展开查看详情
1 .What's New in Apache Spark 2.4?
Wenchen Fan
GIAC | 2018
�
4 .About Me
• Software Engineer at Databricks
• Apache Spark Committer and PMC Member
• Spark SQL and Core
• Github: cloud-fan
�
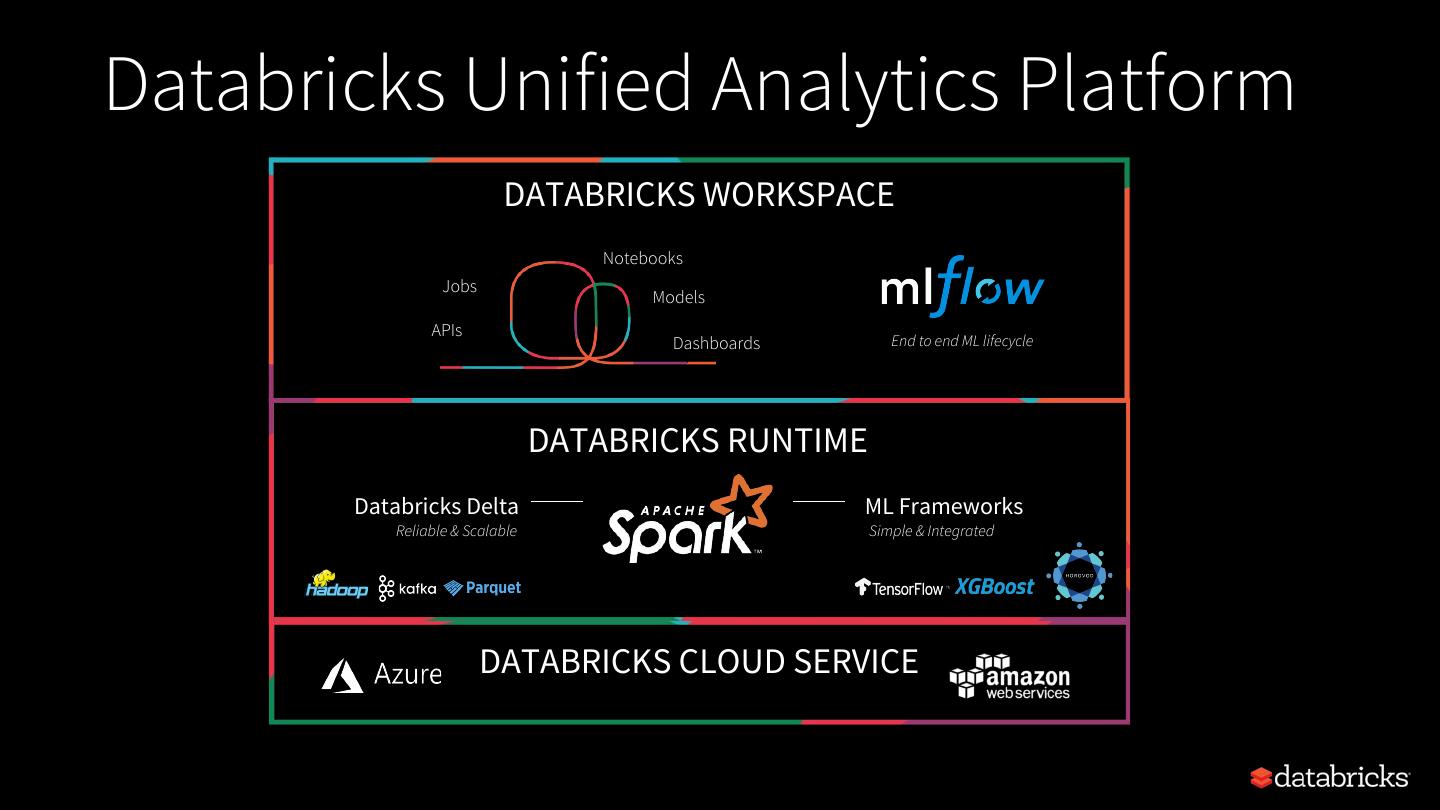
5 .Databricks Unified Analytics Platform
DATABRICKS WORKSPACE
Notebooks
Jobs
Models
APIs
Dashboards End to end ML lifecycle
DATABRICKS RUNTIME
Databricks Delta ML Frameworks
Reliable & Scalable Simple & Integrated
DATABRICKS CLOUD SERVICE
�
6 .Major Features in Spark 2.4
Barrier Spark on Scala PySpark Structured
Execution Kubernetes 2.12 Improvement Streaming
Image Native Avro Built-in source Higher-order Various SQL
Source Support Improvement Functions Features
4
�
7 .Major Features in Spark 2.4
Barrier Spark on Native Avro Image Built-in source
Execution Kubernetes Support Source Improvement
PySpark Higher-order Scala Structured Various SQL
Improvement Functions 2.12 Streaming Features
5
�
8 .Apache Spark: The First Unified Analytics Engine
Uniquely combines Data & AI technologies
Big Data Processing Machine Learning
ETL + SQL +Streaming MLlib + SparkR
�
9 .The cross? ??
Continuous Horovod
Processing
Distributed
Pandas UDF TensorFlow
Structured Streaming tf.data
tf.transform
Keras
TF XLA
AI/ML
Project Tungsten TensorFlow
TensorFrames
ML Pipelines API Caffe/PyTorch/MXNet
TensorFlowOnSpark
GraphLab
50+ Data Sources xgboost
CaffeOnSpark
scikit-learn
DataFrame-based APIs
LIBLINEAR glmnet
Python/Java/R interfaces
Map/Reduce RDD pandas/numpy/scipy R
7
�
10 .Project Hydrogen: Spark + AI
A gang scheduling to Apache Spark that embeds a distributed DL job
as a Spark stage to simplify the distributed training workflow.
[SPARK-24374]
• Launch the tasks in a stage at the same time
• Provide enough information and tooling to embed distributed DL
workloads
• Introduce a new mechanism of fault tolerance (When any task
failed in the middle, Spark shall abort all the tasks and restart the
stage)
8
�
11 .Project Hydrogen: Spark + AI
Barrier Optimized Accelerator
Execution Data Aware
Mode Exchange Scheduling
Demo: Project Hydrogen:
https://vimeo.com/274267107 & https://youtu.be/hwbsWkhBeWM
9
�
12 .Timeline
Spark 2.4
• [SPARK-24374] barrier execution mode (basic scenarios)
• (Databricks) Horovod integration w/ barrier mode
Spark 2.5/3.0
• [SPARK-24374] barrier execution mode
• [SPARK-24579] optimized data exchange
• [SPARK-24615] accelerator-aware scheduling
�
13 .Major Features in Spark 2.4
Barrier Spark on Native Avro Image Built-in source
Execution Kubernetes Support Source Improvement
PySpark Higher-order Scala Structured Various SQL
Improvement Functions 2.12 Streaming Features
11
�
14 .Pandas UDFs
Spark 2.3 introduced vectorized
Pandas UDFs that use Pandas to
process data. Faster data
serialization and execution using
vectorized formats
• Grouped Aggregate Pandas UDFs
• pandas.Series -> a scalar
• returnType: primitive data type
• [SPARK-22274] [SPARK-22239]
12
�
15 .Eager Evaluation
spark.sql.repl.eagerEval.enabled [SPARK-24215]
• Supports DataFrame eager evaluation for PySpark shell and Jupyter.
• When true, the top K rows of Dataset will be displayed.
Prior to 2.4
13
�
16 .Eager Evaluation
spark.sql.repl.eagerEval.enabled [SPARK-24215]
• Supports DataFrame eager evaluation for PySpark shell and Jupyter.
• When true, the top K rows of Dataset will be displayed.
Since 2.4
14
�
17 .Other Notable Features
[SPARK-24396] Add Structured Streaming ForeachWriter for Python
[SPARK-23030] Use Arrow stream format for creating from and collecting
Pandas DataFrames
[SPARK-24624] Support mixture of Python UDF and Scalar Pandas UDF
[SPARK-23874] Upgrade Apache Arrow to 0.10.0
• Allow for adding BinaryType support [ARROW-2141]
[SPARK-25004] Add spark.executor.pyspark.memory limit
15
�
18 .Major Features in Spark 2.4
Barrier Spark on Native Avro Image Built-in source
Execution Kubernetes Support Source Improvement
PySpark Higher-order Scala Structured Various SQL
Improvement Functions 2.12 Streaming Features
16
�
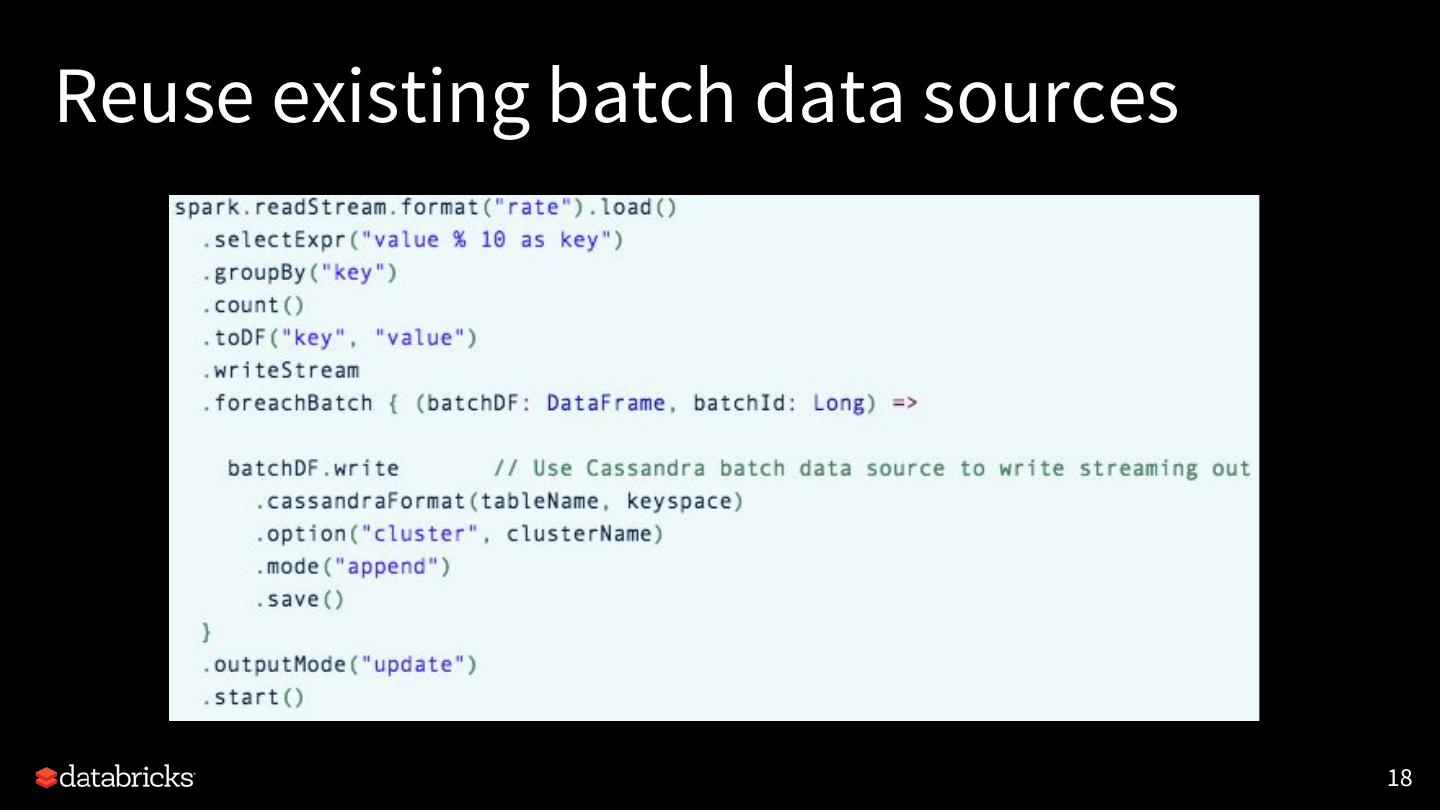
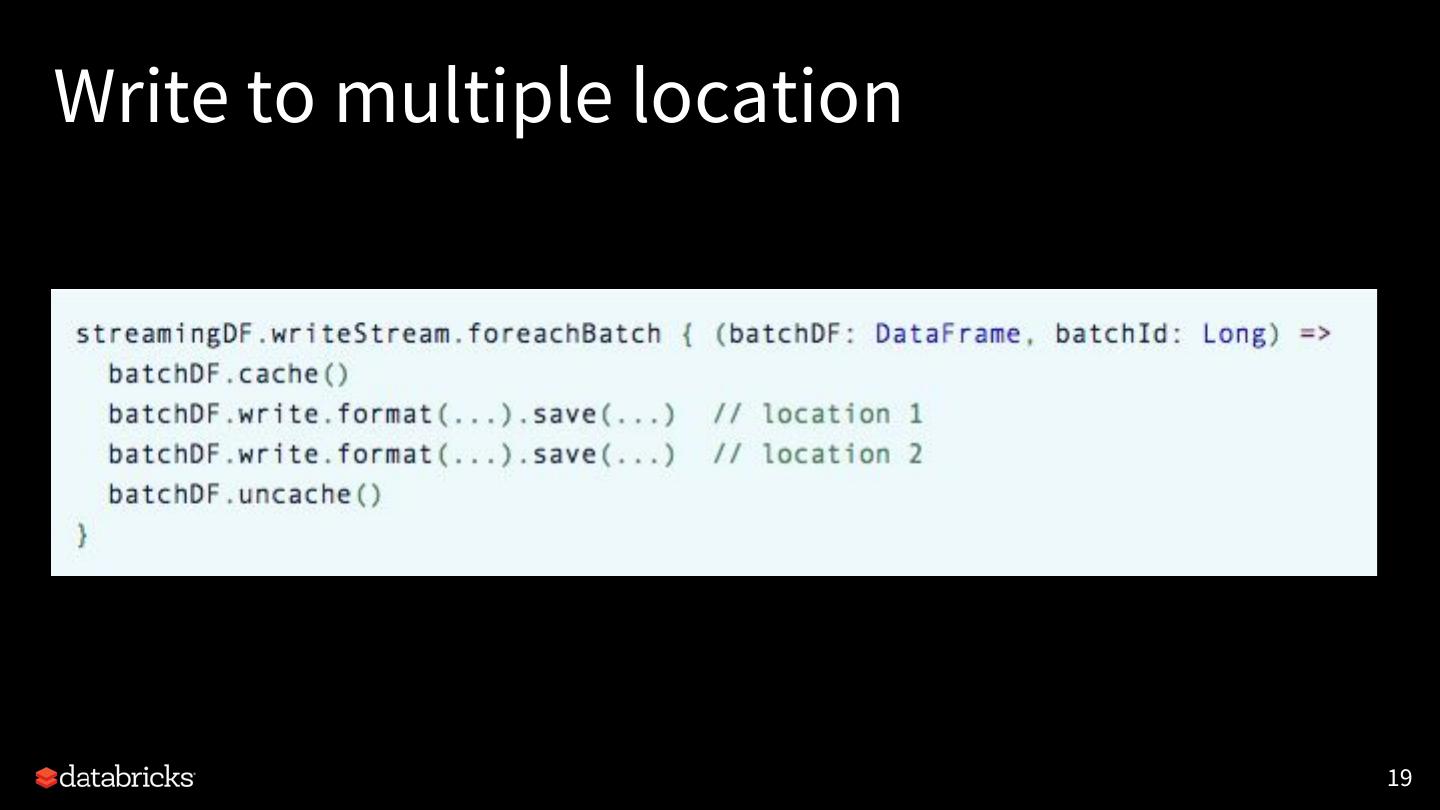
19 .Flexible Streaming Sink
[SPARK-24565] Exposing output rows of each microbatch as a
DataFrame
foreachBatch(f: Dataset[T] => Unit)
• Scala/Java/Python APIs in DataStreamWriter.
• Reuse existing batch data sources
• Write to multiple locations
• Apply additional DataFrame operations
17
�
20 .Reuse existing batch data sources
18
�
21 .Write to multiple location
19
�
22 .Structured Streaming
[SPARK-24662] Support for the LIMIT operator for streams
in Append and Complete output modes.
[SPARK-24763] Remove redundant key data from value in streaming aggregation
[SPARK-24156] Faster generation of output results and/or state cleanup with
stateful operations (mapGroupsWithState, stream-stream join, streaming
aggregation, streaming dropDuplicates) when there is no data in the input
stream.
[SPARK-24730] Support for choosing either the min or max watermark when
there are multiple input streams in a query.
20
�
23 .Kafka Client 2.0.0
[SPARK-18057] Upgraded Kafka client version from 0.10.0.1 to 2.0.0
[SPARK-25005] Support “kafka.isolation.level” to read only committed
records from Kafka topics that are written using a transactional
producer.
21
�
24 .Major Features in Spark 2.4
Barrier Spark on Native Avro Image Built-in source
Execution Kubernetes Support Source Improvement
PySpark Higher-order Scala Structured Various SQL
Improvement Functions 2.12 Streaming Features
22
�
25 .AVRO
• Apache Avro (https://avro.apache.org)
• A data serialization format
• Widely used in the Spark and Hadoop ecosystem, especially for
Kafka-based data pipelines.
• Spark-Avro package (https://github.com/databricks/spark-avro)
• Spark SQL can read and write the avro data.
• Inlining Spark-Avro package [SPARK-24768]
• Better experience for first-time users of Spark SQL and structured
streaming
• Expect further improve the adoption of structured streaming
23
�
26 .AVRO
[SPARK-24811] from_avro/to_avro
functions to read and write Avro
data within a DataFrame instead of
just files.
Example:
1. Decode the Avro data into a struct
2. Filter by column `favorite_color`
3. Encode the column `name` in
Avro format
24
�
27 .AVRO Performance
Runtime comparison (Lower is better)
[SPARK-24800] Refactor Avro Serializer
and Deserializer
2X faster
External library
AVRO Data Row InternalRow
AVRO Data Row InternalRow
Native reader
AVRO Data InternalRow
AVRO Data InternalRow
Notebook: https://dbricks.co/AvroPerf
25
�
28 .AVRO Logical Types
Avro upgrade from 1.7.7 to 1.8. Options:
[SPARK-24771]
• compression
Logical type support: • ignoreExtension
• Date [SPARK-24772] • recordNamespace
• Decimal [SPARK-24774] • recordName
• Timestamp [SPARK-24773] • avroSchema
26
�
29 .Major Features in Spark 2.4
Barrier Spark on Native Avro Image Built-in source
Execution Kubernetes Support Source Improvement
PySpark Higher-order Scala Structured Various SQL
Improvement Functions 2.12 Streaming Features
27
�