






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u7/Apache_Spark_Barrier_Execution_Mode?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
蒋星博-ApacheSparkBarrierExecutionMode_
分享
点赞
0
收藏
1
下载 2
蒋星博-ApacheSparkBarrierExecutionMode_
展开查看详情
1 .Project Hydrogen: Unifying State-of-the-art Big Data and AI in Apache Spark Xingbo Jiang 2018/11
2 .
3 .
4 .Spark: unified analytics engine for big data “Apache Spark is the Taylor Swift of big data software.” - Fortune 500,000 4,000 meetup summit members attendees
5 .AI: re-shaping the world “Artificial Intelligence is the New Electricity.” - Andrew Ng Transportation Healthcare and Genomics Internet of Things Fraud Prevention Personalization
6 .Two communities: big data and AI Significant progress has been made by both big data and AI communities in recent years to push the cutting edge: more complex more complex big data deep learning scenarios scenarios
7 .The cross? ?? Continuous Horovod Processing Distributed Pandas UDF TensorFlow Structured Streaming tf.data tf.transform Keras TF XLA AI/ML Project Tungsten TensorFlow TensorFrames ML Pipelines API Caffe/PyTorch/MXNet TensorFlowOnSpark GraphLab 50+ Data Sources xgboost CaffeOnSpark scikit-learn DataFrame-based APIs LIBLINEAR glmnet Python/Java/R interfaces Map/Reduce RDD pandas/numpy/scipy R 5
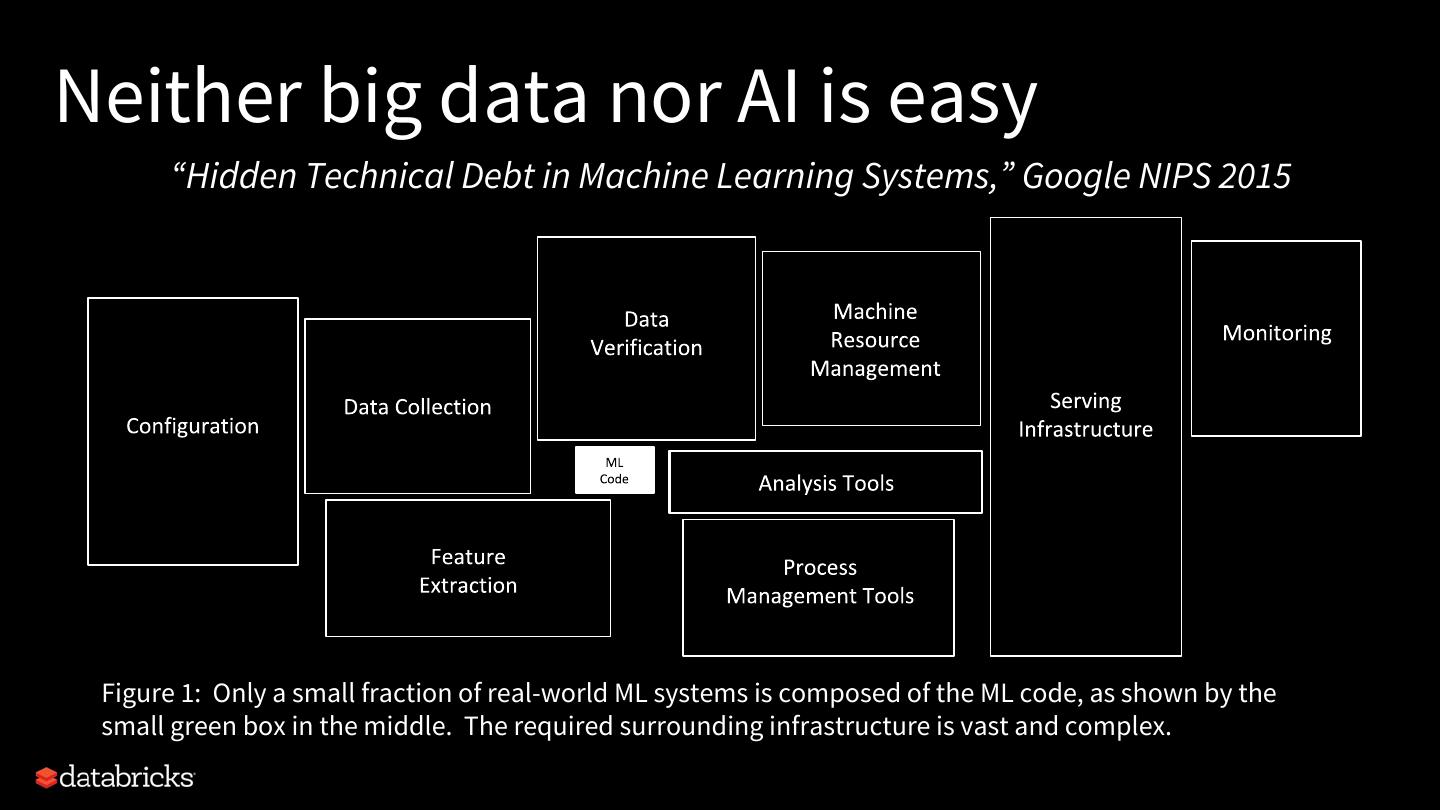
8 .Neither big data nor AI is easy “Hidden Technical Debt in Machine Learning Systems,” Google NIPS 2015 Figure 1: Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small green box in the middle. The required surrounding infrastructure is vast and complex.
9 .Big data for AI A common goal of collecting, processing, and managing big data is to extract value from it. AI/ML is the most mentioned approach in our conversations with customers. improved customer engagement and conversions by improving image classification (case study) increased customer satisfaction, retention, and lifetime value by detecting abusive language in real-time (case study)
10 .Big data for AI There are many efforts from the Spark community to integrate Spark with AI/ML frameworks: ● (Yahoo) CaffeOnSpark, TensorFlowOnSpark ● (Intel) BigDL ● (John Snow Labs) Spark-NLP ● (Databricks) spark-sklearn, tensorframes, spark-deep-learning ● … 80+ ML/AI packages on spark-packages.org
11 .AI needs big data One cannot apply AI techniques without data. And DL models scale with amount of data. We have seen efforts from the AI community to handle different data scenarios: ● tf.data, tf.Transform ● spark-tensorflow-connector ● ... source: Andrew Ng
12 .When AI goes distributed ... When datasets get bigger and bigger, we see more and more distributed training scenarios and open-source offerings, e.g., distributed TensorFlow, Horovod, and distributed MXNet. This is where we see Spark and AI efforts overlap more.
13 .The status quo: two simple stories As a data scientist, I can: ● build a pipeline that fetches training events from a production data warehouse and trains a DL model in parallel; ● apply a trained DL model to a distributed stream of events and enrich it with predicted labels.
14 .Distributed training Databricks Delta load fit model data warehouse Required: Be able to read from Required: distributed GPU cluster Databricks Delta, Parquet, for fast training MySQL, Hive, etc. Answer: Horovod, Distributed Answer: Apache Spark Tensorflow, etc
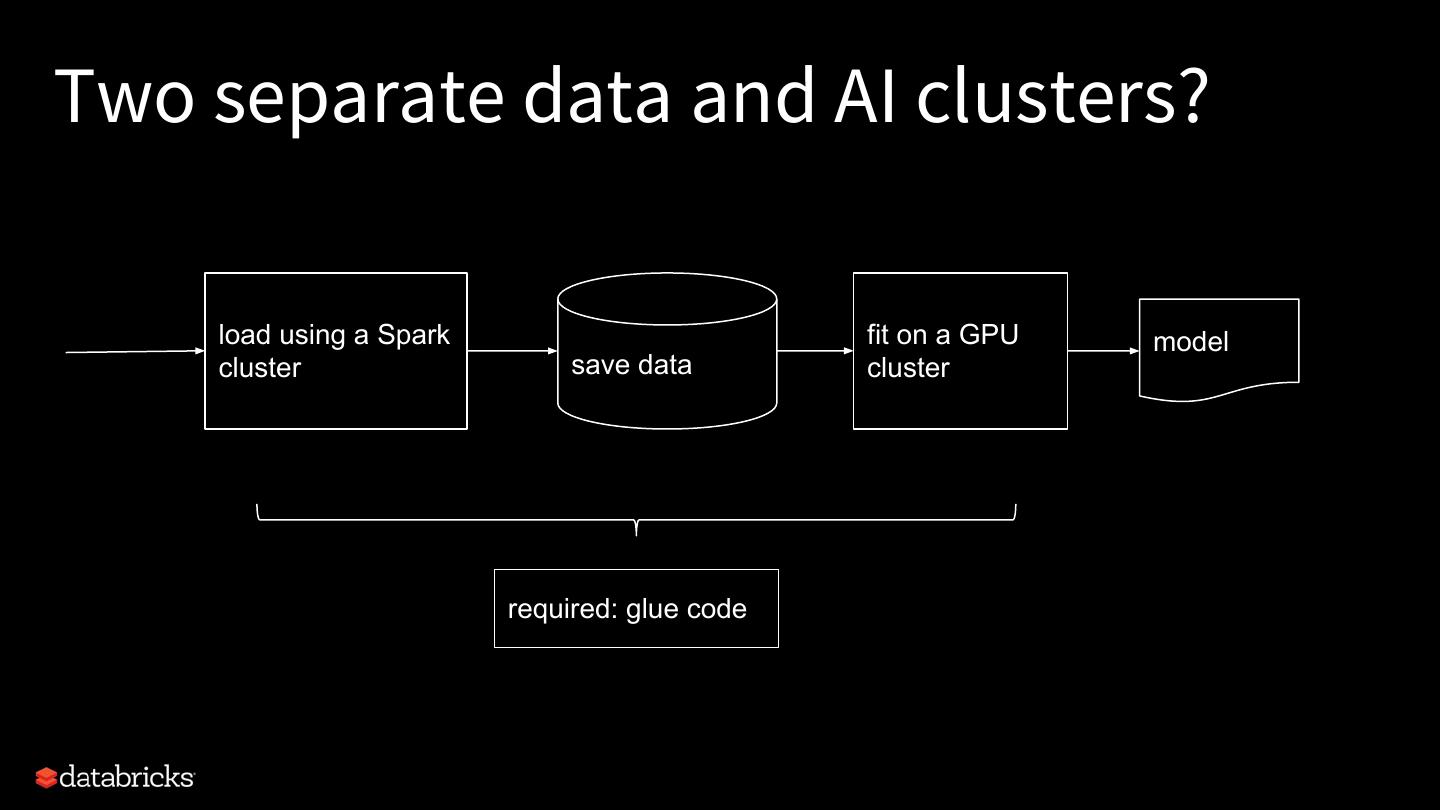
15 .Two separate data and AI clusters? load using a Spark fit on a GPU model cluster save data cluster required: glue code
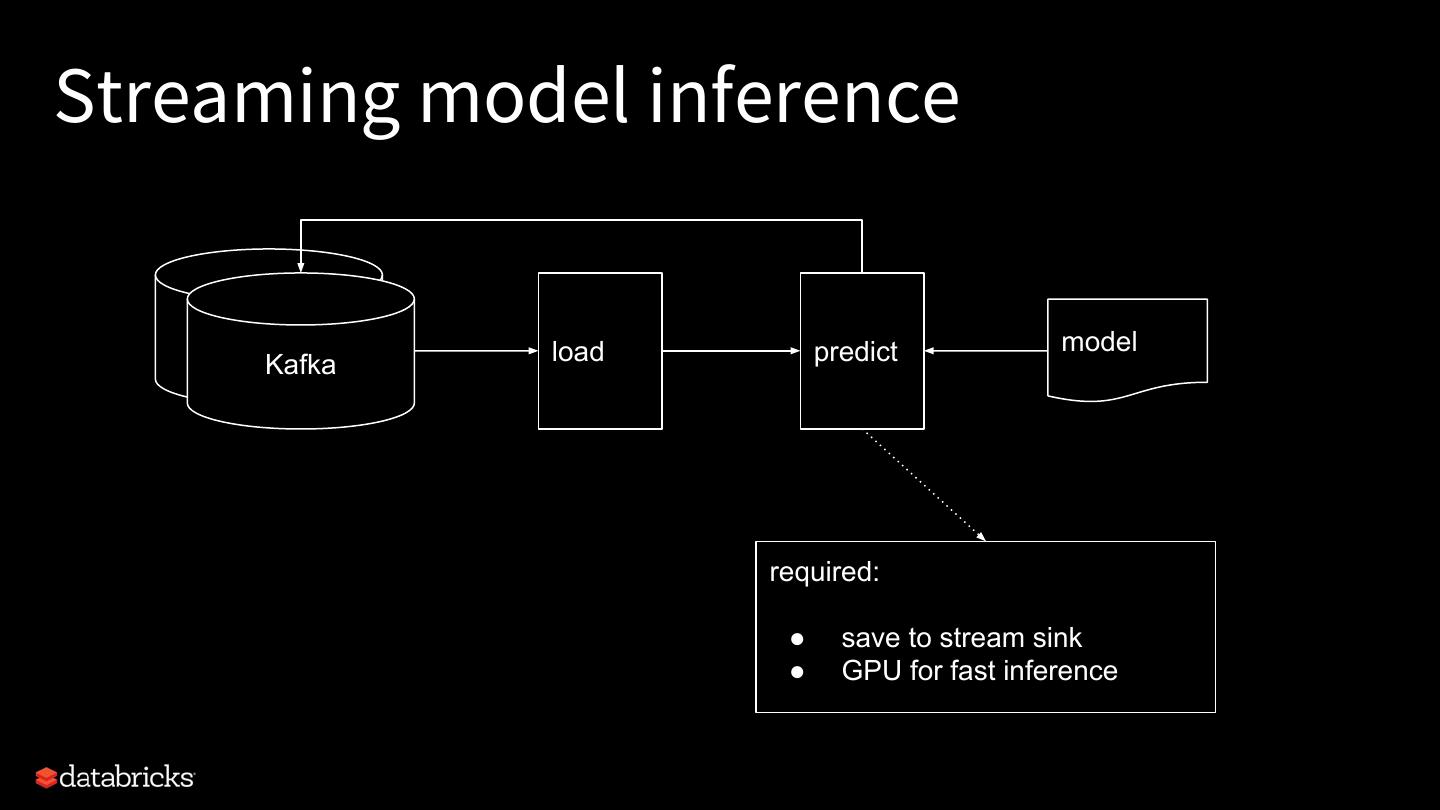
16 .Streaming model inference load predict model Kafka required: ● save to stream sink ● GPU for fast inference
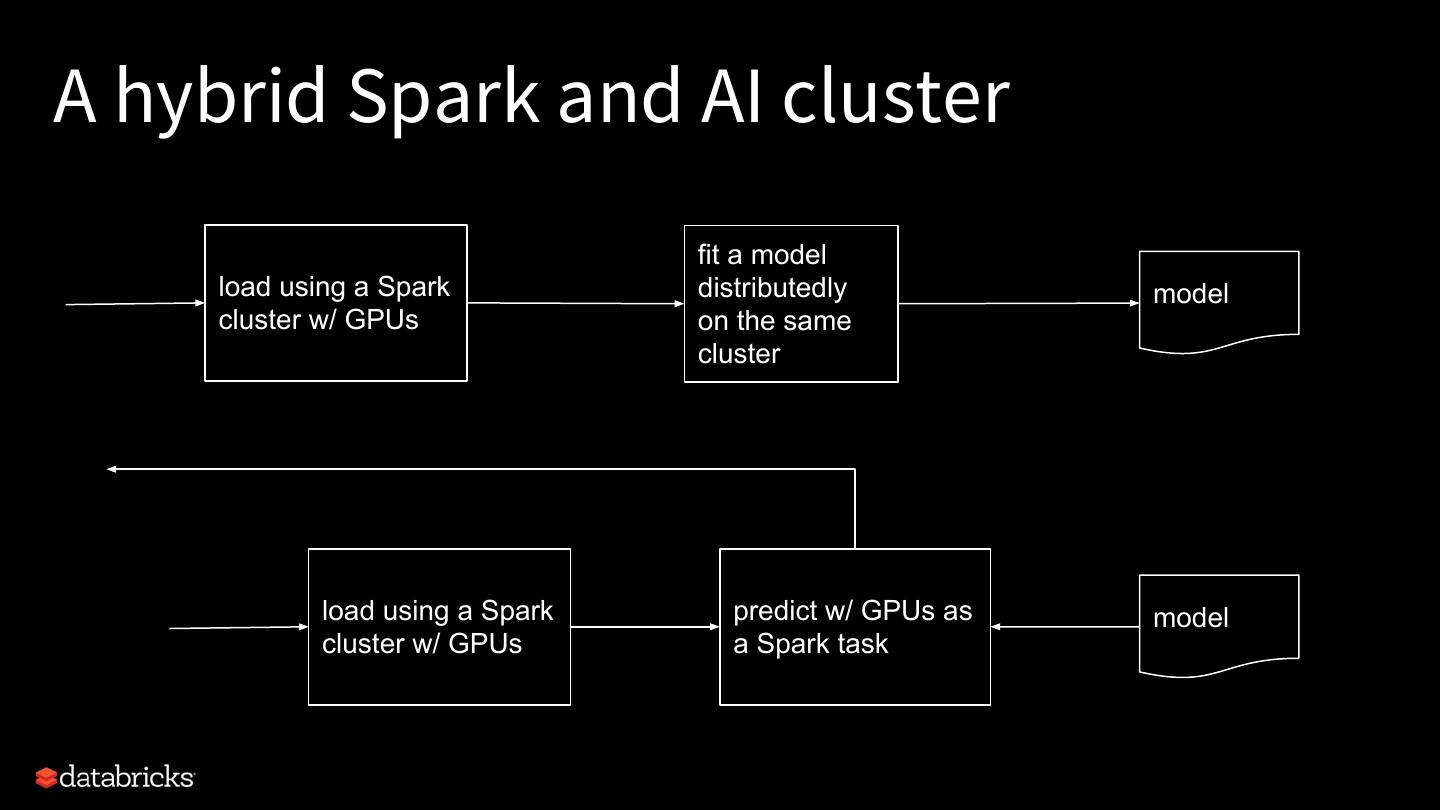
17 .A hybrid Spark and AI cluster fit a model load using a Spark distributedly model cluster w/ GPUs on the same cluster load using a Spark predict w/ GPUs as model cluster w/ GPUs a Spark task
18 .Unfortunately, it doesn’t work out of the box. (Demo that a distributed DL job needs to run as a Spark job to avoid crashing into other Spark workloads on the same cluster.)
19 .Different execution models Spark Task 1 Task 2 Tasks are independent of each other Task 3 Embarrassingly parallel & massively scalable Distributed Training Complete coordination among tasks Optimized for communication 17
20 .Different execution models Spark Task 1 Task 2 Tasks are independent of each other Task 3 Embarrassingly parallel & massively scalable If one crashes… Distributed Training Complete coordination among tasks Optimized for communication 18
21 .Different execution models Spark Task 1 Task 2 Tasks are independent of each other Task 3 Embarrassingly parallel & massively scalable If one crashes, rerun that one Distributed Training Complete coordination among tasks Optimized for communication If one crashes, must rerun all tasks 19
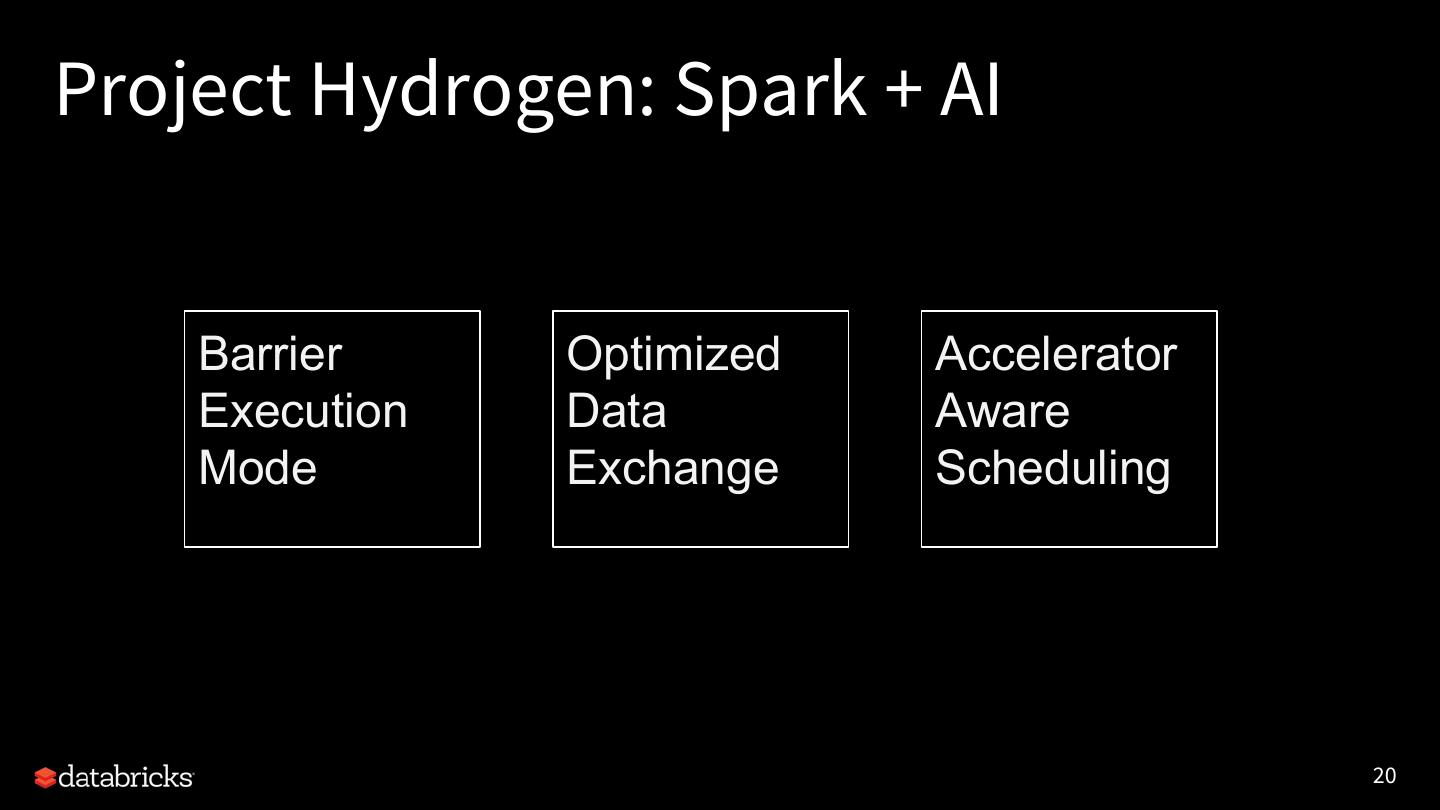
22 .Project Hydrogen: Spark + AI Barrier Optimized Accelerator Execution Data Aware Mode Exchange Scheduling 20
23 .Barrier execution mode We introduce gang scheduling to Spark on top of MapReduce execution model. So a distributed DL job can run as a Spark job. ● It starts all tasks together. ● It provides sufficient info and tooling to run a hybrid distributed job. ● It cancels and restarts all tasks in case of failures. Umbrella JIRA: SPARK-24374 (ETA: Spark 2.4, 3.0) 21
24 .RDD.barrier() RDD.barrier() tells Spark to launch the tasks together. rdd.barrier().mapPartitions { iter => val context = BarrierTaskContext.get() ... } 22
25 .context.barrier() context.barrier() places a global barrier and waits until all tasks in this stage hit this barrier. val context = BarrierTaskContext.get() … // write partition data out context.barrier() 23
26 .context.getTaskInfos() context.getTaskInfos() returns info about all tasks in this stage. if (context.partitionId == 0) { val addrs = context.getTaskInfos().map(_.address) ... // start a hybrid training job, e.g., via MPI } context.barrier() // wait until training finishes 24
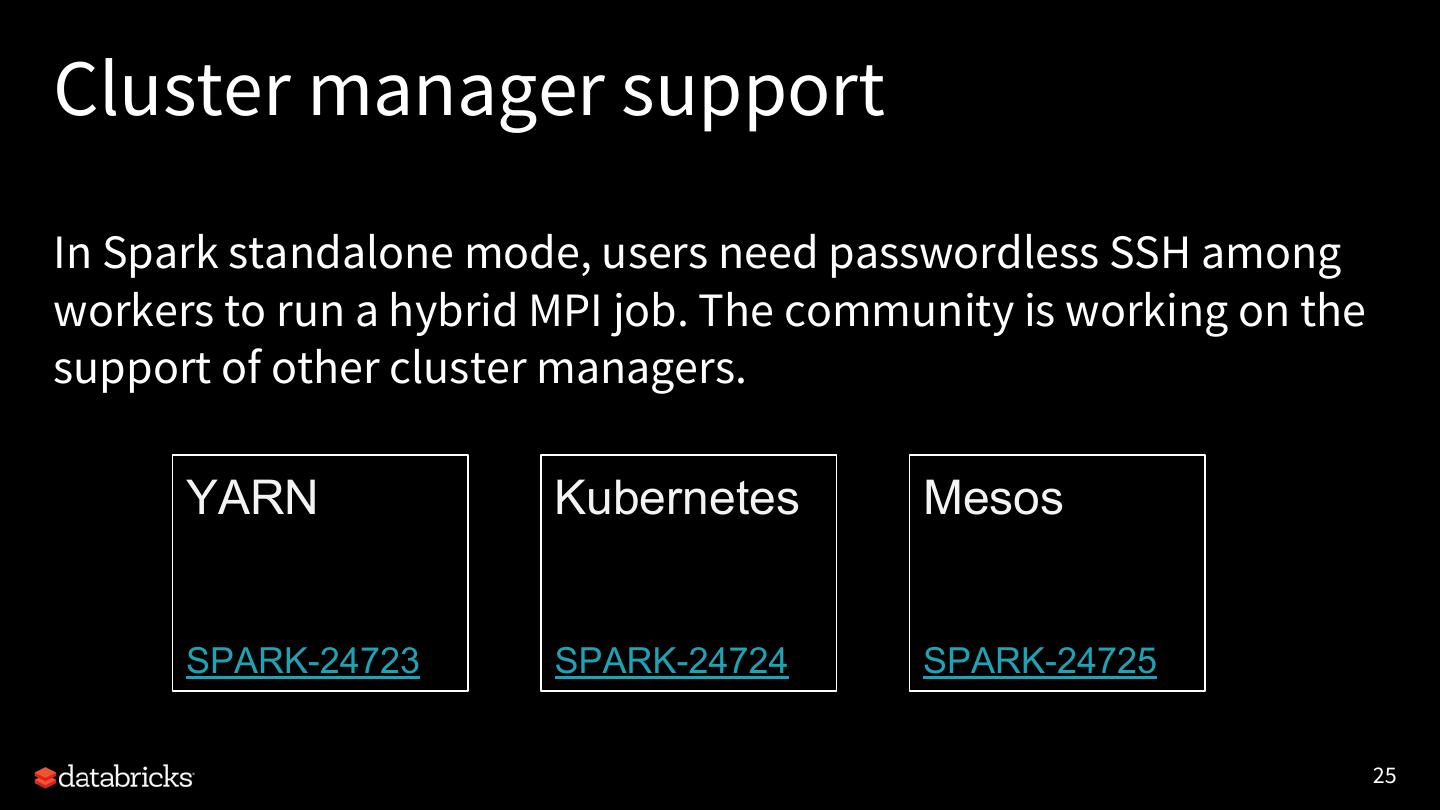
27 .Cluster manager support In Spark standalone mode, users need passwordless SSH among workers to run a hybrid MPI job. The community is working on the support of other cluster managers. YARN Kubernetes Mesos SPARK-24723 SPARK-24724 SPARK-24725 25
28 . Demo (Demo barrier mode prototype, where a distributed DL job runs as a Spark job and does not crash into other Spark workloads.) 26
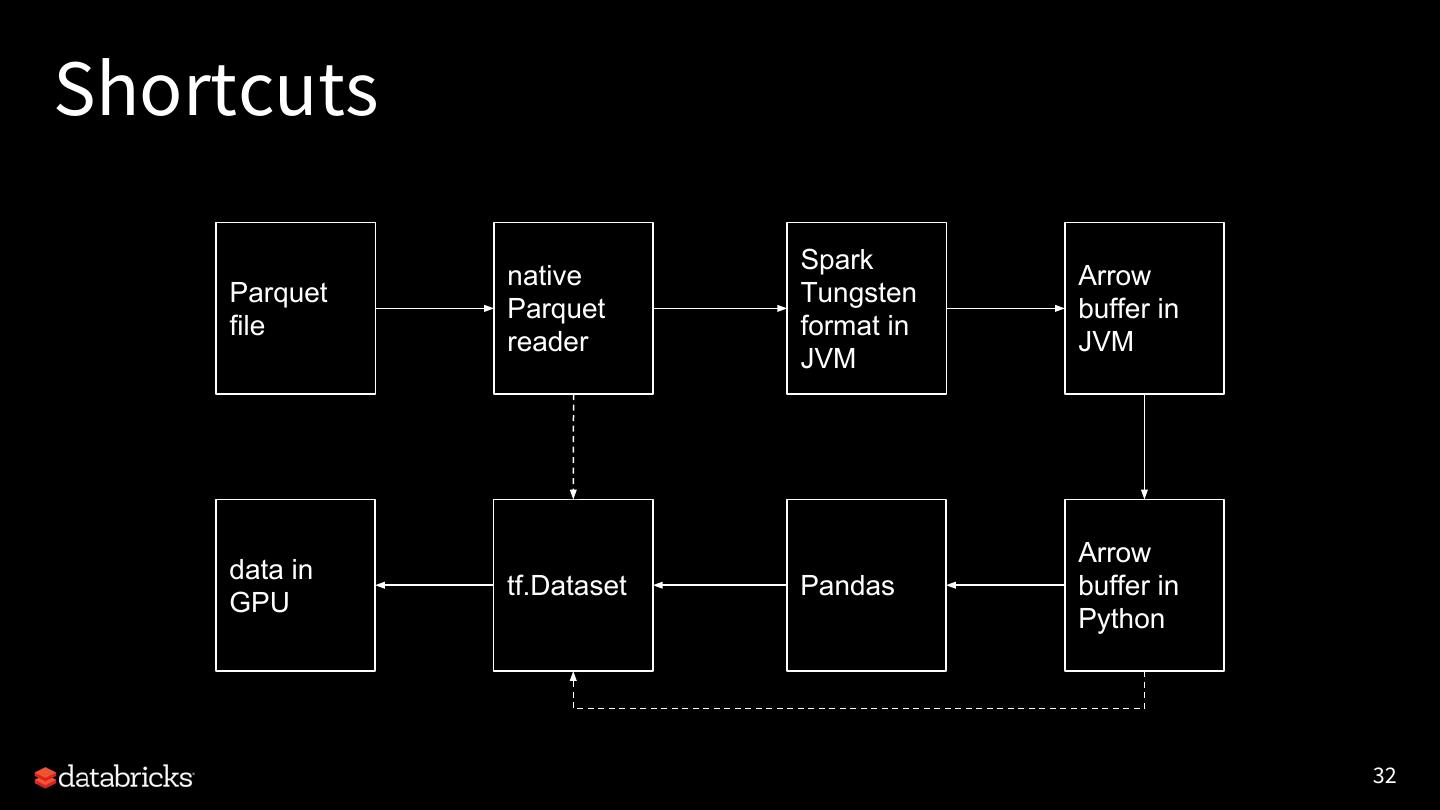
29 .Optimized data exchange (SPIP) None of the integrations are possible without exchanging data between Spark and AI frameworks. And performance matters. We proposed using a standard interface for data exchange to simplify the integrations without introducing much overhead. SPIP JIRA: SPARK-24579 (pending vote, ETA 3.0) 27
相关推荐
3秒后跳转登录页面
去登陆

