
























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2-Parallel Computer Architecture
Outline
Parallel architecture types
Instruction-level parallelism
Vector processing
SIMD
Shared memory
❍ Memory organization: UMA, NUMA
❍ Coherency: CC-UMA, CC-NUMA
Interconnection networks
Distributed memory
Clusters
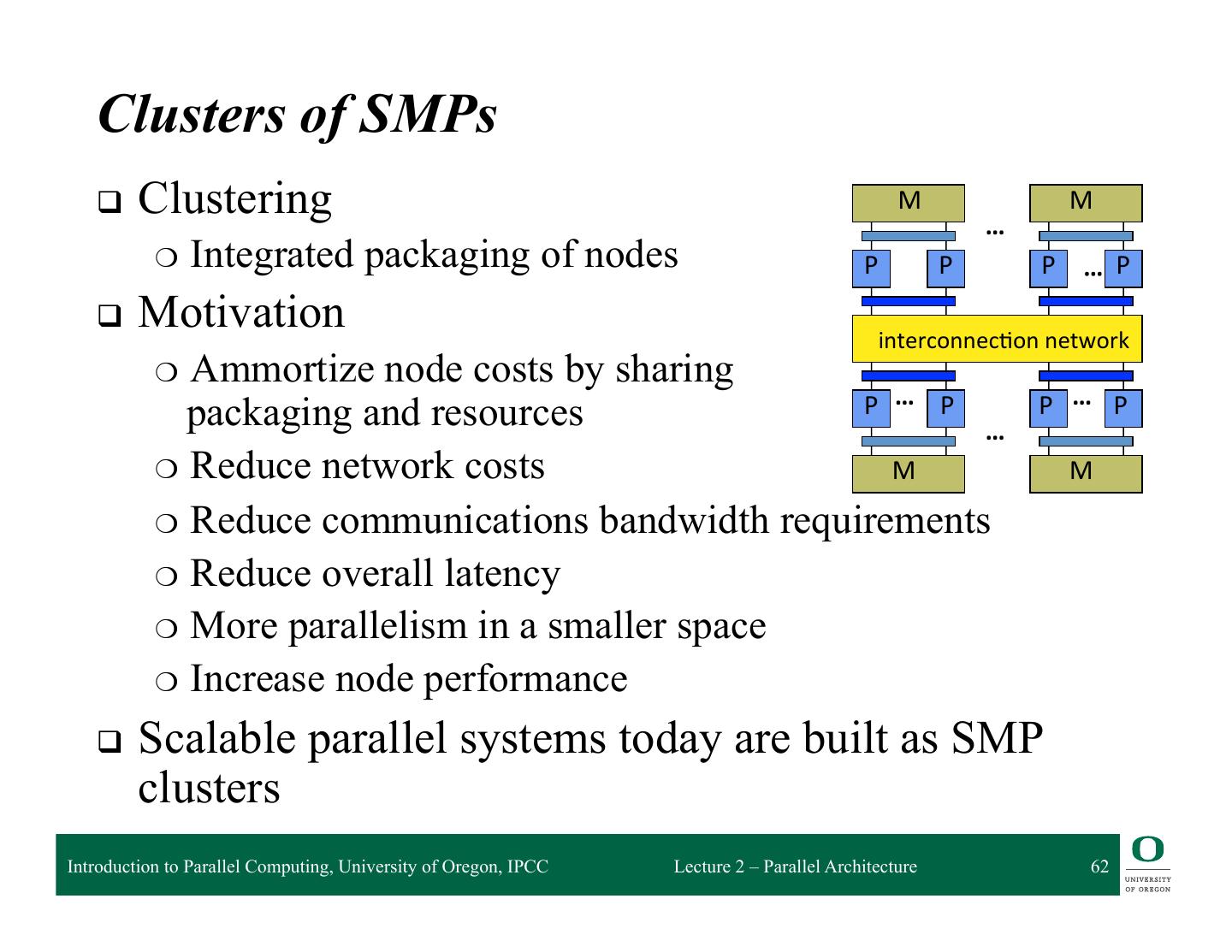
Clusters of SMPs
Heterogeneous clusters of SMPs
展开查看详情
1 . Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture
2 . Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2
3 . Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3
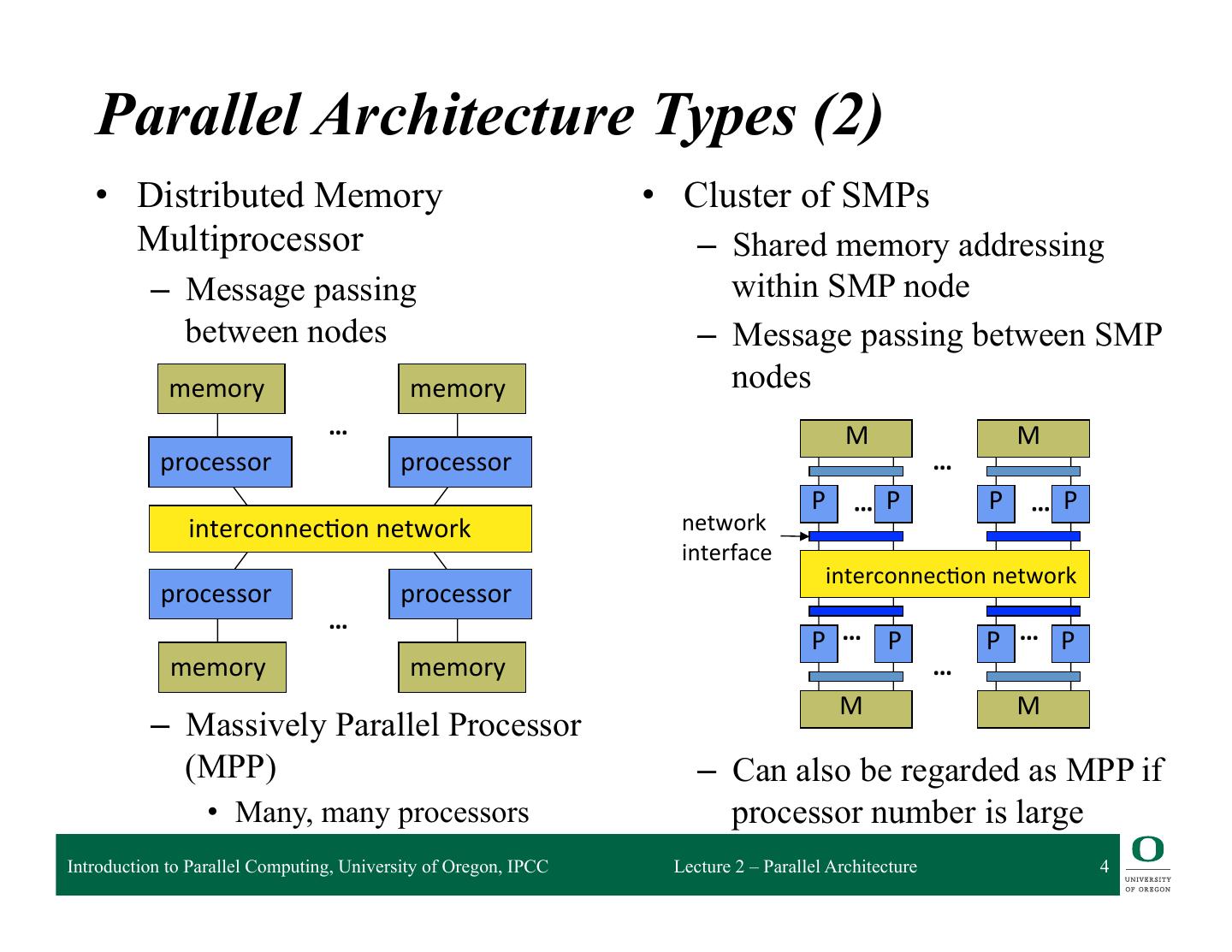
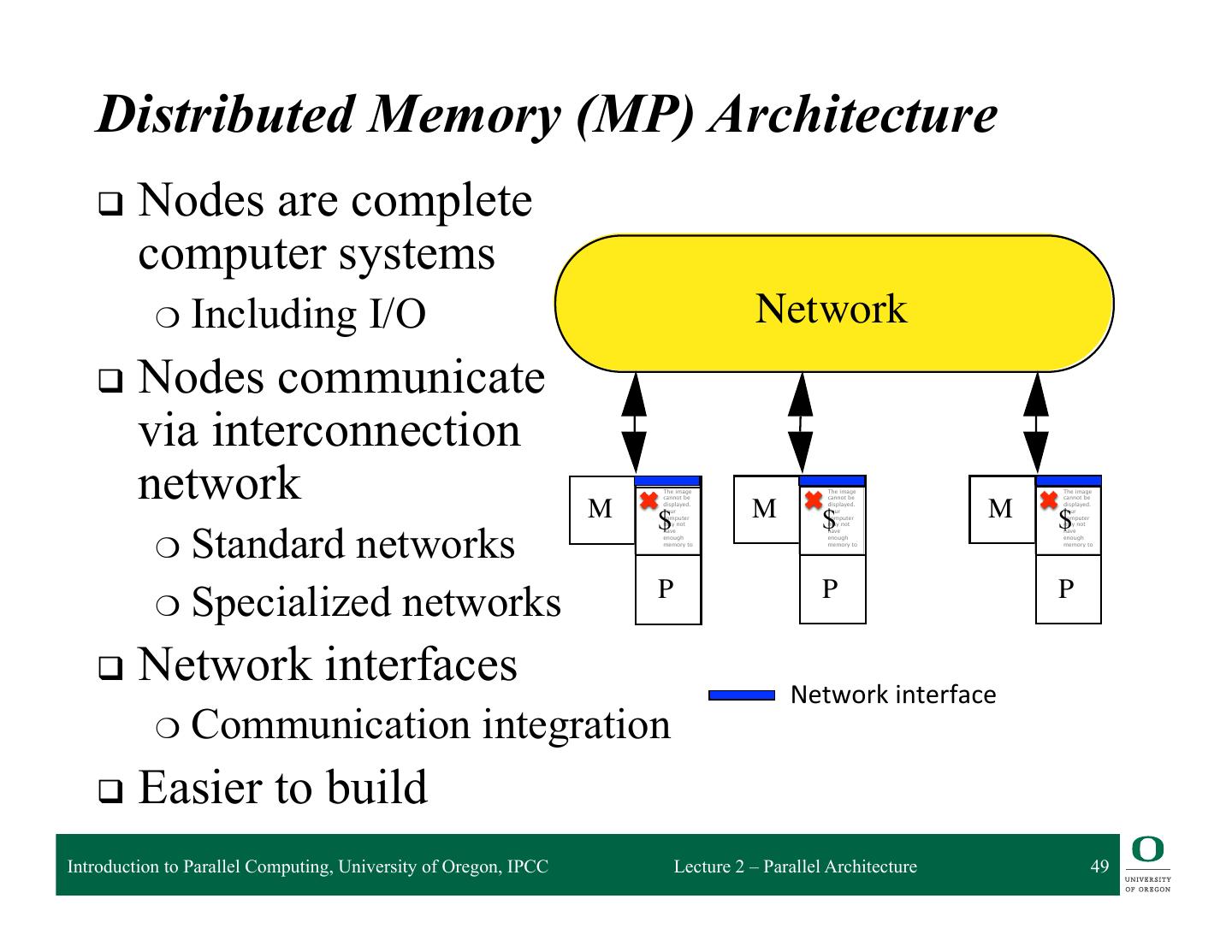
4 . Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … P … P P … P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 4
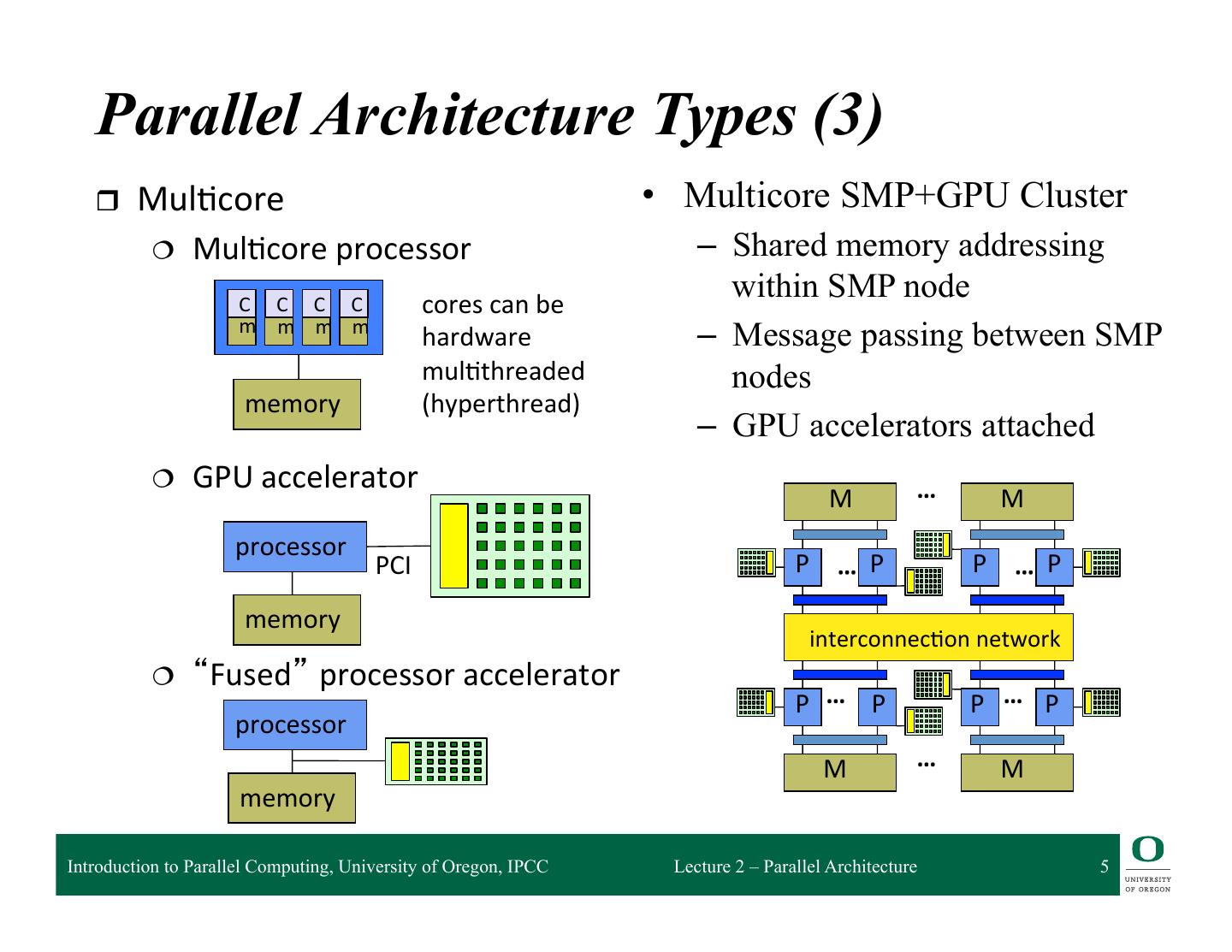
5 . Parallel Architecture Types (3) r Mul2core • Multicore SMP+GPU Cluster ¦ Mul2core processor – Shared memory addressing C C C C cores can be within SMP node m m m m hardware – Message passing between SMP mul2threaded nodes memory (hyperthread) – GPU accelerators attached ¦ GPU accelerator … M M processor PCI P … P P … P memory interconnec2on network ¦ “Fused” processor accelerator P … P P … P processor M … M memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 5
6 . How do you get parallelism in the hardware? q Instruction-Level Parallelism (ILP) q Data parallelism ❍ Increase amount of data to be operated on at same time q Processor parallelism ❍ Increase number of processors q Memory system parallelism ❍ Increase number of memory units ❍ Increase bandwidth to memory q Communication parallelism ❍ Increase amount of interconnection between elements ❍ Increase communication bandwidth Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 6
7 . Instruction-Level Parallelism r Opportunities for splitting up instruction processing r Pipelining within instruction r Pipelining between instructions r Overlapped execution r Multiple functional units r Out of order execution r Multi-issue execution r Superscalar processing r Superpipelining r Very Long Instruction Word (VLIW) r Hardware multithreading (hyperthreading) Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 7
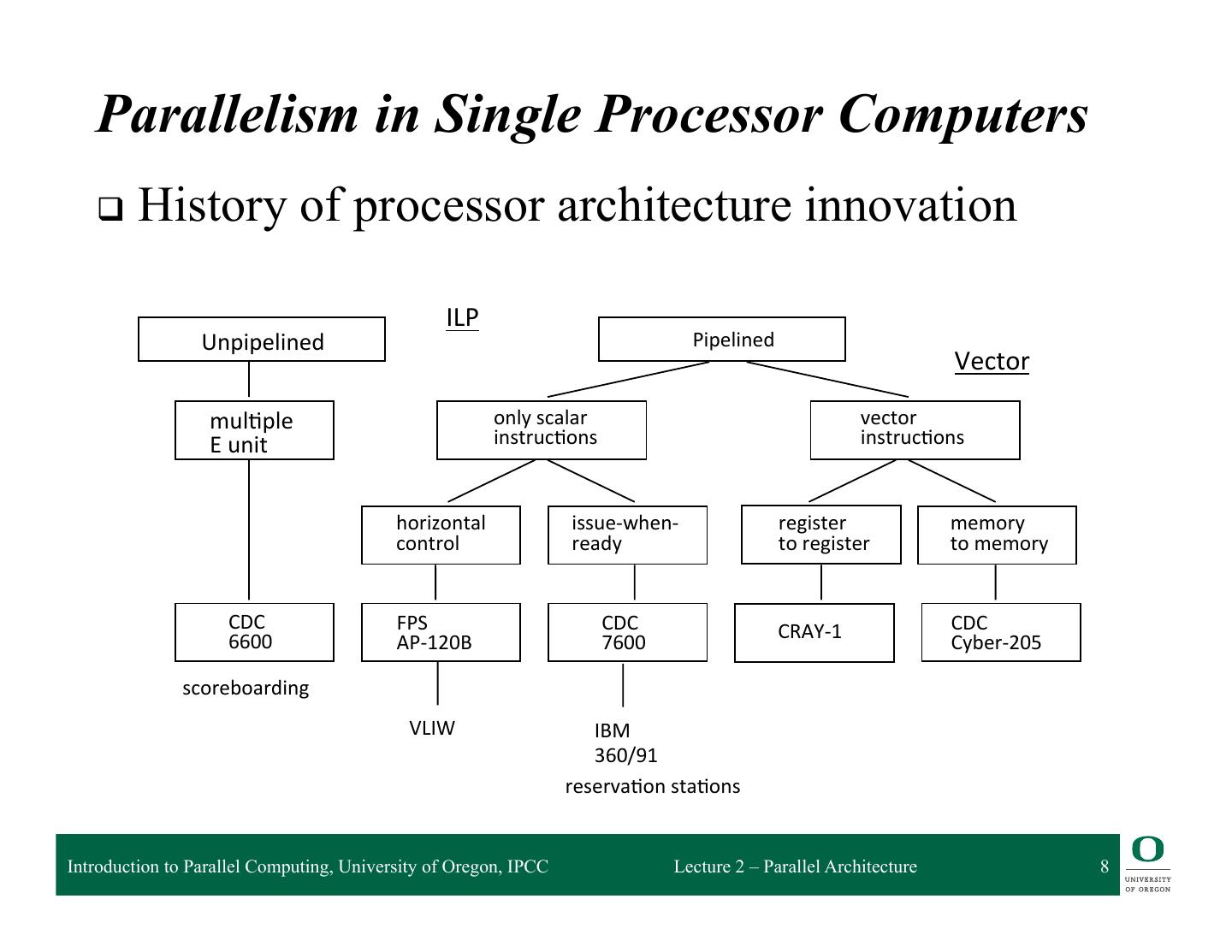
8 . Parallelism in Single Processor Computers q History of processor architecture innovation ILP Unpipelined Pipelined Vector mul2ple only scalar vector E unit instruc2ons instruc2ons horizontal issue-‐when-‐ register memory control ready to register to memory CDC FPS CDC CRAY-‐1 CDC 6600 AP-‐120B 7600 Cyber-‐205 scoreboarding VLIW IBM 360/91 reserva2on sta2ons Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 8
9 . Vector Processing q Scalar processing ❍ Processor instructions operate on scalar values ❍ integer registers and floating point registers q Vectors Liquid-‐cooled with inert ❍ Setof scalar data fluorocarbon. (That’s a ❍ Vector registers waterfall fountain!!!) ◆ integer, floating point (typically) Cray 2 ❍ Vector instructions operate on vector registers (SIMD) q Vector unit pipelining q Multiple vector units q Vector chaining Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 9
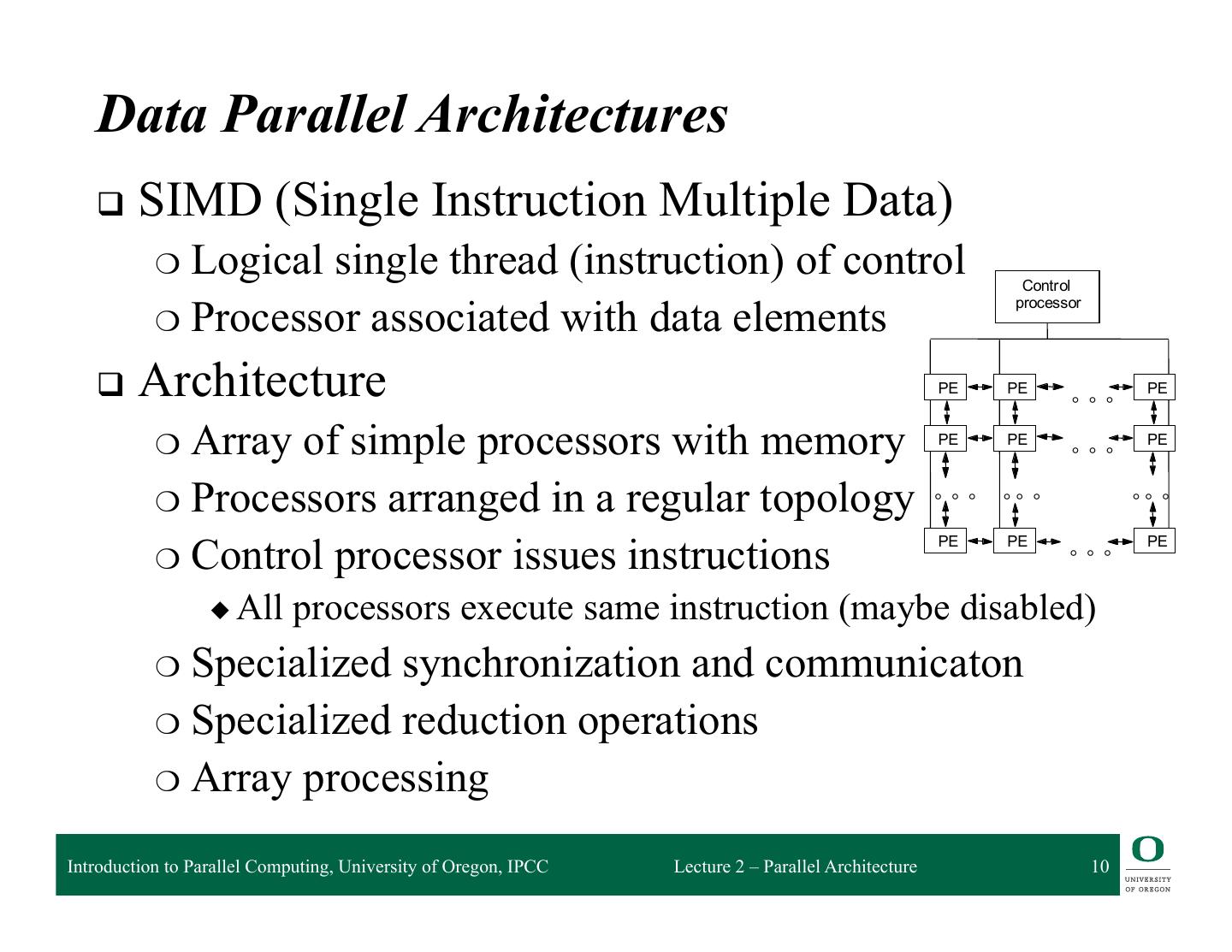
10 . Data Parallel Architectures q SIMD (Single Instruction Multiple Data) ❍ Logicalsingle thread (instruction) of control Contr ol ❍ Processor associated with data elements processor q Architecture PE PE ° ° ° PE ❍ Array of simple processors with memory PE PE ° ° ° PE ❍ Processors arranged in a regular topology ° ° ° ° ° ° ° ° ° ❍ Control processor issues instructions PE PE PE ° ° ° ◆ All processors execute same instruction (maybe disabled) ❍ Specialized synchronization and communicaton ❍ Specialized reduction operations ❍ Array processing Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 10
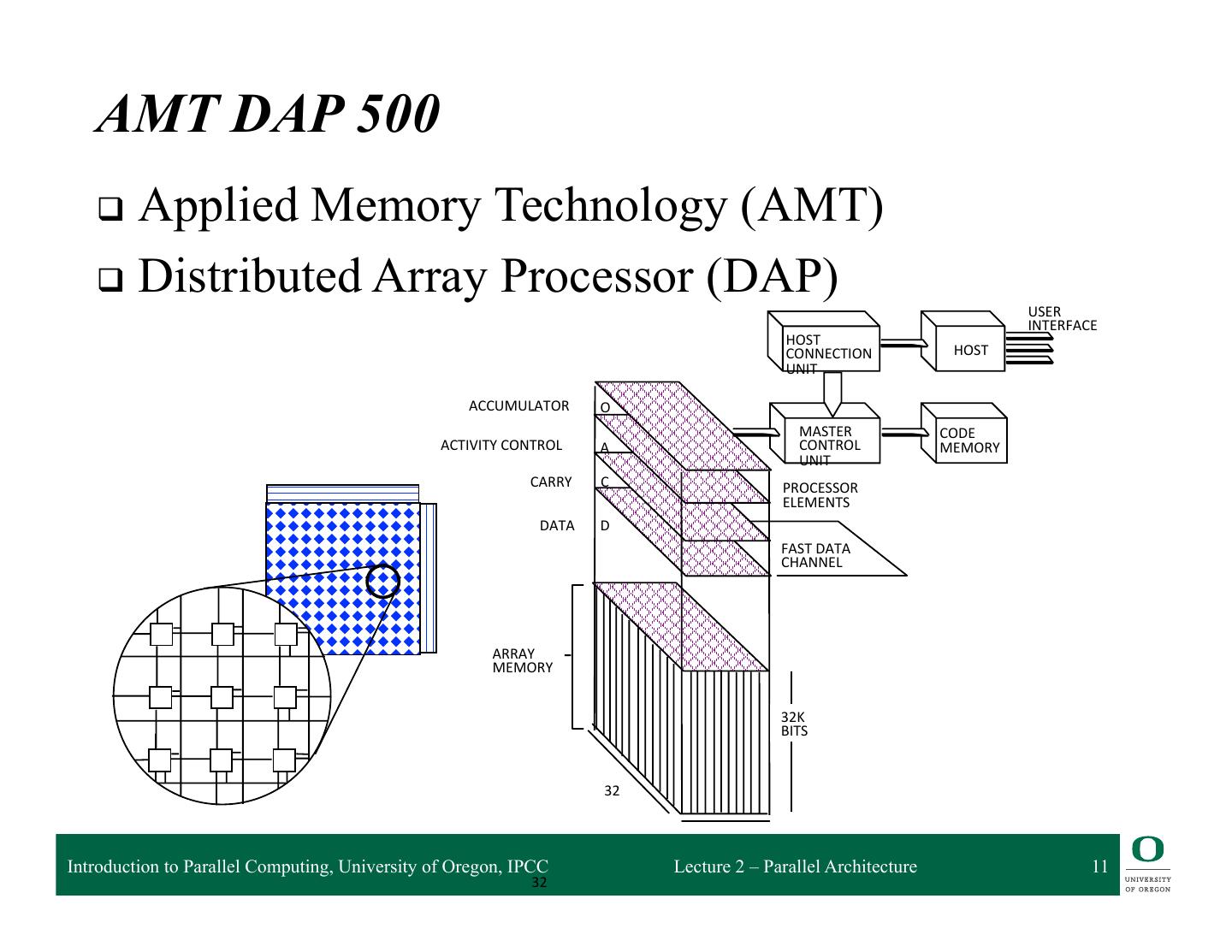
11 . AMT DAP 500 q Applied Memory Technology (AMT) q Distributed Array Processor (DAP) USER INTERFACE HOST CONNECTION HOST UNIT ACCUMULATOR O MASTER CODE ACTIVITY CONTROL A CONTROL MEMORY UNIT CARRY C PROCESSOR ELEMENTS DATA D FAST DATA CHANNEL ARRAY MEMORY 32K BITS 32 Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 11 32
12 . Thinking Machines Connection Machine (Tucker, IEEE Computer, Aug. 1988) 16,000 processors!!! Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 12
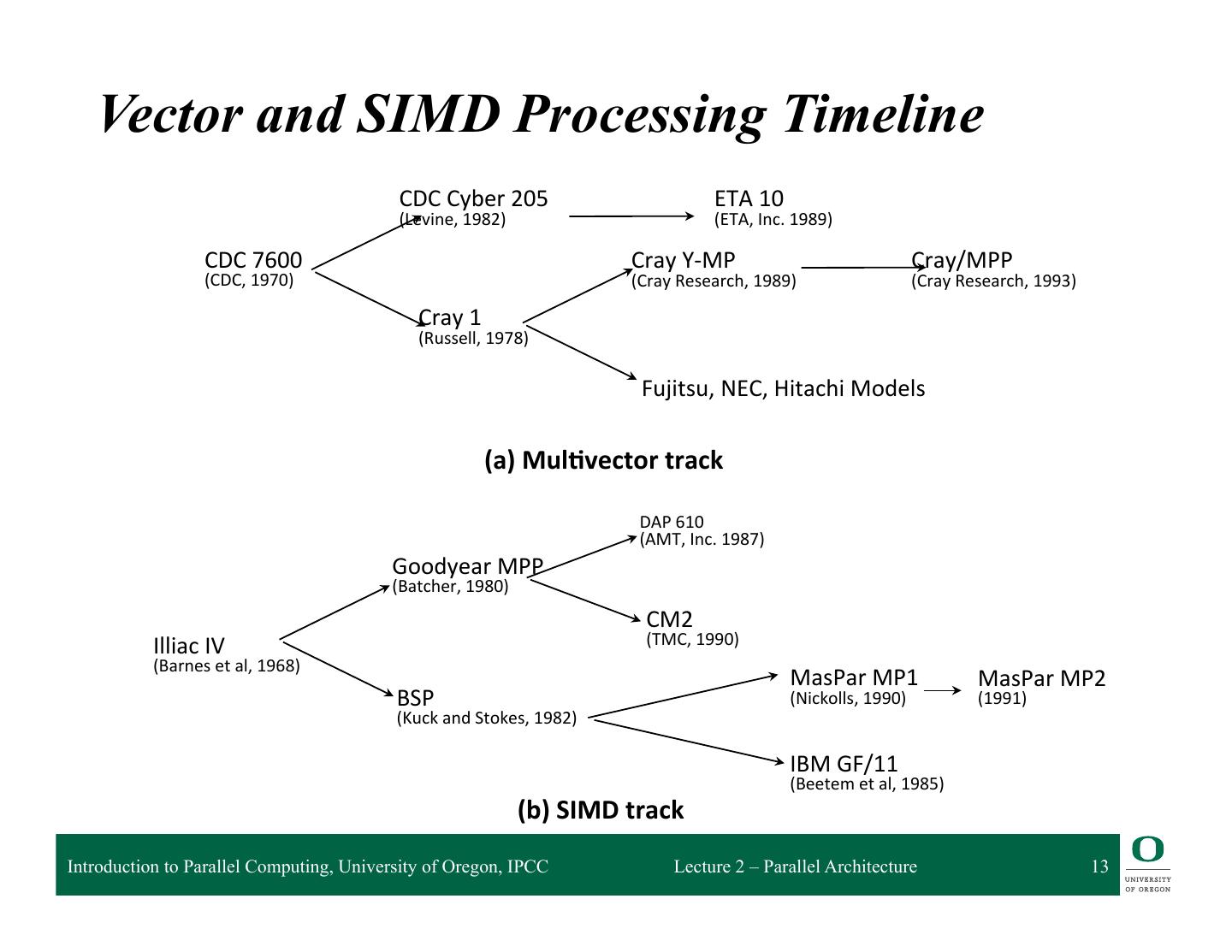
13 . Vector and SIMD Processing Timeline CDC Cyber 205 ETA 10 (Levine, 1982) (ETA, Inc. 1989) CDC 7600 Cray Y-‐MP Cray/MPP (CDC, 1970) (Cray Research, 1989) (Cray Research, 1993) Cray 1 (Russell, 1978) Fujitsu, NEC, Hitachi Models (a) Mul)vector track DAP 610 (AMT, Inc. 1987) Goodyear MPP (Batcher, 1980) CM2 Illiac IV (TMC, 1990) (Barnes et al, 1968) MasPar MP1 MasPar MP2 BSP (Nickolls, 1990) (1991) (Kuck and Stokes, 1982) IBM GF/11 (Beetem et al, 1985) (b) SIMD track Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 13
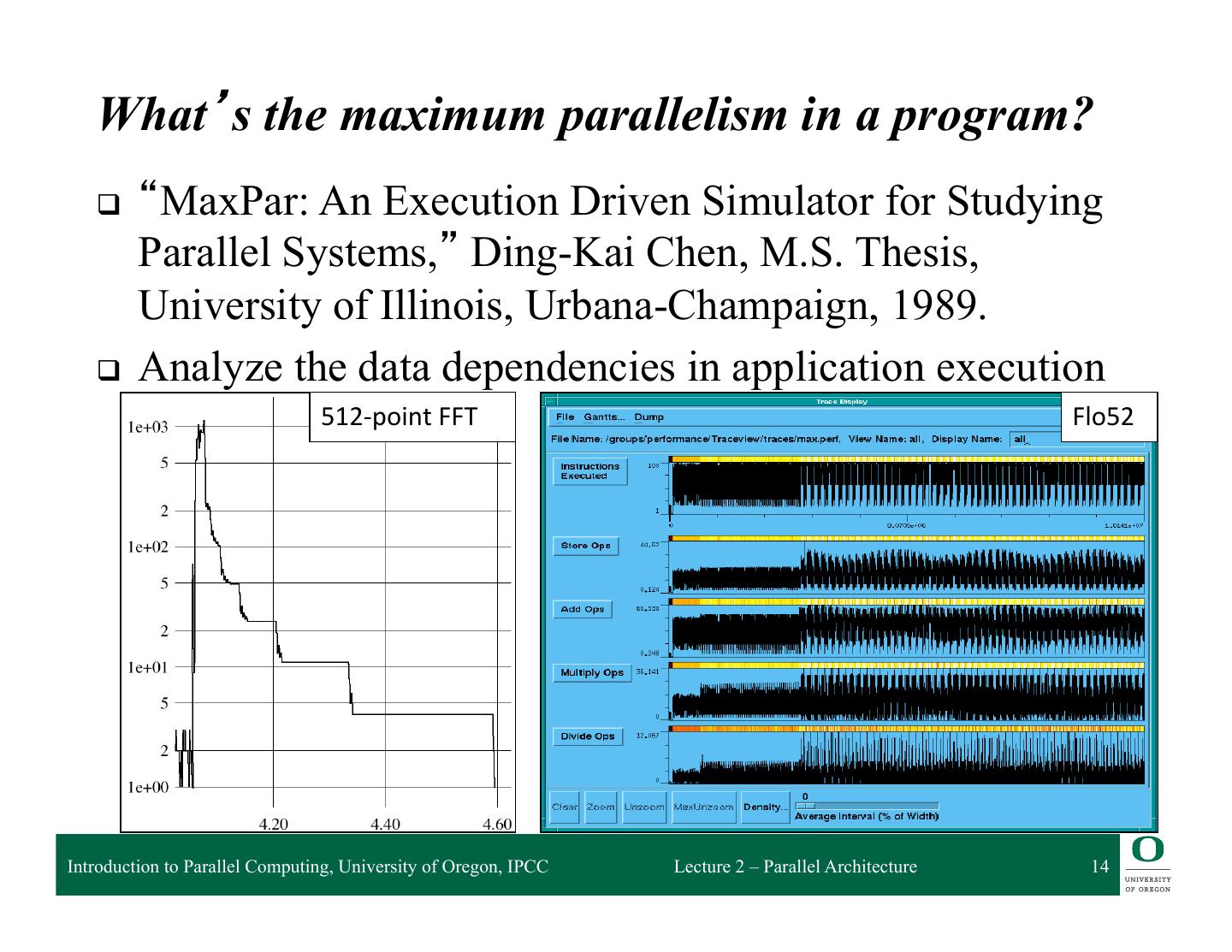
14 . What’s the maximum parallelism in a program? q “MaxPar: An Execution Driven Simulator for Studying Parallel Systems,” Ding-Kai Chen, M.S. Thesis, University of Illinois, Urbana-Champaign, 1989. q Analyze the data dependencies in application execution 512-‐point FFT Flo52 Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 14
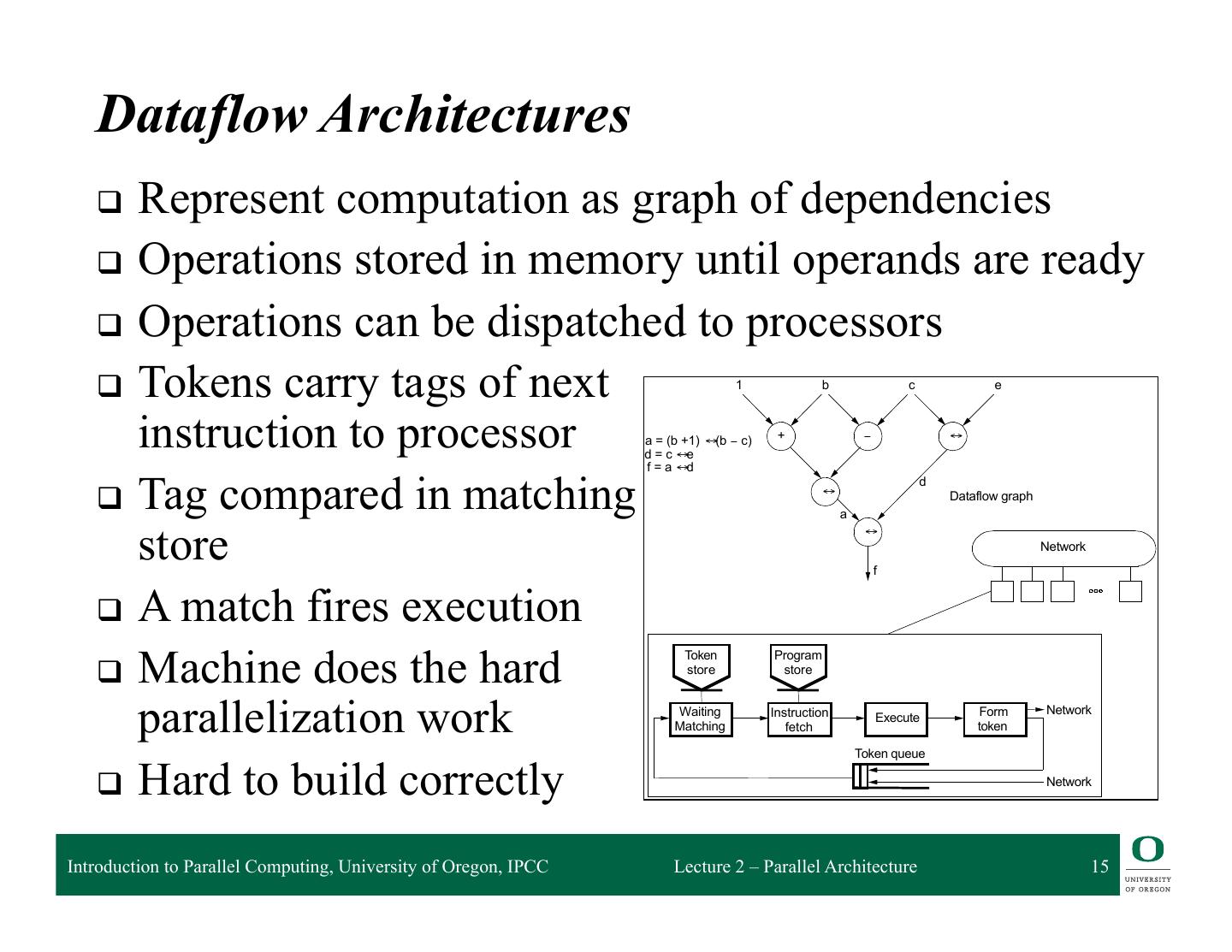
15 . Dataflow Architectures q Represent computation as graph of dependencies q Operations stored in memory until operands are ready q Operations can be dispatched to processors q Tokens carry tags of next 1 b c e instruction to processor a = (b +1) ↔(b − c) d = c ↔e + − ↔ f = a ↔d q Tag compared in matching d ↔ Dataflow graph a store ↔ Network f q A match fires execution q Machine does the hard Token Program store store parallelization work Waiting Matching Instruction fetch Execute Form token Network Token queue q Hard to build correctly Network Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 15
16 . Shared Physical Memory q Add processors to single processor computer system q Processors share computer system resources ❍ Memory, storage, … q Sharing physical memory ❍ Any processor can reference any memory location ❍ Any I/O controller can reference any memory address ❍ Single physical memory address space q Operating system runs on any processor, or all ❍ OS see single memory address space ❍ Uses shared memory to coordinate q Communication occurs as a result of loads and stores Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 16
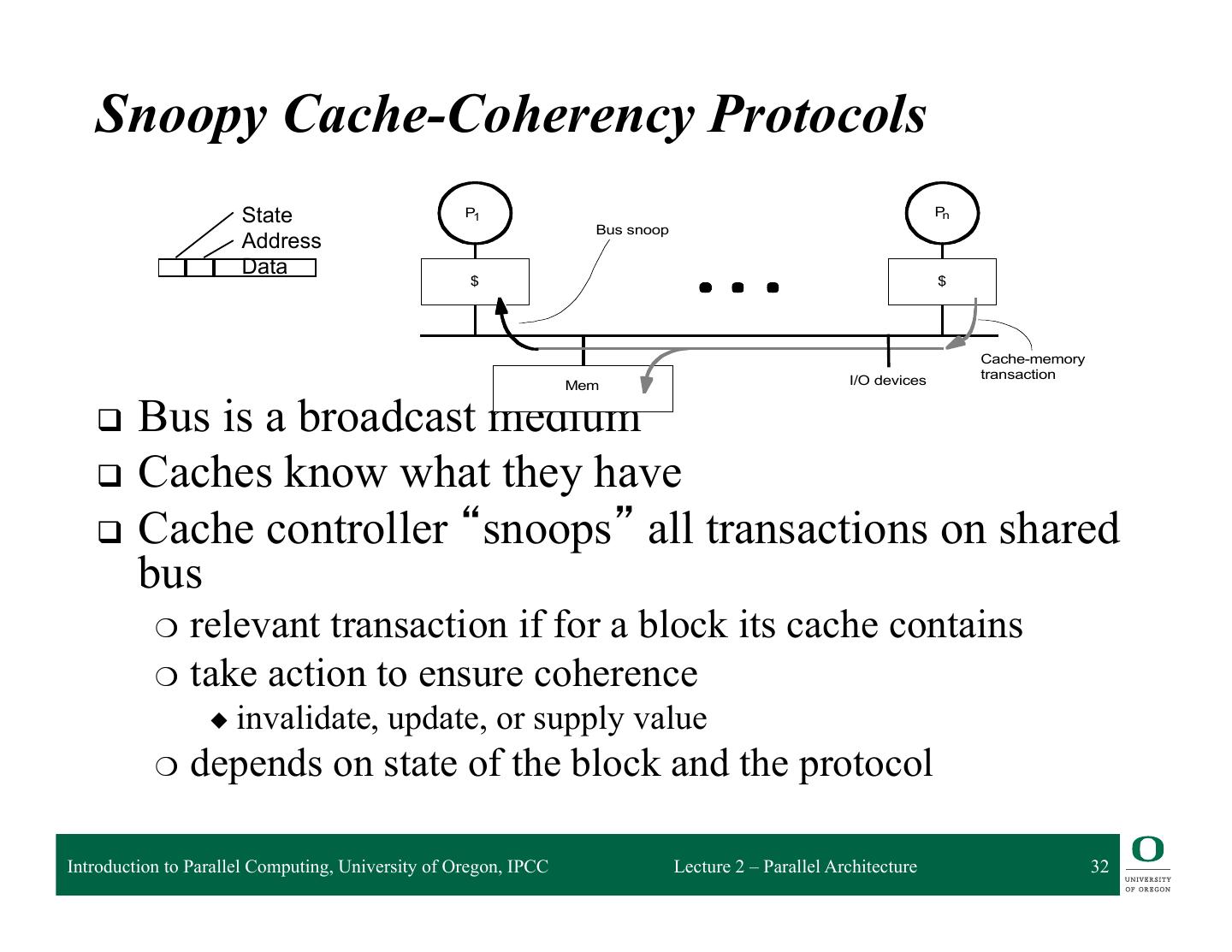
17 . Caching in Shared Memory Systems q Reduce average latency ❍ automatic replication closer to processor q Reduce average bandwidth q Data is logically transferred from producer to consumer to memory ❍ store reg → mem ❍ load reg ← mem q Processors can share data efficiently P P P q What happens when store and load are executed on different processors? q Cache coherence problems Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 17
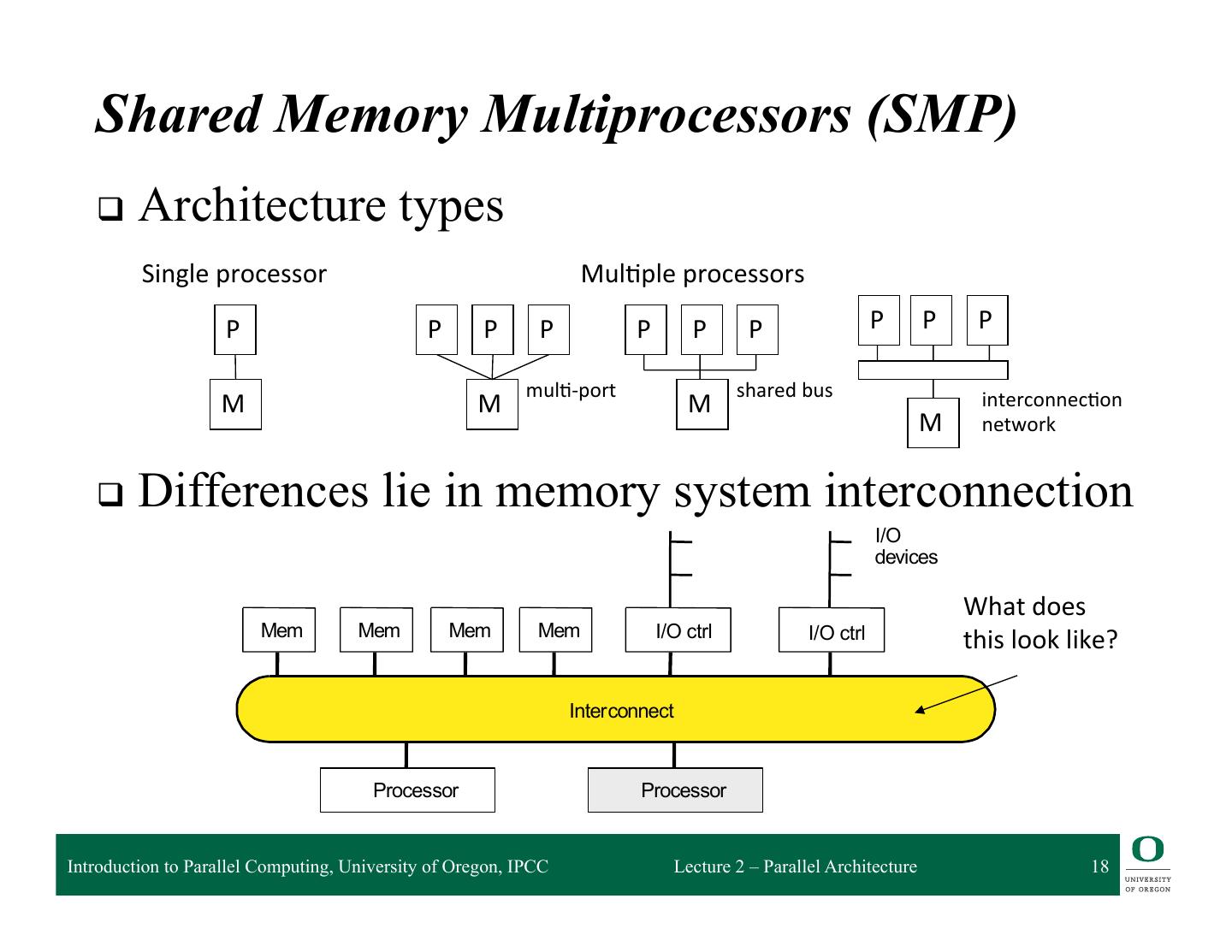
18 . Shared Memory Multiprocessors (SMP) q Architecture types Single processor Mul2ple processors P P P P P P P P P P mul2-‐port shared bus interconnec2on M M M M network q Differences lie in memory system interconnection I/ O de v i c e s What does m Me m Me m Me m Me I/ O c t r l I/ O c t r l this look like? t e r co n n e c t In t e r co n n e c t In Pr o c e s so r Pr o c e s s o r Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 18
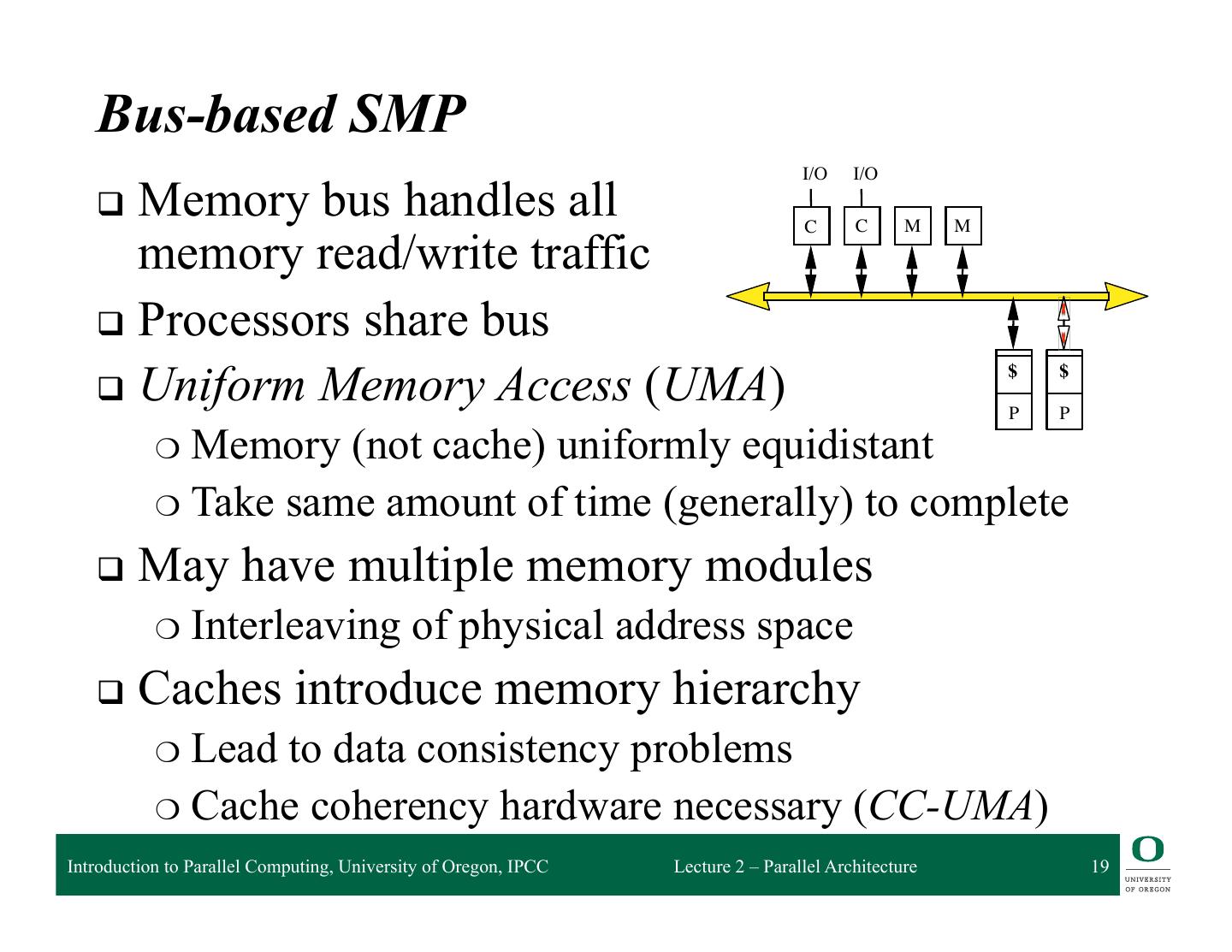
19 . Bus-based SMP I/O I/O q Memory bus handles all C M M C memory read/write traffic q Processors share bus $ $ q Uniform Memory Access (UMA) P P ❍ Memory (not cache) uniformly equidistant ❍ Take same amount of time (generally) to complete q May have multiple memory modules ❍ Interleaving of physical address space q Caches introduce memory hierarchy ❍ Leadto data consistency problems ❍ Cache coherency hardware necessary (CC-UMA) Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 19
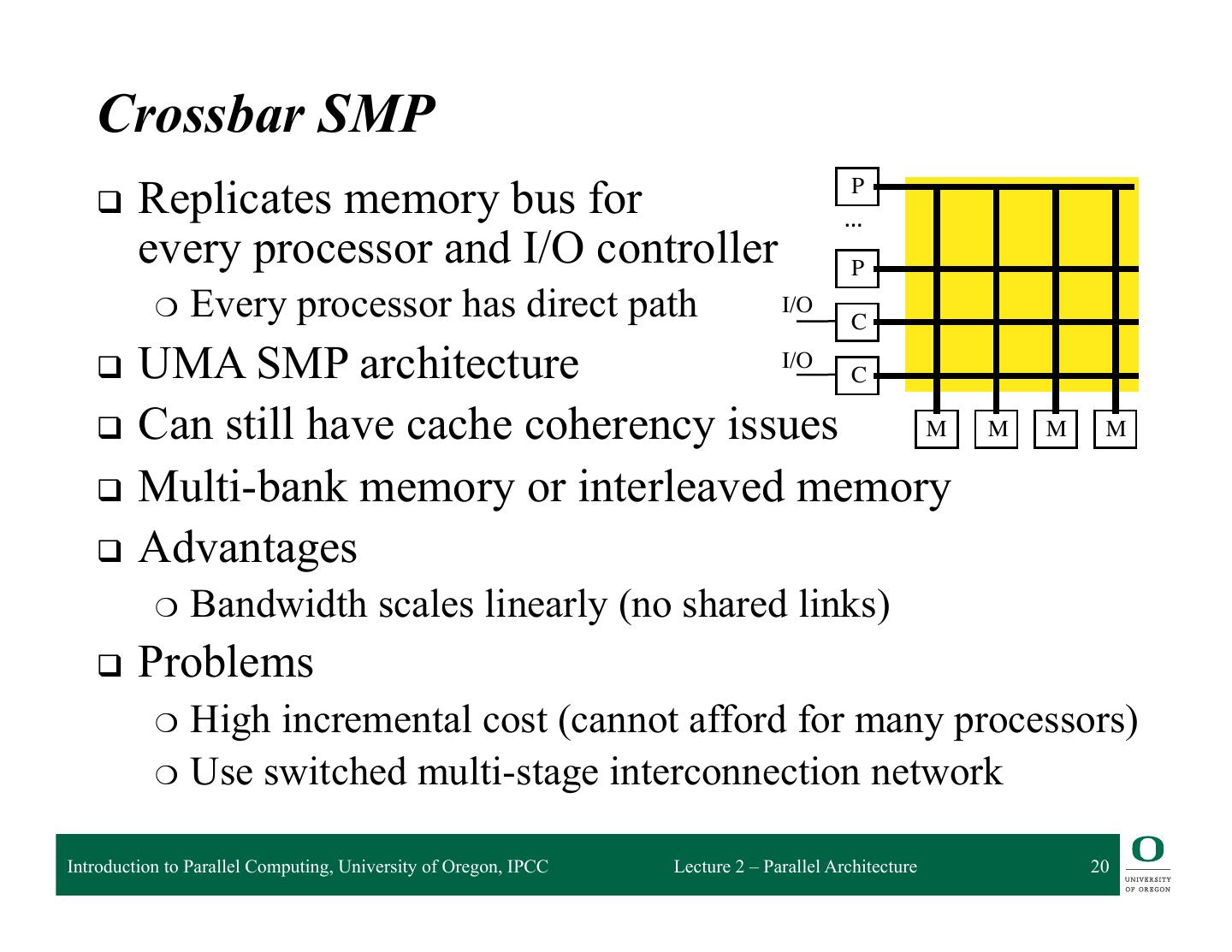
20 . Crossbar SMP P q Replicates memory bus for … every processor and I/O controller P ❍ Every processor has direct path I/O C q UMA SMP architecture I/O C q Can still have cache coherency issues M M M M q Multi-bank memory or interleaved memory q Advantages ❍ Bandwidth scales linearly (no shared links) q Problems ❍ High incremental cost (cannot afford for many processors) ❍ Use switched multi-stage interconnection network Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 20
21 . “Dance Hall” SMP and Shared Cache q Interconnection network connects M M M processors to memory °°° q Centralized memory (UMA) Network q Network determines performance ❍ Continuum from bus to crossbar The The °°° The $ ima $ ima $ ima ❍ Scalable memory bandwidth ge ge ge can can can P P P q Memory is physically separated from processors Main memory (Interleaved) q Could have cache coherence problems q Shared cache reduces coherence First-level $ (Interleaved) problem Switch and provides fine grained data sharing P1 Pn Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 21
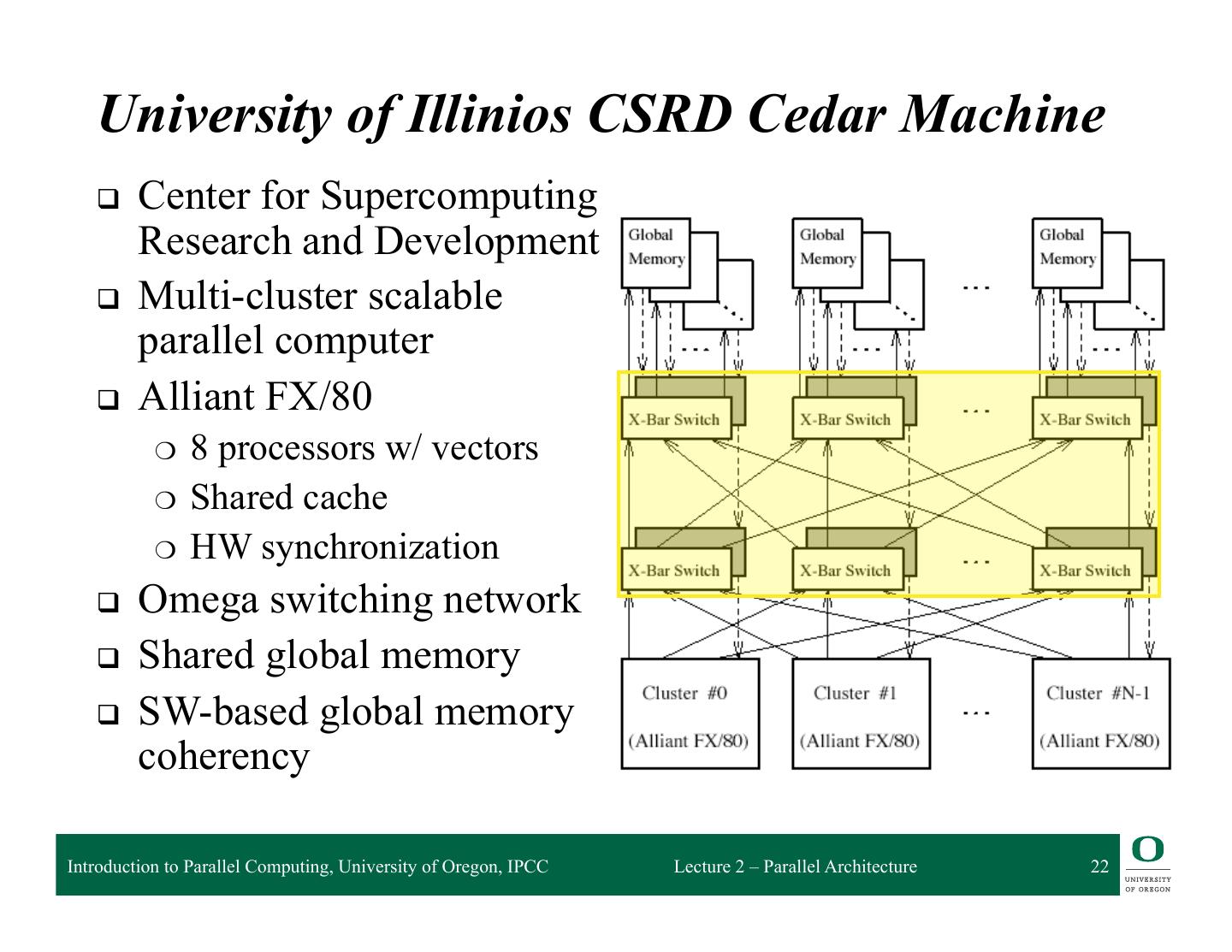
22 . University of Illinios CSRD Cedar Machine q Center for Supercomputing Research and Development q Multi-cluster scalable parallel computer q Alliant FX/80 ❍ 8 processors w/ vectors ❍ Shared cache ❍ HW synchronization q Omega switching network q Shared global memory q SW-based global memory coherency Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 22
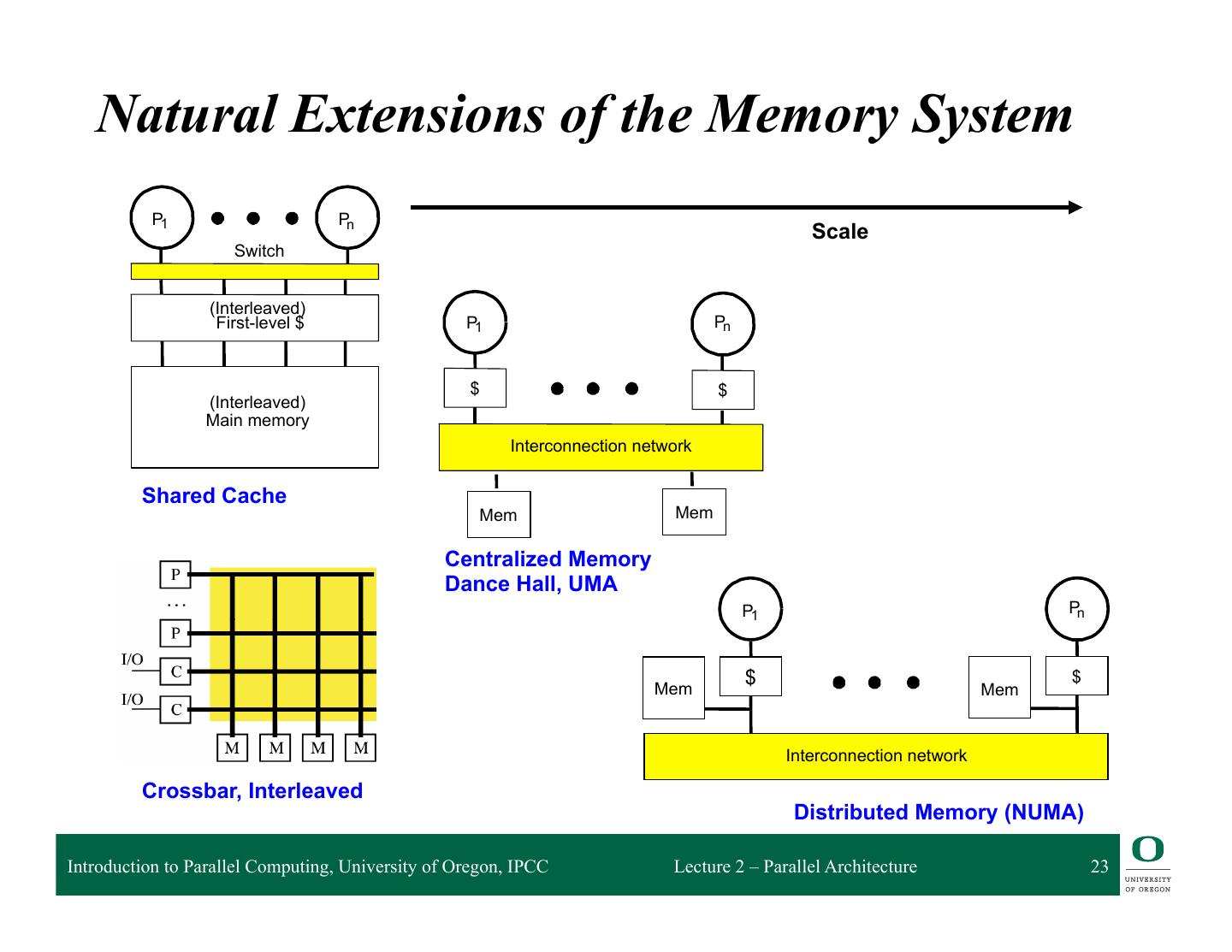
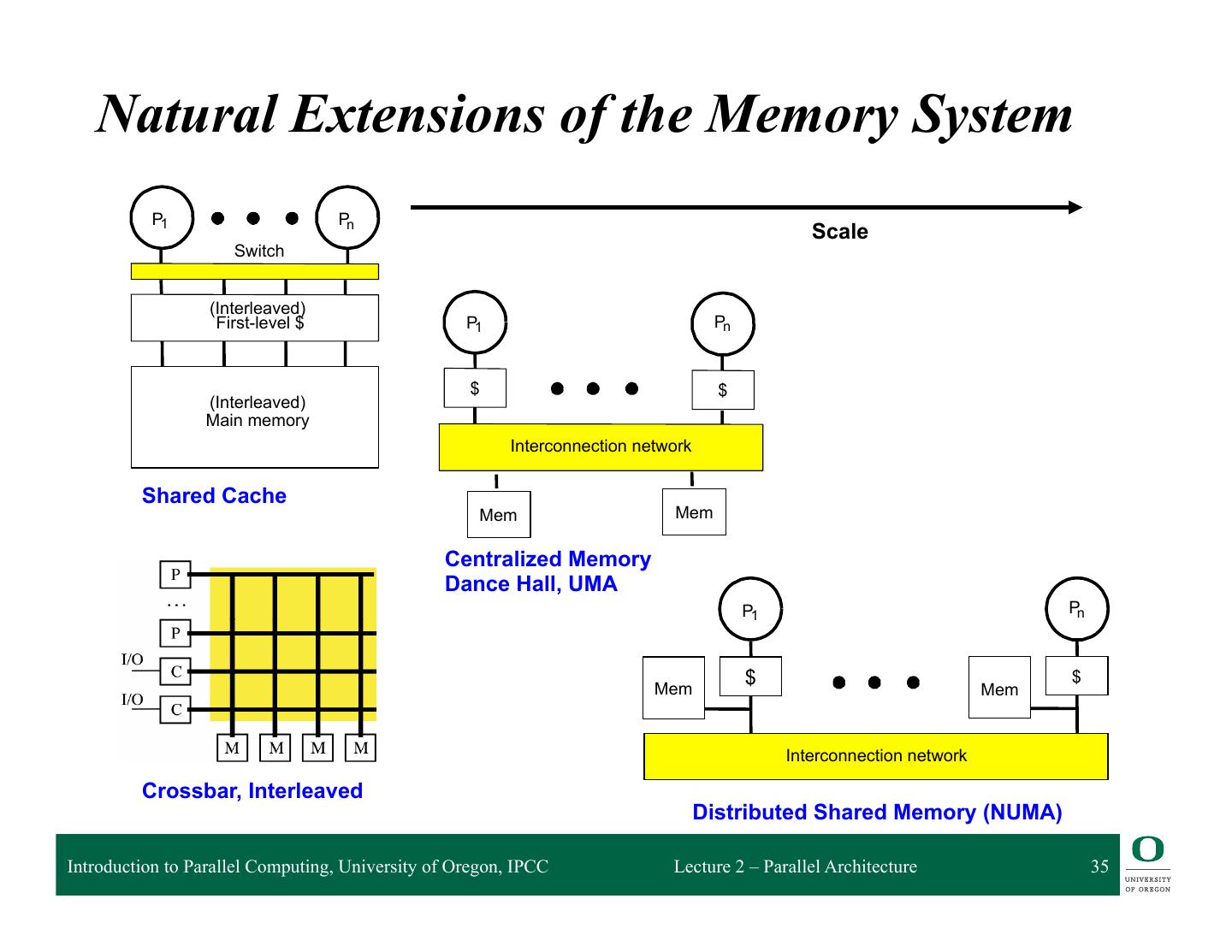
23 . Natural Extensions of the Memory System P1 Pn Scale Switch (Interleaved) First-level $ P1 Pn $ $ (Interleaved) Main memory Interconnection network Shared Cache Mem Mem Centralized Memory Dance Hall, UMA P1 Pn $ $ Mem Mem Interconnection network Crossbar, Interleaved Distributed Memory (NUMA) Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 23
24 . Non-Uniform Memory Access (NUMA) SMPs q Distributed memory Network q Memory is physically resident close to each processor M $ M $ The ima ge can The ima ge can °°° M $ The ima ge can q Memory is still shared P P P q Non-Uniform Memory Access (NUMA) ❍ Local memory and remote memory ❍ Access to local memory is faster, remote memory slower ❍ Access is non-uniform ❍ Performance will depend on data locality q Cache coherency is still an issue (more serious) q Interconnection network architecture is more scalable Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 24
25 . Cache Coherency and SMPs q Caches play key role in SMP performance ❍ Reduce average data access time ❍ Reduce bandwidth demands placed on shared interconnect q Private processor caches create a problem ❍ Copies of a variable can be present in multiple caches ❍ A write by one processor may not become visible to others ◆ they’ll keep accessing stale value in their caches ⇒ Cache coherence problem q What do we do about it? ❍ Organize the memory hierarchy to make it go away ❍ Detect and take actions to eliminate the problem Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 25
26 . Definitions q Memory operation (load, store, read-modify-write, …) q Memory issue is operation presented to memory system q Processor perspective ❍ Write: subsequent reads return the value ❍ Read: subsequent writes cannot affect the value q Coherent memory system ❍ There exists a serial order of memory operations on each location such that ◆ operations issued by a process appear in order issued ◆ value returned by each read is that written by previous write ⇒ write propagation + write serialization Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 26
27 . Motivation for Memory Consistency q Coherence implies that writes to a location become visible to all processors in the same order q But when does a write become visible? q How do we establish orders between a write and a read by different processors? ❍ Use event synchronization q Implement hardware protocol for cache coherency q Protocol will be based on model of memory consistency P1 P2 /* Assume initial value of A and flag is 0 */ A = 1; spin idly */ while (flag == 0); /* flag = 1; print A; Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 27
28 . Memory Consistency q Specifies constraints on the order in which memory operations (from any process) can appear to execute with respect to each other ❍ What orders are preserved? ❍ Given a load, constrains the possible values returned by it q Implications for both programmer and system designer ❍ Programmer uses to reason about correctness ❍ System designer can use to constrain how much accesses can be reordered by compiler or hardware q Contract between programmer and system Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 28
29 . Sequential Consistency q Total order achieved by interleaving accesses from different processes ❍ Maintains program order ❍ Memory operations (from all processes) appear to issue, execute, and complete atomically with respect to others ❍ As if there was a single memory (no cache) “A multiprocessor is sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.” [Lamport, 1979] Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 29
3秒后跳转登录页面
去登陆

