































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
PRCU: A New RCU Design with Low Synchronization Latency
A read-copy update is a widely used synchronization mechanism in Linux kernel. Current RCU implementation eliminates the contention and memory fence on the reading side to achieve high performance but remains long synchronization latency for updates. It's not uncommon to see high-latency reports caused by RCU write side in the Linux kernel mailing list. We provide a new RCU implementation called Passive Read-copy update which achieves relatively low synchronization latency while keeping read side fence-free. The key idea of PRCU is allowing read side to actively report on synchronization and recording an accurate list of cpus on which the threads have done read lock and haven't been scheduled out.
展开查看详情
1 .AN RCU WITH LOW SYNC LATENCY PRCU 张恒 ZHANG HENG
2 . WHAT IS RCU READ READ WRITE • Read-Copy Update • A synchronization primitive EXCLUSIVE which allows readers and LOCK writers execute concurrently • Great for read-mostly data READER • Two phase: WRITER LOCK • update on a new copy • reclaim the old copy (when it is safe) RCU
3 . LIST WITH RWLOCK LOCK_READ 1 2 3 4 UNLOCK_READ LOCK_WRITE 1 2 3 4 UNLOCK_WRITE LOCK_READ 1 3 4 UNLOCK_READ
4 . LIST WITH RCU RCU_READ_LOCK 1 2 3 4 R 1 2 3 4 R 1 2 3 4 U R 1 2 3 4 R RCU_READ_UNLOCK SYNCHRONIZE_RCU 1 2 3 4
5 . RWLOCK OR RCU SAME PROBLEM • Reader-Writer Locks • RCU • when writers can enter CS • when updaters can reclaim the resource ENSURE ALL PREVIOUS READERS HAVE LEFT
6 . RWLOCK OR RCU DIFFERENT ATTITUDE • Reader-Writer Locks • RCU • different algorithms for different • extremely low overhead on read workloads, e.g. rwsem, brlock … side (fastpath) • extremely high overhead on write side
7 . RWLOCK OR RCU TRADEOFF READER WRITER RWSEM HEAVY CONTENTION LIGHTWEIGHT CSNZI COHORT LOCK LIGHT CONTENTION MORE ATOMIC OPS BRLOCK NO CONTENTION MUCH ATOMIC OPS PRWLOCK PERCPU-RWSEM NO FENCE IPI PRCU NO BLOCKING IPI RCU NO BLOCKING IPI
8 . USING ATOMIC OPS • Ref Counter - Single WRITE • R: heavy contention • W: check one counter COUNTER READ READ READ READ READ READ READ READ READ READ READ …
9 . USING ATOMIC OPS • Ref Counter - Multiple WRITE • R: contention reduced • W: check more counters COUNTER COUNTER COUNTER READ READ READ READ READ READ READ READ READ READ READ …
10 . USING ATOMIC OPS WRITE • CSNZI - Hierarchical • R: contention reduced, may increase latency COUNTER • W: check one counter COUNTER COUNTER COUNTER READ READ READ READ READ READ
11 . USING ATOMIC OPS • Ref Counter - 1:1 WRITE • R: No contention • W: check all counters COUNTER COUNTER COUNTER COUNTER COUNTER READ READ READ READ READ
12 . REMOVE FENCE WHAT IS FENCE 1.WRITE X 1.WRITE X CPU0 CPU1 CPU2 CPU3 2.FENCE 2.READ Y 3.READ Y 1 1 2 CACHE CACHE 2 2 1 CACHE SYSTEM
13 . LOCK WITH FENCE 1.R = 1 1.W = 1; 2.FENCE; 2.FENCE; 3.IF (W == 0) 3.IF (R == 0) 4. ENTER CS 4. ENTER CS 5.ELSE CPU0 CPU1 CPU2 CPU3 5.ELSE 6. WAIT 6. … 1 CACHE CACHE R:1 CACHE SYSTEM 2 1 W:0 W:1 2 R:1
14 . PROBLEM WITHOUT FENCE INCONSISTENCY 1.W = 1; 1.R = 1 2.FENCE; 2.IF (W == 0) 3.IF (R == 0) 3. ENTER CS 4. ENTER CS 4.ELSE CPU0 CPU1 CPU2 CPU3 5.ELSE 5. WAIT 6. … 1 2 CACHE CACHE 1 W:0 CACHE SYSTEM W:1 2 R:0 R:1
15 . PROBLEM WITHOUT FENCE INCONSISTENCY 1.W = 1; 1.R = 1 2.FENCE; 2.IF (W == 0) 3.IF (R == 0) 3. ENTER CS 4. ENTER CS 4.ELSE CPU0 CPU1 CPU2 CPU3 5.ELSE 5. WAIT 6. … 1 2 CACHE CACHE 1 W:0 CACHE SYSTEM W:1 2 WHEN DO WE ENSURE R:0 READERS CAN SEE W=1? R:1
16 . THINKING ON HARDWARE I BOUNDED STALENESS CPU0 CPU1 CPU2 CPU3 CACHE CACHE 1 CACHE SYSTEM 1 2 W:1 WATI FOR BS 2 THE WRITER WILL SEE THE READER R:1
17 . THINKING ON HARDWARE I BOUNDED STALENESS CPU0 CPU1 CPU2 CPU3 CACHE CACHE 1 CACHE SYSTEM W:1 1 2 WATI FOR BS 2 THE READER WILL SEE THE WRITER R:1
18 . THINKING ON HARDWARE II BIASED FENCE • Target : the buffer of issued instructions • Light fence: • Async or Passively report the buffer info • Heavy fence: • Wait for remote cores’ previously issued instructions committing
19 . SOLUTION ON SOFTWARE MONOTONE VERSION READER WRITER READER GLOBAL_CNT++ LOCAL_CNT SYNC LOCAL_CNT SYNC CHECK CHECK
20 . SOLUTION ON SOFTWARE MONOTONE VERSION READER WRITER READER GLOBAL_CNT++ LOCAL_CNT SYNC LOCAL_CNT SYNC CHECK CHECK WHAT IF READERS HAVE NO CHANCE TO SYNC
21 . SUPPLEMENT EVENTS & REDUCE EVENTS • Event CPU0 CPU1 CPU2 CPU3 • IPI • Reducing Events READ READ • Domain IDLE/ READ OTHER UPDATE OTHER CONTEXT READ OTHER IPI IN IN OUT DOMAIN DOMAIN DOMAIN
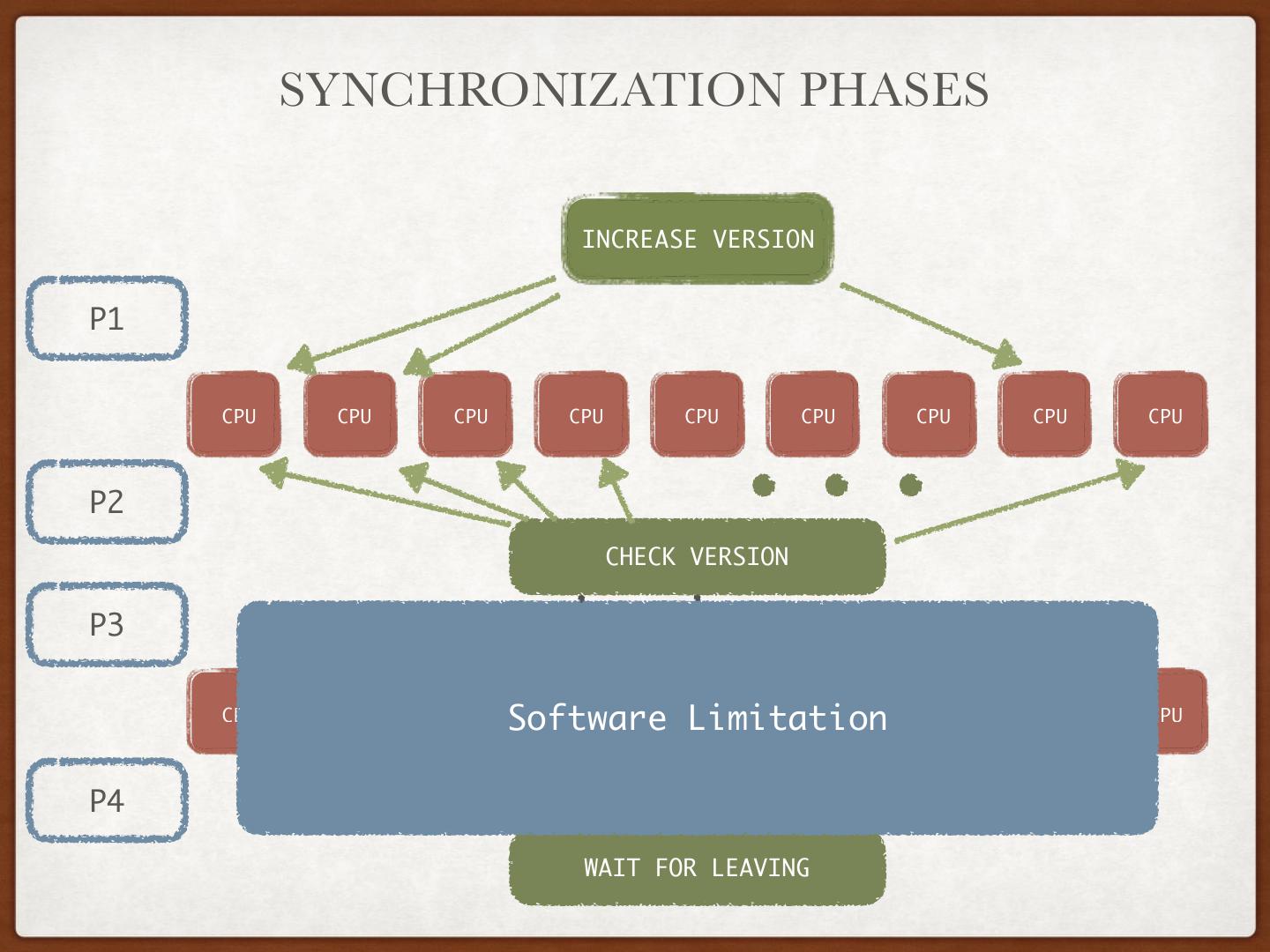
22 . PRCU SYNCHRONIZATION PHASES INCREASE VERSION P1 CPU CPU CPU CPU CPU CPU CPU CPU CPU P2 CHECK VERSION P3 IPI CPU CPU CPU CPU CPU CPU CPU CPU CPU P4 WAIT FOR LEAVING
23 . SYNCHRONIZATION PHASES INCREASE VERSION P1 No dependency: O(1) if hardware support CPU CPU CPU CPU CPU CPU CPU CPU CPU P2 CHECK VERSION P3 IPI CPU CPU CPU CPU CPU CPU CPU CPU CPU P4 WAIT FOR LEAVING
24 . SYNCHRONIZATION PHASES INCREASE VERSION P1 CPU CPU CPU CPU CPU CPU CPU CPU CPU No fence: O(1) cache miss + P2 O(N) instructions (1cycle on pipeline) CHECK VERSION P3 IPI CPU CPU CPU CPU CPU CPU CPU CPU CPU P4 WAIT FOR LEAVING
25 . SYNCHRONIZATION PHASES INCREASE VERSION P1 CPU CPU CPU CPU CPU CPU CPU CPU CPU P2 CHECK VERSION P3 IPI CPU CPU CPU Software CPU Limitation CPU CPU CPU CPU CPU P4 WAIT FOR LEAVING
26 . CORRECTNESS • Testing • Pass rcutorture(—torture rcu) • Formal Verification • Pass model checking
27 . FORMAL VERIFICATION • Tool • CBMC, https://github.com/diffblue/cbmc • Target • prcu_read_lock, prcu_read_unlock, synchronized_prcu • Hardware • 16 cores, Intel Xeon CPU@2.4GHz, 16G Memory • Configuration • 2 reader threads + 1 writer thread + 1 main thread (+ 3 interrupt threads) • safety + liveness • Memory model : SC, TSO, PSO
28 . PERFORMANCE COMPARE WITH TREE RCU (LINUX 4.0.5) PRCU RCU-expedited PRCU 1,000,000,000 100,000,000 10,000,000 Sync Latency (cycle) 1,000,000 62,903K 71,832K 100,000 44,328K 42,813K 47,861K 10,000 1,000 223K 123K 61K 60K 80K 100 28K 13K 19K 10K 12K 10 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 core
29 . SUMMARY • Introduce a problem on reader-writer synchronization • A solution call PRCU which has low latency on ideal hardwares • Proof correctness with testing and formal verification • Code: https://github.com/lihao/linux-prcu
相关推荐
3秒后跳转登录页面
去登陆

