








































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u3818/Introduction_to_Spark?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
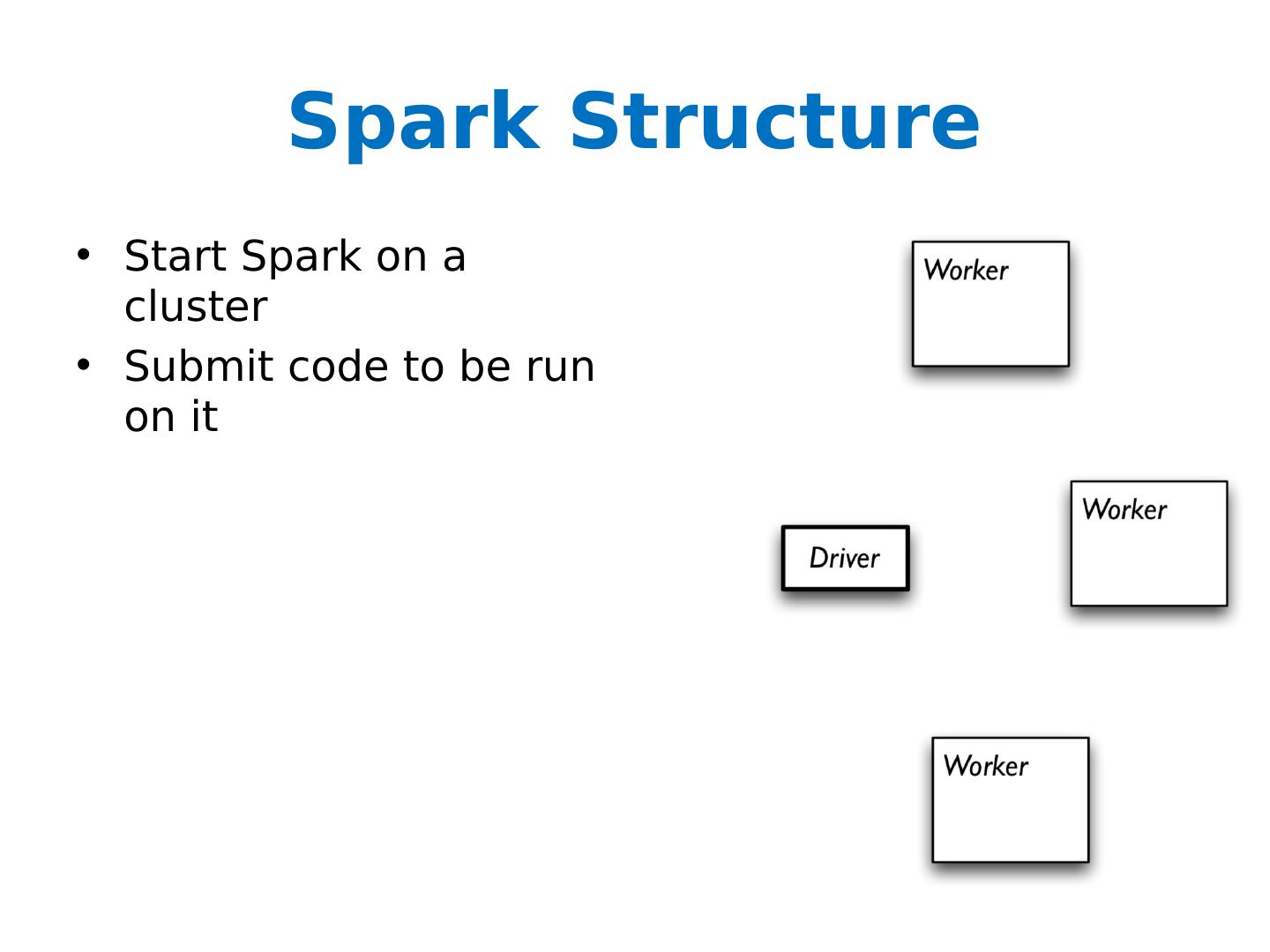
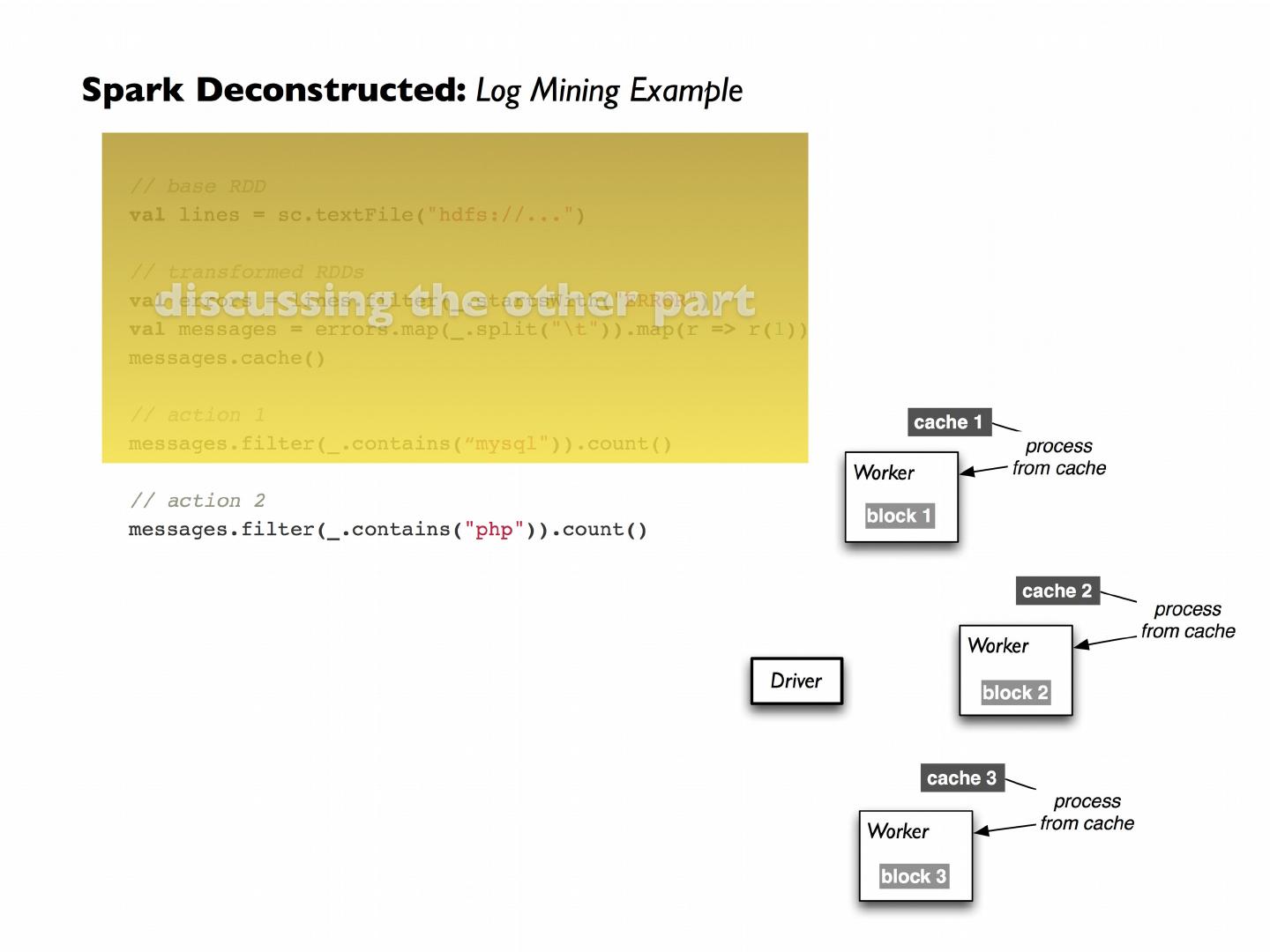
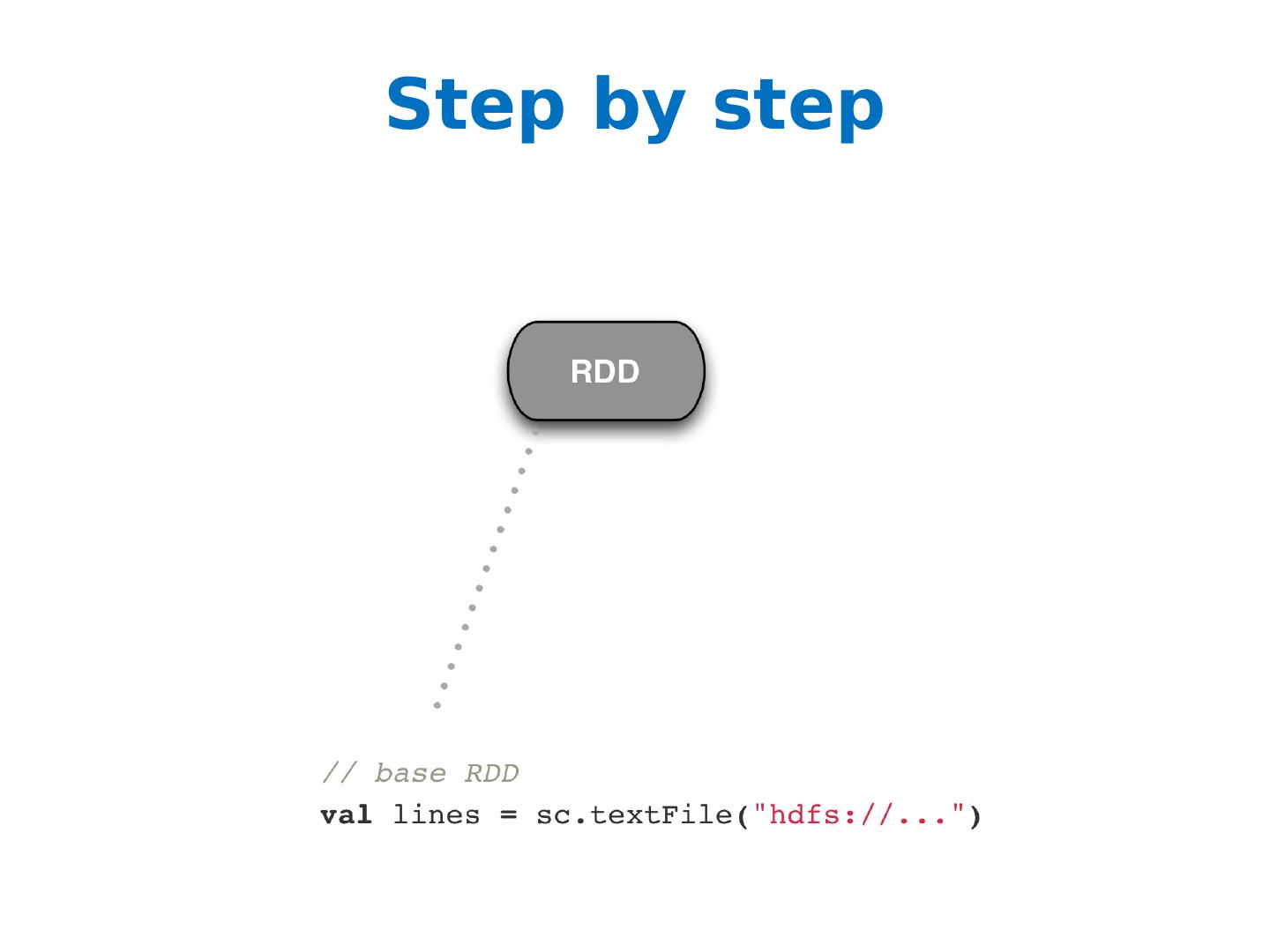
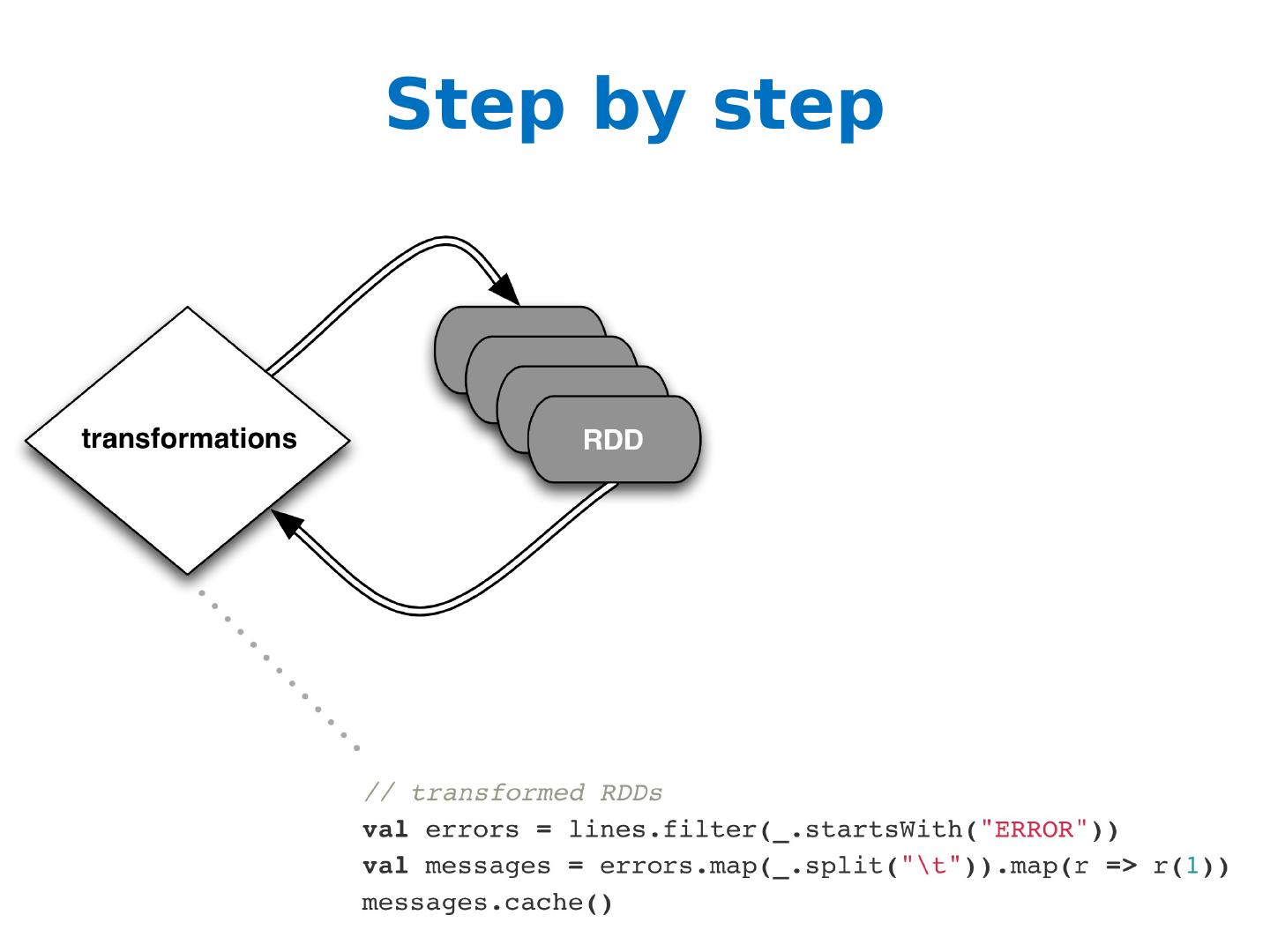
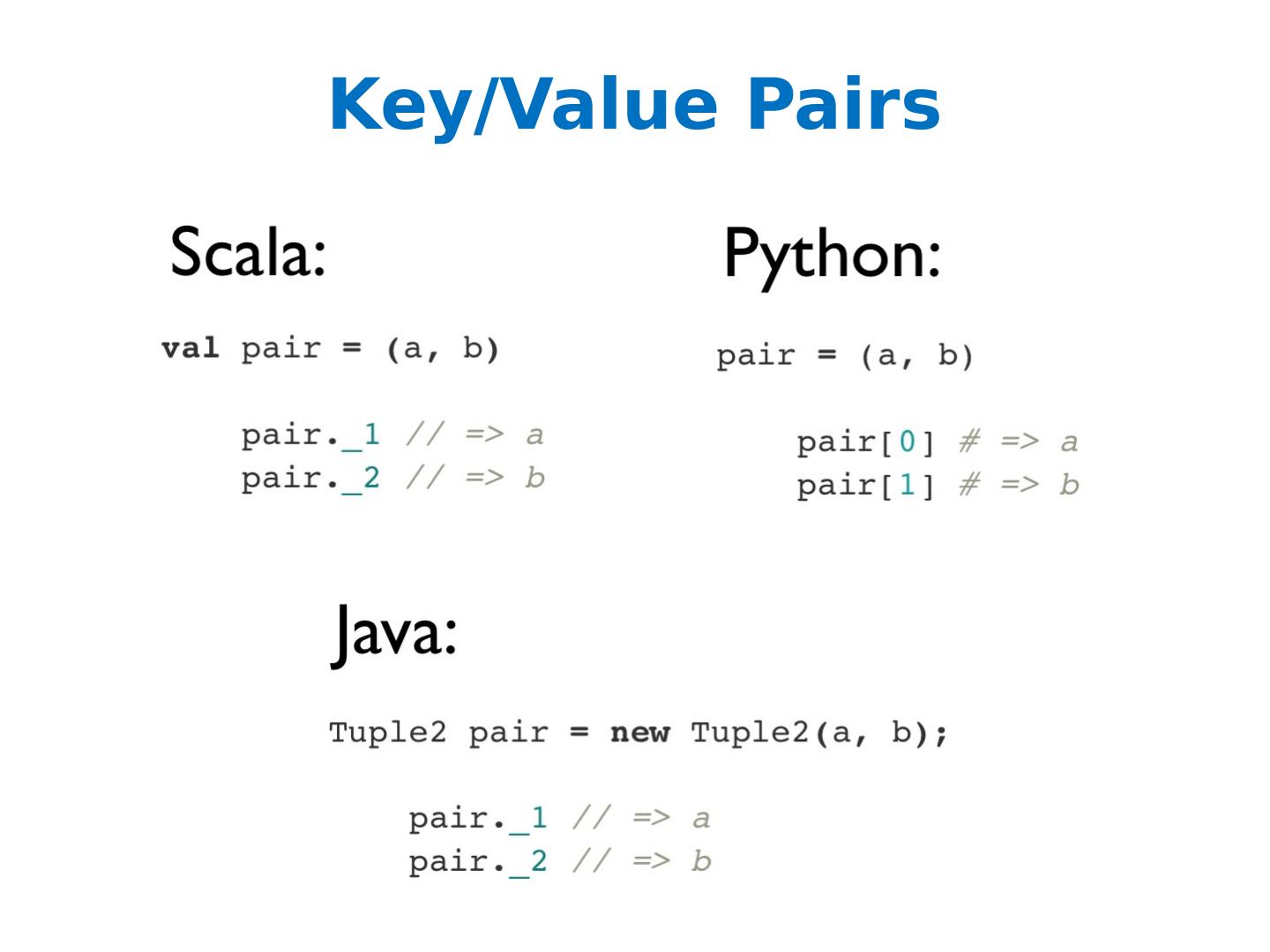
Introduction to Spark
点赞
7
收藏
4
下载 1
Spark’s goal was to generalize MapReduce to support new applications within the same engine
Two additions:
Fast data sharing
General DAGs (directed acyclic graphs)
Best of both worlds: easy to program & more efficient engine in general

