














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u3805/DeepLearning?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Deep Learning
分享
点赞
4
收藏
2
下载 0
Step 1: define a set of function
Step 2: goodness of function
Step 3: pick the best function
展开查看详情
1 .Deep Learning Hung-yi Lee 李宏毅
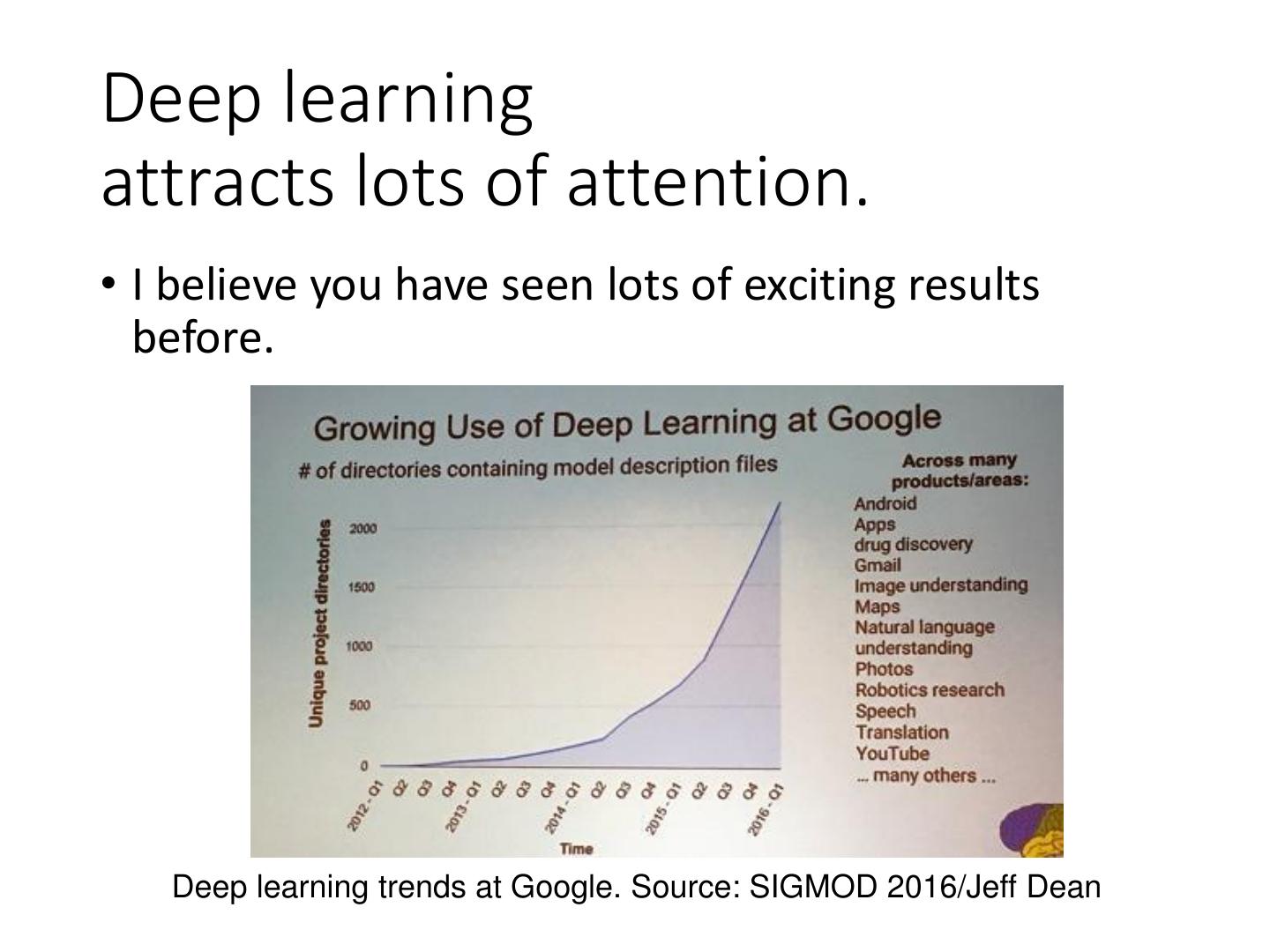
2 .Deep learning attracts lots of attention. • I believe you have seen lots of exciting results before. Deep learning trends at Google. Source: SIGMOD 2016/Jeff Dean
3 . Ups and downs of Deep Learning • 1958: Perceptron (linear model) • 1969: Perceptron has limitation • 1980s: Multi-layer perceptron • Do not have significant difference from DNN today • 1986: Backpropagation • Usually more than 3 hidden layers is not helpful • 1989: 1 hidden layer is “good enough”, why deep? • 2006: RBM initialization • 2009: GPU • 2011: Start to be popular in speech recognition • 2012: win ILSVRC image competition • 2015.2: Image recognition surpassing human-level performance • 2016.3: Alpha GO beats Lee Sedol • 2016.10: Speech recognition system as good as humans
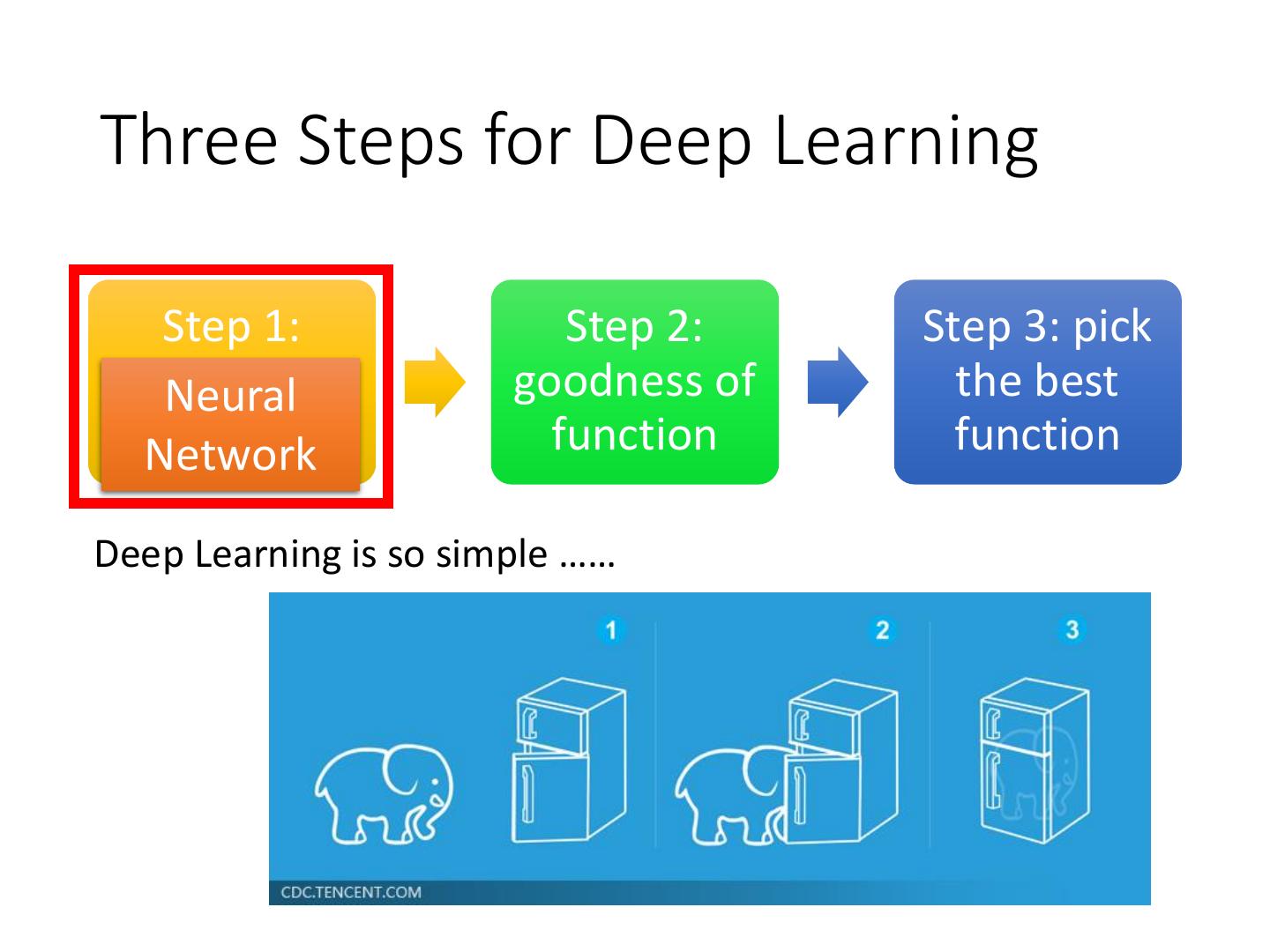
4 .Three Steps for Deep Learning Step 1: Step 2: Step 3: pick define a set Neural goodness of the best ofNetwork function function function Deep Learning is so simple ……
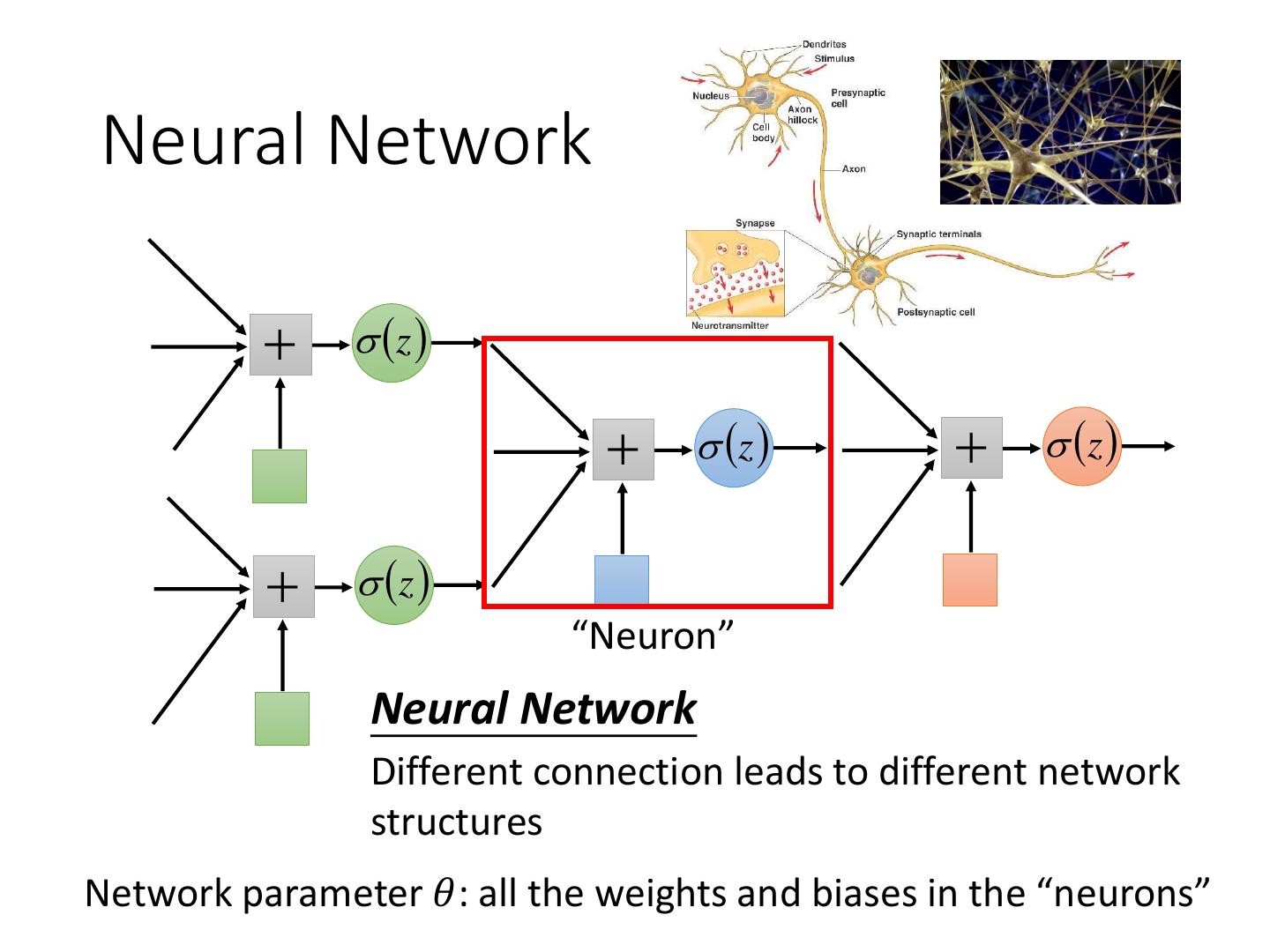
5 .Neural Network z z z z “Neuron” Neural Network Different connection leads to different network structures Network parameter 𝜃: all the weights and biases in the “neurons”
6 .Fully Connect Feedforward Network 1 4 0.98 1 -2 1 -1 -2 0.12 -1 1 0 Sigmoid Function z z 1 z 1 e z
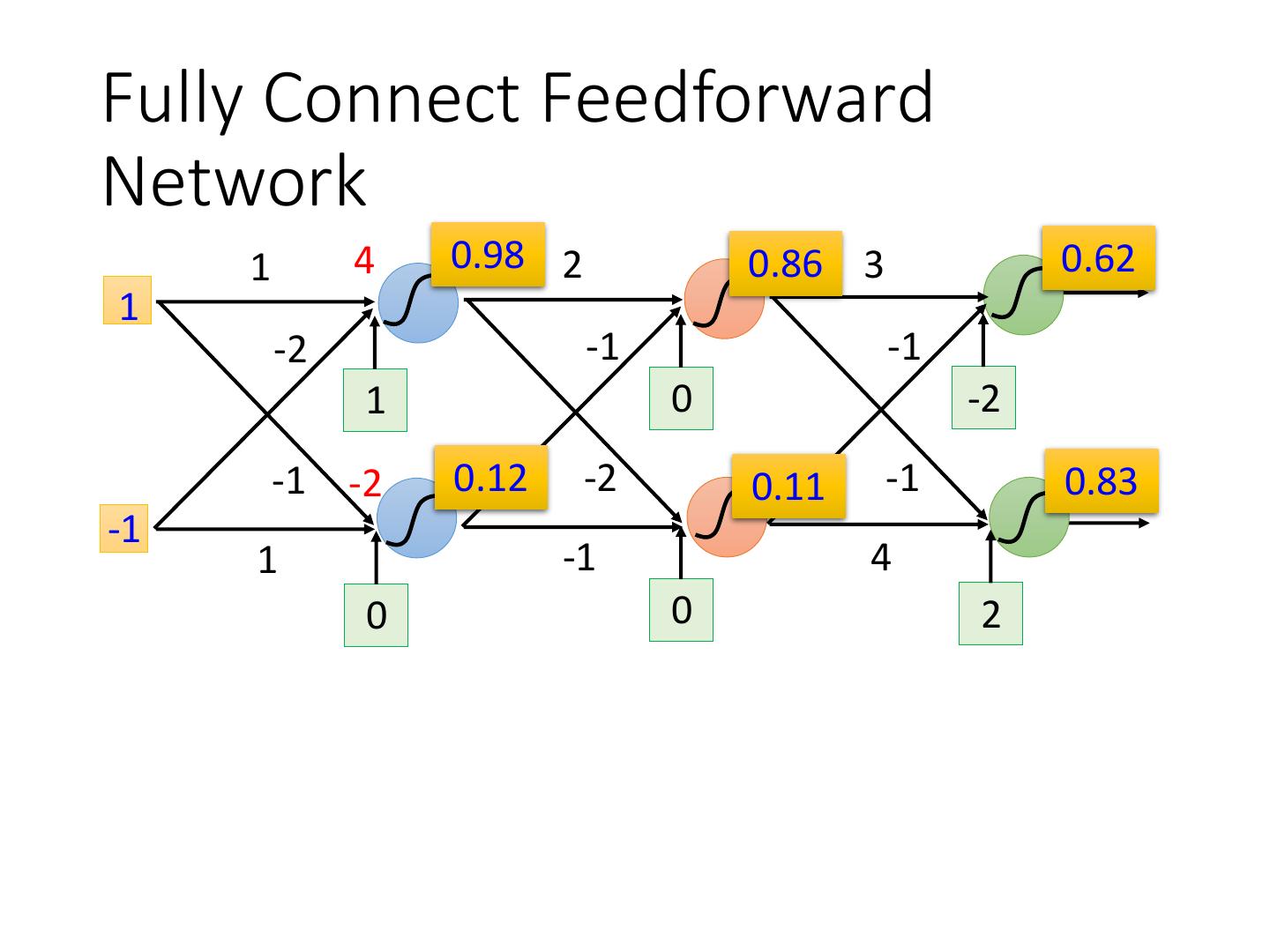
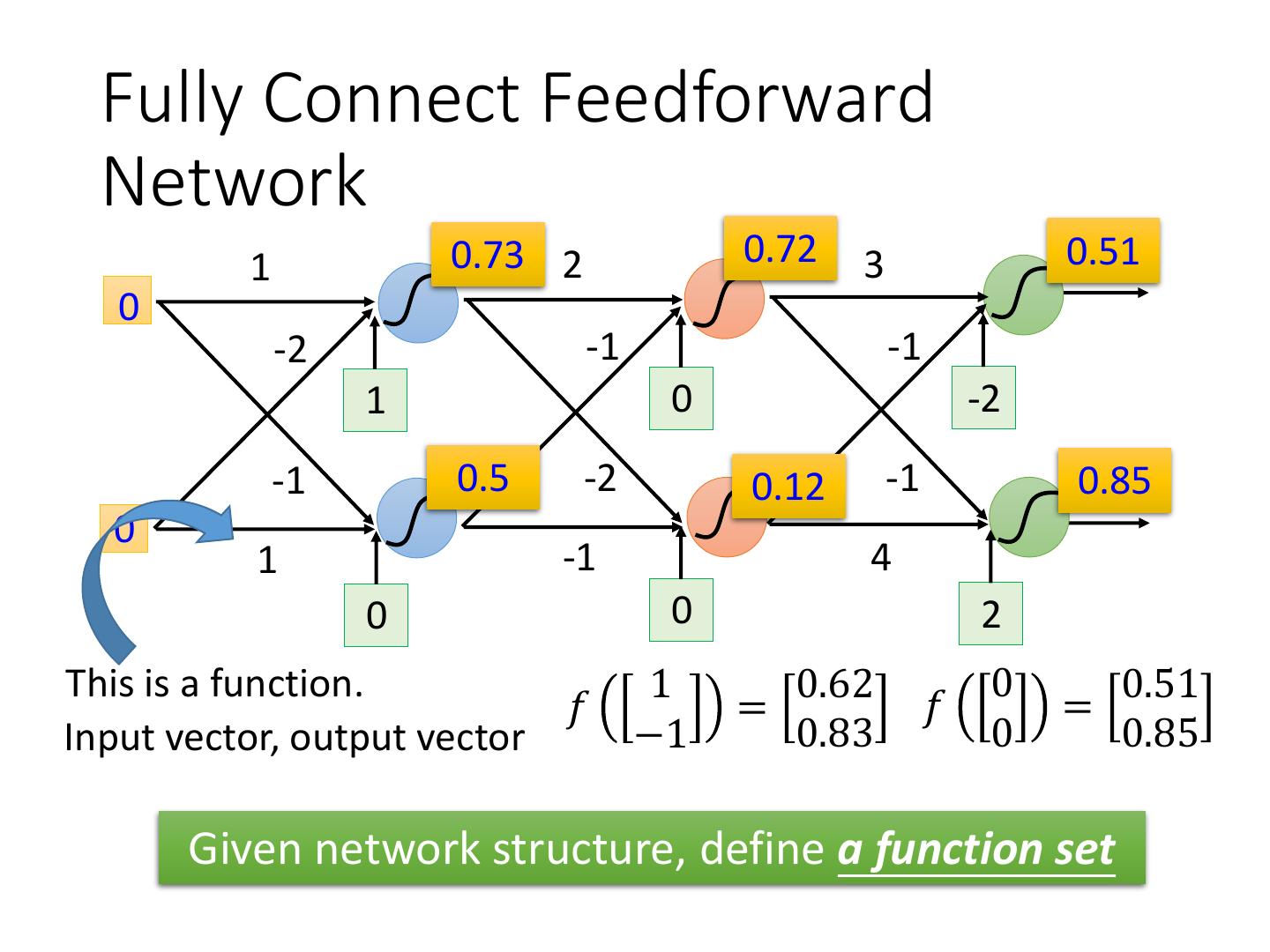
7 .Fully Connect Feedforward Network 1 4 0.98 2 0.86 3 0.62 1 -2 -1 -1 1 0 -2 -1 -2 0.12 -2 0.11 -1 0.83 -1 1 -1 4 0 0 2
8 . Fully Connect Feedforward Network 1 0.73 2 0.72 3 0.51 0 -2 -1 -1 1 0 -2 -1 0.5 -2 0.12 -1 0.85 0 1 -1 4 0 0 2 This is a function. 1 0.62 0 0.51 𝑓 = 𝑓 = Input vector, output vector −1 0.83 0 0.85 Given network structure, define a function set
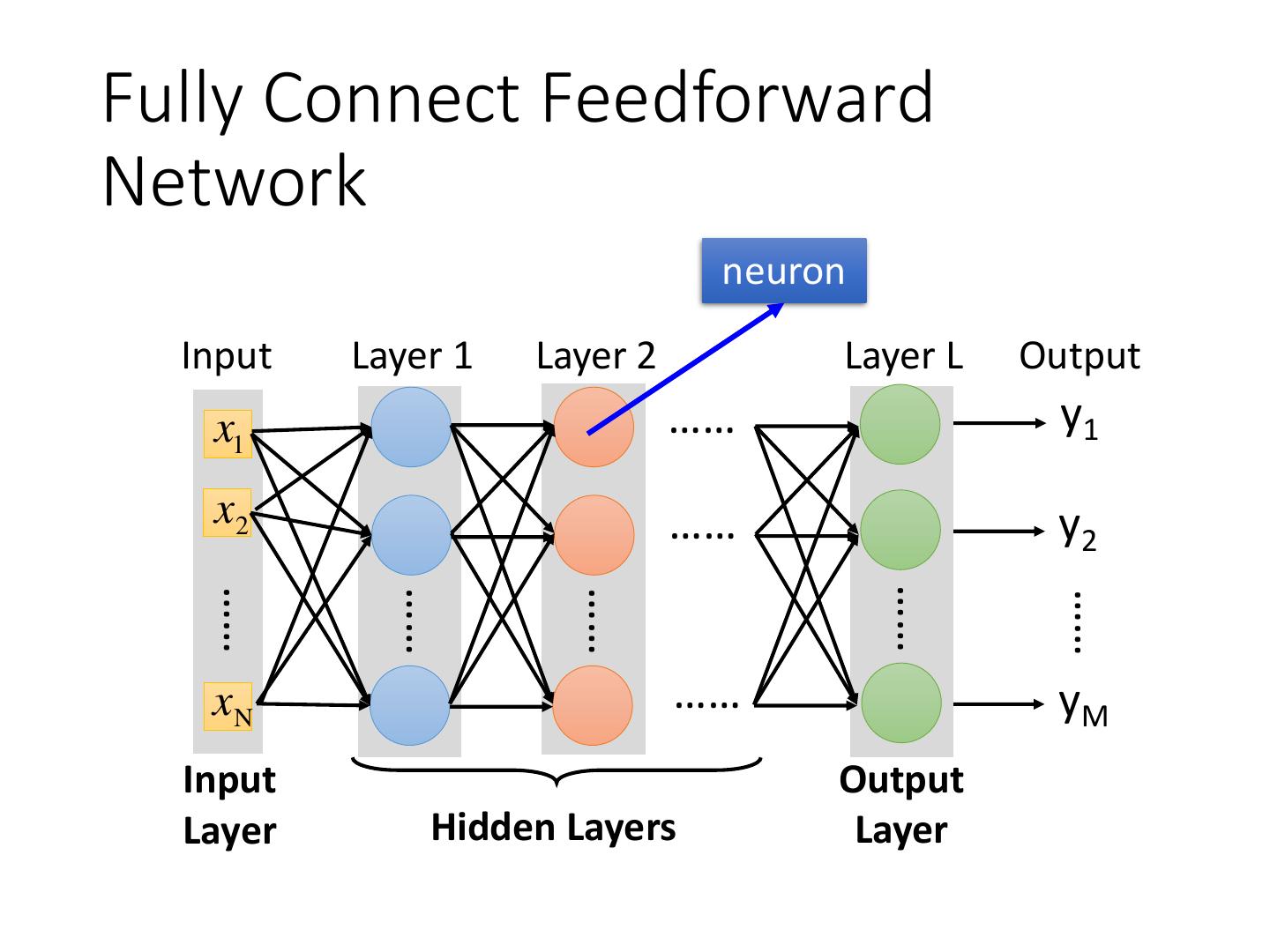
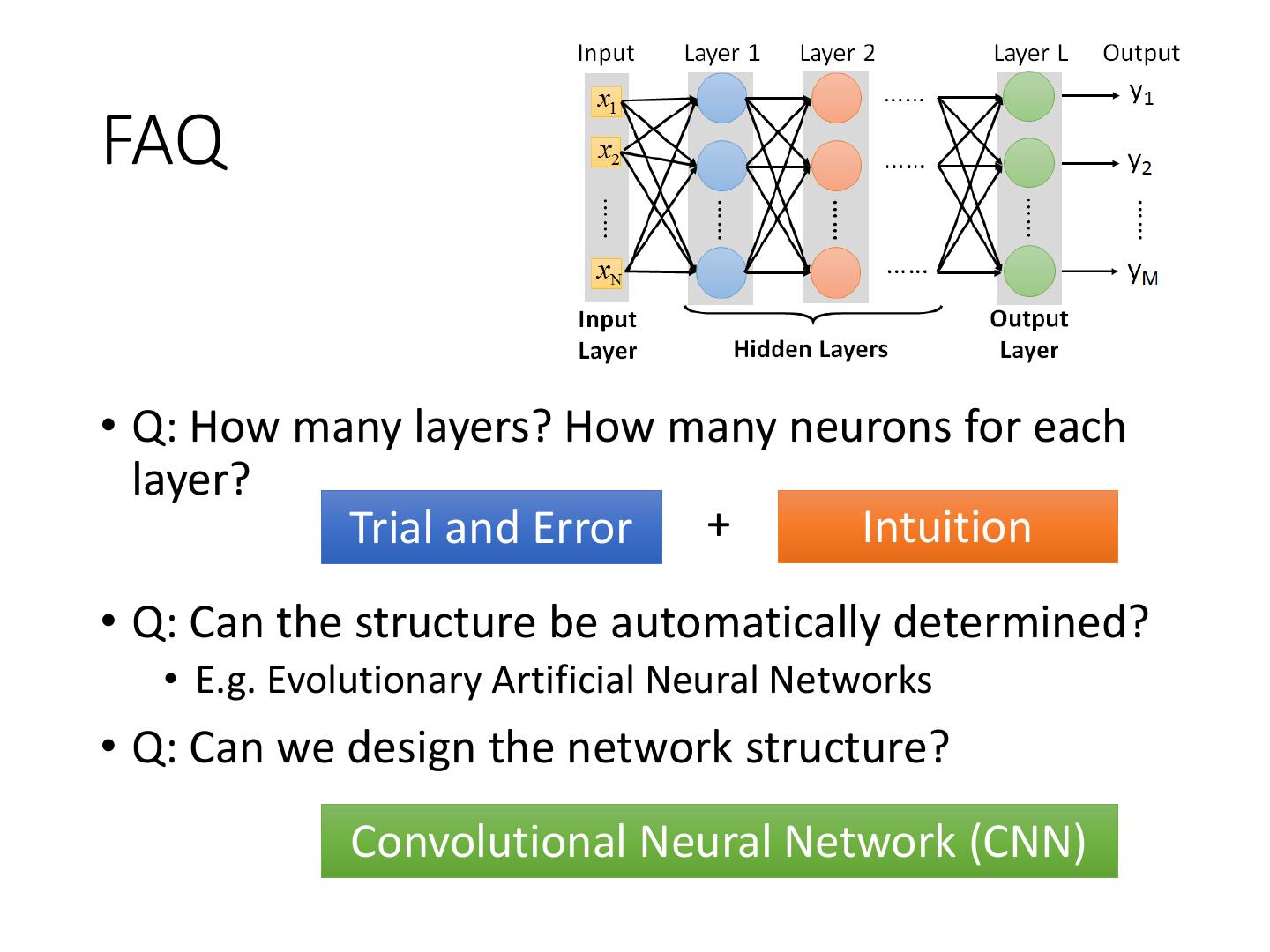
9 .Fully Connect Feedforward Network neuron Input Layer 1 Layer 2 Layer L Output x1 …… y1 x2 …… y2 …… …… …… …… …… xN …… yM Input Output Layer Hidden Layers Layer
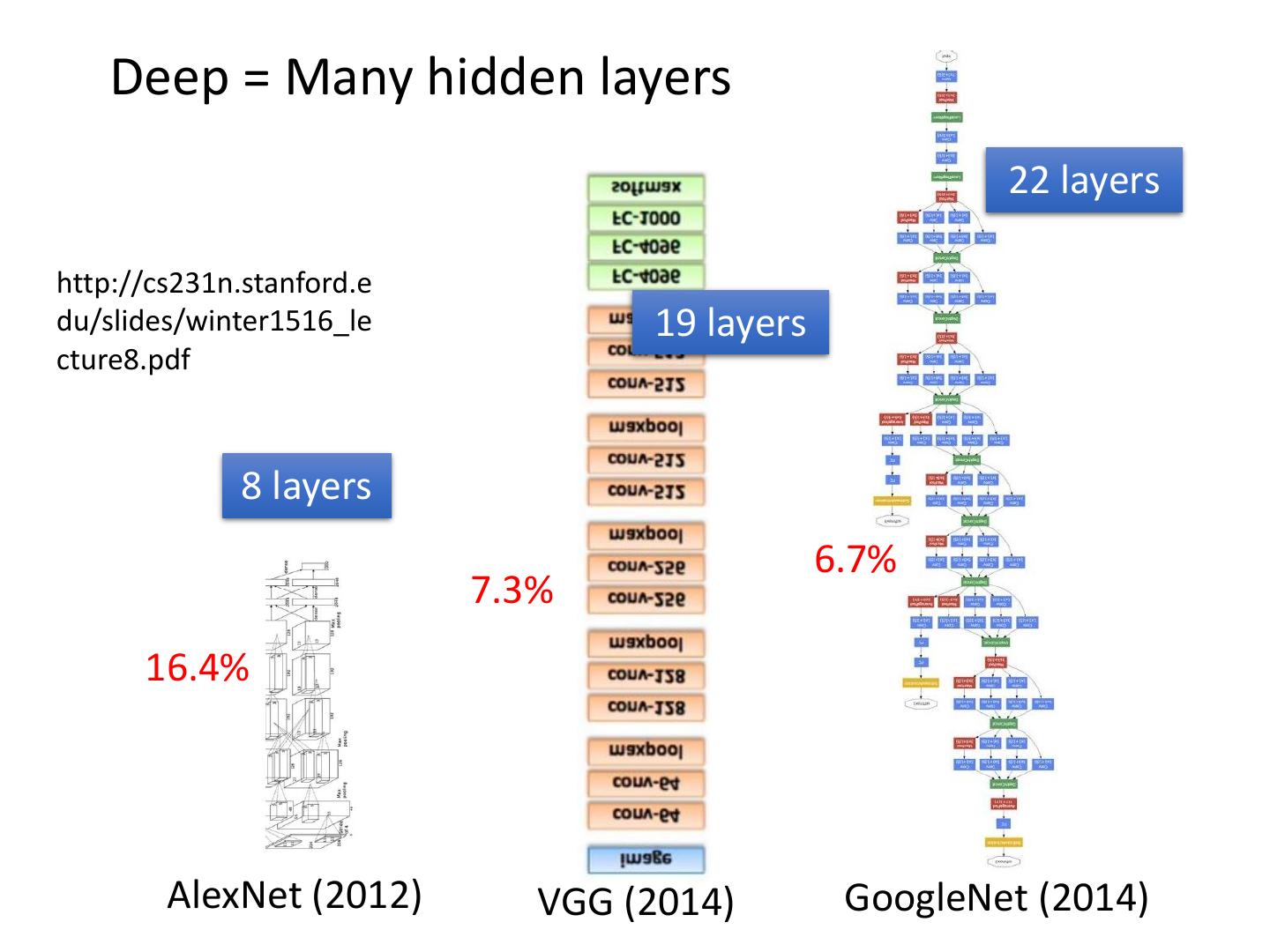
10 . Deep = Many hidden layers 22 layers http://cs231n.stanford.e du/slides/winter1516_le 19 layers cture8.pdf 8 layers 6.7% 7.3% 16.4% AlexNet (2012) VGG (2014) GoogleNet (2014)
11 . Deep = Many hidden layers 152 layers 101 layers Special structure Ref: 3.57% https://www.youtube.com/watch?v= dxB6299gpvI 7.3% 6.7% 16.4% AlexNet VGG GoogleNet Residual Net Taipei (2012) (2014) (2014) (2015) 101
12 .Matrix Operation 1 4 0.98 1 y1 -2 1 -1 -2 0.12 -1 y2 1 0 1 −2 1 1 0.98 𝜎 + = −1 1 −1 0 0.12 4 −2
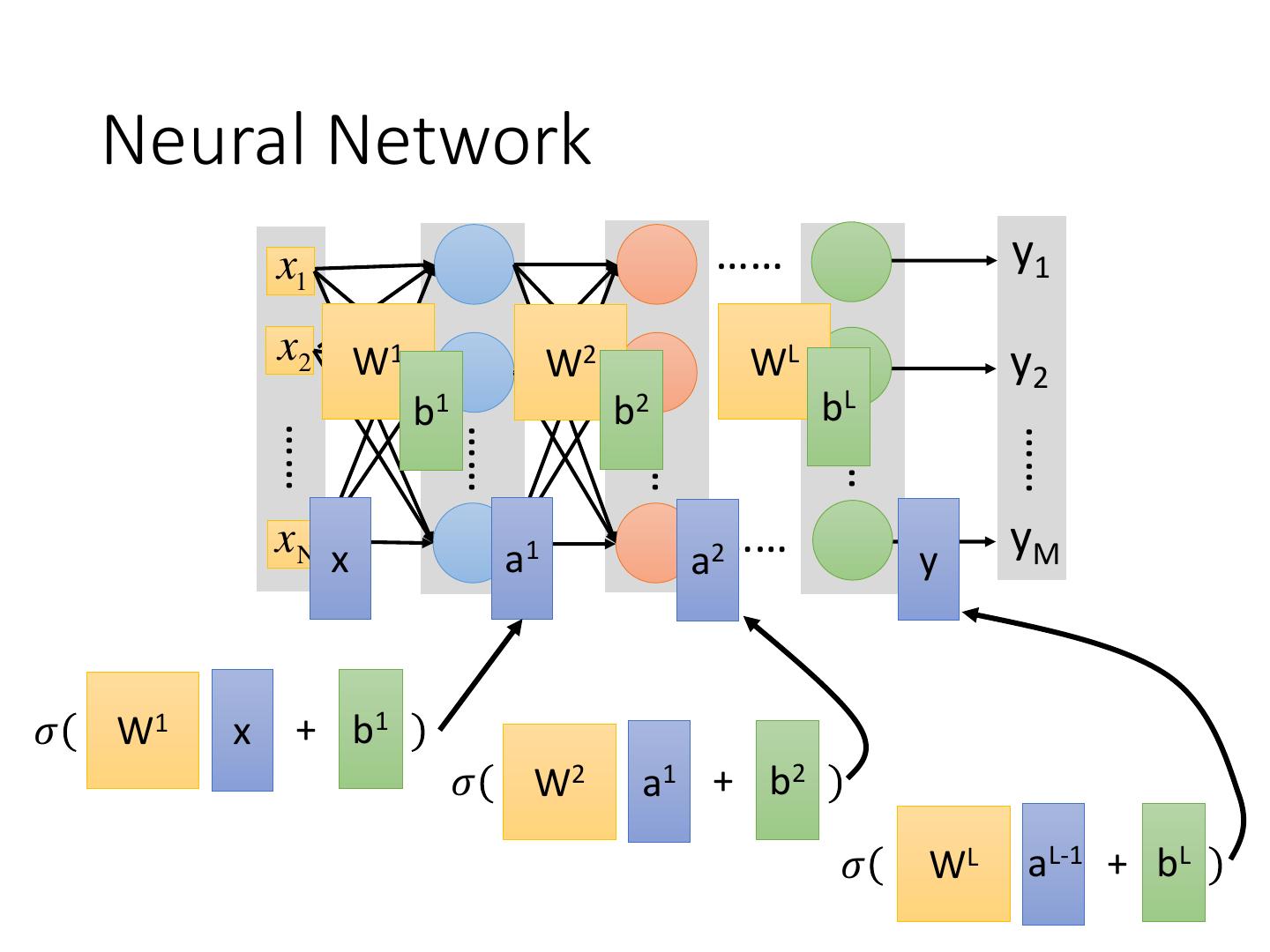
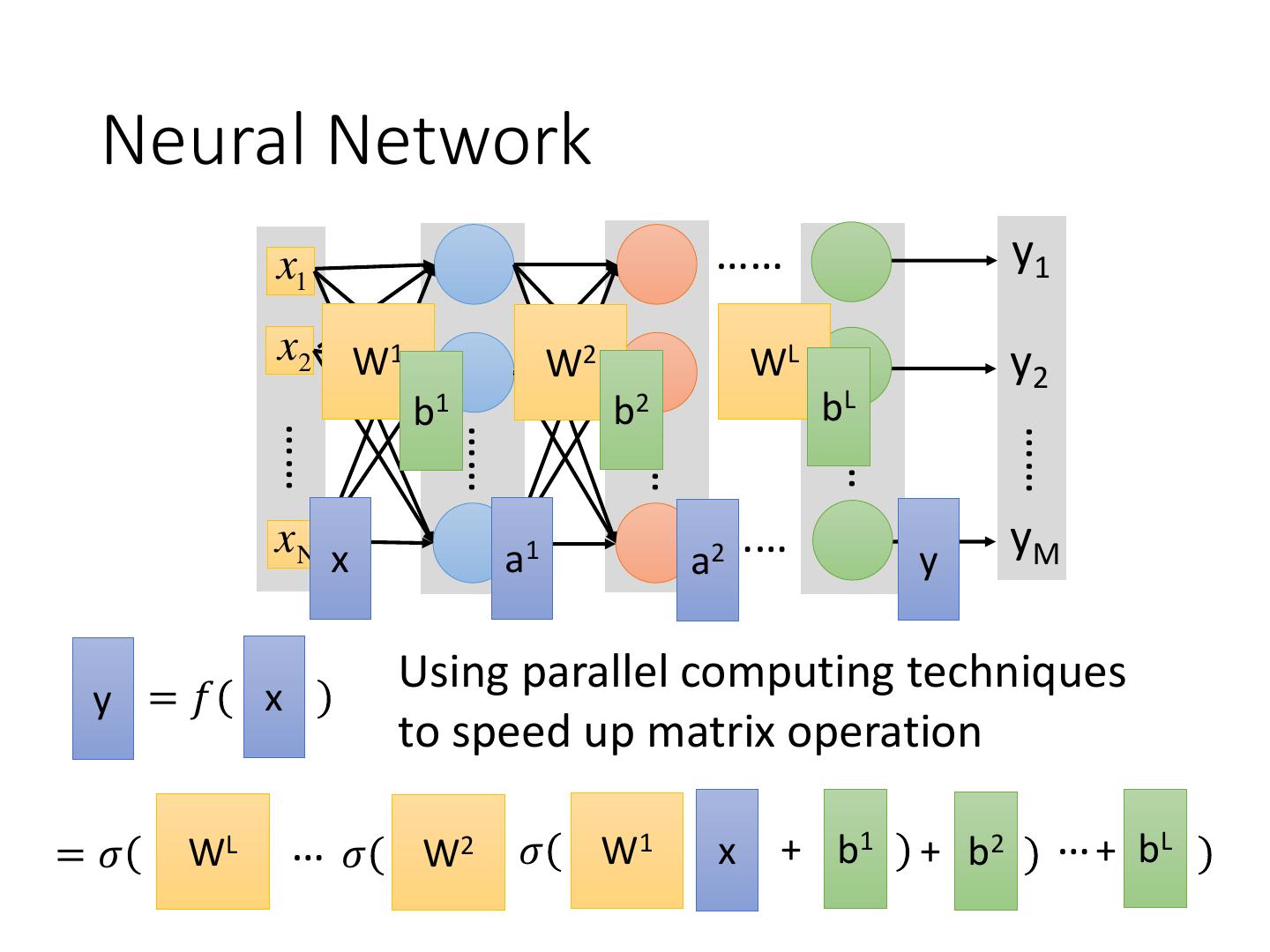
13 . Neural Network x1 …… y1 x2 W1 W2 …… WL y2 b1 b2 bL …… …… …… …… …… xN x a1 …… a2 y yM 𝜎 W1 x + b1 𝜎 W2 a1 + b2 𝜎 WL aL-1 + bL
14 . Neural Network x1 …… y1 x2 W1 W2 …… WL y2 b1 b2 bL …… …… …… …… …… xN x a1 …… a2 y yM Using parallel computing techniques y =𝑓 x to speed up matrix operation =𝜎 WL …𝜎 W2 𝜎 W1 x + b1 + b2 … + bL
15 .Output Layer as Multi-Class Classifier Feature extractor replacing feature engineering x1 y1 …… x2 Softmax …… y2 x …… …… …… …… …… xK …… yM Input Output = Multi-class Layer Hidden Layers Layer Classifier
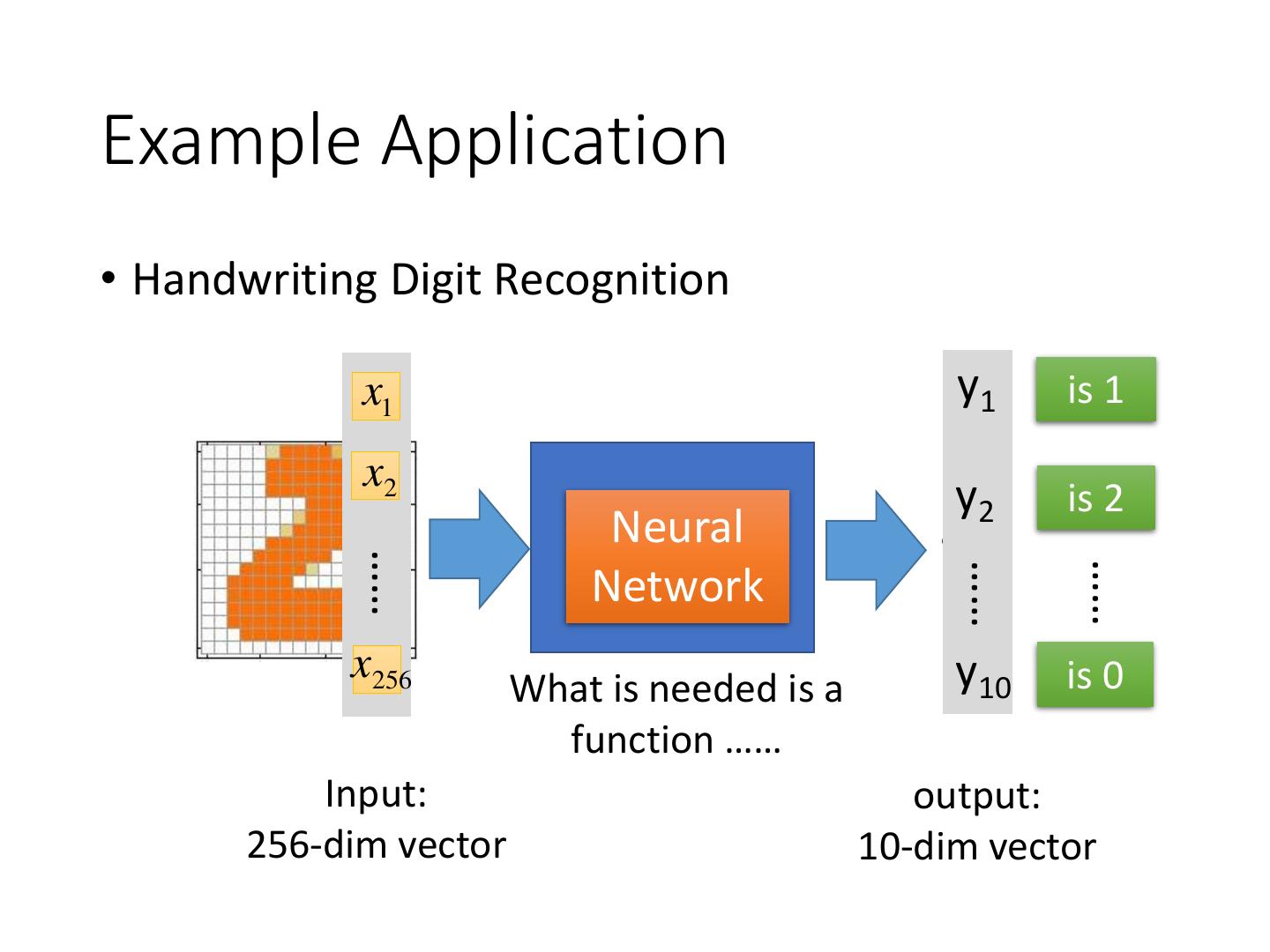
16 .Example Application Input Output y1 0.1 is 1 x1 x2 y2 0.7 is 2 The image is “2” …… …… …… x256 y10 0.2 is 0 16 x 16 = 256 Ink → 1 Each dimension represents No ink → 0 the confidence of a digit.
17 .Example Application • Handwriting Digit Recognition x1 y1 is 1 x2 y2 is 2 Neural Machine “2” …… …… …… Network x256 y10 is 0 What is needed is a function …… Input: output: 256-dim vector 10-dim vector
18 .Example Application Input Layer 1 Layer 2 Layer L Output x1 …… y1 is 1 x2 …… A function set containing the y2 is 2 candidates for “2” …… …… …… …… …… …… Handwriting Digit Recognition xN …… y10 is 0 Input Output Layer Hidden Layers Layer You need to decide the network structure to let a good function in your function set.
19 .FAQ • Q: How many layers? How many neurons for each layer? Trial and Error + Intuition • Q: Can the structure be automatically determined? • E.g. Evolutionary Artificial Neural Networks • Q: Can we design the network structure? Convolutional Neural Network (CNN)
20 .Three Steps for Deep Learning Step 1: Step 2: Step 3: pick define a set Neural goodness of the best ofNetwork function function function Deep Learning is so simple ……
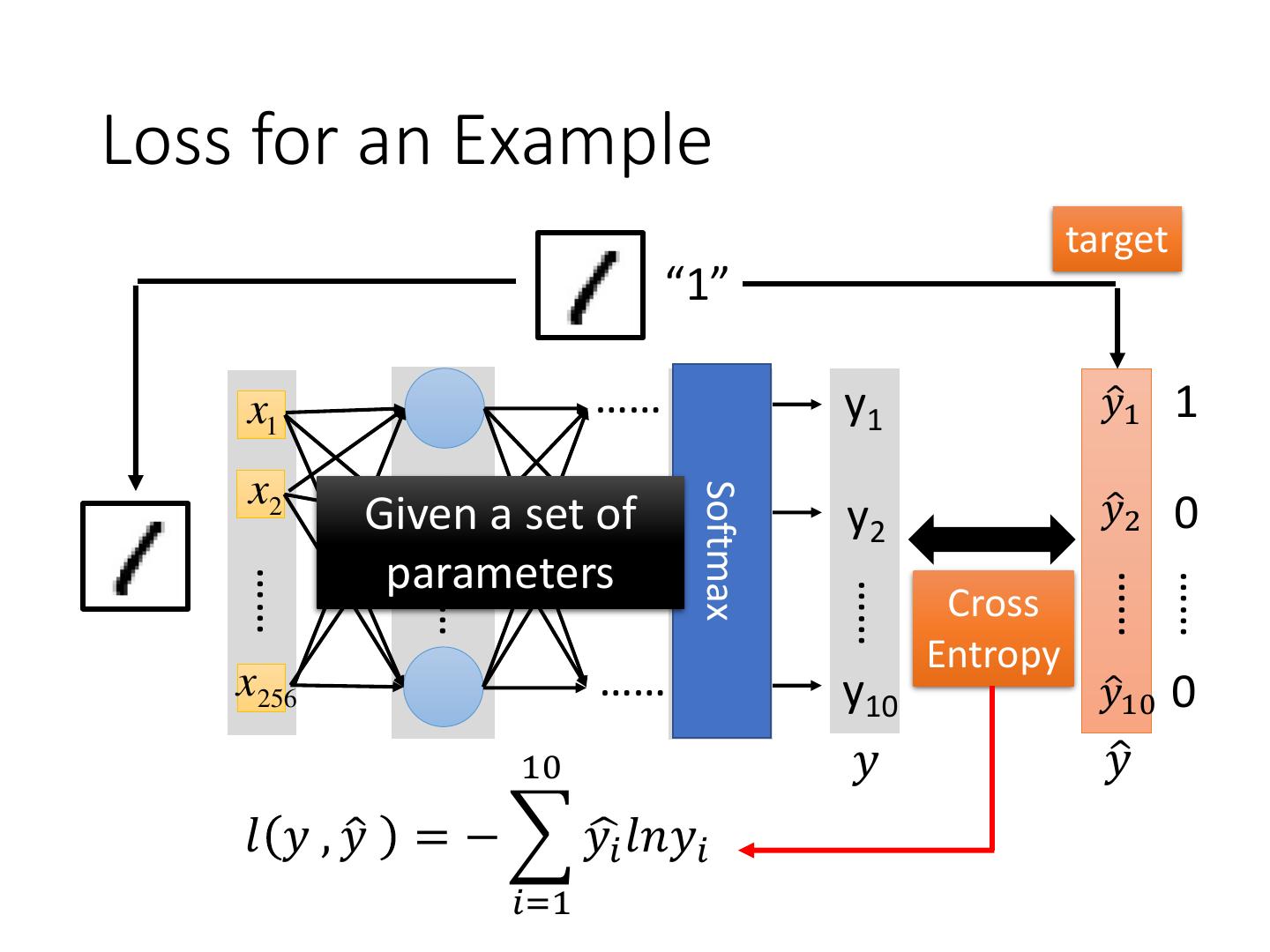
21 .Loss for an Example target “1” x1 …… y1 𝑦ො1 1 x2 Softmax …… Given a set of y2 𝑦ො2 0 parameters …… …… …… …… …… …… Cross Entropy x256 …… y10 𝑦ො10 0 10 𝑦 𝑦ො 𝑙 𝑦 , 𝑦ො = − 𝑦ෝ𝑖 𝑙𝑛𝑦𝑖 𝑖=1
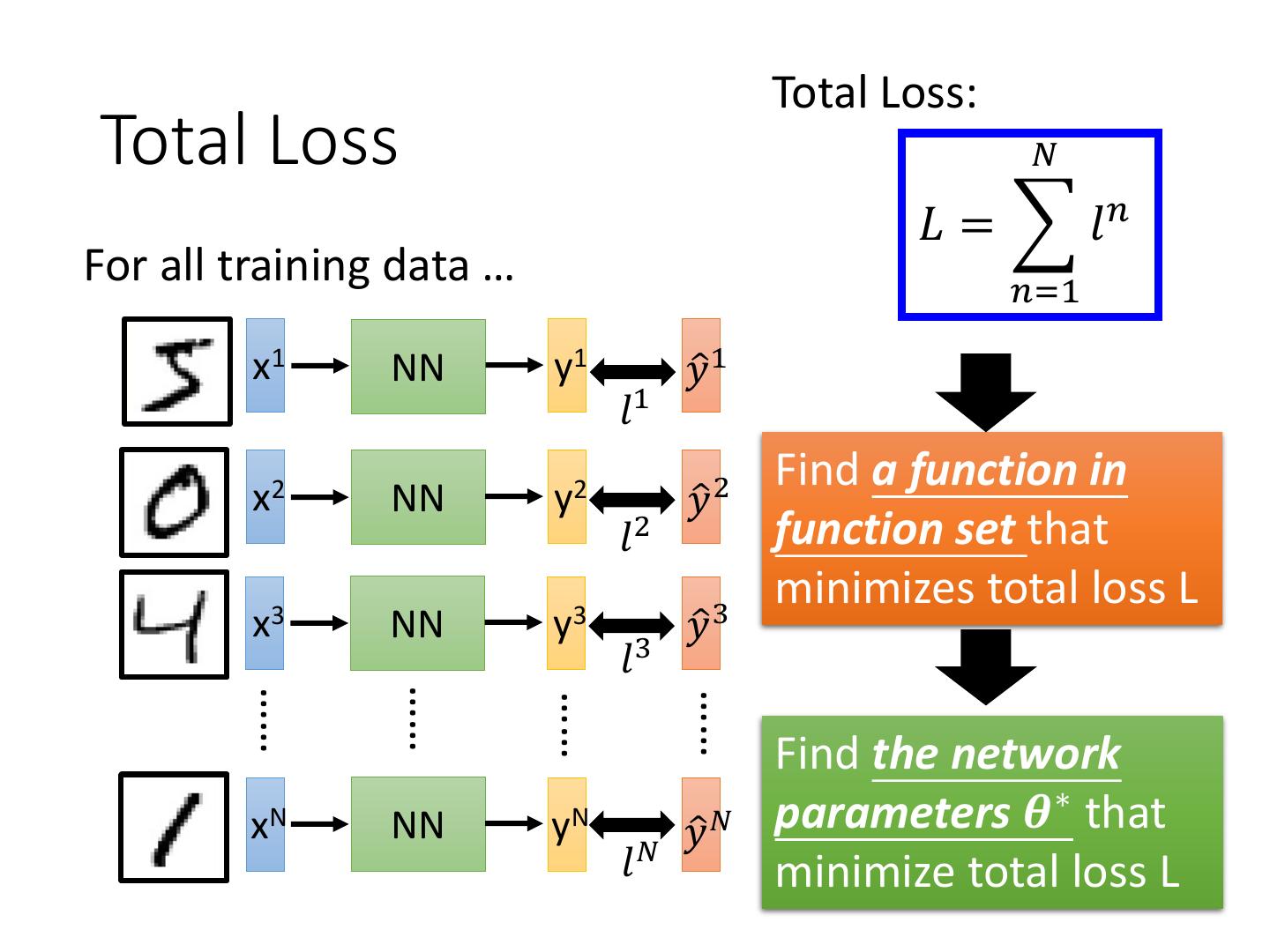
22 . Total Loss: Total Loss 𝑁 𝐿 = 𝑙𝑛 For all training data … 𝑛=1 x1 NN y1 𝑦ො 1 𝑙1 Find a function in x2 NN y2 𝑦ො 2 𝑙2 function set that minimizes total loss L x3 NN y3 𝑦ො 3 𝑙3 …… …… …… …… Find the network xN NN yN 𝑦ො 𝑁 parameters 𝜽∗ that 𝑙𝑁 minimize total loss L
23 .Three Steps for Deep Learning Step 1: Step 2: Step 3: pick define a set Neural goodness of the best ofNetwork function function function Deep Learning is so simple ……
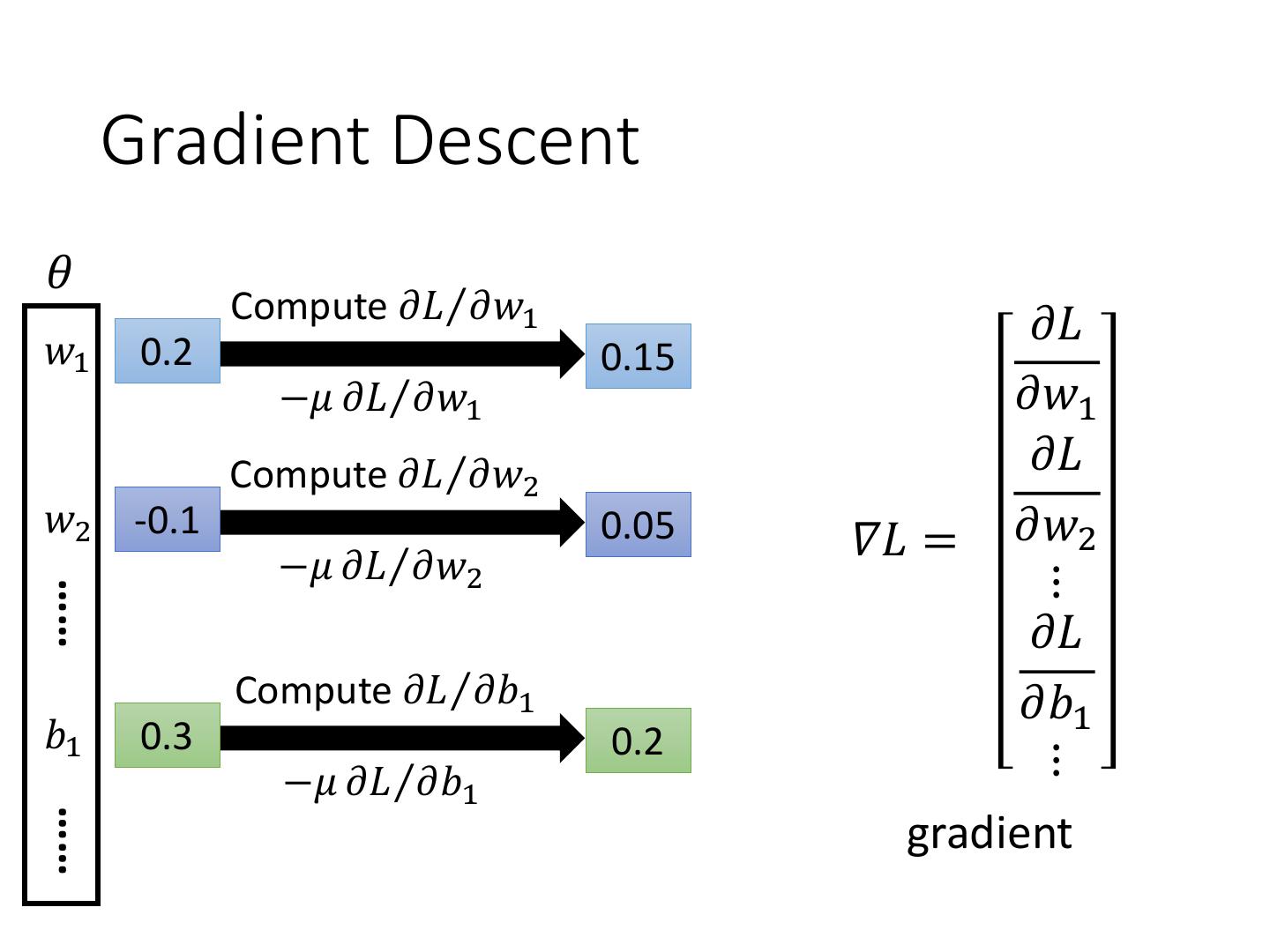
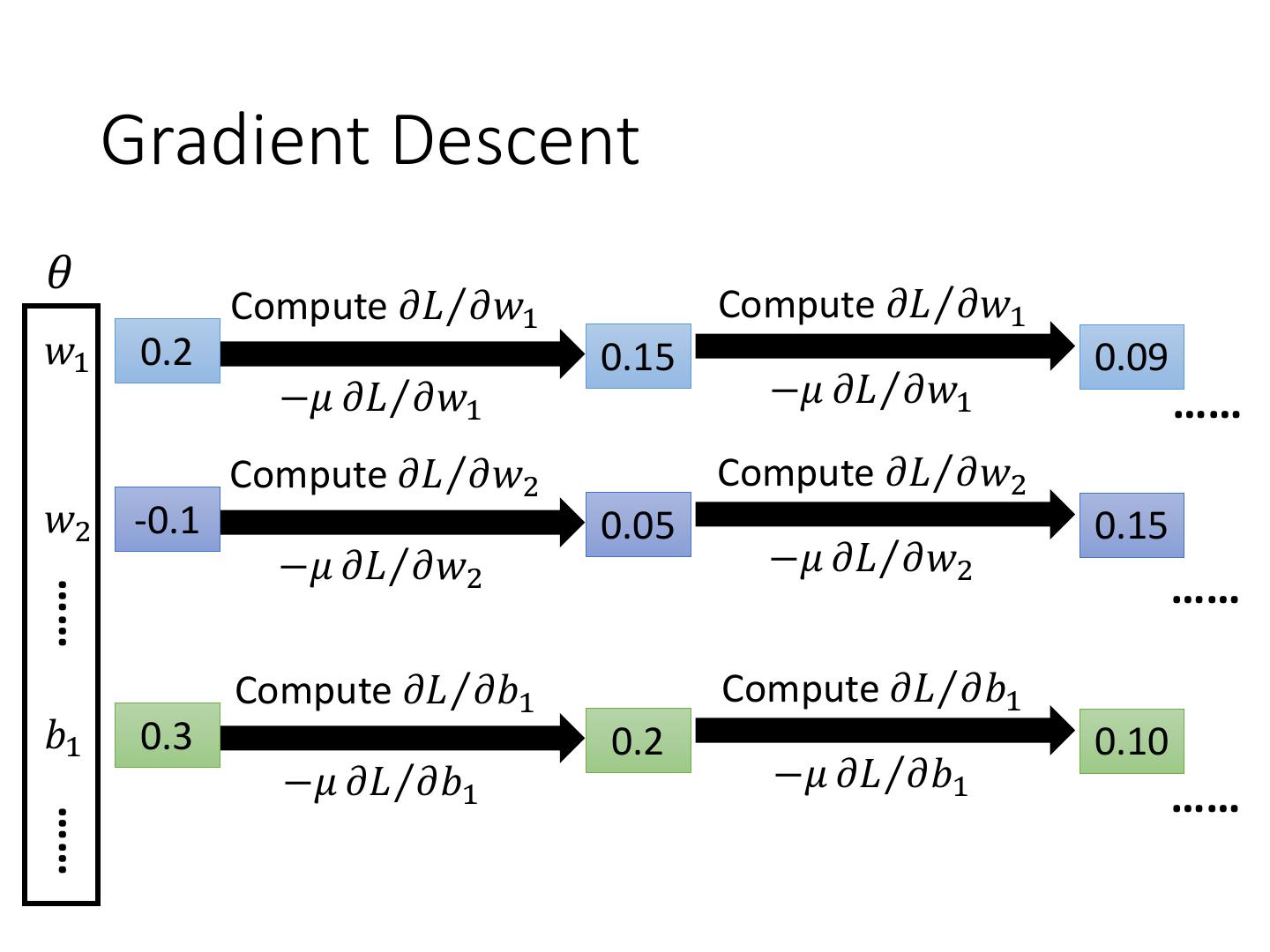
24 . Gradient Descent 𝜃 Compute 𝜕𝐿Τ𝜕𝑤1 𝜕𝐿 𝑤1 0.2 0.15 −𝜇 𝜕𝐿Τ𝜕𝑤1 𝜕𝑤1 Compute 𝜕𝐿Τ𝜕𝑤2 𝜕𝐿 𝑤2 -0.1 −𝜇 𝜕𝐿Τ𝜕𝑤2 0.05 𝛻𝐿 = 𝜕𝑤2 ⋮ …… 𝜕𝐿 Compute 𝜕𝐿Τ𝜕𝑏1 𝜕𝑏1 𝑏1 0.3 0.2 −𝜇 𝜕𝐿Τ𝜕𝑏1 ⋮ …… gradient
25 . Gradient Descent 𝜃 Compute 𝜕𝐿Τ𝜕𝑤1 Compute 𝜕𝐿Τ𝜕𝑤1 𝑤1 0.2 0.15 0.09 −𝜇 𝜕𝐿Τ𝜕𝑤1 −𝜇 𝜕𝐿Τ𝜕𝑤1 …… Compute 𝜕𝐿Τ𝜕𝑤2 Compute 𝜕𝐿Τ𝜕𝑤2 𝑤2 -0.1 0.05 0.15 −𝜇 𝜕𝐿Τ𝜕𝑤2 −𝜇 𝜕𝐿Τ𝜕𝑤2 …… …… Compute 𝜕𝐿Τ𝜕𝑏1 Compute 𝜕𝐿Τ𝜕𝑏1 𝑏1 0.3 0.2 0.10 −𝜇 𝜕𝐿Τ𝜕𝑏1 −𝜇 𝜕𝐿Τ𝜕𝑏1 …… ……
26 .Gradient Descent This is the “learning” of machines in deep learning …… Even alpha go using this approach. People image …… Actually ….. I hope you are not too disappointed :p
27 .Backpropagation • Backpropagation: an efficient way to compute 𝜕𝐿Τ𝜕𝑤 in neural network libdnn 台大周伯威 同學開發 Ref: http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/DNN%20b ackprop.ecm.mp4/index.html
28 .Three Steps for Deep Learning Step 1: Step 2: Step 3: pick define a set Neural goodness of the best ofNetwork function function function Deep Learning is so simple ……
29 .Acknowledgment • 感謝 Victor Chen 發現投影片上的打字錯誤
3秒后跳转登录页面
去登陆

