










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u3805/Keras87833?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
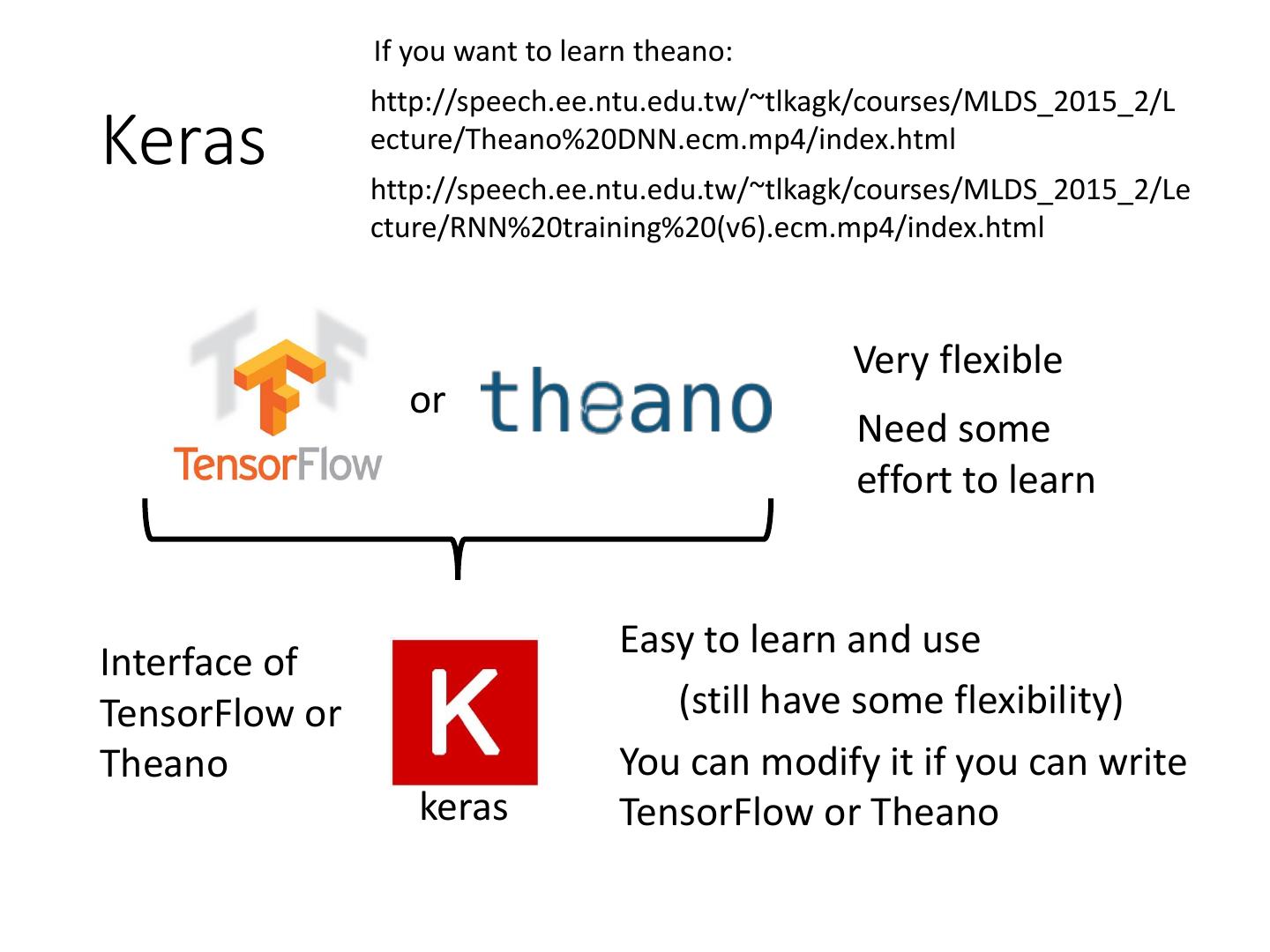
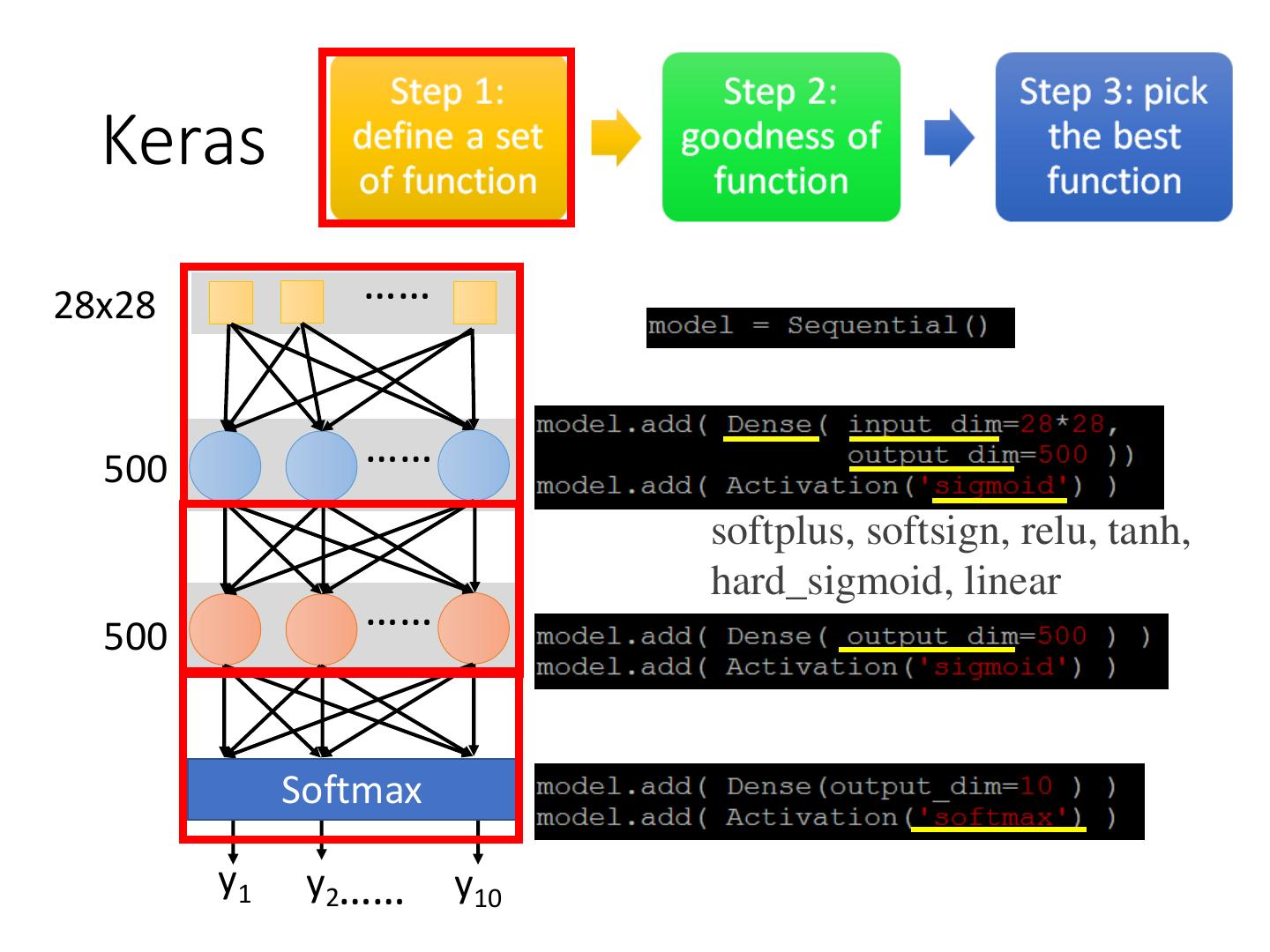
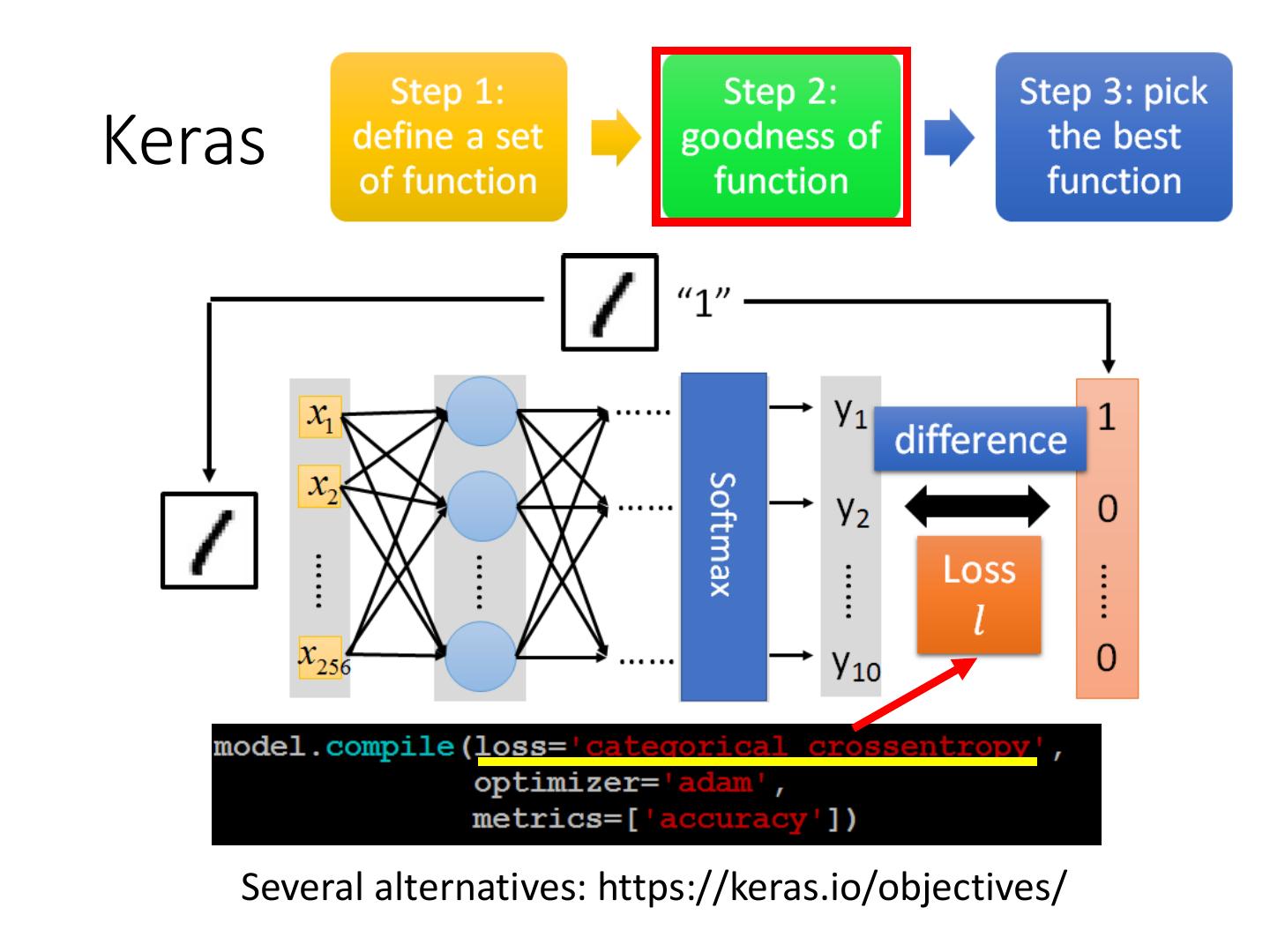
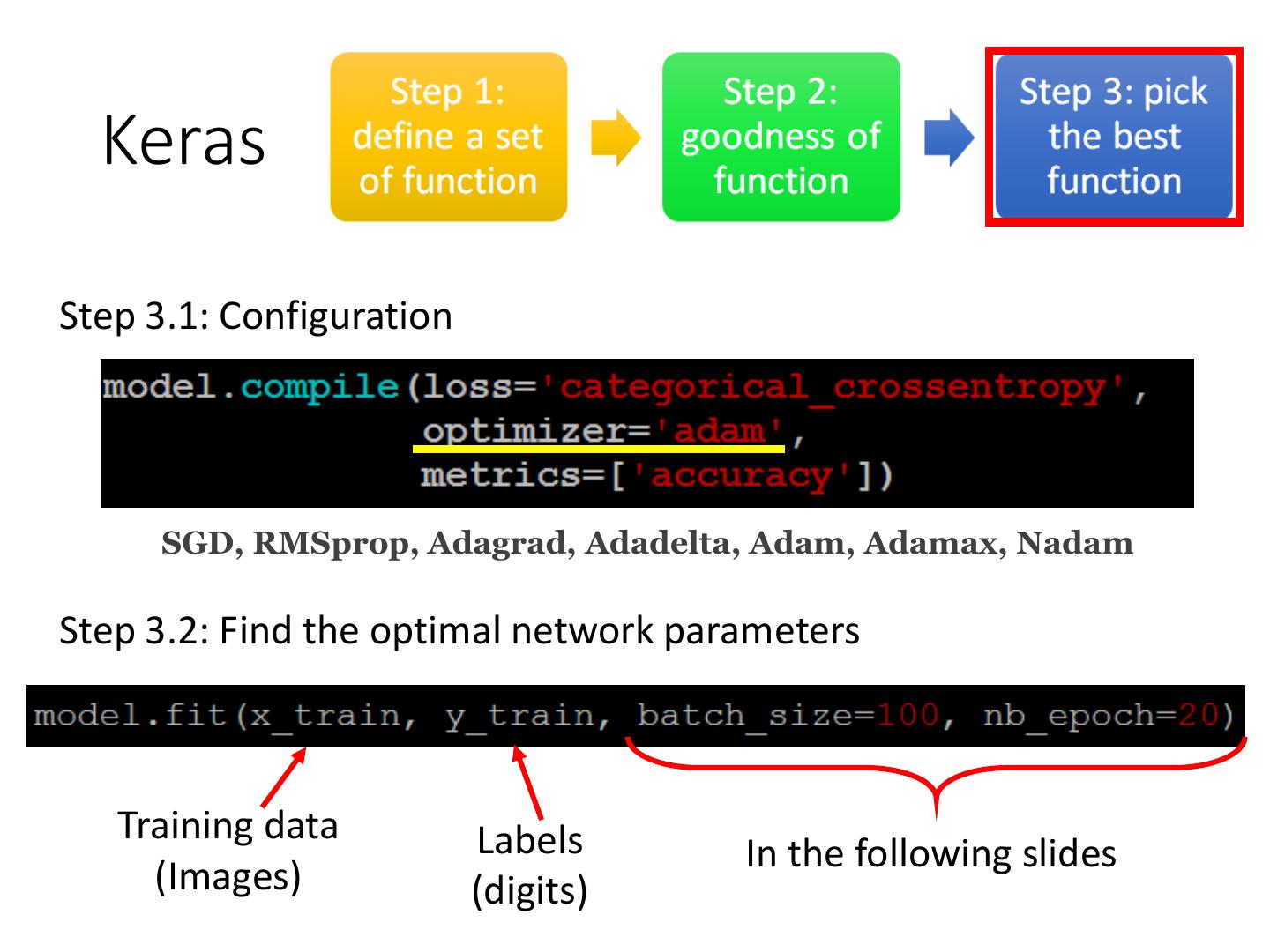
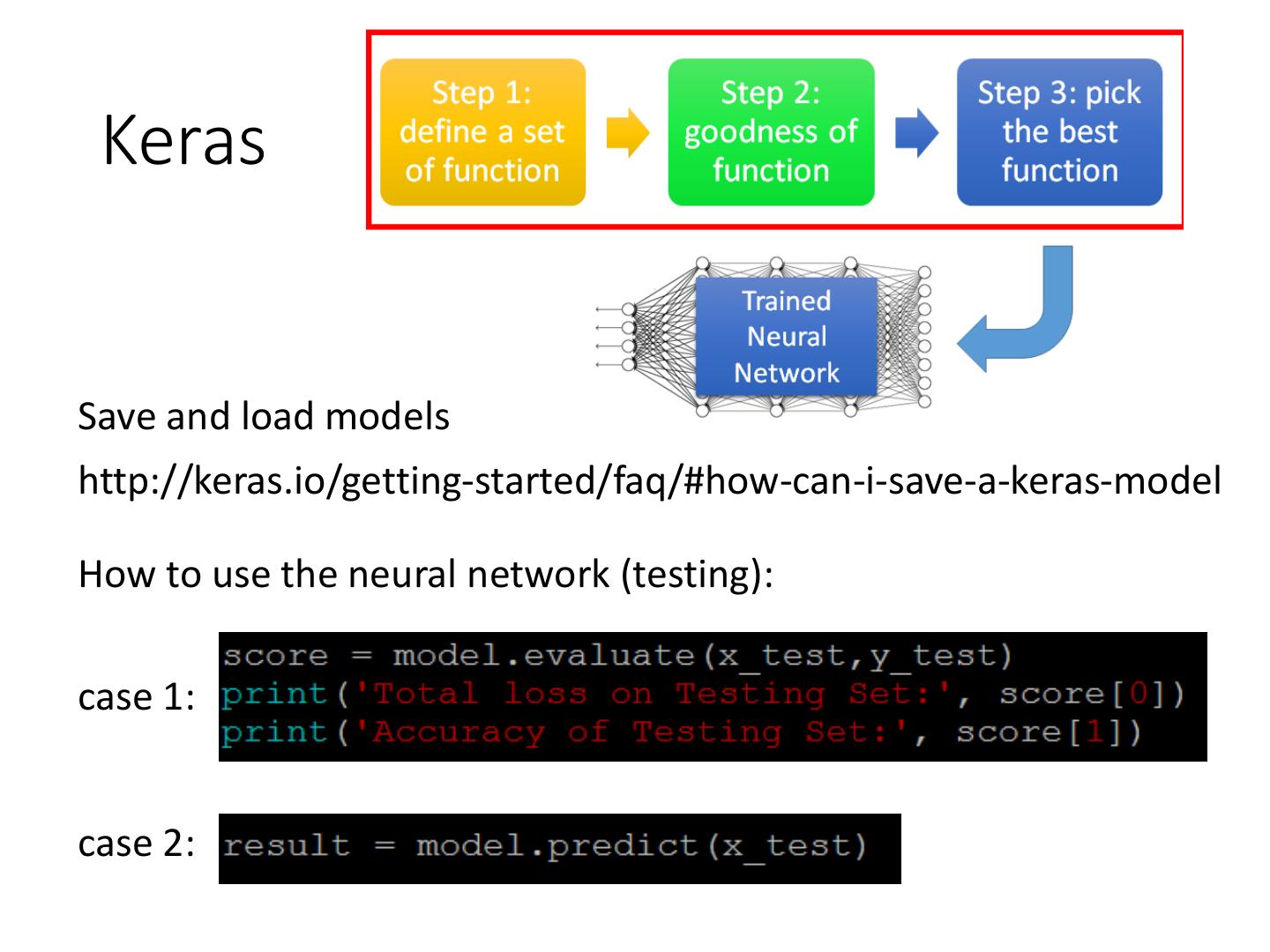
Keras
点赞
3
收藏
1
下载 0
Keras
• François Chollet is the author of Keras.
• He currently works for Google as a deep learning engineer and researcher.
• Keras means horn in Greek
• Documentation: http://keras.io/
• Example:
https://github.com/fchollet/keras/tree/master/examples
相关推荐

基于SeaTunnel快速集成SAP进入Redshift
SeaTunnel

联通数科基于Apache Dolphinscheduler构建Dataops一体化能力
DolphinScheduler社区

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

