

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u3819/Benchmarking_SQL_On_MapReduce_Systems?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Benchmarking SQL-On-MapReduce Systems
分享
点赞
15
收藏
4
下载 0
Benchmarking SQL-On-MapReduce Systems
展开查看详情
1 .Amin Mesmoudi , Mohand-Saïd Hacid and Farouk Toumani Benchmarking SQL-On- MapReduce Systems
2 .Context Recordings every 15 s, 1 visit / 3 days 10 years , 60 PB http://com.isima.fr/Petasky https://www.lsst.org/ XLDB 2017, Clermont-Ferrand, 10-12 October 2017 2
3 .LSST Science goals What is the mysterious dark energy that is driving the acceleration of the cosmic expansion? What is dark matter , how is it distributed , and how do its properties affect the formation of stars , galaxies , and larger structures ? How did the Milky Way form , and how has its present configuration been modified by mergers with smaller bodies over cosmic time? What is the nature of the outer regions of the solar system? Is it possible to make a complete inventory of smaller bodies in the solar system, especially the potentially hazardous asteroids that could someday impact the Earth ? Are there new exotic and explosive phenomena in the universe that have not yet been discovered ? … LSST project: conduct a deep survey over an enormous area of sky; taking repeat images of every part of the sky every few nights in multiple bands, or segments of the electromagnetic spectrum; and continue in this mode for ten years . The result will be astronomical catalogs containing the data necessary to begin searching for answers. https://www.lsst.org/science XLDB 2017, Clermont-Ferrand, 10-12 October 2017 3
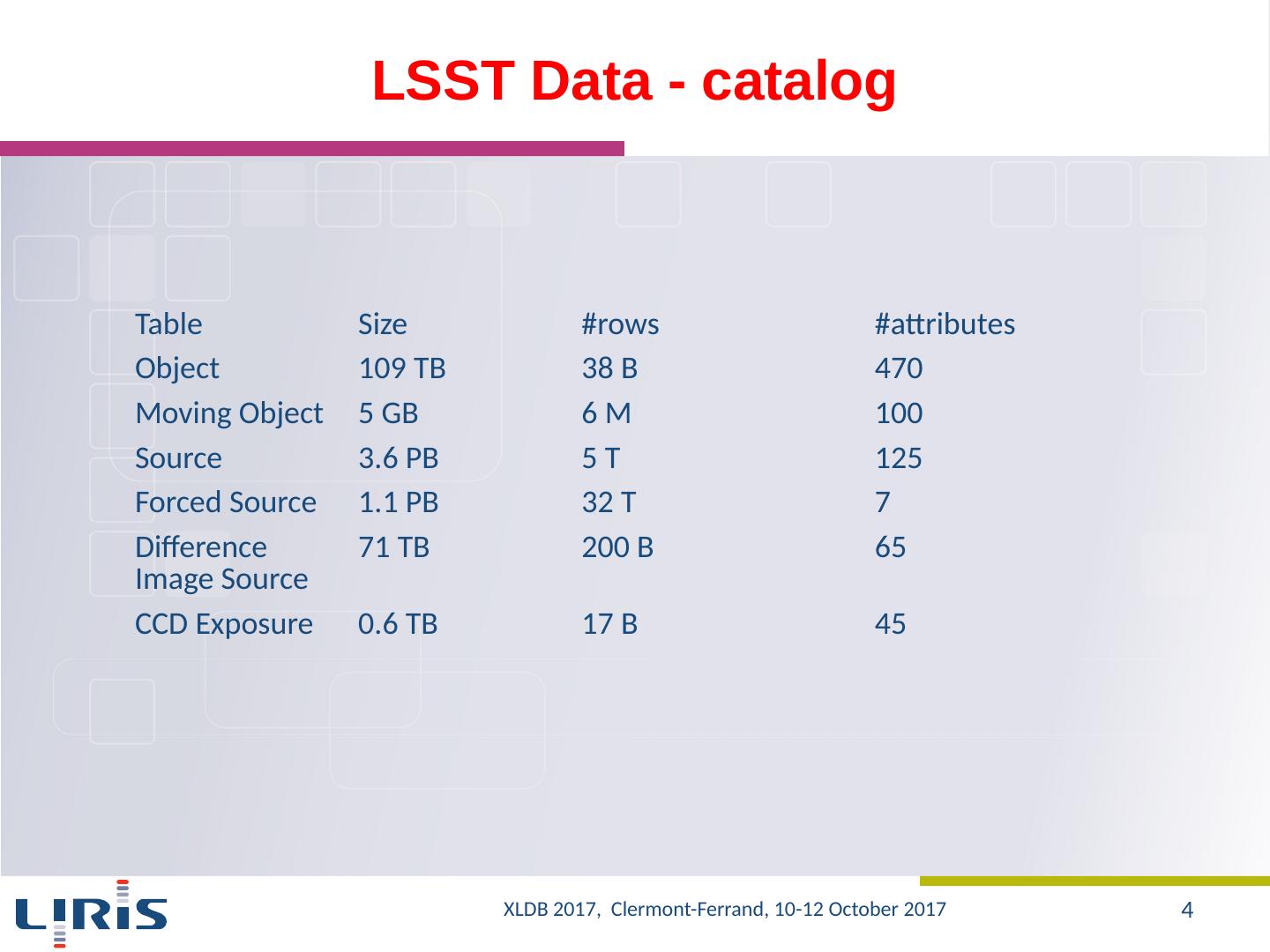
4 .LSST Data - catalog Table Size # rows # attributes Object 109 TB 38 B 470 Moving Object 5 GB 6 M 100 Source 3.6 PB 5 T 125 Forced Source 1.1 PB 32 T 7 Difference Image Source 71 TB 200 B 65 CCD Exposure 0.6 TB 17 B 45 XLDB 2017, Clermont-Ferrand, 10-12 October 2017 4
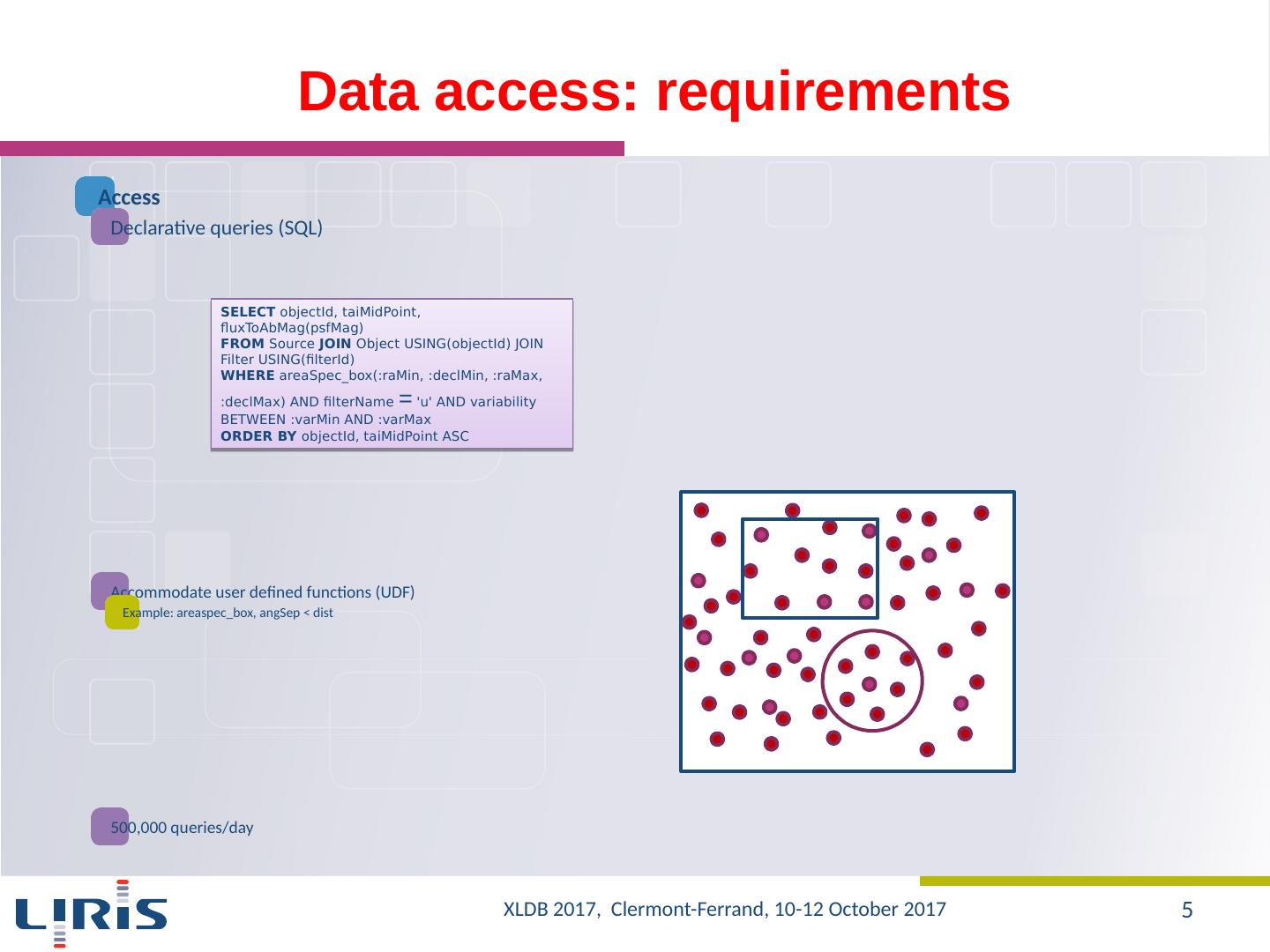
5 .Data access : requirements Access Declarative queries (SQL) Accommodate user defined functions (UDF) Example : areaspec_box , angSep < dist 500,000 queries / day SELECT objectId , taiMidPoint , fluxToAbMag ( psfMag ) FROM Source JOIN Object USING( objectId ) JOIN Filter USING( filterId ) WHERE areaSpec_box (: raMin , : declMin , : raMax , : declMax ) AND filterName = u AND variability BETWEEN : varMin AND : varMax ORDER BY objectId , taiMidPoint ASC XLDB 2017, Clermont-Ferrand, 10-12 October 2017 5
6 .Queries https://dev.lsstcorp.org/trac/wiki/db/queries http ://com.isima.fr/Petasky/groups/sous-groupe1/queries-1 SQL Syntax Meaning SELECT * FROM source WHERE sour ceid =2875056747578937; Retrieve the tuples with a known id (here 2875056747578937) from the Source table SELECT sourceid , taimidpoint FROM source WHERE sourceid =386942193644115 AND scienceccdexposureid =43856065114; Retrieve values of the taimidpoint attribute of the tuples identified by both sourceid (386942193644115) and sci enceccdexposureid (43856065114) SELECT sourceid , taimidpoint FROM source WHERE sourceid =386942193644115; Retrieve values of the taimidpoint attribute of the tuples source identified by sourceid (386942193644115) SELECT * FROM source JOIN object ON ( source.objectid = object.objectid ) WHERE source.objectid =386942193646211; Join the two tables source and object to retrieve all values of tuples with a known sourceid SELECT objectid , count( sourceid ) FROM source GROUP BY objectid ; Retrieve values of the objectid attribute and the number of sourceid related to this objectid SELECT objectid,sourceid FROM source ORDER BY objectid ; Grouping all values of the attributes objectid and sourceid with respect to objectid attribute … … XLDB 2017, Clermont-Ferrand, 10-12 October 2017 6
7 .Objectives A distributed architecture capable to store a few PB of data Open Source Shared -Nothing Evaluate both simple queries (a few seconds ) and complex queries ( hours of computation) XLDB 2017, Clermont-Ferrand, 10-12 October 2017 7
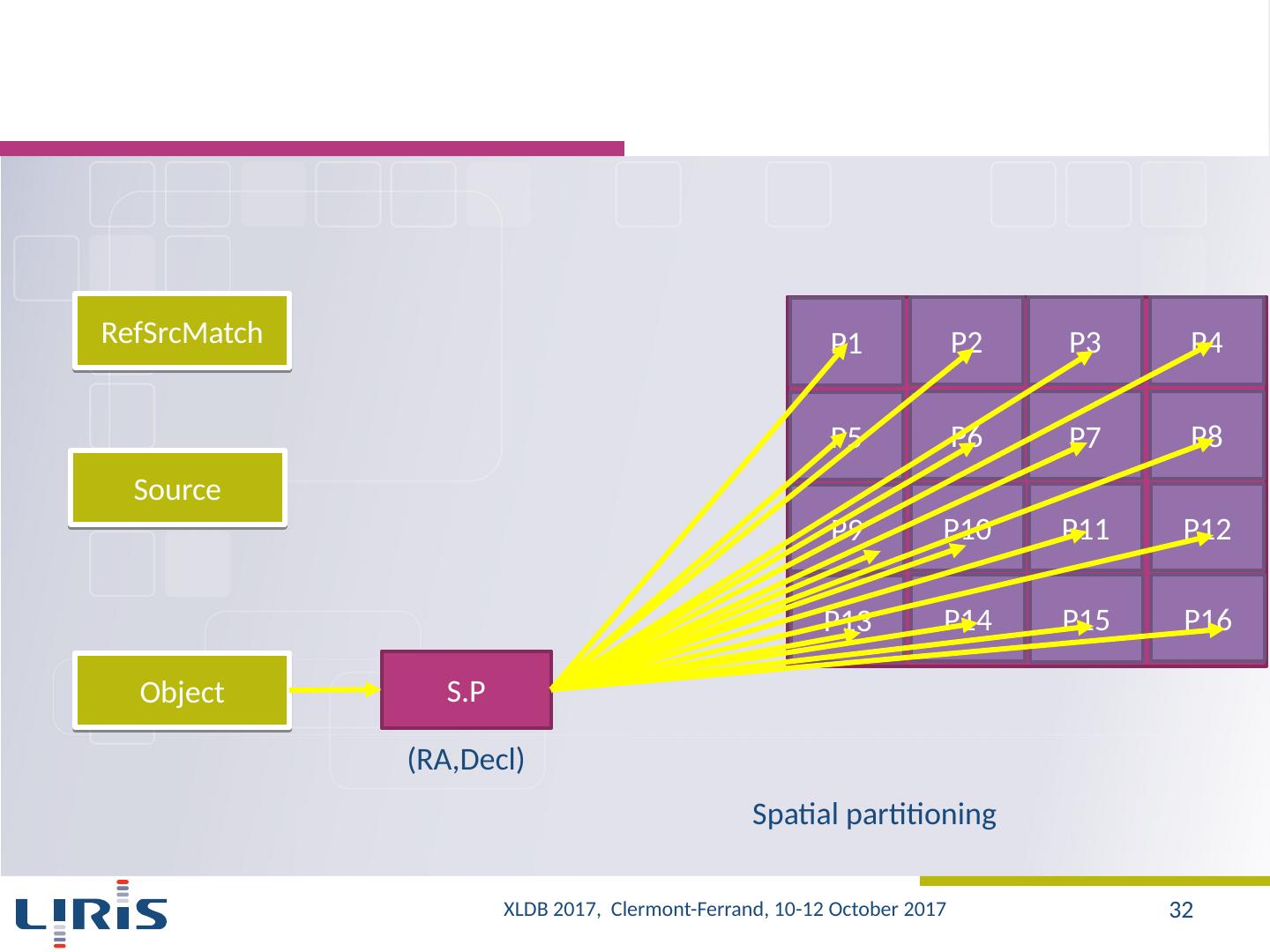
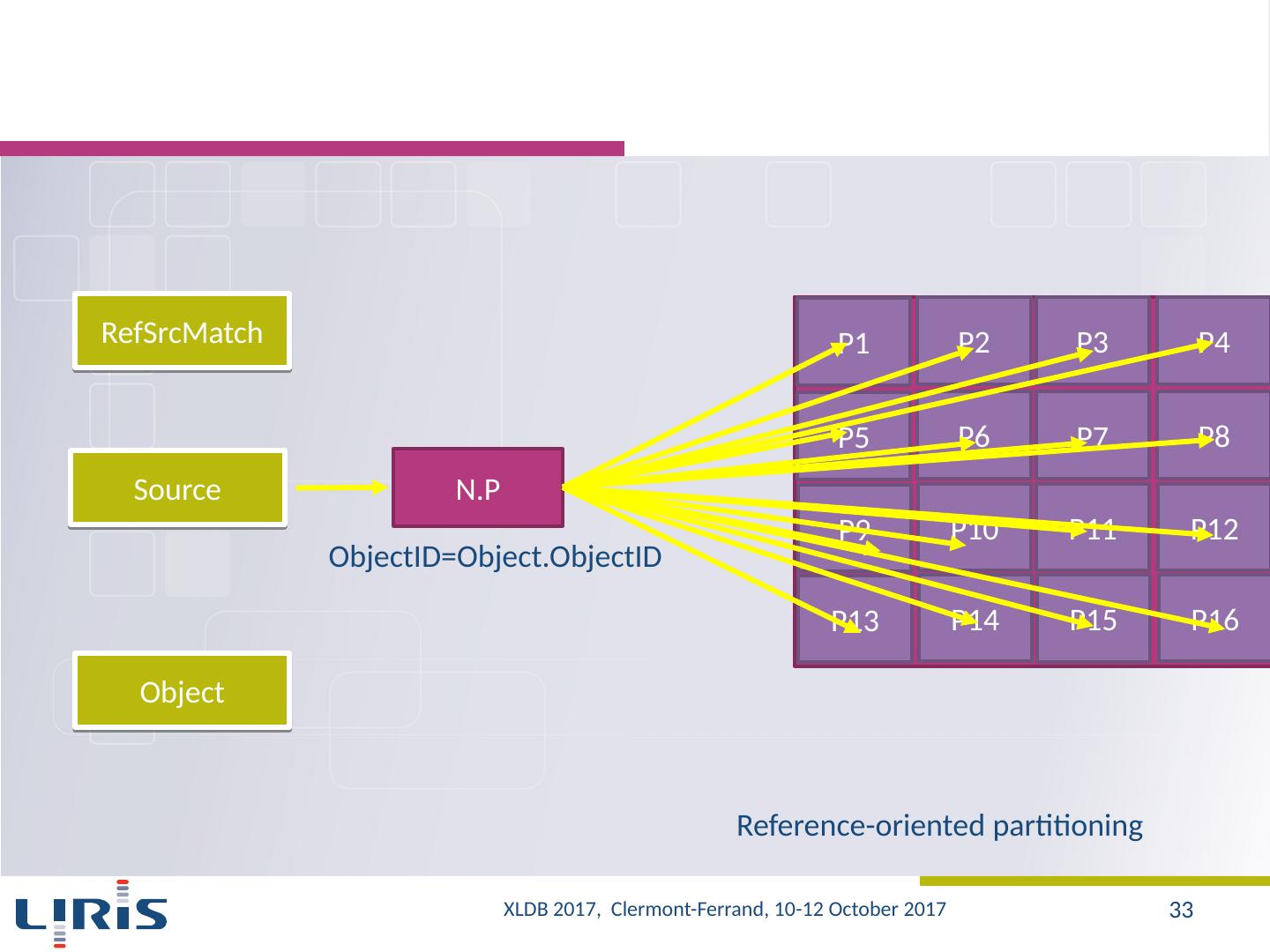
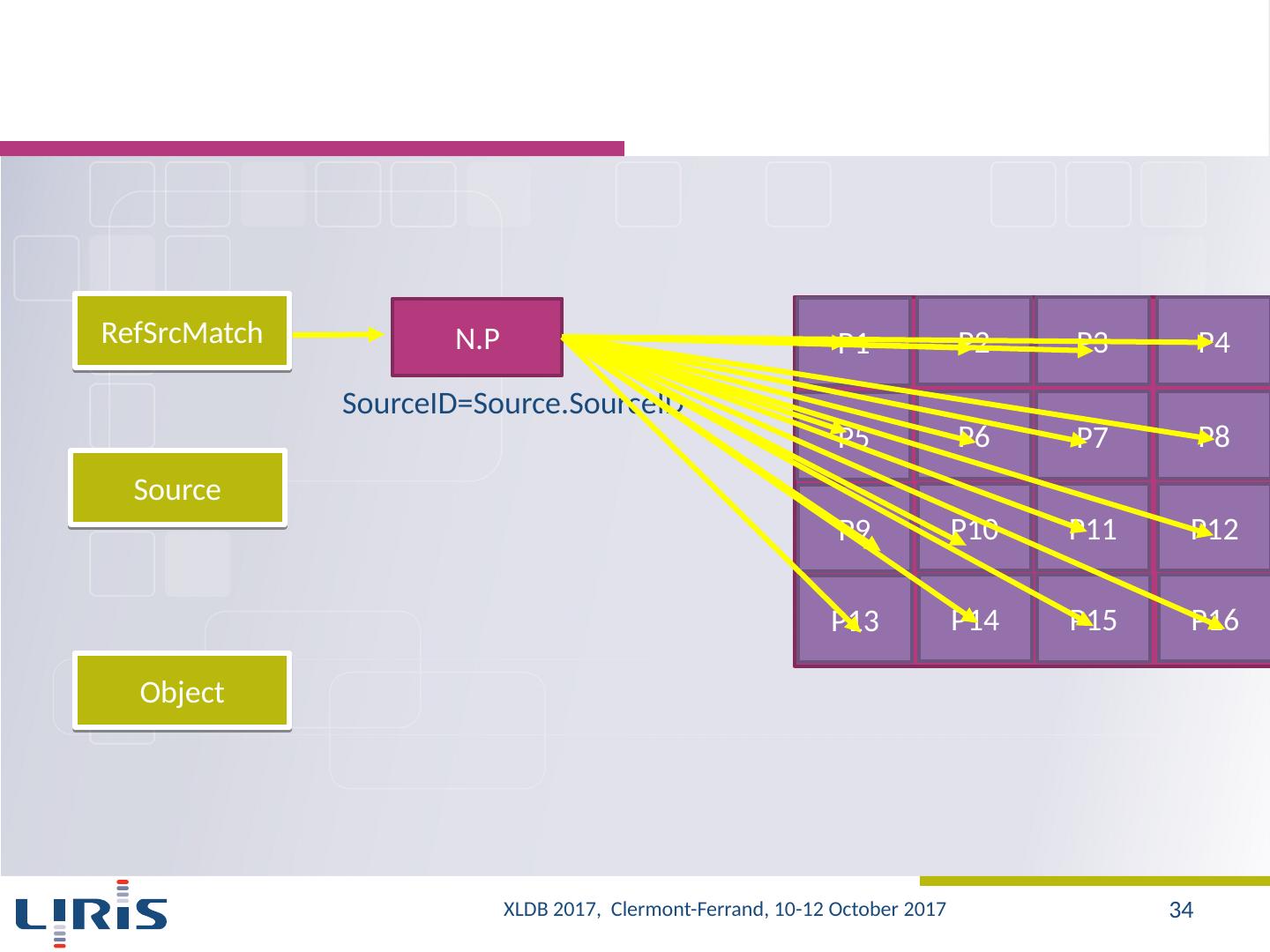
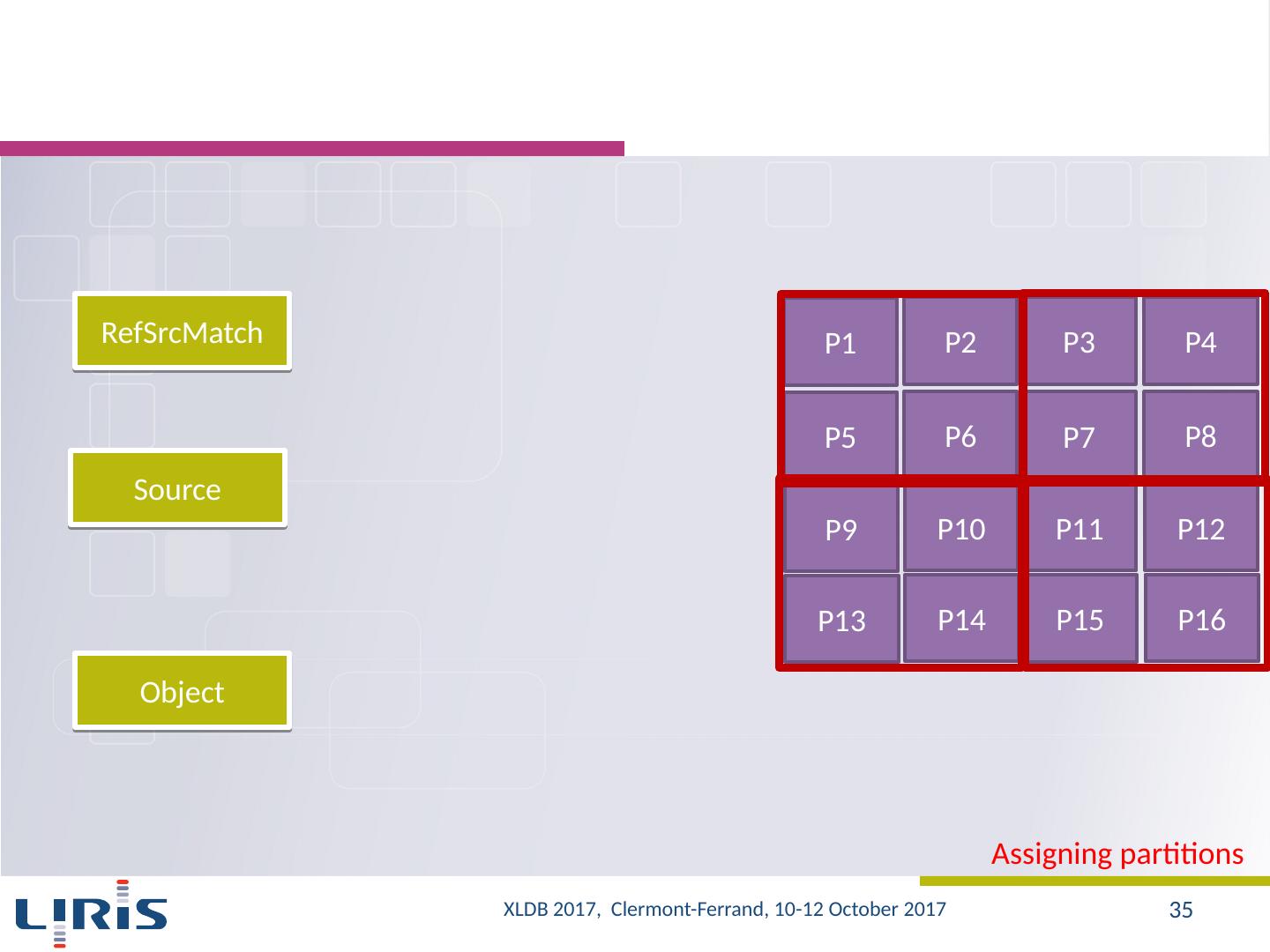
8 .Our approach Evaluation of the capabilities of existing systems (on LSST data samples) SQL-based MapReduce systems A new architecture Storage Partitioning Parallel evaluation of queries Optimization strategies Selection and planning of the execution of sub-queries Changing the location for partitions XLDB 2017, Clermont-Ferrand, 10-12 October 2017 8
9 .Evaluation campaign http ://com.isima.fr/Petasky/hive-vs-hadoopdb XLDB 2017, Clermont-Ferrand, 10-12 October 2017 9
10 .Experiment setting Data sets displaying same features as data expected from the capture 250 GB of data ( generated by simulations) provided by LSST group Additional data were generated 500 GB, 1 TB and 2 TB Characterization of queries according to the required evaluation time Identification of 13 queries compatible with existing systems SELECTION, PROJECTION, JOIN, GROUP BY and ORDER BY A platform with 100 virtual machines 3 Clusters: 25, 50 and 100 machines 350 GB disk 8 GB RAM XLDB 2017, Clermont-Ferrand, 10-12 October 2017 10
11 .Approach (1/2) Data management systems : Parallel ( Map / Reduce based ): Hive and HadoopDB Metrics for evaluation of existing systems : Loading and execution time Scalability : #machines and data volumes Evaluation of available optimization techniques (data compression, parallel processing , indexing , buffering …) XLDB 2017, Clermont-Ferrand, 10-12 October 2017 11
12 .Approach (2/2) Different configurations Indexing Indexed vs. non indexed data 5 indexes Data 250 GB vs. 500 GB vs. 1 TB vs. 2 TB Partitioning Partitioning linked to query samples vs. Partitioning not linked to query samples Clusters 25 vs. 50 Hive vs. HadoopDB Queries : Q1-Q11 Loading time Execution time XLDB 2017, Clermont-Ferrand, 10-12 October 2017 12
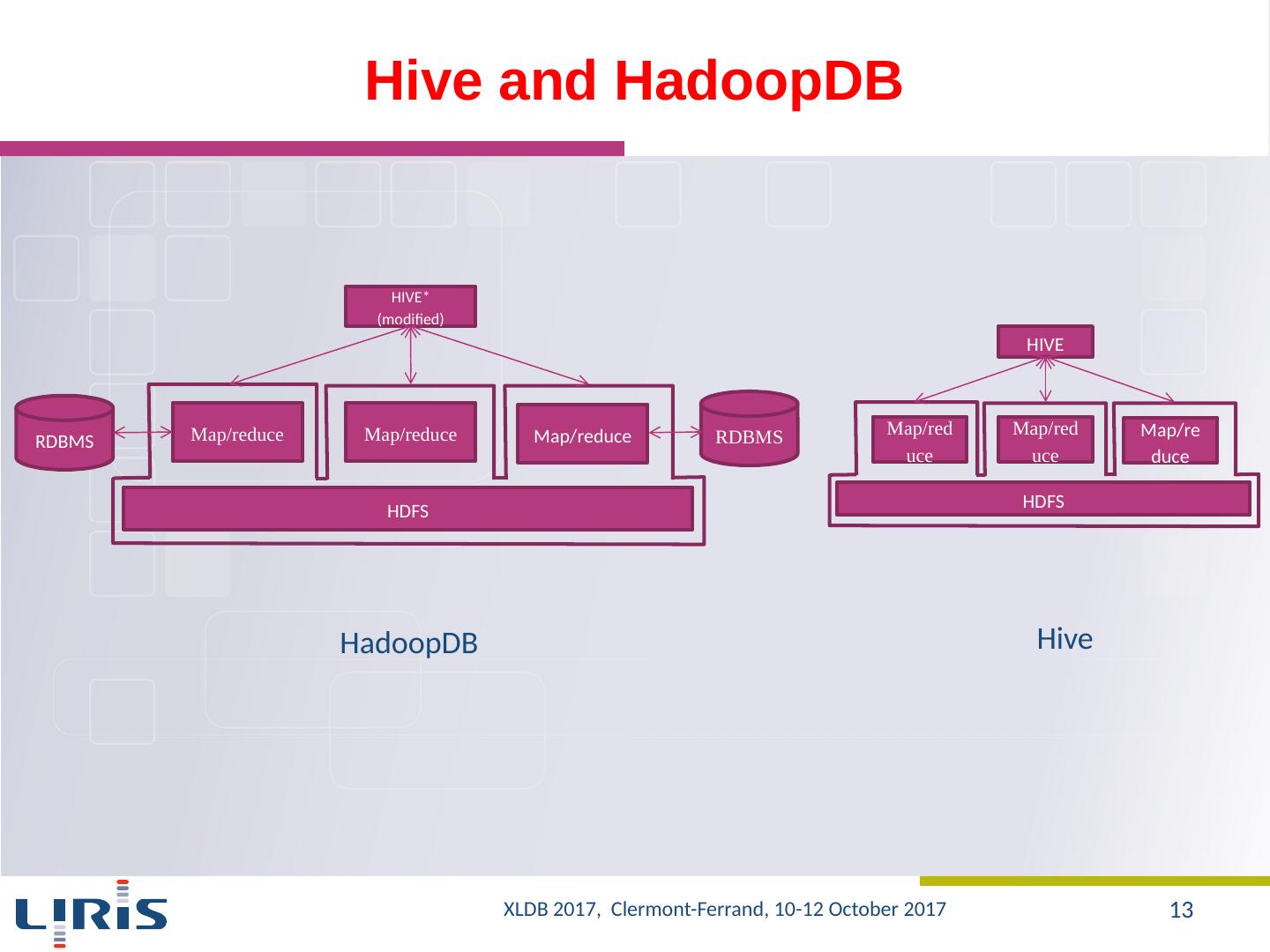
13 .Hive and HadoopDB Map/reduce Map/reduce Map/reduce HDFS HIVE Map/reduce Map/reduce Map/reduce HDFS HIVE* ( modified ) RDBMS RDBMS HadoopDB Hive XLDB 2017, Clermont-Ferrand, 10-12 October 2017 13
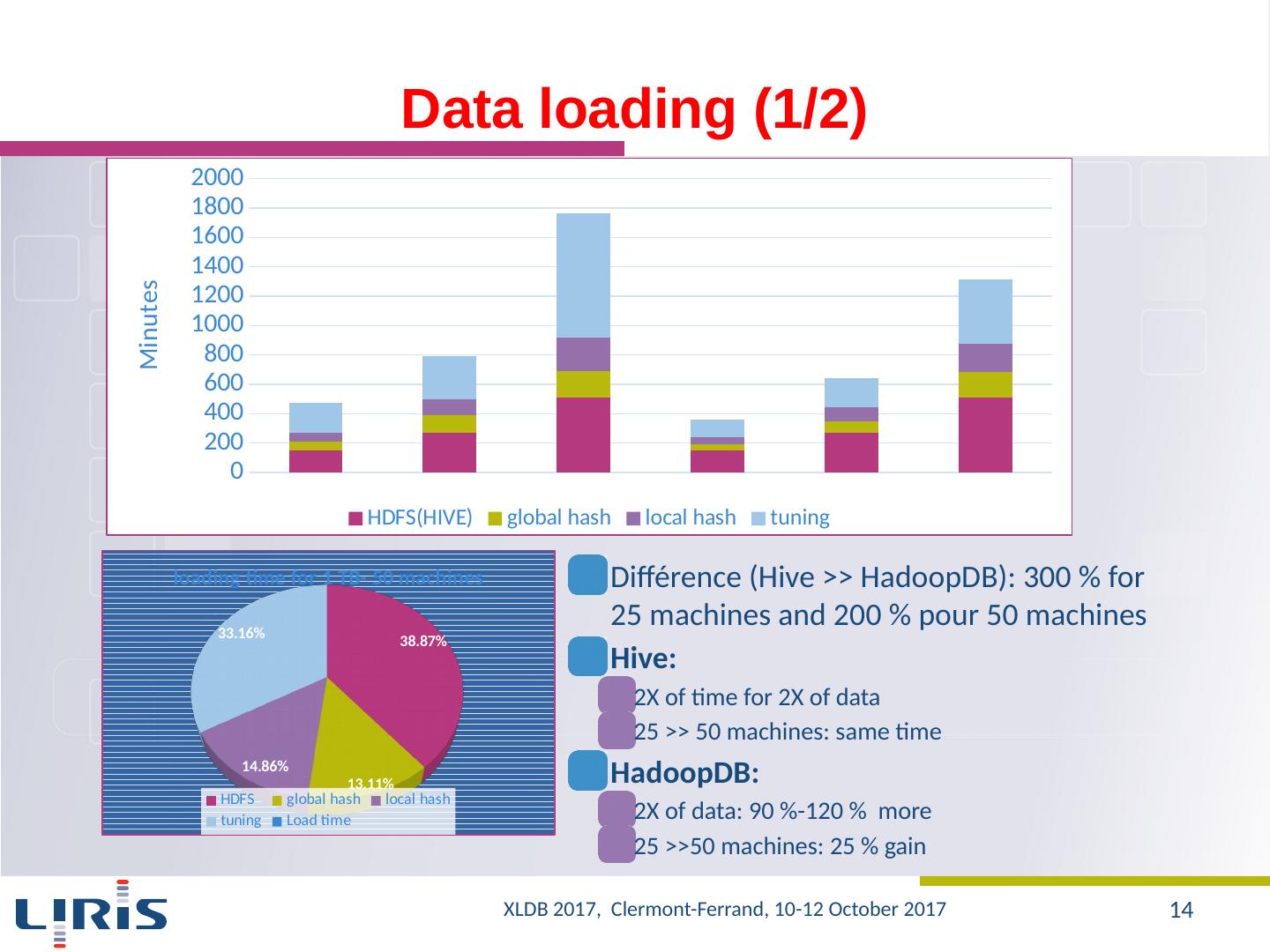
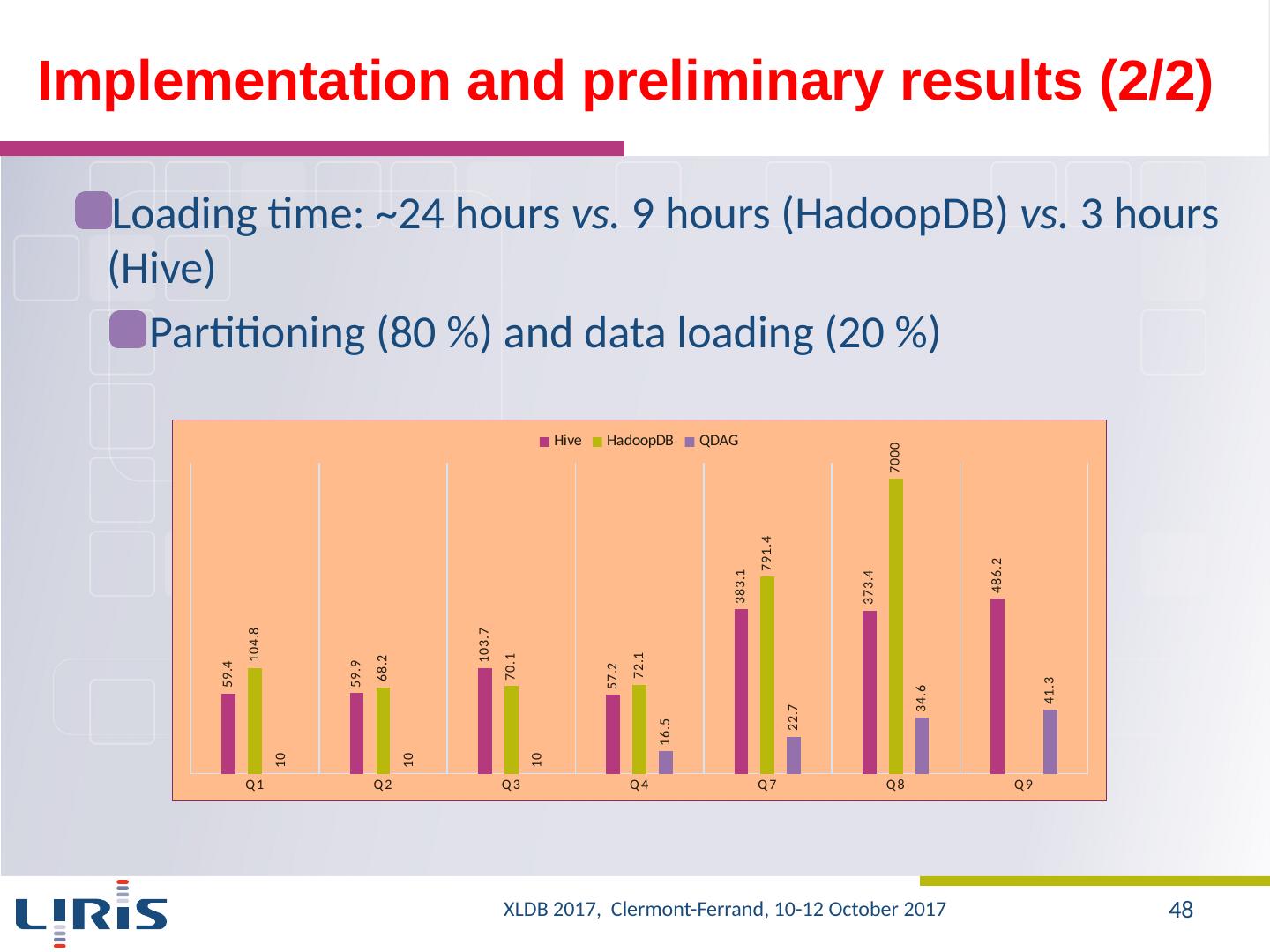
14 .Data loading (1/2) Différence ( Hive >> HadoopDB ): 300 % for 25 machines and 200 % pour 50 machines Hive : 2X of time for 2X of data 25 >> 50 machines: same time HadoopDB : 2X of data: 90 %-120 % more 25 >>50 machines: 25 % gain XLDB 2017, Clermont-Ferrand, 10-12 October 2017 14
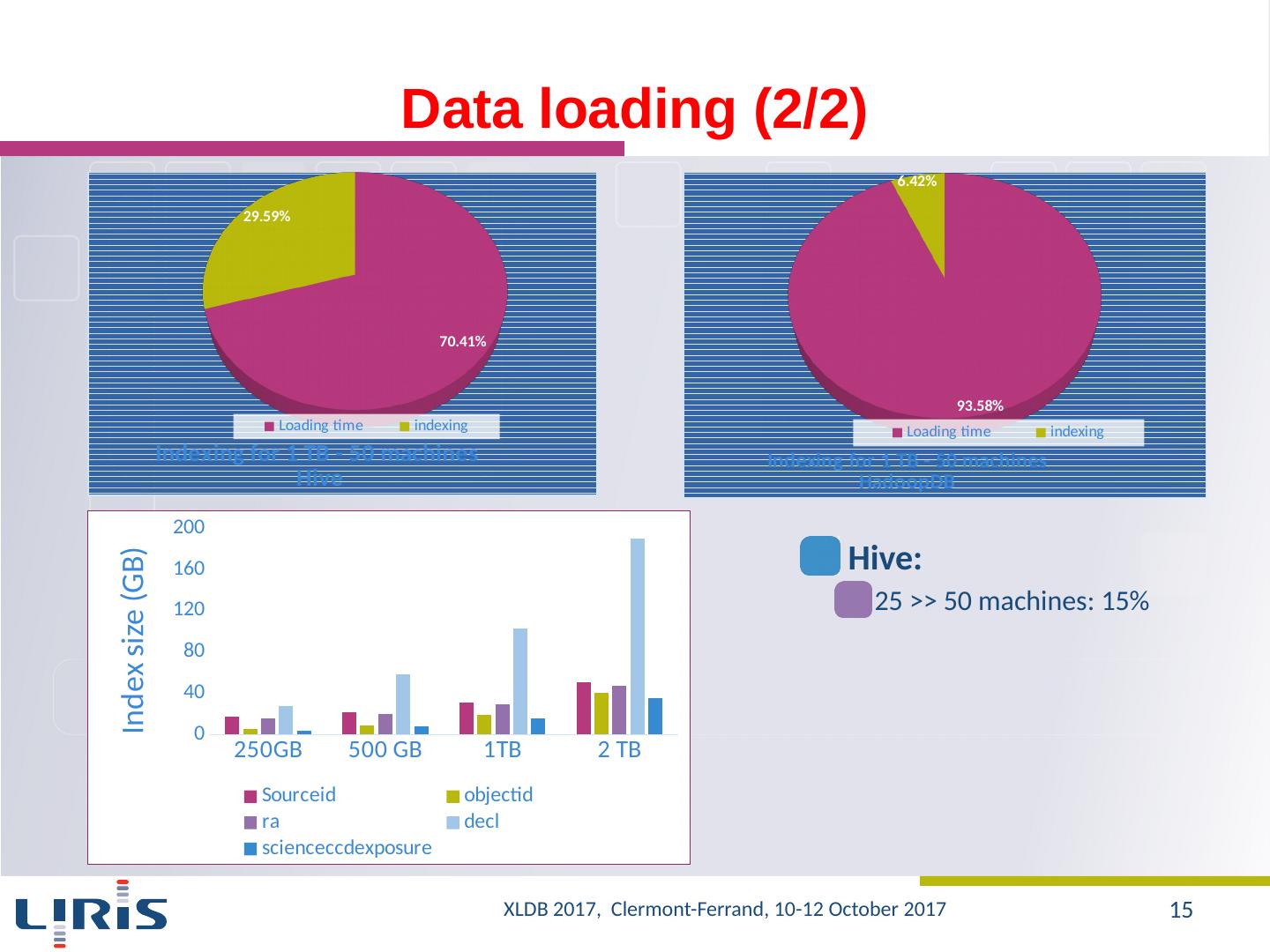
15 .Data loading (2/2) Hive : 25 >> 50 machines: 15% XLDB 2017, Clermont-Ferrand, 10-12 October 2017 15
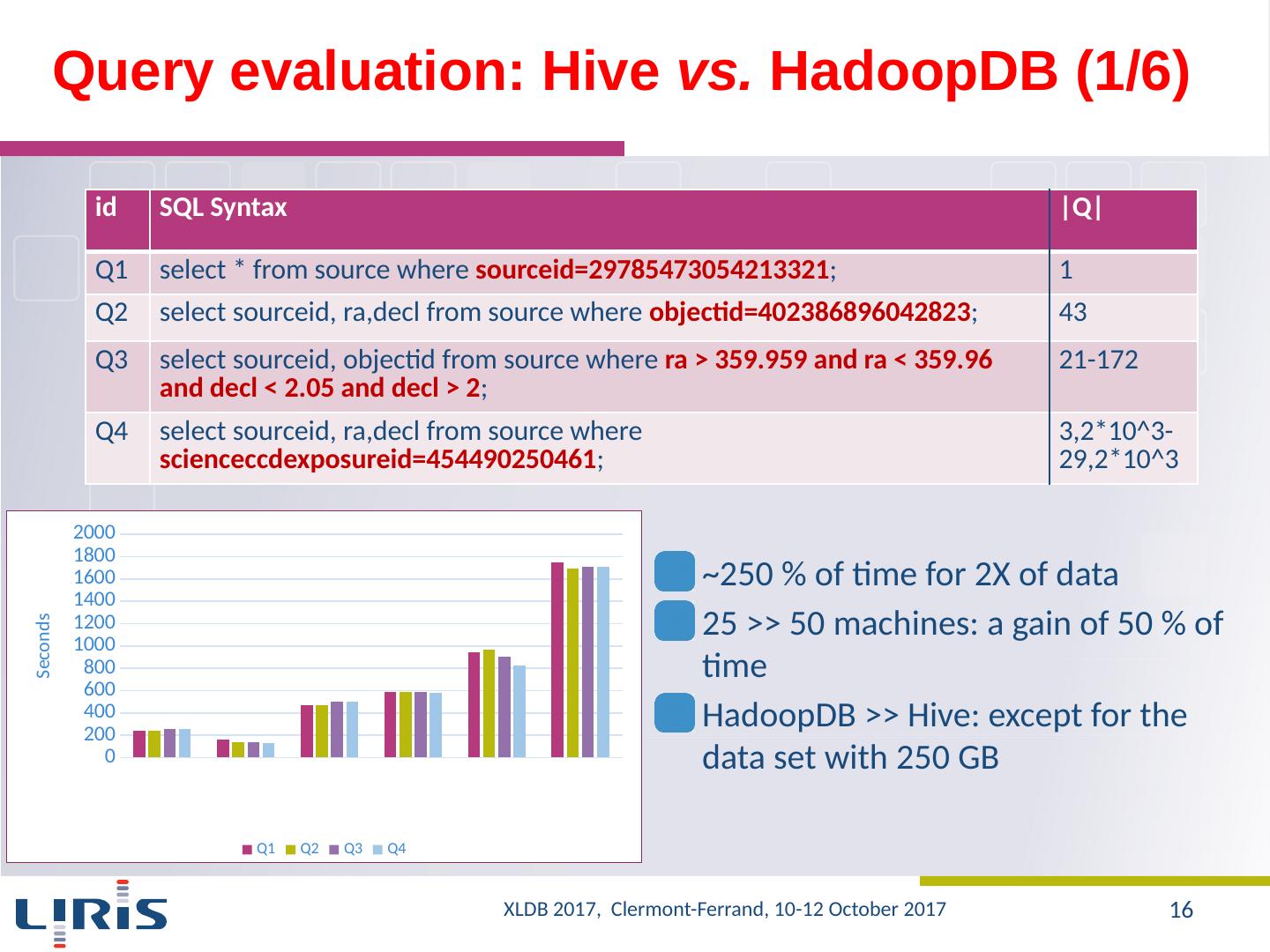
16 .Query evaluation : Hive vs. HadoopDB (1/6) ~250 % of time for 2X of data 25 >> 50 machines: a gain of 50 % of time HadoopDB >> Hive : except for the data set with 250 GB id SQL Syntax |Q| Q1 select * from source where sourceid =29785473054213321 ; 1 Q2 select sourceid , ra,decl from source where objectid =402386896042823 ; 43 Q3 select sourceid , objectid from source where ra > 359.959 and ra < 359.96 and decl < 2.05 and decl > 2 ; 21-172 Q4 select sourceid , ra,decl from source where scienceccdexposureid =454490250461 ; 3,2*10^3- 29,2*10^3 XLDB 2017, Clermont-Ferrand, 10-12 October 2017 16
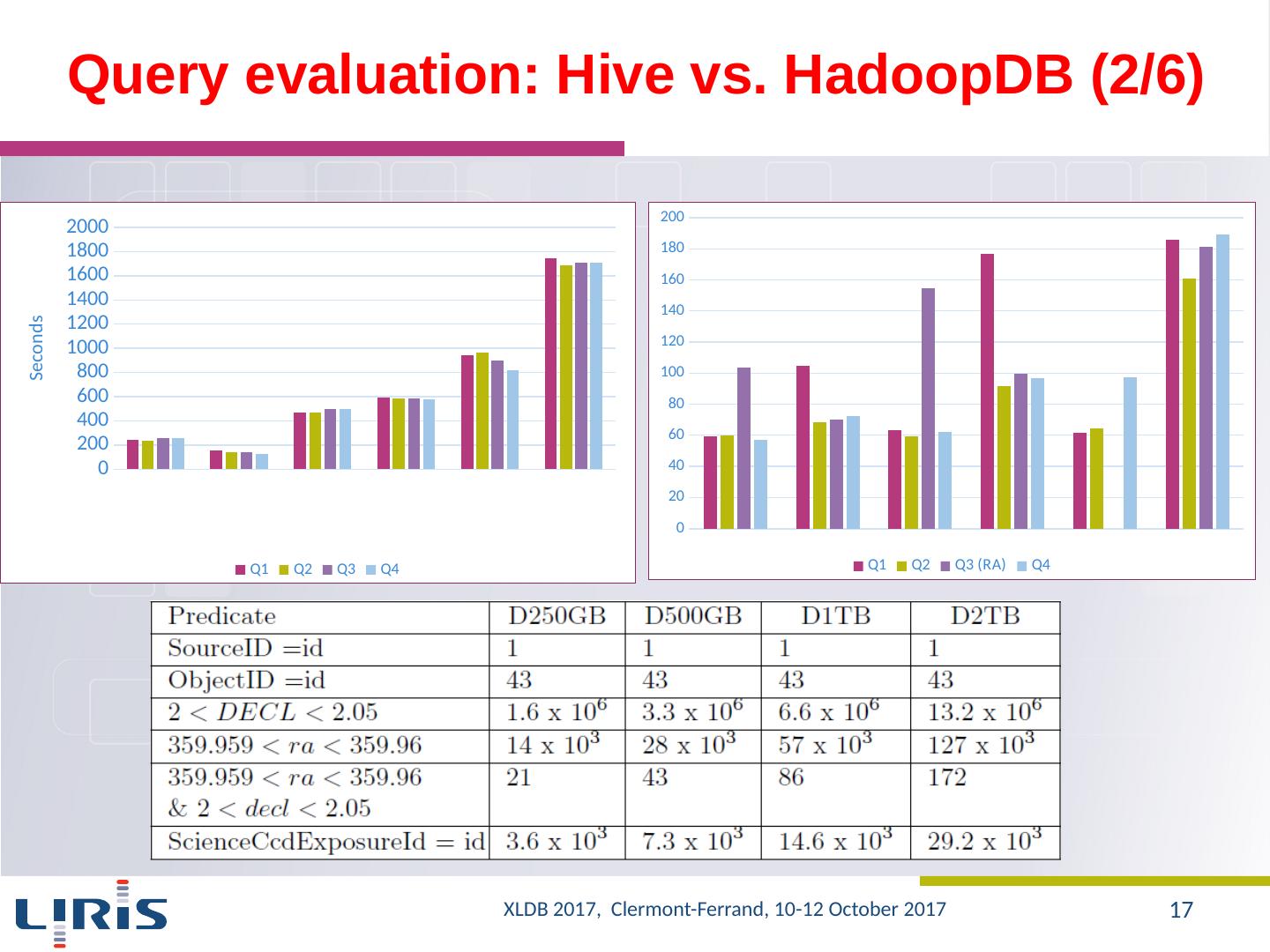
17 .Query evaluation : Hive vs. HadoopDB (2/6) XLDB 2017, Clermont-Ferrand, 10-12 October 2017 17
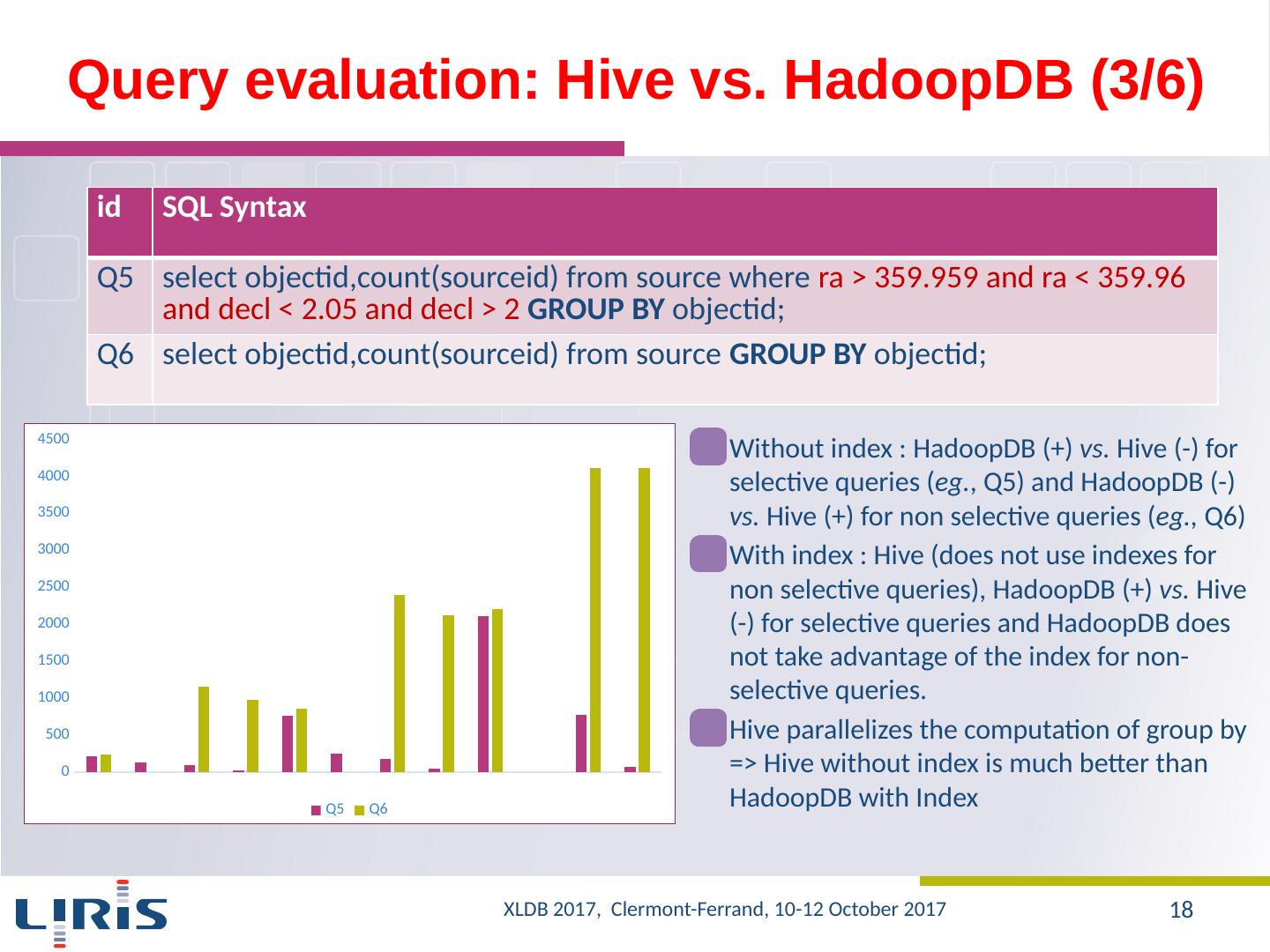
18 .Query evaluation : Hive vs. HadoopDB (3/6) Without index : HadoopDB (+) vs. Hive (-) for selective queries ( eg . , Q5) and HadoopDB (-) vs. Hive (+) for non selective queries ( eg ., Q6) With i ndex : Hive ( does not use indexes for non selective queries ), HadoopDB (+) vs. Hive (-) for selective queries and HadoopDB does not take advantage of the index for non-selective queries. Hive parallelizes the computation of group by => Hive without index is much better than HadoopDB with Index id SQL Syntax Q5 select objectid,count ( sourceid ) from source where ra > 359.959 and ra < 359.96 and decl < 2.05 and decl > 2 GROUP BY objectid ; Q6 select objectid,count ( sourceid ) from source GROUP BY objectid ; XLDB 2017, Clermont-Ferrand, 10-12 October 2017 18
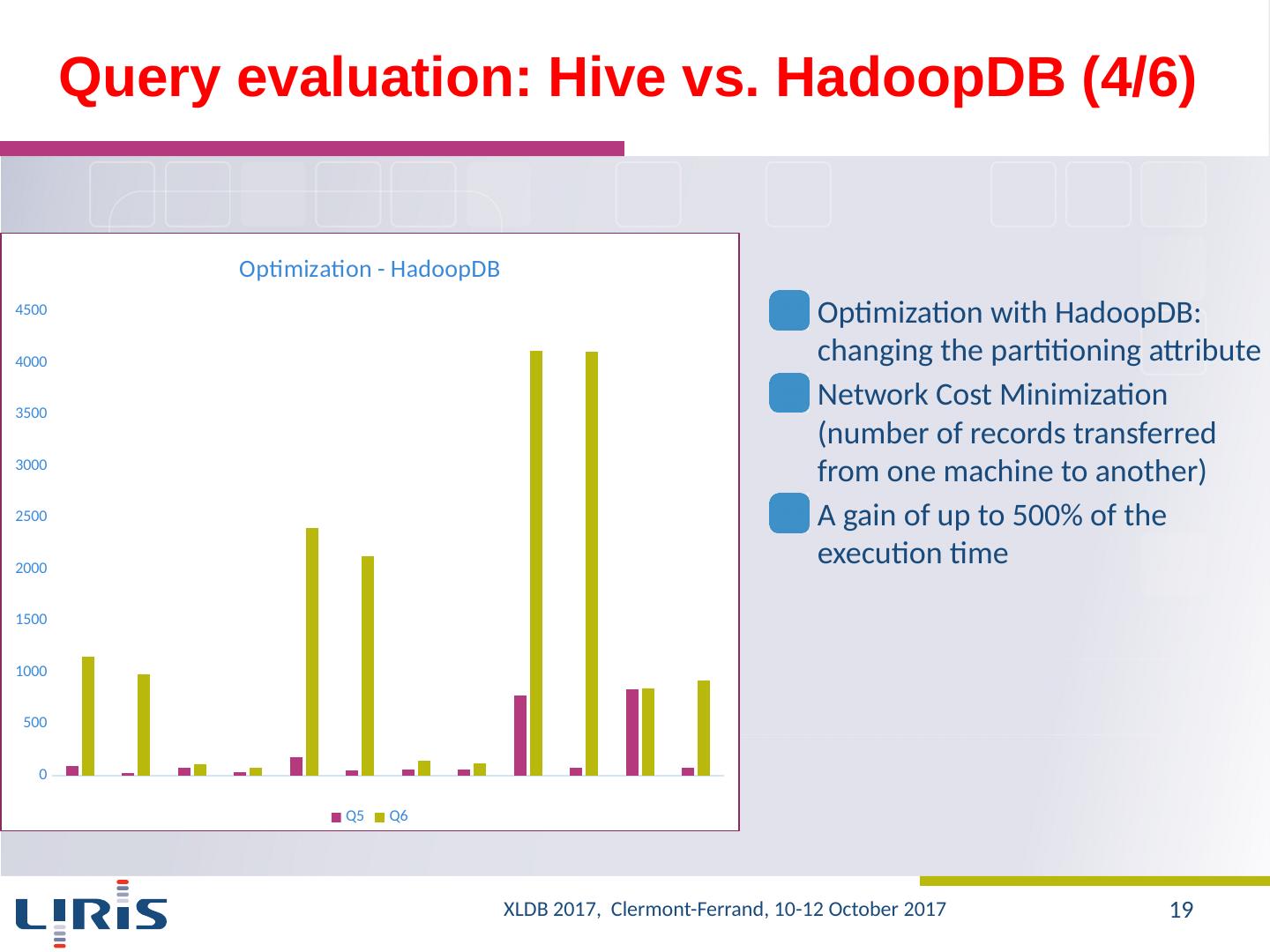
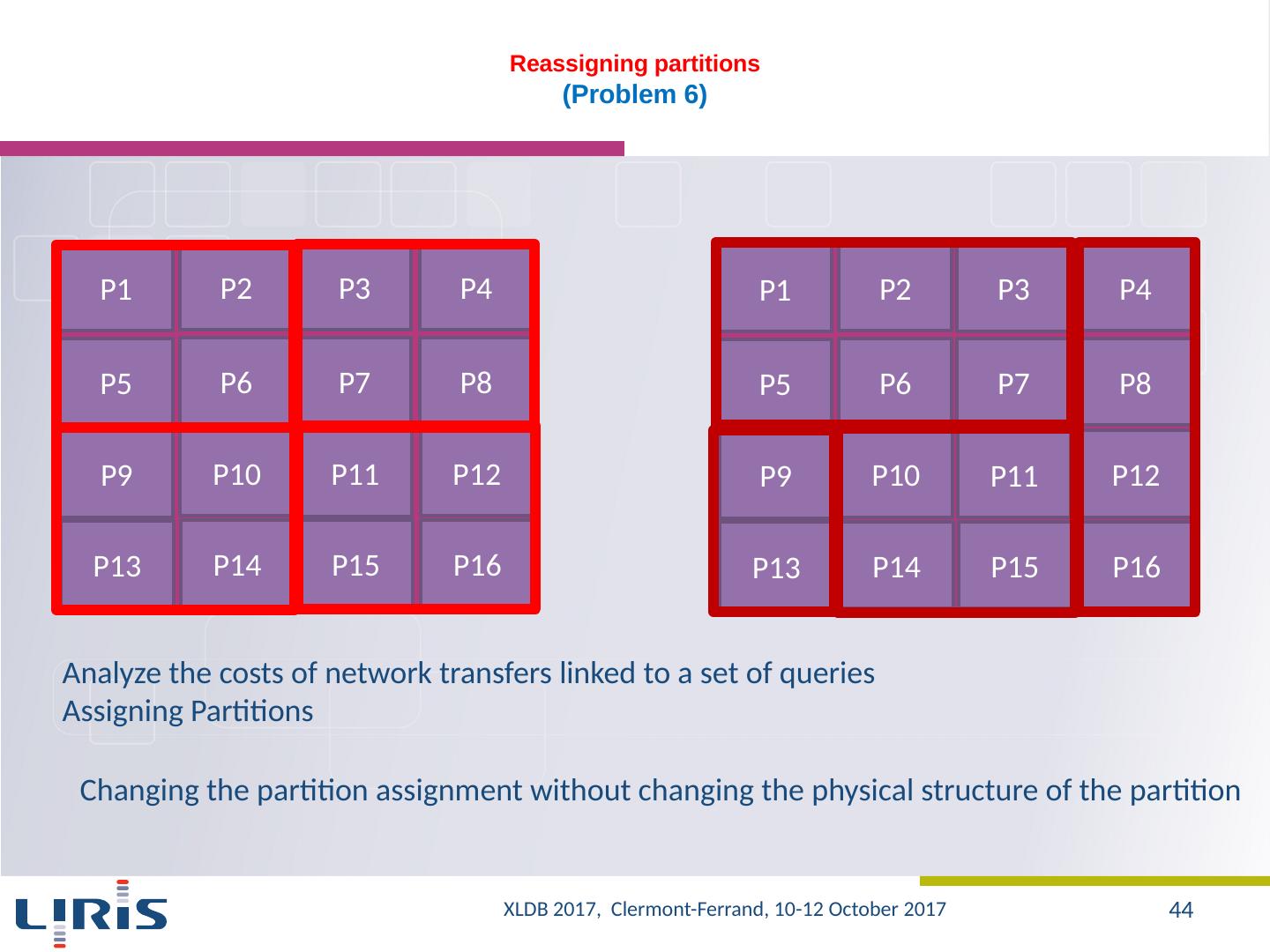
19 .Query evaluation : Hive vs. HadoopDB (4/6) Optimization with HadoopDB : changing the partitioning attribute Network Cost Minimization (number of records transferred from one machine to another ) A gain of up to 500% of the execution time XLDB 2017, Clermont-Ferrand, 10-12 October 2017 19
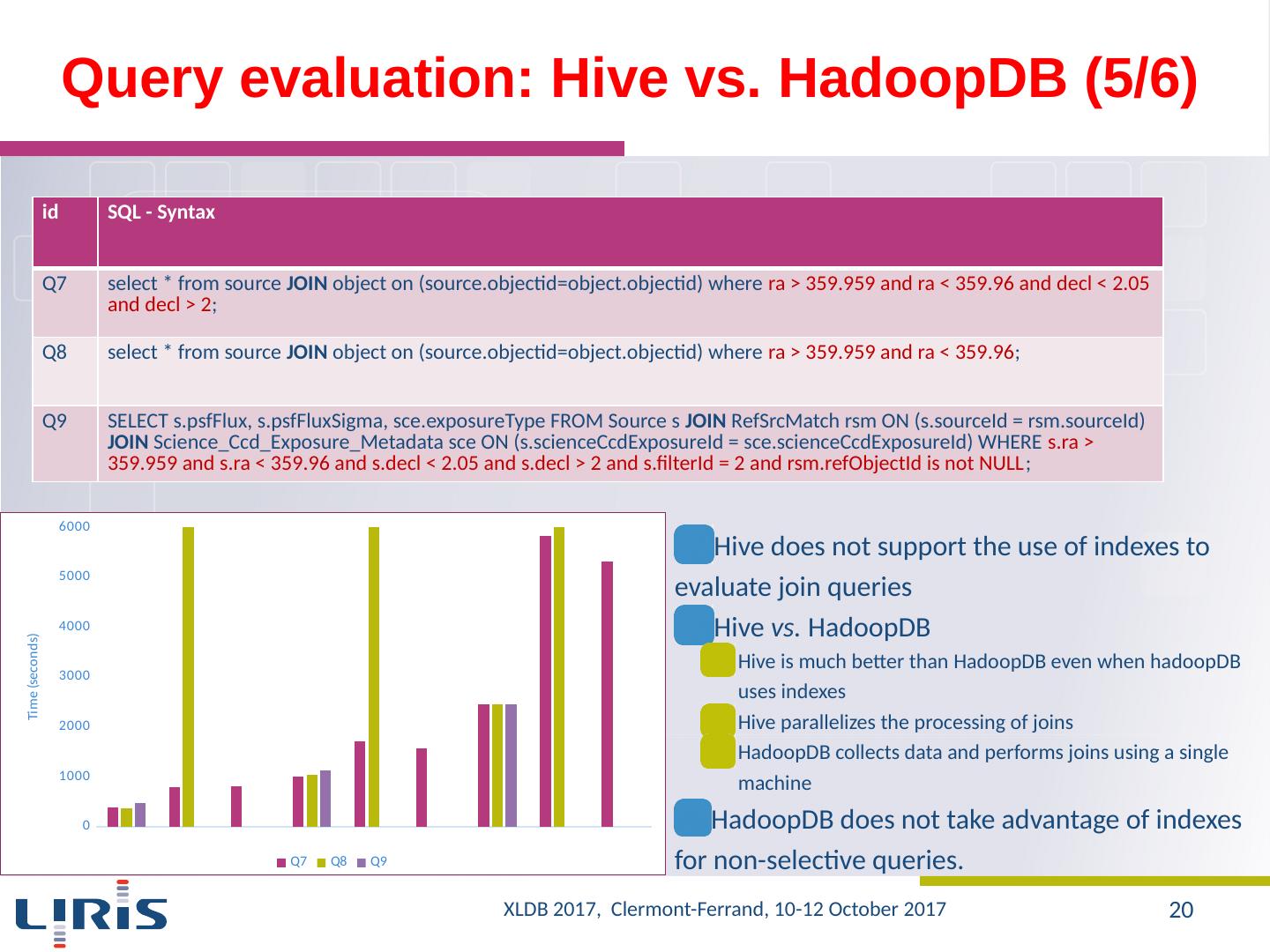
20 .Query evaluation : Hive vs. HadoopDB (5/6) Hive does not support the use of indexes to evaluate join queries Hive vs. HadoopDB Hive is much better than HadoopDB even when hadoopDB uses indexes Hive parallelizes the processing of joins HadoopDB collects data and performs joins using a single machine HadoopDB does not take advantage of indexes for non-selective queries. id SQL - Syntax Q7 select * from source JOIN object on ( source.objectid = object.objectid ) where ra > 359.959 and ra < 359.96 and decl < 2.05 and decl > 2 ; Q8 select * from source JOIN object on ( source.objectid = object.objectid ) where ra > 359.959 and ra < 359.96 ; Q9 SELECT s.psfFlux , s.psfFluxSigma , sce.exposureType FROM Source s JOIN RefSrcMatch rsm ON ( s.sourceId = rsm.sourceId ) JOIN Science_Ccd_Exposure_Metadata sce ON ( s.scienceCcdExposureId = sce.scienceCcdExposureId ) WHERE s.ra > 359.959 and s.ra < 359.96 and s.decl < 2.05 and s.decl > 2 and s.filterId = 2 and rsm.refObjectId is not NULL ; XLDB 2017, Clermont-Ferrand, 10-12 October 2017 20
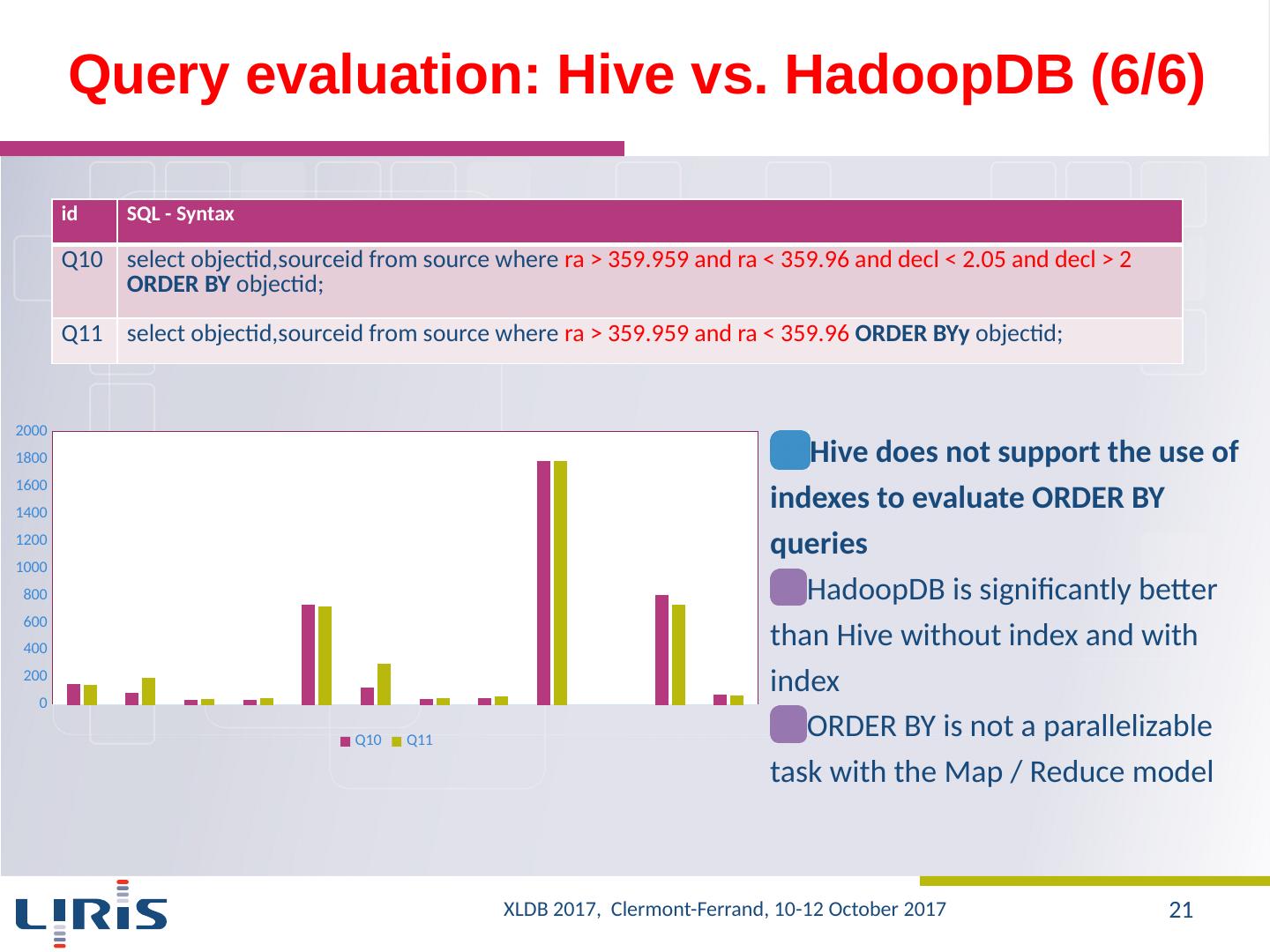
21 .Query evaluation : Hive vs. HadoopDB (6/6) Hive does not support the use of indexes to evaluate ORDER BY queries HadoopDB is significantly better than Hive without index and with index ORDER BY is not a parallelizable task with the Map / Reduce model id SQL - Syntax Q10 select objectid,sourceid from source where ra > 359.959 and ra < 359.96 and decl < 2.05 and decl > 2 ORDER BY objectid ; Q11 select objectid,sourceid from source where ra > 359.959 and ra < 359.96 ORDER BY y objectid ; XLDB 2017, Clermont-Ferrand, 10-12 October 2017 21
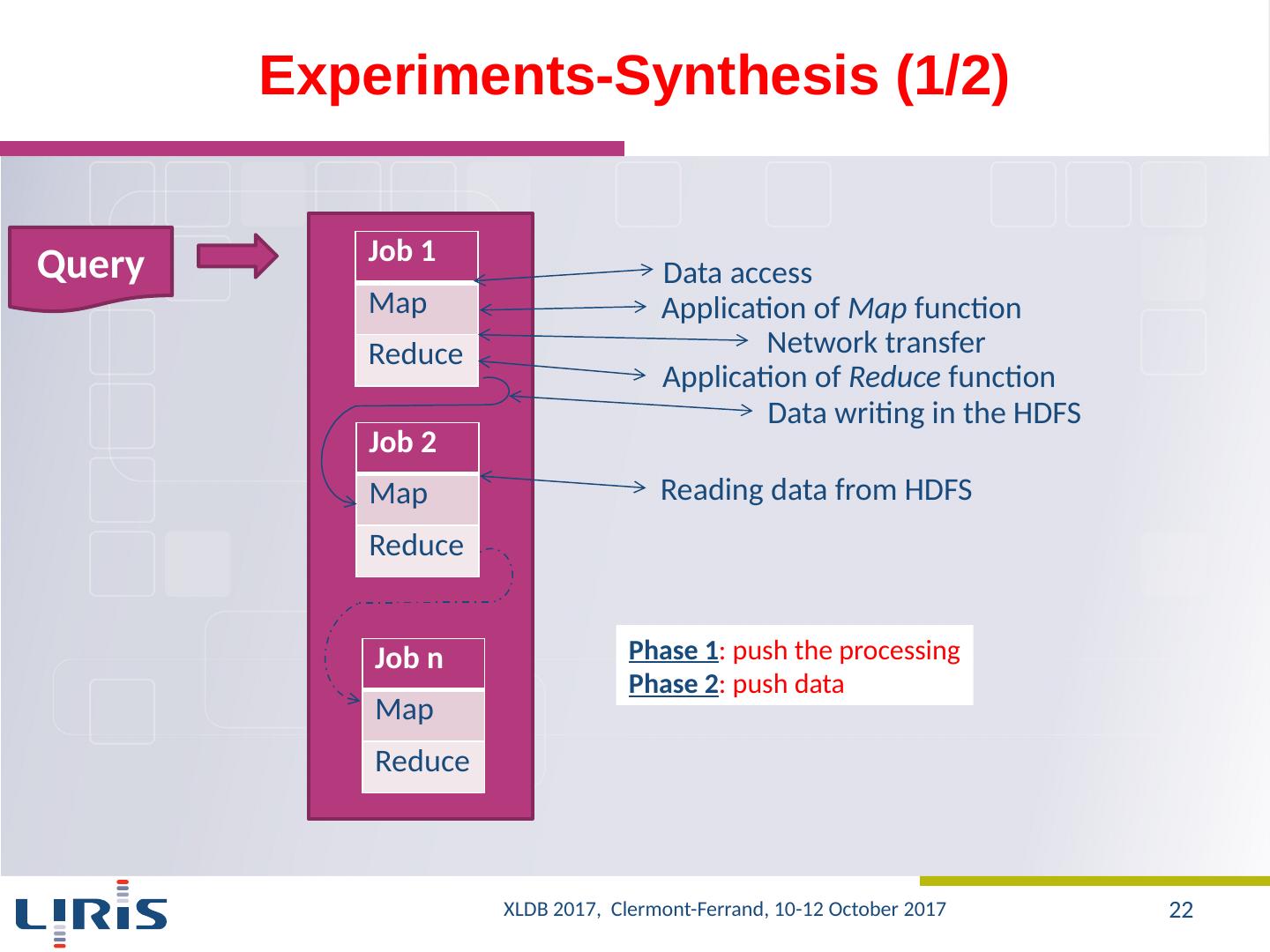
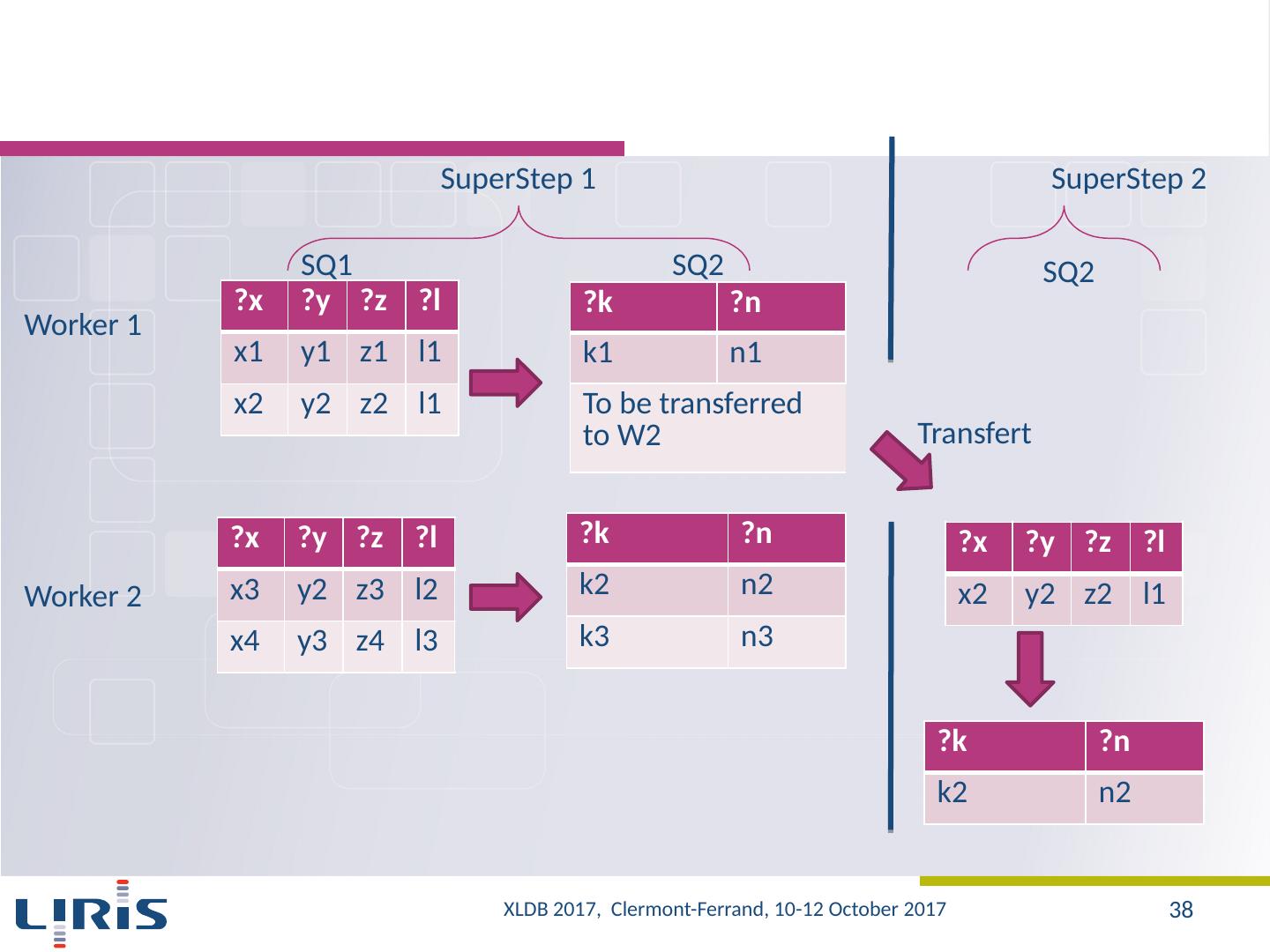
22 .Experiments-Synthesis (1/2) Query Job 1 Map Reduce Job 2 Map Reduce Job n Map Reduce Application of Map function Application of Reduce function Network transfer Data writing in the HDFS Reading data from HDFS Data access Phase 1 : push the processing Phase 2 : push data XLDB 2017, Clermont-Ferrand, 10-12 October 2017 22
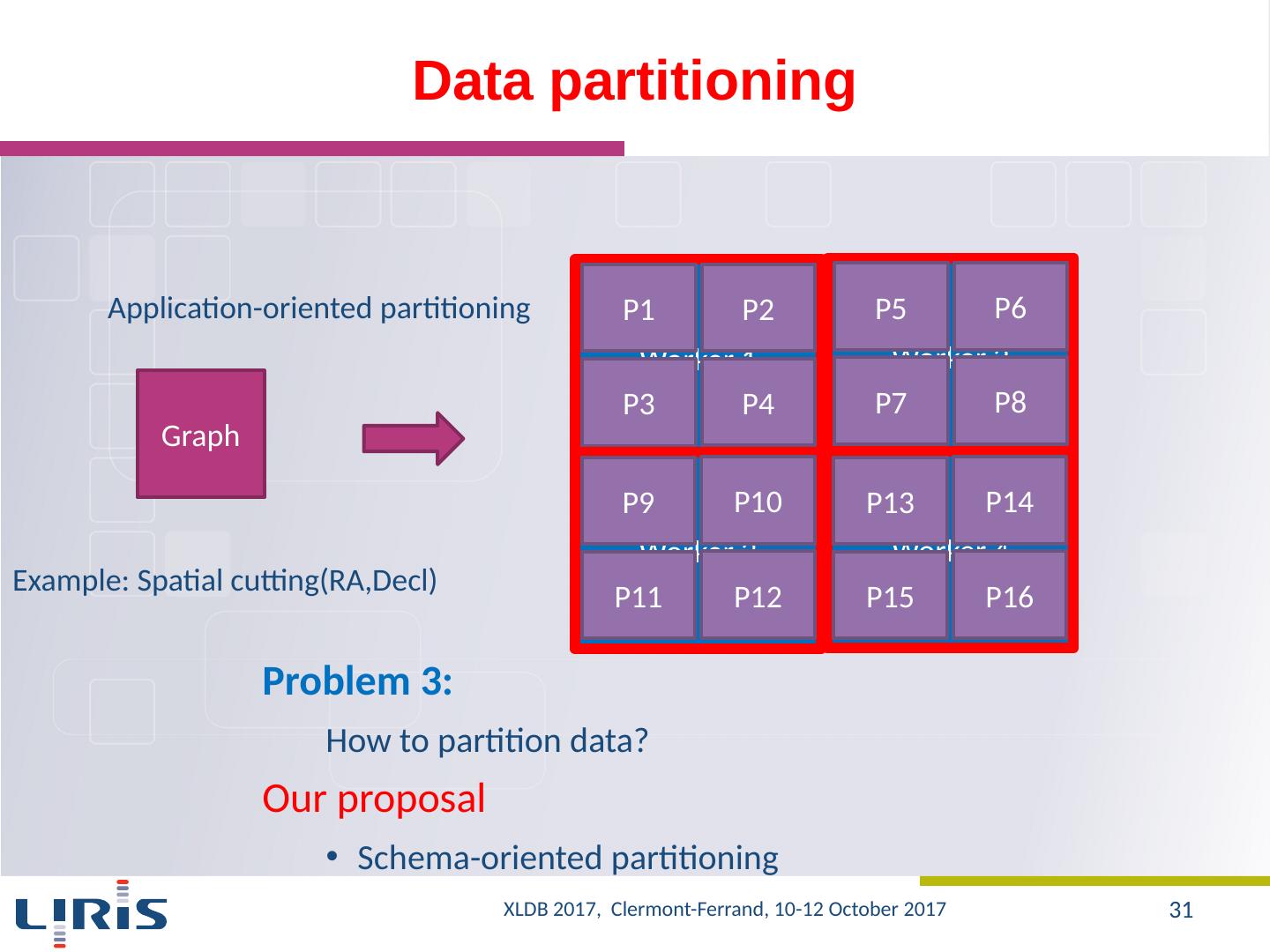
23 .DBMS - must be able to adapt to queries Customized data partitioning - necessary to optimize the evaluation of certain types of queries Optimization techniques ( e.g. , indexing, partitioning , use of buffers, ...) to be revisited Lessons learned from experiments XLDB 2017, Clermont-Ferrand, 10-12 October 2017 23
24 .A new architecture XLDB 2017, Clermont-Ferrand, 10-12 October 2017 24
25 .Required features Access to data by accommodating compression and indexing Flexible Partitioning Techniques Taking into account the characteristics of the data Query evaluation Parallelization Network access only if required Take advantage of partitioning to avoid unnecessary data transfers DBMS - must be able to adapt to queries By changing the location of the data XLDB 2017, Clermont-Ferrand, 10-12 October 2017 25
26 .Features of LSST data Object : 225 attributes ~ 50 % of the values are «NULL» Problem of normalization Raw data: 15% -30% of the data volume 1 st data set : 250 GB SourceID ObjectID RA DECL ExposureID 1 1 10 -3 1 5 2 15 -4 NULL 9 NULL 20 -5 5 13 4 25 -7 NULL Problem 1 : How to store only "non-null" values ? XLDB 2017, Clermont-Ferrand, 10-12 October 2017 26
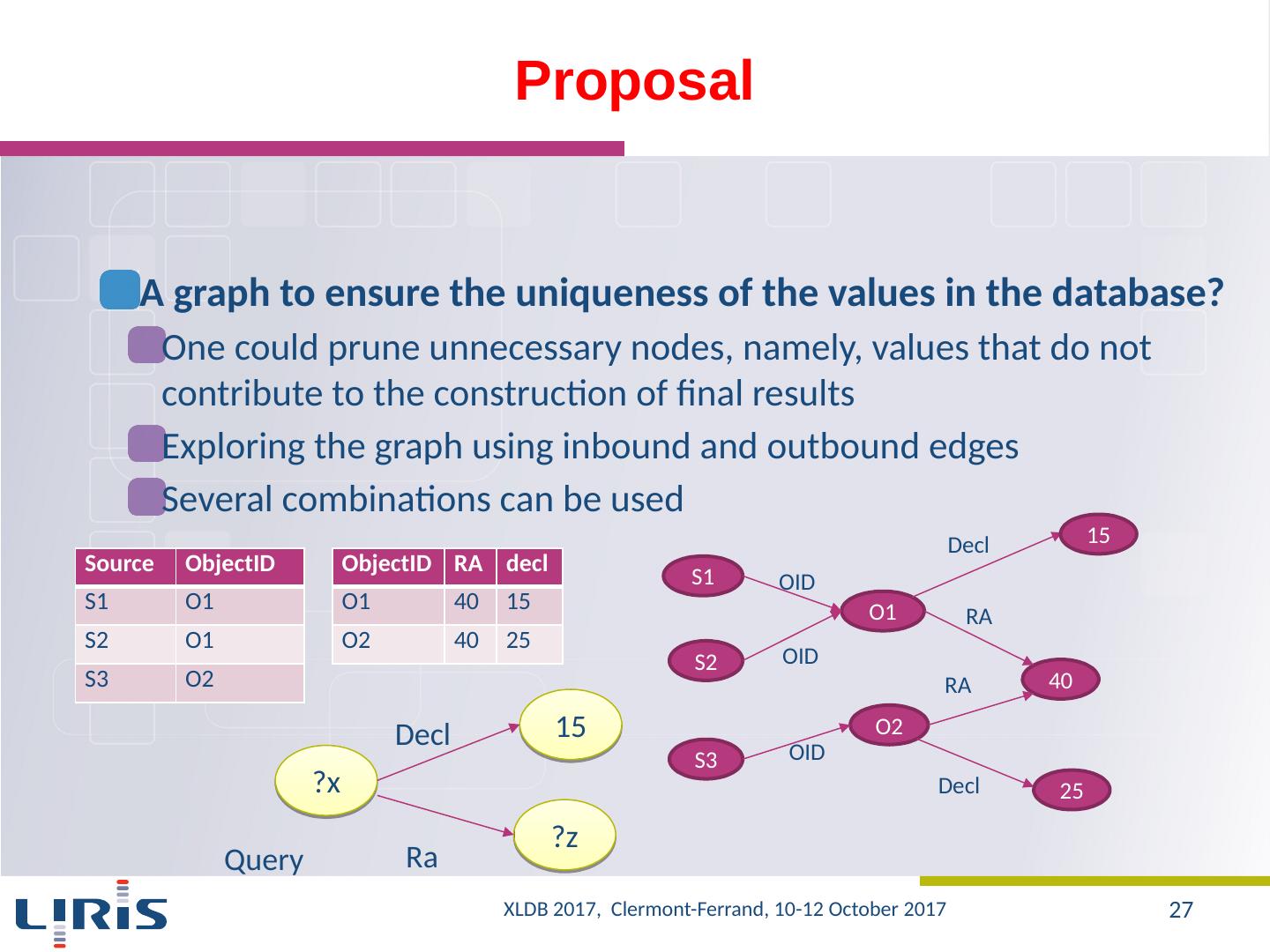
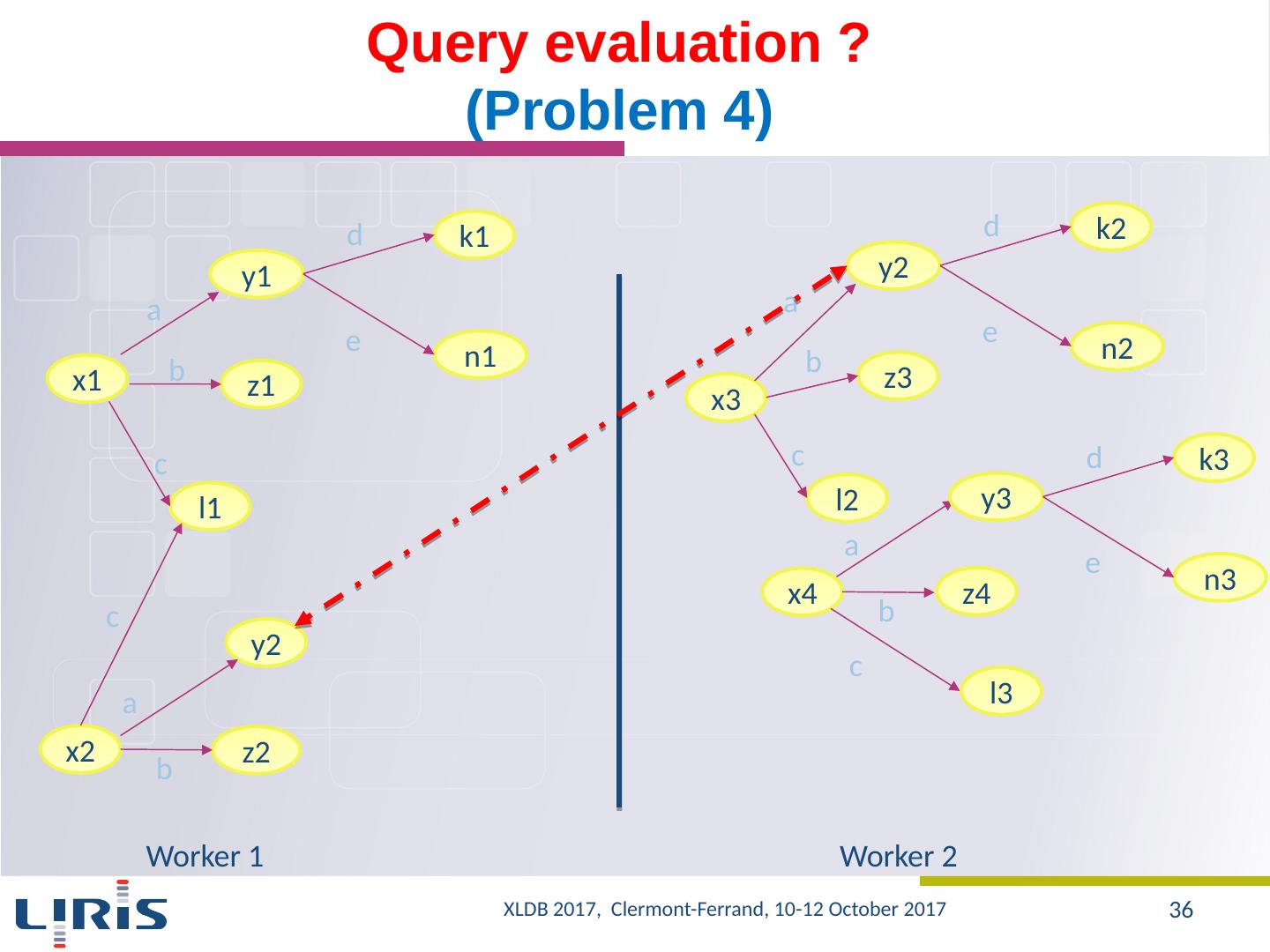
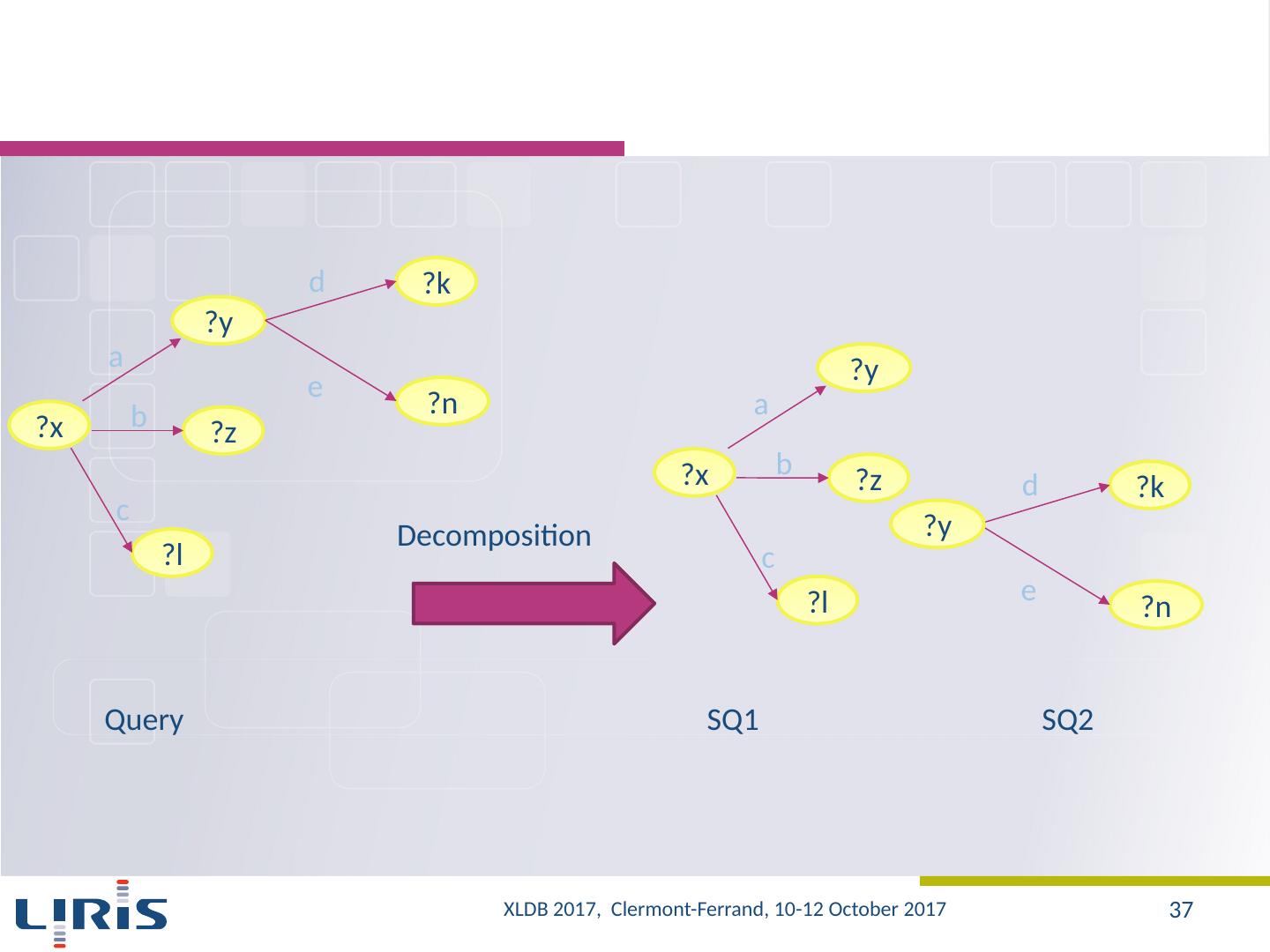
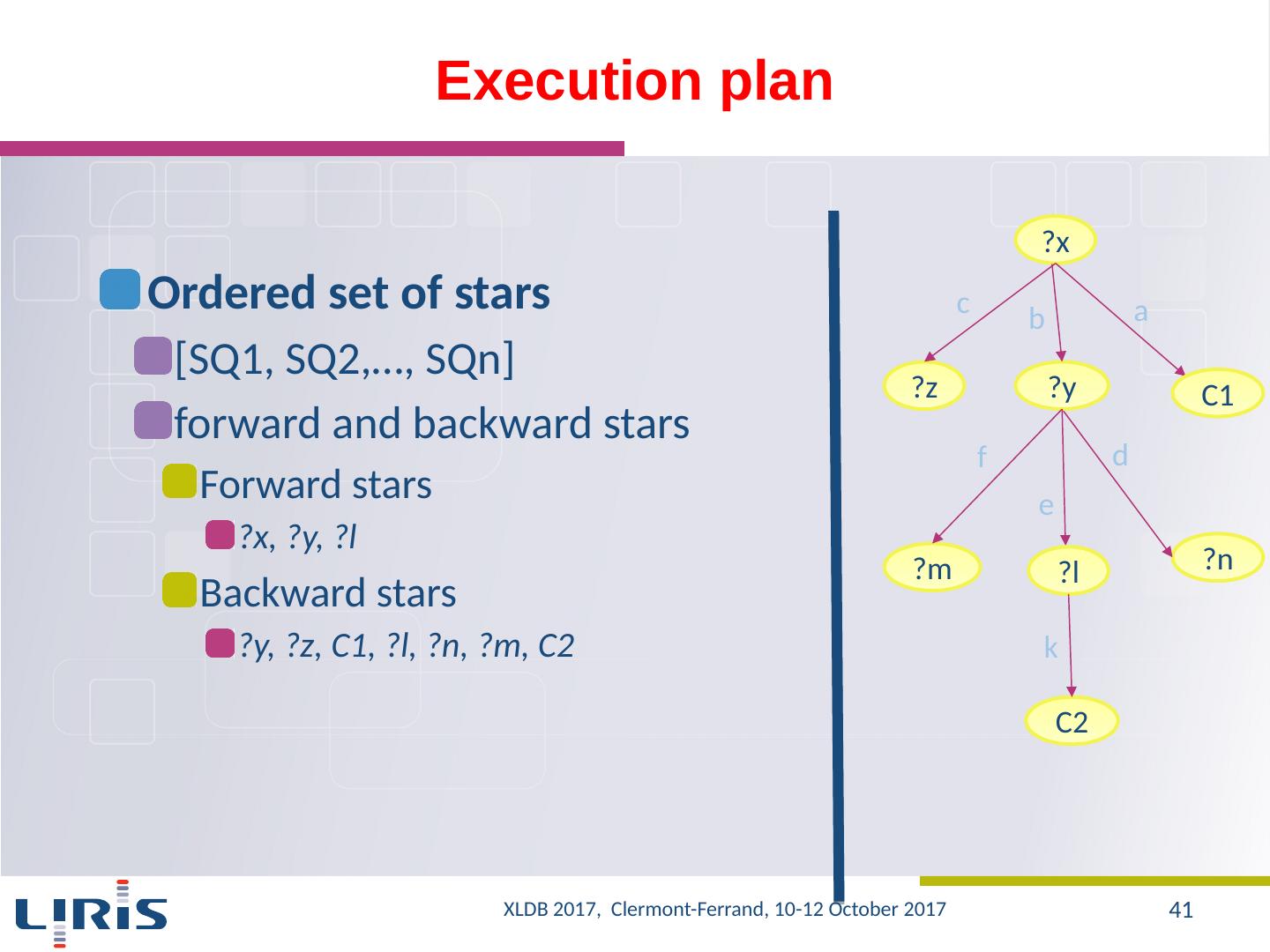
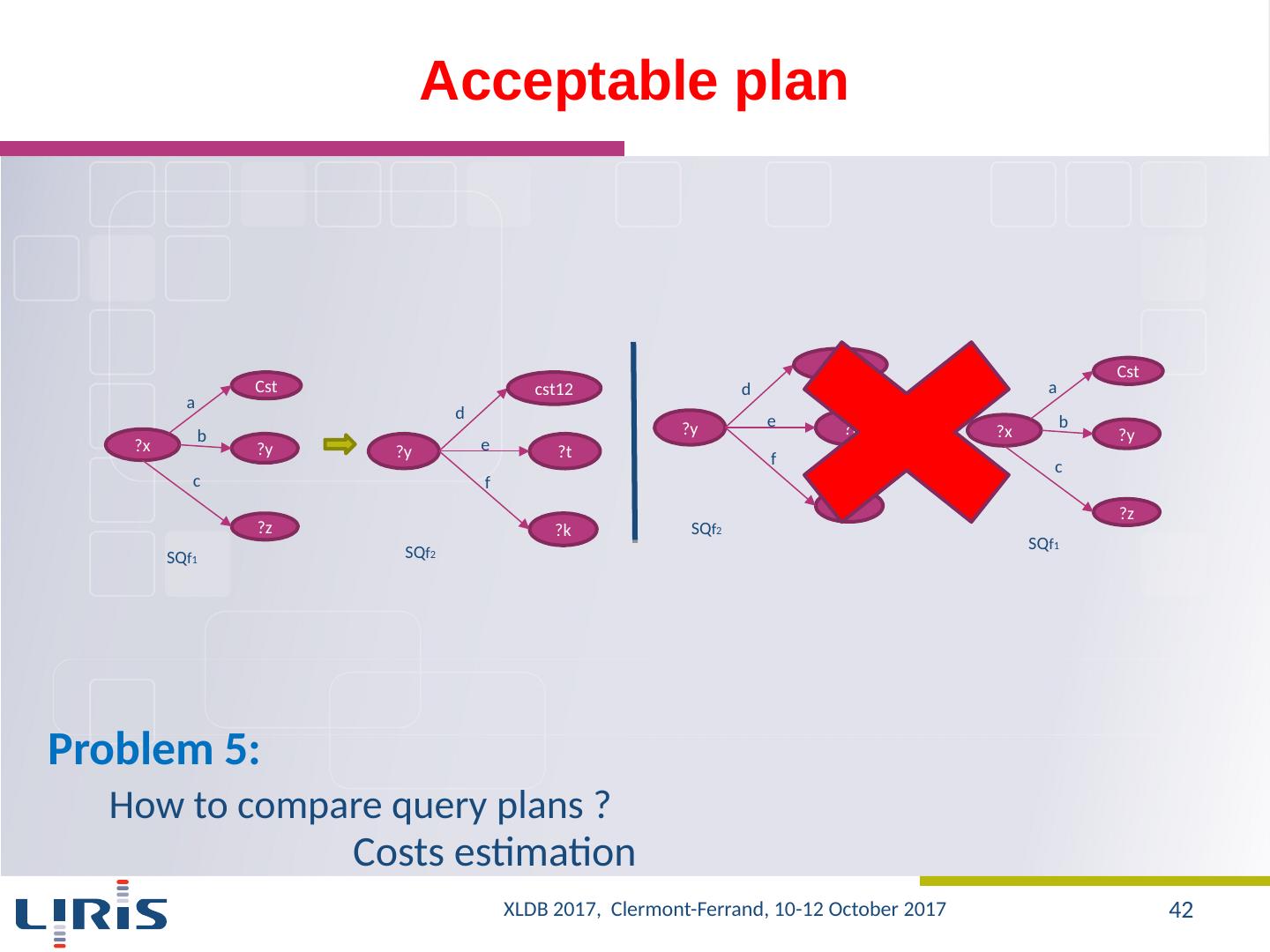
27 .Proposal A graph to ensure the uniqueness of the values in the database? One could prune unnecessary nodes, namely, values that do not contribute to the construction of final results Exploring the graph using inbound and outbound edges Several combinations can be used Source ObjectID S1 O1 S2 O1 S3 O2 ObjectID RA decl O1 40 15 O2 40 25 S1 S3 S2 O1 O2 OID OID OID 40 RA RA 15 Decl Decl 25 ?x 15 ?z D ecl Ra Query XLDB 2017, Clermont-Ferrand, 10-12 October 2017 27
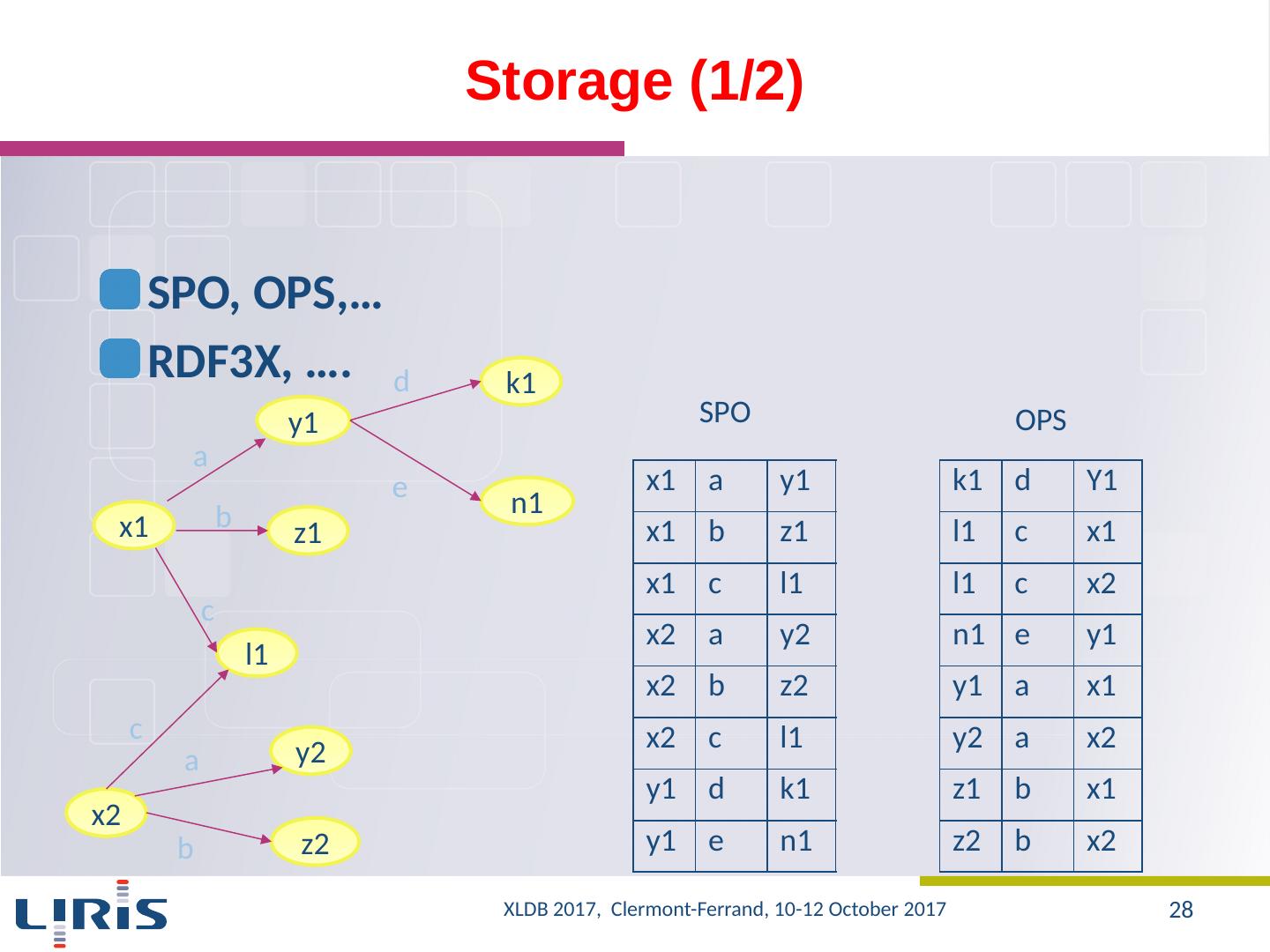
28 .Storage (1/2) SPO, OPS,… RDF3X, …. x1 l1 z1 n1 k1 a b c d e y1 z2 x2 y2 a b c x1 a y1 x1 b z1 x1 c l1 x2 a y2 x2 b z2 x2 c l1 y1 d k1 y1 e n1 SPO k1 d Y1 l1 c x1 l1 c x2 n1 e y1 y1 a x1 y2 a x2 z1 b x1 z2 b x2 OPS XLDB 2017, Clermont-Ferrand, 10-12 October 2017 28
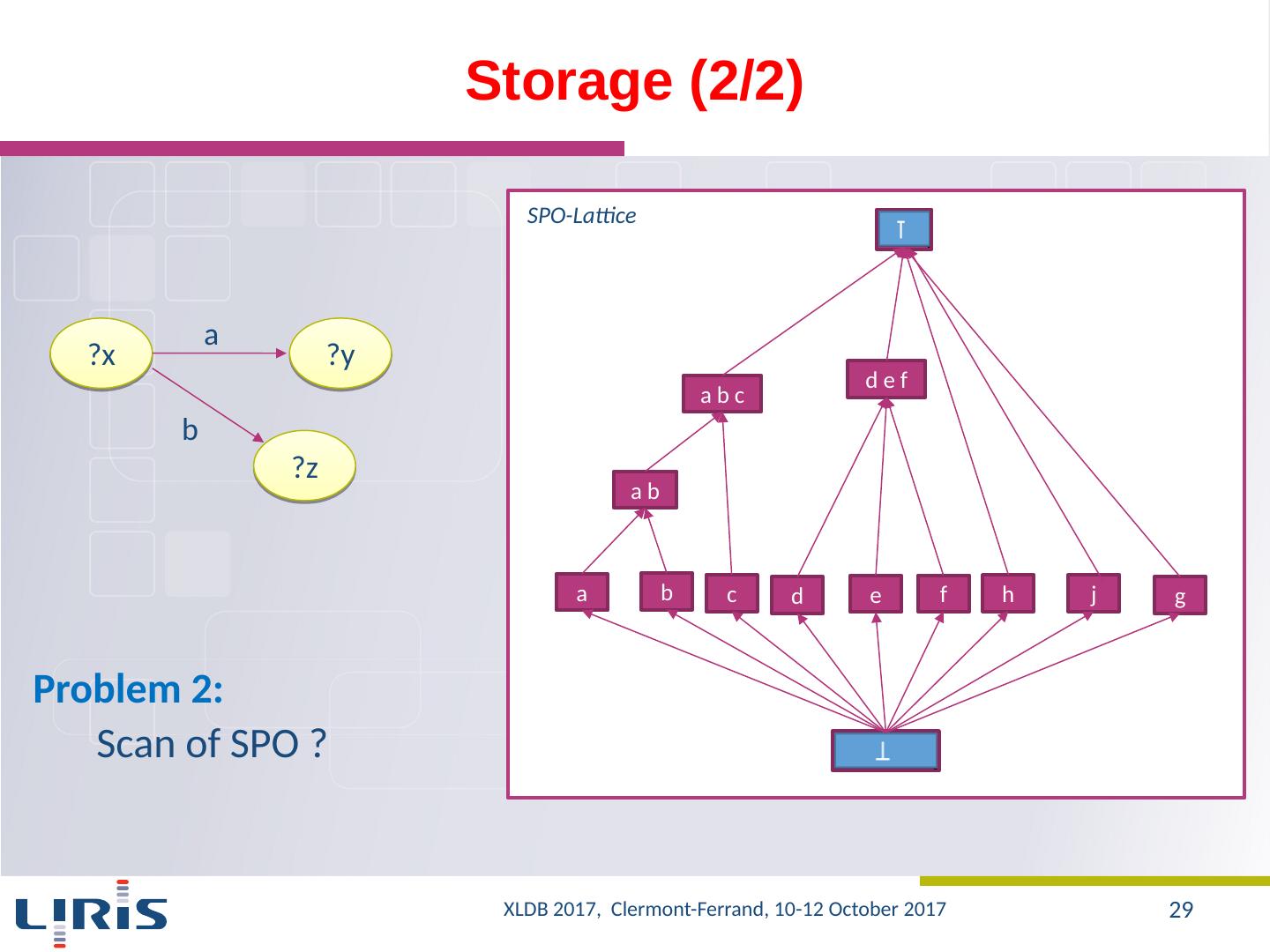
29 .Storage (2/2) ?x ?y ?z a b Problem 2: Scan of SPO ? x1 a y1 x1 b z1 x1 c l1 x2 a y2 x2 b z2 x2 c l1 y1 d k1 y1 e n1 x1 a y1 x1 b z1 x1 c l1 x2 a y2 x2 b z2 x2 c l1 y1 d k1 y1 e n1 a b c d e S P O SPO-Lattice a b c a a b b d e f d e f h j g c XLDB 2017, Clermont-Ferrand, 10-12 October 2017 29
3秒后跳转登录页面
去登陆

