













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Crowddb: Answering Queries with Crowdsourcing
CrowdDB uses human input via crowdsourcing to process queries that neither database systems nor search engines can adequately answer. It uses SQL both as a language for posing complex queries and as a way to model data. While CrowdDB leverages many aspects of traditional database systems, there are also important differences. Conceptually, a major change is that the traditional closed-world assumption for query processing does not hold for human input. From an implementation perspective,human-oriented query operators are needed to solicit, integrate and cleanse crowdsourced data. Furthermore, performance and cost depend on a number of new factors including worker affinity, training, fatigue, motivation and location
展开查看详情
1 . CrowdDB: Answering Queries with Crowdsourcing Michael J. Franklin Donald Kossmann Tim Kraska AMPLab, UC Berkeley Systems Group, ETH Zurich AMPLab, UC Berkeley franklin@cs.berkeley.edu donaldk@inf.ethz.ch kraska@cs.berkeley.edu Sukriti Ramesh Reynold Xin Systems Group, ETH Zurich AMPLab, UC Berkeley ramess@student.ethz.ch rxin@cs.berkeley.edu ABSTRACT assumptions about the correctness, completeness and unambiguity Some queries cannot be answered by machines only. Processing of the data they store. When these assumptions fail to hold, rela- such queries requires human input for providing information that is tional systems will return incorrect or incomplete answers to user missing from the database, for performing computationally difficult questions, if they return any answers at all. functions, and for matching, ranking, or aggregating results based on fuzzy criteria. CrowdDB uses human input via crowdsourcing 1.1 Power to the People to process queries that neither database systems nor search engines One obvious situation where existing systems produce wrong an- can adequately answer. It uses SQL both as a language for pos- swers is when they are missing information required for answering ing complex queries and as a way to model data. While CrowdDB the question. For example, the query: leverages many aspects of traditional database systems, there are SELECT market_capitalization FROM company also important differences. Conceptually, a major change is that WHERE name = "I.B.M."; the traditional closed-world assumption for query processing does not hold for human input. From an implementation perspective, will return an empty answer if the company table instance in the human-oriented query operators are needed to solicit, integrate and database at that time does not contain a record for “I.B.M.”. Of cleanse crowdsourced data. Furthermore, performance and cost de- course, in reality, there are many reasons why such a record may be pend on a number of new factors including worker affinity, train- missing. For example, a data entry mistake may have omitted the ing, fatigue, motivation and location. We describe the design of I.B.M. record or the record may have been inadvertently deleted. CrowdDB, report on an initial set of experiments using Amazon Another possibility is that the record was entered incorrectly, say, Mechanical Turk, and outline important avenues for future work in as “I.B.N.” the development of crowdsourced query processing systems. Traditional systems can erroneously return an empty result even when no errors are made. For example, if the record was entered Categories and Subject Descriptors correctly, but the name used was “International Business Machines” rather than “I.B.M.” This latter “entity resolution” problem is not H.2.4 [Database Management]: Systems due to an error but is simply an artifact of having multiple ways to refer to the same real-world entity. General Terms There are two fundamental problems at work here. First, rela- Human Factors, Languages, Design, Performance tional database systems are based on the “Closed World Assump- tion”: information that is not in the database is considered to be false or non-existent. Second, relational databases are extremely 1. INTRODUCTION literal. They expect that data has been properly cleaned and val- Relational database systems have achieved widespread adoption, idated before entry and do not natively tolerate inconsistencies in not only in the business environments for which they were origi- data or queries. nally envisioned, but also for many other types of structured data, As another example, consider a query to find the best among a such as personal, social, and even scientific information. Still, as collection of images to use in a motivational slide show: data creation and use become increasingly democratized through web, mobile and other technologies, the limitations of the tech- SELECT image FROM picture nology are becoming more apparent. RDBMSs make several key WHERE topic = "Business Success" ORDER BY relevance LIMIT 1; In this case, unless the relevance of pictures to specific topics has Permission to make digital or hard copies of all or part of this work for been previously obtained and stored, there is simply no good way personal or classroom use is granted without fee provided that copies are to ask this question of a standard RDBMS. The issue here is one not made or distributed for profit or commercial advantage and that copies of judgement: one cannot reliably answer the question simply by bear this notice and the full citation on the first page. To copy otherwise, to applying relational operators on the database. republish, to post on servers or to redistribute to lists, requires prior specific All of the above queries, however, while unanswerable by to- permission and/or a fee. SIGMOD’11, June 12–16, 2011, Athens, Greece. day’s relational database systems, could easily be answered by peo- Copyright 2011 ACM 978-1-4503-0661-4/11/06 ...$10.00. ple, especially people who have access to the Internet.
2 .1.2 CrowdDB SQL queries can be run on CrowdDB, and in many cases will re- Recently, there has been substantial interest (e.g. [4, 6, 28]) turn more complete and correct answers than if run on a traditional in harnessing Human Computation for solving problems that are DBMS. Third, as we discuss in subsequent sections, user interface impossible or too expensive to answer correctly using computers. design is a key factor in enabling questions to be answered by peo- Microtask crowdsourcing platforms such as Amazon’s Mechanical ple. Our approach leverages schema information to support the Turk (AMT)[3] provide the infrastructure, connectivity and pay- automatic generation of effective user interfaces for crowdsourced ment mechanisms that enable hundreds of thousands of people to tasks. Finally, because of its declarative programming environment perform paid work on the Internet. AMT is used for many tasks that and operator-based approach, CrowdDB presents the opportunity are easier for people than computers, from simple tasks such as la- to implement cost-based optimizations to improve query cost, time, beling or segmenting images and tagging content to more complex and accuracy — a facility that is lacking from most crowdsourcing tasks such as translating or even editing text. platforms today. It is natural, therefore, to explore how to leverage such human Of course, there are many new challenges that must be addressed resources to extend the capabilities of database systems so that in the design of a crowd-enabled DBMS. The main ones stem from they can answer queries such as those posed above. The approach the fundamental differences in the way that people work compared we take in CrowdDB is to exploit the extensibility of the iterator- to computers and from the inherent ambiguity in many of the hu- based query processing paradigm to add crowd functionality into a man tasks, which often involve natural language understanding and DBMS. CrowdDB extends a traditonal query engine with a small matters of opinion. There are also technical challenges that arise number of operators that solicit human input by generating and sub- due to the use of a specific crowdsourcing platform such as AMT. miting work requests to a microtask crowdsourcing platform. Such challenges include determining the most efficient organiza- As query processing elements, people and computers differ in tion of tasks submitted to the platform, quality control, incentives, fundamental ways. Obviously, the types of tasks at which each ex- payment mechanisms, etc. cel are quite different. Also, people exhibit wider variability, due In the following we explain these challenges and present initial to schedules such as nights, weekends and holidays, and the vast solutions that address them. Our main contributions are: differences in expertise, diligence and temperament among people. Finally, as we discuss in the following sections, in a crowdsourcing • We propose simple SQL schema and query extensions that system, the relationship between job requesters and workers ex- enable the integration of crowdsourced data and processing. tends beyond any one interaction and evolves over time. Care must • We present the design of CrowdDB including new crowd- be taken to properly maintain that relationship. sourced query operators and plan generation techniques that Crowdsourced operators must take into consideration the talents combine crowdsourced and traditional query operators. and limitations of human workers. For example, while it has been shown that crowds can be “programmed” to execute classical algo- • We describe methods for automatically generating effective rithms such as Quicksort on well-defined criteria [19], such a use user interfaces for crowdsourced tasks. of the crowd is neither performant nor cost-efficient. Consider the example queries described in Section 1.1. Correctly • We present the results of microbenchmarks of the perfor- answering these queries depends on two main capabilities of human mance of individual crowdsourced query operators on the computation compared to traditional query processing: AMT platform, and demonstrate that CrowdDB is indeed Finding new data - recall that a key limitation of relational tech- able to answer queries that traditional DBMSs cannot. nology stems from the Closed World Assumption. People, on the other hand, aided by tools such as search engines and reference The remainder of this paper is organized as follows: Section sources, are quite capable of finding information that they do not 2 presents background on crowdsourcing and the AMT platform. have readily at hand. Section 3 gives an overview of CrowdDB, followed by the Crowd- Comparing data - people are skilled at making comparisons that SQL extension to SQL in Section 4, the user interface generation are difficult or impossible to encode in a computer algorithm. For in Section 5, and query processing in Section 6. In Section 7 we example, it is easy for a person to tell, if given the right context, present experimental results. Section 8 reviews related work. Sec- if “I.B.M.” and “International Business Machines” are names for tion 9 presents conclusions and research challenges. the same entity. Likewise, people can easily compare items such as images along many dimensions, such as how well the image 2. CROWDSOURCING represents a particular concept. A crowdsourcing platform creates a marketplace on which re- Thus, for CrowdDB, we develop crowd-based implementations questers offer tasks and workers accept and work on the tasks. We of query operators for finding and comparing data, while relying chose to build CrowdDB using one of the leading platforms, Ama- on the traditional relational query operators to do the heavy lifting zon Mechanical Turk (AMT). AMT provides an API for requesting for bulk data manipulation and processing. We also introduce some and managing work, which enables us to directly connect it to the minimal extensions to the SQL data definition and query languages CrowdDB query processor. In this discussion, we focus on this to enable the generation of queries that involve human computation. particular platform and its interfaces. AMT supports so-called microtasks. Microtasks usually do not 1.3 Paper Overview require any special training and typically take no longer than one Our approach has four main benefits. First, by using SQL we minute to complete; although in extreme cases, tasks can require create a declarative interface to the crowd. We strive to maintain up to one hour to finish [15]. In AMT, as part of specifying a task, SQL semantics so that developers are presented with a known com- a requester defines a price/reward (minimum $0.01) that the worker putational model. Second, CrowdDB provides Physical Data Inde- receives if the task is completed satisfactorily. In AMT currently, pendence for the crowd. That is, application developers can write workers from anywhere in the world can participate but requesters SQL queries without having to focus on which operations will be must be holders of a US credit card. Amazon does not publish cur- done in the database and which will be done by the crowd. Existing rent statistics about the marketplace, but it contained over 200,000
3 .workers (referred to as turkers) in 2006 [2], and by all estimates, • createHIT(title, description, question, keywords, reward, dura- the marketplace has grown dramatically since then [24]. tion, maxAssignments, lifetime) → HitID: Calling this method creates a new HIT on the AMT marketplace. The createHIT 2.1 Mechanical Turk Basics method returns a HitID to the requester that is used to identify AMT has established its own terminology. There are slight dif- the HIT for all further communication. The title, description, ferences in terminology used by requesters and workers. For clarity and reward and other fields are used by AMT to combine HITs in this paper, we use the requesters’ terminology. Key terms are: into HIT Groups. The question parameter encapsulates the user interface that workers use to process the HIT, including HTML • HIT: A Human Intelligent Task, or HIT, is the smallest entity pages. The duration parameter indicates how long the worker of work a worker can accept to do. HITs contain one or more has to complete an assignment after accepting it. The lifetime jobs. For example, tagging 5 pictures could be one HIT. Note attribute indicates an amount of time after which the HIT will that “job” is not an official term used in AMT, but we use it in no longer be available for workers to accept. Requesters can this paper where necessary. also constrain the set of workers that are allowed to process the • Assignment: Every HIT can be replicated into multiple assign- HIT. CrowdDB, however, does not currently use this capability ments. AMT ensures that any particular worker processes at so the details of this and several other parameters are omitted for most a single assignment for each HIT, enabling the requester brevity. to obtain answers to the same HIT from multiple workers. Odd • getAssignmentsForHIT(HitID) → list(asnId, workerId , answer): numbers of assignments per HIT enable majority voting for qual- This method returns the results of all assignments of a HIT that ity assurance, so it is typical to have 3 or 5 assignments per HIT. have been provided by workers (at most, maxAssignments an- Requesters pay workers for each assignment completed satisfac- swers as specified when the requester created the HIT). Each torily. answer of an assignment is given an asnID which is used by the requester to approve or reject that assignment (described next). • HIT Group: AMT automatically groups similar HITs together into HIT Groups based on the requester, the title of the HIT, the • approveAssignment(asnID) / rejectAssignment(asnID): Approval description, and the reward. For example, a HIT Group could triggers the payment of the reward to the worker and the com- contain 50 HITs, each HIT asking the worker to classify several mission to Amazon. pictures. As we discuss below, workers typically choose which • forceExpireHIT(HitID): Expires a HIT immediately. Assign- work to perform based on HIT Groups. ments that have already been accepted may be completed. The basic AMT workflow is as follows: A requester packages the 2.3 CrowdDB Design Considerations jobs comprising his or her information needs into HITs, determines The crowd can be seen as a set of specialized processors. Hu- the number of assignments required for each HIT and posts the mans are good at certain tasks (e.g., image recognition) and rela- HITs. Requesters can optionally specify requirements that work- tively bad at others (e.g., number crunching). Likewise, machines ers must meet in order to be able to accept the HIT. AMT Groups are good and bad at certain tasks and it seems that people’s and compatible HITs into HIT Groups and posts them so that they are machines’ capabilities complement each other nicely. It is this syn- searchable by workers. A worker accepts and processes assign- ergy that provides the opportunity to build a hybrid system such ments. Requesters then collect all the completed assignments for as CrowdDB. However, while the metaphor of humans as comput- their HITs and apply whatever quality control methods they deem ing resources is powerful, it is important to understand when this necessary. metaphor works, and when it breaks down. In this section we high- Furthermore, requesters approve or reject each assignment com- light some key issues that have influenced the design of CrowdDB. pleted by a worker: Approval is given at the discretion of the re- Performance and Variability: Obviously, people and machines quester. Assignments are automatically deemed approved if not differ greatly in the speed at which they work, the cost of that work, rejected within a time specified in the HIT configuration. For each and the quality of the work they produce. More fundamentally, approved assignment the requester pays the worker the pre-defined people show tremendous variability both from one individual to reward, an optional bonus, and a commission to Amazon. another and over time for a particular individual. Malicious behav- Workers access AMT through their web browsers and deal with ior and “spamming” are also concerns. For CrowdDB these dif- two kinds of user interfaces. One is the main AMT interface, which ferences have implications for query planning, fault tolerance and enables workers to search for HIT Groups, list the HITs in a HIT answer quality. Group, and to accept assignments. The second interface is provided Task Design and Ambiguity: Crowd-sourced tasks often have by the requester of the HIT and is used by the worker to actually inherent ambiguities due to natural language and subjective require- complete the HIT’s assignments. A good user interface can greatly ments. The crowd requires a graphical user interface with human- improve result quality and worker productivity. readable instructions. Unlike programming language commands, In AMT, requesters and workers have visible IDs so relationships such instructions can often be interpreted in different ways. Also, and reputations can be established over time. For example, workers the layout and design of the interface can have a direct effect on will often lean towards accepting assignments from requesters who the speed and accuracy with which people complete the tasks. The are known to provide clearly-defined jobs with good user interfaces challenges here are that tasks must be carefully designed with the and who are known for having good payment practices. Informa- workers in mind and that quality-control mechanisms must be de- tion about requesters and HIT Groups are shared among workers veloped, even in cases where it is not possible to determine the via on-line forums. absolute correctness of an answer. Affinity and Learning: Unlike CPUs, which are largely fungi- 2.2 Mechanical Turk APIs ble, crowd workers develop relationships with requesters and skills A requester can automate his or her workflow of publishing HITs, for certain HIT types. They learn over time how to optimize their etc. by using AMT’s web service or REST APIs. The relevant (to revenue. Workers are hesitant to take on tasks for requesters who CrowdDB) interfaces are: do not have a track record of providing well-defined tasks and pay-
4 .ing appropriately and it is not uncommon for workers to specialize must be taken to cultivate and maintain an effective worker pool. on specific HIT types (e.g., classifying pictures) or to favor HITs This module facilitates the most important duties of a requester, from certain requesters [16]. This behavior requires the CrowdDB such as approving/rejecting assignments, paying and granting bonuses, design to take a longer-term view on task and worker community etc. This way, CrowdDB helps to build communities for requesters development. which in the long run pays back in improved result quality, better Relatively Small Worker Pool: Despite the large and growing response times, and lower cost. number of crowdsourcing workers, our experience, and that of oth- User Interface Management: HITs require user interfaces and ers [18] is that the pool of workers available to work for any one human-readable instructions. CrowdSQL extends SQL’s data defi- requester is surprisingly small. This stems from a number of fac- nition language to enable application developers to annotate tables tors, some having to do with the specific design of the AMT web with information that helps in user interface creation. At runtime, site, and others having to do with the affinity and learning issues CrowdDB then automatically generates user interfaces for HITs discussed previously. For CrowdDB, this impacts design issues based on these annotations as well as the standard type definitions around parallelism and throughput. and constraints that appear in the schema. Programmers can also Open vs. Closed World: Finally, as mentioned in the Intro- create specific UI forms to override the standard UI generation in duction, a key difference between traditional data processing and complex or exceptional cases. crowd processing is that in the latter, there is an effectively un- The user interfaces generated for HITs are constrained where bounded amount of data available. Any one query operator could possible so that workers return only a pre-specified number of an- conceivably return an unlimited number of answers. This has pro- swers, and are designed to reduce errors by favoring simple tasks found implications for query planning, query execution costs and and limiting choices (i.e., adding dropdown lists or check boxes). answer quality. HIT Manager: This component manages the interactions be- Having summarized the crowdsourcing platform, we now turn to tween CrowdDB and the crowdsourcing platform (AMT in this the design and implementation of CrowdDB. case). It makes the API calls to post HITs, assess their status, and obtain the results of assignments. The HITs to be posted are deter- 3. OVERVIEW OF CrowdDB mined by the query compiler and optimizer. The HIT manager also Figure 1 shows the general architecture of CrowdDB. An appli- interacts with the storage engine in order to obtain values to pre- cation issues requests using CrowdSQL, a moderate extension of load into the HIT user interfaces and to store the results obtained standard SQL. Application programmers can build their applica- from the crowd into the database. tions in the traditional way; the complexities of dealing with the The following sections explain the most important building blocks crowd are encapsulated by CrowdDB. CrowdDB answers queries of CrowdDB in more detail: CrowdSQL, user interface generation, using data stored in local tables when possible, and invokes the and query processing. crowd otherwise. Results obtained from the crowd can be stored in the database for future use. 4. CrowdSQL CrowdSQL Results This section presents CrowdSQL, a SQL extension that supports crowdsourcing. We designed CrowdSQL to be a minimal extension to SQL to support use cases that involve missing data and subjec- Parser Turker Relationship tive comparisons. This approach allows application programmers MetaData Manager to write (Crowd) SQL code in the same way as they do for tra- ditional databases. In most cases, developers are not aware that UI Form Optimizer their code involves crowdsourcing. While this design results in a Creation Editor powerful language (CrowdSQL is a superset of SQL) with sound semantics, there are a number of practical considerations that such Executor UI Template Manager Statistics a powerful language entails. We discuss these issues and other ex- tensions at the end of this section. Files Access Methods HIT Manager 4.1 Incomplete Data 4.1.1 SQL DDL Extensions Disk 1 Incomplete data can occur in two flavors: First, specific attributes of tuples could be crowdsourced. Second, entire tuples could be crowdsourced. We capture both cases by adding a special key- Disk 2 word, CROWD, to the SQL DDL, as shown in the following two examples. Figure 1: CrowdDB Architecture E XAMPLE 1 (Crowdsourced Column) In the following Department table, the url is marked as crowdsourced. Such a model would be As shown on the left side of the figure, CrowdDB incorporates appropriate, say, if new departments are generated automatically the traditional query compilation, optimization and execution com- (e.g., as part of an application program) and the url is often not ponents. These components are extended to cope with human- provided but is likely available elsewhere. generated input as described in subsequent sections. On the right side of the figure are new components that interact with the crowd- CREATE TABLE Department ( sourcing platform. We briefly describe these from the top down. university STRING, Turker Relationship Management: As described in Section name STRING, 2.3, the requester/worker relationship evolves over time and care url CROWD STRING,
5 . phone STRING, on a CROWD table, then all non-key attributes would be initial- PRIMARY KEY (university, name) ); ized to CNULL, if not specified otherwise as part of the INSERT statement. However, the key of a CROWD table must be specified E XAMPLE 2 (Crowdsourced Table) This example models a Pro- for the INSERT statement as the key is never allowed to contain fessor table as a crowdsourced table. Such a crowdsourced table CNULL. This rule is equivalent to the rule that keys must not be is appropriate if it is expected that the database typically only cap- NULL enforced by most standard SQL database systems. However, tures a subset of the professors of a department. In other words, new tuples of CROWD tables are typically crowdsourced entirely, CrowdDB will expect that additional professors may exist and pos- as described in the next subsection. sibly crowdsource more professors if required for processing spe- In summary, CrowdSQL allows any kind of INSERT, UPDATE, cific queries. and DELETE statements; all these statements can be applied to CROWD columns and tables. Furthermore, CrowdSQL supports CREATE CROWD TABLE Professor ( all standard SQL types (including NULL values). A special CNULL name STRING PRIMARY KEY, value indicates data in CROWD columns that should be crowd- email STRING UNIQUE, sourced when needed as part of processing a query. university STRING, department STRING, 4.1.3 Query Semantics FOREIGN KEY (university, department) CrowdDB supports any kind of SQL query on CROWD tables REF Department(university, name) ); and columns; for instance, joins and sub-selects between two CROWD tables are allowed. Furthermore, the results of these queries are as CrowdDB allows any column and any table to be marked with expected according to the (standard) SQL semantics. the CROWD keyword. CrowdDB does not impose any limitations What makes CrowdSQL special is that it incorporates crowd- with regard to SQL types and integrity constraints; for instance, ref- sourced data as part of processing SQL queries. Specifically, CrowdDB erential integrity constraints can be defined between two CROWD asks the crowd to instantiate CNULL values if they are required to tables, two regular tables, and between a regular and a CROWD ta- evaluate predicates of a query or if they are part of a query result. ble in any direction. There is one exception: CROWD tables (e.g., Furthermore, CrowdDB asks the crowd for new tuples of CROWD Professor) must have a primary key so that CrowdDB can infer if tables if such tuples are required to produce a query result. Crowd- two workers input the same new tuple (Section 4.3). Furthermore, sourcing as a side-effect of query processing is best explained with CROWD columns and tables can be used in any SQL query and the help of examples: SQL DML statement, as shown in the following subsections. SELECT url FROM Department 4.1.2 SQL DML Semantics WHERE name = "Math"; In order to represent values in crowdsourced columns that have not yet been obtained, CrowdDB introduces a new value to each This query asks for the url of the Math department. If the url is SQL type, referred to as CNULL. CNULL is the CROWD equiva- CNULL, then the semantics of CrowdSQL require that the value lent of the NULL value in standard SQL. CNULL indicates that a be crowdsourced. The following query asks for all professors with value should be crowdsourced when it is first used. Berkeley email addresses in the Math department: CNULL values are generated as a side-effect of INSERT state- ments. (The semantics of DELETE and UPDATE statements are un- SELECT * FROM Professor changed in CrowdDB.) CNULL is the default value of any CROWD WHERE email LIKE "%berkeley%" AND dept = "Math"; column. For instance, This query involves crowdsourcing the E-Mail address and depart- INSERT INTO Department(university, name) ment of all known professors (if their current value is CNULL) in VALUES ("UC Berkeley", "EECS"); order to evaluate the WHERE clause. Furthermore, processing this query involves asking the crowd for possibly additional Math pro- would create a new tuple. The phone field of the new department fessors that have not been crowdsourced yet. is initialized to NULL, as specified in standard SQL. The url field CrowdSQL specifies that tables are updated as a side-effect of of the new department is initialized to CNULL, according to the crowdsourcing. In the first query example above, for instance, special CrowdSQL semantics for CROWD columns. Both fields the url column would be implicitly updated with the crowdsourced could be set later by an UPDATE statement. However, the url field URL. Likewise, missing values in the email column would be im- could also be crowdsourced as a side-effect of queries, as described plicitly populated and new professors would be implicitly inserted in the next subsection. as a side-effect of processing the second query. Logically, these up- It is also possible to specify the value of a CROWD column as dates and inserts are carried out as part of the same transaction as part of an INSERT statement; in this case, the value would not be the query and they are executed before the query; i.e., their effects crowdsourced (unless it is explicitly set to CNULL as part of an are visible during query processing. UPDATE statement); e.g., INSERT INTO Department(university, name, url) 4.2 Subjective Comparisons VALUES ("ETH Zurich", "CS", "inf.ethz.ch"); Recall that beyond finding missing data, the other main use of crowdsourcing in CrowdDB is subjective comparisons. In order to It is also possible to initialize or set the value of a CROWD column support this functionality, CrowdDB has two new built in functions: to NULL; in such a case, crowdsourcing would not take effect. Fur- CROWDEQUAL and CROWDORDER. thermore, it is possible to explicitly initialize or set (as part of an CROWDEQUAL takes two parameters (an lvalue and an rvalue) UPDATE statement) the value of a CROWD column to CNULL. and asks the crowd to decide whether the two values are equal. As CNULL is also important for CROWD tables, where all columns syntactic sugar, we use the ∼= symbol and an infix notation, as are implicitly crowdsourced. If an INSERT statement is executed shown in the following example:
6 .E XAMPLE 3 To ask for all "CS" departments, the following query semantics. It should be clear, however, that more sophisticated and could be posed. Here, the query writer asks the crowd to do entity explicit mechanisms to specify budgets are needed. resolution with the possibly different names given for Computer A second extension that we plan for the next version of Crowd- Science in the database: SQL is lineage. In CrowdDB, data can be either crowdsourced as a side-effect of query processing or entered using SQL DML state- SELECT profile FROM department ments. In both cases, application developers may wish to query the WHERE name ~= "CS"; lineage in order to take actions. For instance, it may become known that a certain worker is a spammer; in such a situation, it may be CROWDORDER is used whenever the help of the crowd is needed appropriate to reset all crowdsourced values to CNULL that were to rank or order results. Again, this function is best illustrated with derived from input from that worker. Also, it may be important to an example. know when data was entered in order to determine whether the data is outdated (i.e., time-to-live); the age of data may be relevant for E XAMPLE 4 The following CrowdSQL query asks for a ranking of both crowdsourced and machine-generated data. pictures with regard to how well these pictures depict the Golden A third practical issue involves the cleansing of crowdsourced Gate Bridge. data; in particular, entity resolution of crowdsourced data. As men- tioned in Section 4.1, all CROWD tables must have a primary key. CREATE TABLE picture ( The current version of CrowdDB uses the primary key values in p IMAGE, order to detect duplicate entries of CROWD tables. This approach subject STRING works well if it can be assumed that two independent workers will ); enter exactly the same literals. In many cases, this assumption is SELECT p FROM picture not realistic. As part of future work, we plan to extend the DDL WHERE subject = "Golden Gate Bridge" of CrowdSQL so that application developers can specify that data ORDER BY CROWDORDER(p, cleaning should be carried out on crowdsourced data (e.g., entity "Which picture visualizes better %subject"); resolution). Of course, this feature comes at a cost so that devel- opers should have control to use this feature depending on their As with missing data, CrowdDB stores the results of CROWDEQUAL budget. and CROWDORDER calls so that the crowd is only asked once for each comparison. This caching is equivalent to the caching of ex- 5. USER INTERFACE GENERATION pensive functions in traditional SQL databases, e.g., [13]. This Recall that a key to success in crowdsourcing is the provision of cache can also be invalidated; the details of the syntax and API effective user interfaces. In this section we describe how CrowdDB to control this cache are straightforward and omitted for brevity. automatically generates user interfaces for crowdsourcing incom- plete information and subjective comparisons. As shown in Fig- 4.3 CrowdSQL in Practice ure 1, the generation of user interfaces is a two-step process in The current version of CrowdSQL was designed to be a minimal CrowdDB. At compile-time, CrowdDB creates templates to crowd- extension to SQL and address some of the use cases that involve in- source missing information from all CROWD tables and all reg- complete data and subjective comparisons. This version was used ular tables which have CROWD columns. These user interfaces in the first implementation of CrowdDB which was used as a plat- are HTML (and JavaScript) forms that are generated based on the form for the experiments reported in Section 7. While this minimal CROWD annotations in the schema and optional free-text annota- extension is sound and powerful, there are a number of considera- tions of columns and tables that can also be found in the schema tions that limit the usage of CrowdSQL in practice. [21]. Furthermore, these templates can be edited by application de- The first issue is that CrowdSQL changes the closed-world to an velopers to provide additional custom instructions. These templates open-world assumption. Thus cost and response time of queries are instantiated at runtime in order to provide a user interface for a can be unbounded in CrowdSQL. If a query involves a CROWD concrete tuple or a set of tuples. The remainder of this section gives table, then it is unclear how many tuples need to be crowdsourced examples of user interfaces generated for the tables and subjective in order to fully process the query. For queries that involve reg- comparisons described in Section 4. ular tables with CROWD columns or subjective comparisons, the amount of information that needs to be crowdsourced is bounded 5.1 Basic Interfaces by the number of tuples and CNULL values stored in the database; Figure 2a shows an example user interface generated for crowd- nevertheless, the cost can be prohibitive. In order to be practical, sourcing the URL of the “EECS” department of “UC Berkeley” CrowdSQL should provide a way to define a budget for a query. (Example 1). The title of the HTML is the name of the Table (i.e., Depending on the use case, an application developer should be able Department in this example) and the instructions ask the worker to to constrain the cost, the response time, and/or the result quality. input the missing information. In general, user interface templates For instance, in an emergency situation, response time may be crit- are instantiated by copying the known field values from a tuple into ical whereas result quality should be given priority if a strategic de- the HTML form (e.g., “EECS” and “UC Berkeley” in this exam- cision of an organization depends on a query. In the current version ple). Furthermore, all fields of the tuple that have CNULL values of CrowdDB, we provide only one way to specify a budget — using become input fields of the HTML form (i.e., URL in this example). a LIMIT clause [7]. The LIMIT clause constrains the number of In addition to HTML code, CrowdDB generates JavaScript code tuples that are returned as a result of a query. This way, the LIMIT in order to check for the correct types of input provided by the clause implicitly constrains the cost and response time of a query. workers. For instance, if the CrowdSQL involves a CHECK con- A LIMIT clause (or similar syntax) is supported by most relational straint that limits the domain of a crowdsourced attribute (e.g., “EUR”, database systems and this clause has the same semantics in Crowd- “USD”, etc. for currencies), then a select box is generated that al- SQL as in (traditional) SQL. We used this mechanism because it lows the worker to choose among the legal values for that attribute. was available and did not require any extensions to SQL syntax or A possible optimization that is not shown in Figure 2a is to batch
7 . Please fill out the missing Please fill out the professor data Please fill out the missing Please fill out the missing department data Are the following entities the Which picture visualizes better Richard M. Karp professor data department data same? "Golden Gate Bridge" Name University UC Berkeley University Name Richard M. Karp Name EECS Email IBM == Big Blue Name University Email URL URL Phone (510) 642-3214 Department add Yes No Department Phone Submit Submit Submit Submit Submit (a) Crowd Column & (b) CROWDEQUAL (c) CROWDORDER (d) Foreign Key(normalized) (e) Foreign Key (denormalized) Crowd Tables w/o Foreign Keys Figure 2: Example User Interfaces Generated by CrowdDB several tuples. For instance, if the URL of several departments generated in the case where additional information is being crowd- needs to be crowdsourced, then a single worker could be asked to sourced for existing professor tuples. Similar user interfaces can be provide the URL information of a set of department (e.g., EECS, generated to crowdsource entirely new professor tuples. Such inter- Physics and Chemistry of UC Berkeley). The assumption is that it faces differ from these examples in the following ways: First, the is cheaper to input two pieces of information of the same kind as key attribute(s) (i.e., the name of a professor in this case) becomes part of a single form than twice as part of separate forms. CrowdDB an input field. In order to restrict the set of possible new tuples, supports this batching functionality. CrowdDB allows presetting the value of non-key attributes using Another optimization is prefetching of attributes for the same tu- the where clause, e.g. only considering professors from UC Berke- ple. For instance, if both the department and email of a professor ley. Second, JavaScript logic is generated that shows the names are unknown, but only the email of that professor is required to of professors that have already been recorded while typing in the process a query, the question is whether the department should also name of a (potentially new) professor. Finally, an additional button be crowdsourced. The trade-offs are straight-forward: Prefetching is provided to allow workers to report if they cannot find any new may hurt the cost and response time of the current query, but it may professor records. help reduce the cost and response time of future queries. The cur- rent version of CrowdDB carries out prefetching, thereby assuming 6. QUERY PROCESSING that the incremental cost of prefetching is lower than the return on Since CrowdDB is SQL-based, query plan generation and execu- the prefetching investment. tion follows a largely traditional approach. In particular, as shown CrowdDB also creates user interfaces for the CROWDEQUAL and in Figure 1, CrowdDB has a parser, optimizer, and runtime system CROWDORDER functions. Figures 2b and 2c show example inter- and these components play the same role in CrowdDB as in a tradi- faces for comparing and ordering tuples. Both types of interfaces tional database system. The main differences are that the CrowdDB can also be batched as described earlier. However, for ordering parser has been extended to parse CrowdSQL, CrowdDB has addi- tuples, our current implementation only supports binary compar- tional operators that effect crowdsourcing (in addition to the tradi- isons. Multi-way comparisons remain future work. tional relational algebra operators found in a traditional database system), and the CrowdDB optimizer includes special heuristics to 5.2 Multi-Relation Interfaces generate plans with these additional Crowd operators. This section Crowdsourcing relations with foreign keys require special con- sketches these differences and discusses an example query plan. siderations. In the simplest case, the foreign key references a non- crowdsourced table. In this case, the generated user interface shows 6.1 Crowd Operators a drop-down box containing all the possible foriegn key values, CrowdDB implements all operators of the relational algebra, just or alternatively if the domain is too large for a drop-down box an like any traditional database system (e.g., join, group-by, index Ajax-based “suggest” function is provided. scans, etc.). In addition, CrowdDB implements a set of Crowd op- In contrast, if the referenced table is a CROWD table, the set of erators that encapsulate the instantiation of user interface templates all possible foriegn key values is not known, and additional tuples at runtime and the collection of results obtained from crowdsourc- of the referenced table may need to be crowdsourced. For the mo- ing. This way, the implementation of traditional operators need not ment, let us assume that the department table is indeed a CROWD be changed. The next subsection describes how query plans are table (deviating from its definition in Example 1). In this case, a generated with such Crowd operators. This subsection describes worker may wish to specify that a professor is member of a new the set of Crowd operators currently implemented in CrowdDB. department; i.e., a department that has not yet been obtained from The basic functionality of all Crowd operators is the same. They the crowd. are all initialized with a user interface template and the standard CrowdDB supports two types of user interfaces for such situa- HIT parameters that are used for crowdsourcing as part of a par- tions. The first type is the normalized interface shown in Figure 2d. ticular Crowd operator. At runtime, they consume a set of tuples, This interface requires the worker to enter values for the foreign key e.g., Professors. Depending on the Crowd operator, crowdsourc- attributes, but does not allow him or her to enter any other fields of ing can be used to source missing values of a tuple (e.g., the email the referenced tuple. Here, as above, the “suggest” function can of a Professor) or to source new tuples. In both cases, each tuple help to avoid entity resolution problems. represents one job (using the terminology from Section 2.1). Sev- The second type is a denormalized interface, which allows a eral tuples can be batched into a single HIT as described in Section worker to enter missing values for non-key fields of the referenced 5.1; e.g., a user interface instance could be used to crowdsource table as part of the same task. To this end, the user interface pro- the email of say, three, Professors. Furthermore, Crowd operators vides an add button (in addition, the the drop down menu of known create HIT Groups. For instance, if the email of 300 professors departments). Clicking on this add button brings up a pop-up win- needs to be sourced and each HIT involves three professors, then dow or new browser tab (depending on the browser configuration) one HIT Group of 100 HITs could be generated. As shown in Sec- that allows to enter the information of the new department as visu- tion 7, when using AMT, the size of HIT Groups and how they are alized in Figure 2e. How the optimizer chooses the interface for a posted must be carefully tuned. particular query is explained in the next section. In addition to the creation of HITs and HIT Groups, each Crowd Note that Figures 2d and 2e show the two types of user interfaces operator consumes results returned by the crowd and carries out
8 . Please fill out the missing department data University Name SELECT * ⋈ p.dep=d.name URL FROM professor p, department d σ name="Karp" CrowdJoin (Dep) p.dep = d.name Phone Submit Department WHERE p.department = d.name Please fill out the professor data AND p.university = d.university AND p.name = "Karp" ⋈ p.dep=d.name σ name= CrowdProbe Name Karp "Karp" (Professor) Email Professor Department name=Karp University Professor Department Submit (a) PeopleSQL query (b) Logical plan (c) Logical plan (d) Physical plan before optimization after optimization Figure 3: CrowdSQL Query Plan Generation quality control. In the current CrowdDB prototype, quality control This logical plan is then optimized using traditional and crowd- is carried out by a majority vote on the input provided by different specific optimizations. Figure 3c shows the optimized logical plan workers for the same HIT. The number of workers assigned to for this example. In this example, only predicate push-down was each HIT is controlled by an Assignments parameter (Section 2.1). applied, a well-known traditional optimization technique. Some The initial number of Assignments is currently a static parameter of crowd-specific optimization heuristics used in CrowdDB are de- CrowdDB. As mentioned in Section 4.3, this parameter should be scribed in the next subsection. Finally, the logical plan is translated set by the CrowdDB optimizer based on budget constraints set via into a physical plan which can be executed by the CrowdDB run- CrowdSQL. time system. As part of this step, Crowd operators and traditional The current version of CrowdDB has three Crowd operators: operators of the relational algebra are instantiated. In the example of Figure 3, the query is executed by a CrowdProbe operator in or- • CrowdProbe: This operator crowdsources missing information der to crowdsource missing information from the Professor table of CROWD columns (i.e., CNULL values) and new tuples. It and a CrowdJoin operator in order to crowdsource missing infor- uses interfaces such as those shown in Figures 2a, 2d and 2e. mation from the Department table. (In this example, it is assumed The operator enforces quality control by selecting the majority that the Department is a CROWD table; otherwise, the CrowdJoin answer for every attribute as the final value. That is, given the operator would not be applicable.) answers for a single tuple (i.e., entity with the same key), the ma- jority of turkers have to enter the same value to make it the final 6.3 Heuristics value of the tuple. If no majority exists, more workers are asked The current CrowdDB compiler is based on a simple rule-based until the majority agrees or a pre-set maximum of answers are optimizer. The optimizer implements several essential query rewrit- collected. In the latter case, the final value is randomly selected ing rules such as predicate push-down, stopafter push-down [7], from the values most workers had in common. join-ordering and determining if the plan is bounded [5]. The last In the case of newly created tuples it can happen that all workers optimization deals with the open-world assumption by ensuring enter tuples with different primary keys, making finding a ma- that the amount of data requested from the crowd is bounded. Thus, jority impossible. In this case, the operator re-posts the tasks by the heuristic first annotates the query plan with the cardinality pre- leaving all non-confirmed attributes empty except the ones com- dictions between the operators. Afterwards, the heuristic tries to prising the primary key. This allows CrowdDB to obtain more re-order the operators to minimize the requests against the crowd answers for every key in order to form a majority quorum. and warns the user at compile-time if the number of requests cannot • CrowdJoin: This operator implements an index nested-loop join be bounded. over two tables, at least one of which is crowdsourced. For each Furthermore, we also created a set of crowd-sourcing rules in or- tuple of the outer relation, this operator creates one or more HITs der to set the basic crowdsourcing parameters (e.g., price, batching- in order to crowdsource new tuples from the inner relation that size), select the user interface (e.g., normalized vs. denormalized) matches the tuple of the outer relation. Correspondingly, the in- and several other simple cost-saving techniques. For example, a ner relation must be a CROWD table and the user interface to delete on a crowd-sourced table does not try to receive all tuples crowdsource new tuples from the inner relation is instantiated satisfying the expression in the delete statement before deleting with the join column values of the tuple from the outer relation them. Instead the optimizer rewrites the query to only look into according to the join predicates. The quality control technique existing tuples. is the same as for CrowdProbe. Nevertheless, in contrast to a cost-based optimizer, a rule-based • CrowdCompare: This operator implements the CROWDEQUAL optimizer is not able to exhaustively explore all parameters and and CROWDORDER functions described in Section 4.2. It in- thus, often produces a sub-optimal result. A cost-based optimizer stantiates user interfaces such as those shown in Figures 2c and for CrowdDB, which must also consider the changing conditions 2d. Note that CrowdCompare is typically used inside another on AMT, remains future work. traditional operator, such as sorting or predicate evaluation. For example, an operator that implements quick-sort might use Crowd- 7. EXPERIMENTS AND RESULTS Compare to perform the required binary comparisons. Quality This section presents results from experiments run with CrowdDB control is based on the simple majority vote. and AMT. We ran over 25,000 HITs on AMT during October 2010, varying parameters such as price, jobs per HIT and time of day. We 6.2 Physical Plan Generation measured the response time and quality of the answers provided Figure 3 presents an end-to-end example that shows how CrowdDB by the workers. Here, we report on Micro-benchmarks (Section creates a query plan for a simple CrowdSQL query. A query is 7.1), that use simple jobs involving finding new data or making first parsed; the result is a logical plan, as shown in Figure 3b. subjective comparisons. The goals of these experiments are to ex-
9 . 14 Response Time First HIT $0.04 Assignments completed (%) Response Time First 10 HITs 49.3 97.3 60 $0.03 Response Time First 25 HITs 100 23.5 $0.02 Response Time (mins) 12 HITs completed (%) 163.5 50 $0.01 10 80 7.8 40 8 60 223.8 30 6 40 4 20 20 10 2 0 0 0 10 25 50 100 200 400 10 25 50 100 200 400 0 10 20 30 40 50 60 Number of HITs in a HIT group Number of HITs in a HIT group Time (mins) Figure 4: Response Time (min): Vary Hit Figure 5: Completion (%): Vary Hit Figure 6: Completion (%): Vary Reward Group (1 Asgn/HIT, 1 cent Reward) Group (1 Asgn/HIT, 1 cent Reward) (100 HITs/Group, 5 Asgn/HIT) amine the behavior of workers for the types of tasks required by the number of HITs per HIT Group from 10 to 400 and fixed the CrowdDB, as well as to obtain insight that could be used in the de- number of assignments per HIT to 1 (i.e., no replication). Figures velopment of cost models for query optimization. We also describe 4 and 5 show the results of this experiment. the results of experiments that demonstrate the execution of more Figure 4 shows the time to completion of 1, 10, and 25 HITs as complex queries (Section 7.2). the HIT Group size is varied. The results show that response times It is important to note that the results presented in this section are decrease dramatically as the size of the HIT Groups is increased. highly dependent on the properties of the AMT platform at a partic- For example, for a HIT Group of 25 HITs, the first result was ob- ular point in time (October 2010). AMT and other crowdsourcing tained after approximately four minutes, while for a HIT Group platforms are evolving rapidly and it is quite likely that response containing 400 HITs, the first result was obtained in seconds. time and quality properties will differ significantly between dif- Figure 5 provides a different view on the results of this experi- ferent platforms and even different versions of the same platform. ment. In this case, we show the percentage of the HITs in a HIT Furthermore, our results are highly-dependent on the specific tasks Group completed within 30 minutes, for HIT Groups of different we sent to the crowd. Nevertheless, we believe that a number of in- sizes. The points are annotated with the absolute number of HITs teresting and important observations can be made even from these completed within 30 minutes. This graph shows that there is a initial experiments. We describe these below. tradeoff between throughput (in terms of HITs completed per unit time) and completion percent. That is, while the best throughput 7.1 Micro Benchmarks obtained was for the largest Group size (223.8 out of a Group of We begin by describing the results of experiments with simple 400 HITs), the highest completion rates were obtained with Groups tasks requiring workers to find and fill in missing data for a table of 50 or 100 HITs. The implication is that performance for sim- with two crowdsourced columns: ple tasks can vary widely even when only a single parameter is changed. Thus, more work is required for understanding how to set CREATE TABLE businesses ( the HIT Group size and other parameters — a prerequisite for the name VARCHAR PRIMARY KEY, development of a true cost-based query optimizer for CrowdDB or phone_number CROWD VARCHAR(32), any crowdsourced query answering system. address CROWD VARCHAR(256) ); 7.1.2 Experiment 2: Responsiveness, Vary Reward While Experiment 1 showed that even a fairly technical param- We populated this table with the names of 3607 businesses (restau- eter such as HIT Group size can greatly impact performance, there rants, hotels, and shopping malls) in 40 USA cities. We studied are other parameters that one would perhaps more obviously expect the sourcing of the phone_number and address columns using the to influence the performance of a crowdbased system. High on this following query: list would be the magnitude of the reward given to workers. Here, SELECT phone_number, address FROM businesses; we report on a set of experiments that examine how the response time varies as a function of the reward. In these experiments, 100 Since workers and skills are not evenly distributed across time- HITs were posted per HIT Group and each HIT contained five as- zones, the time of day can impact both response time and answer signments. The expectation is that the higher the reward for a HIT, quality [24]. While we ran tasks at many different times, in this the faster workers will engage into processing that HIT. paper we report only on experiments that were carried out between Figure 6 shows the fraction of HITs (i.e., all five assignments) 0600 and 1500 PST, which reduces the variance in worker avail- that were completed as a function of time. The figure shows the ability [14]. We repeated all experiments four times and provide results for HITs with a reward of (from the bottom up) 1, 2, 3, and the average values. Unless stated otherwise, groups of 100 HITs 4 cents per assignment. Obviously, for all rewards, the longer we were posted and each HIT involved five assignments. By default wait the more HITs are completed. The results show that for this the reward for each job was 1 cent and each HIT asked for the ad- particular task, paying 4 cents gives the best performance, while dress and phone number of one business (i.e., 1 Job per HIT). paying 1 cent gives the worst. Interestingly, there is very little dif- ference between paying 2 cents and 3 cents per assignment. 7.1.1 Experiment 1: Response Time, Vary HIT Groups Figure 7 shows the fraction of HITs that received at least one As mentioned in Section 2, AMT automatically groups HITs of assignment as a function of time and reward. Comparing Figures the same kind into a HIT Group. In the first set of experiments 6 and 7, two observations can be made. First, within sixty minutes we examined the response time of assignments as a function of the almost all HITs received at least one answer if a reward of 2, 3, or number of HITs in a HIT Group. For this experiment we varied 4 cents was given (Figure 7), whereas only about 65% of the HITs
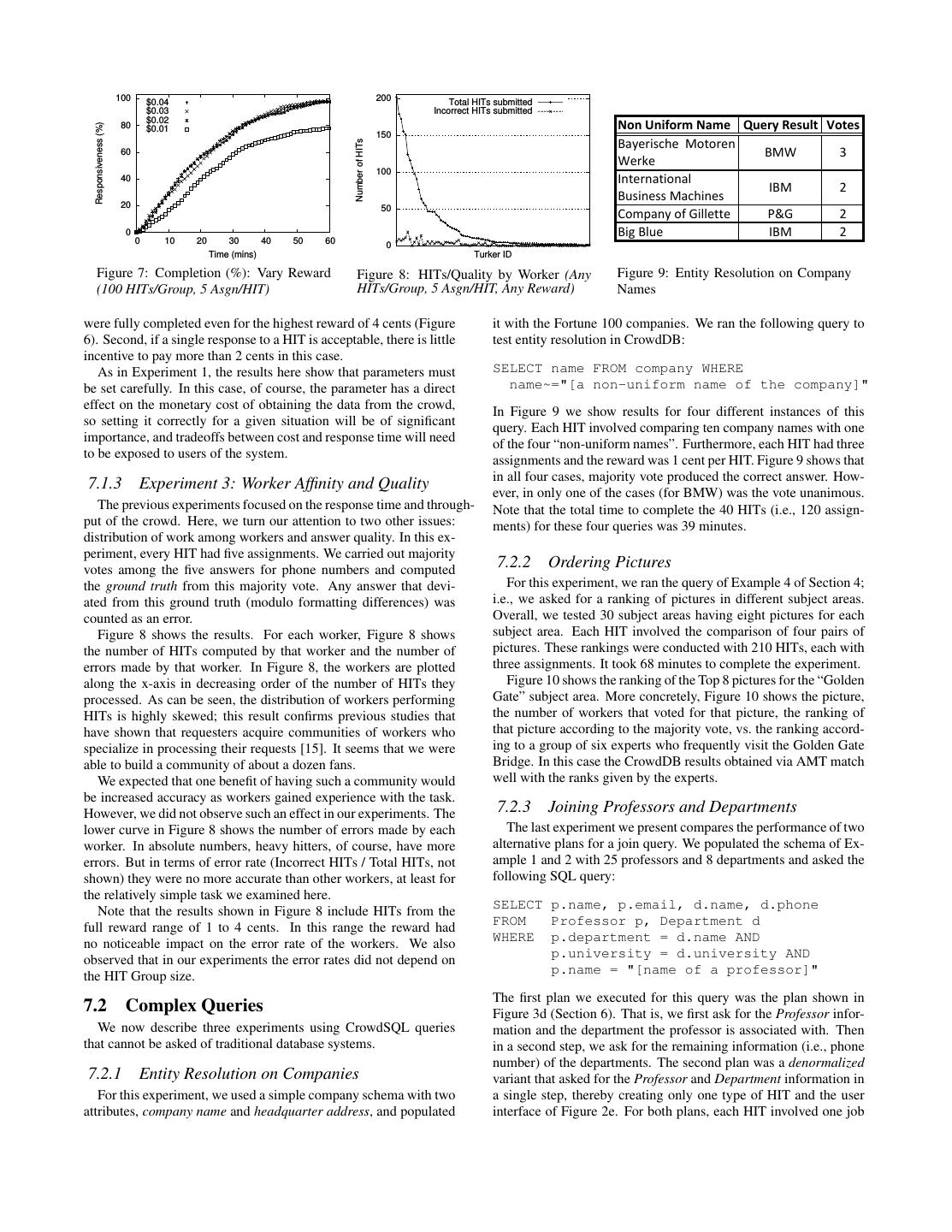
10 . 100 $0.04 200 Total HITs submitted $0.03 Incorrect HITs submitted 80 $0.02 Non Uniform Name Query Result Votes Responsiveness (%) $0.01 150 Bayerische Motoren Number of HITs 60 BMW 3 Werke 100 40 International IBM 2 Business Machines 20 50 Company of Gillette P&G 2 0 Big Blue IBM 2 0 10 20 30 40 50 60 0 Time (mins) Turker ID Figure 7: Completion (%): Vary Reward Figure 8: HITs/Quality by Worker (Any Figure 9: Entity Resolution on Company (100 HITs/Group, 5 Asgn/HIT) HITs/Group, 5 Asgn/HIT, Any Reward) Names were fully completed even for the highest reward of 4 cents (Figure it with the Fortune 100 companies. We ran the following query to 6). Second, if a single response to a HIT is acceptable, there is little test entity resolution in CrowdDB: incentive to pay more than 2 cents in this case. As in Experiment 1, the results here show that parameters must SELECT name FROM company WHERE be set carefully. In this case, of course, the parameter has a direct name~="[a non-uniform name of the company]" effect on the monetary cost of obtaining the data from the crowd, In Figure 9 we show results for four different instances of this so setting it correctly for a given situation will be of significant query. Each HIT involved comparing ten company names with one importance, and tradeoffs between cost and response time will need of the four “non-uniform names”. Furthermore, each HIT had three to be exposed to users of the system. assignments and the reward was 1 cent per HIT. Figure 9 shows that in all four cases, majority vote produced the correct answer. How- 7.1.3 Experiment 3: Worker Affinity and Quality ever, in only one of the cases (for BMW) was the vote unanimous. The previous experiments focused on the response time and through- Note that the total time to complete the 40 HITs (i.e., 120 assign- put of the crowd. Here, we turn our attention to two other issues: ments) for these four queries was 39 minutes. distribution of work among workers and answer quality. In this ex- periment, every HIT had five assignments. We carried out majority votes among the five answers for phone numbers and computed 7.2.2 Ordering Pictures the ground truth from this majority vote. Any answer that devi- For this experiment, we ran the query of Example 4 of Section 4; ated from this ground truth (modulo formatting differences) was i.e., we asked for a ranking of pictures in different subject areas. counted as an error. Overall, we tested 30 subject areas having eight pictures for each Figure 8 shows the results. For each worker, Figure 8 shows subject area. Each HIT involved the comparison of four pairs of the number of HITs computed by that worker and the number of pictures. These rankings were conducted with 210 HITs, each with errors made by that worker. In Figure 8, the workers are plotted three assignments. It took 68 minutes to complete the experiment. along the x-axis in decreasing order of the number of HITs they Figure 10 shows the ranking of the Top 8 pictures for the “Golden processed. As can be seen, the distribution of workers performing Gate” subject area. More concretely, Figure 10 shows the picture, HITs is highly skewed; this result confirms previous studies that the number of workers that voted for that picture, the ranking of have shown that requesters acquire communities of workers who that picture according to the majority vote, vs. the ranking accord- specialize in processing their requests [15]. It seems that we were ing to a group of six experts who frequently visit the Golden Gate able to build a community of about a dozen fans. Bridge. In this case the CrowdDB results obtained via AMT match We expected that one benefit of having such a community would well with the ranks given by the experts. be increased accuracy as workers gained experience with the task. However, we did not observe such an effect in our experiments. The 7.2.3 Joining Professors and Departments lower curve in Figure 8 shows the number of errors made by each The last experiment we present compares the performance of two worker. In absolute numbers, heavy hitters, of course, have more alternative plans for a join query. We populated the schema of Ex- errors. But in terms of error rate (Incorrect HITs / Total HITs, not ample 1 and 2 with 25 professors and 8 departments and asked the shown) they were no more accurate than other workers, at least for following SQL query: the relatively simple task we examined here. SELECT p.name, p.email, d.name, d.phone Note that the results shown in Figure 8 include HITs from the FROM Professor p, Department d full reward range of 1 to 4 cents. In this range the reward had WHERE p.department = d.name AND no noticeable impact on the error rate of the workers. We also p.university = d.university AND observed that in our experiments the error rates did not depend on p.name = "[name of a professor]" the HIT Group size. The first plan we executed for this query was the plan shown in 7.2 Complex Queries Figure 3d (Section 6). That is, we first ask for the Professor infor- We now describe three experiments using CrowdSQL queries mation and the department the professor is associated with. Then that cannot be asked of traditional database systems. in a second step, we ask for the remaining information (i.e., phone number) of the departments. The second plan was a denormalized 7.2.1 Entity Resolution on Companies variant that asked for the Professor and Department information in For this experiment, we used a simple company schema with two a single step, thereby creating only one type of HIT and the user attributes, company name and headquarter address, and populated interface of Figure 2e. For both plans, each HIT involved one job
11 . (a) 15, 1, 1 (b) 15, 1, 2 (c) 14, 3, 4 (d) 13, 4, 5 (e) 10, 5, 6 (f) 9, 6, 3 (g) 4, 7, 7 (h) 4, 7, 8 Figure 10: Pictures of the Golden Gate Bridge [1] ordered by workers. The tuples in the sub-captions is in the following format: {the number of votes by the workers for this picture, rank of the picture ordered by the workers (based on votes), rank of the picture ordered by experts}. (e.g., an entry form for a single professor) and three assignments. query processing. They also show, we believe, the need to auto- The reward per HIT was 1 cent. mate such decisions to shield query and application writers from The two plans were similar in execution time and cost but dif- these complexities and to enable robust behavior in the presence of fered significantly in result quality. The first plan took 206 minutes environmental changes. Such a need should be familiar to database and cost $0.99, while the second plan took 173 minutes and cost systems designers — it is essentially a requirement for a new form $0.75. In terms of quality, the second plan produced wrong results of data independence. for all department telephone numbers. A close look at the data re- vealed that workers unanimously submitted the professors’ phone 8. RELATED WORK numbers instead of the departments’. In contrast, only a single tele- We discuss related work in two primary areas: database systems phone number was incorrect when using the first plan. and the emerging crowdsourcing community. CrowdDB leverages traditional techniques for relational query 7.3 Observations processing wherever possible. Furthermore, we found that some In total, our experiments involved 25,817 assignments processed less-standard techniques developed for other scenarios were useful by 718 different workers. Overall, they confirm the basic hypoth- for crowdsourcing as well. For example, crowdsourced compar- esis of our work: it is possible to employ human input via crowd- isons such CROWDEQUAL, can be seen as special instances of ex- sourcing to process queries that traditional systems cannot. The pensive predicates [13]. Top N optimizations [7] are a useful tool experiments also, however, pointed out some of the challenges that for dealing with the open-world nature of crowdsourcing, partic- remain to be addressed, particularly in terms of understanding and ularly when combined with operation-limiting techniques such as controlling the factors that impact response time, cost and result those developed for cloud scalability in [5]. Looking forward, we quality. In this section, we outline several additional lessons we anticipate that the volatility of crowd performance will require the learned during our experimentation. use of a range of adaptive query processing techniques [12]. First, we observe that unlike computational resources, crowd re- An important feature of CrowdDB is the (semi-) automatic gen- sources involve long-term memory that can impact performance. eration of user interfaces from meta-data (i.e., SQL schemas). As Requesters can track workers’ past performance and workers can mentioned in Section 5, products such as Oracle Forms and MS track and discuss the past behavior of requesters. We found, for Access have taken a similar approach. Model-driven architecture example, that to keep workers happy, it is wise to be less strict in frameworks (MDA) enable similar functionality [17]. Finally, there approving HITs. In one case, when we rejected HITs that failed are useful analogies between CrowdDB and federated database sys- our quality controls, a worker posted the following on TurkOpticon tems (e.g., [8, 11]): CrowdDB can be considered to be a mediator, [27]: “Of the 299 HITs I completed, 11 of them were rejected...I the crowd can be seen as a data sources and the generated user in- have attempted to contact the requester and will update...Until then terfaces can be regarded as wrappers for those sources. be very wary of doing any work for this requester...”. In another As stated in the introduction, crowdsourcing has been gathering case, a bug in CrowdDB triggered false alarms in security warnings increasing attention in the research community. A recent survey of for browsers on the workers’ computers, and within hours concerns the area can be found in [10]. There have been a number of studies about our jobs appeared on Turker Nation [26]. that analyze the behavior of microtask platforms such as Mechan- A second lesson is that user interface design and precise instruc- ical Turk. Ipeirotis, for instance, analyzed the AMT marketplace, tions matter. For our first experiments with AMT, we posted HITs gathering statistics about HITs, requesters, rewards, HIT comple- with handcrafted user interfaces. In one HIT, we gave a list of com- tion rates, etc. [15]. Furthermore, the demographics of workers pany names and asked the workers to check the ones that matched (e.g., age, gender, education, etc.) on AMT have been studied [24]. “IBM”. To our surprise, the quality of the answers was very low. Systems making early attempts to automatically control quality The problem was that in some cases there were no good matches. and optimize response time include CrowdSearch [28] and Soylent We expected workers to simply not check any boxes in such cases, [6]. TurKit is a set of tools that enables programming iterative algo- but this did not occur. Adding a checkbox for “None of the above” rithms over the crowd [19]. This toolkit has been used, for example, improved the quality dramatically. to decipher unreadable hand-writing. Finally, Usher is a research Our experimental results, along with these anecdotes, demon- project that studies the design of data entry forms [9]. strate the complexity and new challenges that arise for crowdsourced Independently of our work on CrowdDB, several groups in the
12 .database research community have begun to explore the use of performance as well. Answer quality assessment and improvement crowdsourcing in relational query processing. Two papers on the will require the development of new techniques and operators. topic appeared in the recent CIDR 2011 conference [20, 23]. As The combination of human input with high-powered database with our work, both of these efforts suggest the use of a declarative processing not only extends the range of existing database systems, query language in order to process queries involving human input. but also enables completely new applications and capabilities. For [20] proposes the use of user-defined functions in SQL to specify this reason, we expect this to be a fruitful area of research and de- the user interfaces and the questions that should be crowdsourced velopment for many years. as part of query processing. [23] suggests the use of Datalog for this purpose. However, neither of these early papers present details Acknowledgements of the system design or experimental results. As these projects ma- This work was supported in part by AMPLab founding sponsors ture, it will be interesting to compare the design decisions made Google and SAP, and AMPLab sponsors Amazon Web Services, and implications with regard to usability and optimizability. Also Cloudera, Huawei, IBM, Intel, Microsoft, NEC, NetApp, and VMWare. related is recent work in the database community on graph search- ing using crowdsourcing [22]. Finally, there has also been work 10. REFERENCES [1] Pictures of the Golden Gate Bridge retrieved from Flickr by akaporn, on defining workflow systems that involve machines and humans. Dawn Endico, devinleedrew, di_the_huntress, Geoff Livingston, Dustdar et al. describe in a recent vision paper how BPEL and web kevincole, Marc_Smith, and superstrikertwo under the Creative services technology could be used for this purpose [25]. Commons Attribution 2.0 Generic license. [2] Amazon. AWS Case Study: Smartsheet, 2006. [3] Amazon Mechanical Turk. http://www.mturk.com, 2010. 9. CONCLUSION [4] S. Amer-Yahia et al. Crowds, Clouds, and Algorithms: Exploring the Human Side of "Big Data" Applications. In SIGMOD, 2010. This paper presented the design of CrowdDB, a relational query [5] M. Armbrust et al. PIQL: A Performance Insightful Query Language. processing system that uses microtask-based crowdsourcing to an- In SIGMOD, 2010. swer queries that cannot otherwise be answered. We highlighted [6] M. S. Bernstein et al. Soylent: A Word Processor with a Crowd two cases where human input is needed: (a) unknown or incom- Inside. In ACM SUIST, 2010. plete data, and (b) subjective comparisons. CrowdDB extends SQL [7] M. J. Carey and D. Kossmann. On saying “Enough already!” in SQL. in order to address both of these cases and it extends the query com- SIGMOD Rec., 26(2):219–230, 1997. piler and runtime system with auto-generated user interfaces and [8] S. S. Chawathe et al. The TSIMMIS Project: Integration of Heterogeneous Information Sources. In IPSJ, 1994. new query operators that can obtain human input via these inter- [9] K. Chen et al. USHER: Improving Data Quality with Dynamic faces. Experiments with CrowdDB on Amazon Mechanical Turk Forms. In ICDE, pages 321–332, 2010. demonstrated that human input can indeed be leveraged to dramat- [10] A. Doan, R. Ramakrishnan, and A. Halevy. Crowdsourcing Systems ically extend the range of SQL-based query processing. on the World-Wide Web. CACM, 54:86–96, Apr. 2011. We described simple extensions to the SQL DDL and DML for [11] L. M. Haas et al. Optimizing Queries Across Diverse Data Sources. crowdsourcing. These simple extensions, however, raise deep and In VLDB, 1997. fundamental issues for the design of crowd-enabled query languages [12] J. M. Hellerstein et al. Adaptive Query Processing: Technology in and execution engines. Perhaps most importantly, they invalidate Evolution. IEEE Data Eng. Bull., 2000. the closed-world assumption on which SQL semantics and process- [13] J. M. Hellerstein and J. F. Naughton. Query Execution Techniques for Caching Expensive Methods. In SIGMOD, pages 423–434, 1996. ing strategies are based. We identified implementation challenges [14] E. Huang et al. Toward Automatic Task Design: A Progress Report. that arise as a result and outlined initial solutions. In HCOMP, 2010. Other important issues concern the assessment and preservation [15] P. G. Ipeirotis. Analyzing the Amazon Mechanical Turk Marketplace. of answer quality. Quality is greatly impacted by the motivation http://hdl.handle.net/2451/29801, 2010. and skills of the human workers as well as the structure and inter- [16] P. G. Ipeirotis. Mechanical Turk, Low Wages, and the Market for faces of the jobs they are asked to do. Performance, in terms of Lemons. http://behind-the-enemy-lines.blogspot.com/2010/07/ latency and cost, is also effected by the way in which CrowdDB mechanical-turk-low-wages-and-market.html, 2010. interacts with workers. Through a series of micro-benchmarks we [17] A. G. Kleppe, J. Warmer, and W. Bast. MDA Explained: The Model identified key design parameters such as the grouping of tasks, the Driven Architecture: Practice and Promise. Addison-Wesley, 2003. [18] G. Little. How many turkers are there? rewards paid to workers, and the number of assignments per task. http://groups.csail.mit.edu/uid/deneme/?p=502, 2009. We also discussed the need to manage the long-term relationship [19] G. Little et al. TurKit: Tools for Iterative Tasks on Mechanical Turk. with workers. It is important to build a community of workers and In HCOMP, 2009. to provide them with timely and appropriate rewards and, if not, to [20] A. Marcus et al. Crowdsourced Databases: Query Processing with give precise and understandable feedback. People. In CIDR, 2011. Of course, there is future work to do. Answer quality is a per- [21] Microsoft. Table Column Properties (SQL Server), 2008. vasive issue that must be addressed. Clear semantics in the pres- [22] A. Parameswaran et al. Human-Assisted Graph Search: It’s Okay to ence of the open-world assumption are needed for for both crowd- Ask Questions. In VLDB, 2011. sourced values and tables. While our existing approach preserves [23] A. Parameswaran and N. Polyzotis. Answering Queries using SQL semantics in principle, there are practical considerations due Humans, Algorithms and Databases. In CIDR, 2011. [24] J. Ross et al. Who are the Crowdworkers? Shifting Demographics in to cost and latency that can impact the answers that will be returned Mechanical Turk. In CHI EA, 2010. by any crowdsourced query processor. [25] D. Schall, S. Dustdar, and M. B. Blake. Programming Human and There are also a host of exciting implementation challenges. Cost- Software-Based Web Services. Computer, 43(7):82–85, 2010. based optimization for the crowd involves many new parameters [26] Turker Nation. http://www.turkernation.com/, 2010. and considerations. Time-of-day, pricing, worker fatigue, task user- [27] Turkopticon. http://turkopticon.differenceengines.com/, 2010. interface design, etc. all impact performance and quality. Adaptive [28] T. Yan, V. Kumar, and D. Ganesan. CrowdSearch: Exploiting Crowds optimization techniques will clearly be needed. Caching and man- for Accurate Real-time. Image Search on Mobile Phones. In aging crowdsourced answers, if done properly, can greatly improve MobiSys, 2010.
3秒后跳转登录页面
去登陆

