












- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Compiled and Vectorization SQL Query
现代数据库系统执行引擎一般基于向量化模式或者以查询运行时编译的代码生成技术,这两种技术在系统结构和代码都有本质的不同,然而知道今天我们也没有弄懂那种模式执行效率会更高,这篇论文用实现的方式,在同一套硬件环境中比较两个性能的执行效率,从CPU cache miss率,执行CPU指令数,SIMD,多核处理等各个维度进行了比较。基本结论是:代码生成方案会生成更少的CPU执行指令,向量化计算在并行数据模式下CPU cache miss要更低,特别是在hash join和聚合操作时表现比较明显。其他方面,比如SIMD,多核等都区别不大。
展开查看详情
1 . Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask Timo Kersten Viktor Leis Alfons Kemper Thomas Neumann Andrew Pavlo Peter Boncz Technische Universitat ¨ Munchen ¨ Carnegie Mellon University Centrum Wiskunde & Informatica {kersten,leis,kemper,neumann}@in.tum.de pavlo@cs.cmu.edu boncz@cwi.nl ABSTRACT Like the Volcano-style iteration model, vectorization uses pull- The query engines of most modern database systems are either based iteration where each operator has a next method that produces based on vectorization or data-centric code generation. These two result tuples. However, each next call fetches a block of tuples state-of-the-art query processing paradigms are fundamentally dif- instead of just one tuple, which amortizes the iterator call over- ferent in terms of system structure and query execution code. Both head. The actual query processing work is performed by primitives paradigms were used to build fast systems. However, until today it that execute a simple operation on one or more type-specialized is not clear which paradigm yields faster query execution, as many columns (e.g., compute hashes for a vector of integers). Together, implementation-specific choices obstruct a direct comparison of ar- amortization and type specialization eliminate most of the overhead chitectures. In this paper, we experimentally compare the two mod- of traditional engines. els by implementing both within the same test system. This allows In data-centric code generation, each relational operator imple- us to use for both models the same query processing algorithms, the ments a push-based interface (produce and consume). However, in- same data structures, and the same parallelization framework to ul- stead of directly processing tuples, the produce/consume calls gen- timately create an apples-to-apples comparison. We find that both erate code for a given query. They can also be seen as operator are efficient, but have different strengths and weaknesses. Vector- methods that get called during a depth-first traversal of the query ization is better at hiding cache miss latency, whereas data-centric plan tree, where produce is called on first visit, and consume on compilation requires fewer CPU instructions, which benefits cache- last visit, after all children have been processed. The resulting code resident workloads. Besides raw, single-threaded performance, we is specialized for the data types of the query and fuses all operators also investigate SIMD as well as multi-core parallelization and dif- in a pipeline of non-blocking relational operators into a single (po- ferent hardware architectures. Finally, we analyze qualitative dif- tentially nested) loop. This generated code can then be compiled to ferences as a guide for system architects. efficient machine code (e.g., using the LLVM). Although both models eliminate the overhead of traditional en- PVLDB Reference Format: gines and are highly efficient, they are conceptually different from T. Kersten, V. Leis, A. Kemper, T. Neumann, A. Pavlo, P. Boncz. Ev- each other: Vectorization is based on the pull model (root-to-leaf erything You Always Wanted to Know About Compiled and Vectorized traversal), vector-at-a-time processing, and interpretation. Data- Queries But Were Afraid to Ask. PVLDB, 11 (13): 2209 - 2222, 2018. centric code generation uses the push model (leaf-to-root traver- DOI: https://doi.org/10.14778/3275366.3275370 sal), tuple-at-a-time processing, and up-front compilation. As we discuss in Section 9, other designs that mix or combine ideas from data-centric compilation and vectorization have been proposed. In 1. INTRODUCTION this paper, we focus on these two specific designs, as they have been In most query engines, each relational operator is implemented highly influential and are in use in multiple widespread systems. using Volcano-style iteration [14]. While this model worked well The differences of the two models are fundamental and deter- in the past when disk was the primary bottleneck, it is inefficient mine the organization of the DBMS’s execution engine source code on modern CPUs for in-memory database management systems and its performance characteristics. Because changing the model (DBMSs). Most modern query engines therefore either use vec- requires rewriting large parts of the source code, DBMS design- torization (pioneered by VectorWise [7, 52]) or data-centric code ers must decide early on which model to use. Looking at recent generation (pioneered by HyPer [28]). Systems that use vector- DBMS developments like Quickstep [33] and Peloton [26], we find ization include DB2 BLU [40], columnar SQL Server [21], and that both choices are popular and plausible: Quickstep is based on Quickstep [33], whereas systems based on data-centric code gener- vectorization, Peloton uses data-centric code generation. ation include Apache Spark [2] and Peloton [26]. Given the importance of this choice, it is surprising that there has not yet been a systematic study comparing the two state-of-the- This work is licensed under the Creative Commons Attribution- art query processing models. In this paper, we provide an in-depth NonCommercial-NoDerivatives 4.0 International License. To view a copy experimental comparison of the two models to understand when a of this license, visit http://creativecommons.org/licenses/by-nc-nd/4.0/. For database architect should prefer one model over the other. any use beyond those covered by this license, obtain permission by emailing To compare vectorization and compilation, one could compare info@vldb.org. Copyright is held by the owner/author(s). Publication the runtime performance of emblematic DBMSs, such as HyPer rights licensed to the VLDB Endowment. and VectorWise. The problem is, however, that such full-featured Proceedings of the VLDB Endowment, Vol. 11, No. 13 DBMSs differ in many design dimensions beyond the query execu- ISSN 2150-8097. tion model. For instance, HyPer does not employ sub-byte com- DOI: https://doi.org/10.14778/3275366.3275370 2209
2 . vec<int> sel_eq_row(vec<string> col, vec<int> tir) pression in its columnar storage [19], whereas VectorWise uses vec<int> res; more compact compression methods [53]. Related to this choice, for(int i=0; i<col.size(); i++) // for colors and tires HyPer features predicate-pushdown in scans but VectorWise does if(col[i] == "green" && tir[i] == 4) // compare both not. Another important dimension in which both systems differ res.append(i) // add to final result is parallelism. VectorWise queries spawn threads scheduled by return res the OS, and controls parallelism using explicit exchange opera- (a) Integrated: Both predicates checked at once tors where the parallelism degree is fixed at query optimization time [3]. HyPer, on the other hand, runs one thread on each core vec<int> sel_eq_string(vec<string> col, string o) vec<int> res; and explicitly schedules query tasks on it on a morsel-driven basis for(int i=0; i<col.size(); i++) // for colors using a NUMA-aware, lock-free queue to distribute work. HyPer if(col[i] == o) // compare color and VectorWise also use different query processing algorithms and res.append(i) // remember position structures, data type representations, and query optimizers. Such return res different design choices affect performance and scalability, but are independent of the query execution model. vec<int> sel_eq_int(vec<int> tir, int o, vec<int> s) vec<int> res; To isolate the fundamental properties of the execution model for(i : s) // for remembered position from incidental differences, we implemented a compilation-based if(tir[i] == o) // compare tires relational engine and a vectorization-based engine in a single test res.append(i) // add to final result system (available at [16]). The experiments where we employed return res data-centric code-generation into C++1 we call “Typer” and the (b) Vectorized: Each predicate checked in one primitive vectorized engine we call ”Tectorwise” (TW). Both implementa- Figure 1: Multi-Predicate Example – The straightforward way tions use the same algorithms and data structures. This allows an to evaluate multiple predicates on one data item is to check all at apples-to-apples comparison of both approaches because the only once (1a). Vectorized code must split the evaluation into one part difference between Tectorwise and Typer is the query execution for each predicate (1b). method: vectorized versus data-centric compiled execution. Our experimental results show that both approaches lead to very efficient execution engines, and the performance differences are 2.1 Vectorizing Algorithms generally not very large. Compilation-based engines have an ad- Typer executes queries by running generated code. This means vantage in calculation-heavy queries, whereas vectorized engines that a developer can create operator implementations in any way are better at hiding cache miss latency, e.g., during hash joins. they see fit. Consider the example in Figure 1a: a function that After introducing the two models in more detail in Section 2 selects every row whose color is green and has four tires. There is a and describing our methodology in Section 3, we perform a micro- loop over all rows and in each iteration, all predicates are evaluated. architectural analysis of in-memory OLAP workloads in Section 4. Tectorwise implements the same algorithms as Typer, staying as We then examine in Section 5 the benefit of data-parallel opera- close to it as possible and reasonable (for performance). This is, tions (SIMD), and Section 6 discusses intra-query parallelization however, only possible to a certain degree, as every function imple- on multi-core CPUs. In Section 7, we investigate different hard- mented in vectorized style has two constraints: It can (i) only work ware platforms (Intel, AMD, Xeon Phi) to find out which model on one data type2 and it (ii) must process multiple tuples. In gener- works better on which hardware. After these quantitative OLAP ated code these decisions can both be put into the expression of one performance comparisons, we discuss other factors in Section 8, if statement. This, however, violates (i) which forces Tectorwise including OLTP workloads and compile time. A discussion of hy- to use two functions as shown in Figure 1b. A (not depicted) in- brid processing models follows in Section 9. We conclude by sum- terpretation logic would start by running the first function to se- marizing our results as a guide for system designers in Section 10. lect all elements by color, then the second function to select by number of tires. By processing multiple elements at a time, these functions also satisfy (ii). The dilemma is faced by all operators 2. VECTORIZED VS. COMPILED QUERIES in Tectorwise and all functions are broken down into primitives The main principle of vectorized execution is batched execu- that satisfy (i) and (ii). This example uses a column-wise storage tion [30] on a columnar data representation: every “work” prim- format, but row-wise formats are feasible as well. To maximize itive function that manipulates data does not work on a single data throughput, database developers tend to highly optimize such func- item, but on a vector (an array) of such data items that represents tions. For example, with the help of predicated evaluation (*res=i; multiple tuples. The idea behind vectorized execution is to amor- res+=cond) or SIMD vectorized instruction logic (see Section 5.1). tize the DBMS’s interpretation decisions by performing as much With these constraints in mind, let us examine the details of op- as possible inside the data manipulation methods. For example, erator implementations of Tectorwise. We implemented selections this work can be to hash 1000s of values, compare 1000s of string as shown above. Expressions are split by arithmetic operators into pairs, update a 1000 aggregates, or fetch a 1000 values from 1000s primitives in a similar fashion. Note that for these simple operators of addresses. the Tectorwise implementation must already change the structure Data-centric compilation generates low-level code for a SQL of the algorithms and deviate from the Typer data access patterns. query that fuses all adjacent non-blocking operators of a query The resulting materialization of intermediates makes fast caches pipeline into a single, tight loop. In order to understand the proper- very important for vectorized engines. ties of vectorized and compiled code, it is important to understand the structure of each variant’s code. Therefore, in this section we 2.2 Vectorized Hash Join and Group By present example operator implementations, motivate why they are Pseudo code for parts of our hash join implementations are shown implemented in this fashion, and discuss some of their properties. in Figure 2. The idea for both, the implementation in Typer and 1 2 HyPer compiles to LLVM IR rather than C++, but this choice only affects compila- Technically, it would be possible to create primitives that work on multiple types. tion time (which we ignore in this paper anyway), not execution time. However, this is not practical, as the number of combinations grows exponentially. 2210
3 .query(...) // build hash table tinues until the candidate vector is empty. Afterwards, the join uses for(i = 0; i < S.size(); i++) buildGather to move data from the hash table into buffers for the ht.insert(<S.att1[i], S.att2[i]>, S.att3[i]) next operator. // probe hash table We take a similar approach in the group by operator. Both phases for(i = 0; i < R.size(); i++) of the aggregation use a hash table that contains group keys and int k1 = R.att1[i] aggregates. The first step for all inbound tuples is to find their group string* k2 = R.att2[i] int hash = hash(k1, k2) in the hash table. We perform this with the same technique as in the for(Entry* e = ht.find(hash); e; e = e->next) hash join. For those tuples whose group is not found, one must be if(e->key1 == k1 && e->key2 == *k2) added. Unfortunately, it is not sufficient to just add one group per ... // code of parent operator group-less tuple as this could lead to groups added multiple times. (a) Code generated for hash join We therefore shuffle all group-less tuples into partitions of equal keys (proceeding component by component for composite keys), class HashJoin and add one group per partition to the hash table. Once the groups Primitives probeHash_, compareKeys_, buildGather_; for all incoming tuples are known we run aggregation primitives. ... Transforming into vectorized form led to an even greater deviation int HashJoin::next() ... // consume build side and create hash table from Typer data access patterns. For the join operator, this leads int n = probe->next()// get tuples from probe side to more independent data accesses (as discussed in Section 4.1). // *Interpretation*: compute hashes However, aggregation incurs extra work. vec<int> hashes = probeHash_.eval(n) Note that in order to implement Tectorwise operators we need // find hash candidate matches for hashes to deviate from the Typer implementations. This deviation is not vec<Entry*> candidates = ht.findCandidates(hashes) by choice, but due to the limitations (i) and (ii) which vectorization // matches: int references a position in hashes vec<Entry*, int> matches = {} imposes. This yields two different implementations for each oper- // check candidates to find matches ator, but at its core, each operator executes the same algorithm with while(candidates.size() > 0) the same parallelization strategy. // *Interpretation* vec<bool> isEqual = compareKeys_.eval(n, candidates) hits, candidates = extractHits(isEqual, candidates) 3. METHODOLOGY matches += hits To isolate the fundamental properties of the execution model // *Interpretation*: gather from hash table into from incidental differences found in real-world systems, we im- // buffers for next operator plemented a compilation-based engine (Typer) and a vectorization- buildGather_.eval(matches) return matches.size() based engine (Tectorwise) in a single test system (available at [16]). To make experiments directly comparable, both implementations (b) Vectorized code that performs a hash join use the same algorithms and data structures. When testing queries, Figure 2: Hash Join Implementations in Typer and Tectorwise we use the same physical query plans for vectorized and compiled – Generated code (Figure 2a) can take any form, e.g., it can com- execution. We do not include query parsing, optimization, code bine the equality check of hash table keys. In vectorized code (Fig- generation, and compilation time in our measurements. This test- ure 2b), this is only possible with one primitive for each check. ing methodology allows an apples-to-apples comparison of both approaches because the only difference between Tectorwise and Tectorwise, is to first consume all tuples from one input and place Typer is the query execution method: vectorized versus data-centric them into a hash table. The entries are stored in row format for compiled execution. better cache locality. Afterwards, for each tuple from the other in- put, we probe the hash table and yield all found combinations to 3.1 Related Work the parent operator. The corresponding code that Typer generates Vectorization was proposed by Boncz et al. [7] in 2005. It was is depicted in Figure 2a. first used in MonetDB/X100, which evolved into the commercial Tectorwise cannot proceed in exactly the same manner. Probing OLAP system VectorWise, and later adopted by systems like DB2 a hash table with composite keys is the intricate part here, as each BLU [40], columnar SQL Server [21], and Quickstep [33]. In probe operation needs to test equality of all parts of the composite 2011, Neumann [28] proposed data-centric code generation using key. Using the former approach would, however, violate (i). There- the LLVM compiler framework as the query processing model of fore, the techniques from Section 2.1 are applied: The join function HyPer, an in-memory hybrid OLAP and OLTP system. It is also first creates hashes from the probe keys. It does this by evaluating used by Peloton [26] and Spark [2]. the probeHash expression. A user of the vectorized hash join must To the best of our knowledge, this paper is the first systemic configure the probeHash and other expressions that belong to the comparison of vectorization and data-centric compilation. Som- operator so that when the expressions evaluate, they use data from polski et al. [45] compare the two models using a number of mi- the operator’s children. Here, the probeHash expression hashes key crobenchmarks, but do not evaluate end-to-end performance for full columns by invoking one primitive per key column and writes the queries. More detailed experimental studies are available for OLTP hashes into an output vector. The join function then uses this vector systems. Appuswamy et al. [4] evaluate different OLTP system ar- of hashes to generate candidate match locations in the hash table. It chitectures in a common prototype, and Sirin et al. [43] perform then inspects all discovered locations and checks for key equality. a detailed micro-architectural analysis of existing commercial and It performs the equality check by evaluating the cmpKey expression. open source OLTP systems. For composite join-keys, this invokes multiple primitives: one for every key column, to avoid violating (i) and (ii). Then, the join 3.2 Query Processing Algorithms function adds the matches to the list of matching tuples, and, in We implemented five relational operators both in Tectorwise and case any candidates have an overflow chain, it uses the overflow Typer: scan, select, project (map), join, and group by. The scan entries as new candidates for the next iteration. The algorithm con- operator at its core consists of a (parallel) for loop over the scanned 2211
4 . q1 q6 q3 q9 q18 Table 1: CPU Counters – TPC-H SF=1, 1 thread, normalized by 50 150 number of tuples processed in that query Runtime [ms] 80 15 150 40 60 10 100 100 30 L1 LLC branch 40 20 cycles IPC instr. miss miss miss 5 50 50 20 10 0 0 0 0 0 Q1 Typer 34 2.0 68 0.6 0.57 0.01 Typer TW Typer TW Typer TW Typer TW Typer TW Q1 TW 59 2.8 162 2.0 0.57 0.03 Q6 Typer 11 1.8 20 0.3 0.35 0.06 Figure 3: Performance – TPC-H SF=1, 1 thread Q6 TW 11 1.4 15 0.2 0.29 0.01 relation. Select statements are expressed as if branches. Projection Q3 Typer 25 0.8 21 0.5 0.16 0.27 is achieved by transforming the expression to the corresponding C Q3 TW 24 1.8 42 0.9 0.16 0.08 code. Unlike production-grade systems, our implementation does Q9 Typer 74 0.6 42 1.7 0.46 0.34 not perform overflow checking of arithmetic expressions. Join uses Q9 TW 56 1.3 76 2.1 0.47 0.39 a single hash table3 with chaining for collision detection. Using Q18 Typer 30 1.6 46 0.8 0.19 0.16 16 (unused) bits of each pointer, the hash table dictionary encodes Q18 TW 48 2.1 102 1.9 0.18 0.37 a small Bloom filter-like structure [22] that improves performance for selective joins (a probe miss usually does not have to traverse data size by a factor of 10, causes 0.5 additional cache misses per the collision list). The group by operator is split into two phases tuple“). for cache friendly parallelization. A pre-aggregation handles heavy hitters and spills groups into partitions. Afterwards, a final step 4. MICRO-ARCHITECTURAL ANALYSIS aggregates the groups in each partition. Using these algorithms To understand the two query processing paradigms, we perform in data-centric code is quite straightforward, while vectorization an in-depth micro-architectural comparison. We initially focus on requires adaptations, which we describe in Section 2.1. sequential performance and defer discussing data-parallelism (SIMD) 3.3 Workload to Section 5 and multi-core parallelization to Section 6. In this paper we focus on OLAP performance, and therefore use 4.1 Single-Threaded Performance the well-known TPC-H benchmark for most experiments. To be Figure 3 compares the single-threaded performance of the two able to show detailed statistics for each individual query as op- models for selected TPC-H queries. For some queries (Q1, Q18), posed to only summary statistics, we chose a representative subset Typer is faster and for others (Q3, Q9) Tectorwise is more efficient. of TPC-H. The selected queries and their performance bottlenecks The relative performance ranges from Typer being faster by 74% are listed in the following: (Q1) to Tectorwise being faster by 32% (Q9). Before we look at • Q1: fixed-point arithmetic, (4 groups) aggregation the reasons for this, we note that these are not large differences, es- • Q6: selective filters pecially when compared to the performance gap to other systems. • Q3: join (build: 147 K entries, probe: 3.2 M entries) For example the difference between HyPer and PostgresSQL is be- • Q9: join (build: 320 K entries, probe: 1.5 M entries) tween one and two orders of magnitude [17]. In other words, the performance of both query processing paradigms is quite close— • Q18: high-cardinality aggregation (1.5 M groups) despite the fact that the two models appear different from the point The given cardinalities are for scale factor (SF) 1 and grow lin- of someone implementing these systems. Nevertheless, neither early with it. Of the remaining 17 queries, most are dominated by paradigm is clearly dominated by the other which makes both vi- join processing and are therefore similar to Q3 and Q9. A smaller able options to implement a processing engine. Therefore, in the number of queries spend most of the time in a high-cardinality ag- following we analyze the performance differences to understand gregation and are therefore similar to Q18. Finally, despite being the strengths and weaknesses of the two models. the only two single-table queries, we show results for both Q1 and Table 1 shows some important CPU statistics, from which a num- Q6 as they behave quite differently. Together, these five queries ber of observations can be made. First, Tectorwise executes signif- cover the most important performance challenges of TPC-H and icantly more instructions (up to 2.4×) and usually has more L1 any execution engine that performs well on them will likely be also data cache misses (up to 3.3×). Tectorwise breaks all operations efficient on the full TPC-H suite [6]. into simple steps and must materialize intermediate results between these steps, which results in additional instructions and cache ac- 3.4 Experimental Setup cesses. Typer, in contrast, can often keep intermediate results in Unless otherwise noted, we use a system equipped with an In- CPU registers and thus perform the same operations with fewer tel i9-7900X (Skylake X) CPU with 10 cores for our experiments. instructions. Based on these observations, it becomes clear why Detailed specifications for this CPU can be found in the hardware Typer is significantly faster on Q1. This query is dominated by section in Table 4. We use Linux as OS and compile our code fixed-point arithmetic operations and a cheap in-cache aggregation. with GCC 7.2. The CPU counters were obtained using Linux’ perf In Tectorwise intermediate results must be materialized, which is events API. Throughout this paper, we normalize CPU counters by similarly expensive as the computation itself. Thus, one key dif- the total number of tuples scanned by that query (i.e., the sum of ference between the two models is that Typer is more efficient for the cardinalities of all tables scanned). This normalization enables computational queries that can hold intermediate results in CPU intuitive observations across systems (e.g., “Tectorwise executes 41 registers and have few cache misses. instructions per tuple more than Typer on query 1“) as well as in- We observe furthermore, that for Q3 and Q9, whose performance teresting comparisons across other dimensions (e.g., “growing the is determined by the efficiency of hash table probing, Tectorwise is 3 Although recent research argues for partitioned hash joins [5, 41], single-table joins faster than Typer (by 4% and 32%). This might be surprising given are still prevalent in production systems and are used by both HyPer and VectorWise. the fact that both engines use exactly the same hash table layout 2212
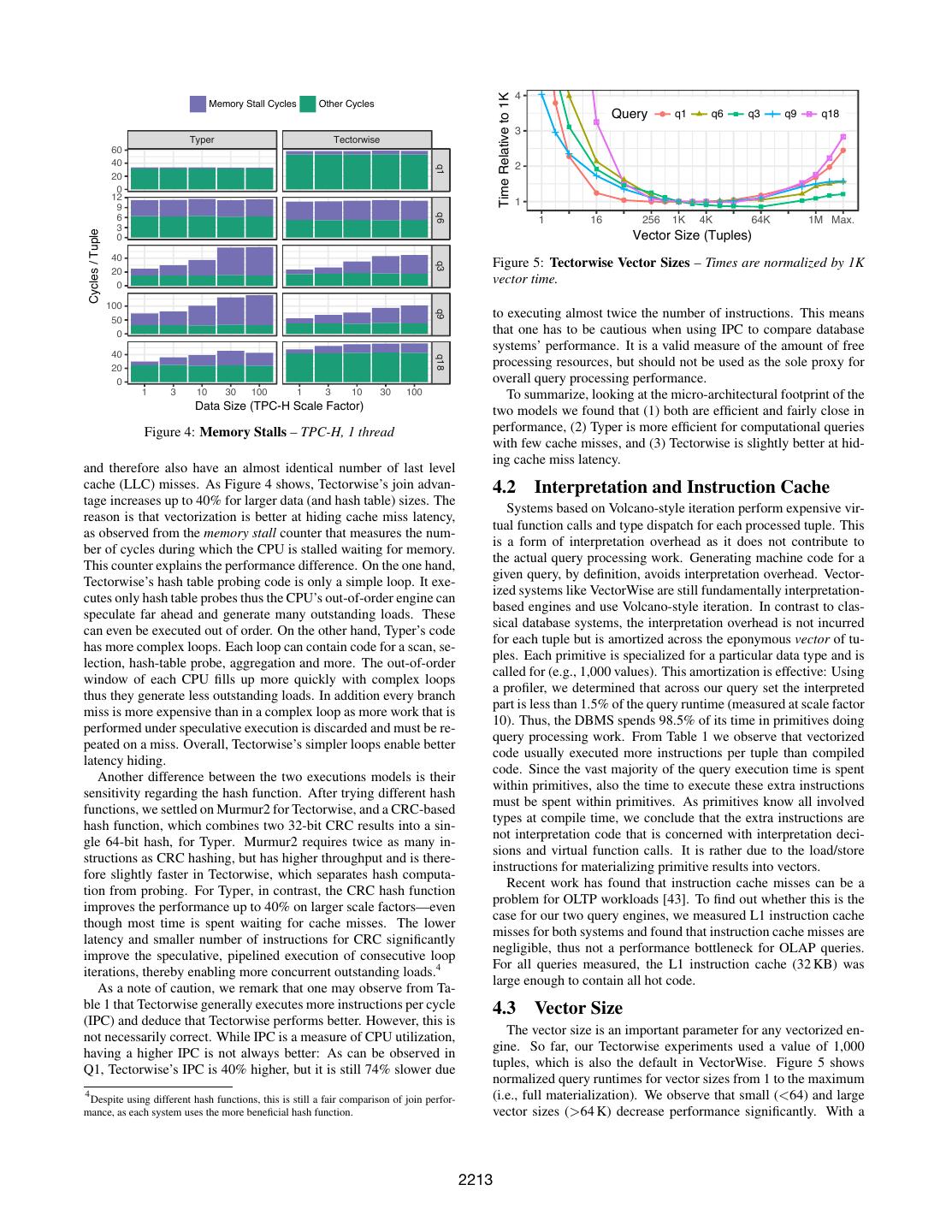
5 . 4 Time Relative to 1K Memory Stall Cycles Other Cycles Query q1 q6 q3 q9 q18 3 Typer Tectorwise 60 40 2 q1 20 0 12 1 9 q6 6 1 16 256 1K 4K 64K 1M Max. 3 Cycles / Tuple 0 Vector Size (Tuples) 40 Figure 5: Tectorwise Vector Sizes – Times are normalized by 1K q3 20 0 vector time. 100 to executing almost twice the number of instructions. This means q9 50 0 that one has to be cautious when using IPC to compare database systems’ performance. It is a valid measure of the amount of free 40 q18 20 processing resources, but should not be used as the sole proxy for 0 overall query processing performance. 1 3 10 30 100 1 3 10 30 100 To summarize, looking at the micro-architectural footprint of the Data Size (TPC-H Scale Factor) two models we found that (1) both are efficient and fairly close in Figure 4: Memory Stalls – TPC-H, 1 thread performance, (2) Typer is more efficient for computational queries with few cache misses, and (3) Tectorwise is slightly better at hid- ing cache miss latency. and therefore also have an almost identical number of last level cache (LLC) misses. As Figure 4 shows, Tectorwise’s join advan- 4.2 Interpretation and Instruction Cache tage increases up to 40% for larger data (and hash table) sizes. The Systems based on Volcano-style iteration perform expensive vir- reason is that vectorization is better at hiding cache miss latency, tual function calls and type dispatch for each processed tuple. This as observed from the memory stall counter that measures the num- is a form of interpretation overhead as it does not contribute to ber of cycles during which the CPU is stalled waiting for memory. the actual query processing work. Generating machine code for a This counter explains the performance difference. On the one hand, given query, by definition, avoids interpretation overhead. Vector- Tectorwise’s hash table probing code is only a simple loop. It exe- ized systems like VectorWise are still fundamentally interpretation- cutes only hash table probes thus the CPU’s out-of-order engine can based engines and use Volcano-style iteration. In contrast to clas- speculate far ahead and generate many outstanding loads. These sical database systems, the interpretation overhead is not incurred can even be executed out of order. On the other hand, Typer’s code for each tuple but is amortized across the eponymous vector of tu- has more complex loops. Each loop can contain code for a scan, se- ples. Each primitive is specialized for a particular data type and is lection, hash-table probe, aggregation and more. The out-of-order called for (e.g., 1,000 values). This amortization is effective: Using window of each CPU fills up more quickly with complex loops a profiler, we determined that across our query set the interpreted thus they generate less outstanding loads. In addition every branch part is less than 1.5% of the query runtime (measured at scale factor miss is more expensive than in a complex loop as more work that is 10). Thus, the DBMS spends 98.5% of its time in primitives doing performed under speculative execution is discarded and must be re- query processing work. From Table 1 we observe that vectorized peated on a miss. Overall, Tectorwise’s simpler loops enable better code usually executed more instructions per tuple than compiled latency hiding. code. Since the vast majority of the query execution time is spent Another difference between the two executions models is their within primitives, also the time to execute these extra instructions sensitivity regarding the hash function. After trying different hash must be spent within primitives. As primitives know all involved functions, we settled on Murmur2 for Tectorwise, and a CRC-based types at compile time, we conclude that the extra instructions are hash function, which combines two 32-bit CRC results into a sin- not interpretation code that is concerned with interpretation deci- gle 64-bit hash, for Typer. Murmur2 requires twice as many in- sions and virtual function calls. It is rather due to the load/store structions as CRC hashing, but has higher throughput and is there- instructions for materializing primitive results into vectors. fore slightly faster in Tectorwise, which separates hash computa- Recent work has found that instruction cache misses can be a tion from probing. For Typer, in contrast, the CRC hash function problem for OLTP workloads [43]. To find out whether this is the improves the performance up to 40% on larger scale factors—even case for our two query engines, we measured L1 instruction cache though most time is spent waiting for cache misses. The lower misses for both systems and found that instruction cache misses are latency and smaller number of instructions for CRC significantly negligible, thus not a performance bottleneck for OLAP queries. improve the speculative, pipelined execution of consecutive loop For all queries measured, the L1 instruction cache (32 KB) was iterations, thereby enabling more concurrent outstanding loads.4 large enough to contain all hot code. As a note of caution, we remark that one may observe from Ta- ble 1 that Tectorwise generally executes more instructions per cycle 4.3 Vector Size (IPC) and deduce that Tectorwise performs better. However, this is The vector size is an important parameter for any vectorized en- not necessarily correct. While IPC is a measure of CPU utilization, gine. So far, our Tectorwise experiments used a value of 1,000 having a higher IPC is not always better: As can be observed in tuples, which is also the default in VectorWise. Figure 5 shows Q1, Tectorwise’s IPC is 40% higher, but it is still 74% slower due normalized query runtimes for vector sizes from 1 to the maximum 4 Despite using different hash functions, this is still a fair comparison of join perfor- (i.e., full materialization). We observe that small (<64) and large mance, as each system uses the more beneficial hash function. vector sizes (>64 K) decrease performance significantly. With a 2213
6 .vector size of 1, Tectorwise is a Volcano-style interpreter with its large CPU overhead. Large vectors do not fit into the CPU caches 2.5 Cycles / Element Cycles / Element 2.0 1.4x and therefore cause cache misses. The other end of the spectrum is 2.0 Time [ms] 1.5 10 to process the query one column at a time; this approach is used in 1.5 2.7x 8.4x 1.0 MonetDB [9]. Generally, a vector size of 1,000 seems to be a good 1.0 5 setting for all queries. The only exception is Q3, which executes 0.5 0.5 15% faster using a vector size of 64K. 0.0 0.0 0 Scalar SIMD Scalar SIMD Scalar SIMD 4.4 Star Schema Benchmark (a) Dense Input (b) Sparse Input (c) TPC-H Q6 So far, we investigated a carefully selected subset of TPC-H. To Figure 6: Scalar vs. SIMD Selection in Tectorwise – (a) 40% show that our findings are more generally applicable, we also im- selectivity. (b) Secondary selection: Input selection vector selects plemented the Star Schema Benchmark (SSB), which consists of 4 40% and selection selects 40%. (c) Runtime of TPC-H Q6, SF=1 query templates (with different selections) and which is dominated by hash table probes. We use one thread and scale factor 30: code [34, 26], this is more challenging since the generated code is L1 LLC branch mem more complex. We will therefore use Tectorwise as the platform cycles IPC instr. miss miss miss stall for evaluating how large the impact of SIMD on in-memory OLAP workloads is. In contrast to most research on SIMD, we use TPC-H Q1.1 Typer 28 0.7 21 0.3 0.31 0.69 6.33 and not micro-benchmarks. Q1.1 TW 12 2.0 23 0.4 0.29 0.05 2.77 The Skylake X CPU we use for this paper supports the new AVX- Q2.1 Typer 39 0.8 30 1.3 0.12 0.17 18.35 512 instruction set and can execute two 512-bit SIMD operations Q2.1 TW 30 1.5 44 1.6 0.13 0.23 7.63 per cycle—doubling register widths and throughput in comparison Q3.1 Typer 55 0.7 40 1.1 0.20 0.24 27.95 with prior microarchitectures. In other words, using AVX-512 one Q3.1 TW 53 1.3 71 1.7 0.23 0.41 15.68 can process 32 values of 32-bit per cycle, while scalar code is lim- Q4.1 Typer 78 0.5 39 1.8 0.31 0.38 45.91 ited to 4 values per cycle. Furthermore, in comparison with prior Q4.1 TW 59 1.0 61 2.5 0.32 0.63 19.48 SIMD instruction sets like AVX2, AVX-512 is more powerful (al- most all operations support masking and there are new instructions These results are quite similar to TPC-H Q3 and Q9 and show like compress and expand) and orthogonal (almost all operations once more that Tectorwise requires more instructions but has an ad- are available in 8, 16, 32, and 64-bit variants). One would therefore vantage for join heavy queries due to better hidden memory stalls. expect significant benefits from using SIMD. In the following, we In general, we find that TPC-H subsumes SSB for our purposes and focus on selection and hash table probing, which are both common in the name of conciseness, we present our findings using TPC-H and important operations. in the rest of this paper. 5.1 Data-Parallel Selection 4.5 Tectorwise/Typer vs. VectorWise/HyPer A vectorized selection primitive produces a selection vector con- Let us close this section taining the indexes of all matching tuples. Using AVX-512 this can Table 2: Production Systems by comparing Actian Vec- be implemented using SIMD quite easily6 . The comparison in- tor 5.0 (the current market- struction generates a mask that we then pass to a compress store HyPer VW Typer TW ing name for VectorWise) and (COMPRESSSTORE) instruction. This operation works across SIMD the research (TUM) version lanes and writes out the positions selected by the mask to memory. Q1 53 71 44 85 of HyPer (a related system is We performed a micro-benchmark for selection, comparing a Q6 10 21 15 15 now with Tableau). The re- branch-free scalar x86 implementation with a SIMD variant. In the Q3 48 50 47 44 Q9 124 154 126 111 sults are shown in Table 2 use benchmark, we select all elements from an 8192 element integer Q18 224 159 90 154 one thread and TPC-H scale array which are smaller than a constant. Results for a best-case sce- factor 1. The first observation nario, in which all consumed data are 32-bit integers, are present in is that HyPer performs simi- the L1 cache, and the input is a contiguous vector, are shown in Fig- larly to Typer, and Tectorwise’s performance is similar to Vector- ure 6a. The observed performance gain for this micro-benchmark Wise. Second, except for Q65 , either Typer or Tectorwise are is 8.4×. However, as Figure 6c shows, in a realistic query with slightly faster than both production-grade systems. It is unsur- multiple expensive selections like Q6, we only observe a speedup prising given that these must handle complex issues like overflow of 1.4×—even though almost 90% of the processing time is spent checking (that our prototype ignores). in SIMD primitives. Our experiments revealed two effects that ac- count for this discrepancy: sparse data loading due to selection vectors and cache misses due to varying stride. The remainder of 5. DATA-PARALLEL EXECUTION (SIMD) this section discusses these effects. Let us now turn our attention to data-parallel execution using Sparse data loading occurs in all selection primitives except for SIMD operations. There has been extensive research investigat- the first one. From the second selection primitive on, all primi- ing SIMD for database operations [51, 50, 36, 37, 38, 35, 46, 44]. tives receive a selection vector that determines the elements to con- It is not surprising that this research generally assumes a vector- sider for comparison. These elements must be gathered from non- ized execution model. The primitives of vectorized engines consist contiguous memory locations. A comparison of selection primi- of simple tight loops that can be translated to data-parallel code. tives with selection vectors (40% selectivity) is shown in Figure 6b. Though there has been research on utilizing SIMD in data-centric Performance gains in this case range only up to a 2.7× (again for 5 6 HyPer is faster on Q6 than the other systems because it evaluates selections using With AVX2, the selection primitive is non-trivial and either requires a lookup ta- SIMD instructions directly on compressed columns [19]. ble [35, 19, 26] or complex permutation logic based on BMI2 [1]. 2214
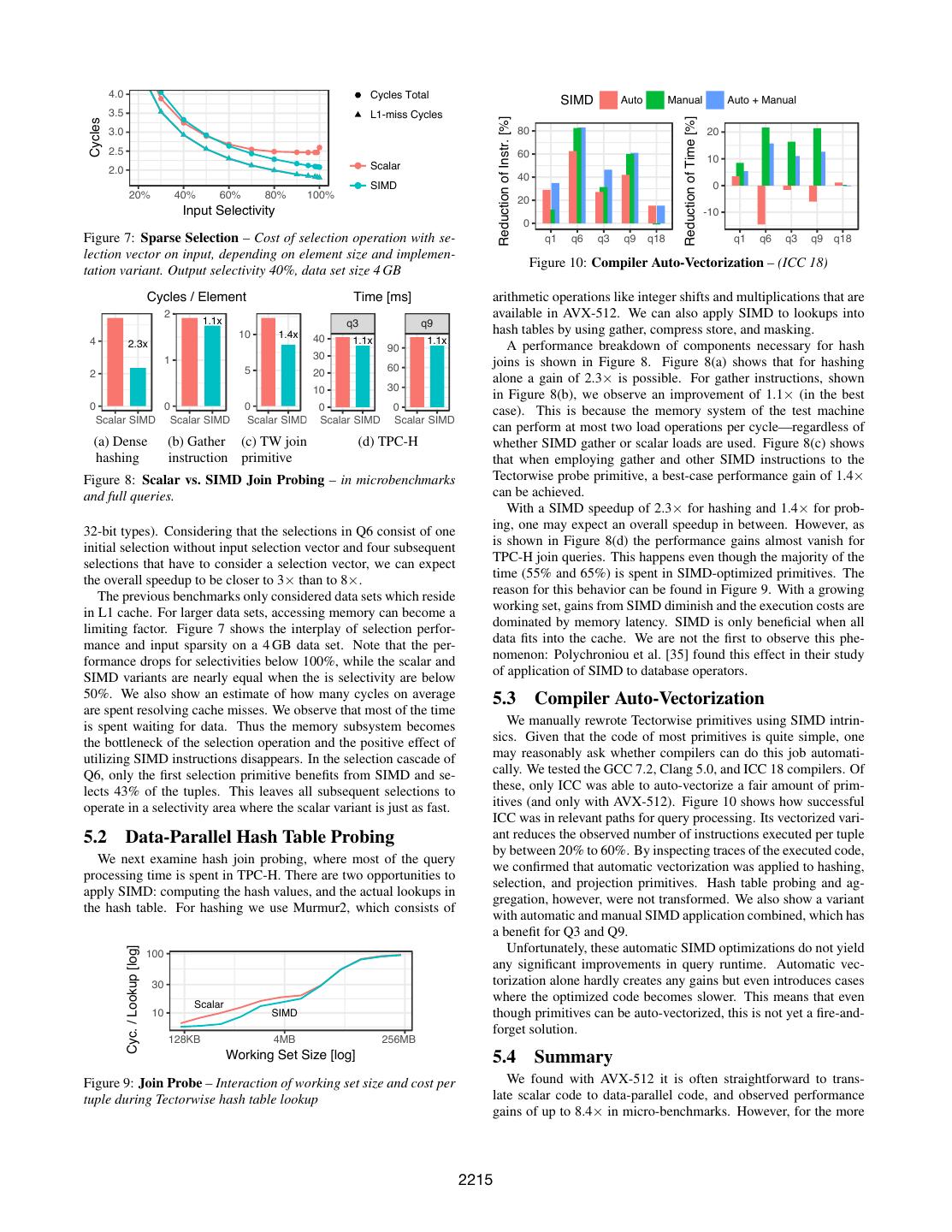
7 . 4.0 Cycles Total SIMD Auto Manual Auto + Manual 3.5 L1-miss Cycles Reduction of Instr. [%] Reduction of Time [%] Cycles 3.0 80 20 2.5 60 10 2.0 Scalar 40 SIMD 0 20% 40% 60% 80% 100% 20 Input Selectivity -10 0 Figure 7: Sparse Selection – Cost of selection operation with se- q1 q6 q3 q9 q18 q1 q6 q3 q9 q18 lection vector on input, depending on element size and implemen- Figure 10: Compiler Auto-Vectorization – (ICC 18) tation variant. Output selectivity 40%, data set size 4 GB Cycles / Element Time [ms] arithmetic operations like integer shifts and multiplications that are 2 1.1x available in AVX-512. We can also apply SIMD to lookups into q3 q9 10 1.4x hash tables by using gather, compress store, and masking. 4 40 1.1x 1.1x 2.3x 90 A performance breakdown of components necessary for hash 1 30 60 joins is shown in Figure 8. Figure 8(a) shows that for hashing 2 5 20 alone a gain of 2.3× is possible. For gather instructions, shown 10 30 in Figure 8(b), we observe an improvement of 1.1× (in the best 0 0 0 0 0 case). This is because the memory system of the test machine Scalar SIMD Scalar SIMD Scalar SIMD Scalar SIMD Scalar SIMD can perform at most two load operations per cycle—regardless of (a) Dense (b) Gather (c) TW join (d) TPC-H whether SIMD gather or scalar loads are used. Figure 8(c) shows hashing instruction primitive that when employing gather and other SIMD instructions to the Figure 8: Scalar vs. SIMD Join Probing – in microbenchmarks Tectorwise probe primitive, a best-case performance gain of 1.4× and full queries. can be achieved. With a SIMD speedup of 2.3× for hashing and 1.4× for prob- 32-bit types). Considering that the selections in Q6 consist of one ing, one may expect an overall speedup in between. However, as initial selection without input selection vector and four subsequent is shown in Figure 8(d) the performance gains almost vanish for selections that have to consider a selection vector, we can expect TPC-H join queries. This happens even though the majority of the the overall speedup to be closer to 3× than to 8×. time (55% and 65%) is spent in SIMD-optimized primitives. The The previous benchmarks only considered data sets which reside reason for this behavior can be found in Figure 9. With a growing in L1 cache. For larger data sets, accessing memory can become a working set, gains from SIMD diminish and the execution costs are limiting factor. Figure 7 shows the interplay of selection perfor- dominated by memory latency. SIMD is only beneficial when all mance and input sparsity on a 4 GB data set. Note that the per- data fits into the cache. We are not the first to observe this phe- formance drops for selectivities below 100%, while the scalar and nomenon: Polychroniou et al. [35] found this effect in their study SIMD variants are nearly equal when the is selectivity are below of application of SIMD to database operators. 50%. We also show an estimate of how many cycles on average 5.3 Compiler Auto-Vectorization are spent resolving cache misses. We observe that most of the time is spent waiting for data. Thus the memory subsystem becomes We manually rewrote Tectorwise primitives using SIMD intrin- the bottleneck of the selection operation and the positive effect of sics. Given that the code of most primitives is quite simple, one utilizing SIMD instructions disappears. In the selection cascade of may reasonably ask whether compilers can do this job automati- Q6, only the first selection primitive benefits from SIMD and se- cally. We tested the GCC 7.2, Clang 5.0, and ICC 18 compilers. Of lects 43% of the tuples. This leaves all subsequent selections to these, only ICC was able to auto-vectorize a fair amount of prim- operate in a selectivity area where the scalar variant is just as fast. itives (and only with AVX-512). Figure 10 shows how successful ICC was in relevant paths for query processing. Its vectorized vari- 5.2 Data-Parallel Hash Table Probing ant reduces the observed number of instructions executed per tuple by between 20% to 60%. By inspecting traces of the executed code, We next examine hash join probing, where most of the query we confirmed that automatic vectorization was applied to hashing, processing time is spent in TPC-H. There are two opportunities to selection, and projection primitives. Hash table probing and ag- apply SIMD: computing the hash values, and the actual lookups in gregation, however, were not transformed. We also show a variant the hash table. For hashing we use Murmur2, which consists of with automatic and manual SIMD application combined, which has a benefit for Q3 and Q9. Unfortunately, these automatic SIMD optimizations do not yield Cyc. / Lookup [log] 100 any significant improvements in query runtime. Automatic vec- 30 torization alone hardly creates any gains but even introduces cases Scalar where the optimized code becomes slower. This means that even 10 SIMD though primitives can be auto-vectorized, this is not yet a fire-and- forget solution. 128KB 4MB 256MB Working Set Size [log] 5.4 Summary Figure 9: Join Probe – Interaction of working set size and cost per We found with AVX-512 it is often straightforward to trans- tuple during Tectorwise hash table lookup late scalar code to data-parallel code, and observed performance gains of up to 8.4× in micro-benchmarks. However, for the more 2215
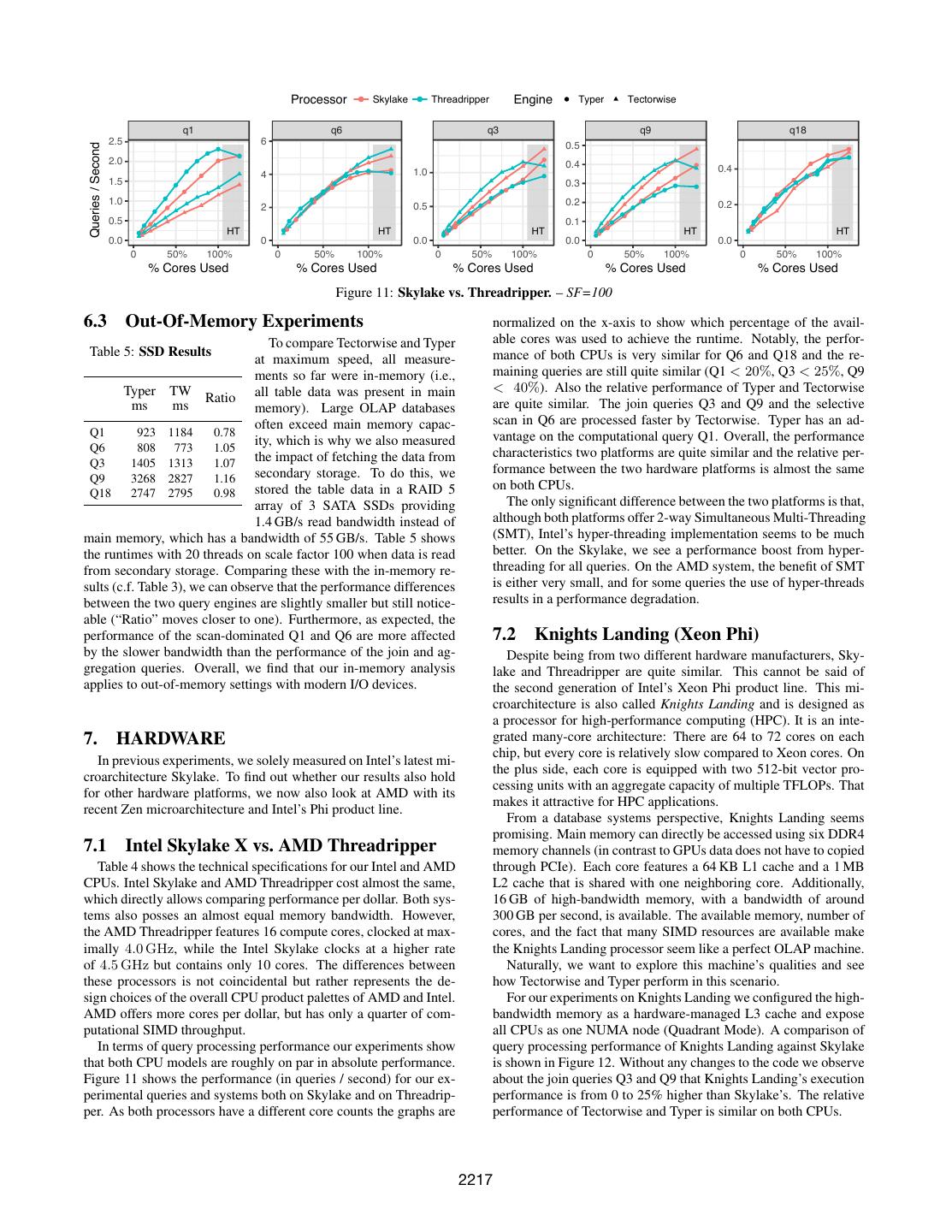
8 .Table 3: Multi-Threaded Execution – TPC-H SF=100 on Skylake Table 4: Hardware Platforms – used in experiments. (10 cores, 20 hyper-threads) Intel AMD Intel Typer Typer TW TW Skylake T.ripper KNL Thr. ms speedup ms speedup Ratio model i9-7900X 1950X Phi 7210 cores (SMT) 10 (x2) 16 (x2) 64 (x4) Q1 1 4426 1.0 7871 1.0 0.56 Q1 10 496 8.9 867 9.1 0.57 issue width 4 4 2 Q1 20 466 9.5 708 11.1 0.66 SIMD [bit] 2×512 2×128 2×512 clock rate [GHz] 3.4-4.5 3.4-4.0 1.2-1.5 Q6 1 1511 1.0 1443 1.0 1.05 Q6 10 243 6.2 213 6.8 1.14 L1 cache 32 KB 32 KB 64 KB Q6 20 236 6.4 196 7.4 1.20 L2 cache 1 MB 1 MB 1 MB LLC 14 MB 32 MB (16 GB) Q3 1 9754 1.0 7627 1.0 1.28 Q3 10 1119 8.7 913 8.4 1.23 list price [$] 989 1000 1881 Q3 20 842 11.6 743 10.3 1.13 launch Q2’17 Q3’17 Q4’16 mem BW [GB/s] 58 56 68 Q9 1 28086 1.0 20371 1.0 1.38 Q9 10 3047 9.2 2394 8.5 1.27 Q9 20 2525 11.1 2083 9.8 1.21 Q18 1 13620 1.0 18072 1.0 0.75 and exclusive resources for every worker. To achieve that the work- Q18 10 2099 6.5 2432 7.4 0.86 ers can work together on one query, every operator can have shared Q18 20 1955 7.0 2026 8.9 0.97 state. For each operator, a single instance of shared state is created. All workers have access to it and use it to communicate. For ex- ample, the shared state for a hash join contains the hash-table for complicated TPC-H queries, the performance gains are quite small the build side and all workers insert tuples into it. In general, the (around 10% for join queries). Fundamentally, this is because most shared state of each operator is used to share results and coordinate OLAP queries are bound by data access, which does not (yet) bene- work distribution. Additionally, pipeline breaking operators use a fit much from SIMD, and not by computation, which is the strength barrier to enforce a global order of sub-tasks. The hash join oper- of SIMD. Coming back to the comparison between data-centric ator uses this barrier to enforce that first all workers consume the compilation and vectorization, we therefore argue that SIMD does build side and insert results into a shared hash table. Only after not shift the balance in favor of vectorization much7 . that, the probe phase of the join can start. With shared state and a barrier, the Tectorwise implementation exhibits the same workload 6. INTRA-QUERY PARALLELIZATION balancing parallelization behavior as Typer. Given the decade-long trends of stagnating single-threaded per- formance and growing number of CPU cores—Intel is selling 28 6.2 Multi-Threaded Execution cores (56 hyper-threads) on a single Xeon chip—any modern query We executed our TPC-H workload on scale factor 100 (ca. 100 GB engine must make good use of all available cores. In the following, of data). Table 3 shows runtimes and speedups in comparison with we discuss how to incorporate parallelism into the two query pro- single-threaded execution. Using the 10 physical cores of our Sky- cessing models. lake CPU, we see speedups between 8× and 9× for Q1, Q3, and Q9 in both systems. Given that modern CPUs reduce clock rates 6.1 Exchange vs. Morsel-Driven Parallelism significantly when multiple threads are used these results are close The original implementations of VectorWise and HyPer use dif- to perfect scalability. For the scan query Q6 the speedup is lim- ferent approaches. VectorWise uses exchange operators [3]. This ited by the available read memory bandwidth, and the large-scale classic approach [13] keeps its query processing operators like ag- aggregation of Q18 approaches the write bandwidth. gregation and join largely unaware of parallelism. HyPer, on the We also conducted these experiments on AWS EC2 machines other hand, uses morsel-driven parallelism, in which joins and ag- and found that both systems scale equally well. However, we ob- gregations use shared hash-tables and are explicitly aware of paral- serve that when we use a larger EC2 instance to speed up query ex- lelism. This allows HyPer to achieve better locality, load-balancing, ecution, the price per query rises. For example, the geometric mean and thus scalability, than VectorWise [22]. Using the 20 hyper- over our TPC-H queries for a m5.2xlarge instance with 8 vCPUs is threads on our 10-core CPU, we measured an average speedup 0.0002$ per query (2027 ms runtime). On an instance with 48 cores on the five TPC-H queries of 11.7× in HyPer, but only 7.2× in it is 0.00034$ per query (534 ms runtime). So in this case, running VectorWise. The parallelization framework is, however, orthogonal queries 4× faster costs 1.7× more. to the query processing model and we implemented morsel-driven Tectorwise and Typer have similar scaling behavior. Neverthe- parallelization in both Tectorwise and Typer, as it has been shown less, the “Ratio” column of Table 3, which is the quotient of the to scale better than exchange operators [22]. runtimes of both systems, reveals an interesting effect: For all but Morsel-driven parallelism was developed for HyPer [22] and can one query, the performance gap between the two systems becomes therefore be implemented quite straightforwardly in Typer: The smaller when all 20 hyper-threads are used8 . For the join queries table scan loop is replaced with a parallel loop and shared data Q3 and Q9, the performance benefit of Tectorwise is cut in half, and structures like hash tables are appropriately synchronized similar Tectorwise comes closer to Typer for Q1 and Q18. This indicates to HyPer’s implementation [22, 23]. that hyper-threading is effective at hiding some of the downsides of For Tectorwise, it is less obvious how to use morsel-driven par- microarchitecturally sub-optimal code. allelism. The runtime system of Tectorwise creates an operator tree 8 Q6 is memory bound and is the only exception. Typer’s branch- 7 free selection implementation consumes more memory bandwidth We note that the benefit of SIMD can be larger when data is compressed [19] and on vector-oriented CPUs like Xeon Phi (see Section 7). resulting in 20% lower performance at high thread counts. 2216
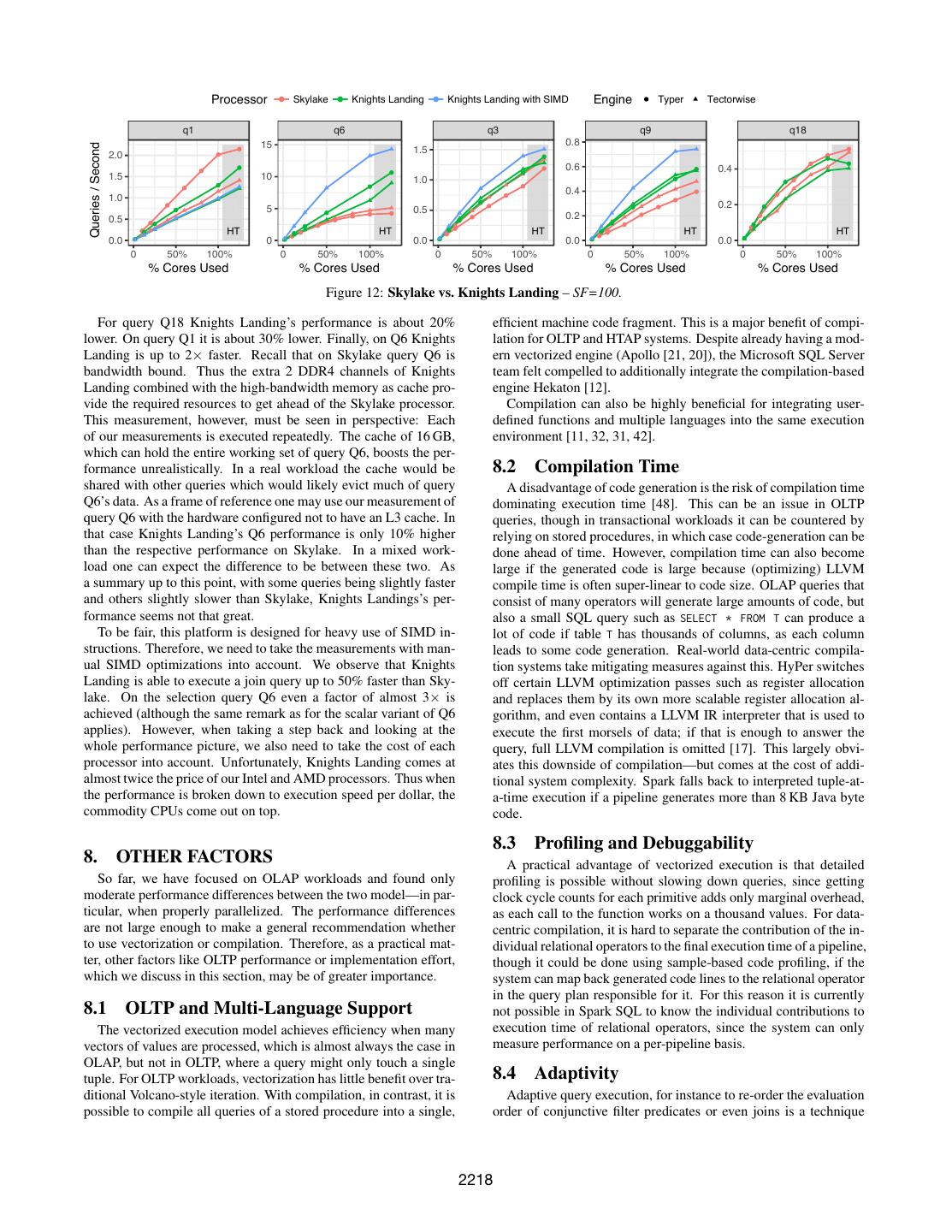
9 . Processor Skylake Threadripper Engine Typer Tectorwise q1 q6 q3 q9 q18 2.5 6 0.5 Queries / Second 2.0 0.4 1.0 0.4 4 1.5 0.3 1.0 0.2 0.2 2 0.5 0.5 0.1 HT HT HT HT HT 0.0 0 0.0 0.0 0.0 0 50% 100% 0 50% 100% 0 50% 100% 0 50% 100% 0 50% 100% % Cores Used % Cores Used % Cores Used % Cores Used % Cores Used Figure 11: Skylake vs. Threadripper. – SF=100 6.3 Out-Of-Memory Experiments normalized on the x-axis to show which percentage of the avail- To compare Tectorwise and Typer able cores was used to achieve the runtime. Notably, the perfor- Table 5: SSD Results mance of both CPUs is very similar for Q6 and Q18 and the re- at maximum speed, all measure- ments so far were in-memory (i.e., maining queries are still quite similar (Q1 < 20%, Q3 < 25%, Q9 Typer TW Ratio all table data was present in main < 40%). Also the relative performance of Typer and Tectorwise ms ms memory). Large OLAP databases are quite similar. The join queries Q3 and Q9 and the selective often exceed main memory capac- scan in Q6 are processed faster by Tectorwise. Typer has an ad- Q1 923 1184 0.78 vantage on the computational query Q1. Overall, the performance Q6 808 773 1.05 ity, which is why we also measured the impact of fetching the data from characteristics two platforms are quite similar and the relative per- Q3 1405 1313 1.07 secondary storage. To do this, we formance between the two hardware platforms is almost the same Q9 3268 2827 1.16 stored the table data in a RAID 5 on both CPUs. Q18 2747 2795 0.98 array of 3 SATA SSDs providing The only significant difference between the two platforms is that, 1.4 GB/s read bandwidth instead of although both platforms offer 2-way Simultaneous Multi-Threading main memory, which has a bandwidth of 55 GB/s. Table 5 shows (SMT), Intel’s hyper-threading implementation seems to be much the runtimes with 20 threads on scale factor 100 when data is read better. On the Skylake, we see a performance boost from hyper- from secondary storage. Comparing these with the in-memory re- threading for all queries. On the AMD system, the benefit of SMT sults (c.f. Table 3), we can observe that the performance differences is either very small, and for some queries the use of hyper-threads between the two query engines are slightly smaller but still notice- results in a performance degradation. able (“Ratio” moves closer to one). Furthermore, as expected, the performance of the scan-dominated Q1 and Q6 are more affected 7.2 Knights Landing (Xeon Phi) by the slower bandwidth than the performance of the join and ag- Despite being from two different hardware manufacturers, Sky- gregation queries. Overall, we find that our in-memory analysis lake and Threadripper are quite similar. This cannot be said of applies to out-of-memory settings with modern I/O devices. the second generation of Intel’s Xeon Phi product line. This mi- croarchitecture is also called Knights Landing and is designed as a processor for high-performance computing (HPC). It is an inte- 7. HARDWARE grated many-core architecture: There are 64 to 72 cores on each chip, but every core is relatively slow compared to Xeon cores. On In previous experiments, we solely measured on Intel’s latest mi- the plus side, each core is equipped with two 512-bit vector pro- croarchitecture Skylake. To find out whether our results also hold cessing units with an aggregate capacity of multiple TFLOPs. That for other hardware platforms, we now also look at AMD with its makes it attractive for HPC applications. recent Zen microarchitecture and Intel’s Phi product line. From a database systems perspective, Knights Landing seems promising. Main memory can directly be accessed using six DDR4 7.1 Intel Skylake X vs. AMD Threadripper memory channels (in contrast to GPUs data does not have to copied Table 4 shows the technical specifications for our Intel and AMD through PCIe). Each core features a 64 KB L1 cache and a 1 MB CPUs. Intel Skylake and AMD Threadripper cost almost the same, L2 cache that is shared with one neighboring core. Additionally, which directly allows comparing performance per dollar. Both sys- 16 GB of high-bandwidth memory, with a bandwidth of around tems also posses an almost equal memory bandwidth. However, 300 GB per second, is available. The available memory, number of the AMD Threadripper features 16 compute cores, clocked at max- cores, and the fact that many SIMD resources are available make imally 4.0 GHz, while the Intel Skylake clocks at a higher rate the Knights Landing processor seem like a perfect OLAP machine. of 4.5 GHz but contains only 10 cores. The differences between Naturally, we want to explore this machine’s qualities and see these processors is not coincidental but rather represents the de- how Tectorwise and Typer perform in this scenario. sign choices of the overall CPU product palettes of AMD and Intel. For our experiments on Knights Landing we configured the high- AMD offers more cores per dollar, but has only a quarter of com- bandwidth memory as a hardware-managed L3 cache and expose putational SIMD throughput. all CPUs as one NUMA node (Quadrant Mode). A comparison of In terms of query processing performance our experiments show query processing performance of Knights Landing against Skylake that both CPU models are roughly on par in absolute performance. is shown in Figure 12. Without any changes to the code we observe Figure 11 shows the performance (in queries / second) for our ex- about the join queries Q3 and Q9 that Knights Landing’s execution perimental queries and systems both on Skylake and on Threadrip- performance is from 0 to 25% higher than Skylake’s. The relative per. As both processors have a different core counts the graphs are performance of Tectorwise and Typer is similar on both CPUs. 2217
10 . Processor Skylake Knights Landing Knights Landing with SIMD Engine Typer Tectorwise q1 q6 q3 q9 q18 15 0.8 Queries / Second 1.5 2.0 0.6 0.4 1.5 10 1.0 0.4 1.0 5 0.2 0.5 0.5 0.2 HT HT HT HT HT 0.0 0 0.0 0.0 0.0 0 50% 100% 0 50% 100% 0 50% 100% 0 50% 100% 0 50% 100% % Cores Used % Cores Used % Cores Used % Cores Used % Cores Used Figure 12: Skylake vs. Knights Landing – SF=100. For query Q18 Knights Landing’s performance is about 20% efficient machine code fragment. This is a major benefit of compi- lower. On query Q1 it is about 30% lower. Finally, on Q6 Knights lation for OLTP and HTAP systems. Despite already having a mod- Landing is up to 2× faster. Recall that on Skylake query Q6 is ern vectorized engine (Apollo [21, 20]), the Microsoft SQL Server bandwidth bound. Thus the extra 2 DDR4 channels of Knights team felt compelled to additionally integrate the compilation-based Landing combined with the high-bandwidth memory as cache pro- engine Hekaton [12]. vide the required resources to get ahead of the Skylake processor. Compilation can also be highly beneficial for integrating user- This measurement, however, must be seen in perspective: Each defined functions and multiple languages into the same execution of our measurements is executed repeatedly. The cache of 16 GB, environment [11, 32, 31, 42]. which can hold the entire working set of query Q6, boosts the per- formance unrealistically. In a real workload the cache would be 8.2 Compilation Time shared with other queries which would likely evict much of query A disadvantage of code generation is the risk of compilation time Q6’s data. As a frame of reference one may use our measurement of dominating execution time [48]. This can be an issue in OLTP query Q6 with the hardware configured not to have an L3 cache. In queries, though in transactional workloads it can be countered by that case Knights Landing’s Q6 performance is only 10% higher relying on stored procedures, in which case code-generation can be than the respective performance on Skylake. In a mixed work- done ahead of time. However, compilation time can also become load one can expect the difference to be between these two. As large if the generated code is large because (optimizing) LLVM a summary up to this point, with some queries being slightly faster compile time is often super-linear to code size. OLAP queries that and others slightly slower than Skylake, Knights Landings’s per- consist of many operators will generate large amounts of code, but formance seems not that great. also a small SQL query such as SELECT * FROM T can produce a To be fair, this platform is designed for heavy use of SIMD in- lot of code if table T has thousands of columns, as each column structions. Therefore, we need to take the measurements with man- leads to some code generation. Real-world data-centric compila- ual SIMD optimizations into account. We observe that Knights tion systems take mitigating measures against this. HyPer switches Landing is able to execute a join query up to 50% faster than Sky- off certain LLVM optimization passes such as register allocation lake. On the selection query Q6 even a factor of almost 3× is and replaces them by its own more scalable register allocation al- achieved (although the same remark as for the scalar variant of Q6 gorithm, and even contains a LLVM IR interpreter that is used to applies). However, when taking a step back and looking at the execute the first morsels of data; if that is enough to answer the whole performance picture, we also need to take the cost of each query, full LLVM compilation is omitted [17]. This largely obvi- processor into account. Unfortunately, Knights Landing comes at ates this downside of compilation—but comes at the cost of addi- almost twice the price of our Intel and AMD processors. Thus when tional system complexity. Spark falls back to interpreted tuple-at- the performance is broken down to execution speed per dollar, the a-time execution if a pipeline generates more than 8 KB Java byte commodity CPUs come out on top. code. 8.3 Profiling and Debuggability 8. OTHER FACTORS A practical advantage of vectorized execution is that detailed So far, we have focused on OLAP workloads and found only profiling is possible without slowing down queries, since getting moderate performance differences between the two model—in par- clock cycle counts for each primitive adds only marginal overhead, ticular, when properly parallelized. The performance differences as each call to the function works on a thousand values. For data- are not large enough to make a general recommendation whether centric compilation, it is hard to separate the contribution of the in- to use vectorization or compilation. Therefore, as a practical mat- dividual relational operators to the final execution time of a pipeline, ter, other factors like OLTP performance or implementation effort, though it could be done using sample-based code profiling, if the which we discuss in this section, may be of greater importance. system can map back generated code lines to the relational operator in the query plan responsible for it. For this reason it is currently 8.1 OLTP and Multi-Language Support not possible in Spark SQL to know the individual contributions to The vectorized execution model achieves efficiency when many execution time of relational operators, since the system can only vectors of values are processed, which is almost always the case in measure performance on a per-pipeline basis. OLAP, but not in OLTP, where a query might only touch a single tuple. For OLTP workloads, vectorization has little benefit over tra- 8.4 Adaptivity ditional Volcano-style iteration. With compilation, in contrast, it is Adaptive query execution, for instance to re-order the evaluation possible to compile all queries of a stored procedure into a single, order of conjunctive filter predicates or even joins is a technique 2218
11 .for improving robustness that can compensate for (inevitable) esti- Compilation HyPer [28] Peloton [26] mation errors in query optimization. Integrating adaptivity in com- piled execution is very hard; the idea of adaptive execution works best in systems that interpret a query—in adaptive systems they can HyPer + Data Blocks [19] change the way they interpret it during runtime. Vectorized execu- tion is interpreted, and thus amenable for adaptivity. The combina- Sompolski [45] tion of fine-grained profiling and adaptivity allows VectorWise to make various micro-adaptive decisions [39]. Interpretation We saw that VectorWise was faster than Tectorwise on TPC-H System R [25] VectorWise [7] Q1 (see Table 1); this is due to an adaptive optimization in the for- Tuple-at-a-time Vectorization mer, similar to [15], that it not present in the latter. During aggre- gation, the system partitions the input tuples in multiple selection Figure 13: Design space between vectorization and compilation vectors; one for each group-by key. This task only succeeds if there – hybrid models integrate the advantages of the other approach. are few groups in the current vector; if it fails the system exponen- tially backs off from trying this optimization in further vectors. If it during runtime and profiling is easier. Finally, both systems have succeeds, by iterating over all elements in a selection vector, i.e. all their own implementation challenges: Implementing operators with tuples of one group in the vector, hash-based aggregation is turned code generation introduces an additional indirection, whereas vec- into ordered aggregation. Ordered aggregation then performs par- torization comes with a set of constraints on the code, which can tial aggregate calculation, keeping e.g. the sum in a register which be complicated to handle. strongly reduces memory traffic, since updating aggregate values in a hash table for each tuple is no longer required. Rather, the 9. BEYOND BASIC VECTORIZATION AND aggregates are just updated once per vector. DATA-CENTRIC CODE GENERATION 8.5 Implementation Issues 9.1 Hybrid Models Both models are non-trivial to implement. In vectorized exe- Vectorization and data-centric code generation are fundamen- cution the challenge is to separate the functionality of relational tally different query processing models and the applied techniques operators in control logic and primitives such that the primitives are mostly orthogonal. That means that a design space, as visu- are responsible for the great majority of computation time (see alized in Figure 13, exists between them. Many systems combine Section 2.1). In compiled query execution, the database system ideas from both paradigms in order to achieve the “best of both is a compiler and consists of code that generates code, thus it is worlds”. We first describe how vectorization can be used to im- harder to comprehend and debug; especially if the generated code prove the performance of the compilation-based systems HyPer and is quite low-level, such as LLVM IR. To make code generation Peloton, before discussing how compilation can help vectorization. maintainable and extensible, modern compilation systems intro- In contrast to other operators in HyPer, scans of the compressed, duce abstraction layers that simplify code generation [42] and make columnar Data Block format [19] are implemented in template- it portable to multiple backends [32, 31]. For HyPer, some of these heavy C++ using vectorization and without generating any code abstractions have been discussed in the literature [29], while others at runtime. Each attribute chunk (e.g., 216 values) of a Data Block have yet to be published. may use a different compression format (based on the data in that It is worth mentioning that vectorized execution is at some disad- block). Using the basic data-centric compilation model, a scan vantage when sort-keys in order by or window functions are com- would therefore have to generate code for all combinations of ac- posite (consist of multiple columns). Such order-aware operations cessed attributes and compression formats—yielding exponential depend on comparison primitives, but primitives can only be spe- code size growth [19]. Besides compilation time, a second bene- cialized for a single type (in order to avoid code explosion). There- fit of using vectorization-style processing in scans is that it allows fore, such comparisons must be decomposed in multiple primitives, utilizing SIMD instructions where it is most beneficial (Section 5). which requires a (boolean) vector as interface to these multiple Since, Data Blocks is the default storage data format, HyPer (in primitives. This extra materialization costs performance. Com- contrast to Typer) may be considered a hybrid system that uses vec- piled query execution can generate a full sort algorithm specifically torization for base table selections and decompression, and data- specialized to the record format and sort keys at hand. centric code generation for all other operators. 8.6 Summary By default, data-centric code generation fuses all operators of the same pipeline into a single code fragment. This is often ben- As a consequence of their architecture and code structure compi- eficial for performance, as it avoids writing intermediate results lation and vectorization have distinct qualities that are not directly to cache/memory by keeping the attributes of the current row in related to OLAP performance: CPU registers as much as possible. However, there are also cases where it would be better to explicitly break a single pipeline into Lang. Comp. Pro- Adapt- Imple- multiple fragments—for example, in order to better utilize out-of- OLTP Support Time filing ivity mentation order execution and prefetching during a hash join. This is the Comp. ( ) Indirection key insight behind Peloton’s relaxed operator fusion [26] model, Vect. Constraints which selectively introduces explicit materialization boundaries in the generated code. By batching multiple tuples, Peloton can easily On the one hand, compiled queries allow for fast OLTP stored introduce SIMD and software prefetching instructions [26]. Con- procedures and seamlessly integrating different programming lan- sequently, Peloton’s pipelines are shorter and their structure resem- guages. Vectorization, on the other hand, offers very low query bles vectorized code (see Figure 13). If the query optimizer’s de- compile times, as primitives are precompiled: As a result of this cision about whether to break up a pipeline is correct (which is structure, parts of a vectorized query can be swapped adaptively non-trivial [24]), Peloton can be faster than both standard models. 2219
12 . Table 6: Query Processing Models – and pioneering systems. of the reasons it has been adopted by Virtuoso [8]. One downside of the push model is that it is slightly less flexible in terms of con- System Pipelining Execution Year trol flow: A merge-sort, for example, has to fully materialize one System R [25] pull interpretation 1974 input relation. Some systems, mostly notably MonetDB [10], do PushPull [27] push interpretation 2001 not implement pipelining at all—and fully materialize intermediate MonetDB [9] n/a vectorization 1996 results. This simplifies the implementation, but comes at the price VectorWise [7] pull vectorization 2005 of increased main memory bandwidth consumption. Virtuoso [8] push vectorization 2013 In the last decade, compilation emerged as a viable alternative Hique [18] n/a compilation 2010 to interpretation and vectorization. As Table 6 shows, although HyPer [28] push compilation 2011 compilation can be combined with all 3 pipelining approaches, the Hekaton [12] pull compilation 2014 push model is most widespread as it tends to result in more efficient code [47]. One exception is Hekaton [12], which uses pull-based The two previous approaches use vectorization to improve an compilation. An advantage of pull-based compilation is that it au- engine that is principally based on compilation. Conversely, com- tomatically avoids exponential code size growth for operators that pilation can also improve the performance of vectorized systems. call consume more than once. With push-based compilation, an op- Sompolski et al. [45], for example, observed that it is sometimes erator like full outer join that produces result tuples from two dif- beneficial to fuse the loops of two (or more) VectorWise-style prim- ferent places in the source code, must avoid inlining the consumer itives into a single loop—saving materialization steps. This fusion code twice by moving it into a separate function that is called twice. step would require JIT compilation and result in a hybrid approach, thus moving it towards compilation-based systems in Figure 13. However, to the best of our knowledge, this idea has not (yet) been 10. SUMMARY integrated into any system. To our surprise, the performance of vectorized and data-centric Tupleware is a data management system focused on UDFs, specif- compiled query execution is quite similar in OLAP workloads. In ically a hybrid between data-centric and vectorized execution, and the following, we summarize some of our main findings: uses a cost model and UDF-analysis techniques to choose the exe- < Computation: Data-centric compiled code is better at compu- cution method best suited to the task [11]. tationally-intensive queries, as it is able to keep data in registers Apache Impala uses a form of compiled execution, which, in and thus needs to execute fewer instructions. a different way, is also a hybrid with vectorized execution [49]. Rather than fusing relational operators together, they are kept apart, > Parallel data access: Vectorized execution is slightly better in and interface with each other using vectors representing batches of generating parallel cache misses, and thus has some advantage tuples. The Impala query operators are C++ templates, parame- in memory-bound queries that access large hash-tables for ag- terized by tuple-specific functions (data movement, record access, gregation or join. comparison expressions) in, for example, a join. Impala has default = SIMD has lately been one of the prime mechanisms employed slow ADT implementations for these functions. During compila- by hardware architects to increase CPU performance. In theory, tion, the generic ADT function calls are replaced with generated vectorized query execution is in a better position to profit from LLVM IR. The advantages of this approach is that (unit) testing, that trend. In practice, we find that the benefits are small as most debugging and profiling can be integrated easily—whereas the dis- operations are dominated by memory access cost. advantage is that by lack of fusing operators into pipelines makes the Impala code less efficient. = Parallelization: With find that with morsel-driven parallelism both vectorized and compilation based-engines can scale very 9.2 Other Query Processing Models well on multi-core CPUs. Vectorization and data-centric compilation are the two state-of- = Hardware platforms: We performed all experiments on Intel the-art query processing paradigms used by most modern systems, Skylake, Intel Knights Landing, and AMD Ryzen. The effects and have largely superseded the traditional pull-based iterator model, listed above occur on all of the machines and neither vector- which effectively is an interpreter. Nevertheless, there are also ization nor data-centric compilation dominates on any hardware other (more or less common) models. Before discussing the strengths platform. and weaknesses of these alternative approaches, we taxonomize them in Table 6. We classify query processing paradigms regarding Besides OLAP performance, other factors also play an important (1) how/whether pipelining is implemented, and (2) how execution role. Compilation-based engines have advantages in is performed. Pipelining can be implemented either using the pull (next) interface, the push (produce/consume) interface, or not at all < OLTP as they can create fast stored procedures and (i.e., full materialization after each operator). Orthogonally to the < language support as they can seamlessly integrate code written pipelining dimension, we use the execution method (interpreted, in different languages. vectorized, or compilation-based) as the second classification cri- terion. Thus, in total there are 9 configurations, and, as Table 6 Vectorized engines have advantages in terms of shows, 8 of these have actually been used/proposed. > compile time as primitives are pre-compiled, Since System R, most database systems avoided materializing intermediate results using pull-based iteration. The push model be- > profiling as runtime can be attributed to primitives, and came prominent as a model for compilation, but has also been used > adaptivity as execution primitives can be swapped mid-flight. in vectorized and interpreted engines. One advantage of the push model is that it enables DAG-structured query plans (as opposed Acknowledgements. This work was partially funded by the DFG to trees), i.e., an operator may push its output to more than one grant KE401/22-1. We would like to thank Orri Erling for explain- consumer [27]. Push-based execution also has advantages in dis- ing Virtuoso’s vectorized push model and the anonymous reviewers tributed query processing with Exchange operators, which is one for their valuable feedback. 2220
13 .11. REFERENCES [20] P. Larson, C. Clinciu, C. Fraser, E. N. Hanson, M. Mokhtar, M. Nowakiewicz, V. Papadimos, S. L. Price, S. Rangarajan, R. Rusanu, and M. Saubhasik. Enhancements to SQL Server [1] https://stackoverflow.com/questions/36932240/ column stores. In SIGMOD, pages 1159–1168, 2013. avx2-what-is-the-most-efficient-way-to-pack- [21] P. Larson, C. Clinciu, E. N. Hanson, A. Oks, S. L. Price, left-based-on-a-mask, 2016. S. Rangarajan, A. Surna, and Q. Zhou. SQL Server column [2] S. Agarwal, D. Liu, and R. Xin. Apache Spark as a compiler: store indexes. In SIGMOD, pages 1177–1184, 2011. Joining a billion rows per second on a laptop. [22] V. Leis, P. Boncz, A. Kemper, and T. Neumann. ”https://databricks.com/blog/2016/05/23/apache- Morsel-driven parallelism: A NUMA-aware query spark-as-a-compiler-joining-a-billion-rows-per- evaluation framework for the many-core age. In SIGMOD, second-on-a-laptop.html”, 2016. pages 743–754, 2014. [3] K. Anikiej. Multi-core parallelization of vectorized query [23] V. Leis, K. Kundhikanjana, A. Kemper, and T. Neumann. execution. Master’s thesis, University of Warsaw and VU Efficient processing of window functions in analytical SQL University Amsterdam, 2010. queries. PVLDB, 8(10):1058–1069, 2015. http://homepages.cwi.nl/∼boncz/msc/2010- [24] V. Leis, B. Radke, A. Gubichev, A. Mirchev, P. Boncz, KamilAnikijej.pdf. A. Kemper, and T. Neumann. Query optimization through [4] R. Appuswamy, A. Anadiotis, D. Porobic, M. Iman, and the looking glass, and what we found running the join order A. Ailamaki. Analyzing the impact of system architecture on benchmark. VLDB Journal, 2018. the scalability of OLTP engines for high-contention [25] R. A. Lorie. XRM - an extended (n-ary) relational memory. workloads. PVLDB, 11(2):121–134, 2017. IBM Research Report, G320-2096, 1974. ¨ [5] C. Balkesen, J. Teubner, G. Alonso, and M. T. Ozsu. [26] P. Menon, A. Pavlo, and T. Mowry. Relaxed operator fusion Main-memory hash joins on multi-core CPUs: Tuning to the for in-memory databases: Making compilation, underlying hardware. In ICDE, pages 362–373, 2013. vectorization, and prefetching work together at last. PVLDB, [6] P. Boncz, T. Neumann, and O. Erling. TPC-H analyzed: 11(1):1–13, 2017. Hidden messages and lessons learned from an influential [27] T. Neumann. Efficient generation and execution of benchmark. In TPCTC, 2013. DAG-structured query graphs. PhD thesis, University of [7] P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: Mannheim, 2005. Hyper-pipelining query execution. In CIDR, 2005. [28] T. Neumann. Efficiently compiling efficient query plans for [8] P. A. Boncz, O. Erling, and M. Pham. Advances in modern hardware. PVLDB, 4(9):539–550, 2011. large-scale RDF data management. In Linked Open Data - [29] T. Neumann and V. Leis. Compiling database queries into Creating Knowledge Out of Interlinked Data - Results of the machine code. IEEE Data Eng. Bull., 37(1):3–11, 2014. LOD2 Project, pages 21–44. Springer, 2014. [30] S. Padmanabhan, T. Malkemus, R. C. Agarwal, and [9] P. A. Boncz, M. L. Kersten, and S. Manegold. Breaking the A. Jhingran. Block oriented processing of relational database memory wall in MonetDB. Commun. ACM, 51(12):77–85, operations in modern computer architectures. In ICDE, 2008. pages 567–574, 2001. [10] P. A. Boncz, W. Quak, and M. L. Kersten. Monet and its [31] S. Palkar, J. J. Thomas, D. Narayanan, A. Shanbhag, geographic extensions: A novel approach to high R. Palamuttam, H. Pirk, M. Schwarzkopf, S. P. Amarasinghe, performance GIS processing. In EDBT, pages 147–166, S. Madden, and M. Zaharia. Weld: Rethinking the interface 1996. between data-intensive applications. CoRR, abs/1709.06416, [11] A. Crotty, A. Galakatos, K. Dursun, T. Kraska, C. Binnig, 2017. U. C¸etintemel, and S. Zdonik. An architecture for compiling [32] S. Palkar, J. J. Thomas, A. Shanbhag, M. Schwarzkopt, S. P. UDF-centric workflows. PVLDB, 8(12):1466–1477, 2015. Amarasinghe, and M. Zaharia. A common runtime for high [12] C. Freedman, E. Ismert, and P. Larson. Compilation in the performance data analysis. In CIDR, 2017. Microsoft SQL Server Hekaton engine. IEEE Data Eng. [33] J. M. Patel, H. Deshmukh, J. Zhu, H. Memisoglu, N. Potti, Bull., 37(1):22–30, 2014. S. Saurabh, M. Spehlmann, and Z. Zhang. Quickstep: A data [13] G. Graefe. Encapsulation of parallelism in the Volcano query platform based on the scaling-in approach. PVLDB, processing system. In SIGMOD, pages 102–111, 1990. 11(6):663–676, 2018. [14] G. Graefe and W. J. McKenna. The Volcano optimizer [34] H. Pirk, O. Moll, M. Zaharia, and S. Madden. Voodoo - A generator: Extensibility and efficient search. In ICDE, pages vector algebra for portable database performance on modern 209–218, 1993. hardware. PVLDB, 9(14):1707–1718, 2016. [15] T. Gubner and P. Boncz. Exploring query compilation [35] O. Polychroniou, A. Raghavan, and K. A. Ross. Rethinking strategies for JIT, vectorization and SIMD. In IMDM, 2017. SIMD vectorization for in-memory databases. In SIGMOD, [16] T. Kersten. https://github.com/TimoKersten/db- pages 1493–1508, 2005. engine-paradigms, 2018. [36] O. Polychroniou and K. A. Ross. High throughput heavy [17] A. Kohn, V. Leis, and T. Neumann. Adaptive execution of hitter aggregation for modern SIMD processors. In DaMoN, compiled queries. In ICDE, 2018. 2013. [18] K. Krikellas, S. Viglas, and M. Cintra. Generating code for [37] O. Polychroniou and K. A. Ross. Vectorized bloom filters for holistic query evaluation. In ICDE, pages 613–624, 2010. advanced SIMD processors. In DaMoN, 2014. [19] H. Lang, T. M¨uhlbauer, F. Funke, P. Boncz, T. Neumann, and [38] O. Polychroniou and K. A. Ross. Efficient lightweight A. Kemper. Data Blocks: Hybrid OLTP and OLAP on compression alongside fast scans. In DaMoN, 2015. compressed storage using both vectorization and compilation. In SIGMOD, pages 311–326, 2016. 2221
14 .[39] B. Raducanu, P. Boncz, and M. Zukowski. Micro adaptivity in Vectorwise. In SIGMOD, pages 1231–1242, 2013. [40] V. Raman, G. K. Attaluri, R. Barber, N. Chainani, D. Kalmuk, V. KulandaiSamy, J. Leenstra, S. Lightstone, S. Liu, G. M. Lohman, T. Malkemus, R. M¨uller, I. Pandis, B. Schiefer, D. Sharpe, R. Sidle, A. J. Storm, and L. Zhang. DB2 with BLU acceleration: So much more than just a column store. PVLDB, 6(11):1080–1091, 2013. [41] S. Schuh, X. Chen, and J. Dittrich. An experimental comparison of thirteen relational equi-joins in main memory. In SIGMOD, pages 1961–1976, 2016. [42] A. Shaikhha, Y. Klonatos, L. Parreaux, L. Brown, M. Dashti, and C. Koch. How to architect a query compiler. In SIGMOD, pages 1907–1922, 2016. [43] U. Sirin, P. T¨oz¨un, D. Porobic, and A. Ailamaki. Micro-architectural analysis of in-memory OLTP. In SIGMOD, pages 387–402, 2016. [44] E. A. Sitaridi, O. Polychroniou, and K. A. Ross. SIMD-accelerated regular expression matching. In DaMoN, 2016. [45] J. Sompolski, M. Zukowski, and P. A. Boncz. Vectorization vs. compilation in query execution. In DaMoN, pages 33–40, 2011. [46] D. Song and S. Chen. Exploiting SIMD for complex numerical predicates. In ICDE, pages 143–149, 2016. [47] R. Y. Tahboub, G. M. Essertel, and T. Rompf. How to architect a query compiler, revisited. In SIGMOD, pages 307–322, 2018. [48] A. Vogelsgesang, M. Haubenschild, J. Finis, A. Kemper, V. Leis, T. M¨uhlbauer, T. Neumann, and M. Then. Get real: How benchmarks fail to represent the real world. In DBTest, 2018. [49] S. Wanderman-Milne and N. Li. Runtime code generation in Cloudera Impala. IEEE Data Eng. Bull., 37(1):31–37, 2014. [50] T. Willhalm, N. Popovici, Y. Boshmaf, H. Plattner, A. Zeier, and J. Schaffner. SIMD-Scan: Ultra fast in-memory table scan using on-chip vector processing units. PVLDB, 2(1):385–394, 2009. [51] J. Zhou and K. A. Ross. Implementing database operations using SIMD instructions. In SIGMOD, pages 145–156, 2002. [52] M. Zukowski. Balancing Vectorized Query Execution with Bandwidth-Optimized Storage. PhD thesis, University of Amsterdam, 2009. [53] M. Zukowski, S. H´eman, N. Nes, and P. A. Boncz. Super-scalar RAM-CPU cache compression. In ICDE, 2006. 2222
相关推荐
3秒后跳转登录页面
去登陆

