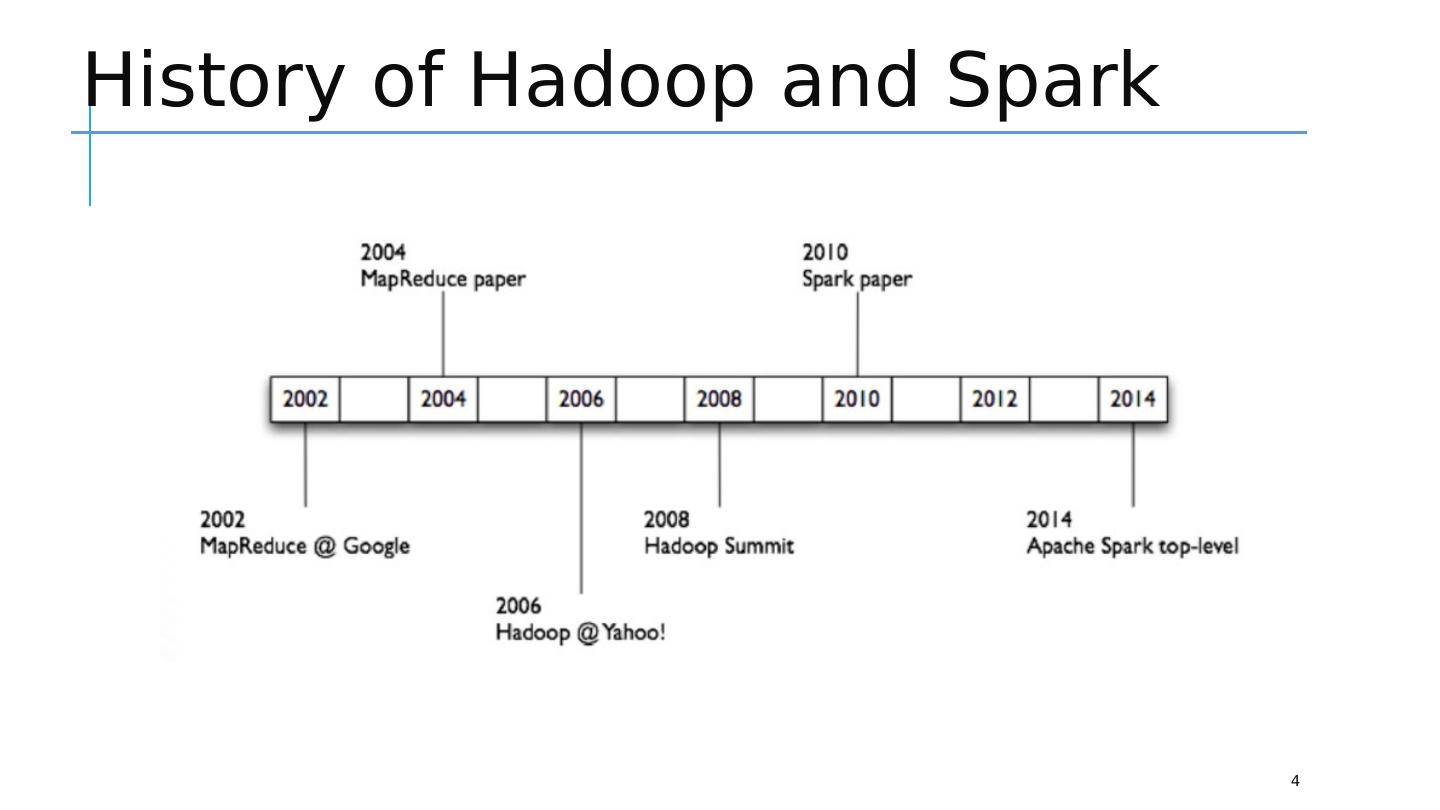
4 .History of Hadoop and Spark 4
5 .Apache Hadoop & Apache Spark 5 Yet Another Resource Negotiator (YARN) Map Reduce Hive Spark Stream Spark SQL Other Applications Data Ingestion Systems e.g., Apache Kafka, Flume, etc Hadoop Database (HBase) Hadoop Distributed File System (HDFS) Cassandra etc., other storage systems Mesos etc. Spark Core Pig Data Storage Resource manager Hadoop Spark Processing
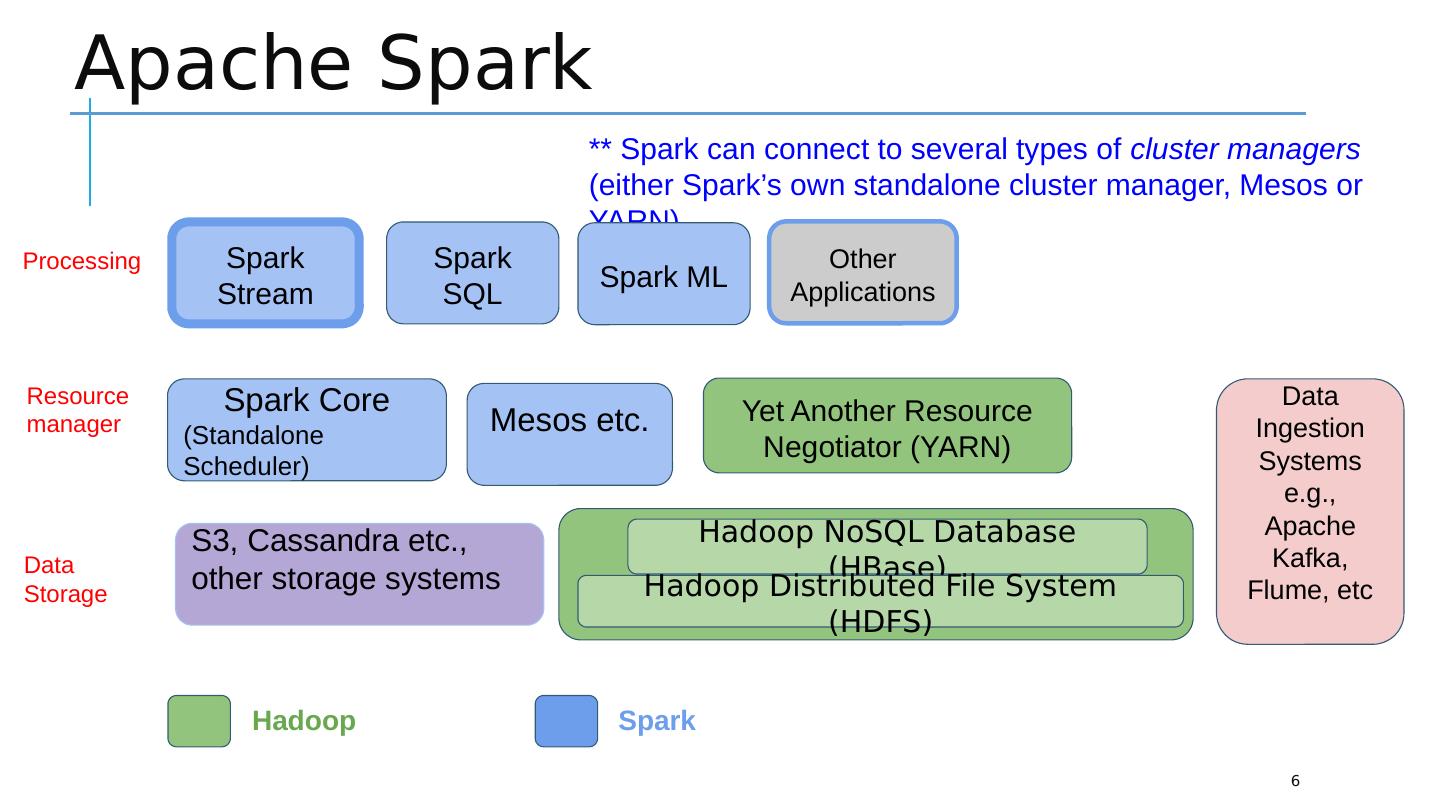
6 .Apache Spark 6 Yet Another Resource Negotiator (YARN) Spark Stream Spark SQL Other Applications Data Ingestion Systems e.g., Apache Kafka, Flume, etc Hadoop NoSQL Database (HBase) Hadoop Distributed File System (HDFS) S3, Cassandra etc., other storage systems Mesos etc. Spark Core (Standalone Scheduler) Data Storage Resource manager Hadoop Spark Processing ** Spark can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN) Spark ML
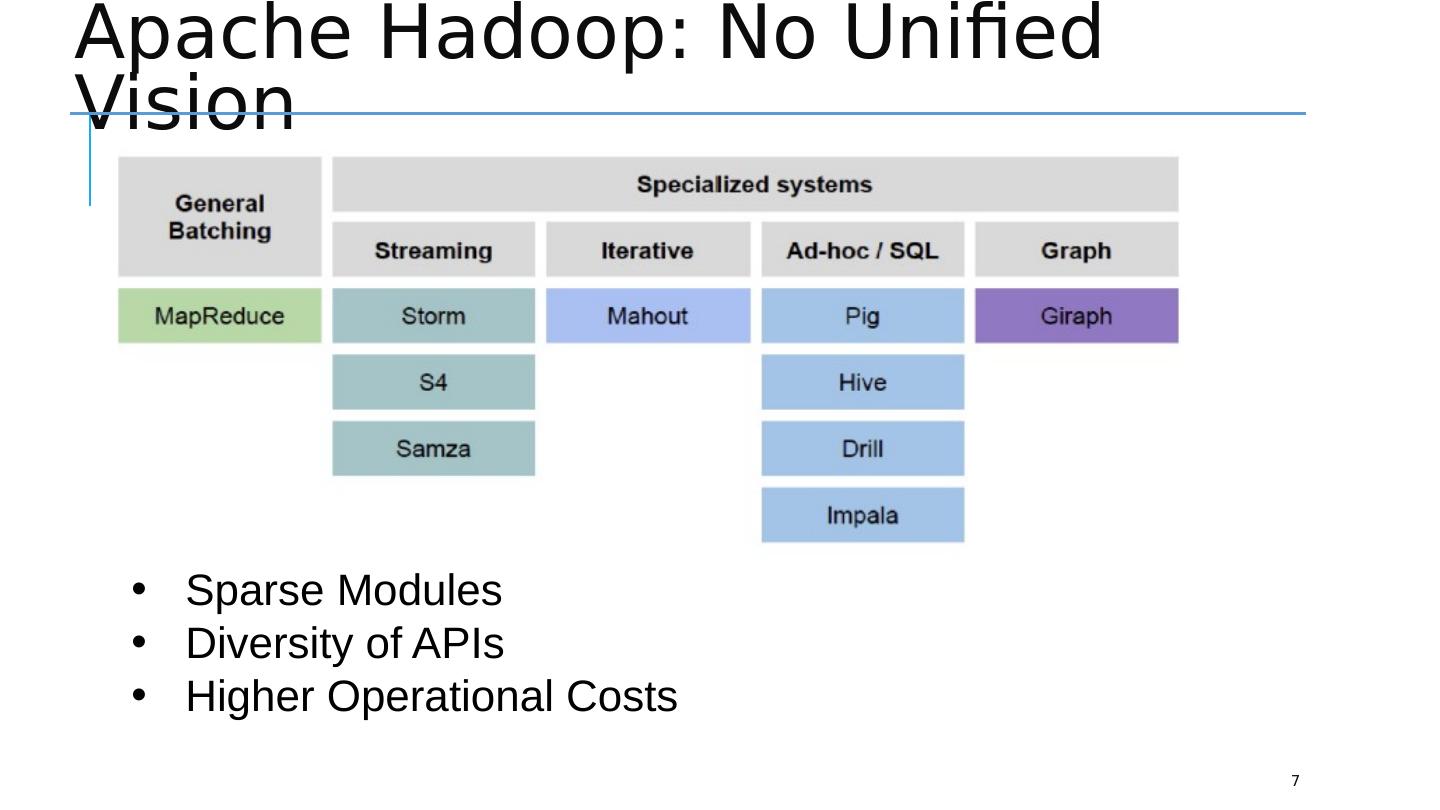
7 .Apache Hadoop: No Unified Vision 7 Sparse Modules Diversity of APIs Higher Operational Costs
8 .Spark Ecosystem: A Unified Pipeline 8
9 .Spark vs MapReduce: Data Flow 9
10 .Data Access Rates 10 With in a node: CPU to Memory: 10 GB/sec CPU to HardDisk : 0.1 GB/sec CPU to SSD: 0.6 GB/sec Nodes between networks: 0.125 GB/sec to 1 GB/sec Nodes in the same rack: 0.125 GB/sec to 1 GB/sec Nodes between racks: 0.1 GB/sec
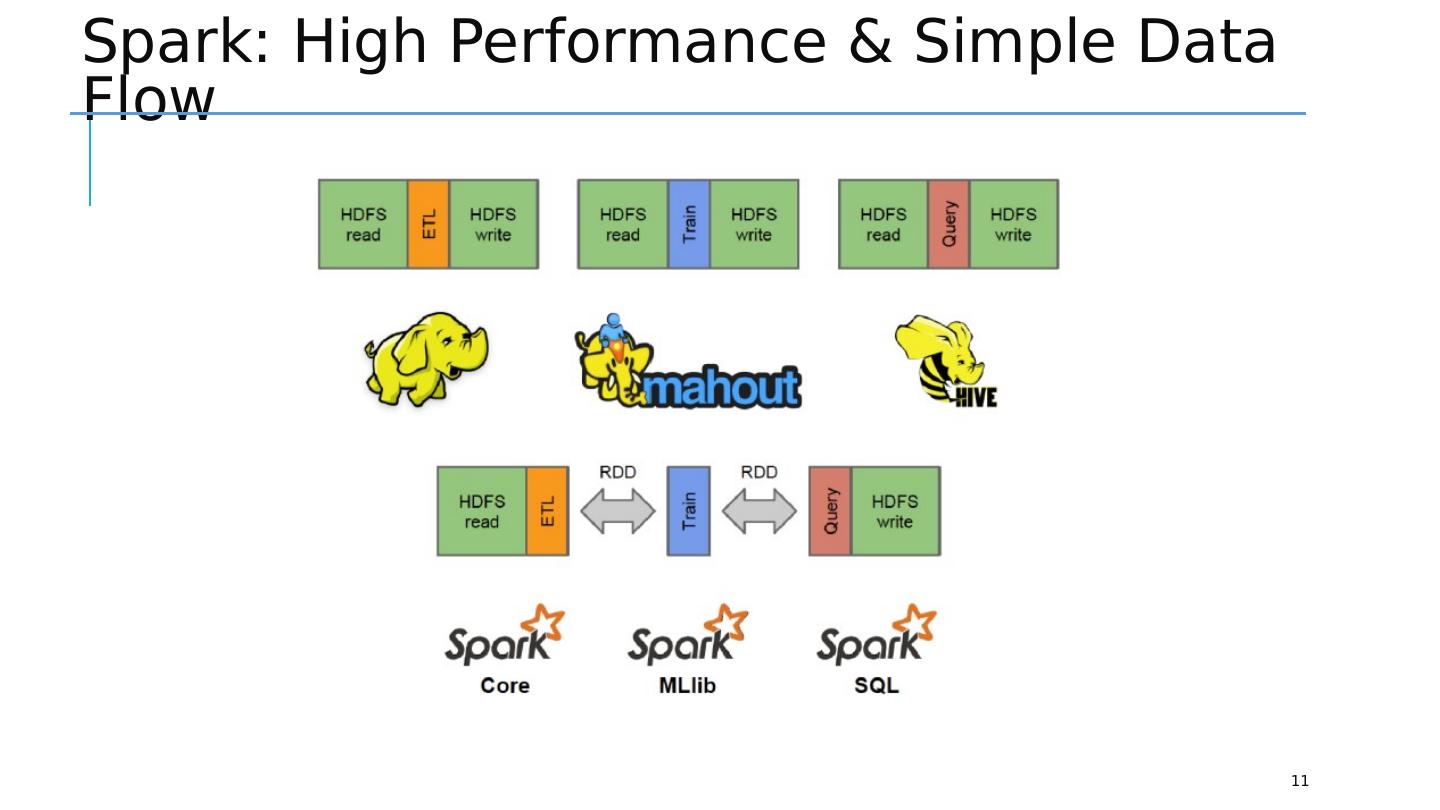
11 .Spark: High Performance & Simple Data Flow 11
12 .Performance: Spark vs MapReduce (1) 12 Iterative algorithms Spark is faster a simplified data flow Avoids materializing data on HDFS after each iteration Example: k-means algorithm, 1 iteration HDFS Read Map(Assign sample to closest centroid) GroupBy ( Centroid_ID ) NETWORK Shuffle Reduce(Compute new centroids) HDFS Write
13 .Performance: Spark vs MapReduce (2) 13
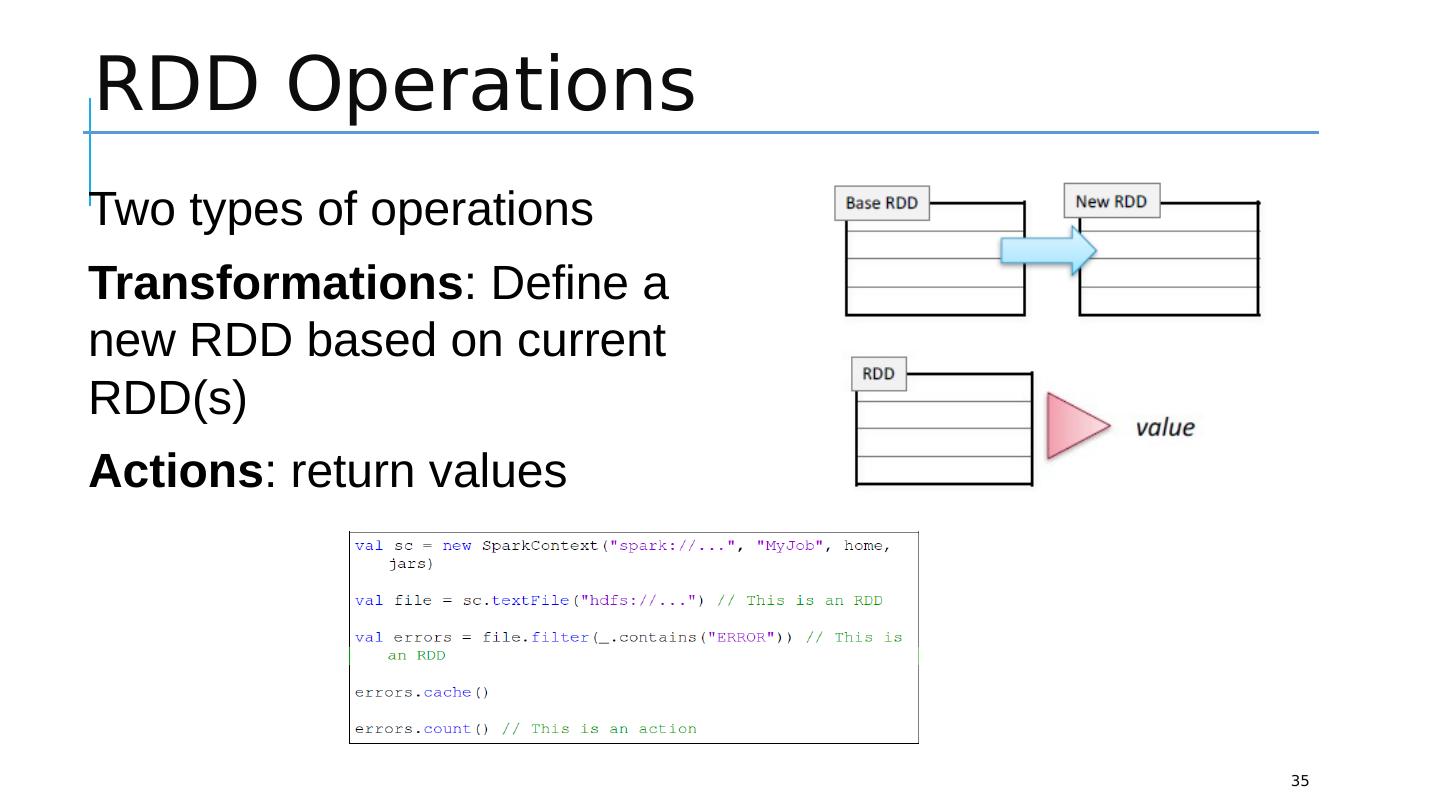
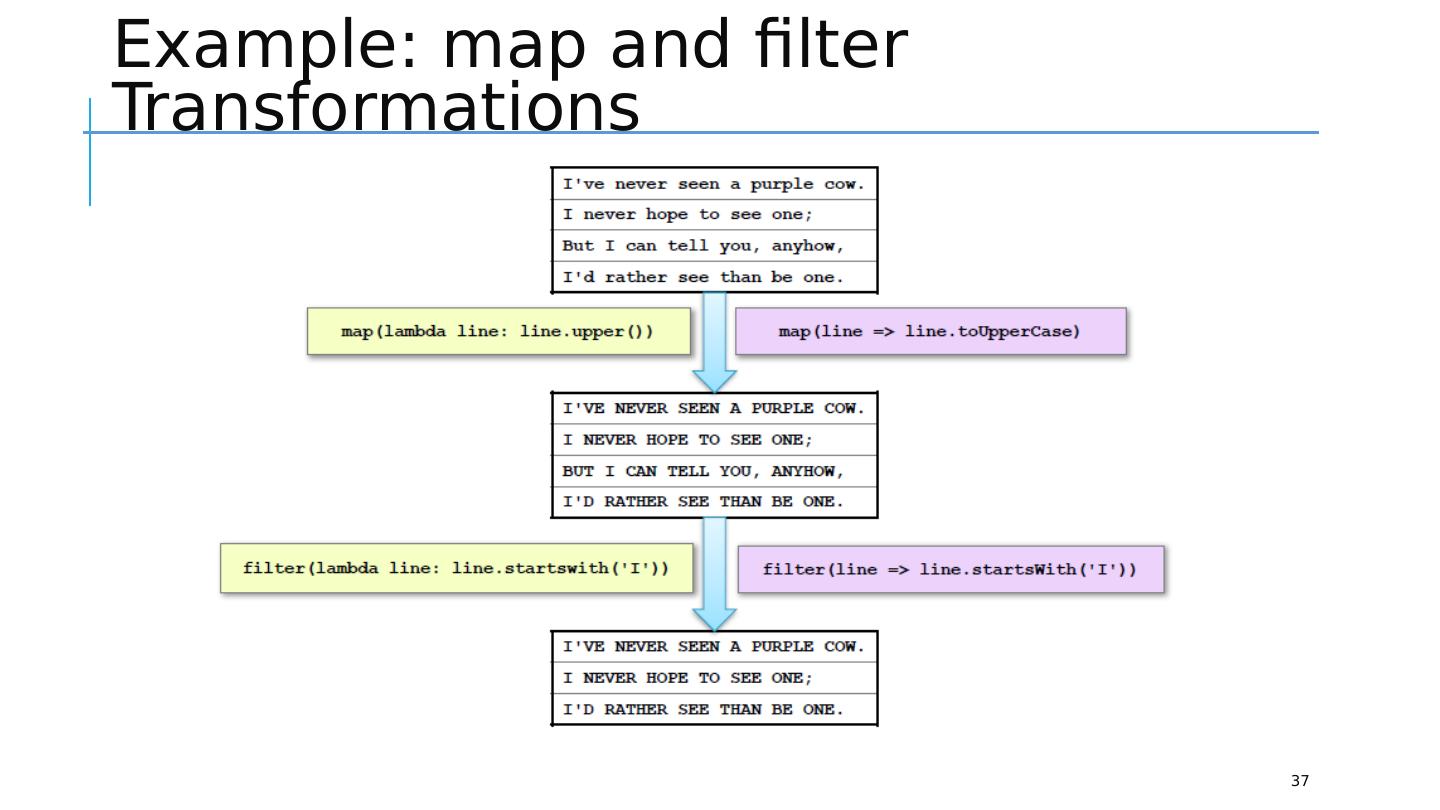
14 .Code: Hadoop vs Spark (e.g., Word Count) 14 Simple/Less code Multiple stages pipeline Operations Transformations: apply user code to distribute data in parallel Actions: assemble final output from distributed data
15 .Motivation (1) 15 MapReduce : The original scalable, general, processing engine of the Hadoop ecosystem Disk-based data processing framework (HDFS files) Persists intermediate results to disk Data is reloaded from disk with every query → Costly I/O Best for ETL like workloads (batch processing) Costly I/O → Not appropriate for iterative or stream processing workloads
16 .Motivation (2) 16 Spark : General purpose computational framework that substantially improves performance of MapReduce, but retains the basic model Memory based data processing framework → avoids costly I/O by keeping intermediate results in memory Leverages distributed memory Remembers operations applied to dataset Data locality based computation → High Performance Best for both iterative (or stream processing) and batch workloads
17 .Motivation - Summary 17 Software engineering point of view Hadoop code base is huge Contributions/Extensions to Hadoop are cumbersome Java-only hinders wide adoption, but Java support is fundamental System/Framework point of view Unified pipeline Simplified data flow Faster processing speed Data abstraction point of view New fundamental abstraction RDD Easy to extend with new operators More descriptive computing model
18 .Today’s Topics 18 Motivation Spark Basics Spark Programming
19 .Spark Basics(1) 19 Spark: Flexible, in-memory data processing framework written in Scala Goals : Simplicity (Easier to use): Rich APIs for Scala, Java, and Python Generality: APIs for different types of workloads Batch, Streaming, Machine Learning, Graph Low Latency (Performance) : In-memory processing and caching Fault-tolerance: Faults shouldn’t be special case
20 .Spark Basics(2) 20 There are two ways to manipulate data in Spark Spark Shell : Interactive – for learning or data exploration Python or Scala Spark Applications For large scale data processing Python, Scala, or Java
21 .Spark Shell 21 The Spark Shell provides interactive data exploration (REPL) REPL: Repeat/Evaluate/Print Loop
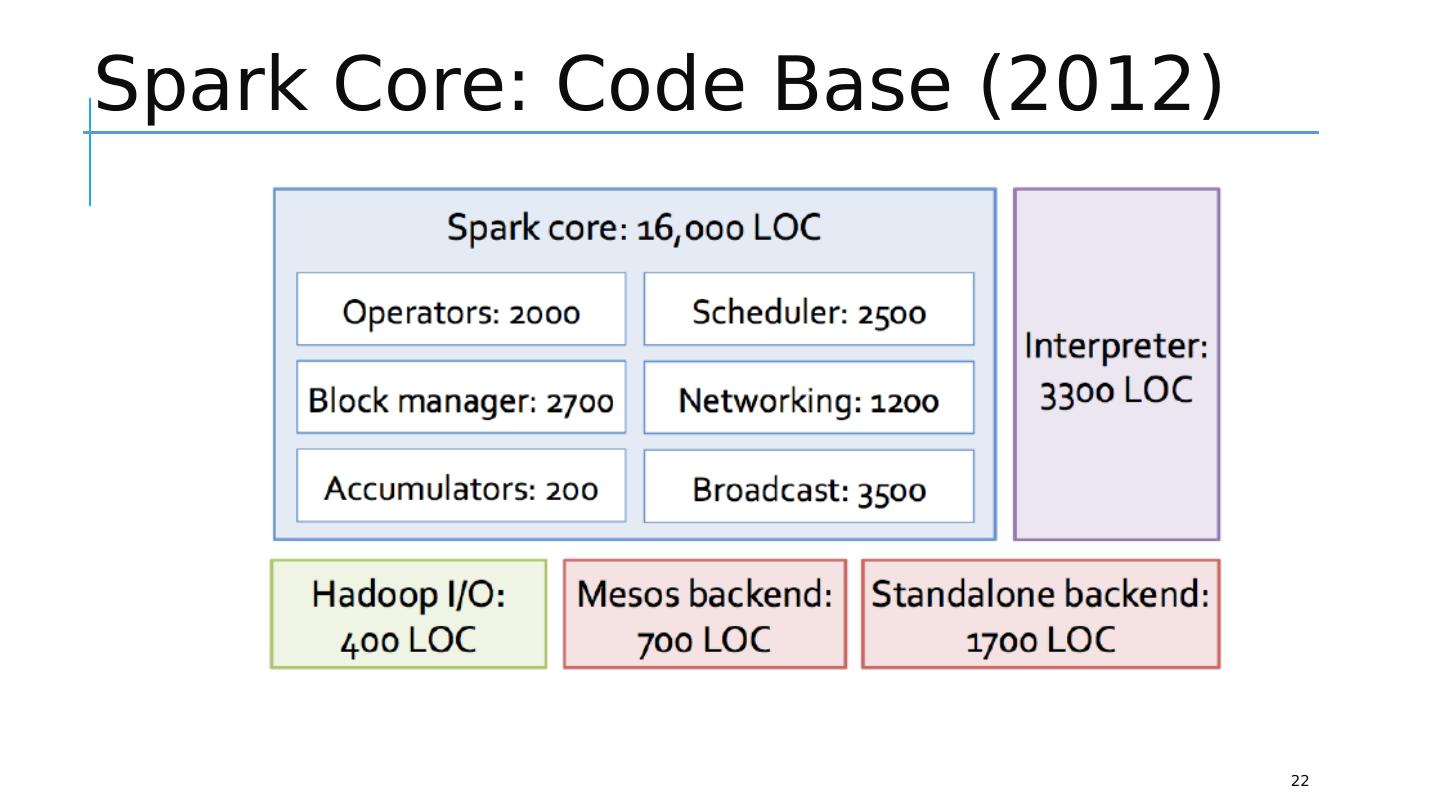
22 .Spark Core: Code Base (2012) 22
23 .Spark Fundamentals 23 Spark Context Resilient Distributed Data Transformations Actions Example of an application:
24 .Spark: Fundamentals 24 Spark Context Resilient Distributed Datasets (RDDs) Transformations Actions
25 .Spark Context (1) 25 Every Spark application requires a spark context: the main entry point to the Spark API Spark Shell provides a preconfigured Spark Context called “ sc ”
26 .Spark Context (2) 26 Standalone applications Driver code Spark Context Spark Context represents connection to a Spark cluster Standalone Application (Driver Program)
27 .Spark Context (3) 27 Spark context works as a client and represents connection to a Spark cluster
28 .Spark Fundamentals 28 Spark Context Resilient Distributed Data Transformations Actions Example of an application:
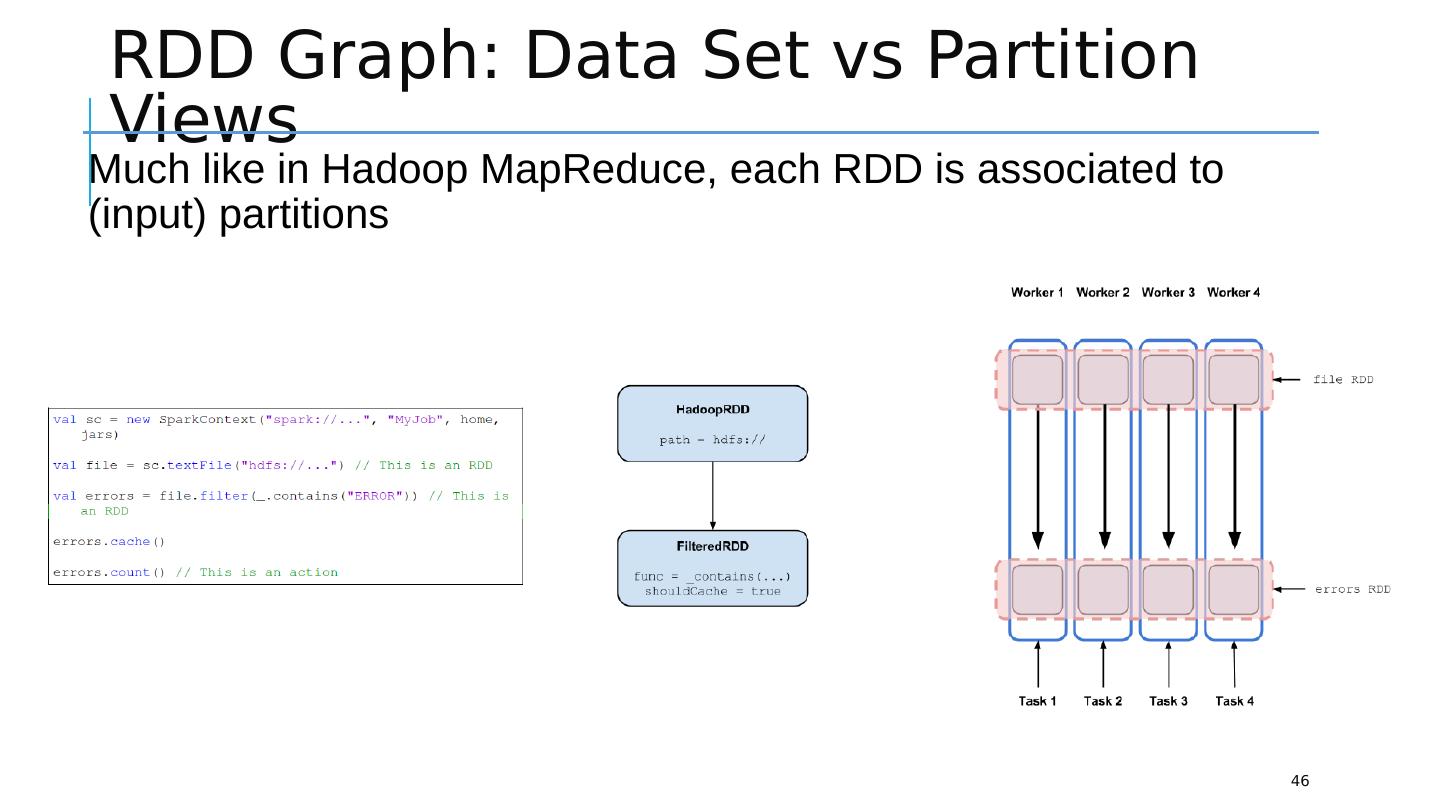
29 .Resilient Distributed Dataset 29 RDD (Resilient Distributed Dataset) is the fundamental unit of data in Spark : An Immutable collection of objects (or records, or elements) that can be operated on “in parallel” ( spread across a cluster) Resilient -- if data in memory is lost, it can be recreated Recover from node failures An RDD keeps its lineage information it can be recreated from parent RDDs Distributed -- processed across the cluster Each RDD is composed of one or more partitions (more partitions – more parallelism) Dataset -- initial data can come from a file or be created
3秒后跳转登录页面
去登陆

