









































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Analytics Zoo: Unifying Big Data Analytics and AI for Spark
包括了3部分的内容:Apache Spark之上的分布式深度学习框架BigDL原理介绍,其中涉及分布式数据并行训练的基本原理,如何利用Analytics Zoo构建端到端的分布式深度学习应用,及Analytics Zoo的特性,功能以及实际案例分享。
展开查看详情
1 .Analytics Zoo: Unifying Big Data Analytics and AI for Apache Spark
2 .Motivations
3 .Data Scale Driving Deep Learning Process “Machine Learning Yearning”, “Hidden Technical Debt in Machine Learning Systems”, Andrew Ng, 2016 Google, NIPS 2015 paper
4 . Chasm b/w Deep Learning and Big Data Communities The Chasm Deep learning experts Average users (Big Data users, data scientists, analysts, etc.)
5 .Large-Scale Image Recognition at JD.com
6 .Unified Big Data Analytics Platform Hadoop & Spark Platform Machine Graph Leaning Analytics SQL Notebook Spreadsheet Batch Streaming Interactive R Java Python DataFrame Flink Storm Data ML Pipelines Processing SQL SparkR Streaming MLlib GraphX & Analysis MR Giraph Spark Core Resource Mgmt YARN ZooKeeper & Co-ordination Data Flume Kafka Storage HDFS Parquet Avro HBase Input
7 .Overview
8 . BigDL Bringing Deep Learning To Big Data Platform • Distributed deep learning framework for Apache Spark* • Make deep learning more accessible to big data users and data scientists • Write deep learning applications as standard Spark programs • Run on existing Spark/Hadoop clusters (no changes needed) DataFrame • Feature parity with popular deep learning frameworks ML Pipeline • E.g., Caffe, Torch, Tensorflow, etc. SQL SparkR Streaming MLlib GraphX • High performance (on CPU) • Powered by Intel MKL and multi-threaded programming Spark Core • Efficient scale-out https://github.com/intel-analytics/BigDL • Leveraging Spark for distributed training & inference https://bigdl-project.github.io/
9 . BigDL Run as Standard Spark Programs Standard Spark jobs • No changes to the Spark or Hadoop clusters needed Iterative • Each iteration of the training runs as a Spark job Data parallel • Each Spark task runs the same model on a subset of the data (batch) BigDL Program Worker Worker Worker Spark Spark BigDL lib Intel MKL DL App on Driver Executor Task (JVM) Spark BigDL Spark Standard Program library jobs Spark jobs Worker Worker Worker Spark Spark BigDL lib Intel MKL Executor Task (JVM)
10 . Data Parallel Training Worker 1 Worker 2 Worker n Sample Partition 1 Partition 2 Partition n RDD Task 1 Task 2 Task n: zip Sample and model RDDs, and compute gradient on co-located Sample and model partitions Partition 1 Partition 2 Model Partition n RDD “Model Forward-Backward” Job
11 . Distributed Training in BigDL Data Parallel, Synchronous Mini-Batch SGD Prepare training data as an RDD of Samples Construct an RDD of models (each being a replica of the original model) for (i <- 1 to N) { //”model forward-backward” job for each task in the Spark job: read the latest weights get a random batch of data from local Sample partition compute errors (forward on local model replica) compute gradients (backward on local model replica) //”parameter synchronization” job aggregate (sum) all the gradients update the weights per specified optimization method }
12 . Network and Memory Bottlenecks • Large-scale problem settings Training –Model size: 100s of millions ~ billions unique features Set –Weight (W) and gradient (G) are both double vector, one entry for each Partition 1 unique feature Worker –Training data: billions ~ trillions training samples Training samples Sample –Partitioned & cached across workers cached in worker memory 2 1 3 Partition 2 Worker Driver 1 Sample Broadcast W (>800MB) Each task computes to each worker in 2 4 G (>800MB) in each each iteration iteration 3 … 1 Partition n Worker Each task sends G Sample (>800MB) for 3 aggregation in each 2 iteration 12
13 . Parameter Synchronization local local local gradient gradient gradient 1 2 n 1 2 n 1 2 n ∑ ∑ ∑ gradient 1 1 gradient 2 2 gradient n n update update update weight 1 1 weight 2 2 weight n n Task 1 Task 2 Task n “Parameter Synchronization” Job
14 . Training Scalability Throughput of ImageNet Inception v1 training (w/ BigDL 0.3.0 and dual-socket Intel Broadwell 2.1 GHz); the throughput scales almost linear up to 128 nodes (and continue to scale reasonably up to 256 nodes). Source: Scalable Deep Learning with BigDL on the Urika-XC Software Suite (https://www.cray.com/blog/scalable-deep-learning-bigdl-urika-xc-software-suite/)
15 . Analytics Zoo Build E2E Deep Learning Applications for Big Data at Scale Analytics + AI Platform for Apache Spark and BigDL • Anomaly detection, sentiment analysis, fraud detection, image Reference Use Cases generation, etc. Built-In Deep Learning • Image classification, object detection, text classification, Models recommendations, etc. Feature transformations for Feature Engineering • Image, text, 3D imaging, time series, speech, etc. • Native deep learning support in Spark DataFrames and ML Pipelines High-Level Pipeline APIs • Autograd, Keras and transfer learning APIs for model definition • Model serving API for model serving/inference pipelines Backbends Spark, BigDL, TensorFlow, Python, https://github.com/intel-analytics/analytics-zoo/ etc. https://analytics-zoo.github.io/
16 . Models Interoperability Support (e.g., between TensorFlow, Keras, Caffe, Torch, BigDL models) • Load existing TensorFlow, Keras, Caffe, Torch Model • Useful for inference and model fine-tuning • Allows for transition from single-node for distributed application deployment • Allows for model sharing between data scientists and production engineers
17 . Industrial Inspection Platform in Midea* and KUKA* https://software.intel.com/en-us/articles/industrial-inspection-platform-in-midea-and-kuka- using-distributed-tensorflow-on-analytics
18 .TensorFlow Object Detection: SSDLite+MobileNet V2
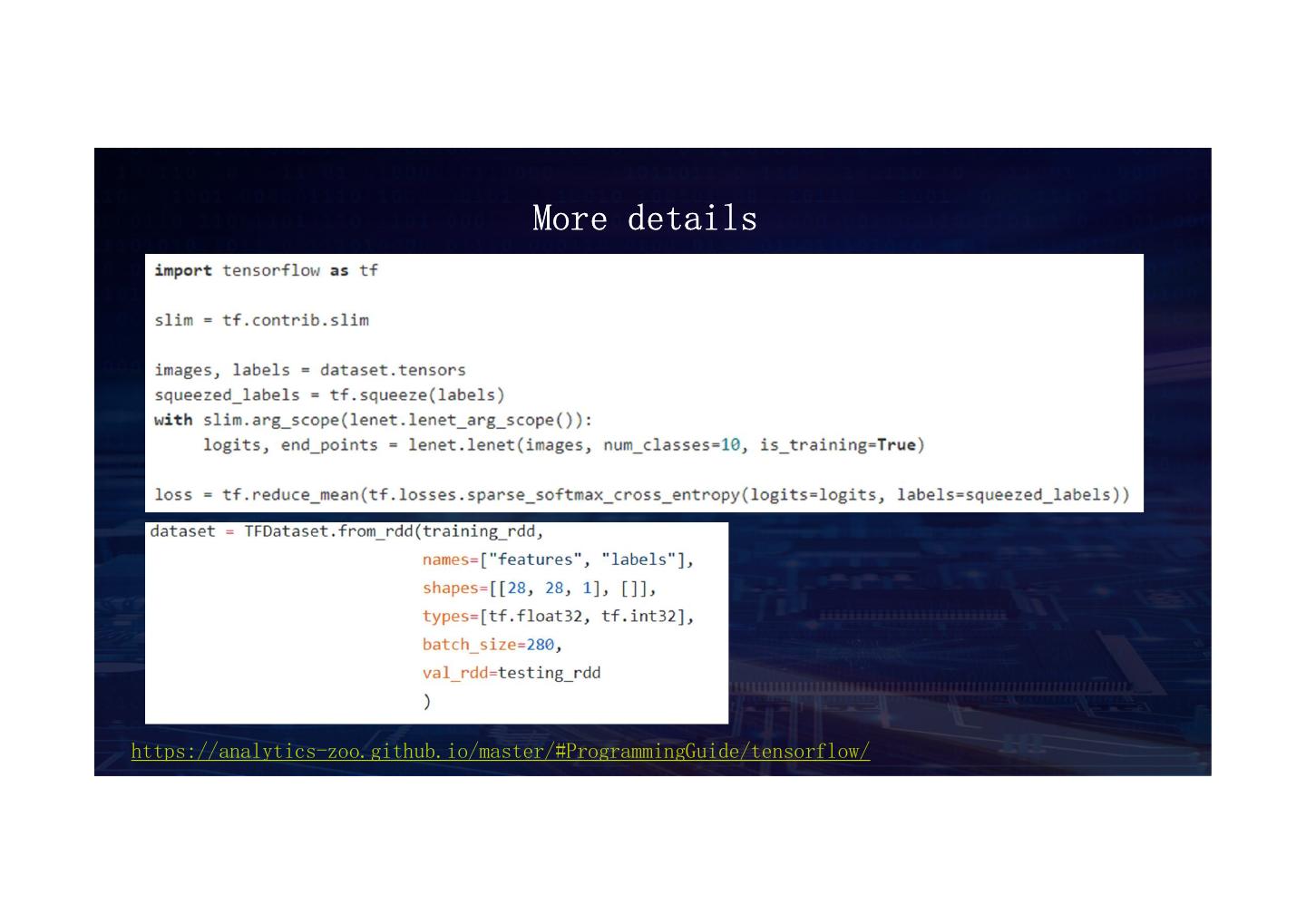
19 . More details https://analytics-zoo.github.io/master/#ProgrammingGuide/tensorflow/
20 . More details https://analytics-zoo.github.io/master/#ProgrammingGuide/tensorflow/
21 . Feature Engineering 1. Read images into local or distributed ImageSet from zoo.common.nncontext import * from zoo.feature.image import * spark = init_nncontext() local_image_set = ImageSet.read(image_path) distributed_image_set = ImageSet.read(image_path, spark, 2) 2. Image augmentations using built-in ImageProcessing operations transformer = ChainedPreprocessing([ImageBytesToMat(), ImageColorJitter(), ImageExpand(max_expand_ratio=2.0), ImageResize(300, 300, -1), ImageHFlip()]) new_local_image_set = transformer(local_image_set) new_distributed_image_set = transformer(distributed_image_set) Image Augmentations Using Built-in Image Transformations (w/ OpenCV on Spark)
22 . Autograd, Keras &Transfer Learning APIs 1. Use transfer learning APIs to • Load an existing Caffe model • Remove last few layers • Freeze first few layers • Append a few layers from zoo.pipeline.api.net import * full_model = Net.load_caffe(def_path, model_path) # Remove layers after pool5 model = full_model.new_graph(outputs=["pool5"]).to_keras()) # freeze layers from input to res4f inclusive model.freeze_up_to(["res4f"]) # append a few layers image = Input(name="input", shape=(3, 224, 224)) resnet = model.to_keras()(image) resnet50 = Flatten()(resnet) Build Siamese Network Using Transfer Learning
23 . Autograd, Keras &Transfer Learning APIs 2. Use autograd and Keras-style APIs to build the Siamese Network import zoo.pipeline.api.autograd as A from zoo.pipeline.api.keras.layers import * from zoo.pipeline.api.keras.models import * input = Input(shape=[2, 3, 226, 226]) features = TimeDistributed(layer=resnet50)(input) f1 = features.index_select(1, 0) #image1 f2 = features.index_select(1, 1) #image2 diff = A.abs(f1 - f2) fc = Dense(1)(diff) output = Activation("sigmoid")(fc) model = Model(input, output) Build Siamese Network Using Transfer Learning
24 . nnframes Native DL support in Spark DataFrames and ML Pipelines 1. Initialize NNContext and load images into DataFrames using NNImageReader from zoo.common.nncontext import * from zoo.pipeline.nnframes import * sc = init_nncontext() imageDF = NNImageReader.readImages(image_path, sc) 2. Process loaded data using DataFrame transformations getName = udf(lambda row: ...) df = imageDF.withColumn("name", getName(col("image"))) 3. Processing image using built-in feature engineering operations from zoo.feature.image import * transformer = ChainedPreprocessing( [RowToImageFeature(), ImageChannelNormalize(123.0, 117.0, 104.0), ImageMatToTensor(), ImageFeatureToTensor()])
25 . nnframes Native DL support in Spark DataFrames and ML Pipelines 4. Define model using Keras-style API from zoo.pipeline.api.keras.layers import * from zoo.pipeline.api.keras.models import * model = Sequential() .add(Convolution2D(32, 3, 3, activation='relu', input_shape=(1, 28, 28))) \ .add(MaxPooling2D(pool_size=(2, 2))) \ .add(Flatten()).add(Dense(10, activation='softmax'))) 5. Train model using Spark ML Pipelines Estimater = NNEstimater(model, CrossEntropyCriterion(), transformer) \ .setLearningRate(0.003).setBatchSize(40).setMaxEpoch(1) \ .setFeaturesCol("image").setCachingSample(False) nnModel = estimater.fit(df)
26 . Built-in Deep Learning Models • Object detection API • High-level API and pretrained models (e.g., SSD, Faster-RCNN, etc.) for object detection • Image classification API • High-level API and pretrained models (e.g., VGG, Inception, ResNet, MobileNet, etc.) for image classification • Text classification API • High-level API and pre-defined models (using CNN, LSTM, etc.) for text classification • Recommendation API • High-level API and pre-defined models (e.g., Neural Collaborative Filtering, Wide and Deep Learning, etc.) for recommendation
27 . Object Detection API 1. Load pretrained model in Detection Model Zoo from zoo.common.nncontext import * from zoo.models.image.objectdetection import * spark = init_nncontext() model = ObjectDetector.load_model(model_path) 2. Off-the-shell inference using the loaded model image_set = ImageSet.read(img_path, spark) output = model.predict_image_set(image_set) 3. Visualize the results using utility methods config = model.get_config() visualizer = Visualizer(config.label_map(), encoding="jpg") visualized = visualizer(output).get_image(to_chw=False).collect() Off-the-shell Inference Using Analytics Zoo Object Detection API https://github.com/intel-analytics/analytics-zoo/tree/master/pyzoo/zoo/examples/objectdetection
28 . Reference Use Cases • Anomaly Detection • Using LSTM network to detect anomalies in time series data • Fraud Detection • Using feed-forward neural network to detect frauds in credit card transaction data • Recommendation • Use Analytics Zoo Recommendation API (i.e., Neural Collaborative Filtering, Wide and Deep Learning) for recommendations on data with explicit feedback. • Sentiment Analysis • Sentiment analysis using neural network models (e.g. CNN, LSTM, GRU, Bi-LSTM) • Variational Autoencoder (VAE) • Use VAE to generate faces and digital numbers https://github.com/intel-analytics/analytics-zoo/tree/master/apps
29 .Use Cases
相关推荐
3秒后跳转登录页面
去登陆

