Flowkube: JDOS上的GPU资源管理系统 - Yongqing,Liang, JD.com
分享
点赞
4
收藏
0
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
1. GPU机器管理:安装,驱动管理,标签管理
2. 内置CI系统:用户不需要自行制作镜像
3. 统一的文件存储系统:存放用户的训练素材和结果
4. 基于kubeflow的tensorflow训练系统
5. 训练完成后一键Serving功能
6. 实时的GPU资源使用情况监控
7. 资源记账系统统一管理多部门资源使用情况
展开查看详情
1 .GPU Resource Management On JDOS 梁永清 liangyongqing1@jd.com
2 .提供的服务 用于实验的 GPU 容器 基于 Kubeflow 的机器学习训练服务 模型管理和模型 Serving 服务 均基于容器,不对业务方直接提供 GPU 物理机
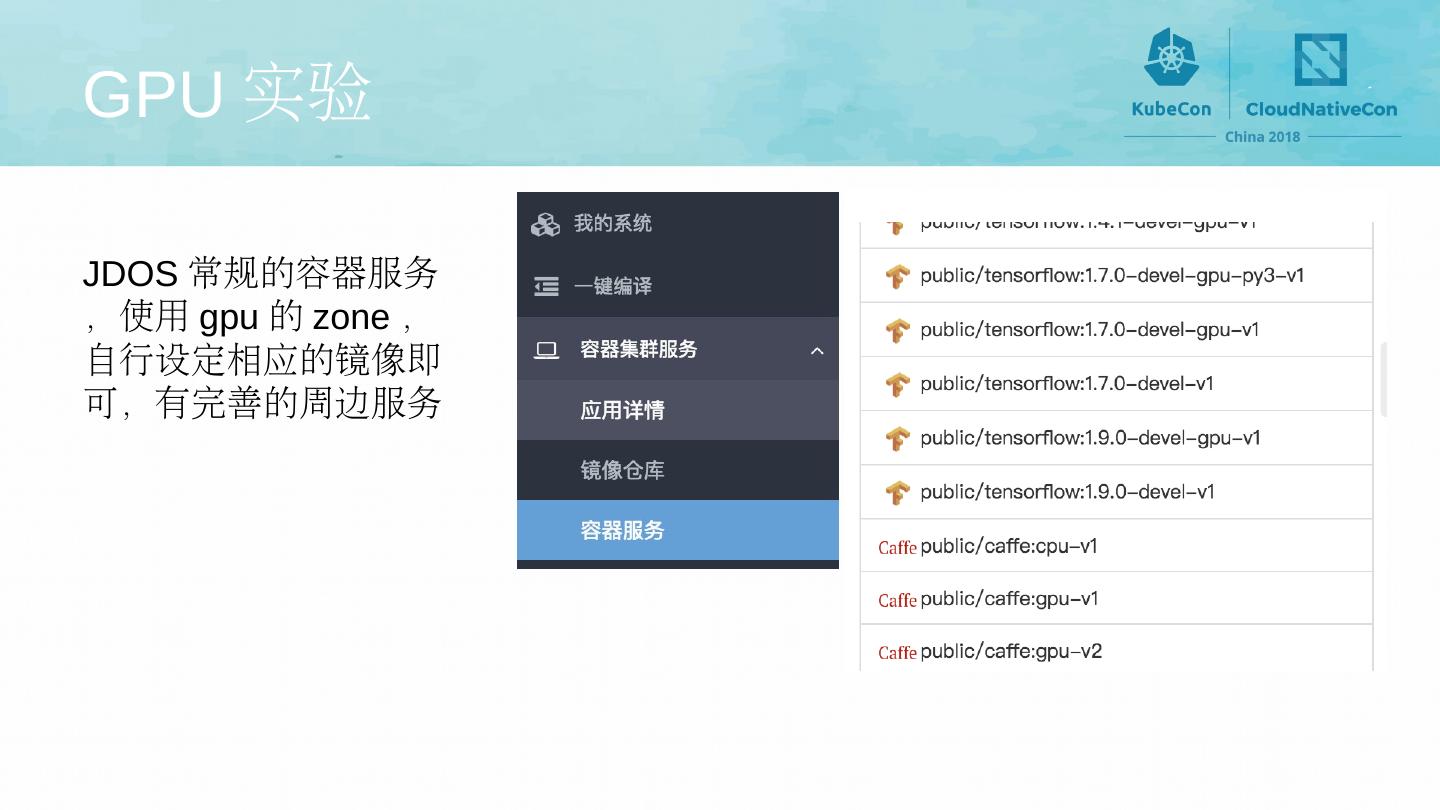
3 .GPU 实验 JDOS 常规的容器服务,使用 gpu 的 zone ,自行设定相应的镜像即可,有完善的周边服务
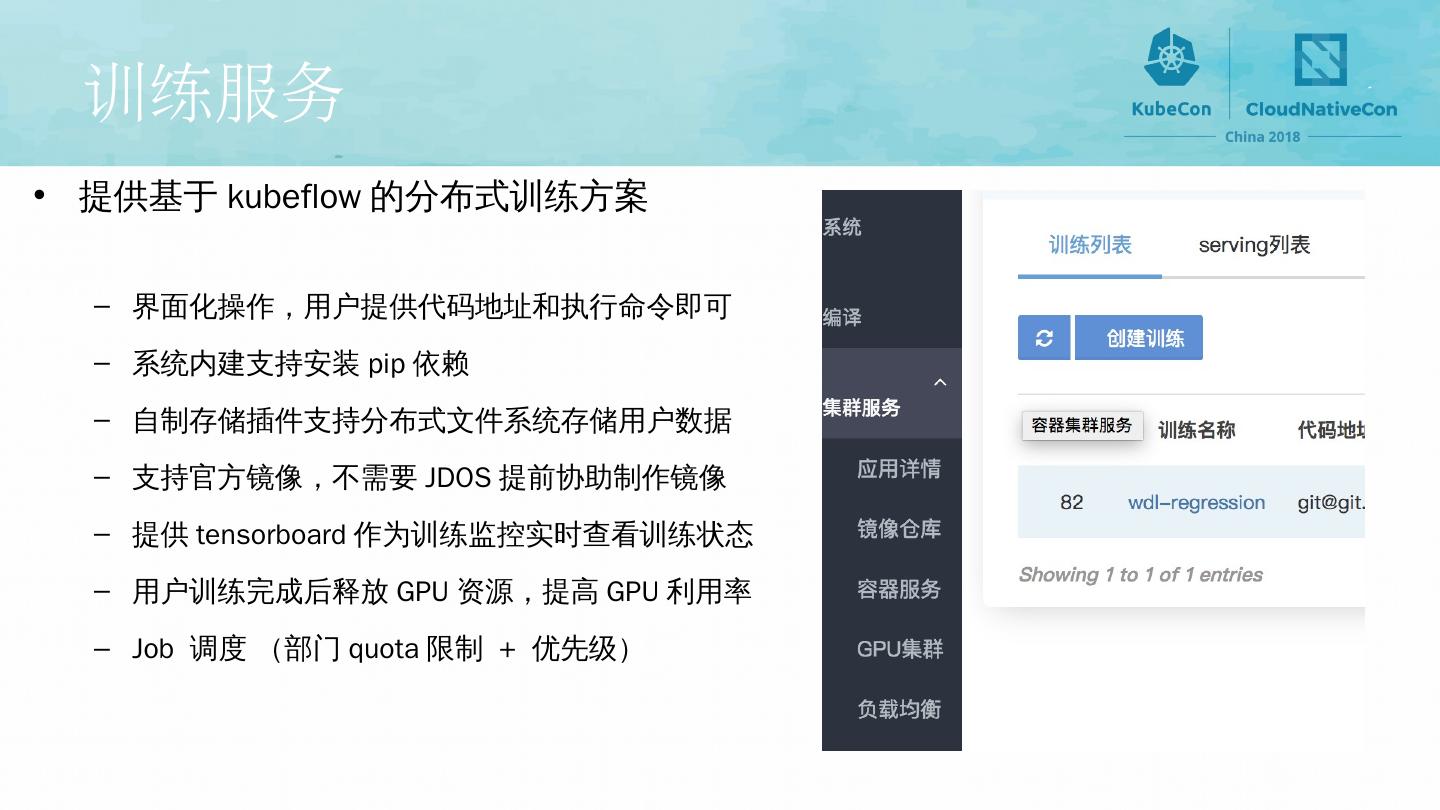
4 .训练服务 提供基于 kubeflow 的分布式训练方案 界面化操作,用户提供代码地址和执行命令即可 系统内建支持安装 pip 依赖 自制存储插件支持分布式文件系统存储用户数据 支持官方镜像,不需要 JDOS 提前协助制作镜像 提供 tensorboard 作为训练监控实时查看训练状态 用户训练完成后释放 GPU 资源,提高 GPU 利用率 Job 调度 (部门 quota 限制 + 优先级)
5 .创建训练 用户选择集群提供代码地址和执行命令即可 选择所用框架(镜像):支持官方,亦可自制 (提供 dockerfile 生成镜像服务) 选择存储来源:对接了内部的存储 填写代码地址,执行的命令等 可以选择是否监控训练,提供 tensorboard
6 .任务列表 可以指定 git 的 commit-id 发起任务
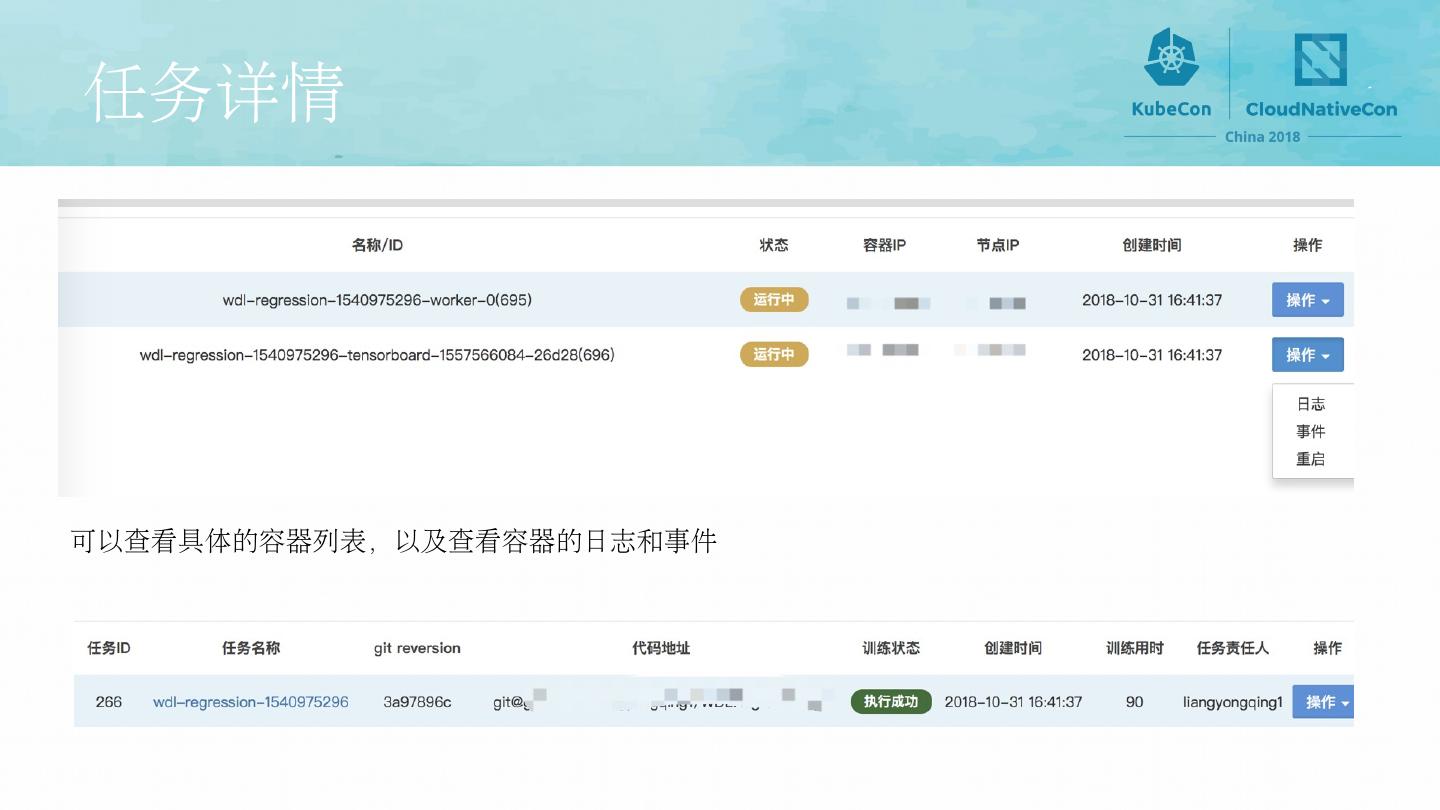
7 .任务详情 可以查看具体的容器列表,以及查看容器的日志和事件
8 .Serving 服务 提供统一便捷的 Serving 服务,只需用户指定模型,即可提供 grpc 和 rest 服务,同时使用 GPU 复用 +HPA 提高 GPU 利用率
9 .创建 Serving 与训练集成 用户只需要简单选择机房和镜像填写模型名即可完成 Serving 服务创建 自有模型 用户只需要填写模型地址即可
10 .GPU 监控 容器监控服务,自适应 GPU 容器,可根据容器 IP 查询记录 , 便于用户查看服务状态,亦可作为 HPA 的数据源 采集项 name,index,fan.speed,temperature.gpu,pstate,power.draw,power.limit,memory.used,memory.total,utilization.gpu,ecc.errors.uncorrected.aggregate.total