























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
21-The Apache big-data technologies
Hadoop is a popular open-source version of MapReduce. We'll discuss the MapReduce model, and then talk about how Hadoop actually works. Hadoop is a way to run parallel batch applications on files, using a scheduler called YARN and a set of file access accelerators called HBase, PIG and Hive. We won't talk about PIG and Hive in this lecture.
展开查看详情
1 .CS5412 / Lecture 21 Big Data Systems Ken Birman & Kishore Pusuku ri , Spring 2019 HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 1
2 .PUTTING IT ALL TOGETHER We have seen a great deal of the structure at the edge of the cloud, and how it might “talk” to data sources of various kinds. Tasks like machine learning and “big data” analytics occur at the back. How are these connected together? Some tier two -services store data into files or append-only logs Periodically (delay depends on the use) we process in batches. … we batch the operations because of the massive scale. … idea is to compute “once” but answer many questions! HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 2
3 .Batched computing For example, imagine a smart city. We could collect a batch of new location data, then update all the “people locations” in some database in a single (parallel) computation. One computation reads a lot of files, and updates many data fields. The pattern is typical of today’s cloud. Due to delays, batched computing not ideal for instant reaction. … But it is adequate for tasks where a short delay is fine. 3
4 .Why batch? The core issue is overhead. Doing things one by one incurs high overheads. Updating data in a batch pays the overhead once on behalf of many events, hence we “amortize” those costs. The advantage can be huge. But batching must accumulate enough individual updates to justify running the big parallel batched computation. Tradeoff: Delay versus efficiency. 4
5 .Exponential Growth of Data (Big Data) Petabytes of data need to be processed or accessed everyday 300 Billion Google searches per day 300 Million photos uploaded on Facebook per day Nature of the data causes it to be massive: 3 V’s Volume, Velocity, and Variety The volume of unstructured data exploded in the past decade By 2020, it will be 53 ZettaBytes (53 trillion gigabytes) -- an increase of 10 times in 15 years (it was below 5 ZB until 2003) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 5
6 .Common Big Data Use Cases Extract/Transform/Load (ETL) – Huge Data Warehouses Text Mining Graph Creation and Analysis Prediction Models Analytics HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 6 To exploit batching, Google/Facebook etc., precompute the results for anticipated search queries. They analyze data in batches, then cache results.
7 .Big Data Processing? Nature of the data forces us to use massive parallelism Recall: Huge Volumes, High Velocity, and Variety Traditional Single Server Systems are far to weak for processing petabytes of data – insufficient compute and storage The only option: Distribute data, obtain parallelism with multiple servers HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 7
8 .Traditional Distributed Systems The Data Bottleneck: Data was historically first stored in a central location … then copied to processors at runtime Fine for limited amounts of data, breaks with massive data sets Solution : A new style in which we process huge numbers of data files in parallel -- BigData Systems (e.g., Apache Hadoop, Apache Spark) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 8
9 .Big Data Systems Two key ideas Distribute data right from the outset, when the data is initially stored Bring computation to the data rather than sending data to the computation Scalable and economical data storage, processing and analysis Distributed and Fault-tolerant Harness the power of industry standard hardware Heavily inspired by Open Source technologies (HDFS, HBase , etc.) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 9
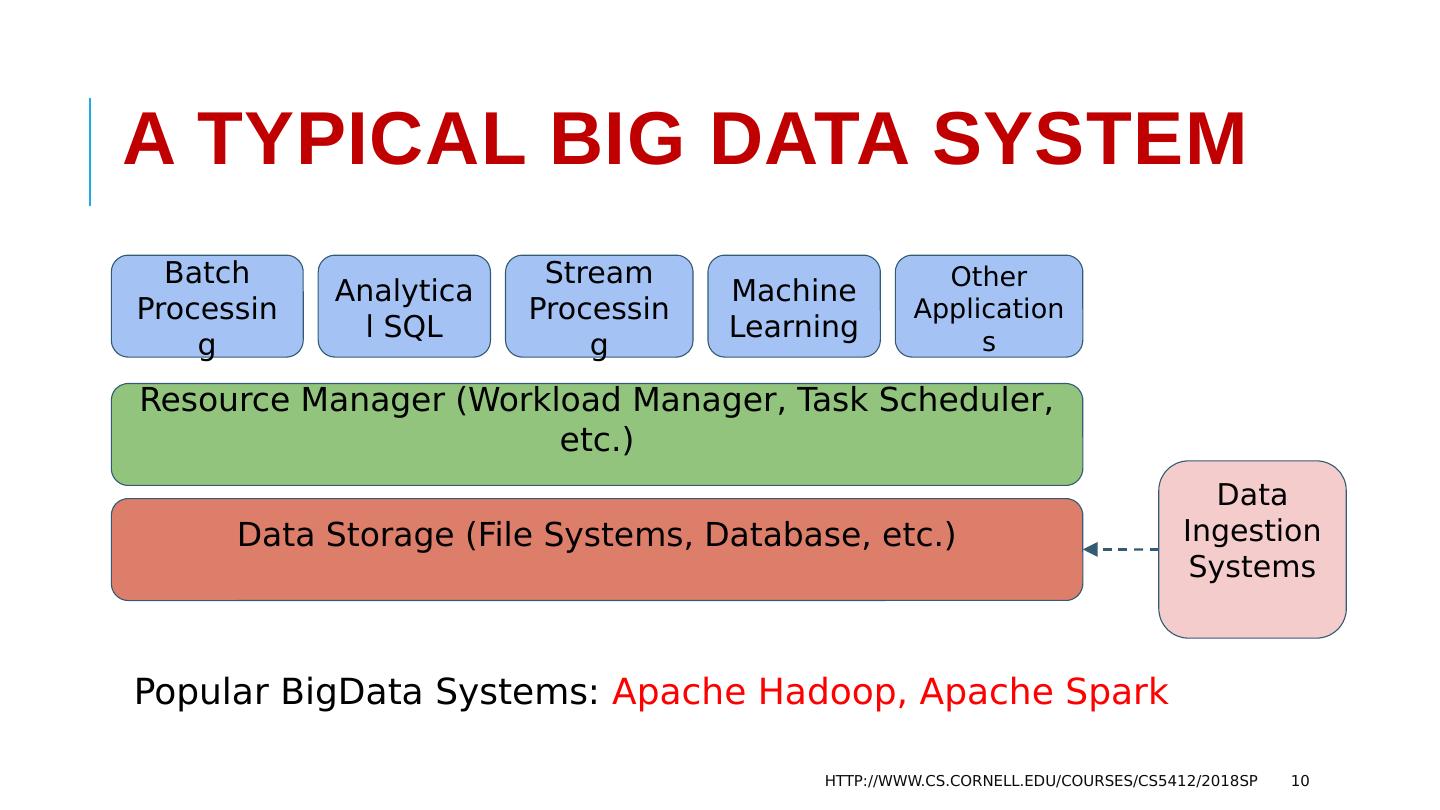
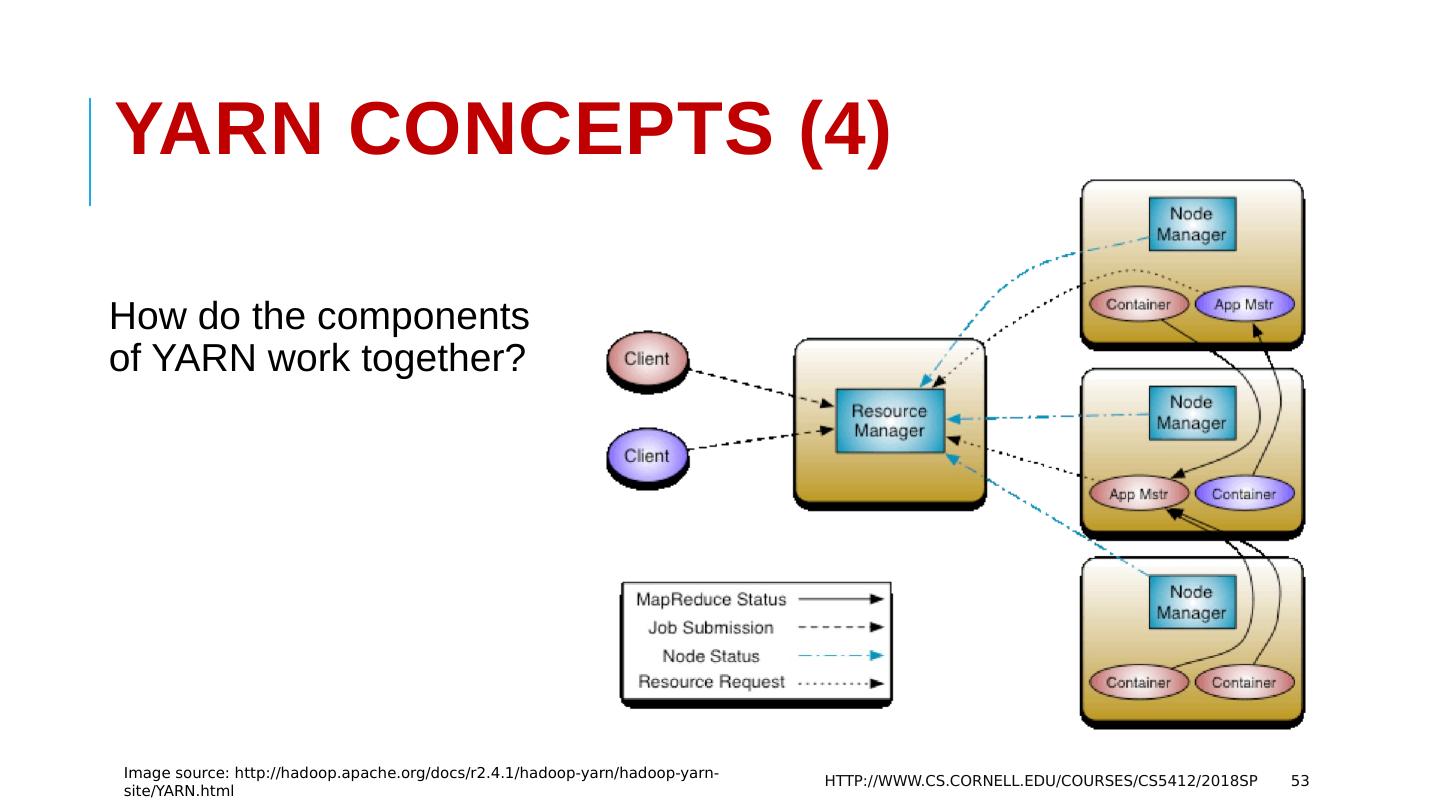
10 .A Typical Big Data System HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 10 Data Storage (File Systems, Database, etc.) Resource Manager (Workload Manager, Task Scheduler, etc.) Batch Processing Analytical SQL Stream Processing Machine Learning Other Applications Data Ingestion Systems Popular BigData Systems: Apache Hadoop, Apache Spark
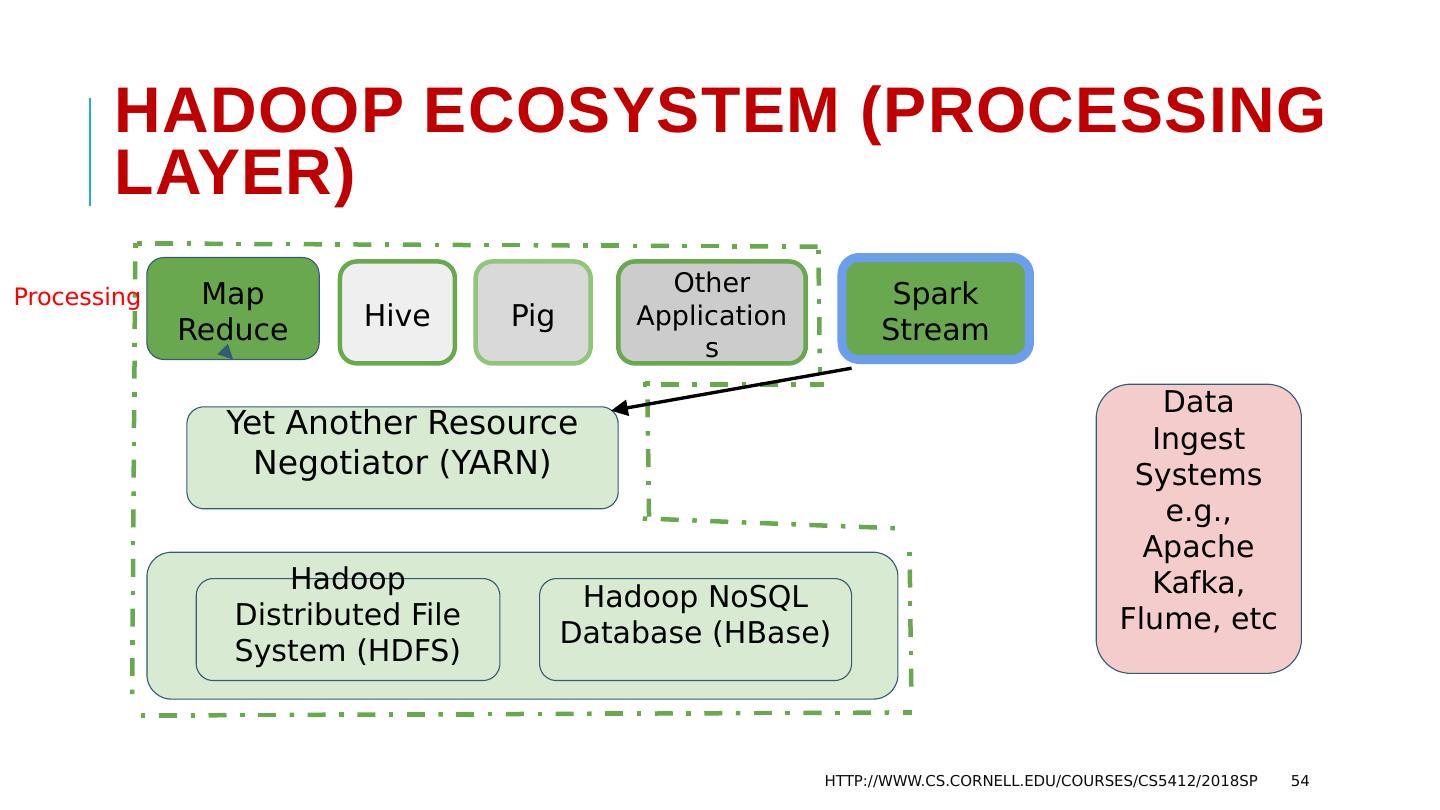
11 .Apache Hadoop Ecosystem 11 Yet Another Resource Negotiator (YARN) Map Reduce Hive Spark Stream Other Applications Data Ingest Systems e.g., Apache Kafka, Flume, etc Hadoop NoSQL Database (HBase) Hadoop Distributed File System (HDFS) Pig Cluster
12 .Hadoop Ecosystem 12 HDFS, HBase Yet Another Resource Negotiator MapReduce , Hive Kafka
13 .Hadoop Distributed File System (HDFS) HDFS is the storage layer for Hadoop BigData System HDFS is based on the Google File System (GFS) Fault-tolerant distributed file system Designed to turn a computing cluster (a large collection of loosely connected compute nodes) into a massively scalable pool of storage Provides redundant storage for massive amounts of data -- scales up to 100PB and beyond 13
14 .HDFS is for Batch Processing Designed for batch processing rather than interactive High throughput of data access rather than low latency 14
15 .HDFS Must never lose any data (Resilience) Sits on top of native file systems (e.g., xfs, ext3, ext4) -- HDFS is written in Java, i.e., JVM → OS (file system) → Storage (disks) Write-once read-many (or append-only) paradigm Batch Processing High Troughput 15 Data is distributed when stored & move computation to the data Minimizes network congestion and increases throughput
16 .HDFS: Key Features Scalable: HDFS is designed for massive scalability, so you can store unlimited amounts of data in a single platform Flexible: Store data of any type -- structured, semi-structured, unstructured -- without any upfront modeling. Reliable: Multiple copies of your data are always available for access and protection from data loss (build-in fault tolerance) 16
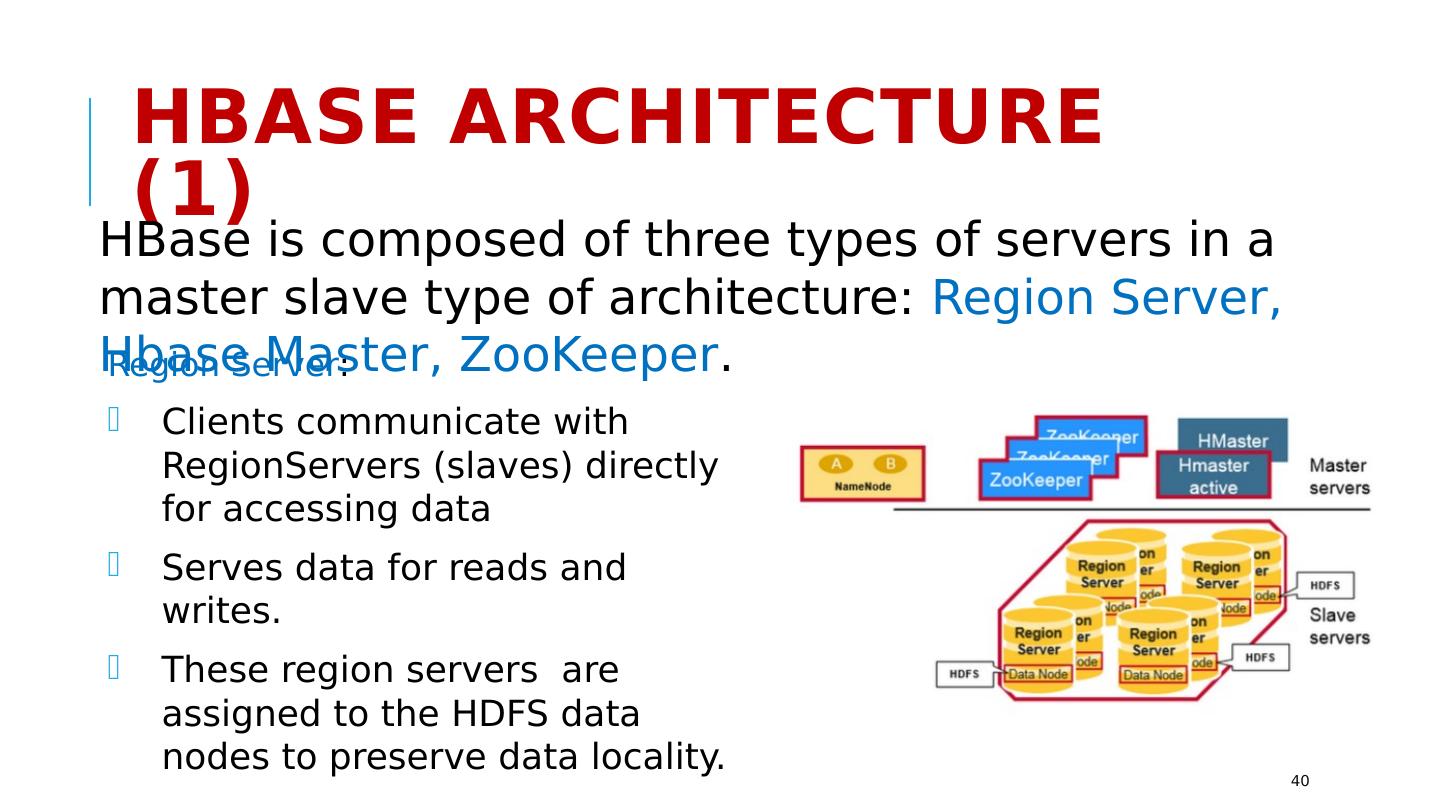
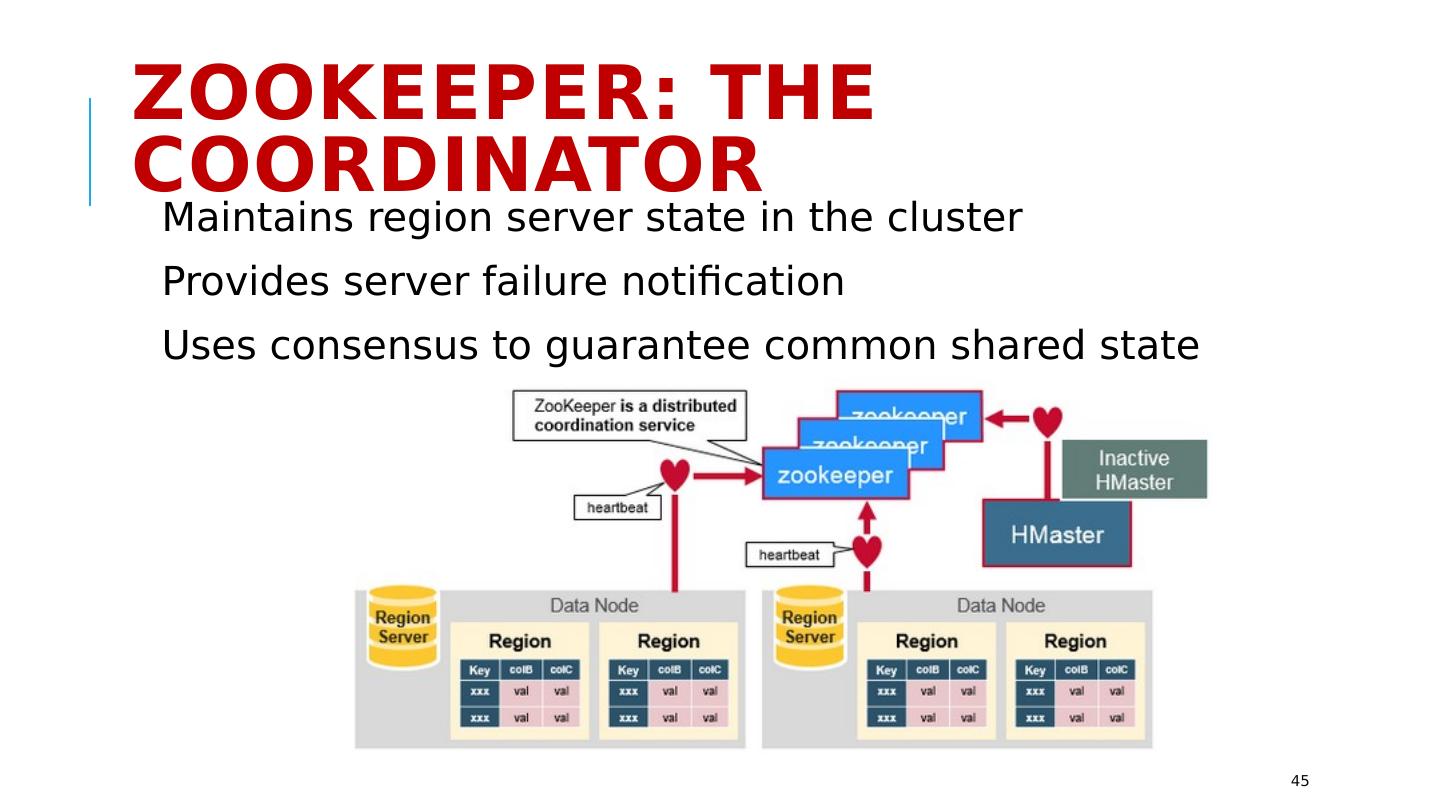
17 .HDFS: Architecture Master/slave architecture: NameNode (the master process -- one per cluster) Availability of Name Node is critical -- single point of failure? The NameNode executes file system namespace operations such as opening, closing etc. The DataNodes (slaves) are responsible for serving read and write requests from the file system’s clients 17 Image source: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
18 .HDFS: Architecture Master/slave architecture: NameNode (the master process -- one per cluster) Availability of Name Node is critical -- single point of failure? The NameNode executes file system namespace operations such as opening, closing etc. The DataNodes (slaves) are responsible for serving read and write requests from the file system’s clients 17 Image source: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
19 .HDFS: Data Replication 19 How to choose number of replicas (replication factor)?
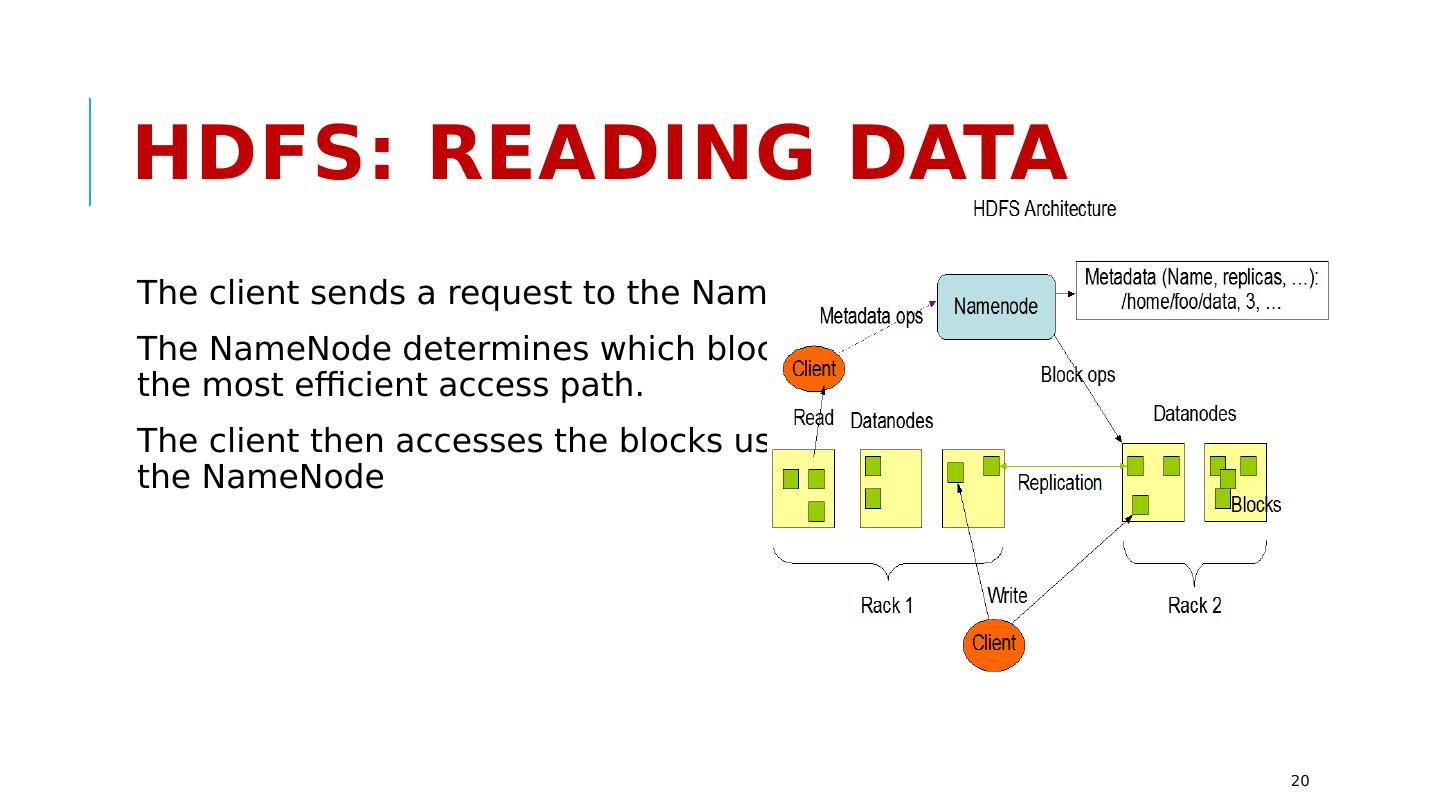
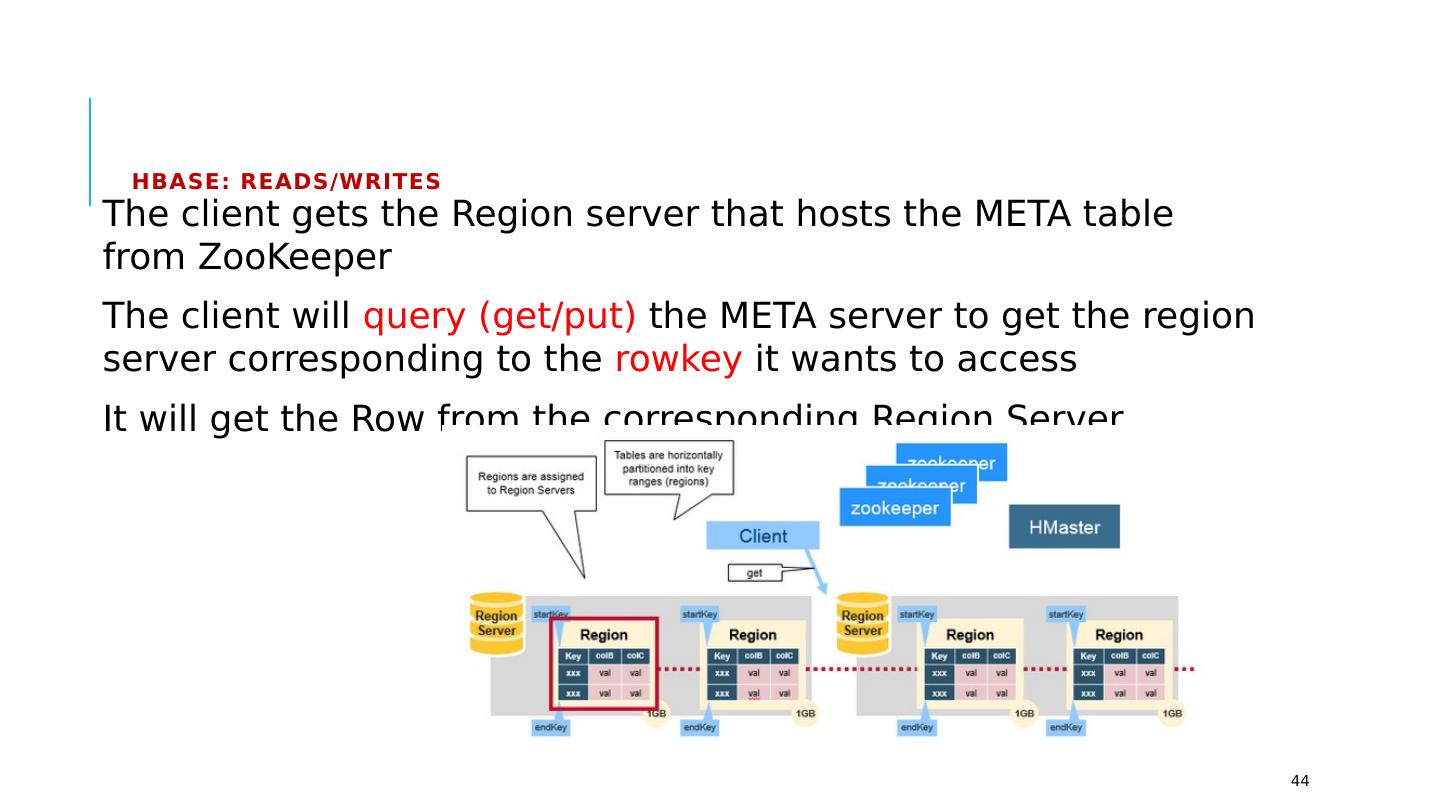
20 .HDFS: Reading Data The client sends a request to the NameNode for a file. The NameNode determines which blocks are involved and chooses the most efficient access path. The client then accesses the blocks using the addresses given by the NameNode 20
21 .HDFS: Writing Data (1) Get a Lease → Write Data → Close the Lease Getting Lease: The client sends a request to the NameNode to create a new file. The NameNode determines how many blocks are needed, and the client is granted a lease for creating these new file blocks in the cluster. 21
22 .HDFS: Writing Data (2) Get a Lease → Write Data → Close the Lease Write Data: The client then writes the first copies of the file blocks to the slave nodes using the lease assigned by the NameNode. As each block is written to HDFS, a special background task duplicates the updates to the other slave nodes identified by the NameNode. 22
23 .HDFS: Writing Data (3) Get a Lease → Write Data → Close the Lease Close Lease: The DataNode daemons acknowledge the file block replicas have been created, The client application closes the file and notifies the NameNode NameNode closes the open lease. Updates become visible at this point. 23
24 .HDFS: Some Limitations Not appropriate for real-time, low-latency processing -- have to close the file immediately after writing to make data visible, hence a real time task would be forced to create too many files Centralized metadata storage -- multiple single points of failures 24 The Persistence of File System Metadata?
25 .Hadoop Database (HBase) A NoSQL database built on HDFS A table can have thousands of columns Supports very large amounts of data and high throughput HBase Strong Consistency Random access, low latency 25
26 .HBase HBase is based on Google’s Bigtable A NoSQL distributed database/map built on top of HDFS Designed for Distribution, Scale, and Speed Relational Database (RDBMS) vs NoSQL Database: RDBMS → vertical scaling (expensive) → not appropriate for BigData NoSQL → horizontal scaling / sharding (cheap) appropriate for BigData 26
27 .RDBMS vs NoSQL (1) 27 BASE not ACID: RDBMS (ACID): Atomicity, Consistency, Isolation, Durability NoSQL (BASE): B asically A vailable S oft state E ventually consistency The idea is that by giving up ACID constraints, one can achieve much higher availability, performance, and scalability e.g. most of the systems call themselves “eventually consistent”, meaning that updates are eventually propagated to all nodes
28 .RDBMS vs NoSQL (2) 28 NoSQL (e.g., CouchDB, HBase) is a good choice for 100 Millions/Billions of rows RDBMS (e.g., mysql ) is a good choice for a few thousand/millions of rows NoSQL eventual consistency (e.g., CouchDB) or strong consistency (HBase)
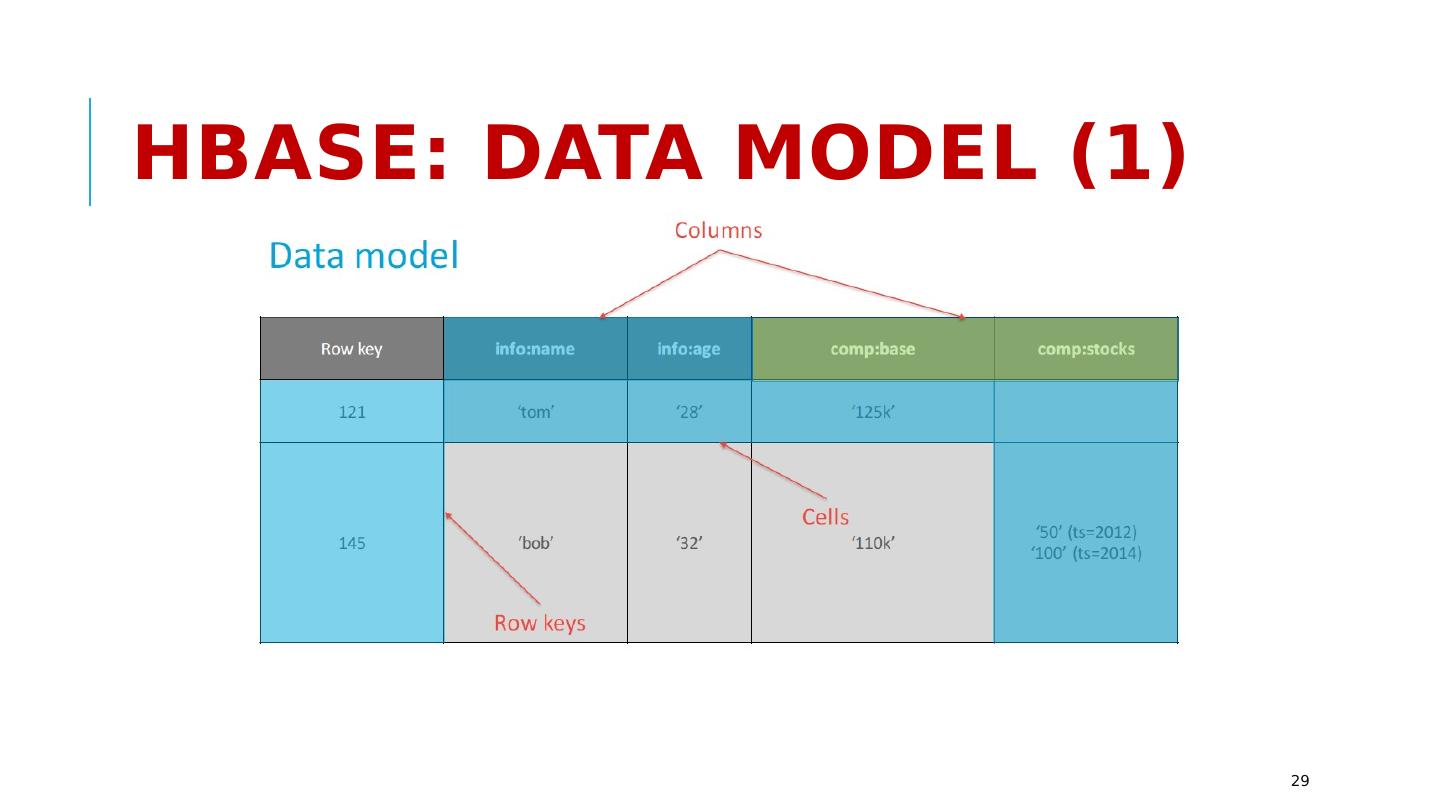
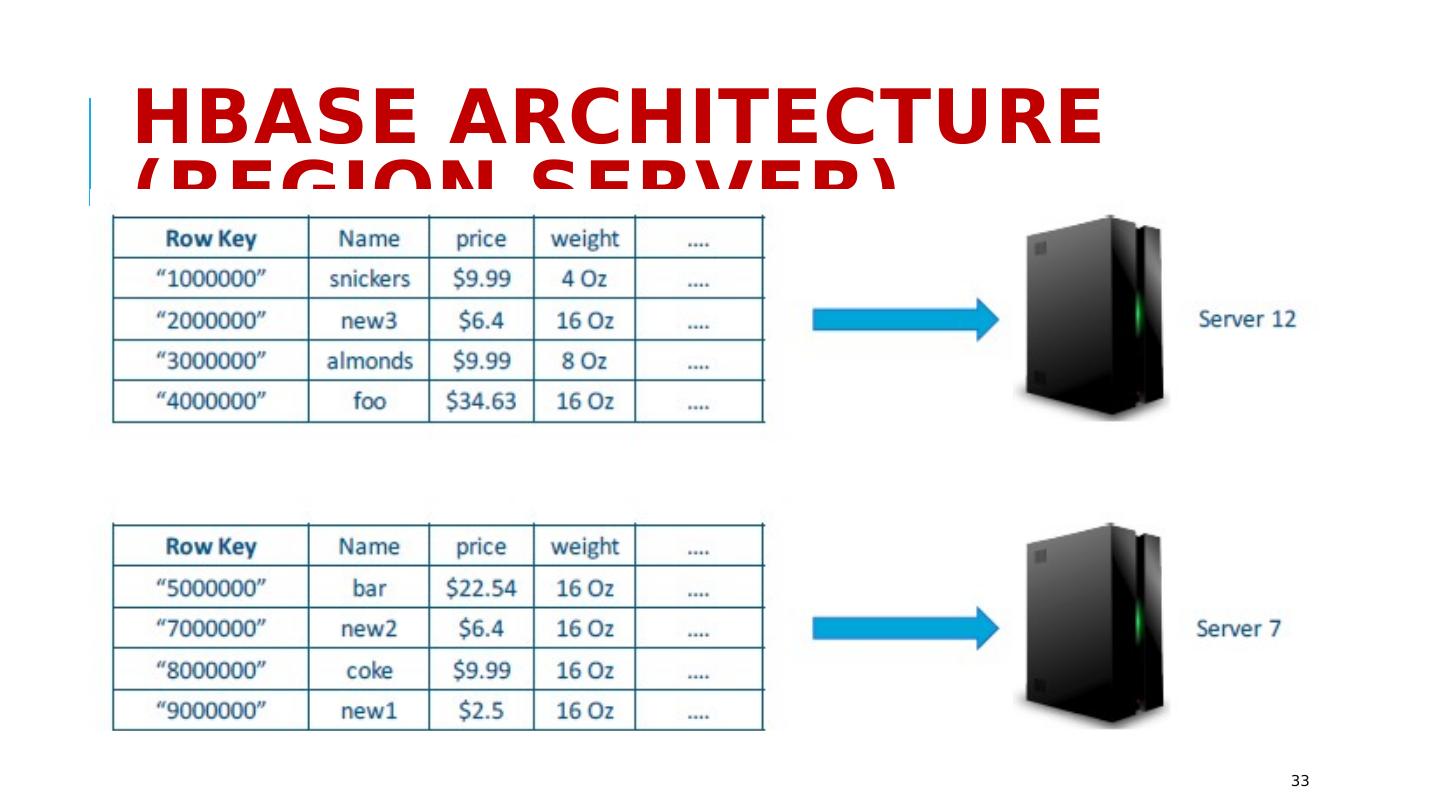
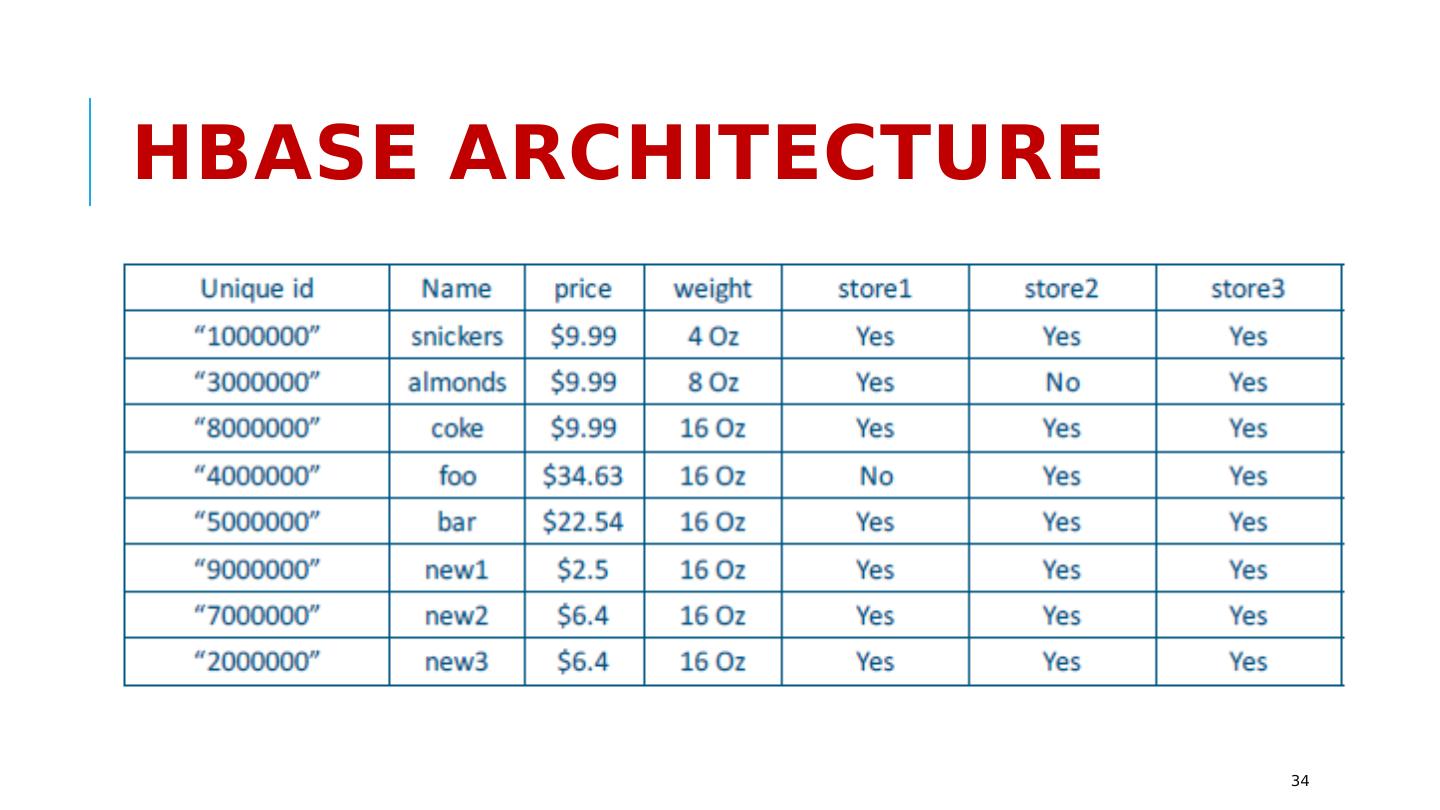
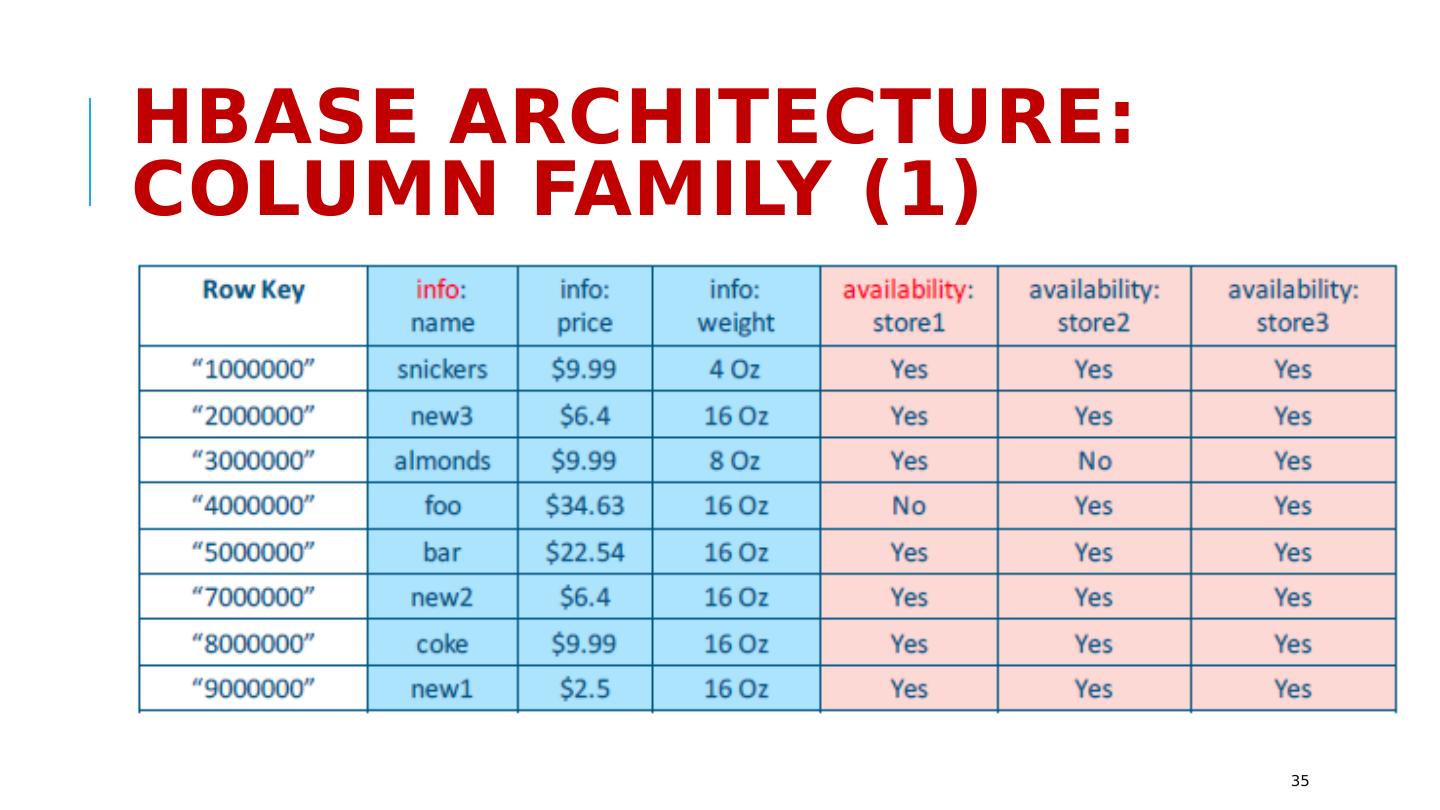
29 .HBase: Data Model (1) 29
3秒后跳转登录页面
去登陆

