展开查看详情
1 .Spark on Kubernetes Best Practice
Junjie Chen, Jerry Shao
Tencent Cloud
�
2 .About US
• Junjie Chen
• Senior Software Engineer at Tencent. Focus on big data and cloud area over
years, past work experience at Intel.
• Jerry Shao
• Expert Software Engineer at Tencent, Apache Spark Committer. Focus on open
source Big Data area, past work experience at Hortonworks, Intel.
�
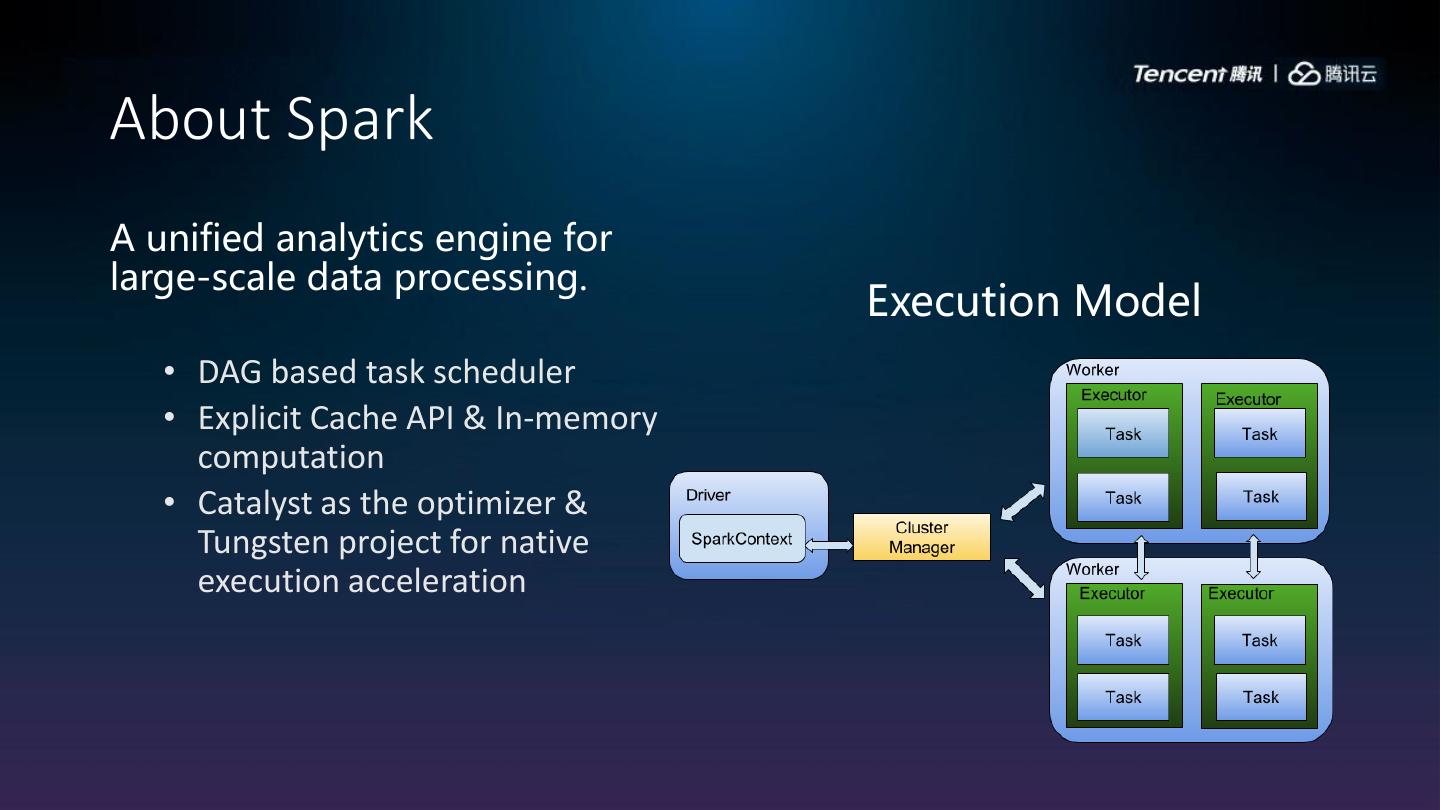
3 .About Spark
A unified analytics engine for
large-scale data processing.
Execution Model
• DAG based task scheduler
• Explicit Cache API & In-memory
computation
• Catalyst as the optimizer &
Tungsten project for native
execution acceleration
�
4 .Spark Cluster Manager
Apache Mesos Spark Apache Hadoop
Standalone Yarn
• Spark support • Lightweight • Comes from
Apache Mesos built-in cluster Hadoop 2.0
in early stage manager
�
5 .Spark Cluster Manager
Spark Apache
Apache Mesos Kubernetes
Standalone Hadoop Yarn
• Spark support • Lightweight • Comes from • Start from
Apache Mesos built-in cluster Hadoop 2.0 Spark 2.3.0
in early stage manager
�
6 .Why Kubernetes
• Kubernetes advantages
• Portability of Docker
• Out of box management support, namespace, RBAC,
authentication, logging, etc..
• Docker ecosystem and large OSS community
�
7 .Deployment Consideration
• Heterogeneous Deployment
• Serverless
�
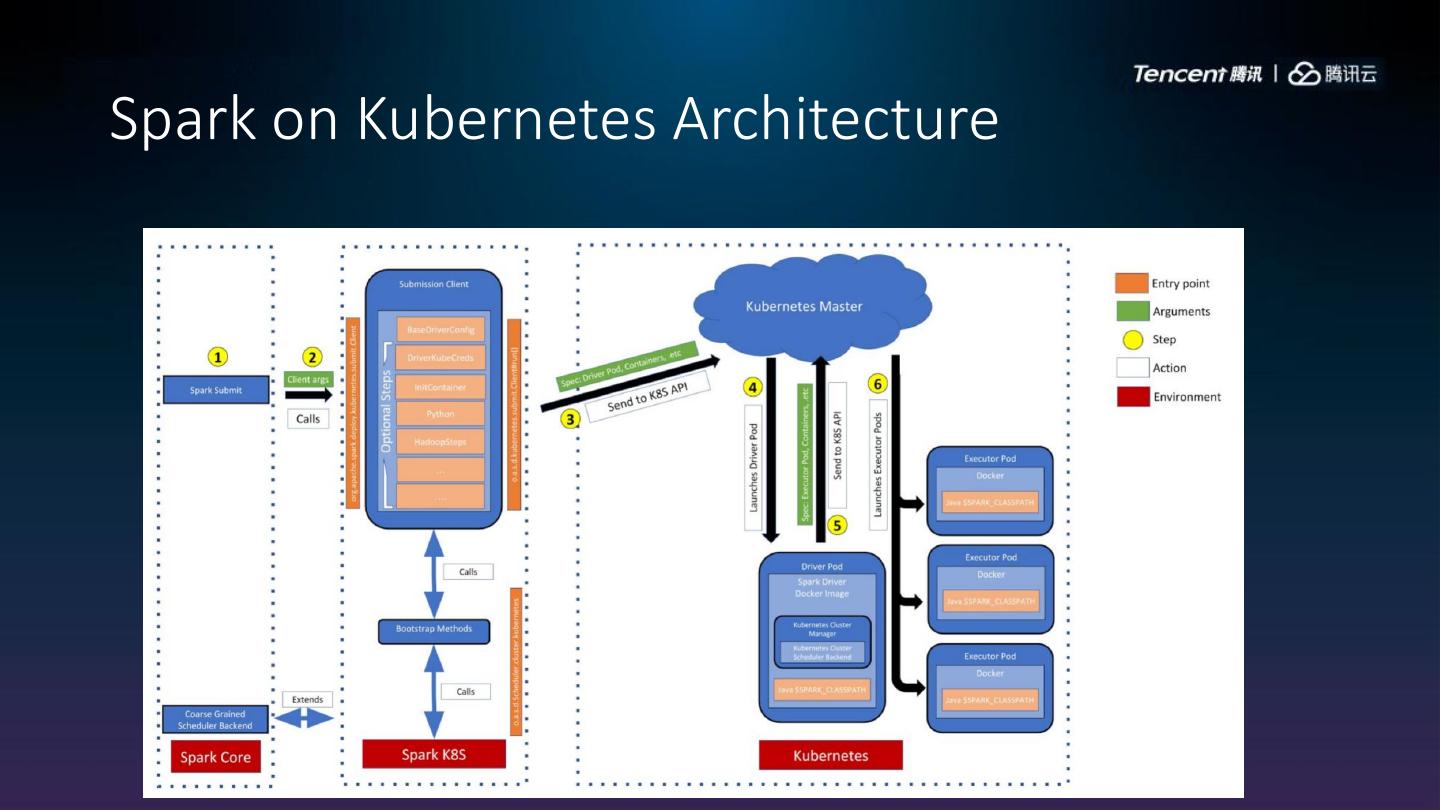
8 .Spark on Kubernetes Architecture
�
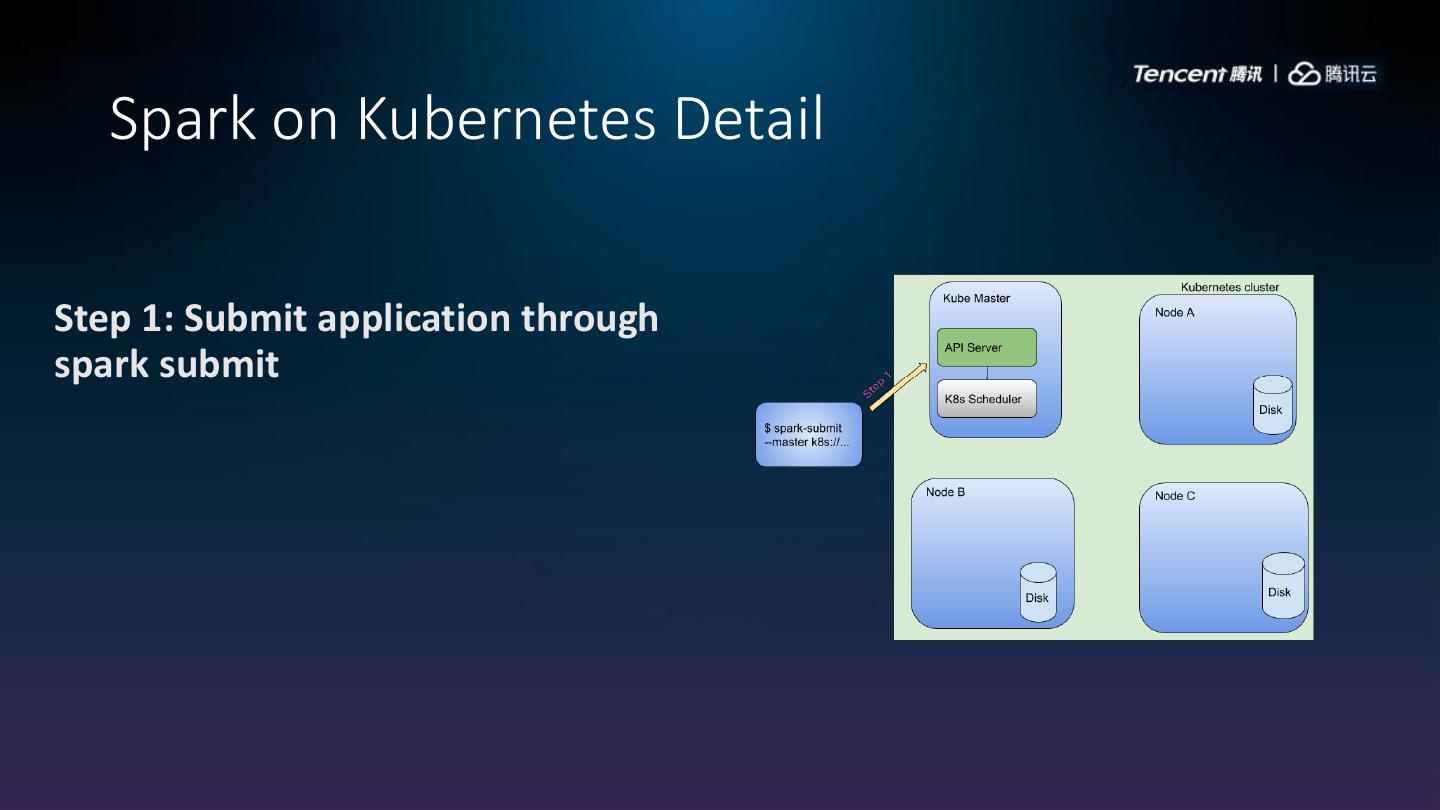
9 . Spark on Kubernetes Detail
Step 1: Submit application through
spark submit
�
10 . Spark on Kubernetes Detail
Step 1: Submit application
through spark submit
Step 2: Scheduler allocate driver
pod
�
11 . Spark on Kubernetes Detail
Step 1: Submit application
through spark submit
Step 2: Scheduler allocate driver
pod
Step 3:Driver Pod ask k8s
scheduler to allocate executor
pods
�
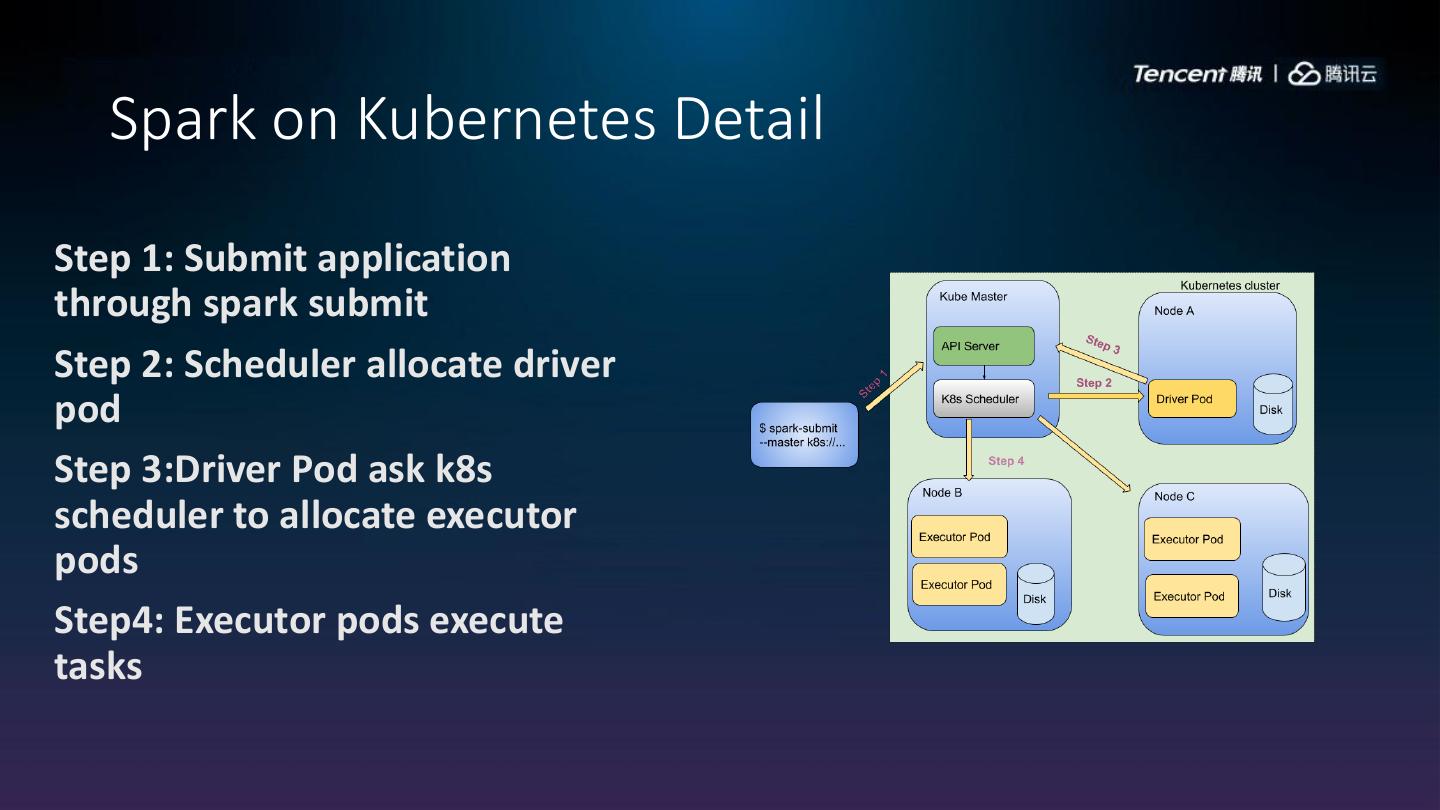
12 . Spark on Kubernetes Detail
Step 1: Submit application
through spark submit
Step 2: Scheduler allocate driver
pod
Step 3:Driver Pod ask k8s
scheduler to allocate executor
pods
Step4: Executor pods execute
tasks
�
14 . Spark on k8s Status
• Done in 2.4
• Cluster/Client mode spark submit
• Static allocation
• Staging server for dependencies management
• Java, Scala, Python, R.
• Working in Progress
• Dynamic allocation
• External shuffle service
• Security (Kerberos)
�
16 .Sparkling
• A PB scale EDW with benefits of fast deployment, resource
elasticity, high performance and cost-effective.
RDBMS
Oracle, Mysql
PostgreSQL
…
Object Storage
COS BI
…
Data Integration Data Marts
Other Data Analysis
Big Data Service
Elastic
MapReduce Cloud Data Warehouse
Machine Learning
Stream
Computing …
SCS …
�
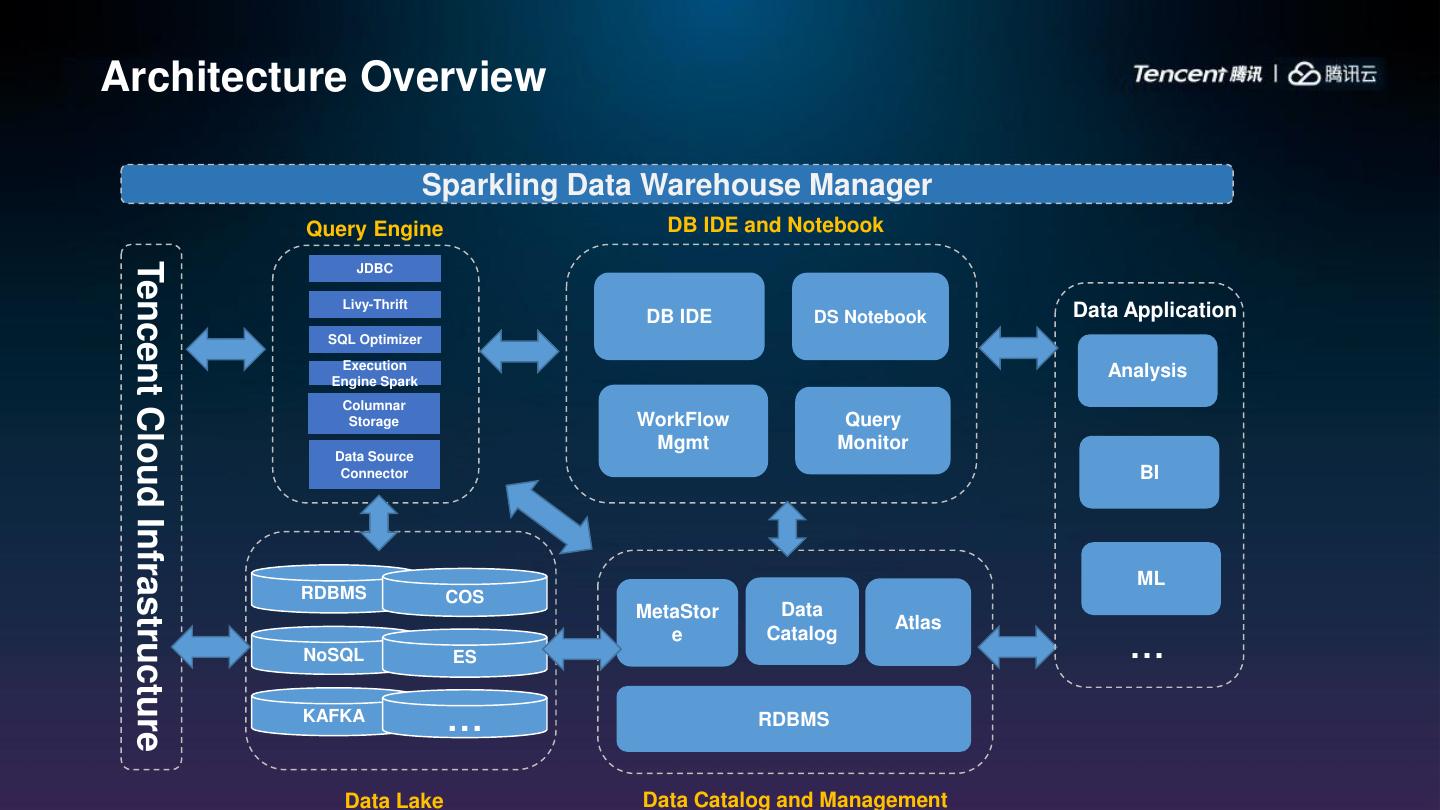
17 .Architecture Overview
Sparkling Data Warehouse Manager
Query Engine DB IDE and Notebook
Tencent Cloud Infrastructure
JDBC
Livy-Thrift
DB IDE DS Notebook Data Application
SQL Optimizer
Execution
Engine Spark
Analysis
Columnar
Storage WorkFlow Query
Mgmt Monitor
Data Source
Connector BI
ML
RDBMS COS
MetaStor Data
Atlas
…
e Catalog
NoSQL ES
KAFKA
… RDBMS
Data Lake Data Catalog and Management
�
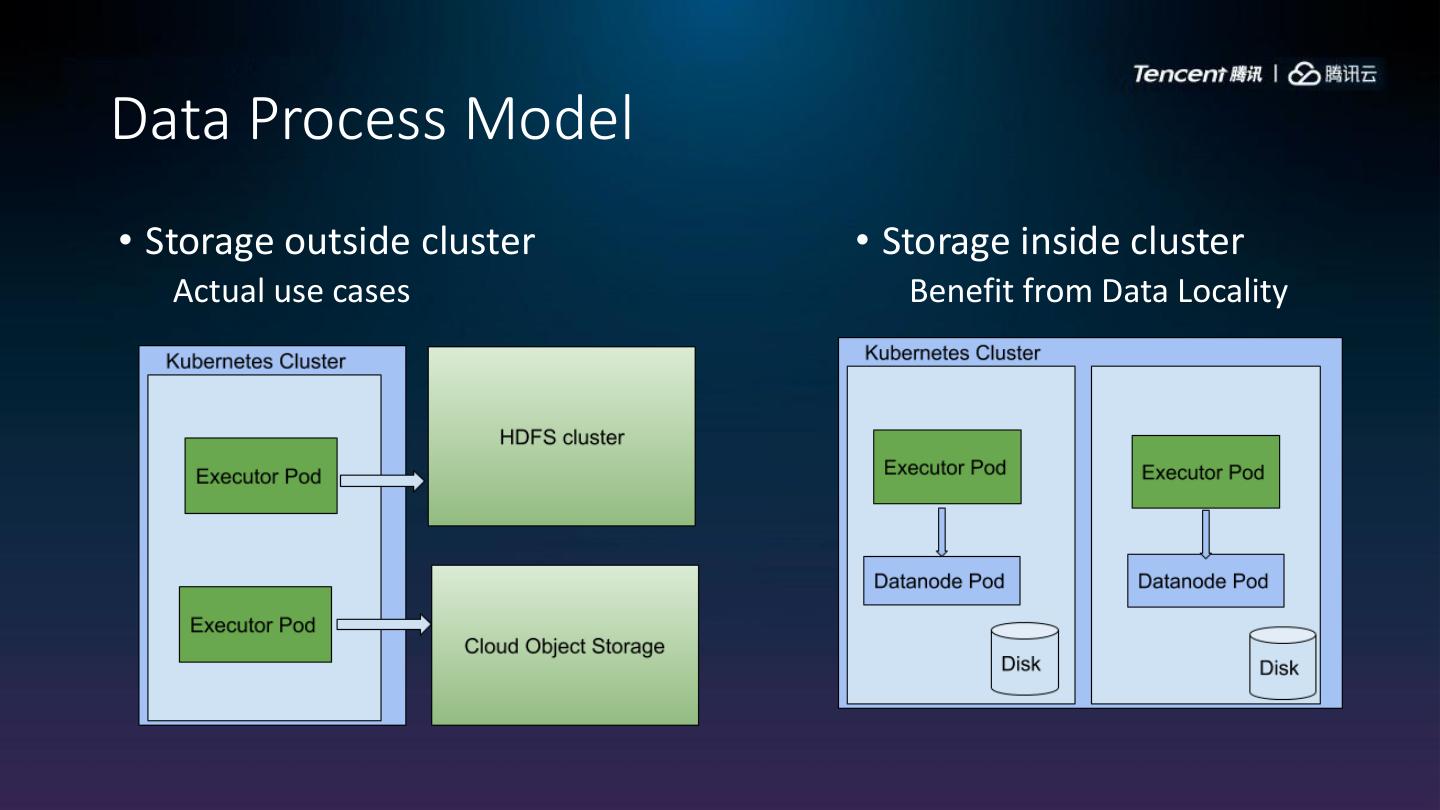
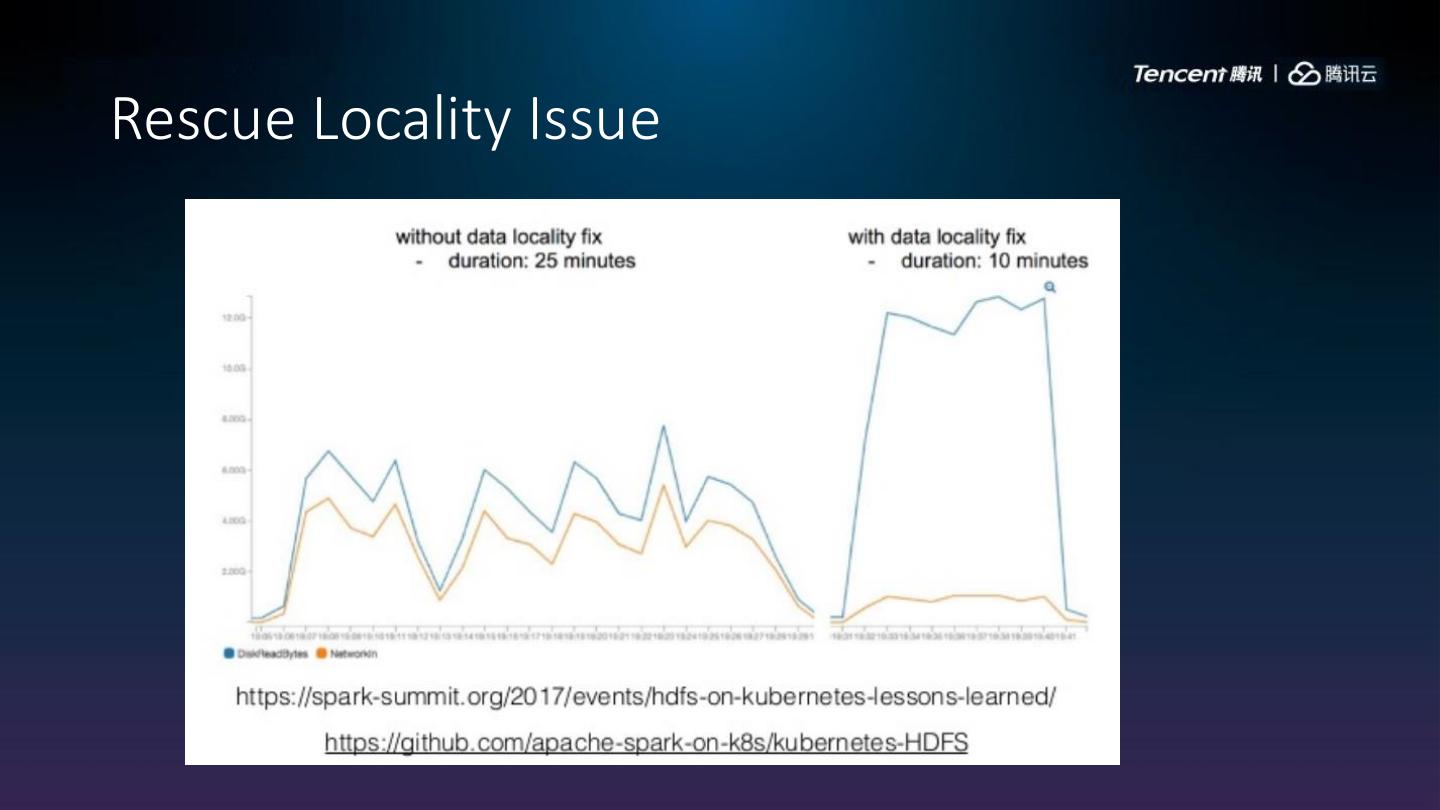
18 .Data Process Model
• Storage outside cluster • Storage inside cluster
Actual use cases Benefit from Data Locality
�
19 .Sparkling on Kubernetes
�
20 .Deploy HDFS
• Use same image for Namenode,
Datanode.
• Identify pod type through docker
env.
• Define Namenode as NodePort
service.
�
21 .Deploy HDFS Cont.
• Namenode • Datanode
�
22 .Other components
• Deploy as NodePort services
�
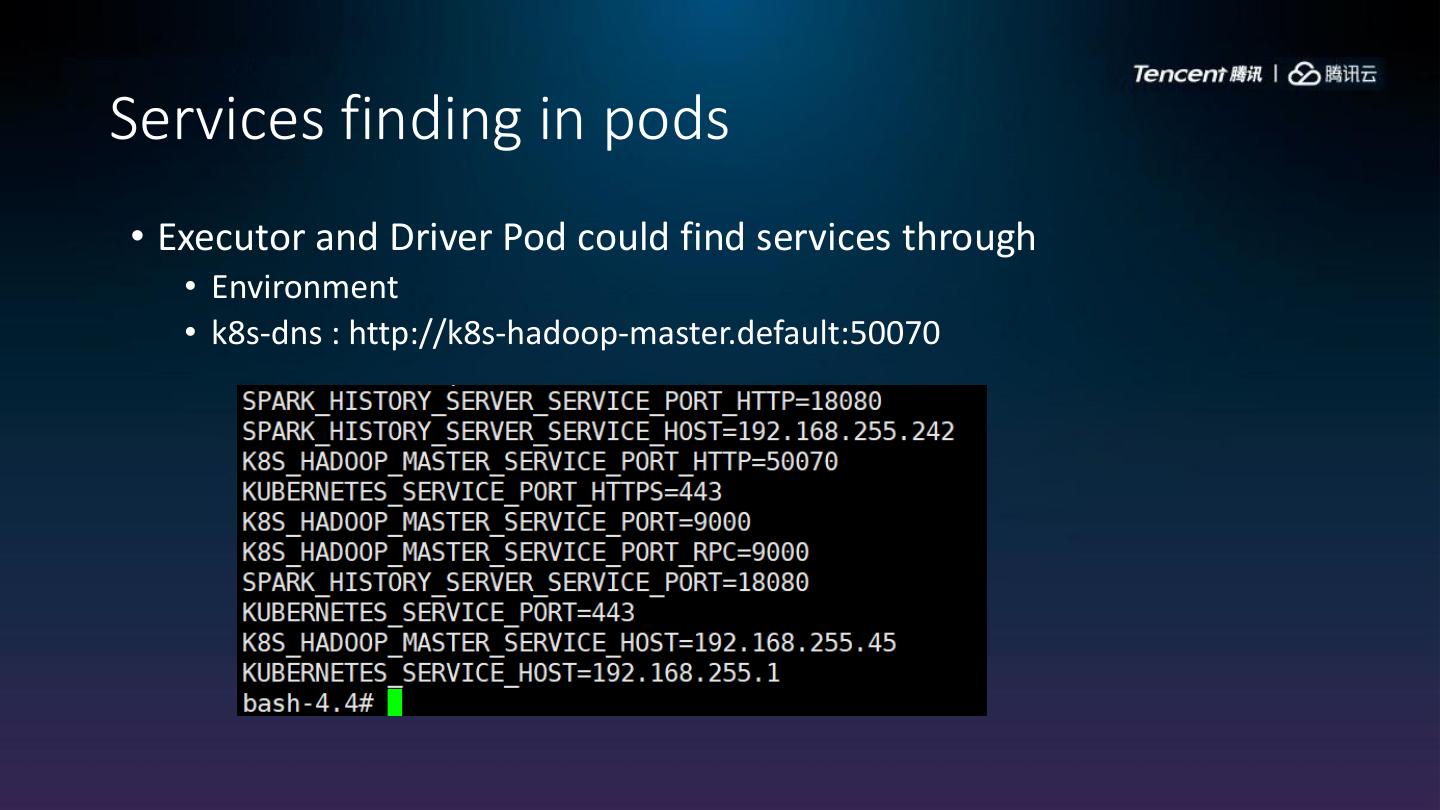
23 .Services finding in pods
• Executor and Driver Pod could find services through
• Environment
• k8s-dns : http://k8s-hadoop-master.default:50070
�
25 .Environment
• Spark on K8S env1 • Spark on Yarn env1
• Allocated through TKE • Allocated through CVM
• 10 x (32core + 128G + 4T HDD x 12 ) • 6 x (56 core + 224G + 4T HDD x 12)
• Spark on K8S env2 • Spark on Yarn env2
• Allocated through TKE • Allocated through CVM
• 10 x (16core + 128G + 200G SSDx1) • 10 x (16core + 128G + 200G SSDx1)
�
26 .Workload
• TPD-DS
• The TPC Benchmark DS is a decision support benchmark.
• It includes 99 queries of statistic, report, OLAP, data mine
• Skew data, close to real scenario.
• Scale
• 1T
�
27 . Configurations
• Common configuration • Kubernetes specific configuration
Key Value
key Value
spark.kubernetes.allocation.batch.size 5
spark.driver.memory 16G
spark.kubenetes.driver.limit.cores 1
spark.executor.memory 6G
spark.kubernetes.executor.limit.cores 1
spark.executor.cores 1
spark.kubernetes.node.selector.executorkey compute
spark.executor.memoryOverhead 1G
spark.kubernetes.authenticate.driver.servic spark
spark.sql.shuffle.partition 1024
eAccountName
spark.sql.autoBroadcastJoinThreshold 32m spark.kubernetes.driver.volumes.hostpath.r /mnt
spark.executor.instances 150 esult.mount.path
spark.kubernetes.executor.volumes.hostpat /mnt
h.shuffle.mount.path
�
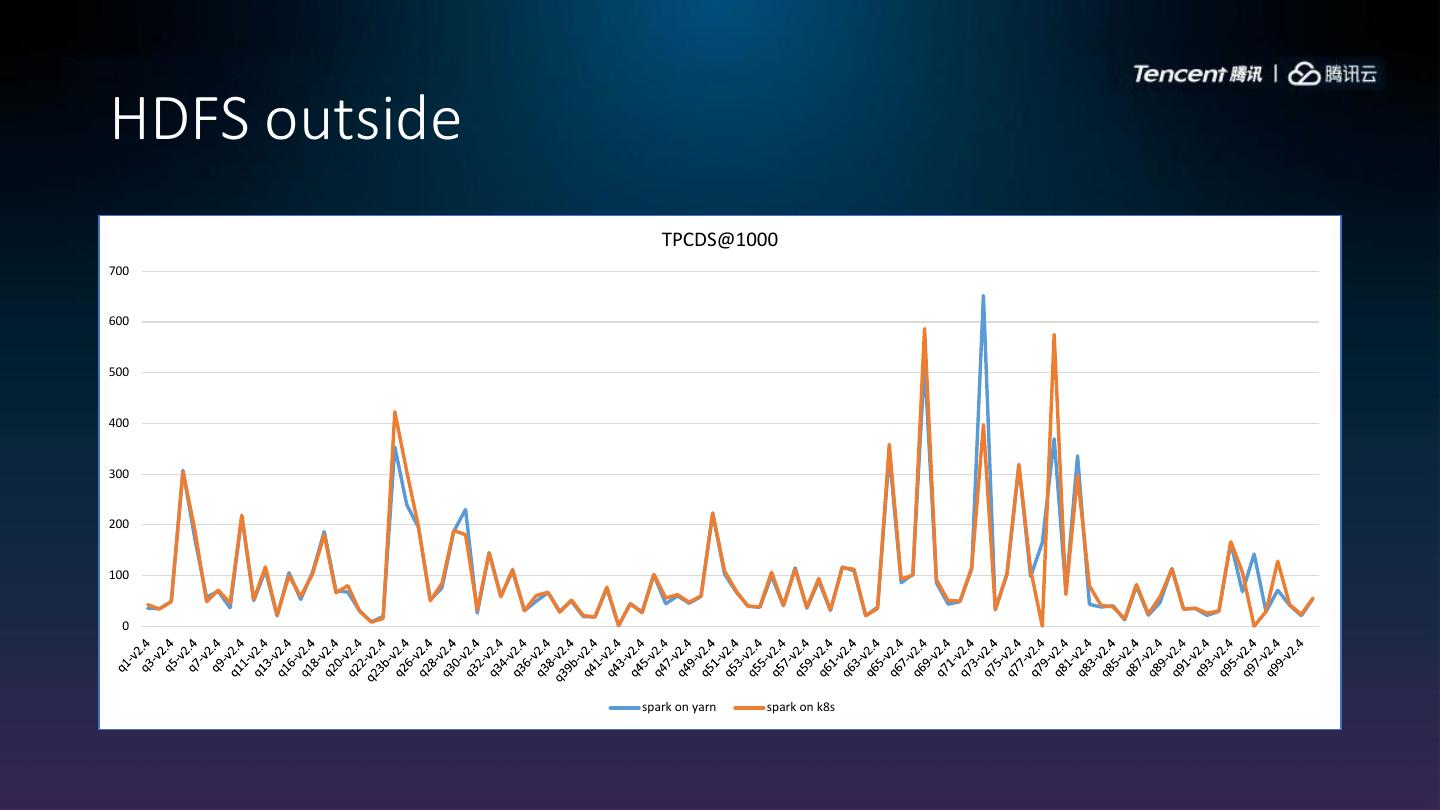
28 .HDFS outside
TPCDS@1000
700
600
500
400
300
200
100
0
spark on yarn spark on k8s
�
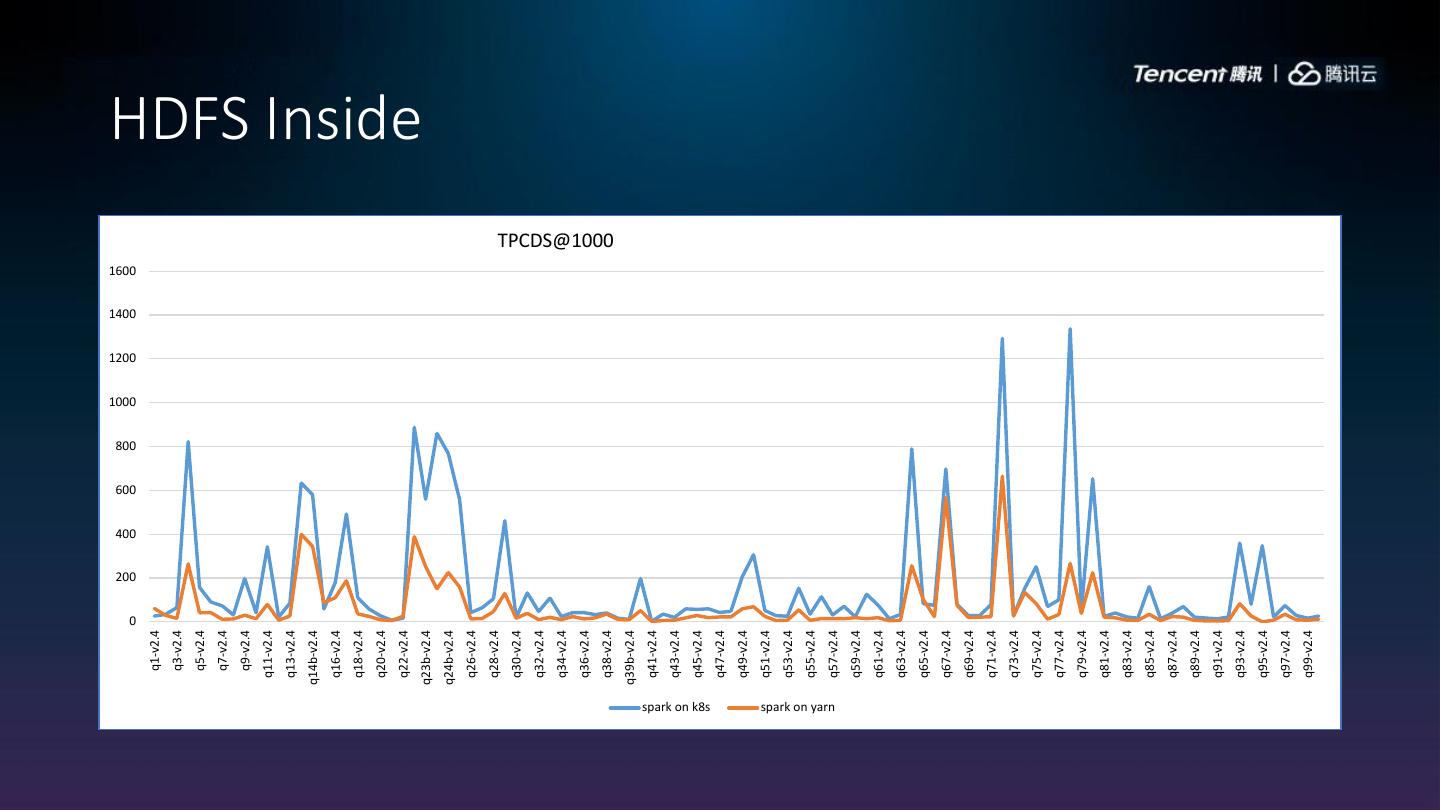
29 . 200
400
600
800
1000
1200
1400
1600
0
q1-v2.4
q3-v2.4
q5-v2.4
q7-v2.4
q9-v2.4
q11-v2.4
q13-v2.4
q14b-v2.4
q16-v2.4
q18-v2.4
q20-v2.4
q22-v2.4
HDFS Inside
q23b-v2.4
q24b-v2.4
q26-v2.4
q28-v2.4
q30-v2.4
q32-v2.4
q34-v2.4
q36-v2.4
TPCDS@1000
q38-v2.4
q39b-v2.4
q41-v2.4
q43-v2.4
q45-v2.4
spark on k8s
q47-v2.4
q49-v2.4
q51-v2.4
q53-v2.4
q55-v2.4
spark on yarn
q57-v2.4
q59-v2.4
q61-v2.4
q63-v2.4
q65-v2.4
q67-v2.4
q69-v2.4
q71-v2.4
q73-v2.4
q75-v2.4
q77-v2.4
q79-v2.4
q81-v2.4
q83-v2.4
q85-v2.4
q87-v2.4
q89-v2.4
q91-v2.4
q93-v2.4
q95-v2.4
q97-v2.4
q99-v2.4
�