
























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
SparkSQL & Scala
Spark SQL重度依赖Scala的语言特性,让SQL编译程序变得简单直接,特别是Spark SQL其核心代码库Tree结构,作者用直接明了的展示了代码,如何完成语法树的操作和变化,包括基于规则的性能优化等,把Scala语言的特性发挥淋漓极致,是学习Spark SQL内核代码的必备教材。
展开查看详情
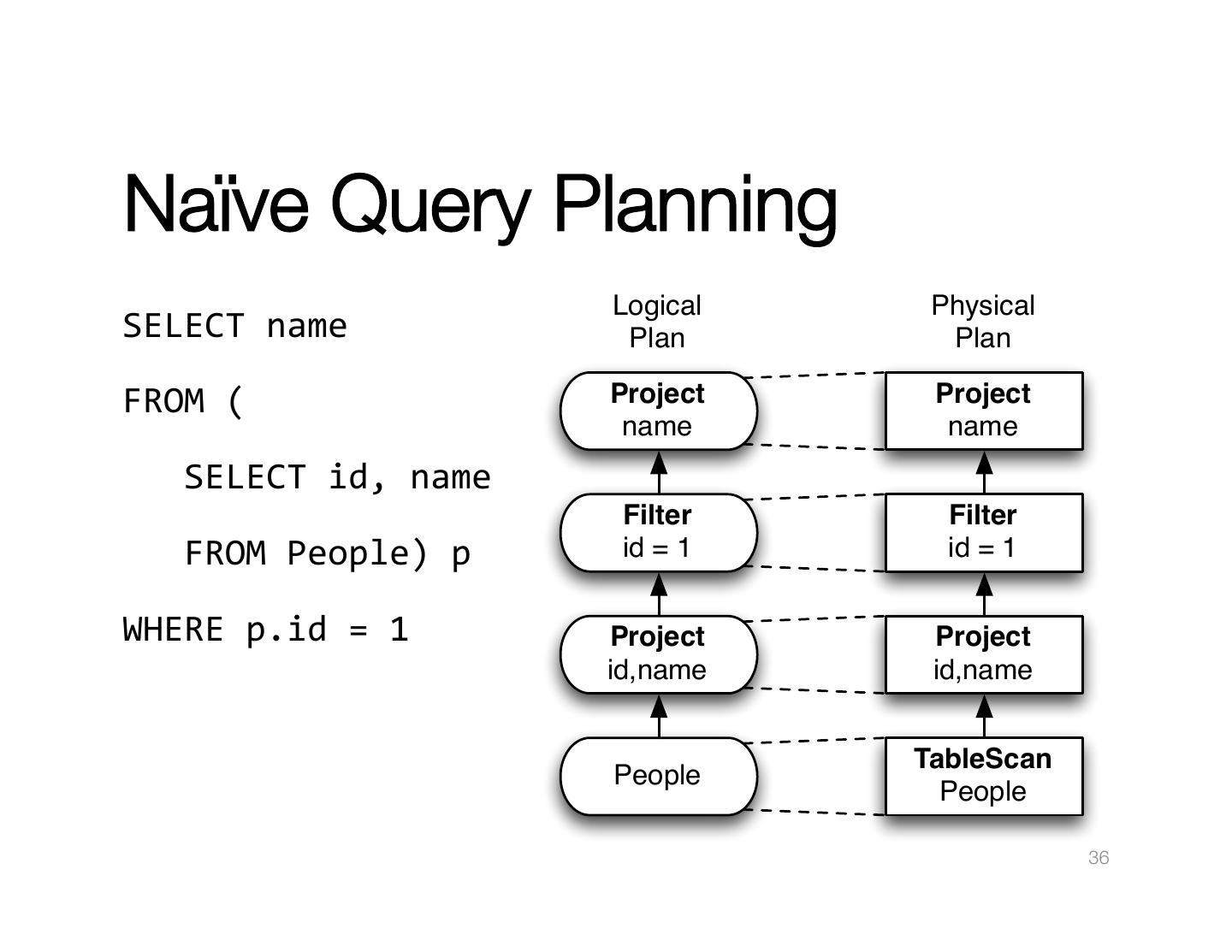
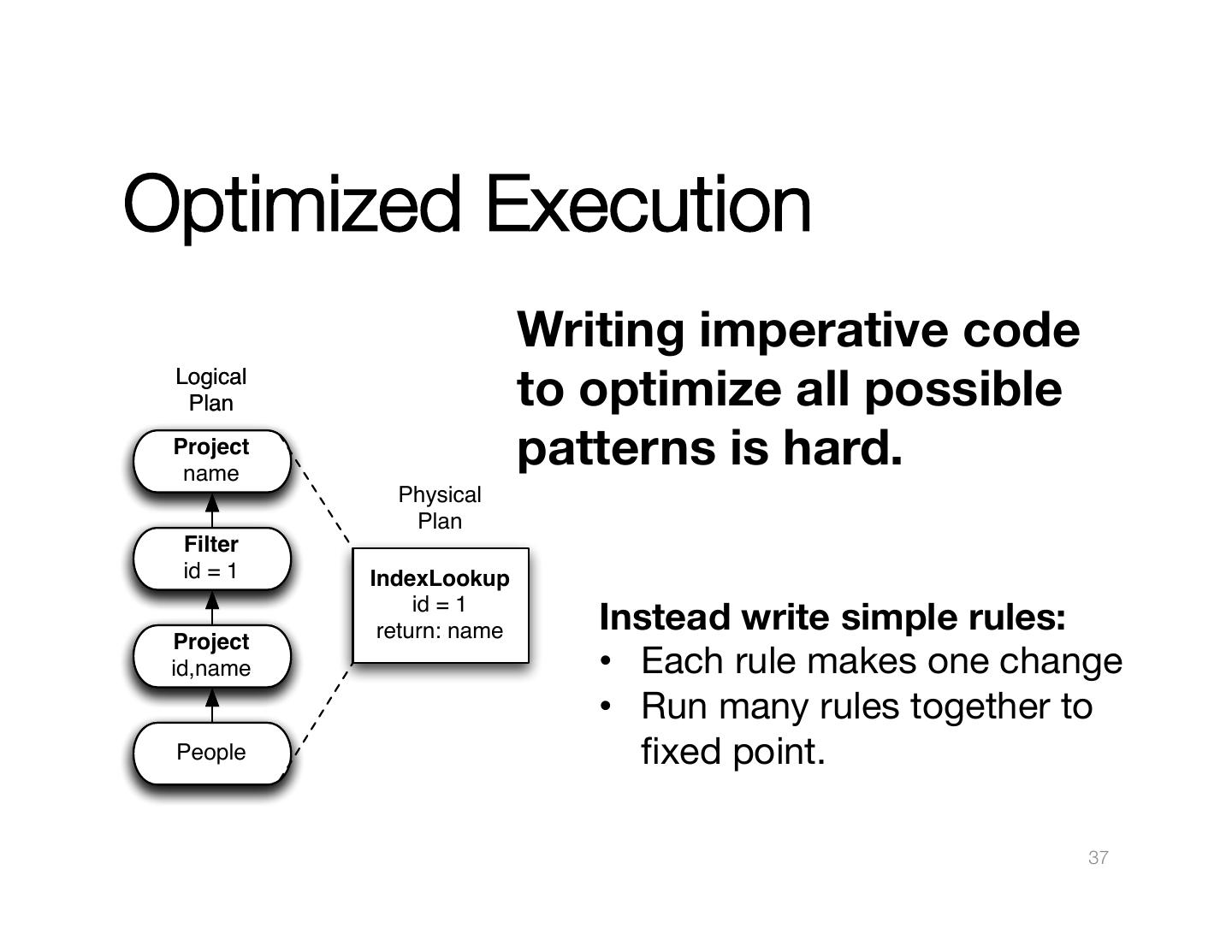
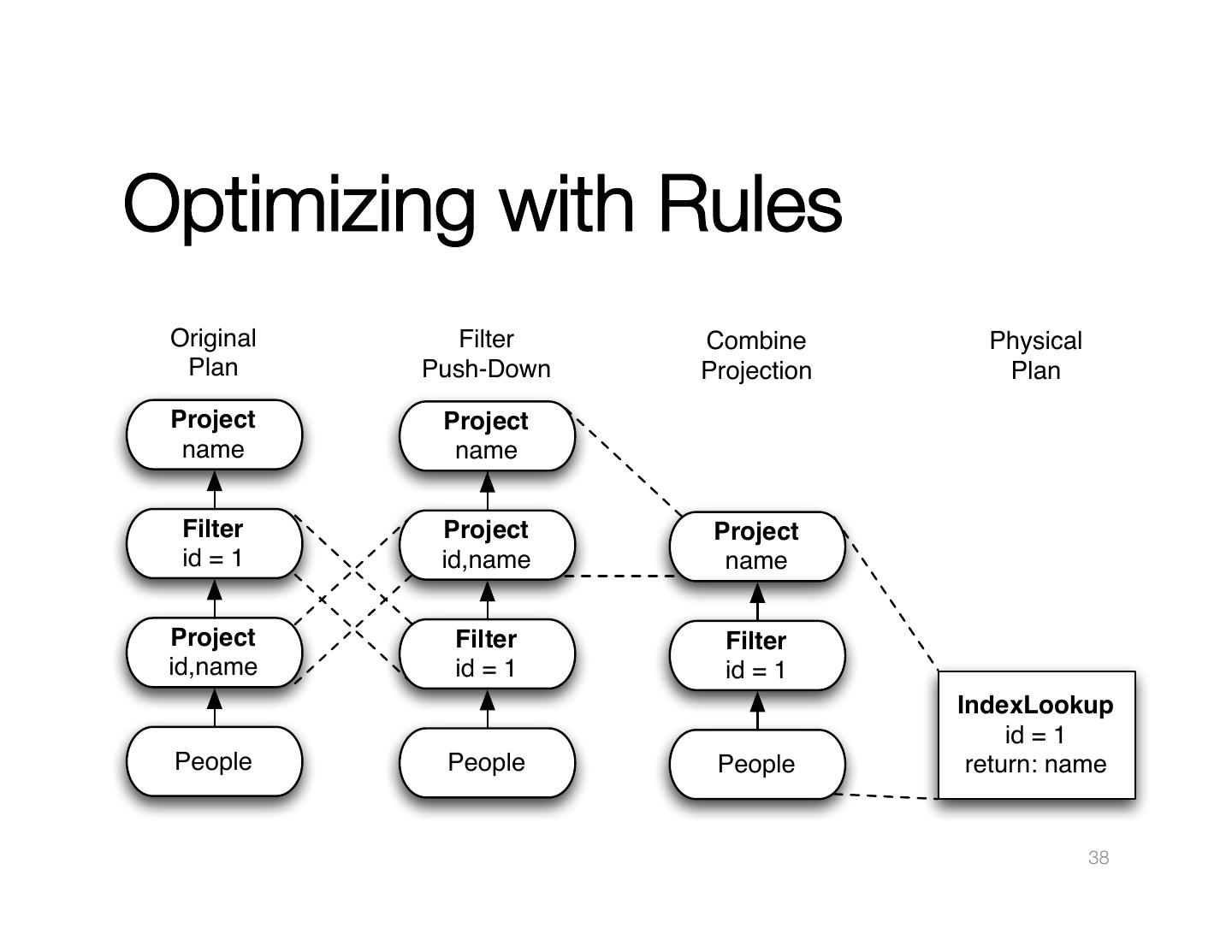
1 .Functional Query Optimization with" " SQL Michael Armbrust @michaelarmbrust spark.apache.org
2 .What is Apache Spark? Fast and general cluster computing system interoperable with Hadoop Improves efficiency through: » In-memory computing primitives Up to 100× faster » General computation graphs (2-10× on disk) Improves usability through: » Rich APIs in Scala, Java, Python 2-5× less code » Interactive shell
3 .A General Stack Spark MLlib Spark GraphX SQL Streaming" graph machine real-time learning … Spark
4 .Spark Model Write programs in terms of transformations on distributed datasets Resilient Distributed Datasets (RDDs) » Collections of objects that can be stored in memory or disk across a cluster » Parallel functional transformations (map, filter, …) » Automatically rebuilt on failure
5 .More than Map/Reduce map reduce sample filter count take groupBy fold first sort reduceByKey partitionBy union groupByKey mapWith join cogroup pipe leftOuterJoin cross save rightOuterJoin zip ...
6 . Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns BaseTransformed RDD RDD messages val lines = spark.textFile(“hdfs://...”) Cache 1 val errors = lines.filter(_ startswith “ERROR”) results Worker val messages = errors.map(_.split(“\t”)(2)) tasks lines messages.cache() Driver Block 1 Action messages.filter(_ contains “foo”).count() messages.filter(_ contains “bar”).count() messages Cache 2 . . . Worker messages Cache 3 Result: scaled full-texttosearch 1 TB data in 5-7 sec" of Wikipedia in Worker lines Block 2 <1 (vs sec170 secsec (vs 20 for for on-disk data) on-disk data) lines Block 3
7 .Fault Tolerance RDDs track lineage info to rebuild lost data file.map(record => (record.tpe, 1)) .reduceByKey(_ + _) .filter { case (_, count) => count > 10 } map reduce filter Input file
8 .Fault Tolerance RDDs track lineage info to rebuild lost data file.map(record => (record.tpe, 1)) .reduceByKey(_ + _) .filter { case (_, count) => count > 10 } map reduce filter Input file
9 . and Scala Provides: Lines of Code • Concise Serializable* Functions Scala! Python! • Easy interoperability with the Hadoop ecosystem Java! Shell! • Interactive REPL Other! * Made even better by Spores (5pm today)
10 . Reduced Developer Complexity 140000 120000 100000 80000 60000 40000 20000 0 Hadoop Storm Impala (SQL) Giraph Spark MapReduce (Streaming) (Graph) non-test, non-example source lines
11 . Reduced Developer Complexity 140000 120000 100000 80000 60000 40000 Streaming 20000 0 Hadoop Storm Impala (SQL) Giraph Spark MapReduce (Streaming) (Graph) non-test, non-example source lines
12 . Reduced Developer Complexity 140000 120000 100000 80000 60000 40000 SparkSQL Streaming 20000 0 Hadoop Storm Impala (SQL) Giraph Spark MapReduce (Streaming) (Graph) non-test, non-example source lines
13 . Reduced Developer Complexity 140000 120000 100000 80000 60000 GraphX 40000 SparkSQL Streaming 20000 0 Hadoop Storm Impala (SQL) Giraph Spark MapReduce (Streaming) (Graph) non-test, non-example source lines
14 .Spark Community One of the largest open source projects in big data 150+ developers contributing 30+ companies contributing Contributors in past year 150 100 50 Giraph Storm Tez 0
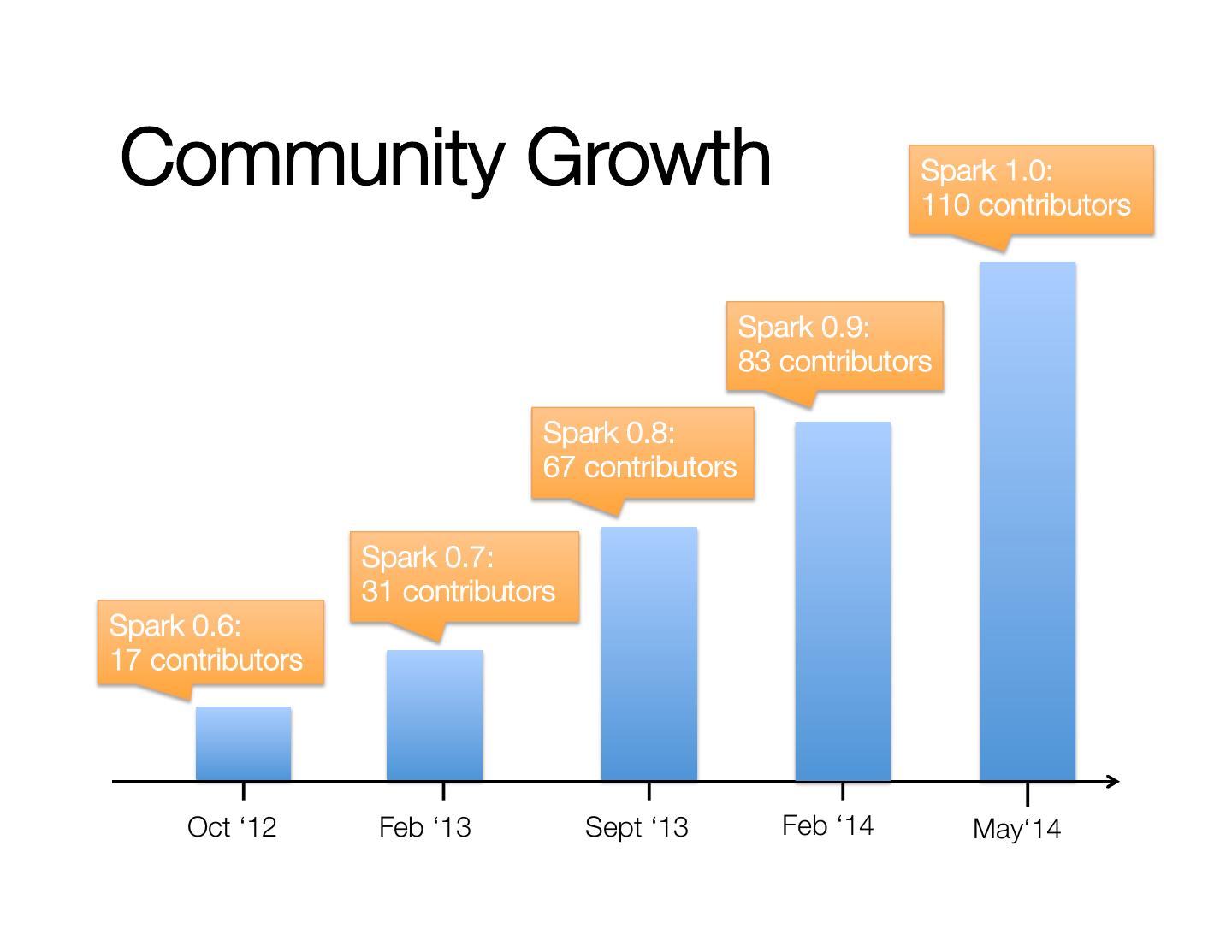
15 .Community Growth Spark 1.0: 110 contributors Spark 0.9: 83 contributors Spark 0.8: 67 contributors Spark 0.7:" 31 contributors Spark 0.6: 17 contributors Oct ‘12 Feb ‘13 Sept ‘13 Feb ‘14 May‘14
16 .With great power… Strict project coding guidelines to make it easier for non-Scala users and contributors: • Absolute imports only • Minimize infix function use • Java/Python friendly wrappers for user APIs • …
17 .SQL
18 .Relationship to Shark modified the Hive backend to run over Spark, but had two challenges: » Limited integration with Spark programs » Hive optimizer not designed for Spark Spark SQL reuses the best parts of Shark: Borrows Adds • Hive data loading • RDD-aware optimizer • In-memory column store • Rich language interfaces
19 .Spark SQL Components Catalyst Optimizer 38%! • Relational algebra + expressions • Query optimization Spark SQL Core 36%! • Execution of queries as RDDs • Reading in Parquet, JSON … 26%! Hive Support • HQL, MetaStore, SerDes, UDFs
20 .Adding Schema to RDDs Spark + RDDs! User User User Functional transformations on User User User partitioned collections of opaque objects. Name Age Height Name Age Height SQL + SchemaRDDs! Name Age Height Declarative transformations on Name Age Height partitioned collections of tuples.! Name Age Height Name Age Height
21 .Using Spark SQL SQLContext • Entry point for all SQL functionality • Wraps/extends existing spark context val sc: SparkContext // An existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // Importing the SQL context gives access to all the SQL functions and conversions. import sqlContext._
22 .Example Dataset A text file filled with people’s names and ages: Michael, 30 Andy, 31 Justin Bieber, 19 …
23 .Turning an RDD into a Relation // Define the schema using a case class. case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table. val people = sc.textFile("examples/src/main/resources/people.txt") .map(_.split(",")) .map(p => Person(p(0), p(1).trim.toInt)) people.registerAsTable("people")
24 .Querying Using SQL // SQL statements are run with the sql method from sqlContext. val teenagers = sql(""" SELECT name FROM people WHERE age >= 13 AND age <= 19""") // The results of SQL queries are SchemaRDDs but also // support normal RDD operations. // The columns of a row in the result are accessed by ordinal. val nameList = teenagers.map(t => "Name: " + t(0)).collect()
25 .Querying Using the Scala DSL Express queries using functions, instead of SQL strings. // The following is the same as: // SELECT name FROM people // WHERE age >= 10 AND age <= 19 val teenagers = people .where('age >= 10) .where('age <= 19) .select('name)
26 .Caching Tables In-Memory Spark SQL can cache tables using an in- memory columnar format: • Scan only required columns • Fewer allocated objects (less GC) • Automatically selects best compression cacheTable("people")
27 .Parquet Compatibility Native support for reading data in Parquet: • Columnar storage avoids reading unneeded data. • RDDs can be written to parquet files, preserving the schema.
28 .Using Parquet // Any SchemaRDD can be stored as Parquet. people.saveAsParquetFile("people.parquet") // Parquet files are self-‐describing so the schema is preserved. val parquetFile = sqlContext.parquetFile("people.parquet") // Parquet files can also be registered as tables and then used // in SQL statements. parquetFile.registerAsTable("parquetFile”) val teenagers = sql( "SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
29 .Hive Compatibility Interfaces to access data and code in" the Hive ecosystem: o Support for writing queries in HQL o Catalog info from Hive MetaStore o Tablescan operator that uses Hive SerDes o Wrappers for Hive UDFs, UDAFs, UDTFs
相关推荐
3秒后跳转登录页面
去登陆

