











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u5174/lec12_File_Systems?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
文件系统
分享
点赞
6
收藏
1
下载 0
文件的分配,分配方法的优劣
展开查看详情
1 . Goals for Today CS194-24 • Paging (Con’t) Advanced Operating Systems • Memory Allocation Structures and Implementation • File Systems Lecture 12 Paging Memory Allocation and File Systems Interactive is important! Ask Questions! March 5th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.2 Recall: What is in a Page Table Entry (PTE)? Recall: Ways to exploit the PTE • What is in a Page Table Entry (or PTE)? • How do we use the PTE? – Pointer to next-level page table or to actual page – Invalid PTE can imply different things: – Permission bits: valid, read-only, read-write, write-only » Region of address space is actually invalid or » Page/directory is just somewhere else than memory • Example: Intel x86 architecture PTE: – Validity checked first – Address same format previous slide (10, 10, 12-bit offset) » OS can use other (say) 31 bits for location info – Intermediate page tables called “Directories” • Usage Example: Demand Paging Page Frame Number Free – Keep only active pages in memory PCD PWT 0 L D A U WP – Place others on disk and mark their PTEs invalid (Physical Page Number) (OS) 31-12 11-9 8 7 6 5 4 3 2 1 0 • Usage Example: Copy on Write P: Present (same as “valid” bit in other architectures) – UNIX fork gives copy of parent address space to child » Address spaces disconnected after child created W: Writeable – How to do this cheaply? U: User accessible » Make copy of parent’s page tables (point at same memory) PWT: Page write transparent: external cache write-through » Mark entries in both sets of page tables as read-only PCD: Page cache disabled (page cannot be cached) » Page fault on write creates two copies A: Accessed: page has been accessed recently • Usage Example: Zero Fill On Demand D: Dirty (PTE only): page has been modified recently – New data pages must carry no information (say be zeroed) L: L=14MB page (directory only). – Mark PTEs as invalid; page fault on use gets zeroed page Bottom 22 bits of virtual address serve as offset – Often, OS creates zeroed pages in background 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.3 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.4
2 . Recall: Demand Paging Mechanisms Steps in Handling a Page Fault • PTE helps us implement demand paging – Valid Page in memory, PTE points at physical page – Not Valid Page not in memory; use info in PTE to find it on disk when necessary • Suppose user references page with invalid PTE? – Memory Management Unit (MMU) traps to OS » Resulting trap is a “Page Fault” – What does OS do on a Page Fault?: » Choose an old page to replace » If old page modified (“D=1”), write contents back to disk » Change its PTE and any cached TLB to be invalid » Load new page into memory from disk » Update page table entry, invalidate TLB for new entry » Continue thread from original faulting location – TLB for new page will be loaded when thread continued! – While pulling pages off disk for one process, OS runs another process from ready queue » Suspended process sits on wait queue 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.5 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.6 Page Replacement Policies Replacement Policies (Con’t) • Why do we care about Replacement Policy? • LRU (Least Recently Used): – Replacement is an issue with any cache – Replace page that hasn’t been used for the longest time – Particularly important with pages – Programs have locality, so if something not used for a » The cost of being wrong is high: must go to disk while, unlikely to be used in the near future. » Must keep important pages in memory, not toss them out – Seems like LRU should be a good approximation to MIN. • FIFO (First In, First Out) – Throw out oldest page. Be fair – let every page live in • How to implement LRU? Use a list! memory for same amount of time. – Bad, because throws out heavily used pages instead of Head Page 6 Page 7 Page 1 Page 2 infrequently used pages • MIN (Minimum): Tail (LRU) – Replace page that won’t be used for the longest time – On each use, remove page from list and place at head – Great, but can’t really know future… – LRU page is at tail – Makes good comparison case, however • Problems with this scheme for paging? • RANDOM: – Pick random page for every replacement – Need to know immediately when each page used so that can change position in list… – Typical solution for TLB’s. Simple hardware – Pretty unpredictable – makes it hard to make real-time – Many instructions for each hardware access guarantees • In practice, people approximate LRU (more later) 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.7 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.8
3 . Implementing LRU Clock Algorithm: Not Recently Used • Perfect: Single Clock Hand: – Timestamp page on each reference Advances only on page fault! – Keep list of pages ordered by time of reference Check for pages not used recently – Too expensive to implement in reality for many reasons Mark pages as not used recently • Clock Algorithm: Arrange physical pages in circle with Set of all pages single clock hand in Memory – Approximate LRU (approx to approx to MIN) – Replace an old page, not the oldest page • Details: – Hardware “use” bit per physical page: » Hardware sets use bit on each reference • What if hand moving slowly? » If use bit isn’t set, means not referenced in a long time – Good sign or bad sign? » Nachos hardware sets use bit in the TLB; you have to copy » Not many page faults and/or find page quickly this back to page table when TLB entry gets replaced – On page fault: • What if hand is moving quickly? » Advance clock hand (not real time) – Lots of page faults and/or lots of reference bits set » Check use bit: 1used recently; clear and leave alone • One way to view clock algorithm: 0selected candidate for replacement – Will always find a page or loop forever? – Crude partitioning of pages into two groups: young and old » Even if all use bits set, will eventually loop aroundFIFO – Why not partition into more than 2 groups? 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.9 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.10 Nth Chance version of Clock Algorithm Clock Algorithms: Details • Nth chance algorithm: Give page N chances • Which bits of a PTE entry are useful to us? – OS keeps counter per page: # sweeps – Use: Set when page is referenced; cleared by clock – On page fault, OS checks use bit: algorithm » 1clear use and also clear counter (used in last sweep) – Modified: set when page is modified, cleared when page » 0increment counter; if count=N, replace page written to disk – Means that clock hand has to sweep by N times without page being used before page is replaced – Valid: ok for program to reference this page • How do we pick N? – Read-only: ok for program to read page, but not modify – Why pick large N? Better approx to LRU » For example for catching modifications to code pages! » If N ~ 1K, really good approximation • Do we really need hardware-supported “modified” bit? – Why pick small N? More efficient » Otherwise might have to look a long way to find free page – No. Can emulate it (BSD Unix) using read-only bit • What about dirty pages? » Initially, mark all pages as read-only, even data pages – Takes extra overhead to replace a dirty page, so give » On write, trap to OS. OS sets software “modified” bit, dirty pages an extra chance before replacing? and marks page as read-write. – Common approach: » Whenever page comes back in from disk, mark read-only » Clean pages, use N=1 » Dirty pages, use N=2 (and write back to disk when N=1) 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.11 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.12
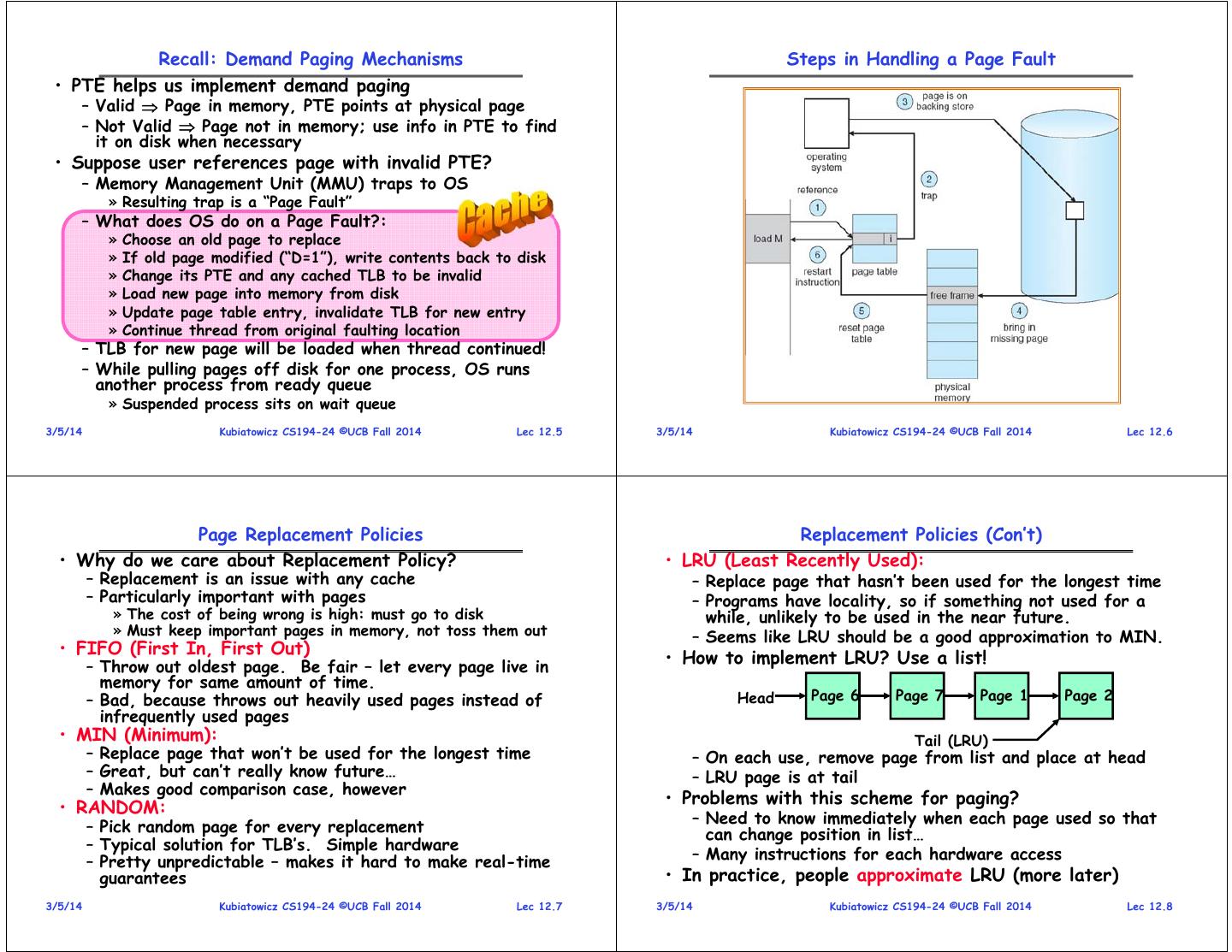
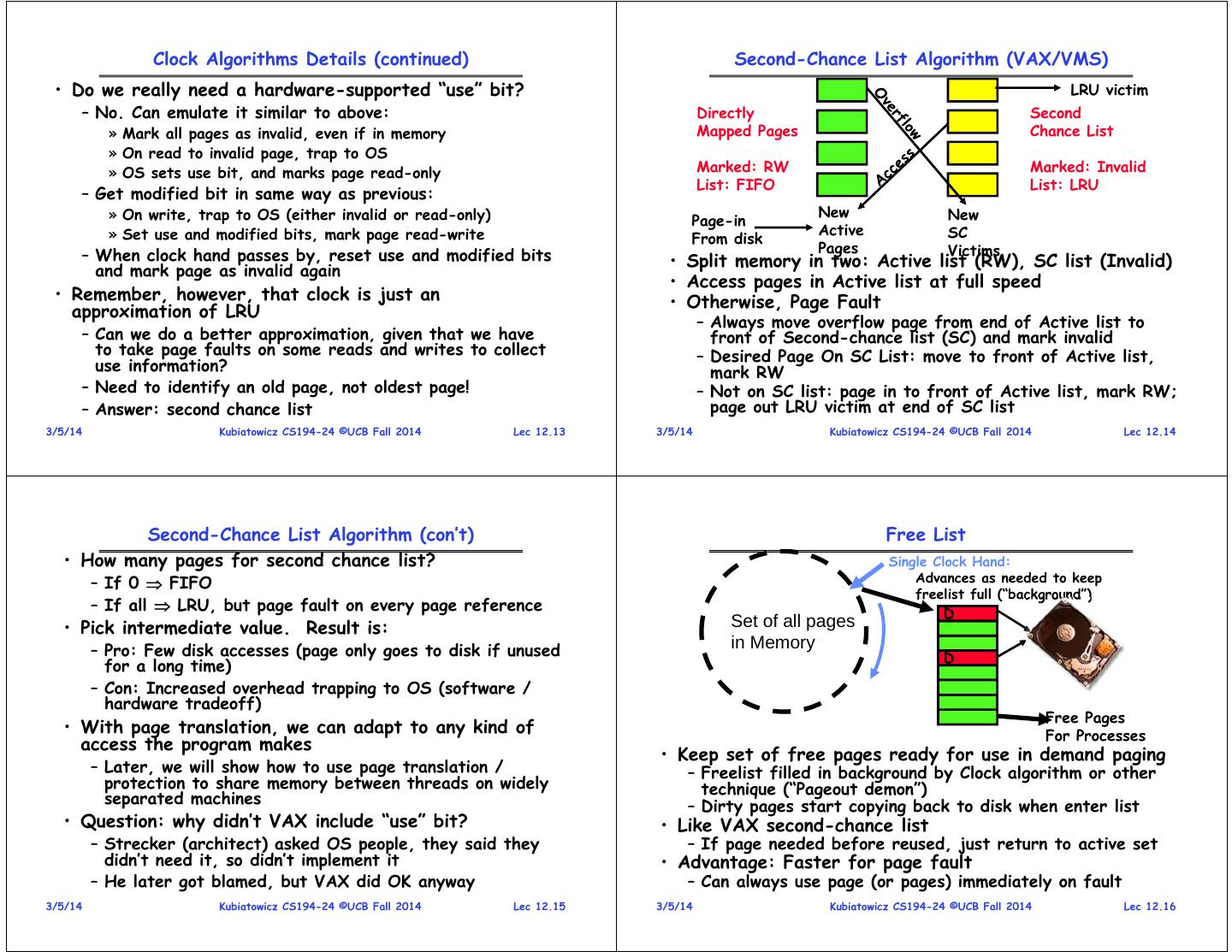
4 . Clock Algorithms Details (continued) Second-Chance List Algorithm (VAX/VMS) • Do we really need a hardware-supported “use” bit? LRU victim – No. Can emulate it similar to above: Directly Second » Mark all pages as invalid, even if in memory Mapped Pages Chance List » On read to invalid page, trap to OS » OS sets use bit, and marks page read-only Marked: RW Marked: Invalid List: FIFO List: LRU – Get modified bit in same way as previous: » On write, trap to OS (either invalid or read-only) New New Page-in » Set use and modified bits, mark page read-write Active SC From disk Pages Victims – When clock hand passes by, reset use and modified bits • Split memory in two: Active list (RW), SC list (Invalid) and mark page as invalid again • Access pages in Active list at full speed • Remember, however, that clock is just an • Otherwise, Page Fault approximation of LRU – Always move overflow page from end of Active list to – Can we do a better approximation, given that we have front of Second-chance list (SC) and mark invalid to take page faults on some reads and writes to collect – Desired Page On SC List: move to front of Active list, use information? mark RW – Need to identify an old page, not oldest page! – Not on SC list: page in to front of Active list, mark RW; – Answer: second chance list page out LRU victim at end of SC list 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.13 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.14 Second-Chance List Algorithm (con’t) Free List • How many pages for second chance list? Single Clock Hand: – If 0 FIFO Advances as needed to keep freelist full (“background”) – If all LRU, but page fault on every page reference D • Pick intermediate value. Result is: Set of all pages – Pro: Few disk accesses (page only goes to disk if unused in Memory D for a long time) – Con: Increased overhead trapping to OS (software / hardware tradeoff) Free Pages • With page translation, we can adapt to any kind of For Processes access the program makes • Keep set of free pages ready for use in demand paging – Later, we will show how to use page translation / – Freelist filled in background by Clock algorithm or other protection to share memory between threads on widely technique (“Pageout demon”) separated machines – Dirty pages start copying back to disk when enter list • Question: why didn’t VAX include “use” bit? • Like VAX second-chance list – Strecker (architect) asked OS people, they said they – If page needed before reused, just return to active set didn’t need it, so didn’t implement it • Advantage: Faster for page fault – He later got blamed, but VAX did OK anyway – Can always use page (or pages) immediately on fault 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.15 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.16
5 . Reverse Page Mapping (Sometimes called “Coremap”) Administrivia • Physical page frames often shared by many different • Midterm I: Next Wednesday (3/12)! address spaces/page tables – Intention is a 1.5 hour exam over 3 hours – All children forked from given process – No class on day of exam! – Shared memory pages between processes • Midterm Timing: • Whatever reverse mapping mechanism that is in place must be very fast – 7:00-10:00PM in 306 Soda Hall (Here!) – Must hunt down all page tables pointing at given page • Topics: everything up to Monday frame when freeing a page – OS Structure, BDD, Process support, Synchronization, – Must hunt down all PTEs when seeing if pages “active” Memory Management, File systems • Implementation options: – Labs/Papers – For every page descriptor, keep linked list of page table entries that point to it » Management nightmare – expensive – Linux 2.6: Object-based reverse mapping » Link together memory region descriptors instead (much coarser granularity) 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.17 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.18 Linux Memory Details? Recall: Linux Virtual memory map • Memory management in Linux considerably more complex that the previous indications 0xFFFFFFFF 0xFFFFFFFFFFFFFFFF • Memory Zones: physical memory categories 128TiB 896MB Kernel Kernel 1GB Addresses 64 TiB Addresses – ZONE_DMA: < 16MB memory, DMAable on ISA bus Physical Physical – ZONE_NORMAL: 16MB 896MB (mapped at 0xC0000000) 0xC0000000 0xFFFF800000000000 – ZONE_HIGHMEM: Everything else (> 896MB) • Each zone has 1 freelist, 2 LRU lists (Active/Inactive) “Canonical Hole” Empty Space • Many different types of allocation 3GB Total User – SLAB allocators, per-page allocators, mapped/unmapped Addresses 0x00007FFFFFFFFFFF • Many different types of allocated memory: 128TiB – Anonymous memory (not backed by a file, heap/stack) User Addresses – Mapped memory (backed by a file) • Allocation priorities 0x00000000 0x0000000000000000 – Is blocking allowed/etc 32-Bit Virtual Address Space 64-Bit Virtual Address Space 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.19 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.20
6 . Virtual Map (Details) Internal Interfaces: Allocating Memory • Kernel memory not generally visible to user • One mechanism for requesting pages: everything else – Exception: special VDSO facility that maps kernel code into user on top of this mechanism: space to aid in system calls (and to provide certain actual – Allocate contiguous group of pages of size 2order bytes system calls such as gettimeofday(). given the specified mask: • Every physical page described by a “page” structure struct page * alloc_pages(gfp_t gfp_mask, – Collected together in lower physical memory unsigned int order) – Can be accessed in kernel virtual space – Allocate one page: – Linked together in various “LRU” lists • For 32-bit virtual memory architectures: struct page * alloc_page(gfp_t gfp_mask) – When physical memory < 896MB » All physical memory mapped at 0xC0000000 – Convert page to logical address (assuming mapped): – When physical memory >= 896MB void * page_address(struct page *page) » Not all physical memory mapped in kernel space all the time • Also routines for freeing pages » Can be temporarily mapped with addresses > 0xCC000000 • Zone allocator uses “buddy” allocator that trys to • For 64-bit virtual memory architectures: keep memory unfragmented – All physical memory mapped above 0xFFFF800000000000 • Allocation routines pick from proper zone, given flags 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.21 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.22 Allocation flags Page Frame Reclaiming Algorithm (PFRA) • Possible allocation type flags: • Several entrypoints: – GFP_ATOMIC: Allocation high-priority and must never – Low on Memory Reclaiming: The kernel detects a “low on sleep. Use in interrupt handlers, top memory” condition halves, while holding locks, or other times – Hibernation reclaiming: The kernel must free memory because cannot sleep it is entering in the suspend-to-disk state – GFP_NOWAIT: Like GFP_ATOMIC, except call will – Periodic reclaiming: A kernel thread is activated periodically not fall back on emergency memory to perform memory reclaiming, if necessary pools. Increases likely hood of failure • Low on Memory reclaiming: – GFP_NOIO: Allocation can block but must not – Start flushing out dirty pages to disk initiate disk I/O. – Start looping over all memory nodes in the system – GFP_NOFS: Can block, and can initiate disk I/O, » try_to_free_pages() but will not initiate filesystem ops. » shrink_slab() – GFP_KERNEL: Normal allocation, might block. Use in » pdflush kenel thread writing out dirty pages process context when safe to sleep. • Periodic reclaiming: This should be default choice – Kswapd kernel threads: checks if number of free page – GFP_USER: Normal allocation for processes frames in some zone has fallen below pages_high watermark – GFP_HIGHMEM: Allocation from ZONE_HIGHMEM – Each zone keeps two LRU lists: Active and Inactive – GFP_DMA Allocation from ZONE_DMA. Use in » Each page has a last-chance algorithm with 2 count combination with a previous flag » Active page lists moved to inactive list when they have been idle for two cycles through the list » Pages reclaimed from Inactive list 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.23 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.24
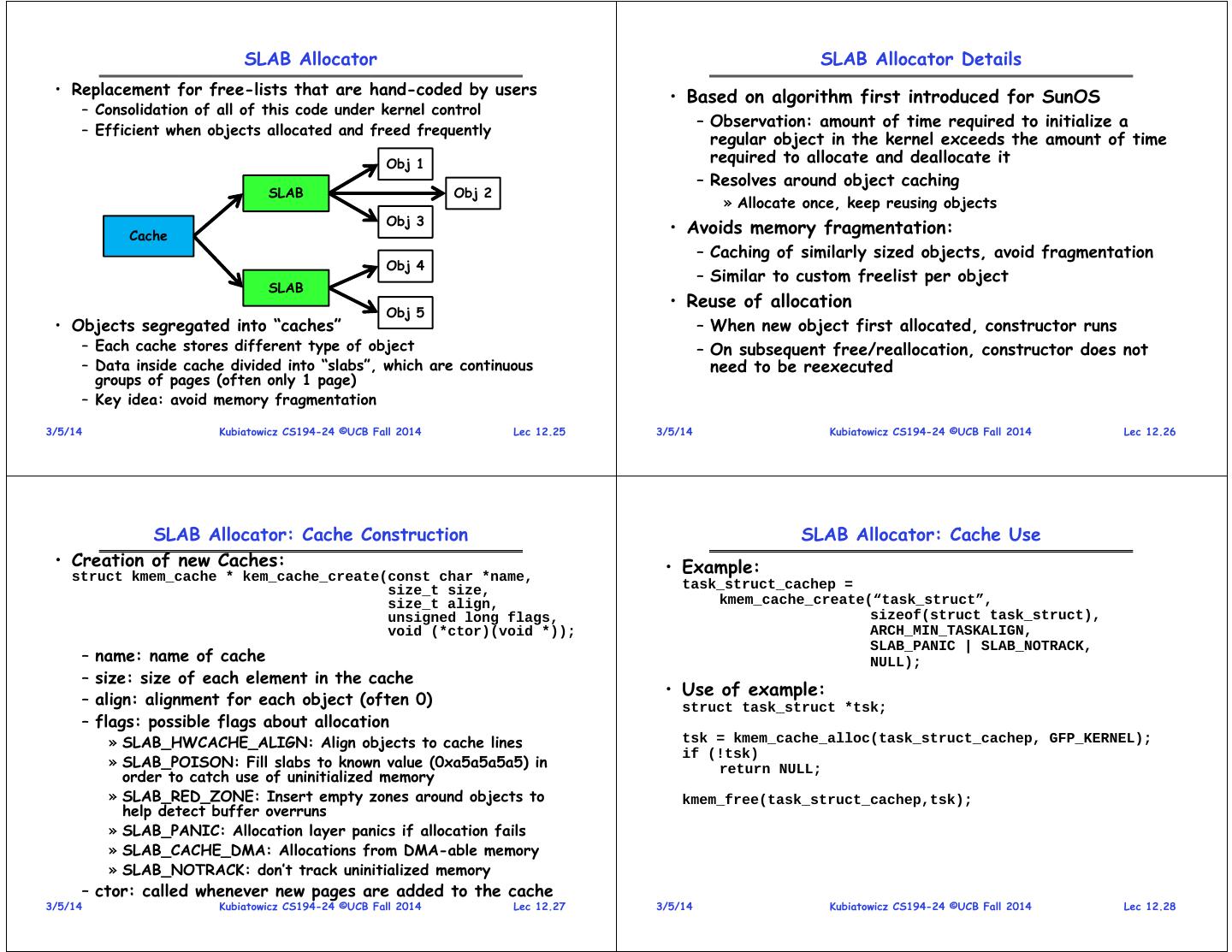
7 . SLAB Allocator SLAB Allocator Details • Replacement for free-lists that are hand-coded by users • Based on algorithm first introduced for SunOS – Consolidation of all of this code under kernel control – Observation: amount of time required to initialize a – Efficient when objects allocated and freed frequently regular object in the kernel exceeds the amount of time Obj 1 required to allocate and deallocate it – Resolves around object caching SLAB Obj 2 » Allocate once, keep reusing objects Obj 3 Cache • Avoids memory fragmentation: – Caching of similarly sized objects, avoid fragmentation Obj 4 – Similar to custom freelist per object SLAB • Reuse of allocation Obj 5 • Objects segregated into “caches” – When new object first allocated, constructor runs – Each cache stores different type of object – On subsequent free/reallocation, constructor does not – Data inside cache divided into “slabs”, which are continuous need to be reexecuted groups of pages (often only 1 page) – Key idea: avoid memory fragmentation 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.25 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.26 SLAB Allocator: Cache Construction SLAB Allocator: Cache Use • Creation of new Caches: • Example: struct kmem_cache * kem_cache_create(const char *name, size_t size, task_struct_cachep = size_t align, kmem_cache_create(“task_struct”, unsigned long flags, sizeof(struct task_struct), void (*ctor)(void *)); ARCH_MIN_TASKALIGN, SLAB_PANIC | SLAB_NOTRACK, – name: name of cache NULL); – size: size of each element in the cache • Use of example: – align: alignment for each object (often 0) struct task_struct *tsk; – flags: possible flags about allocation » SLAB_HWCACHE_ALIGN: Align objects to cache lines tsk = kmem_cache_alloc(task_struct_cachep, GFP_KERNEL); if (!tsk) » SLAB_POISON: Fill slabs to known value (0xa5a5a5a5) in return NULL; order to catch use of uninitialized memory » SLAB_RED_ZONE: Insert empty zones around objects to kmem_free(task_struct_cachep,tsk); help detect buffer overruns » SLAB_PANIC: Allocation layer panics if allocation fails » SLAB_CACHE_DMA: Allocations from DMA-able memory » SLAB_NOTRACK: don’t track uninitialized memory – ctor: called whenever new pages are added to the cache 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.27 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.28
8 . SLAB Allocator Details (Con’t) Recall: Kmalloc/Kfree: The “easy interface” to memory • Caches can be later destroyed with: • Simplest kernel interface to manage memory: int kmem_cache_destroy(struct kmem_cache *cachep); kmalloc()/kfree() – Allocate chunk of memory in kernel’s address space (will – Assuming that all objects freed be physically contiguous and virtually contiguous): – No one ever tries to use cache again void * kmalloc(size_t size, gfp_t flags); • All caches kept in global list – Including global caches set up with objects of powers of – Example usage: 2 from 25 to 217 struct dog *p; – General kernel allocation (kmalloc/kfree) uses least-fit p = kmalloc(sizeof(struct dog), GFP_KERNEL); for requested cache size if (!p) /* Handle error! */ • Reclamation of memory – Caches keep sorted list of empty, partial, and full slabs – Free memory: void kfree(const void *ptr); » Easy to manage – slab metadata contains reference count – Important restrictions! » Must call with memory previously allocated through » Objects within slabs linked together kmalloc() interface!!! – Ask individual caches for full slabs for reclamation » Must not free memory twice! 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.29 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.30 Alternatives for allocation Designing the File System: Access Patterns • According to Robert Love, “SLAB” has become a name • How do users access files? for any allocator with a similar API – Need to know type of access patterns user is likely to throw at system – Kinda like “Kleenex” has become a generic noun • Sequential Access: bytes read in order (“give me the • A number of options in the kernel for object allocation: next X bytes, then give me next, etc”) – SLAB: original allocator based on Bonwick’s paper from – Almost all file access are of this flavor SunOS • Random Access: read/write element out of middle of array (“give me bytes i—j”) – SLUB: Newer allocator with same interface but better – Less frequent, but still important. For example, virtual use of metadata (Default since Linux 2.6.23) memory backing file: page of memory stored in file » Keeps SLAB metadata in the page data structure (for pages – Want this to be fast – don’t want to have to read all that happen to be in kernel caches) bytes to get to the middle of the file » Debugging options compiled in by default, just need to be • Content-based Access: (“find me 100 bytes starting enabled with KUBIATOWICZ”) – SLOB: low-memory footprint allocator for embedded – Example: employee records – once you find the bytes, systems increase my salary by a factor of 2 – Many systems don’t provide this; instead, databases are built on top of disk access to index content (requires efficient random access) 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.31 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.32
9 . Designing the File System: Usage Patterns How to organize files on disk • Most files are small (for example, .login, .c files) • Goals: – A few files are big – nachos, core files, etc.; the nachos – Maximize sequential performance executable is as big as all of your .class files combined – Easy random access to file – However, most files are small – .class’s, .o’s, .c’s, etc. – Easy management of file (growth, truncation, etc) • First Technique: Continuous Allocation • Large files use up most of the disk space and – Use continuous range of blocks in logical block space bandwidth to/from disk » Analogous to base+bounds in virtual memory – May seem contradictory, but a few enormous files are » User says in advance how big file will be (disadvantage) – Search bit-map for space using best fit/first fit equivalent to an immense # of small files » What if not enough contiguous space for new file? • Although we will use these observations, beware usage – File Header Contains: patterns: » First sector/LBA in file » File size (# of sectors) – Good idea to look at usage patterns: beat competitors by – Pros: Fast Sequential Access, Easy Random access optimizing for frequent patterns – Cons: External Fragmentation/Hard to grow files – Except: changes in performance or cost can alter usage » Free holes get smaller and smaller » Could compact space, but that would be really expensive patterns. Maybe UNIX has lots of small files because big • Continuous Allocation used by IBM 360 files are really inefficient? – Result of allocation and management cost: People would create a big file, put their file in the middle 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.33 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.34 Linked List Allocation Linked Allocation: File-Allocation Table (FAT) • Second Technique: Linked List Approach – Each block, pointer to next on disk File Header Null – Pros: Can grow files dynamically, Free list same as file – Cons: Bad Sequential Access (seek between each block), Unreliable (lose block, lose rest of file) – Serious Con: Bad random access!!!! • MSDOS links pages together to create a file – Technique originally from Alto (First PC, built at Xerox) – Links not in pages, but in the File Allocation Table (FAT) » No attempt to allocate contiguous blocks » FAT contains an entry for each block on the disk » FAT Entries corresponding to blocks of file linked together – Access properies: » Sequential access expensive unless FAT cached in memory » Random access expensive always, but really expensive if FAT not cached in memory 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.35 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.36
10 . Indexed Allocation Multilevel Indexed Files (UNIX BSD 4.1) • Multilevel Indexed Files: Like multilevel address translation (from UNIX 4.1 BSD) – Key idea: efficient for small files, but still allow big files – File header contains 13 pointers » Fixed size table, pointers not all equivalent » This header is called an “inode” in UNIX – File Header format: » First 10 pointers are to data blocks » Block 11 points to “indirect block” containing 256 blocks » Block 12 points to “doubly indirect block” containing 256 indirect blocks for total of 64K blocks » Block 13 points to a triply indirect block (16M blocks) • Indexed Files (Nachos, VMS) • Discussion – System Allocates file header block to hold array of – Basic technique places an upper limit on file size that is pointers big enough to point to all blocks approximately 16Gbytes » User pre-declares max file size; » Designers thought this was bigger than anything anyone – Pros: Can easily grow up to space allocated for index would need. Much bigger than a disk at the time… » Fallacy: today, EOS producing 2TB of data per day Random access is fast – Pointers get filled in dynamically: need to allocate – Cons: Clumsy to grow file bigger than table size indirect block only when file grows > 10 blocks. Still lots of seeks: blocks may be spread over disk » On small files, no indirection needed 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.37 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.38 Example of Multilevel Indexed Files File Allocation for Cray-1 DEMOS • Sample file in multilevel basesize disk group indexed format: 1,3,2 – How many accesses for 1,3,3 1,3,4 Basic Segmentation Structure: block #23? (assume file 1,3,5 header accessed on open)? 1,3,6 Each segment contiguous on disk » Two: One for indirect block, 1,3,7 one for data 1,3,8 file header 1,3,9 – How about block #5? » One: One for data • DEMOS: File system structure similar to segmentation – Block #340? – Idea: reduce disk seeks by » Three: double indirect block, » using contiguous allocation in normal case indirect block, and data » but allow flexibility to have non-contiguous allocation • UNIX 4.1 Pros and cons – Cray-1 had 12ns cycle time, so CPU:disk speed ratio about the same as today (a few million instructions per seek) – Pros: Simple (more or less) Files can easily expand (up to a point) • Header: table of base & size (10 “block group” pointers) Small files particularly cheap and easy – Each block chunk is a contiguous group of disk blocks – Cons: Lots of seeks – Sequential reads within a block chunk can proceed at high Very large files must read many indirect block (four speed – similar to continuous allocation I/Os per block!) • How do you find an available block group? – Use freelist bitmap to find block of 0’s. 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.39 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.40
11 . Large File Version of DEMOS How to keep DEMOS performing well? base size base size disk group 1,3,2 • In many systems, disks are always full 1,3,3 – How to fix? Announce that disk space is getting low, so 1,3,4 please delete files? 1,3,5 1,3,6 » Don’t really work: people try to store their data faster 1,3,7 – Sidebar: Perhaps we are getting out of this mode with indirect 1,3,8 new disks… However, let’s assume disks full for now file header 1,3,9 block group • Solution: • What if need much bigger files? – Don’t let disks get completely full: reserve portion – If need more than 10 groups, set flag in header: BIGFILE » Free count = # blocks free in bitmap » Each table entry now points to an indirect block group » Scheme: Don’t allocate data if count < reserve – Suppose 1000 blocks in a block group 80GB max file – How much reserve do you need? » Assuming 8KB blocks, 8byte entries (10 ptrs1024 groups/ptr1000 blocks/group)*8K =80GB » In practice, 10% seems like enough • Discussion of DEMOS scheme – Tradeoff: pay for more disk, get contiguous allocation – Pros: Fast sequential access, Free areas merge simply » Since seeks so expensive for performance, this is a very Easy to find free block groups (when disk not full) good tradeoff – Cons: Disk full No long runs of blocks (fragmentation), so high overhead allocation/access – Full disk worst of 4.1BSD (lots of seeks) with worst of continuous allocation (lots of recompaction needed) 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.41 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.42 UNIX BSD 4.2 Attack of the Rotational Delay • Same as BSD 4.1 (same file header and triply indirect • Problem 2: Missing blocks due to rotational delay blocks), except incorporated ideas from DEMOS: – Issue: Read one block, do processing, and read next – Uses bitmap allocation in place of freelist block. In meantime, disk has continued turning: missed – Attempt to allocate files contiguously next block! Need 1 revolution/block! Skip Sector – 10% reserved disk space – Skip-sector positioning (mentioned next slide) • Problem: When create a file, don’t know how big it Track Buffer will become (in UNIX, most writes are by appending) (Holds complete track) – How much contiguous space do you allocate for a file? – Solution1: Skip sector positioning (“interleaving”) – In Demos, power of 2 growth: once it grows past 1MB, allocate 2MB, etc » Place the blocks from one file on every other block of a track: give time for processing to overlap rotation – In BSD 4.2, just find some range of free blocks – Solution2: Read ahead: read next block right after first, » Put each new file at the front of different range even if application hasn’t asked for it yet. » To expand a file, you first try successive blocks in » This can be done either by OS (read ahead) bitmap, then choose new range of blocks » By disk itself (track buffers). Many disk controllers have – Also in BSD 4.2: store files from same directory near internal RAM that allows them to read a complete track each other • Important Aside: Modern disks+controllers do many • Fast File System (FFS) complex things “under the covers” – Track buffers, elevator algorithms, bad block filtering – Allocation and placement policies for BSD 4.2 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.43 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.44
12 . Conclusion • SLAB Allocator – Consolidation of allocation code under single API – Efficient when objects allocated and freed frequently • Multilevel Indexed Scheme – Inode contains file info, direct pointers to blocks, – indirect blocks, doubly indirect, etc.. • Cray DEMOS: optimization for sequential access – Inode holds set of disk ranges, similar to segmentation • 4.2 BSD Multilevel index files – Inode contains pointers to actual blocks, indirect blocks, double indirect blocks, etc – Optimizations for sequential access: start new files in open ranges of free blocks – Rotational Optimization 3/5/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 12.45
3秒后跳转登录页面
去登陆

