



































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
尤洋-ColossalAI | User Group-机器学习专题-211226
展开查看详情
1 .Colossal-AI https://github.com/hpcaitech/ColossalAI 1
2 .About Myself ✔ PhD in Computer Science from UC Berkeley ✔ IPDPS Best Paper Award (0.8%, first author) ✔ ICPP Best Paper Award (0.3%, first author) ✔ ACM/IEEE George Michael HPC Fellowship ✔ Forbes 30 Under 30 Asia list (2021) ✔ IEEE CS TCHPC Early Career Researchers Award ✔ Lotfi A. Zadeh Prize for outstanding UC Berkeley PhD ✔ ICML Expert reviewer ✔ Lab’s homepage : https://ai.comp.nus.edu.sg/ Yang You Research Interests: ● High Performance Computing ● Deep Learning Optimization ● Machine Learning System 2
3 .Outline 01 Background and Overview 02 Parallelism Scalable Large-scale Optimizer 03 04 Memory System 3 05 Colossal-AI
4 .
5 . Background ● The growth of sizes of neural networks time model size June, 2018 OpenAI GPT 0.11 billion Oct, 2018 BERT 0.34 billion Feb, 2019 GPT-2 1.5 billion Sep, 2019 Megatron-LM 8.3 billion AI model size: 3.5-month doubling Moore’s law: 18-month doubling Feb, 2020 Turing-NLP 17 billion June, 2020 GPT-3 175 billion 5 June, 2020 Google MoE 600 billion Jan, 2021 Google Switch 16000 billion Transformer https://openai.com/blog/ai-and-compute/
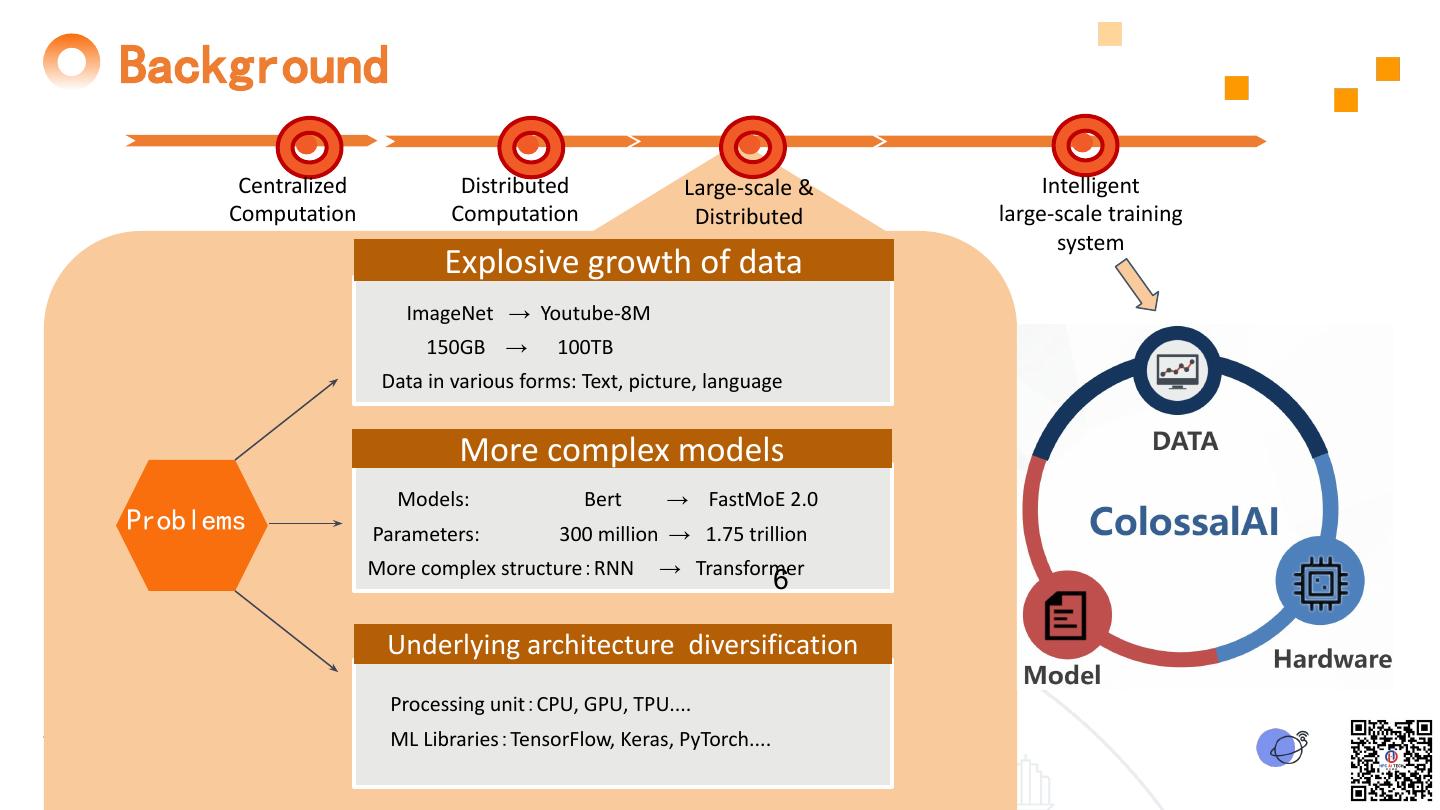
6 .Background Centralized Distributed Large-scale & Intelligent Computation Computation Distributed large-scale training system Explosive growth of data ImageNet → Youtube-8M 150GB → 100TB Data in various forms: Text, picture, language More complex models Models: Bert → FastMoE 2.0 Problems Parameters: 300 million → 1.75 trillion More complex structure:RNN → Transformer 6 Underlying architecture diversification Processing unit:CPU, GPU, TPU.... ML Libraries:TensorFlow, Keras, PyTorch....
7 . Existing Solutions: 3D Parallelism • Megatron — NVIDIA • Support data, model (tensor splitting), pipeline parallelism • DeepSpeed — Microsoft • Support data, pipeline and one-dimensional model parallelism • MeshTensorFlow/Gpipe/Gshard — Google • Support data and pipeline parallelism • FSDP — Facebook • Support data and one-dimensional model parallelism • Oneflow — Oneflow • Support data, model (tensor splitting), pipeline parallelism 7 • PaddlePaddle — Baidu • Support data, model (tensor splitting), pipeline parallelism
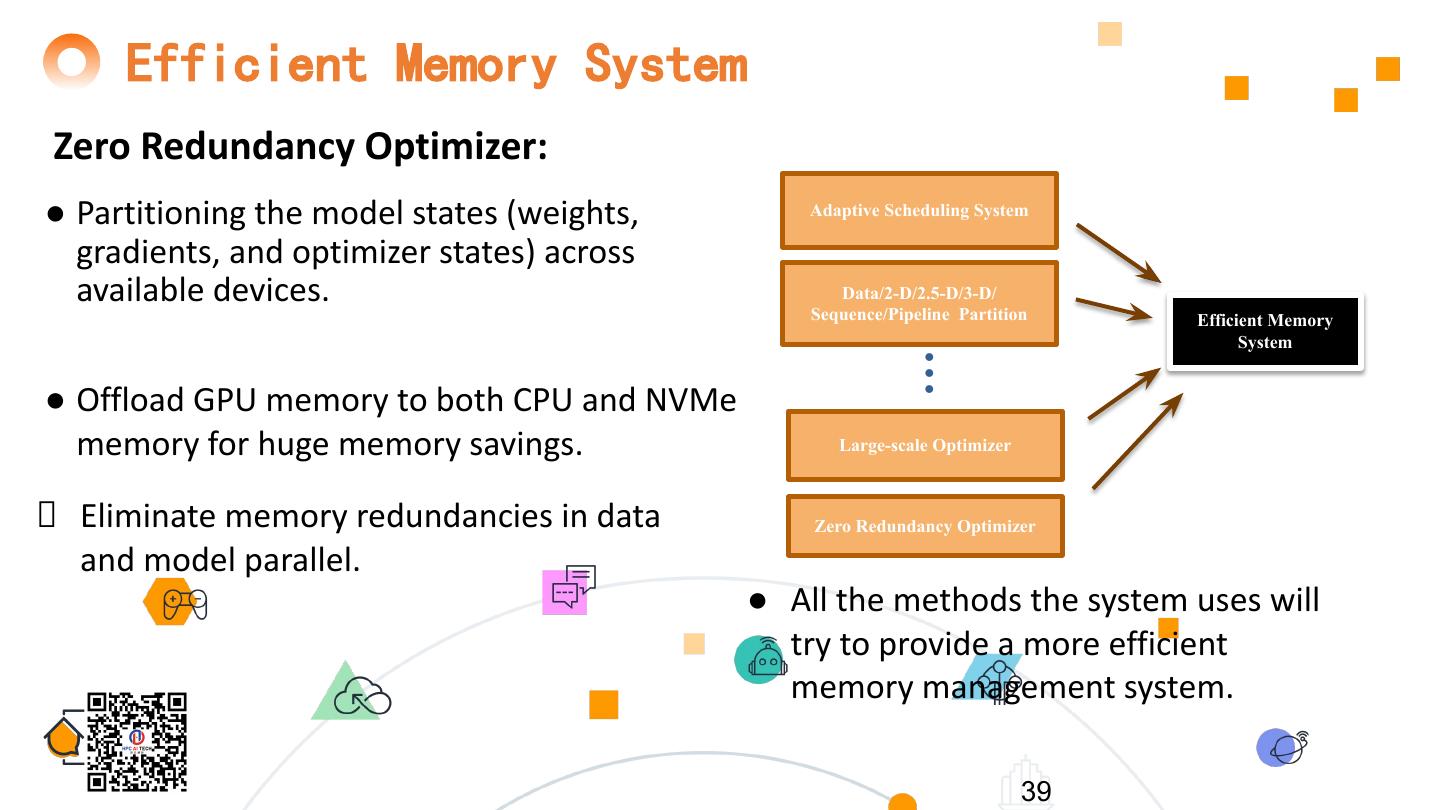
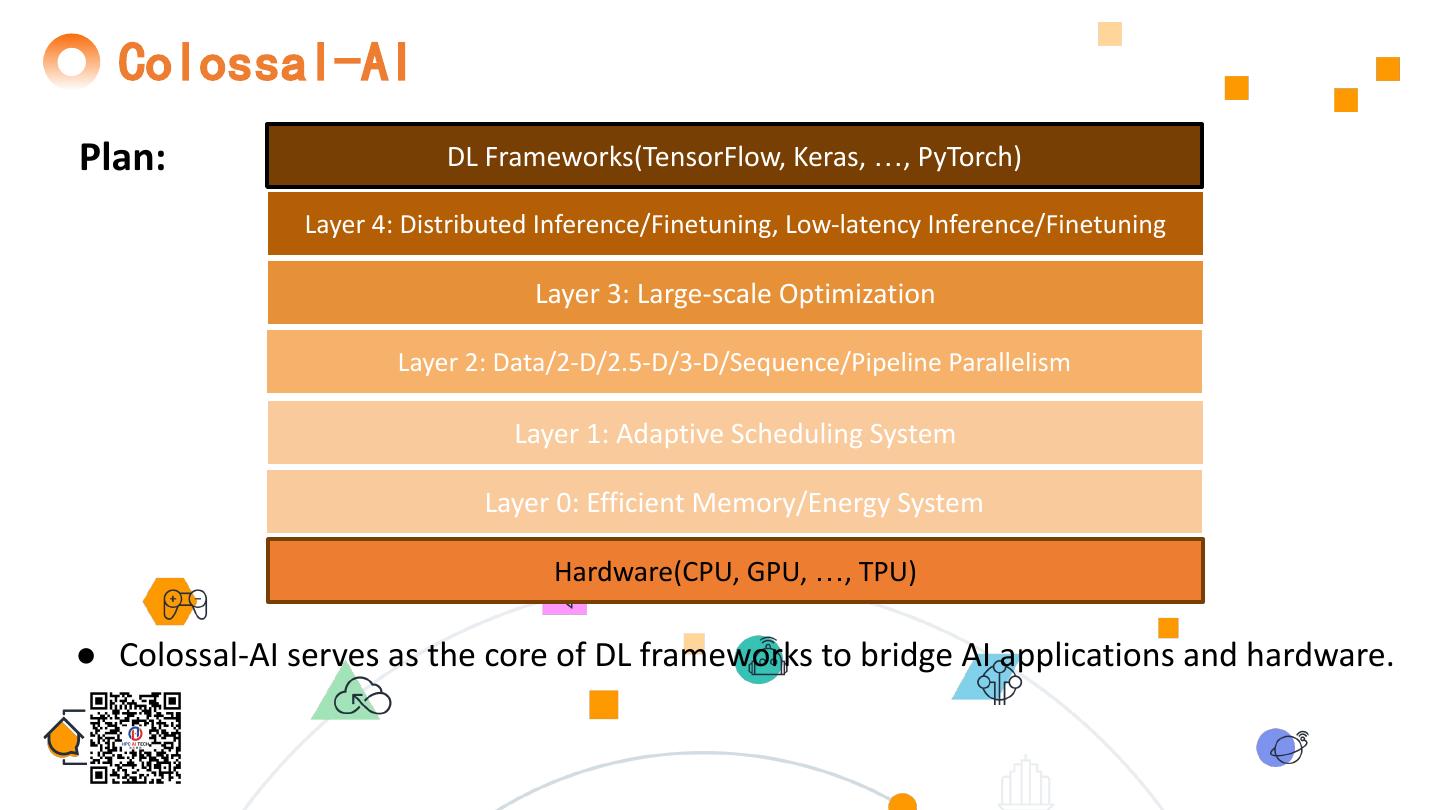
8 . ColossalAI Overview ● Maximize AI deployment efficiency Applications (CV, NLP, …) by Frameworks ● Maximize computational efficiency ● Minimize system running time Layer 3: Large-scale Optimization + Dynamic Scheduling ● Minimize communication … Layer 2: Data/2-D/2.5-D/3-D/Sequence/Pipeline Parallelism ● Minimize code refactoring Layer 1: Efficient Memory System ● Dynamic adaptive scaling ● Reduce memory footprint CPU, GPU, NPU, TPU 8 ● Minimize deployment costs
9 .9
10 . Background of Parallelism Data Parallelism Pipeline Parallelism Tensor Parallelism ●Distribute data across processors ● Model is split by layer ● Tensor is split across devices ●Processed in parallel, and parameters are ● Data is split into micro batches for ● Example: Megatron updated synchronously. pipelining ●Communication happens at the all-reduce ● Communication occurs between operations to sum the gradients from all pipeline stages(devices) processors 10 Parameter synchronization
11 . Existing Solutions • Megatron — NVIDIA • Featured by tensor splitting (a) MLP (b) self attention 11 • DeepSpeed — Microsoft • Compatible with Megatron • Support Zero Redundancy Optimizer (Eliminate memory redundancies)
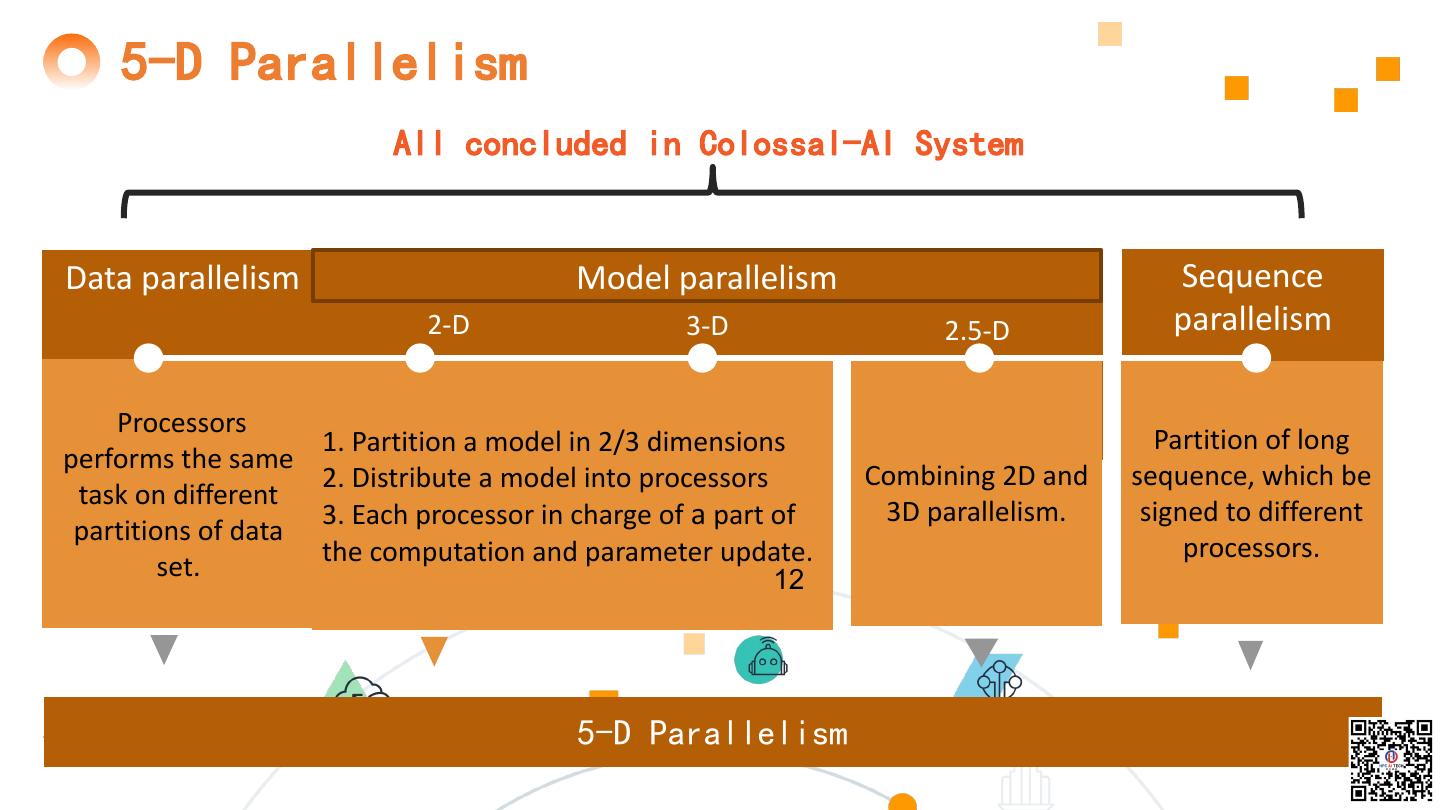
12 . 5-D Parallelism All concluded in Colossal-AI System Data parallelism Model parallelism Sequence 2-D 3-D 2.5-D parallelism Processors 1. Partition a model in 2/3 dimensions Partition of long performs the same 2. Distribute a model into processors Combining 2D and sequence, which be task on different 3. Each processor in charge of a part of 3D parallelism. signed to different partitions of data the computation and parameter update. processors. set. 12 5-D Parallelism
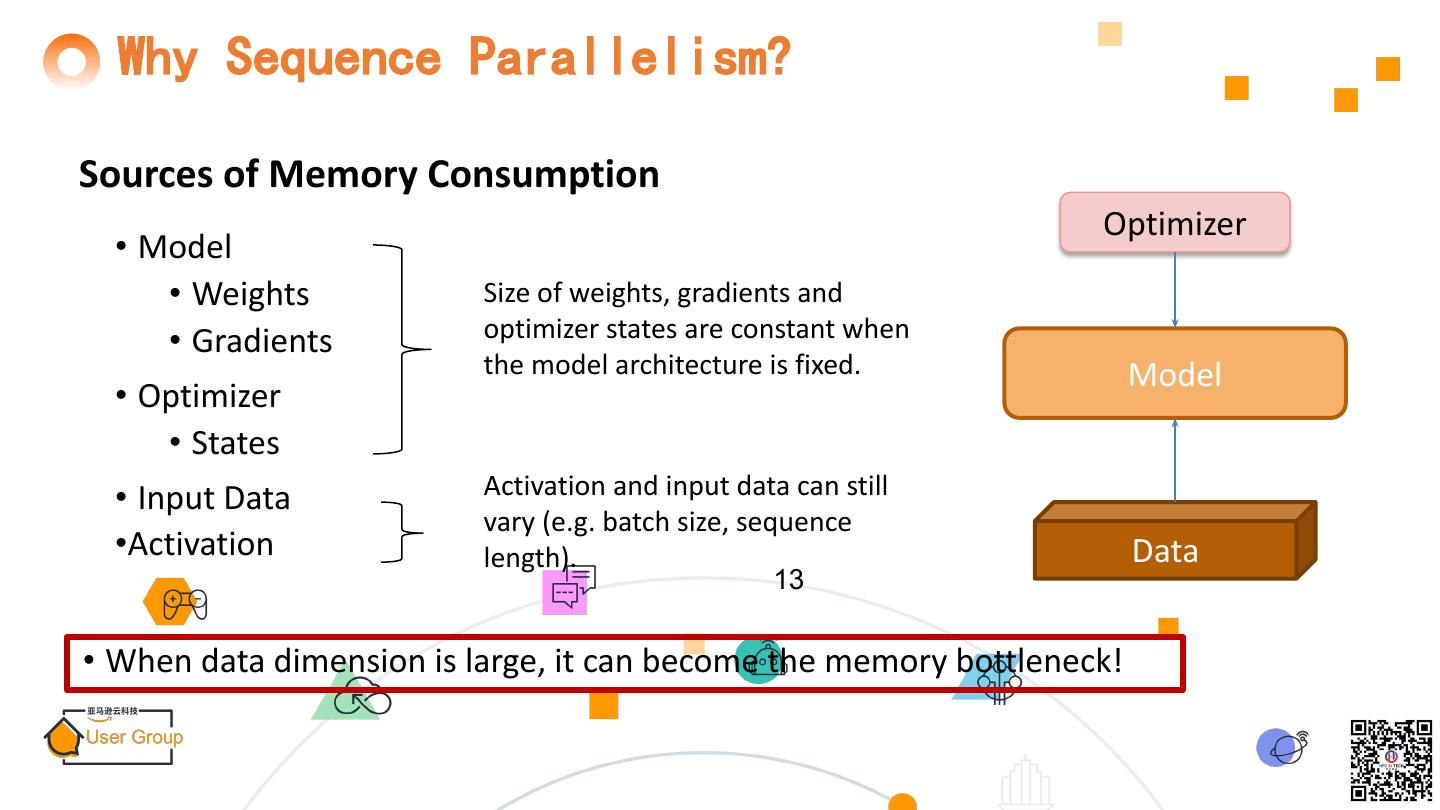
13 . Why Sequence Parallelism? Sources of Memory Consumption Optimizer • Model • Weights Size of weights, gradients and • Gradients optimizer states are constant when the model architecture is fixed. Model • Optimizer • States • Input Data Activation and input data can still vary (e.g. batch size, sequence •Activation length). Data 13 • When data dimension is large, it can become the memory bottleneck!
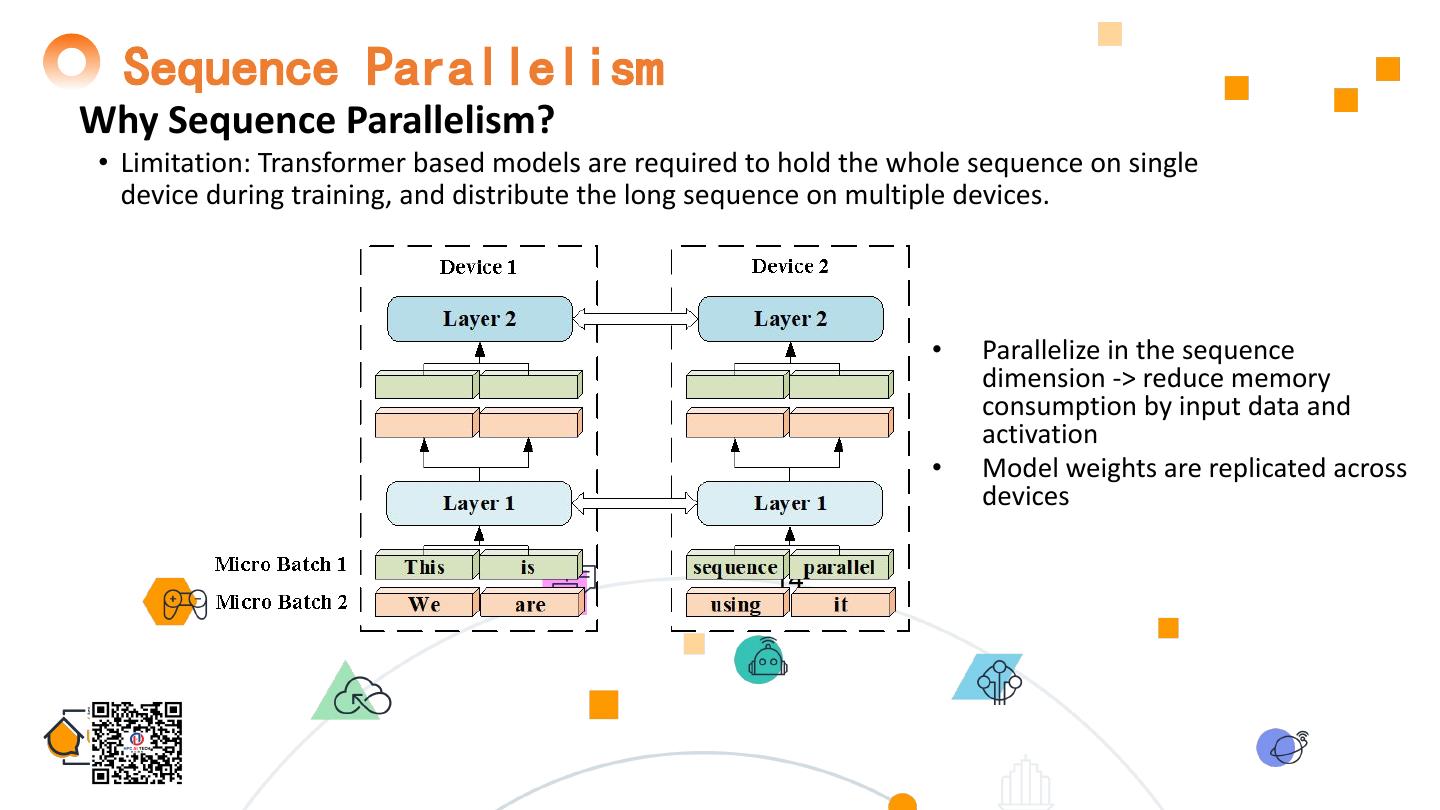
14 . Sequence Parallelism Why Sequence Parallelism? • Limitation: Transformer based models are required to hold the whole sequence on single device during training, and distribute the long sequence on multiple devices. • Parallelize in the sequence dimension -> reduce memory consumption by input data and activation • Model weights are replicated across devices 14
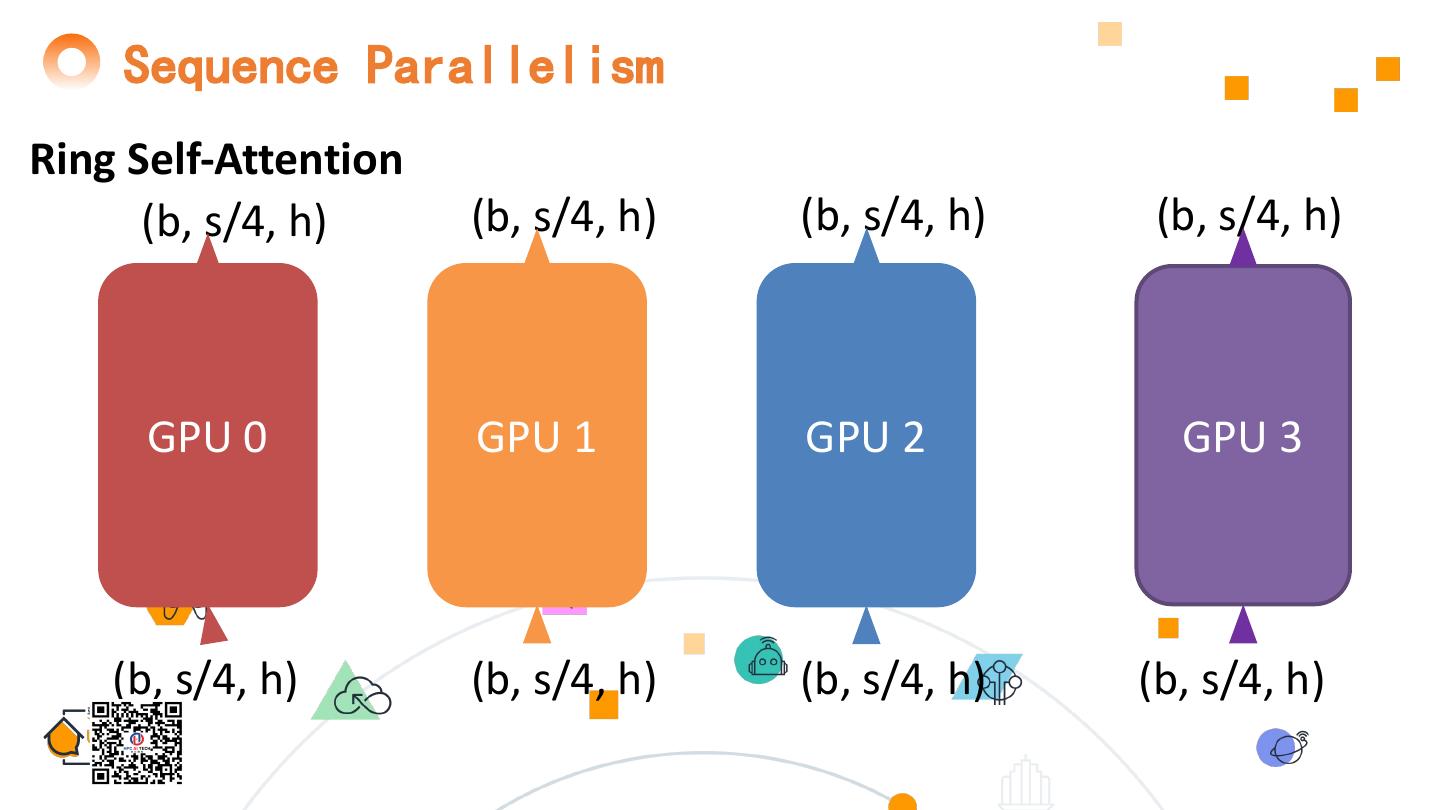
15 . Sequence Parallelism Ring Self-Attention (b, s/4, h) (b, s/4, h) (b, s/4, h) (b, s/4, h) GPU 0 GPU 1 GPU 2 GPU 3 (b, s/4, h) (b, s/4, h) (b, s/4, h) (b, s/4, h)
16 . Sequence Parallelism Ring Self-Attention GPU 0 Q K V GPU 3 GPU 1 Q K V Q K V GPU 2 Q K V 16
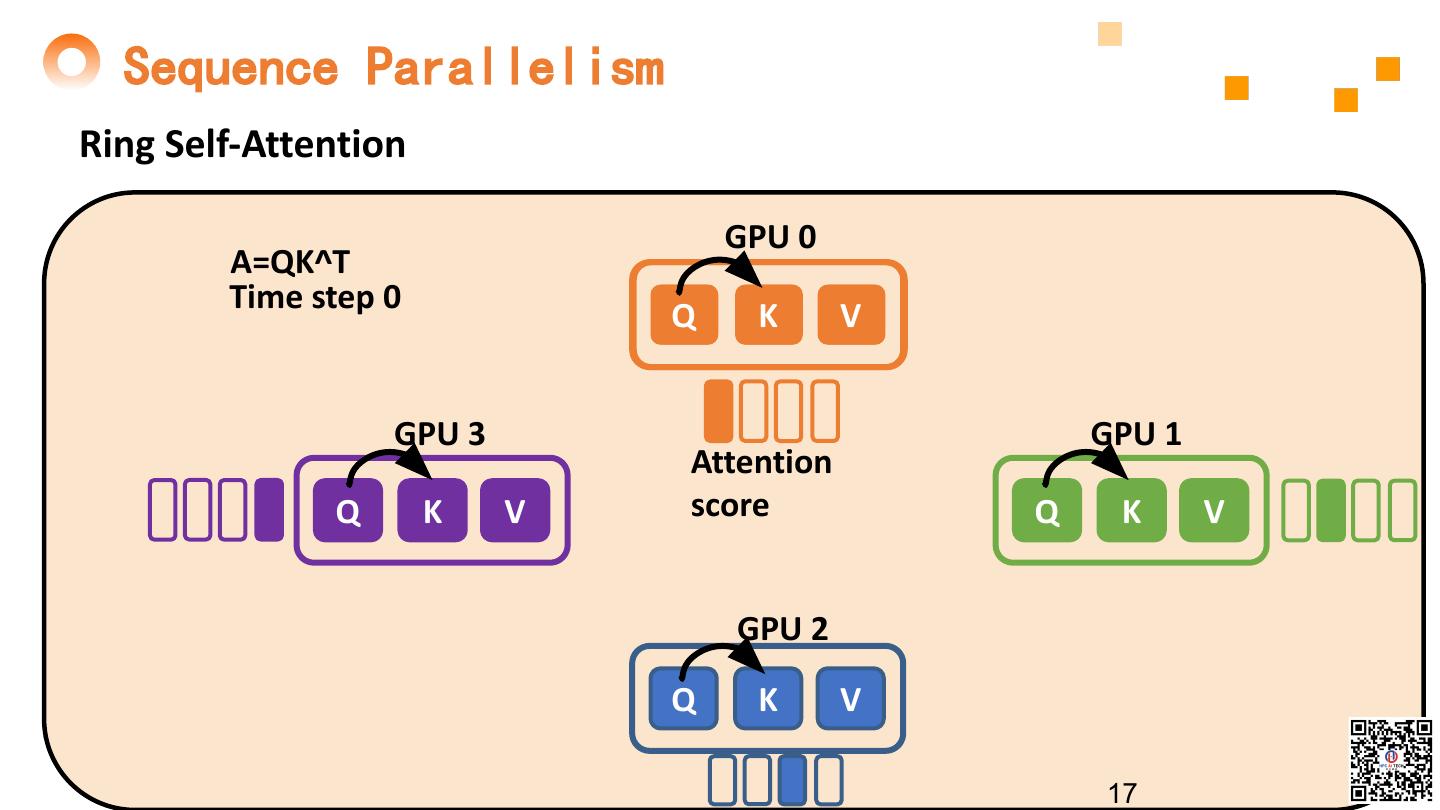
17 . Sequence Parallelism Ring Self-Attention GPU 0 A=QK^T Time step 0 Q K V GPU 3 GPU 1 Attention Q K V score Q K V GPU 2 Q K V 17
18 . Sequence Parallelism Ring Self-Attention A=QK^T GPU 0 Time step 1 K Q K V K GPU 3 GPU 1 Attention Q K V score Q K V K GPU 2 Q K V K 18
19 . Sequence Parallelism Ring Self-Attention GPU 0 A=QK^T Time step 2 K Q K V K GPU 3 GPU 1 Attention Q K V score Q K V K GPU 2 Q K V K 19
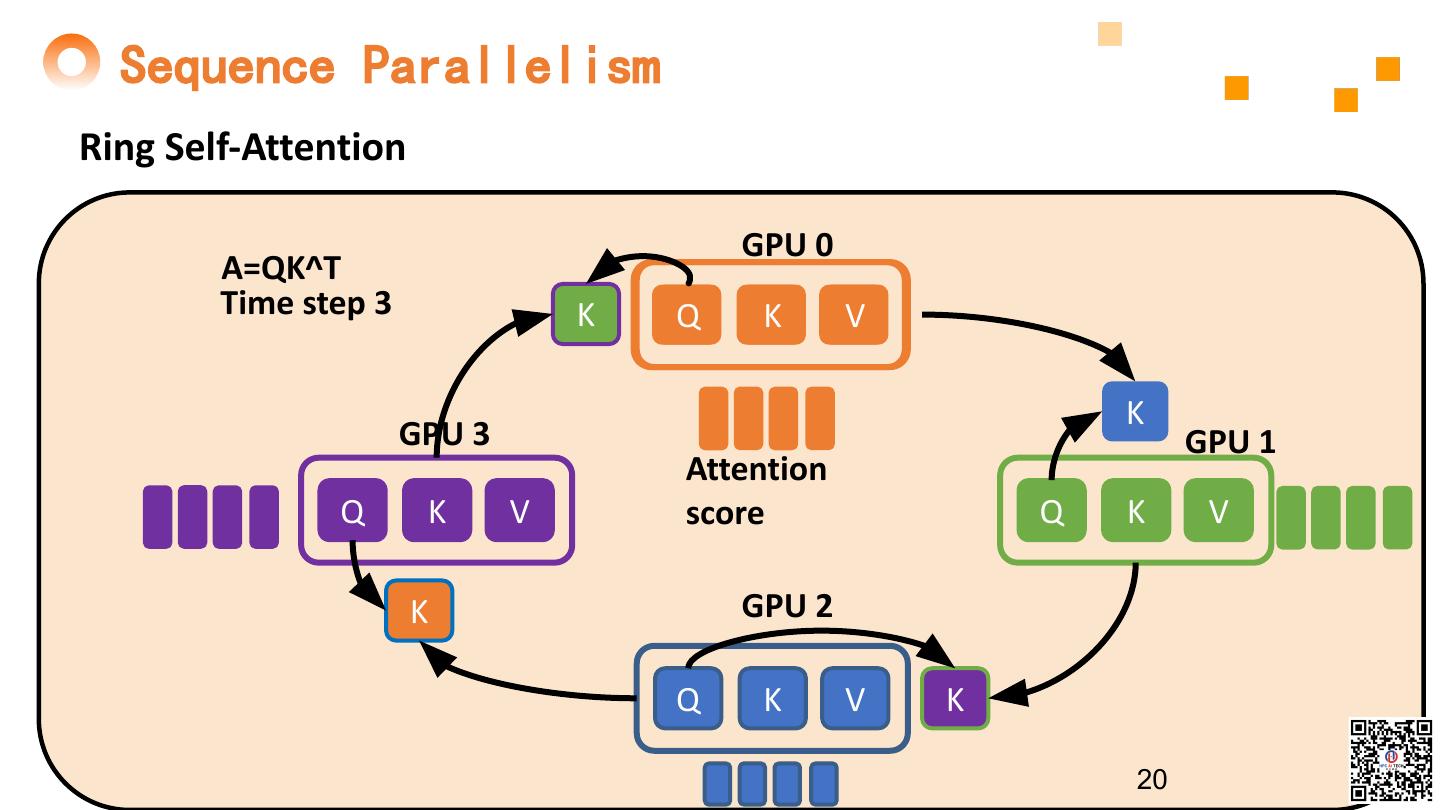
20 . Sequence Parallelism Ring Self-Attention GPU 0 A=QK^T Time step 3 K Q K V K GPU 3 GPU 1 Attention Q K V score Q K V K GPU 2 Q K V K 20
21 . Sequence Parallelism Tensor parallelism Sequence parallelism P B S Ring Self-Attention M T M T 1 64 512 8477.28 9946.15 8477.53 9261.04 • Notation 2 128 512 9520.47 15510.19 8478.76 13938.22 4 256 512 12232.52 20701.96 8481.26 21269.91 – P: tensor or sequence parallel size 8 512 512 OOM OOM 8490.75 26401.64 – B: global batch size 1 64 256 3707.39 9752.61 3707.01 9340.13 – S: sequence length 2 64 512 4993.43 14195.17 4670.64 13144.16 – M: max allocated memory (MB) 4 64 1024 8175.93 19879.27 6601.88 18243.82 – T: throughput (tokens processed 8 64 2048 14862.09 22330.5 10536.38 21625.51 per second) – OOM: out of memory • Sequence parallelism • Constant 21 memory consumption when scaling with batch size • Lower memory consumption when scaling with sequence length
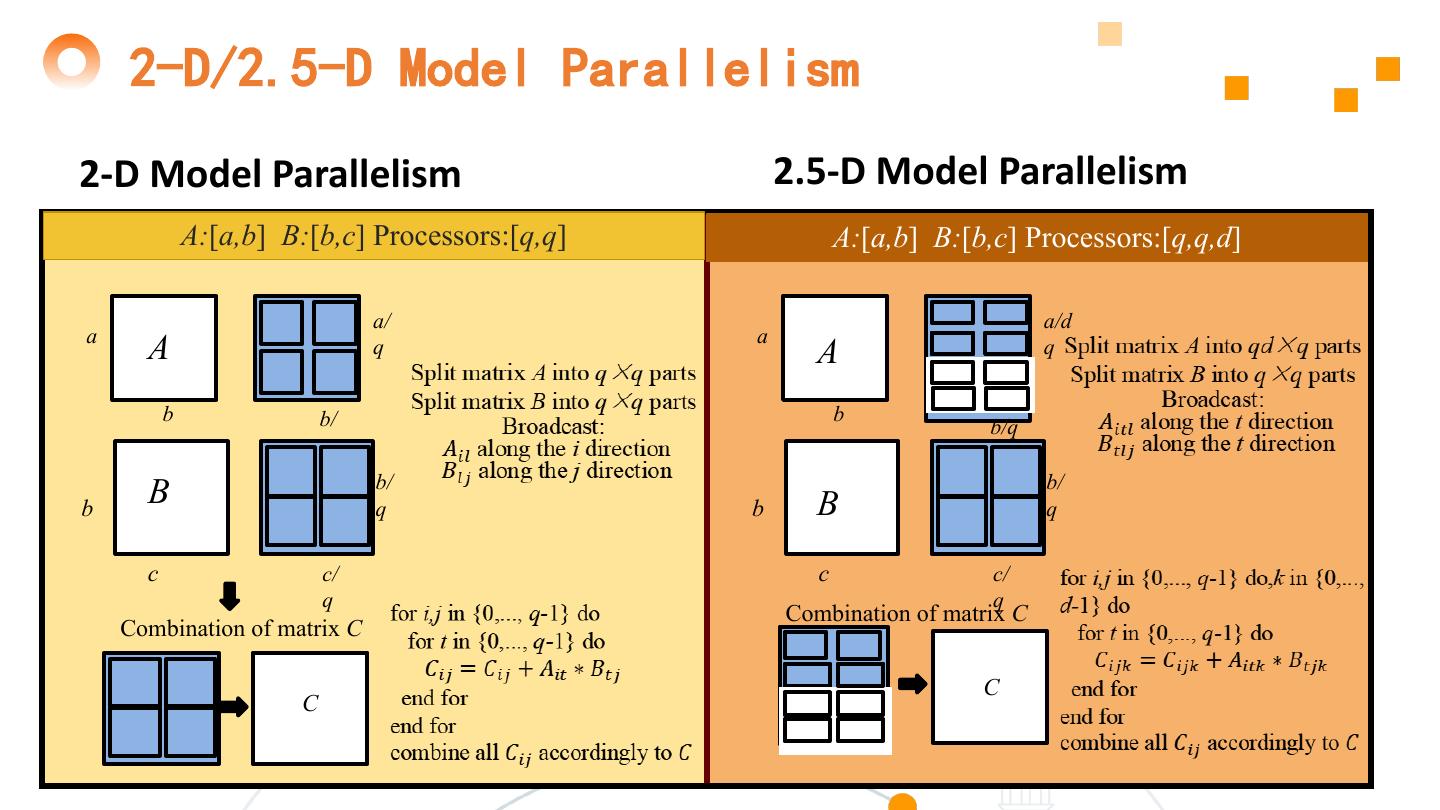
22 . 2-D/2.5-D Model Parallelism 2-D Model Parallelism 2.5-D Model Parallelism aa/qa/q A:[a,b] B:[b,c] Processors:[q,q] A:[a,b] B:[b,c] Processors:[q,q,d] a/ a/d a a A q A q b b/ b b/q q b/ b/ b B q b B q c c/ 22 c c/ q q Combination of matrix C Combination of matrix C C C
23 .2-D Model Parallelism 23 ● 2-D Model Parallelism: speedup on 64 GPUs compared with Megatron
24 .2.5-D Model Parallelism Weak scaling: Strong scaling: 24 ● In the strong/weak scaling setting experiments, compared to Megatron-LM, 2.5-D Model Parallelism reached a speedup of 1.3751/3.3746 on 64 GPUs.
25 . 3-D Model Parallelism ●3-D matrix multiplication: C = AB on a 2 × 2 × 2 processing cube. 1 2 4 3 25
26 . 3-D Model Parallelism Weak scaling: Strong scaling: 26 3-D Model Parallelism: Speedup on 64 GPUs compared with 2-D Model Parallelism and 1-D Model Parallelism.
27 .
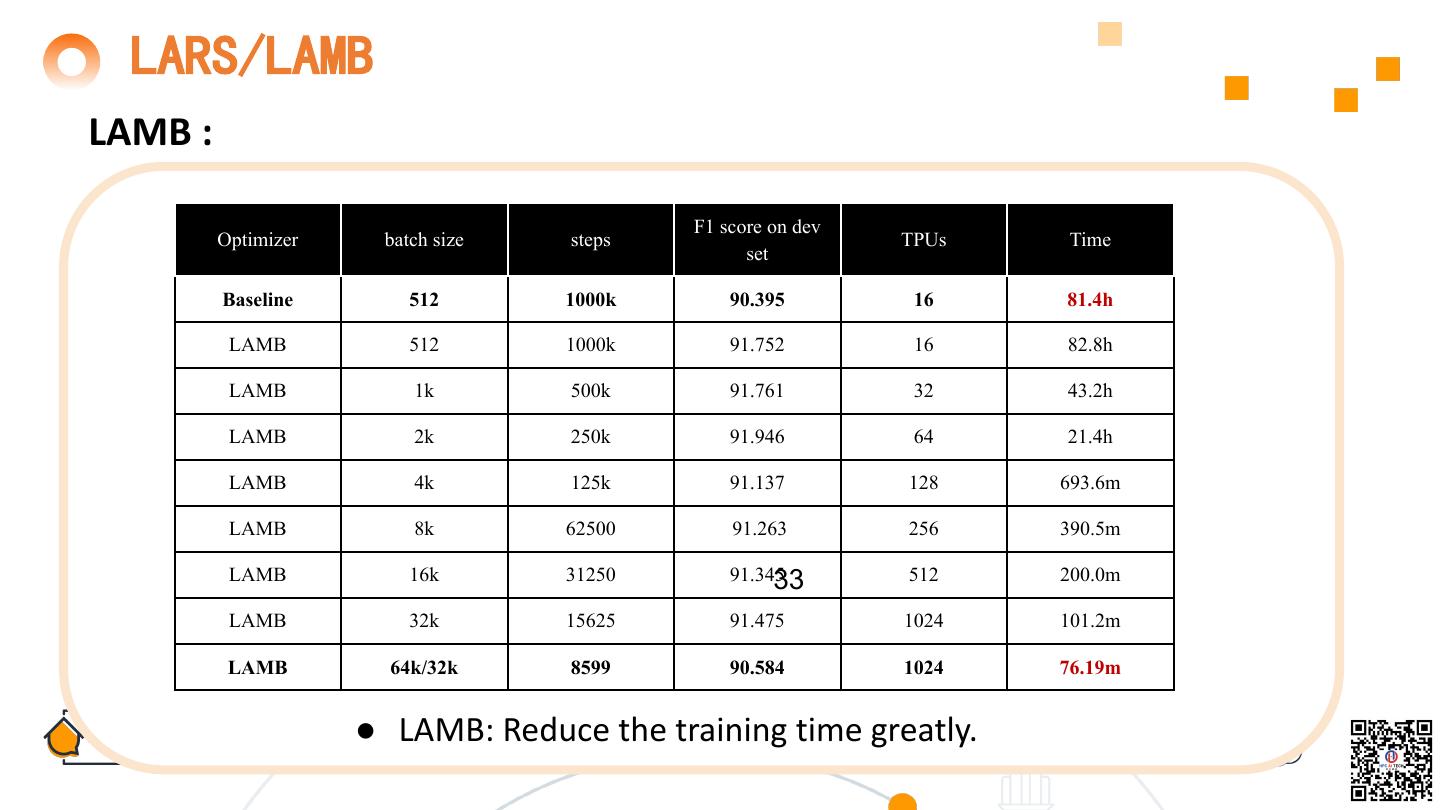
28 . LARS/LAMB Problems of existing algorithm : sharp minimum problem Reduced accuracy Large batch training = sharp minimum problem. For problem with shape the sharp minimum, a good performance does not mean a good performance in the test set. ●Large batch training = sharp minimum problem. Reason:sharp minimum problem & poor convergence ●For problem with shape the sharp minimum, a good Larger batch requires a greater learning rate. The performance does not mean a good performance in the upper limit of batch size for other methods is 8K. test set. 28
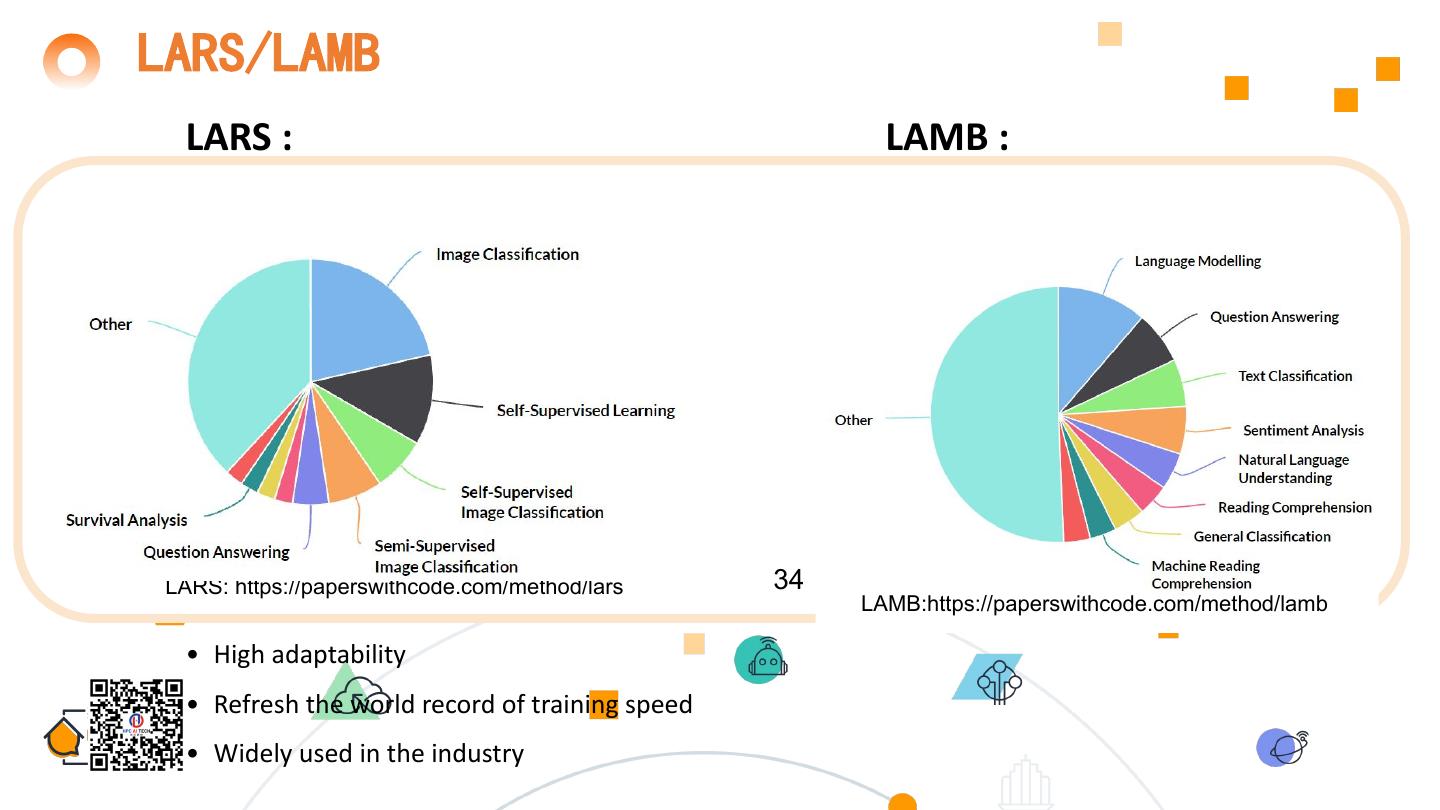
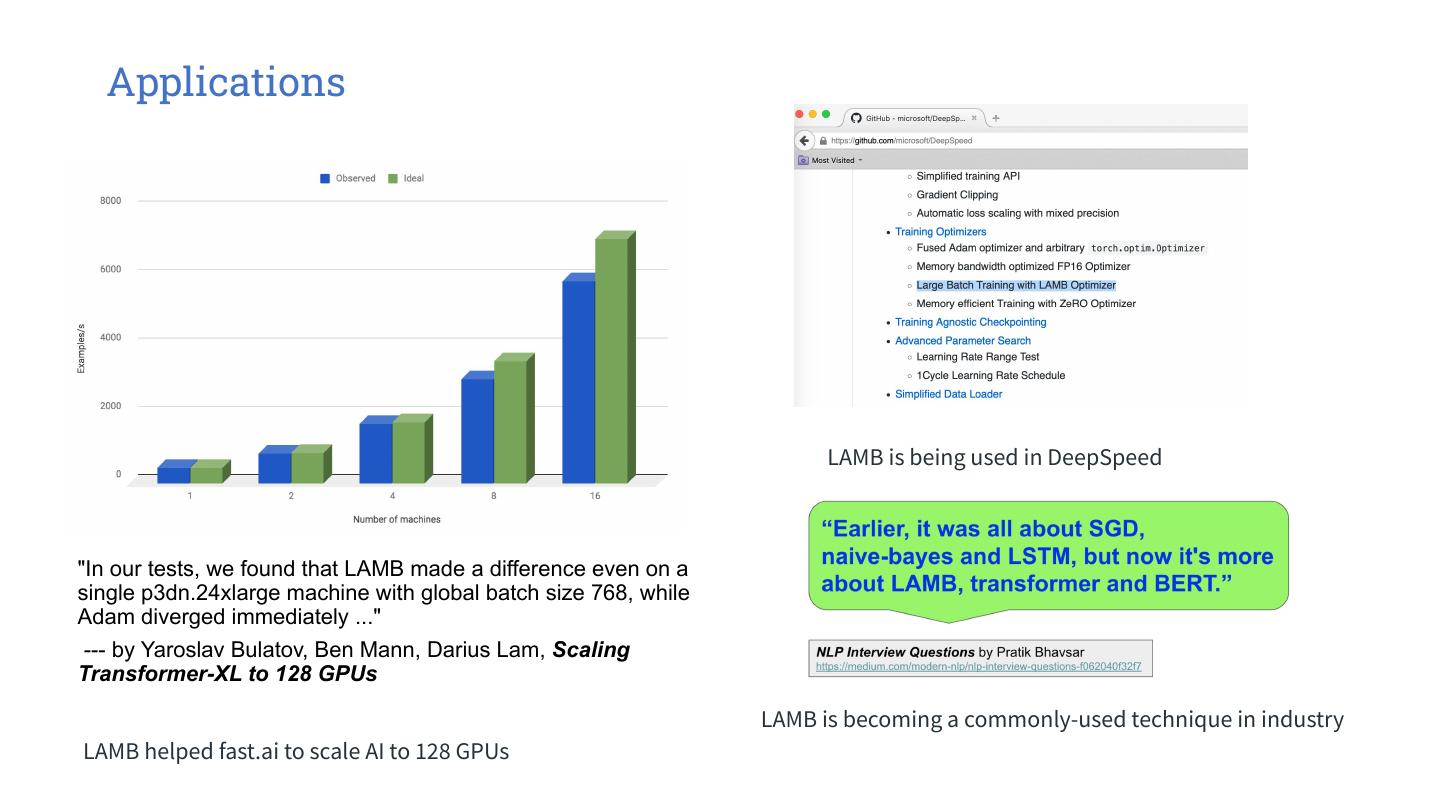
29 . LARS/LAMB LARS : 29
相关推荐
3秒后跳转登录页面
去登陆

