展开查看详情
14 .ML/DL for Everyone with Lecture 9: Softmax Classifier Sung Kim < hunkim+ml@gmail.com > HKUST Code: https://github.com/hunkim/PyTorchZeroToAll Slides: http://bit.ly/PyTorchZeroAll Videos: http://bit.ly/PyTorchVideo
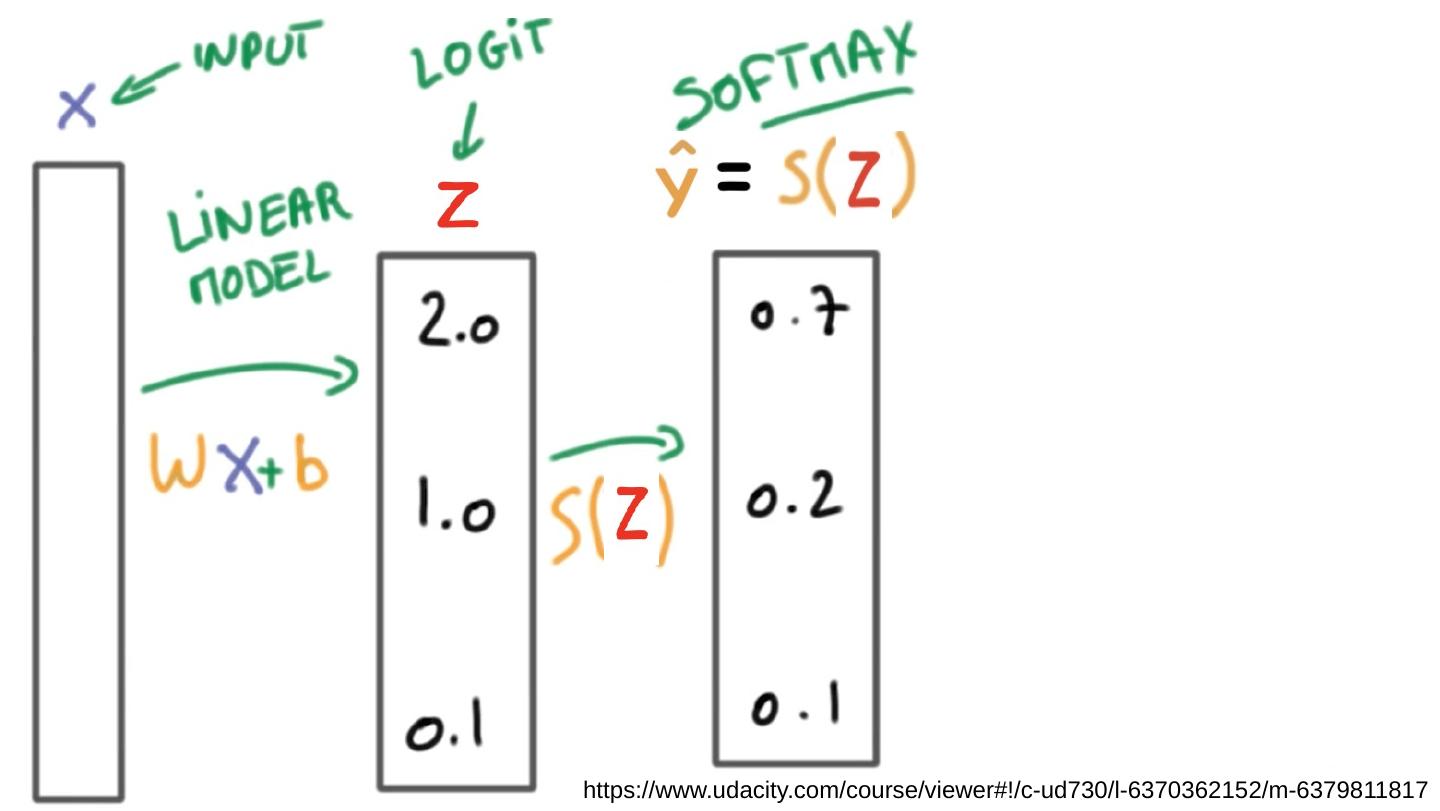
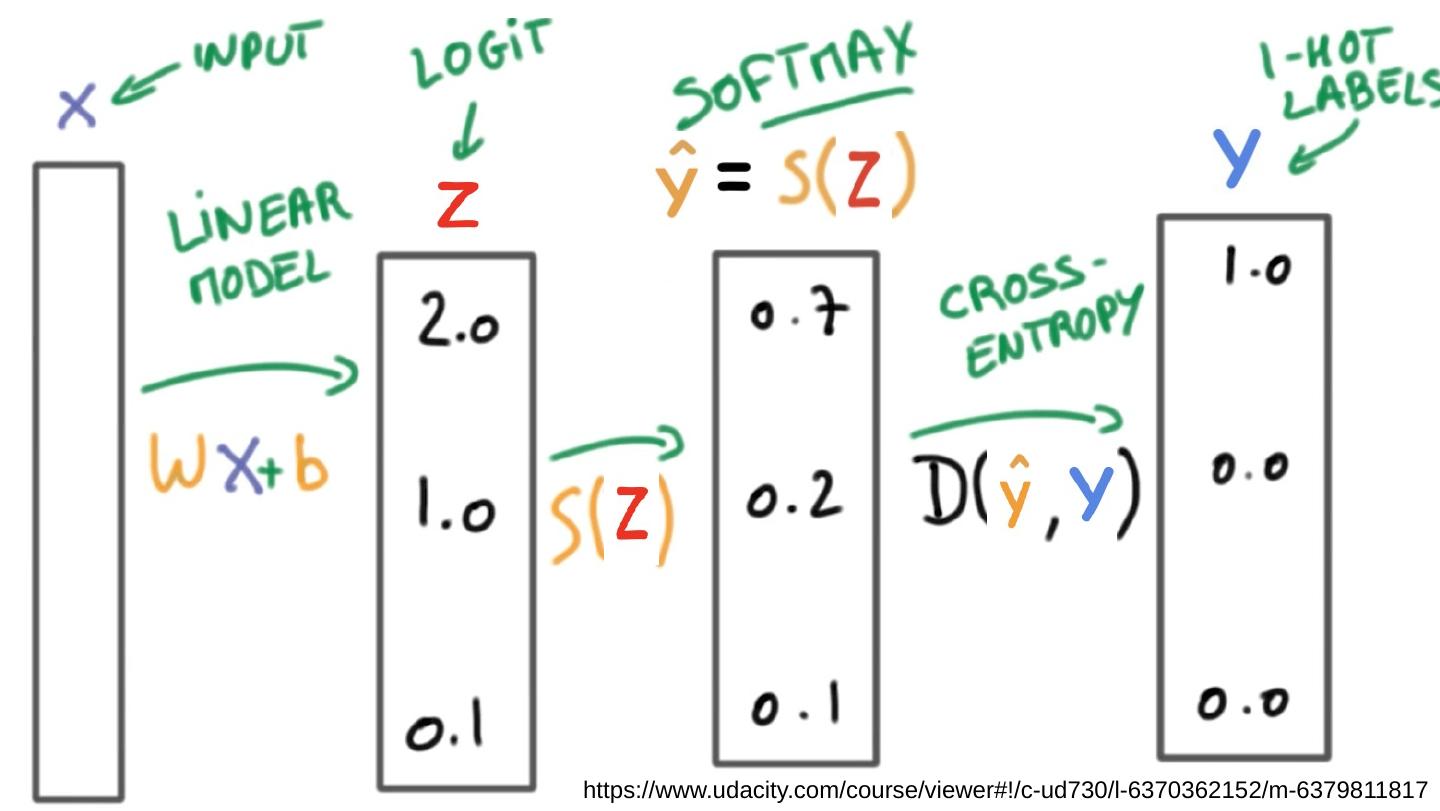
15 .Cost function: cross entropy https://www.udacity.com/course/viewer#!/c-ud730/l-6370362152/m-6379811817
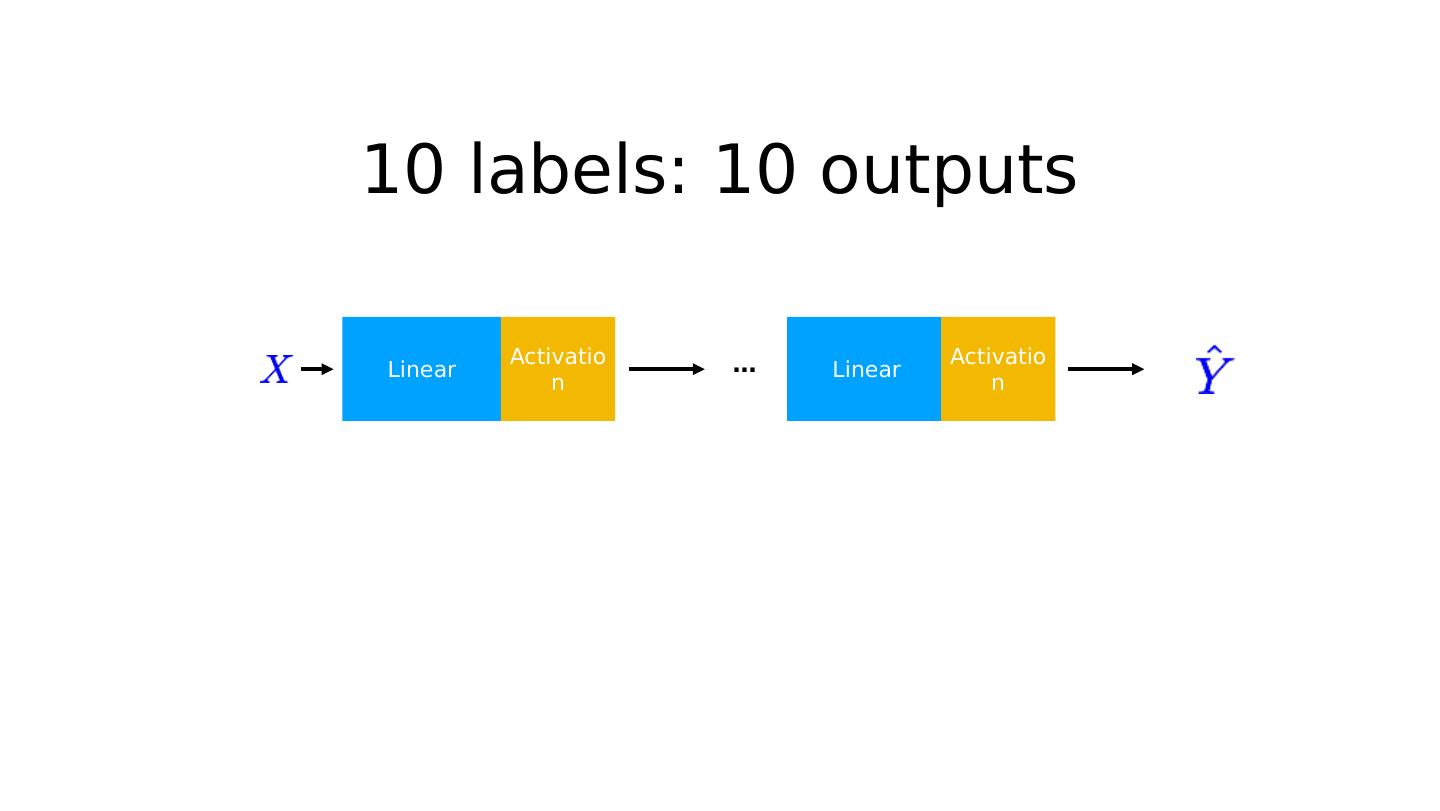
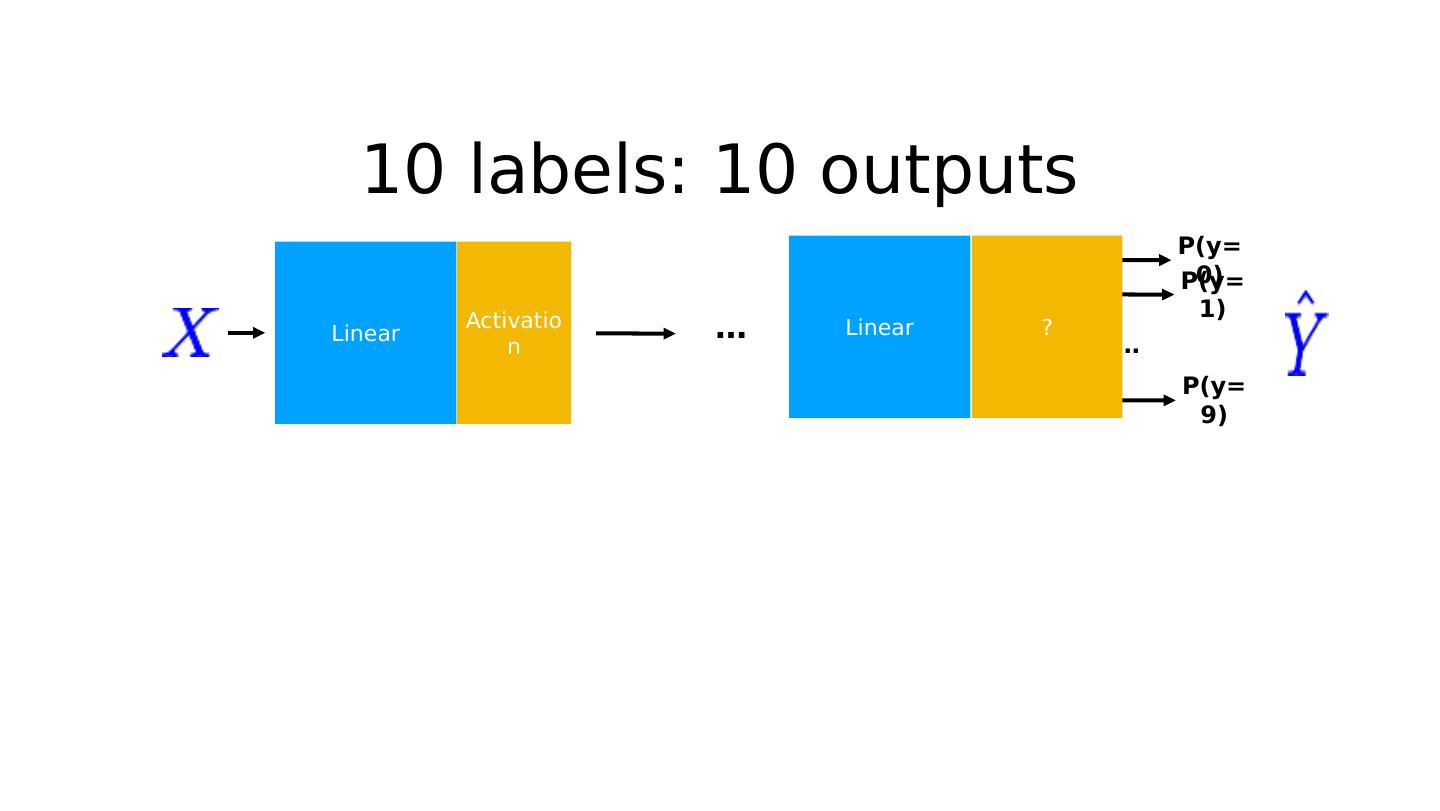
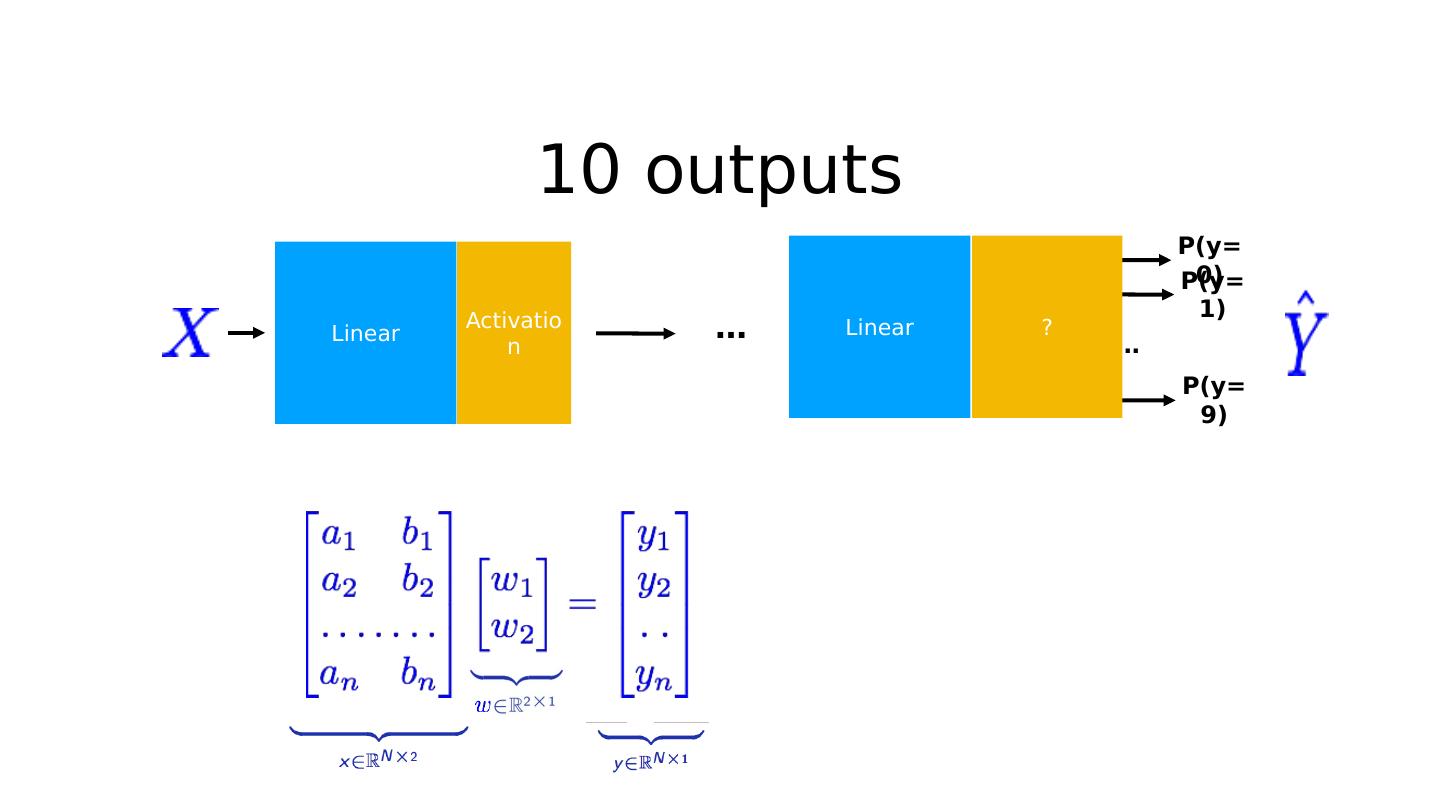
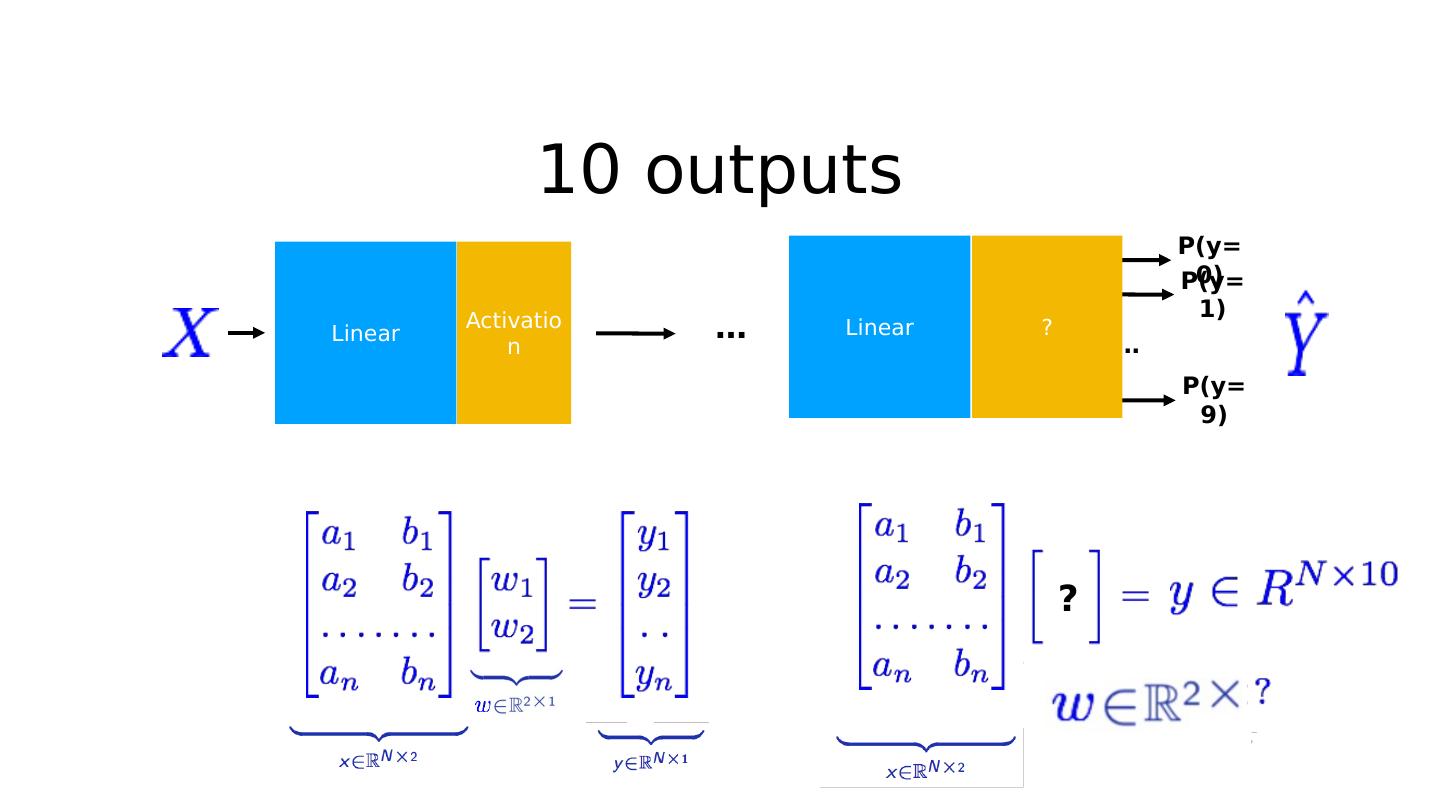
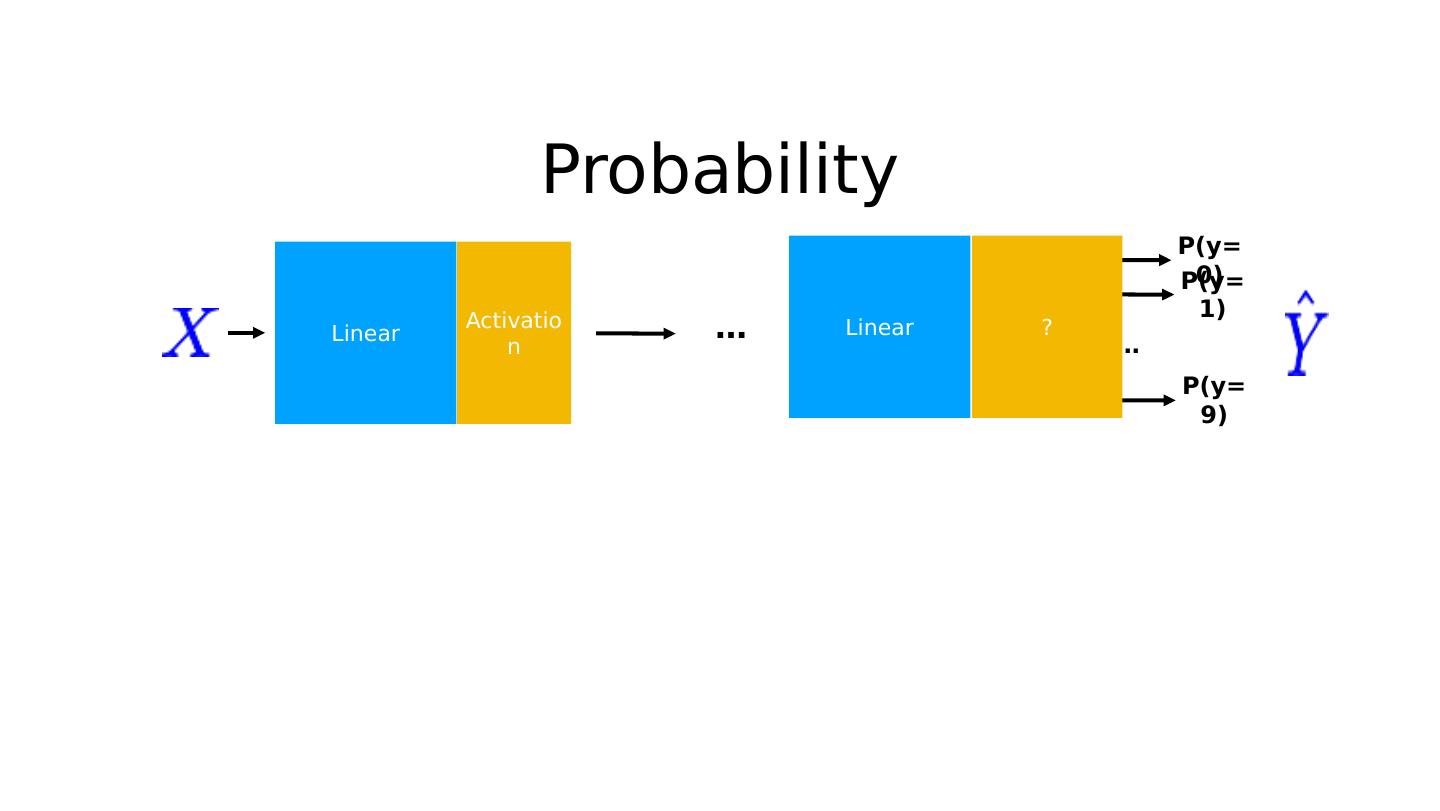
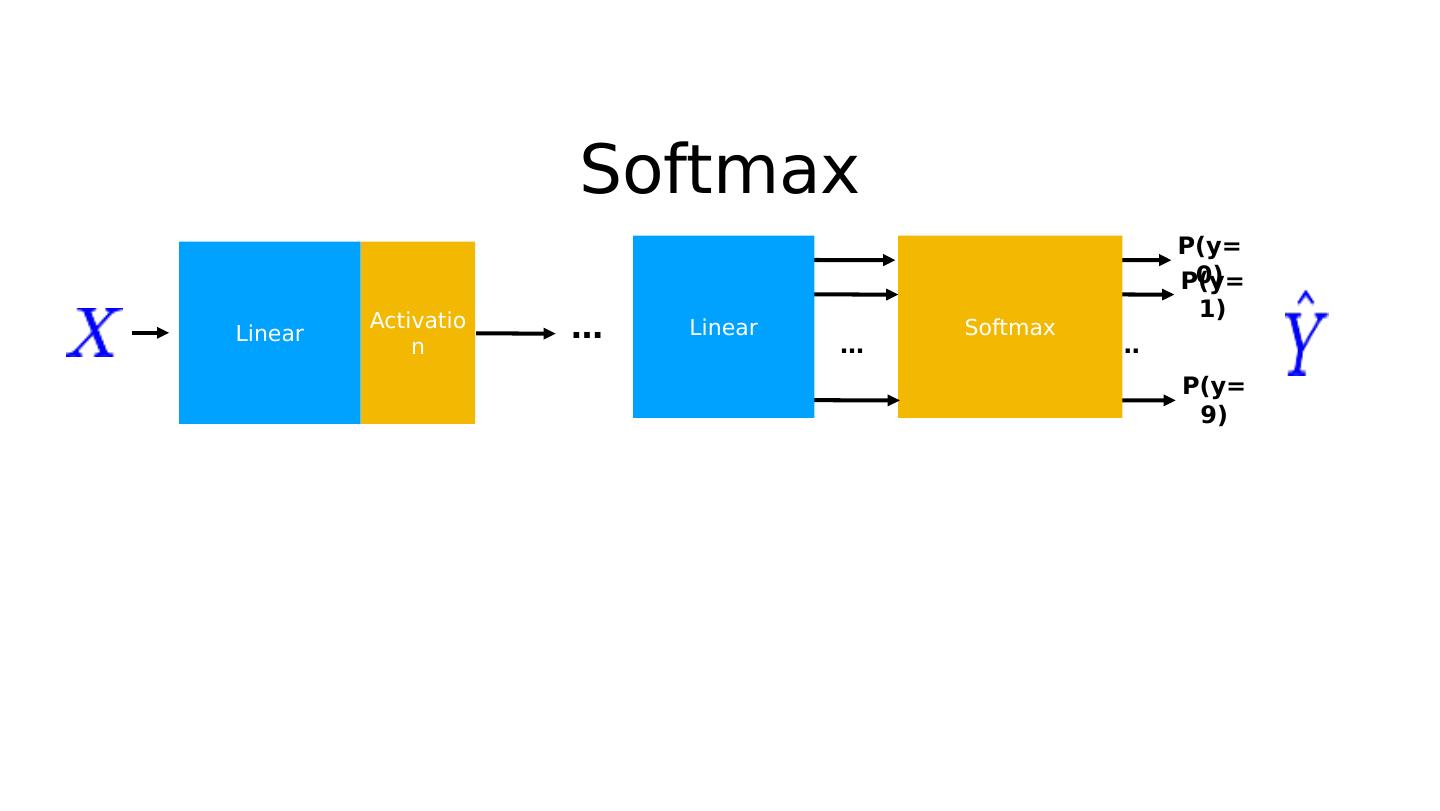
16 .10 labels: 10 outputs Linear P(y=0) P(y=1) P(y=9) … ? Linear Activation …
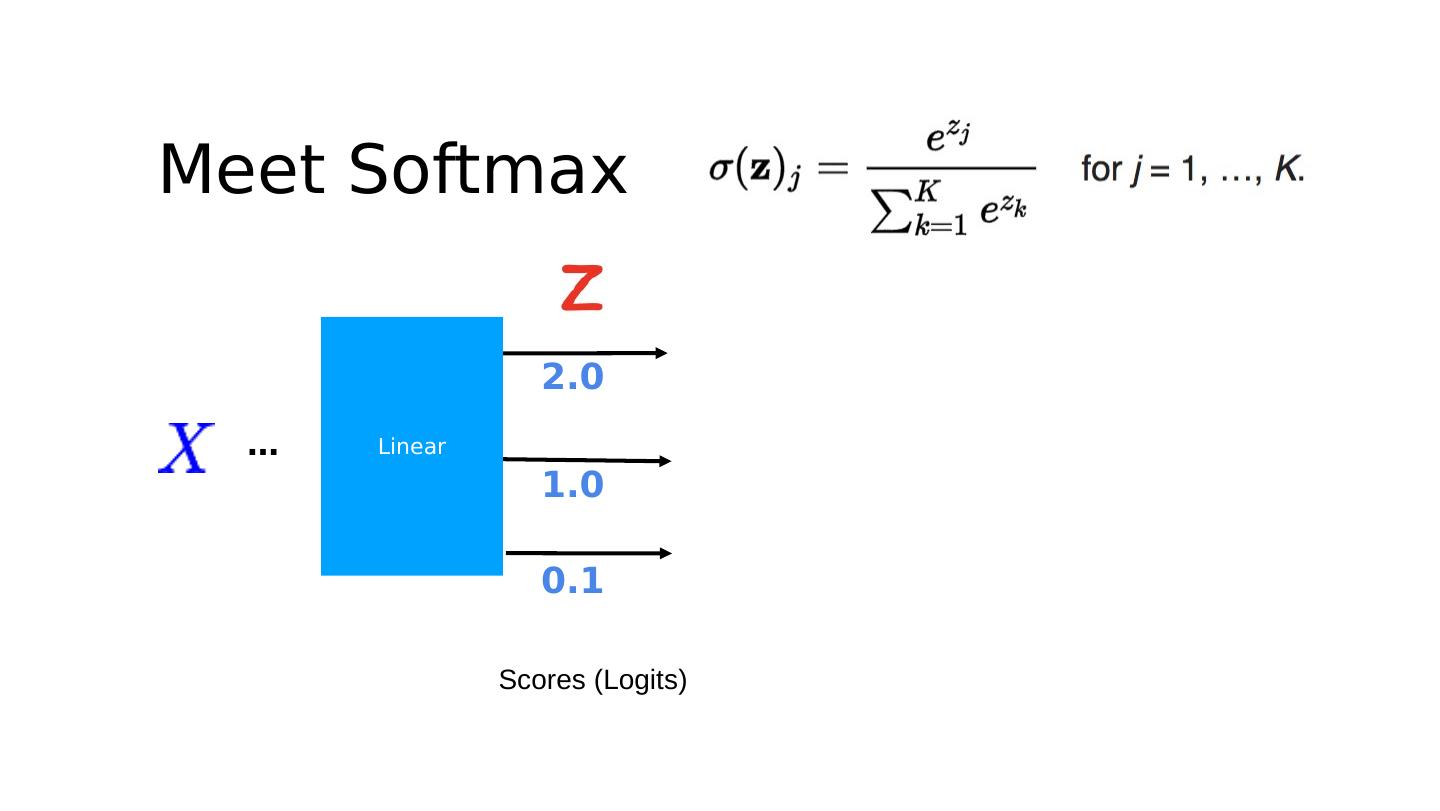
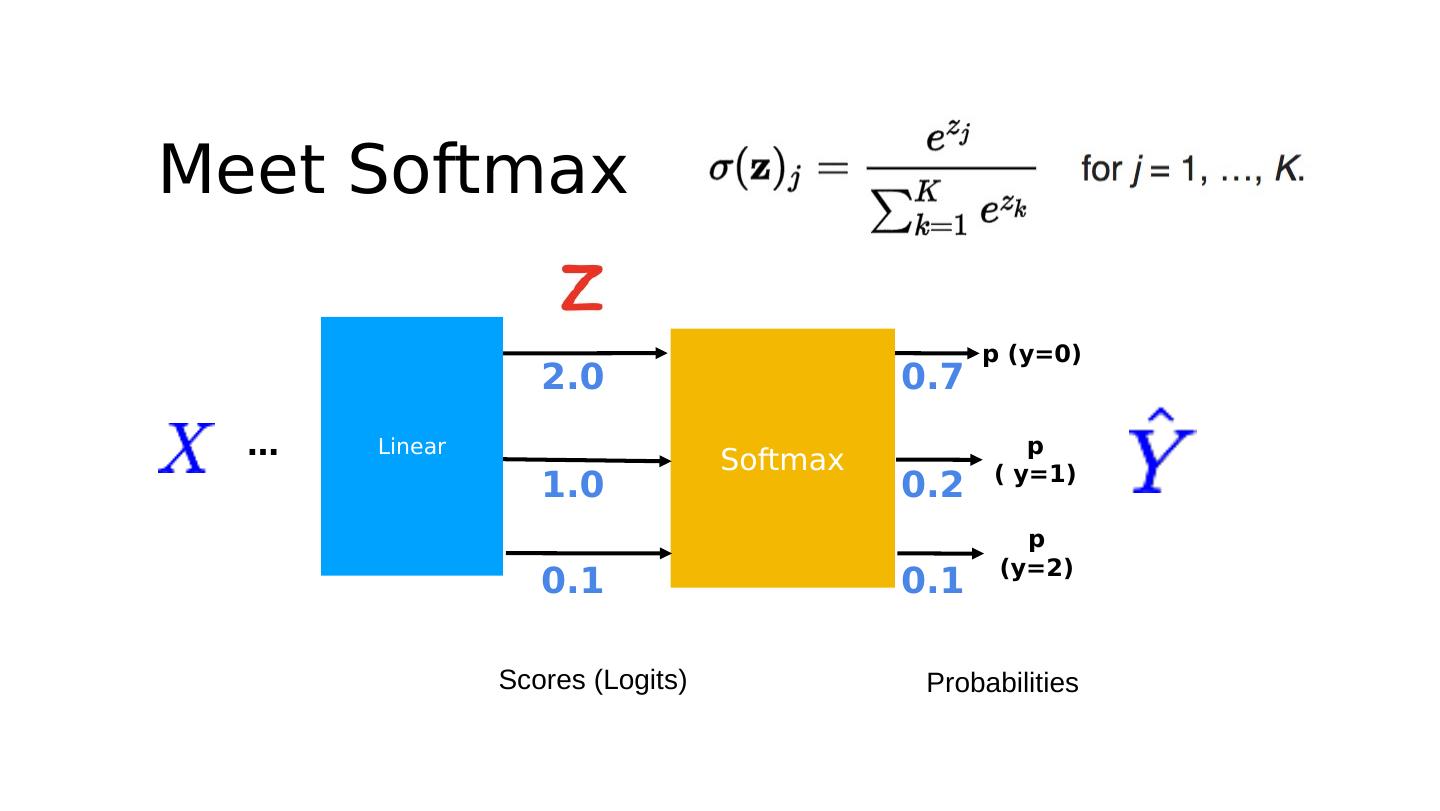
17 .Meet Softmax p (y=0) p ( y=1) p (y= 2 ) Softmax … Linear Scores (Logits) Probabilities 2.0 1.0 0.1 0.7 0.2 0.1
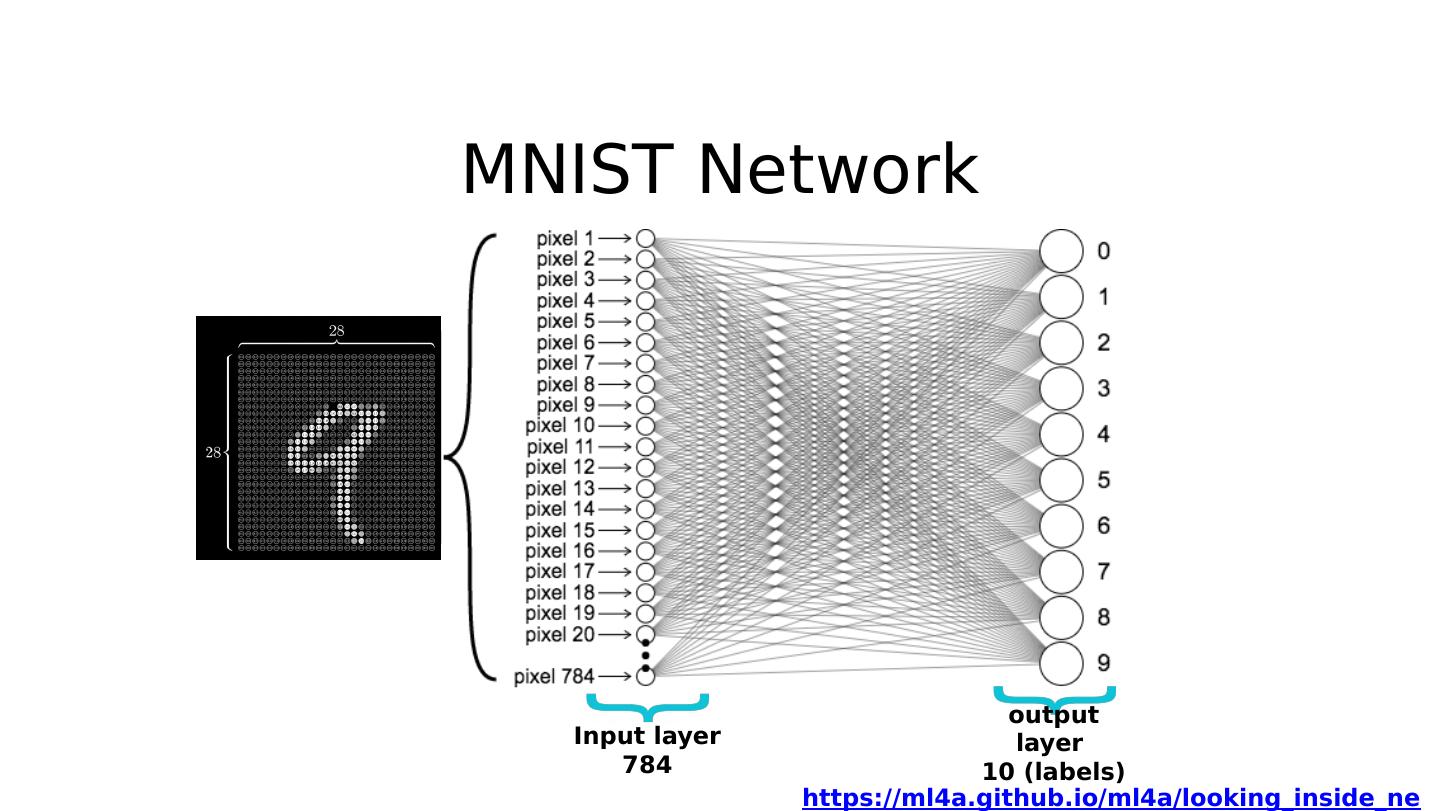
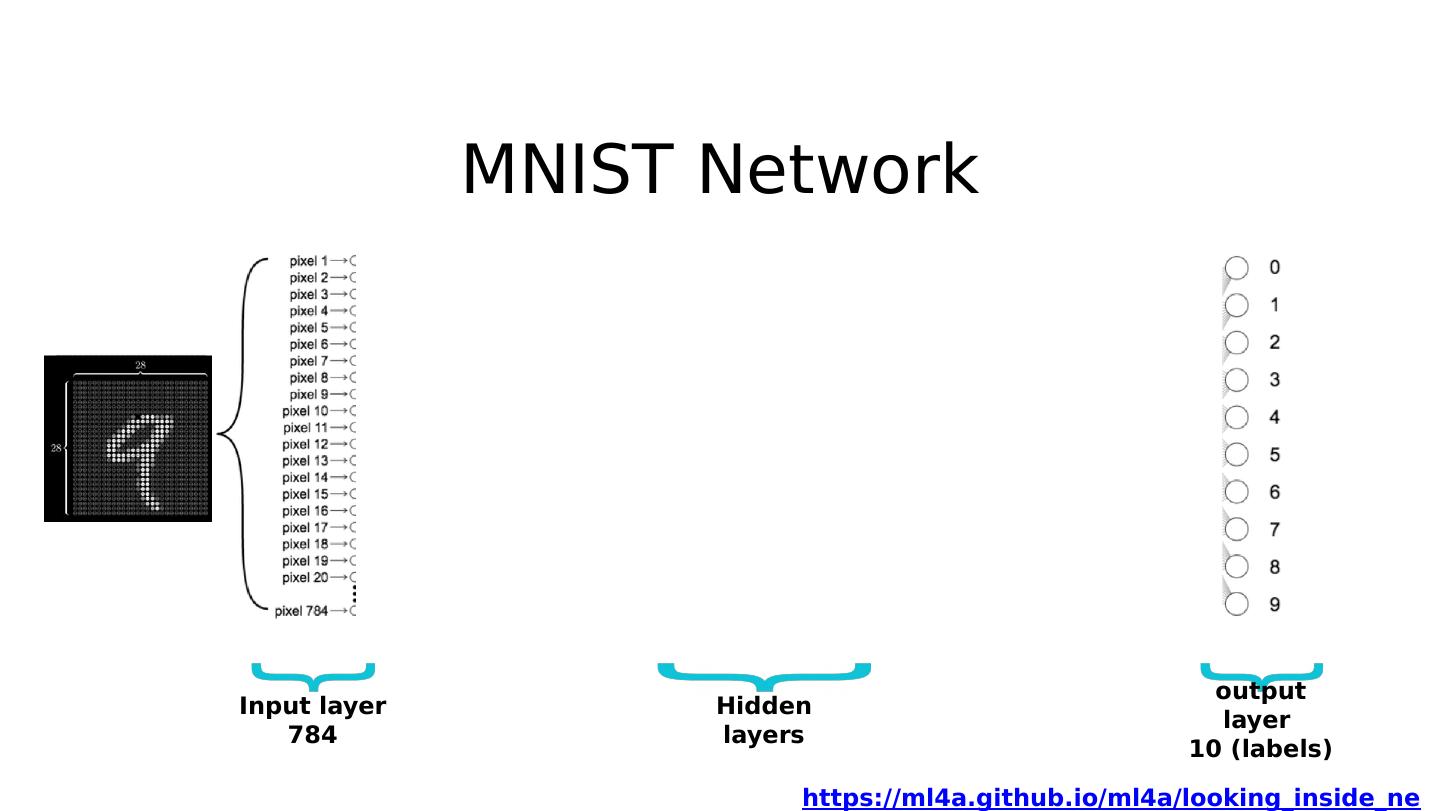
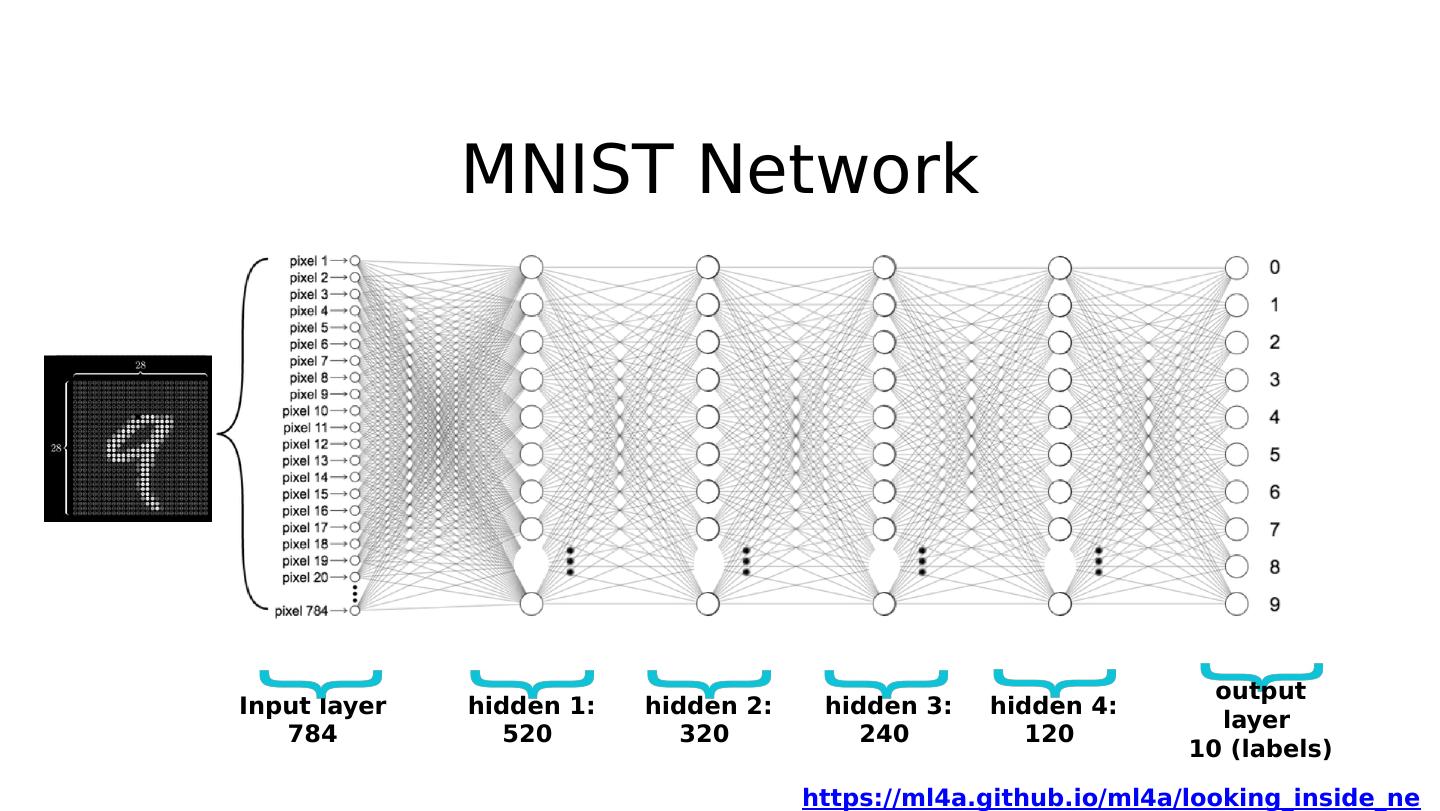
18 .MNIST Network Input layer 784 output layer 10 (labels) hidden 1: 520 hidden 2: 320 hidden 3: 240 hidden 4 : 120 https://ml4a.github.io/ml4a/looking_inside_neural_nets
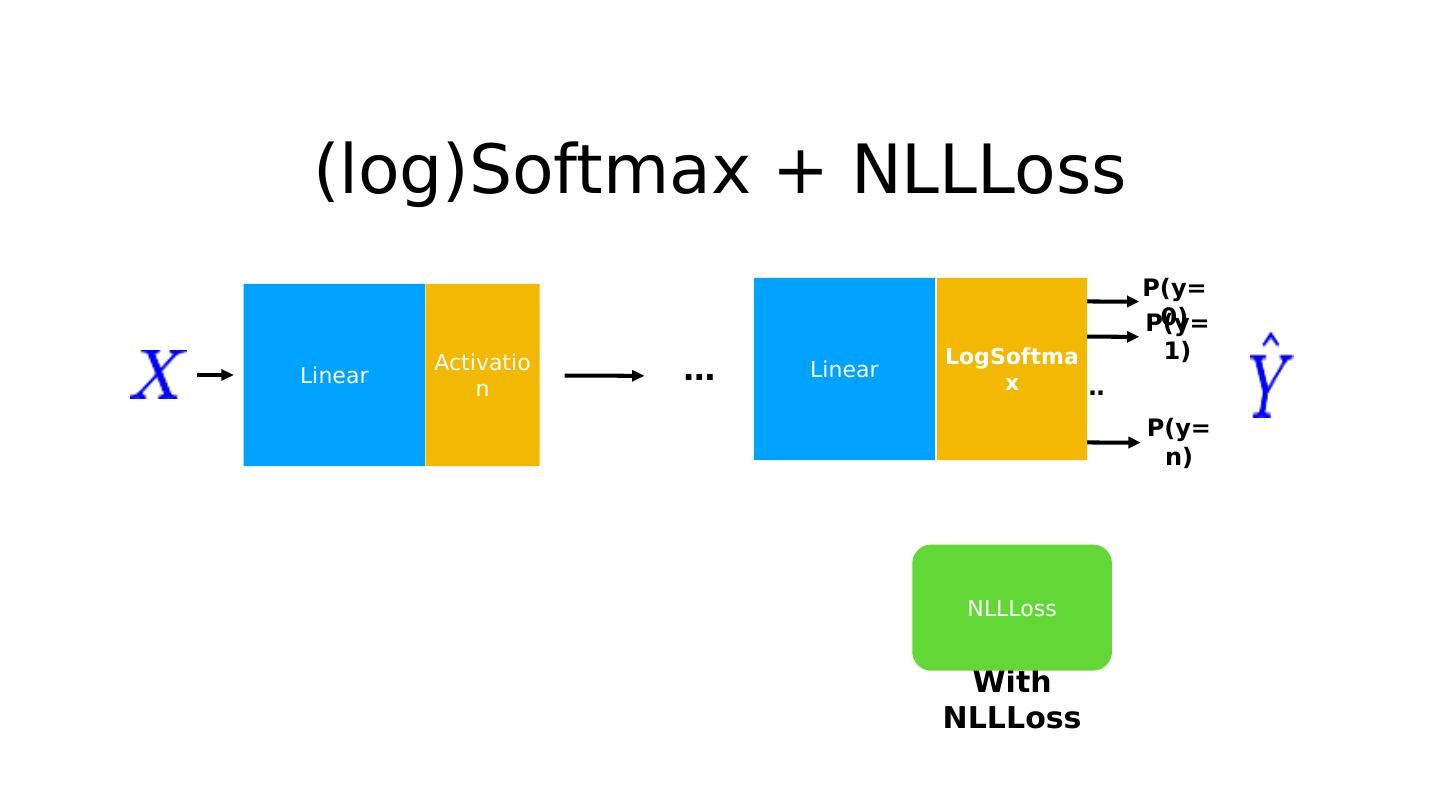
19 .C ross entropy in PyTorch https://www.udacity.com/course/viewer#!/c-ud730/l-6370362152/m-6379811817 # Softmax + CrossEntropy (logSoftmax + NLLLoss) loss = nn.CrossEntropyLoss() # target is of size nBatch # element in target has to have 0 <= value < nClasses (0-2) # Input is class, not one-hot Y = Variable(torch.LongTensor([ 2 , 0 , 1 ]), requires_grad = False ) # input is of size nBatch x nClasses = 2 x 4 # Y_pred are logits (not softmax) Y_pred1 = Variable(torch.Tensor([[ 0.1 , 0.2 , 0.9 ], [ 1.1 , 0.1 , 0.2 ], [ 0.2 , 2.1 , 0.1 ]])) Y_pred2 = Variable(torch.Tensor([[ 0.8 , 0.2 , 0.3 ], [ 0.2 , 0.3 , 0.5 ], [ 0.2 , 0.2 , 0.5 ]])) l1 = loss(Y_pred1, Y) l2 = loss(Y_pred2, Y) print ( "Batch Loss1 = " , l1.data, "
20 .MNIST input https://www.youtube.com/watch?v=aircAruvnKk&t=1s 28x28 pixels = 784
21 .Probability Linear P(y=0) P(y=1) P(y=9) … ? Linear Activation …
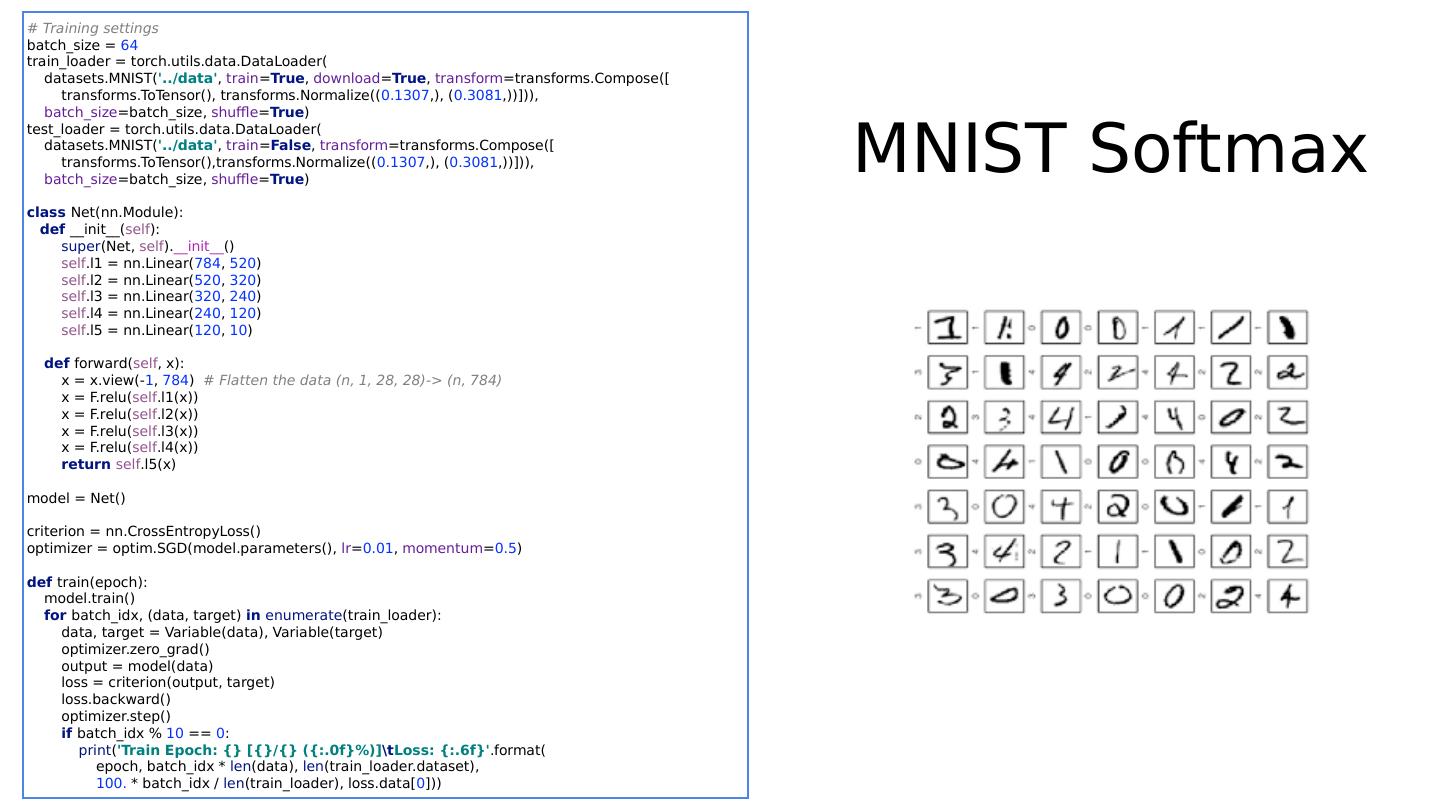
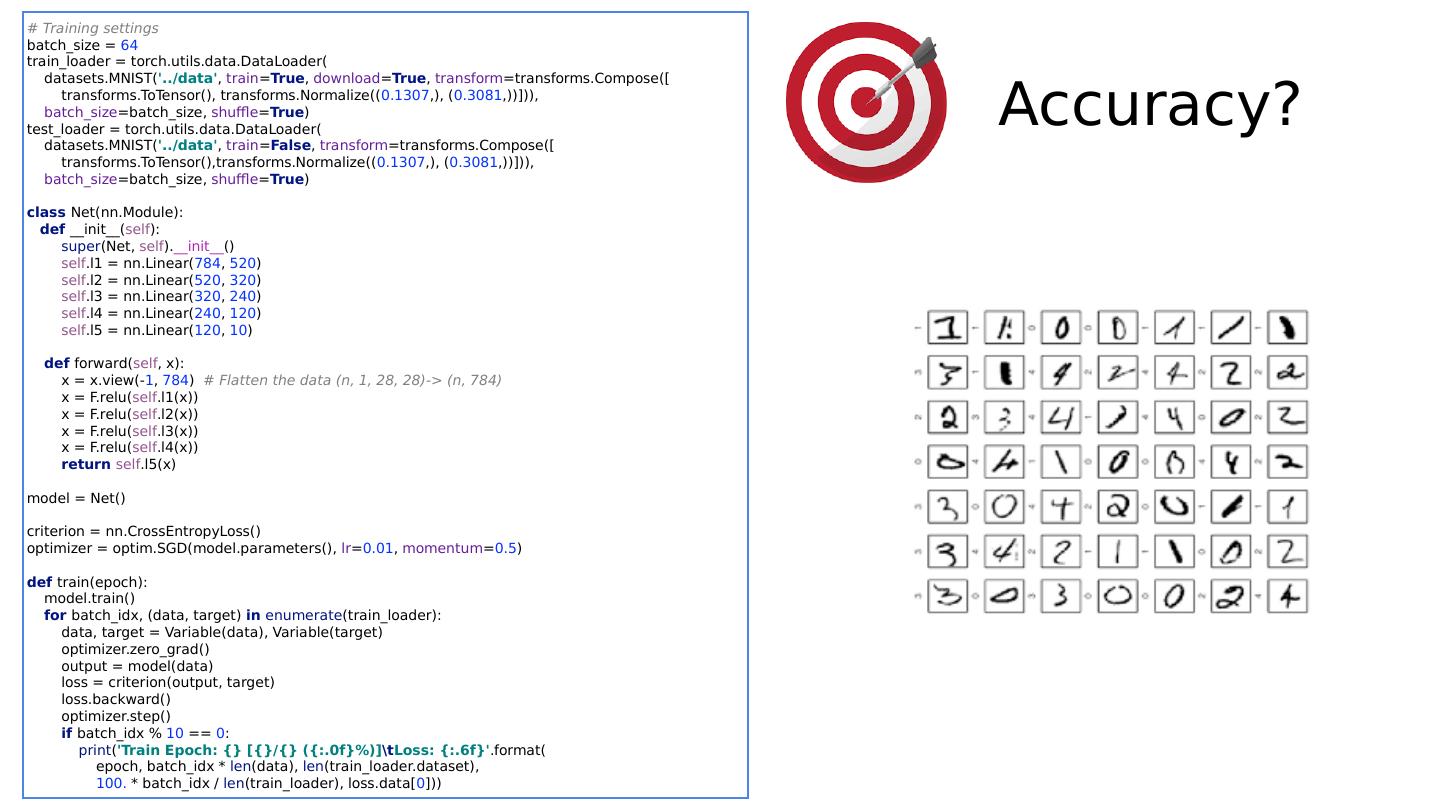
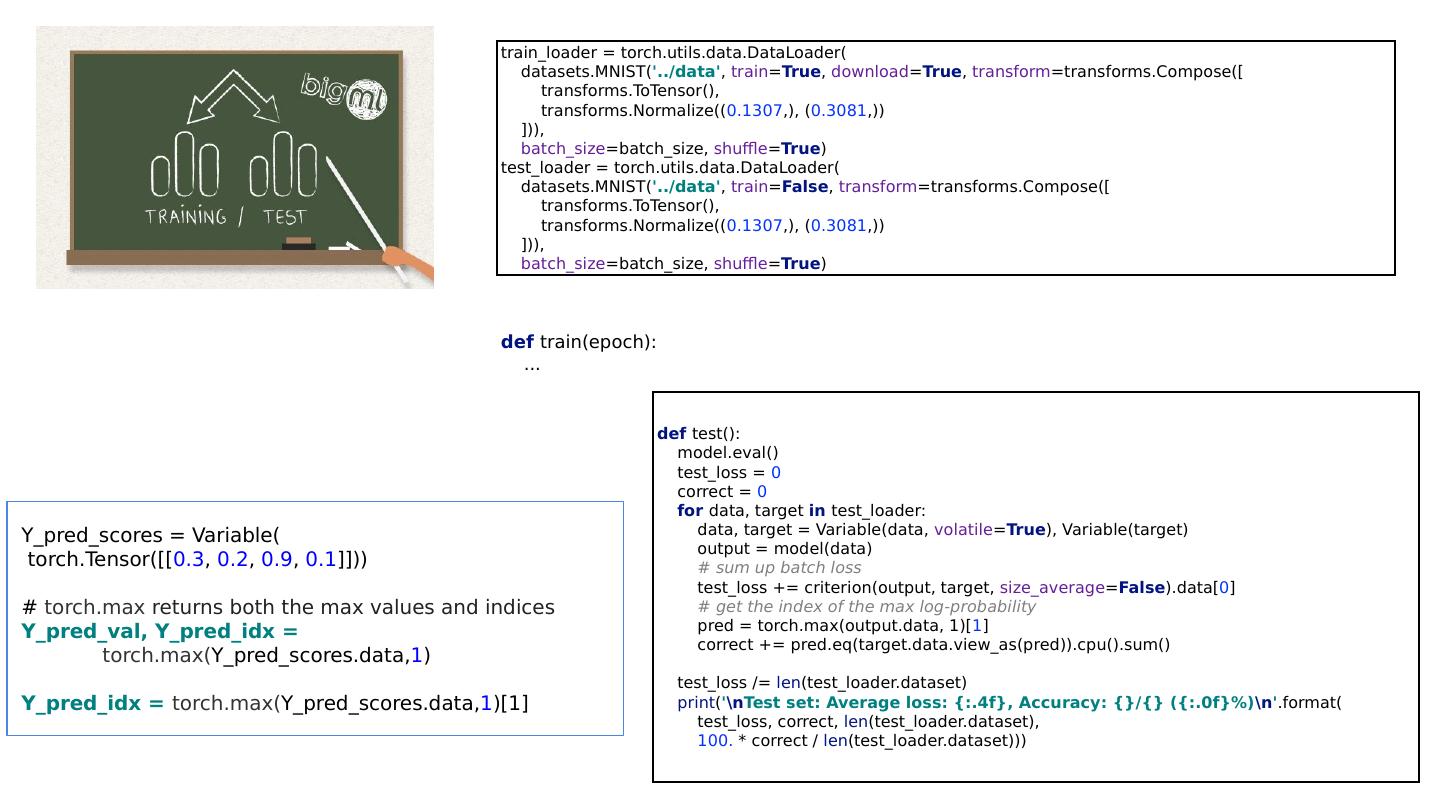
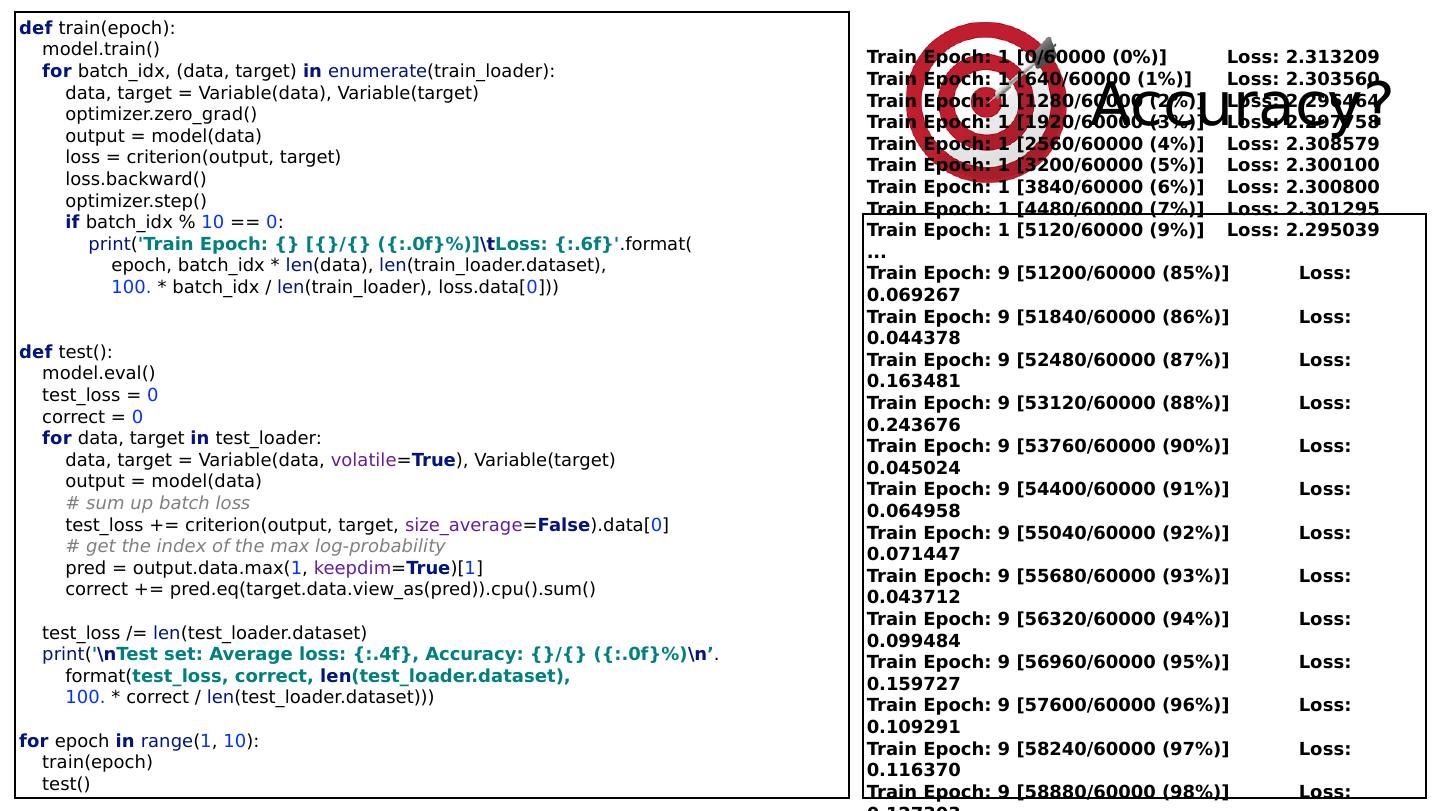
22 .Softmax & NLL loss criterion = nn.CrossEntropyLoss() … for batch_idx, (data, target) in enumerate (train_loader): data, target = Variable(data), Variable(target) optimizer.zero_grad() output = model(data) loss = criterion (output, target) loss.backward() optimizer.step() class Net(nn.Module): def __init__ ( self ): super (Net, self ). __init__ () self .l1 = nn.Linear( 784 , 520 ) self .l2 = nn.Linear( 520 , 320 ) self .l3 = nn.Linear( 320 , 240 ) self .l4 = nn.Linear( 240 , 120 ) self .l5 = nn.Linear( 120 , 10 ) def forward( self , x): # Flatten the data (n, 1, 28, 28)-> (n, 784) x = x.view(- 1 , 784 ) x = F.relu( self .l1(x)) x = F.relu( self .l2(x)) x = F.relu( self .l3(x)) x = F.relu( self .l4(x)) return self .l5(x) # No need activation
23 .Softmax & NLL loss criterion = nn.CrossEntropyLoss() … for batch_idx, (data, target) in enumerate (train_loader): data, target = Variable(data), Variable(target) optimizer.zero_grad() output = model(data) loss = criterion (output, target) loss.backward() optimizer.step() class Net(nn.Module): def __init__ ( self ): super (Net, self ). __init__ () self .l1 = nn.Linear( 784 , 520 ) self .l2 = nn.Linear( 520 , 320 ) self .l3 = nn.Linear( 320 , 240 ) self .l4 = nn.Linear( 240 , 120 ) self .l5 = nn.Linear( 120 , 10 ) def forward( self , x): # Flatten the data (n, 1, 28, 28)-> (n, 784) x = x.view(- 1 , 784 ) x = F.relu( self .l1(x)) x = F.relu( self .l2(x)) x = F.relu( self .l3(x)) x = F.relu( self .l4(x)) return self .l5(x) # No need activation
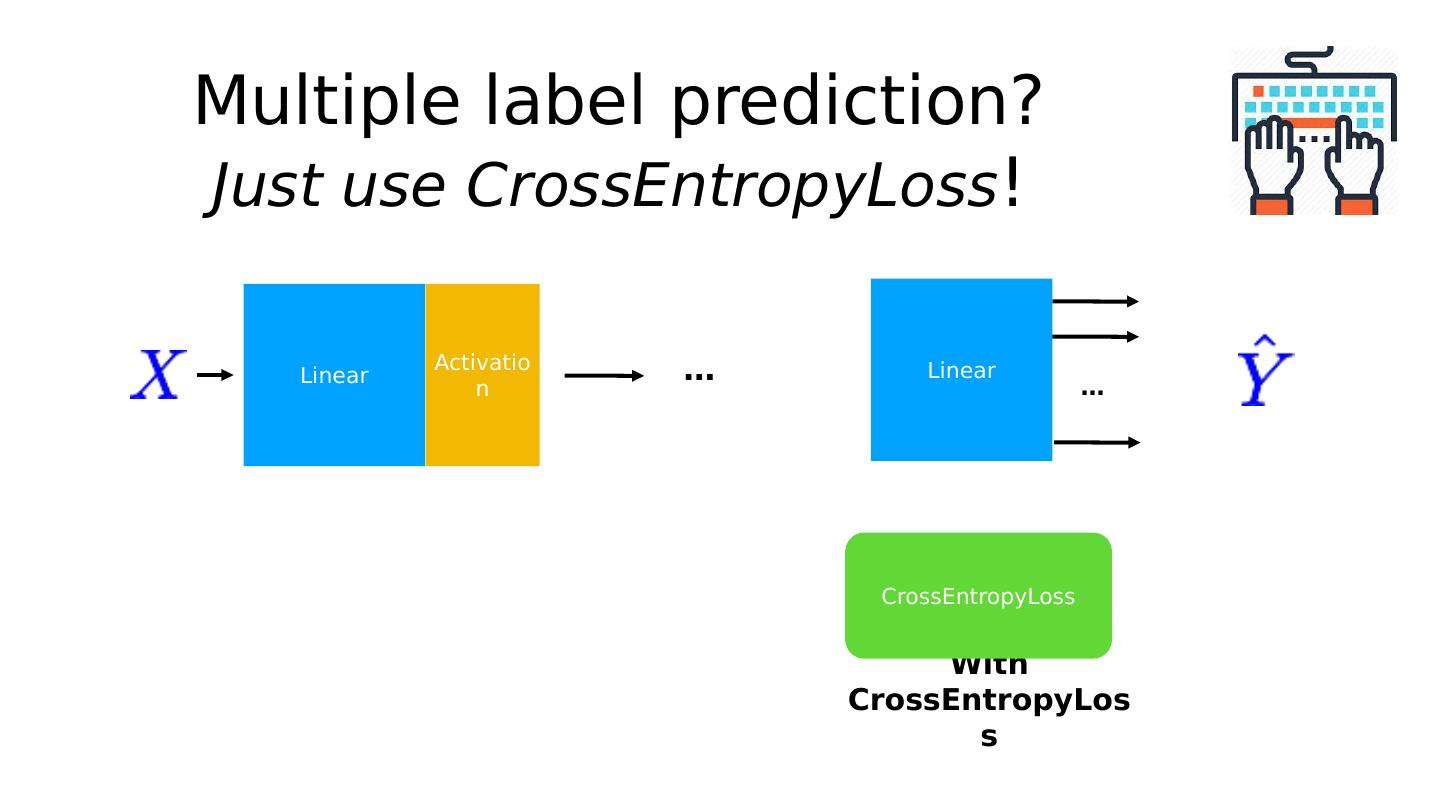
24 .Linear … Multiple label prediction? Just use CrossEntropyLoss ! With CrossEntropyLoss Linear Activation … CrossEntropyLoss