


































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u70/dbms_nosql?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
NoSQL
分享
点赞
12
收藏
3
下载 0
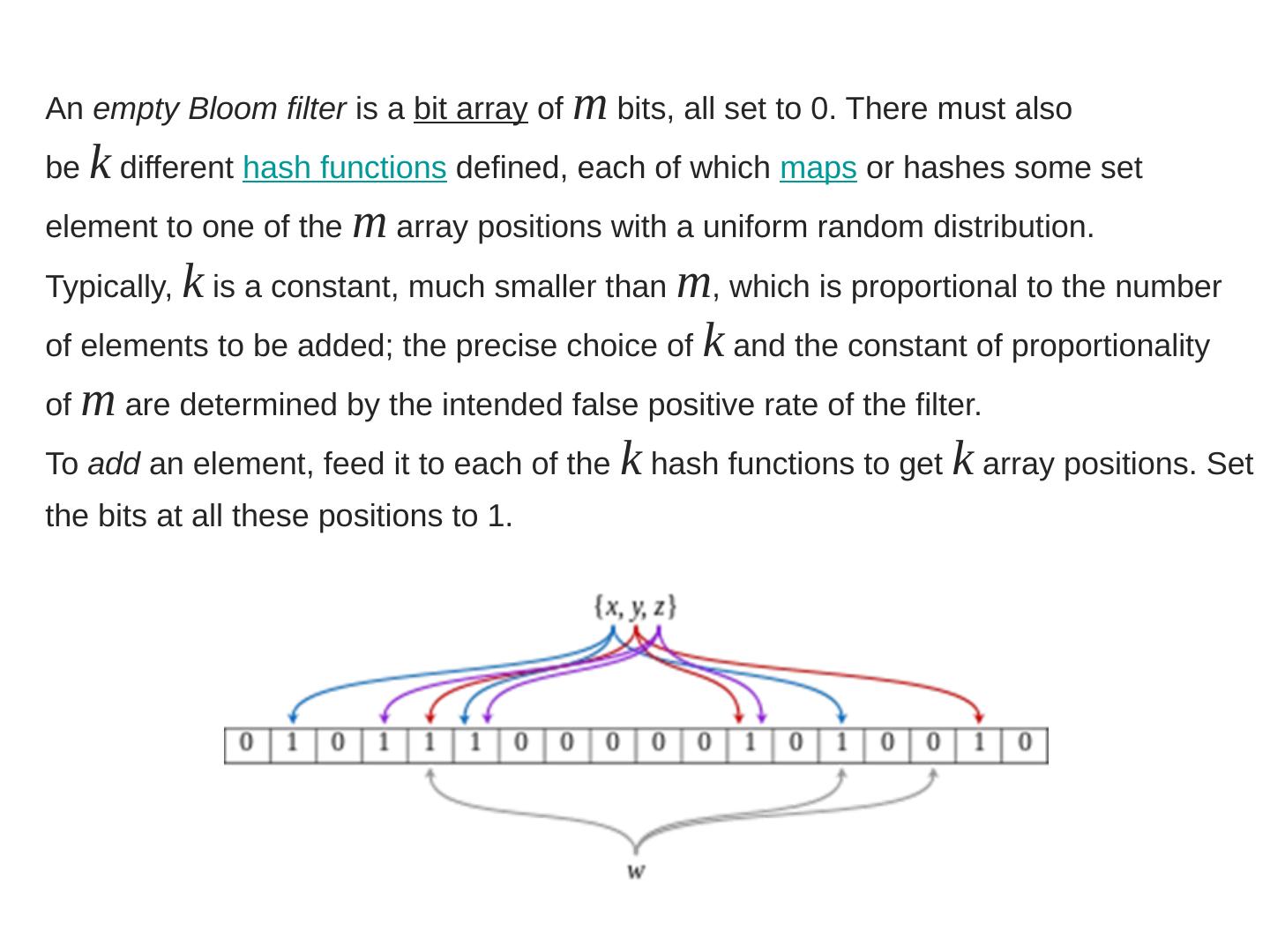
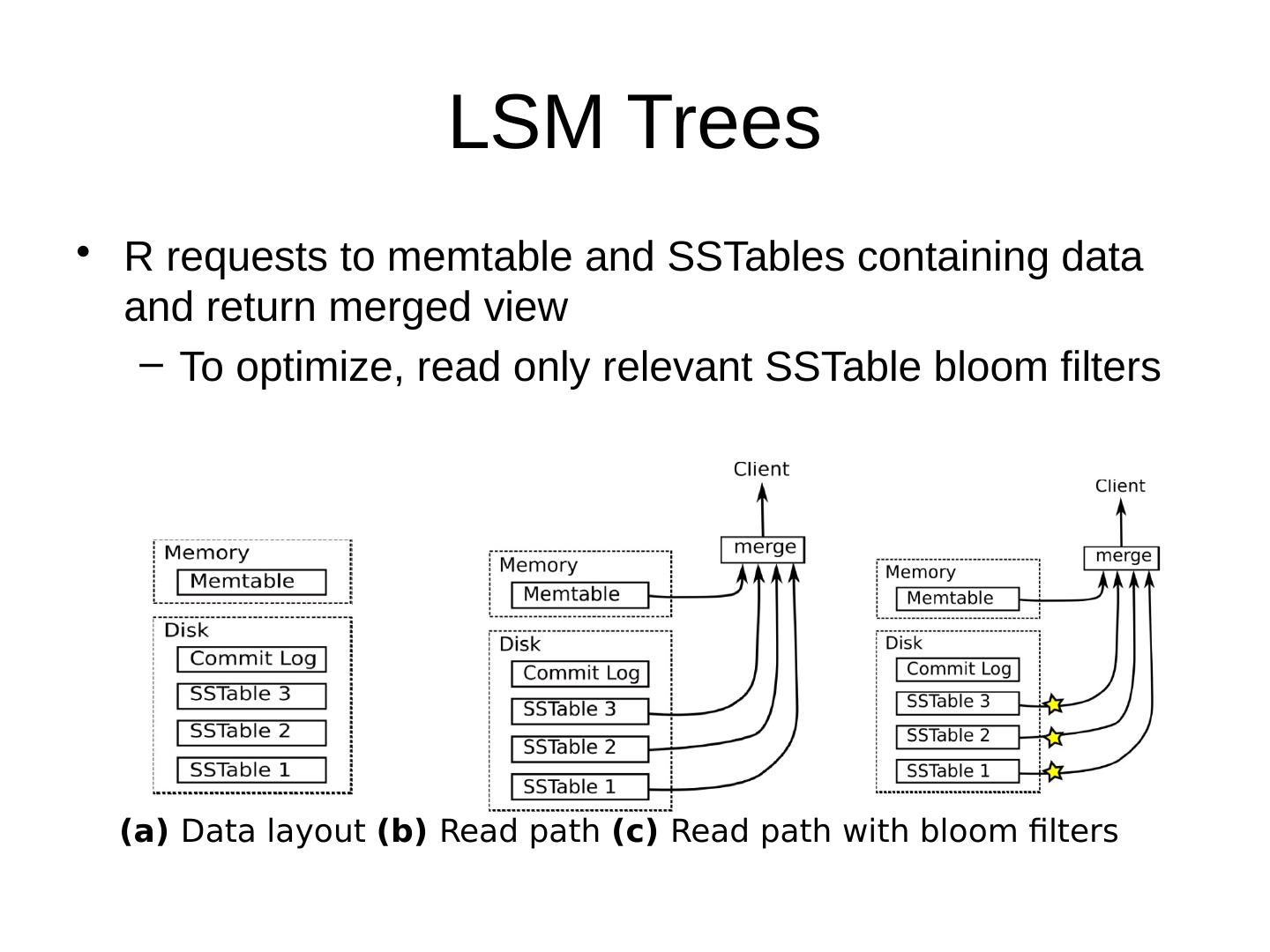
这是小编见过介绍NoSQL最全面的PPT!从传统的关系数据库系统(RDMS)开讲,谈到RDMS的短板,NoSQL诞生的动机,解决的问题根源,再谈到NoSQL系统需要解决的问题和这些问题的解决之道,并点评了当代NoSQL代表(Cassandra/MongoDB/CouchDB)它们各自的特点,以及解决NoSQL问题的方式方法,并从中带出了很多其它新的问题探讨,比如:Column Storage V.S. Row Storage,LSM,文件格式,Sharding的方案,高效过滤器BloomFilter,怎么平衡磁盘和内存存储,当然还要根据存储内容,还要划分为KV-Store,文档存储,列式存储不同应用场景和特点。从分布式上又谈到了分布式一致性的问题,如何动态分片利用一致性哈希(Consistent Hashing)。其中的每一个主题都是一个很值得去钻研,扩展开来又是一个比较大的话题,供大家学习参考,整理自己的知识体系。
展开查看详情
1 .NoSQL Databases C. Strauch
2 .RDBMS RDBMS – dominant Different approaches – Object DBs , XML stores Want same market share as relational Absorbed by relational or niche products One size fits all? Movement – NoSQL does not include those existing before, e.g. object, pure XML
3 .NoSQL Movement Term first used in 1998 For relational that omitted use of SQL Used again in 2009 for non-relational by a Rackspace employee blogger purpose is to seek alternatives to solve problems relational is a bad fit Relational viewed as slow, expensive Startups built own datastores Amazon’s Dynamo, Google Bigtable , Facebook Cassandra Cassandra – write 2500 times faster than MySQL Open source
4 .Benefits of NoSQL NoSQL more efficient? Avoids Complexity Relax ACID properties – consistency Store in memory Higher throughput Column store Scalability, Commodity hardware Horizontal, single server performance, schema design Avoid Expensive Object-relational Mapping Data structures are simpler, e.g. key value store SQL awkward for procedural code Mapping into SQL is only good if repeated manipulations SQL not good if simple db structure
5 .Benefits of NoSQL Complexity/cost of setting up DB clusters Clusters can be expanded without cost and complexity of sharding Compromise reliability for performance Applications willing to compromise May not store in persistent storage One Solution (RDS) for all is wrong Growth of data to be stored Process more data faster Facebook doesn’t need ACID
6 .Myth Myth: Centralized Data models have effortless distribution and partitioning Doesn’t necessarily scale nor work correctly without effort At first, replicate then shard Failures within network different than in a single machine Latency, distributed failures, etc.
7 .Motivation for NoSQL Movement in programming languages and development frameworks Trying to hide the use of SQL Ruby on Rails, Object-relational mappers in Java, completely omit SQL, e.g. Simple DB Requirements of Cloud Computing Ultimate scalability, low administration overhead Data warehousing, key/value stores, additional features to bridge gap with RDBMS
8 .Motivation for NoSQL More motivation of NoSQL Less overhead and memory footprint than RDB Usage of Web technology and RPC calls for access Optional forms of queries
9 .SQL Limitations RDBMS + caching vs. built from scratch scalable systems cache objects in memcached for high read loads Less capable as systems grow RDS place computation on reads instead of avoiding complex reads Serial nature of applications waiting for I/O Large scale data Operating costs of running and maintaining systems (Twitter) Some sites make use of RDBS, but scale more important
10 .SQL Limitations Yesterday’s vs. today’s needs Instead of high end servers, commodity servers that will fail Data no longer rigidly structured RDBs designed for centralized not distributed Synchronization not implemented efficiently, requires 2PC or 3PC
11 .False assumptions False assumptions about distributed computing: Network is reliable latency is 0 bandwidth is infinite network is secure topology doesn’t change one administrator transport cost is 0 network is homogenous Do not try to hide distribution applications
12 .Positives of RDBMS Historical positives of RDBMS: Disk oriented storage and indexing structures Multi threading to hide latency Locking-based concurrency control Log-base recovery
13 .SQL Negatives Requires rewrite because not good for: Text Data warehouses Stream processing Scientific and intelligence databases Interactive transactions Direct SQL interfaces are rare
14 .RDBMS Changes needed Rewrite of RDBMS Main memory – currently disk-oriented solution for main memory problems Disk based recovery log files – impact performance negatively Multi-threading and resource control – Transactions affect only a few data sets, cheap if in memory – if long break up No need for multithreaded execution with elaborate code to minimize CPU and disk usage if in memory
15 .RDBMS Changes needed DBs developed from shared memory to shared disk Today - shared nothing Horizontal partitioning of data over several nodes No need to reload and no downtimes Can transfer parts of data between nodes without impacting running transactions
16 .RDBMS Changes needed Transactions, processing environment Avoid persistent redo-logs Avoid client-server odbc communication, instead run application logic like stored procedures in process Eliminate undo log Reduce dynamic locking Single-threaded execution to eliminate latching and overhead for short transactions 2PC avoided whenever possible – network roundtrips take order of ms
17 .RDBMS Changes needed High Availability and Disaster Recovery Keep multiple replicas consistent Assumed shared nothing at the bottom of system Disperse load across multiple machines (P2P) Inter machine replication for fault tolerance Instead of redo log, just refresh data from operational site Only need undo log in memory that can delete when commit No persistent redo log, just transient undo
18 .RDBMS Changes needed No knobs – Computers were expensive, people cheap Now computers cheap, people expensive But DBA needed to maximize performance (used to have complex tuning knobs)) Need self tuning
19 .Future No one size fits all model No more one size fits all language Ad-hoc queries rarely deployed Instead prepared statements, stored procedures Data warehouses have complex queries not fulfilled by SQL Embed DB capabilities in programming languages E.g. modify Python, Perl, etc.
20 .Types of NoSQL DBs Researchers have proposed many different classification taxonomies We will use: Category Key-value stores Document stores Column Stores
21 .Key-value store Key–value ( k , v ) stores allow the application to store its data in a schema-less way Keys – can be ? Values – objects not interpreted by the system v can be an arbitrarily complex structure with its own semantics or a simple word Good for unstructured data Data could be stored in a datatype of a programming language or an object No meta data No need for a fixed data model
22 .Key-Value Stores Simple data model Map/dictionary Put/request values per key Length of keys limited, few limitations on value High scalability over consistency No complex ad-hoc querying and analytics No joins, aggregate operations
23 .Document Store Next logical step after key-value to slightly more complex and meaningful data structures Notion of a document No strict schema documents must conform to Documents encapsulate and encode data in some standard formats or encodings Encodings include: XML, YAML, and JSON binary forms like BSON, PDF and Microsoft Office documents
24 .Document Store Documents can be organized/grouped as: Collections Tags Non-visible Metadata Directory hierarchies
25 .Document Store Collections – tables documents – records But not all documents in a collection have same fields Documents are addressed in the database via a unique key beyond the simple key-document (or key–value) lookup API or query language allows retrieval of documents based on their contents
26 .Document Store More functionality than key-value More appropriate for semi-structured data Recognizes structure of objects stored Objects are documents that may have attributes of various types Objects grouped into collections Simple query mechanisms to search collections for attribute values
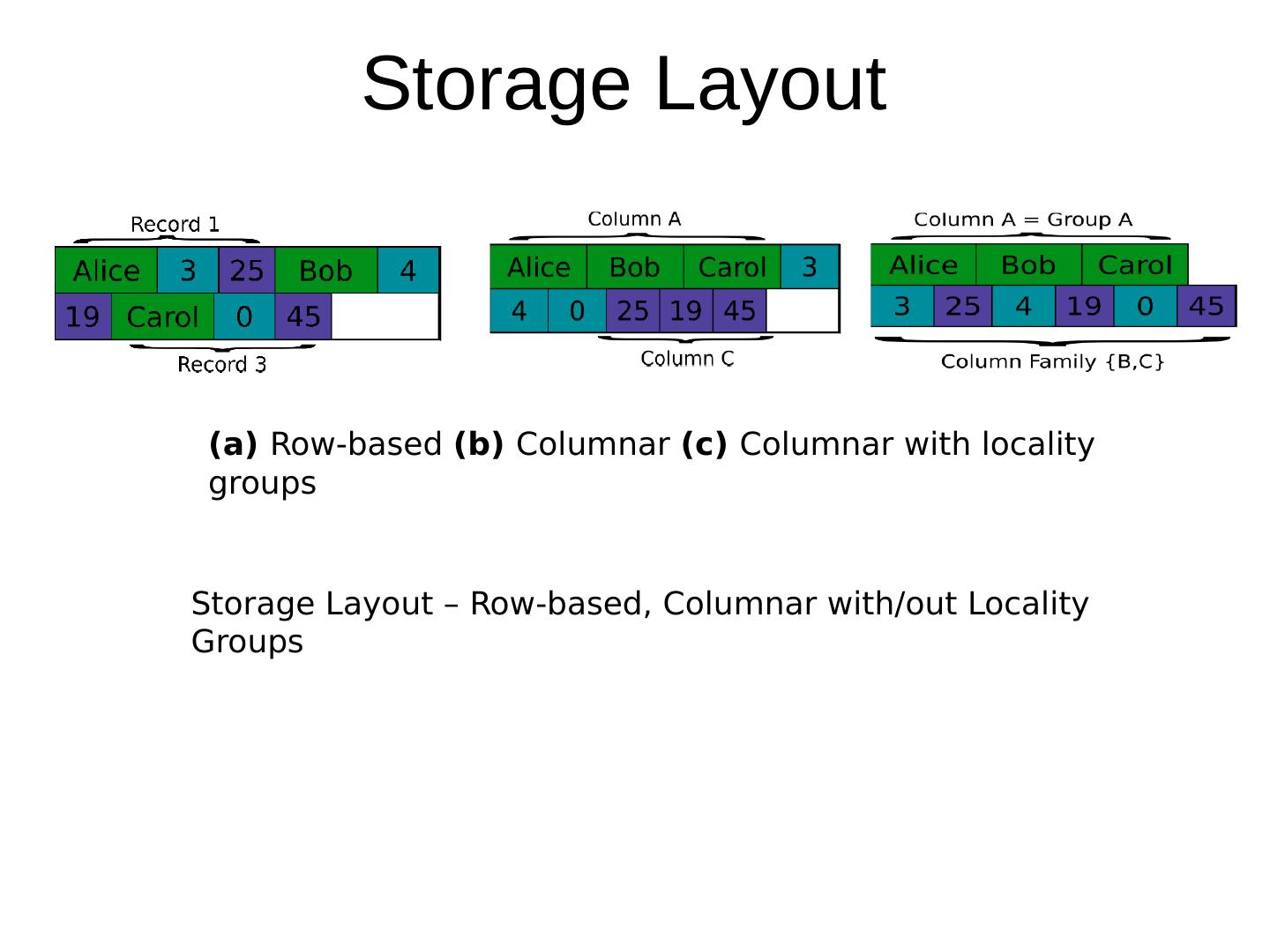
27 .Column Store Stores data tables Column order Relational stores in row order Advantages for data warehouses, customer relationship management (CRM) systems More efficient for: Aggregates, many columns of same row required Update rows in same column Easier to compress, all values same per column
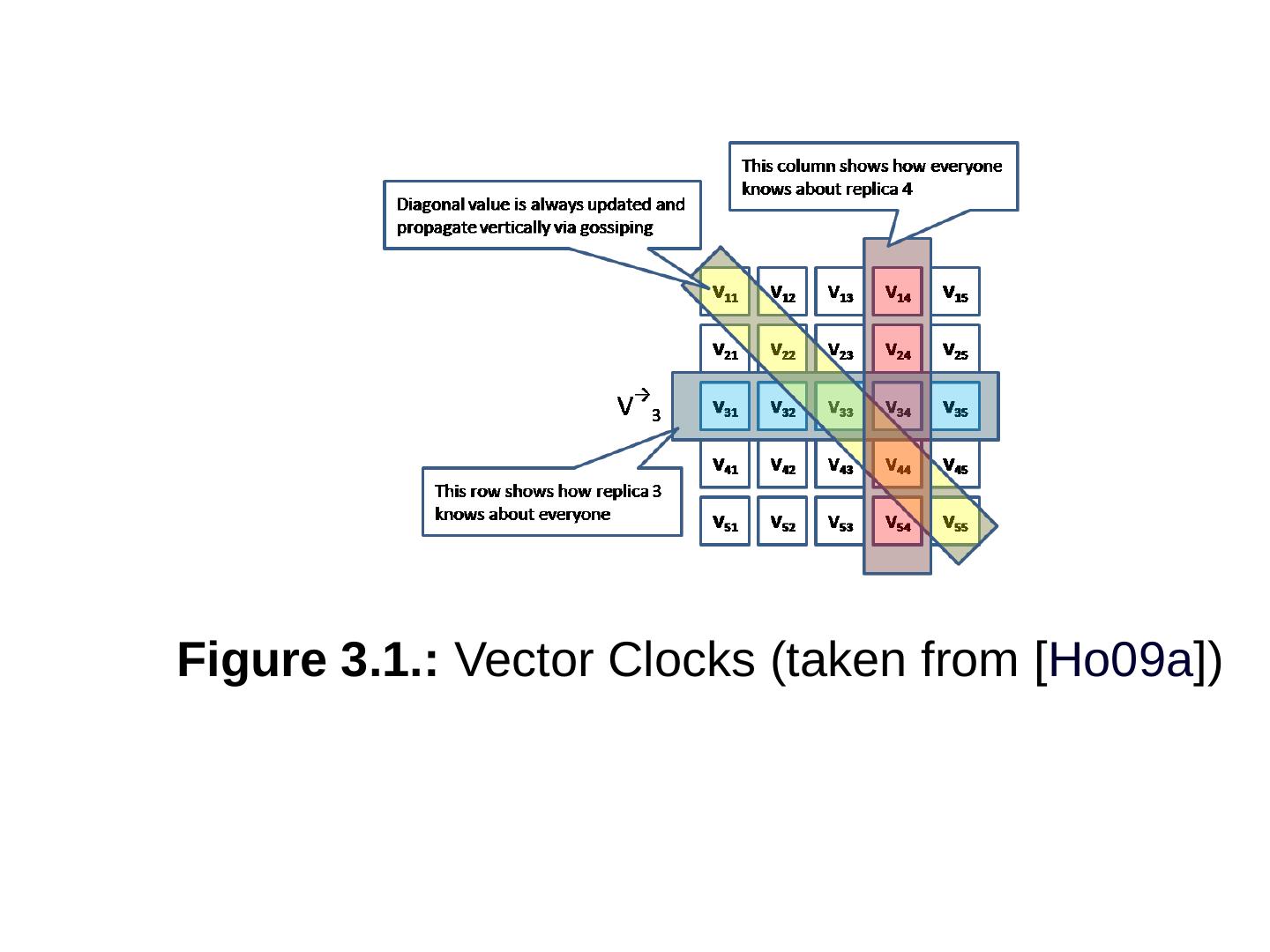
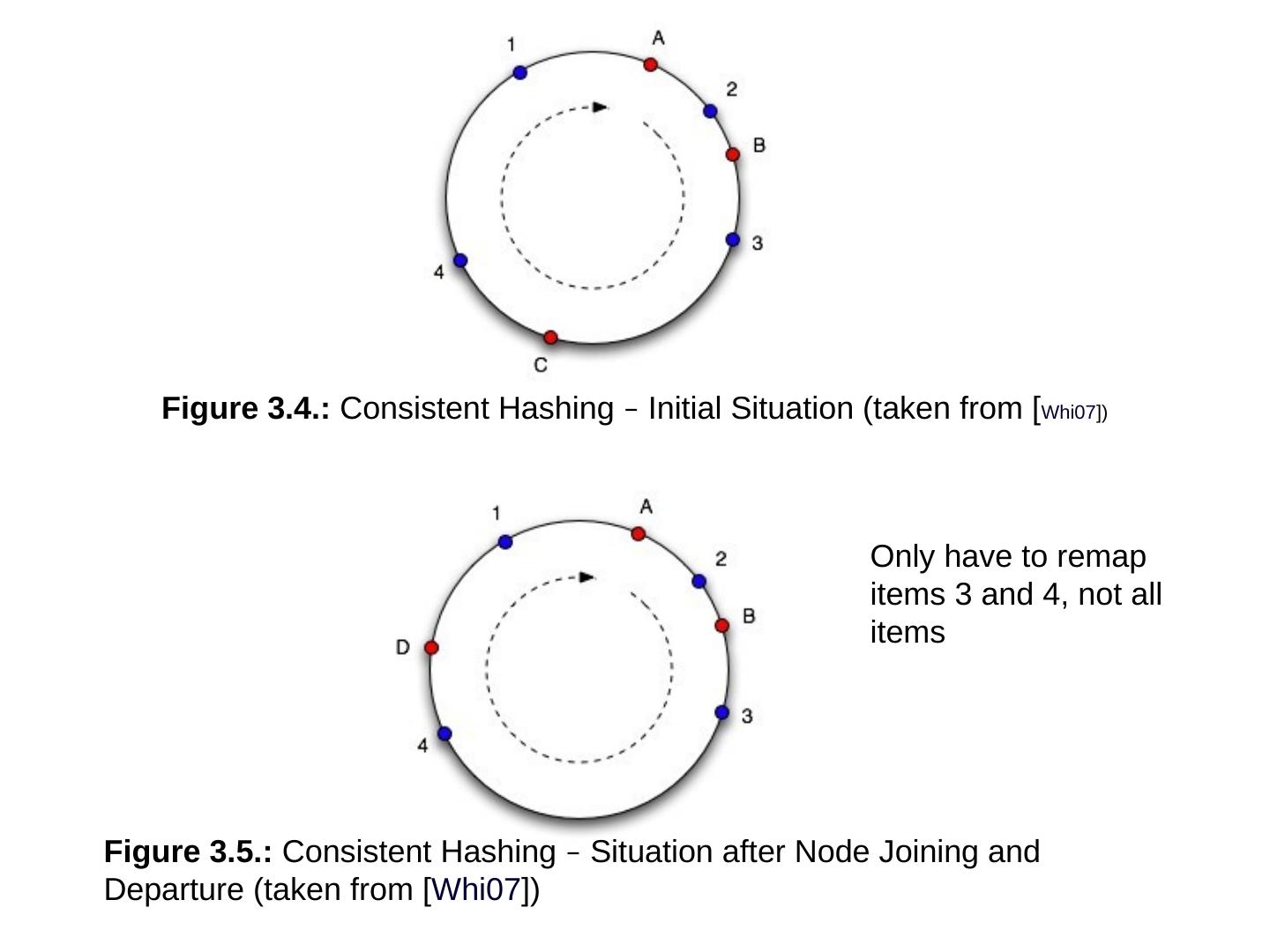
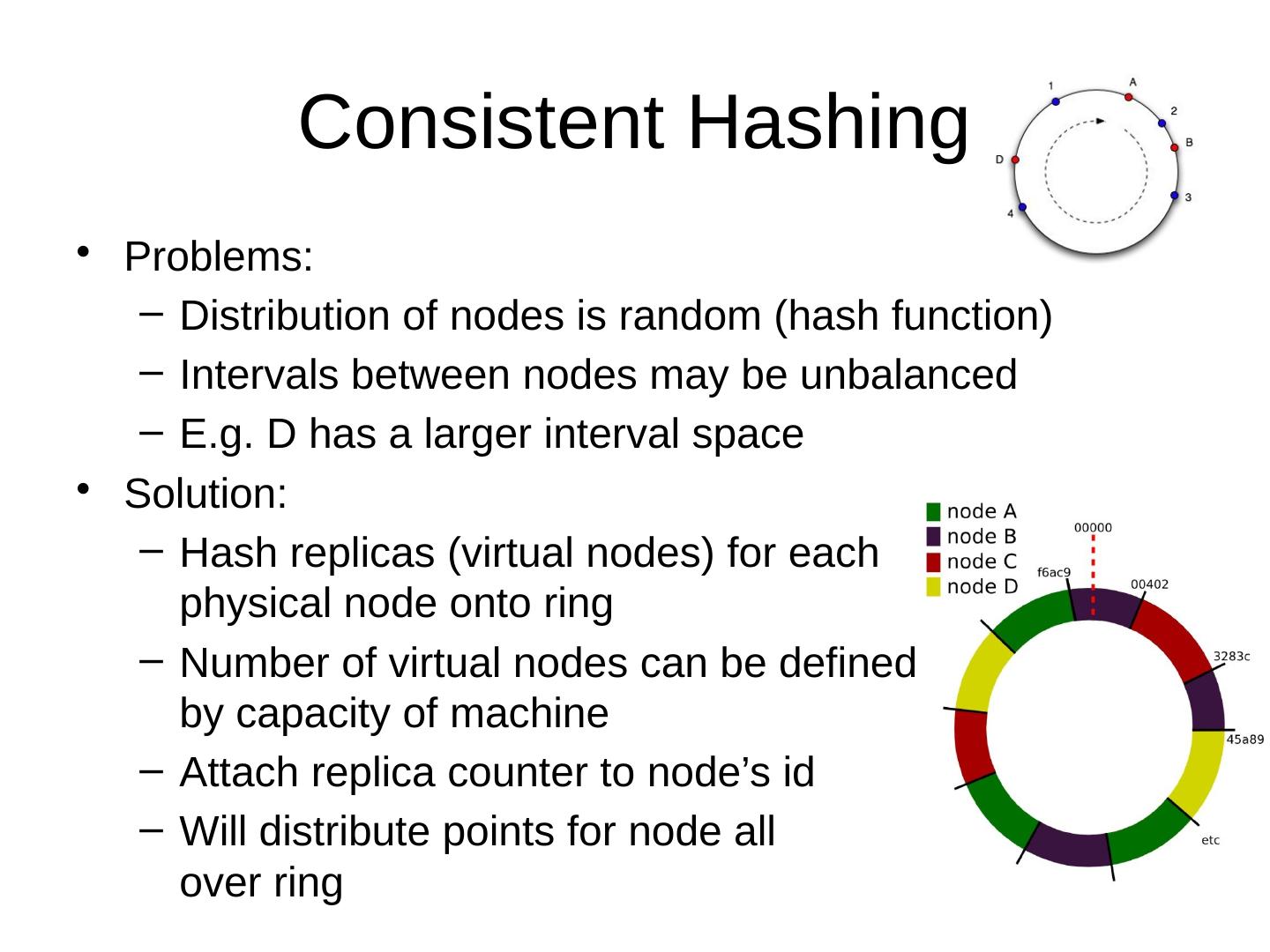
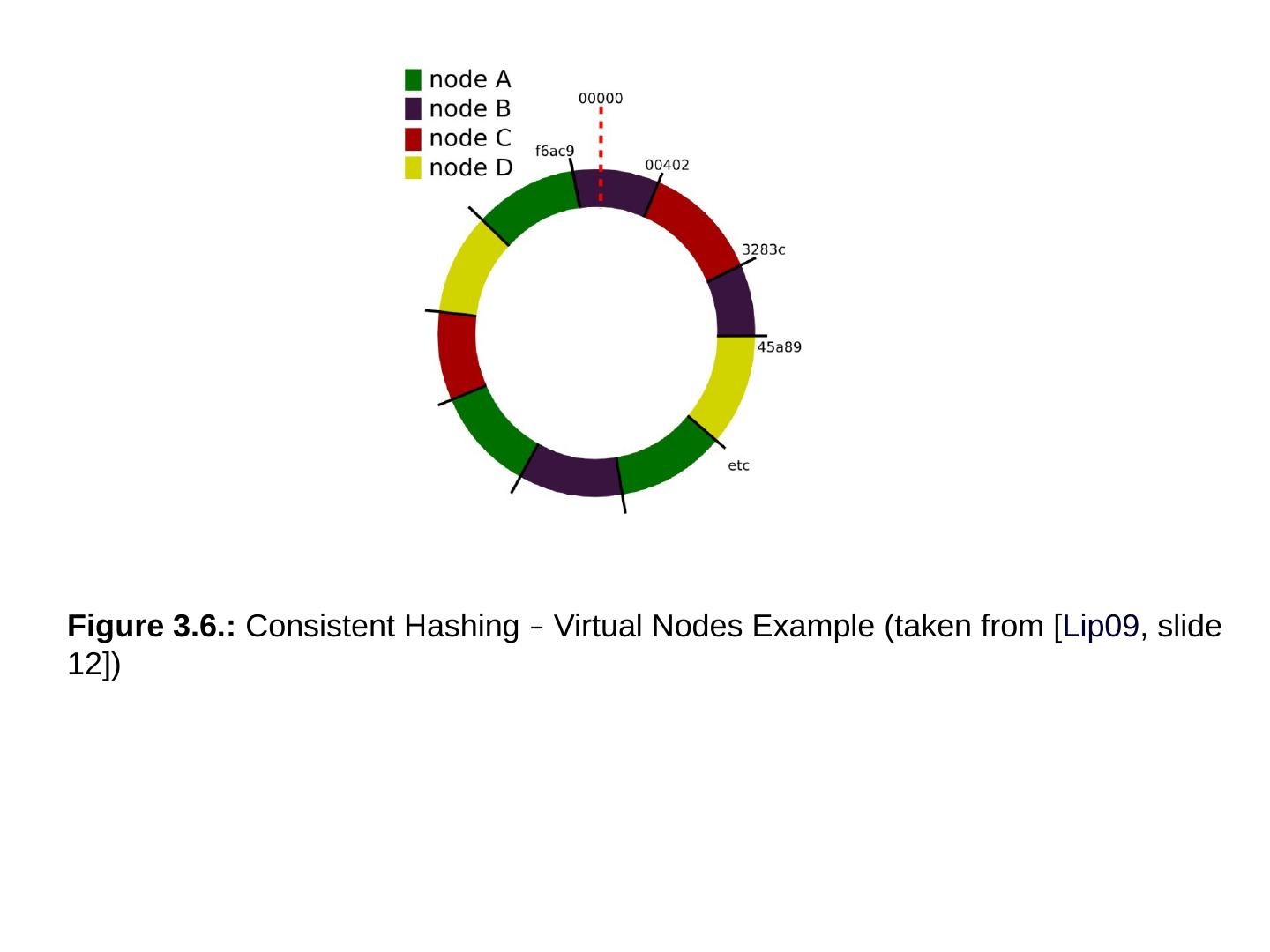
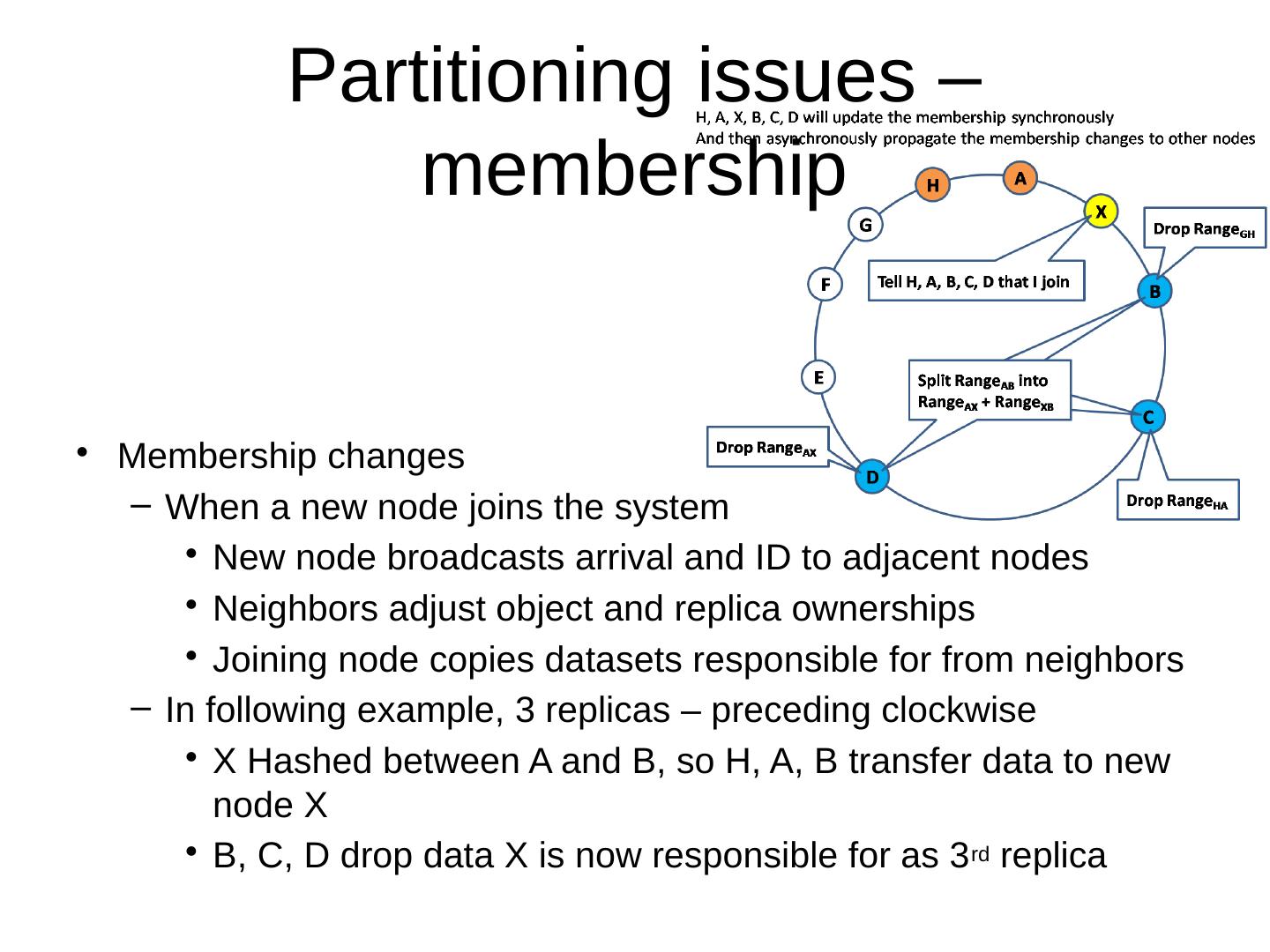
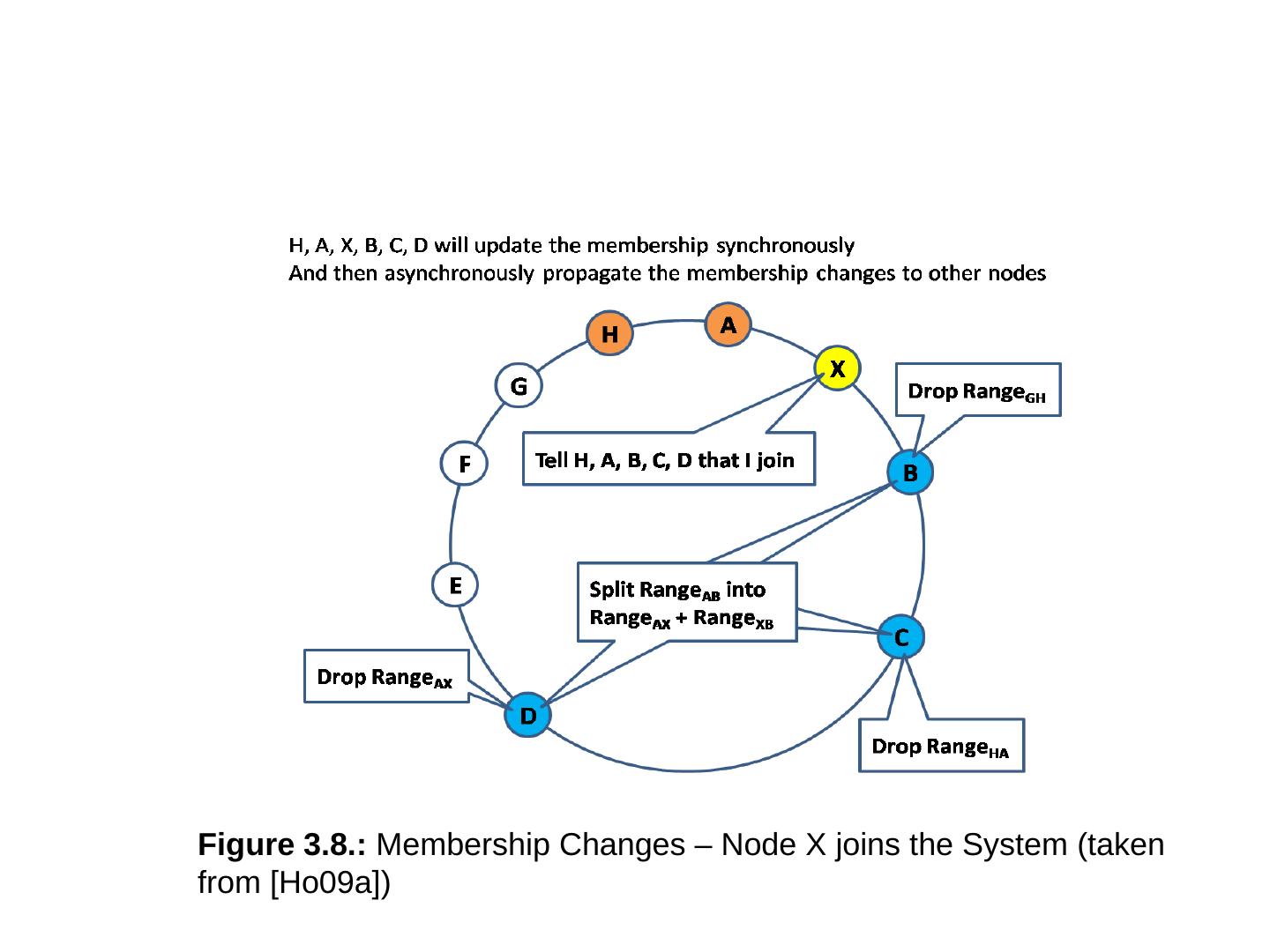
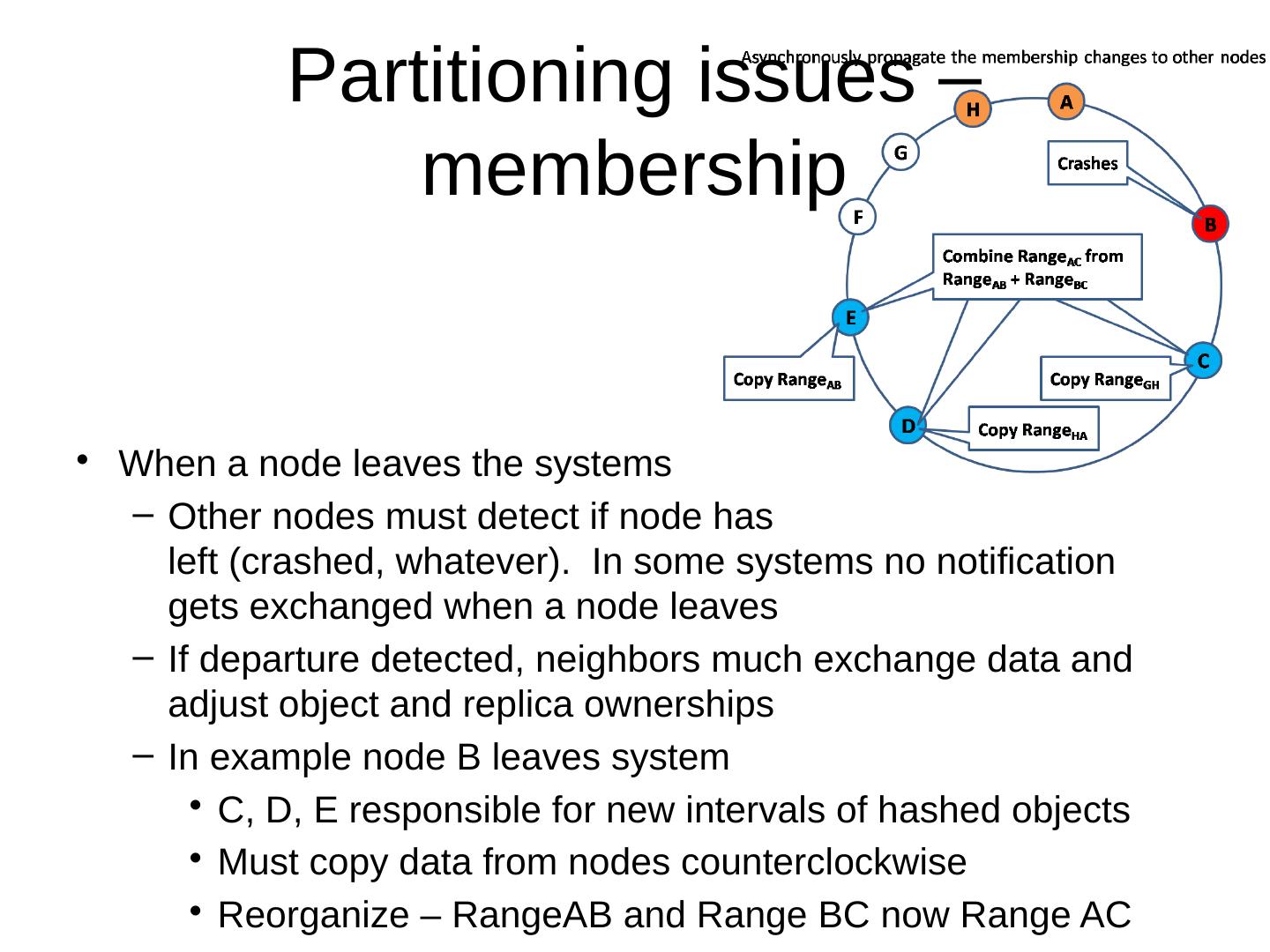
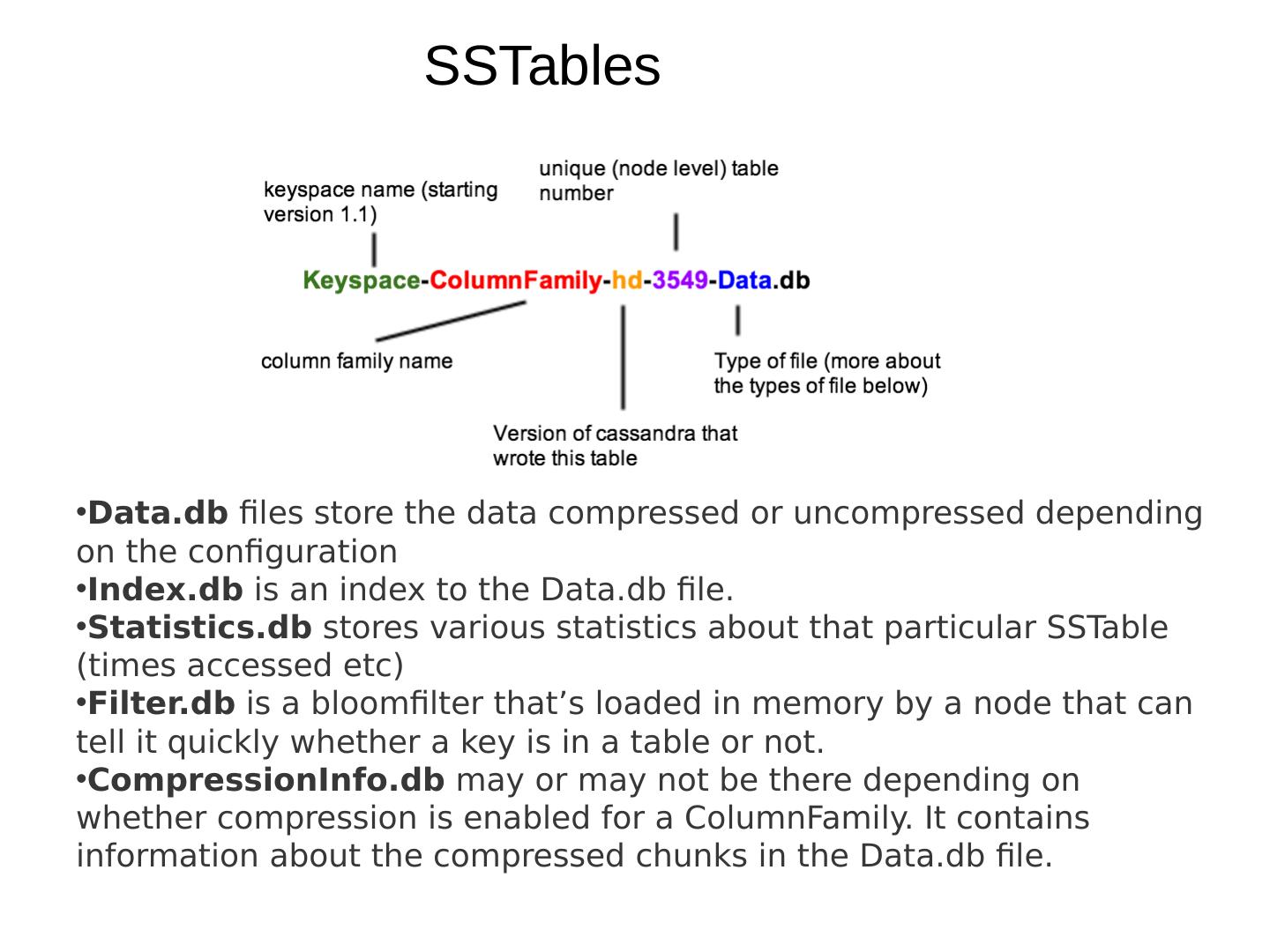
28 .Basic Concepts of NoSQL Distributed issues
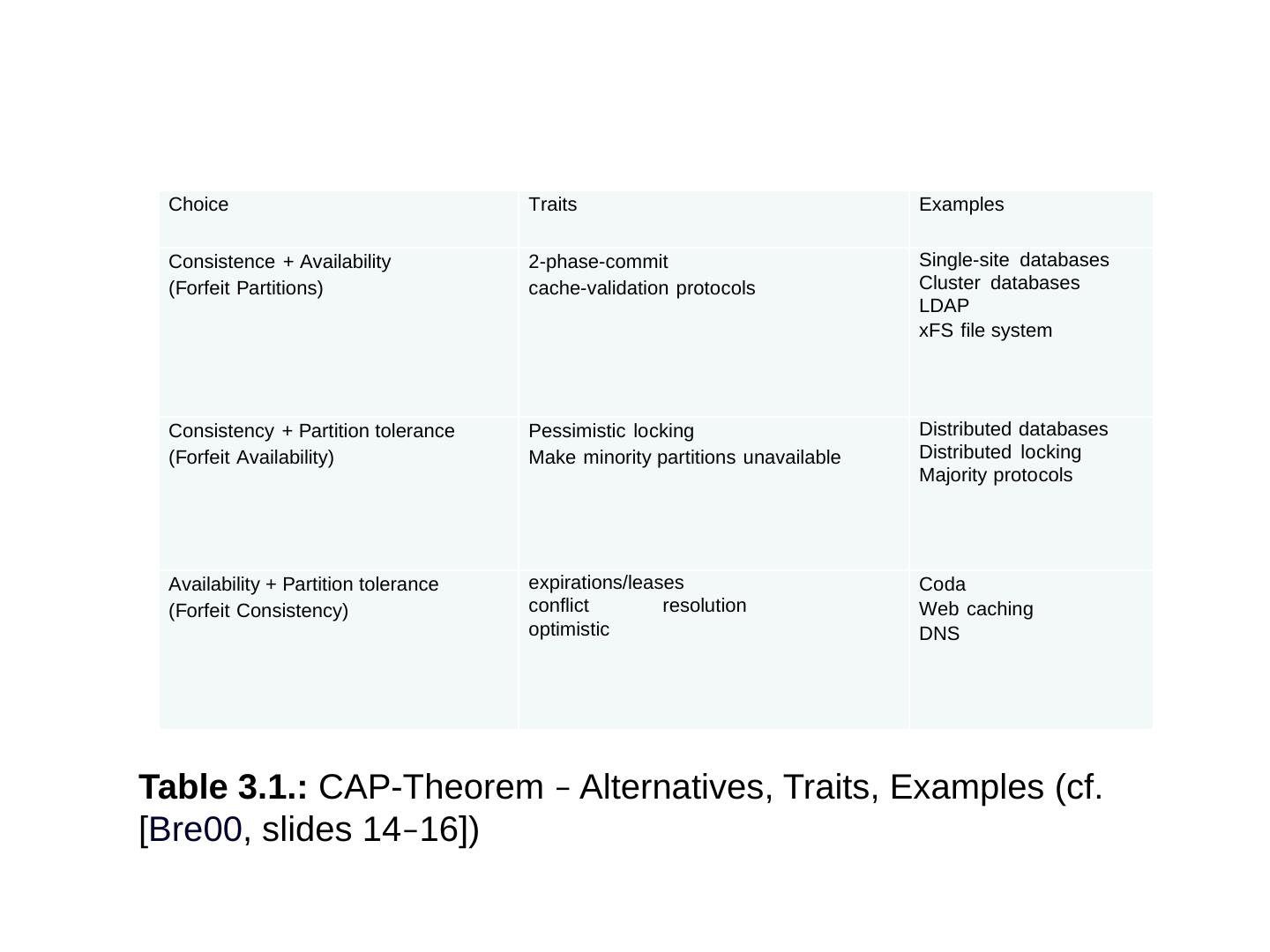
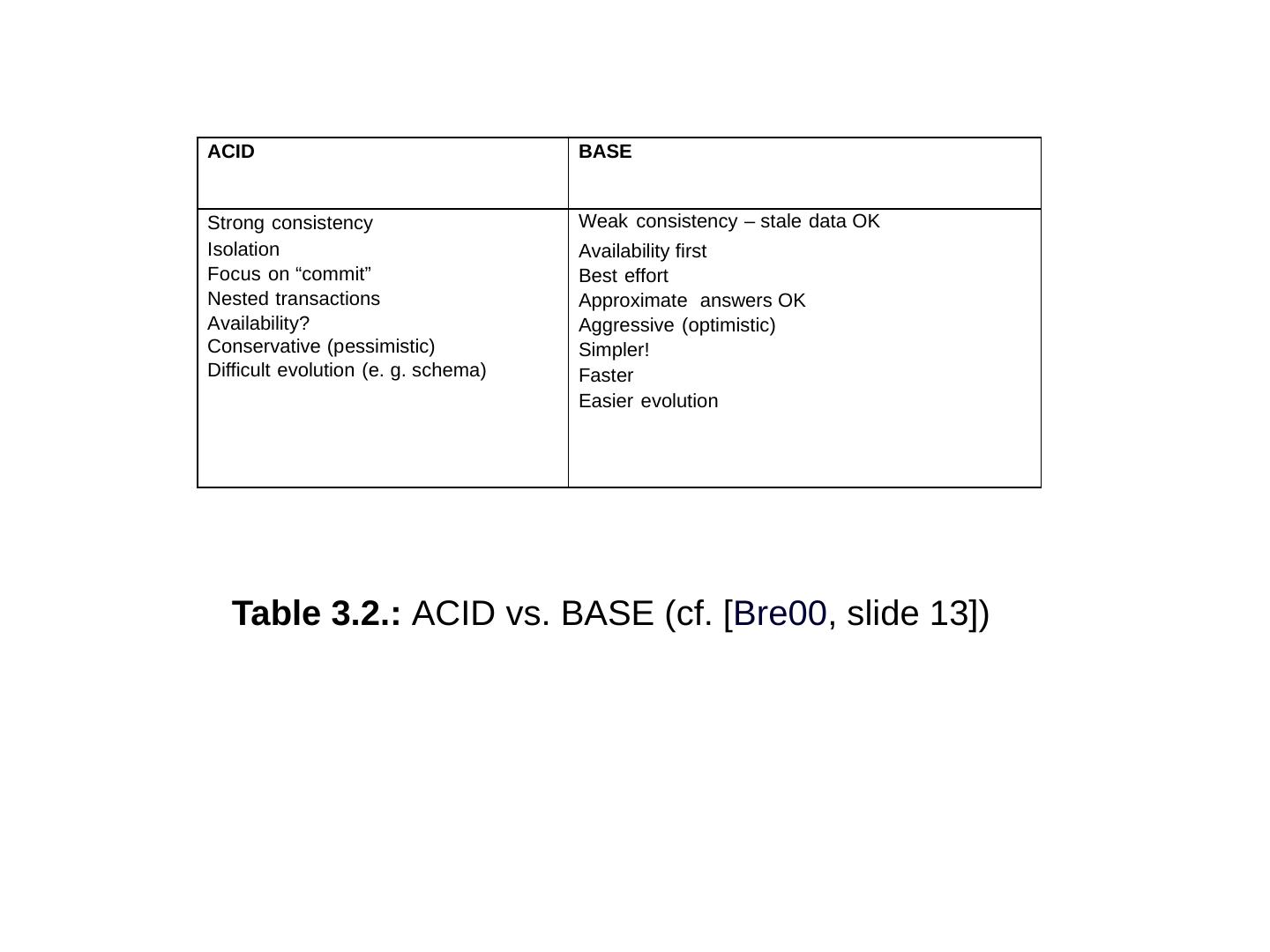
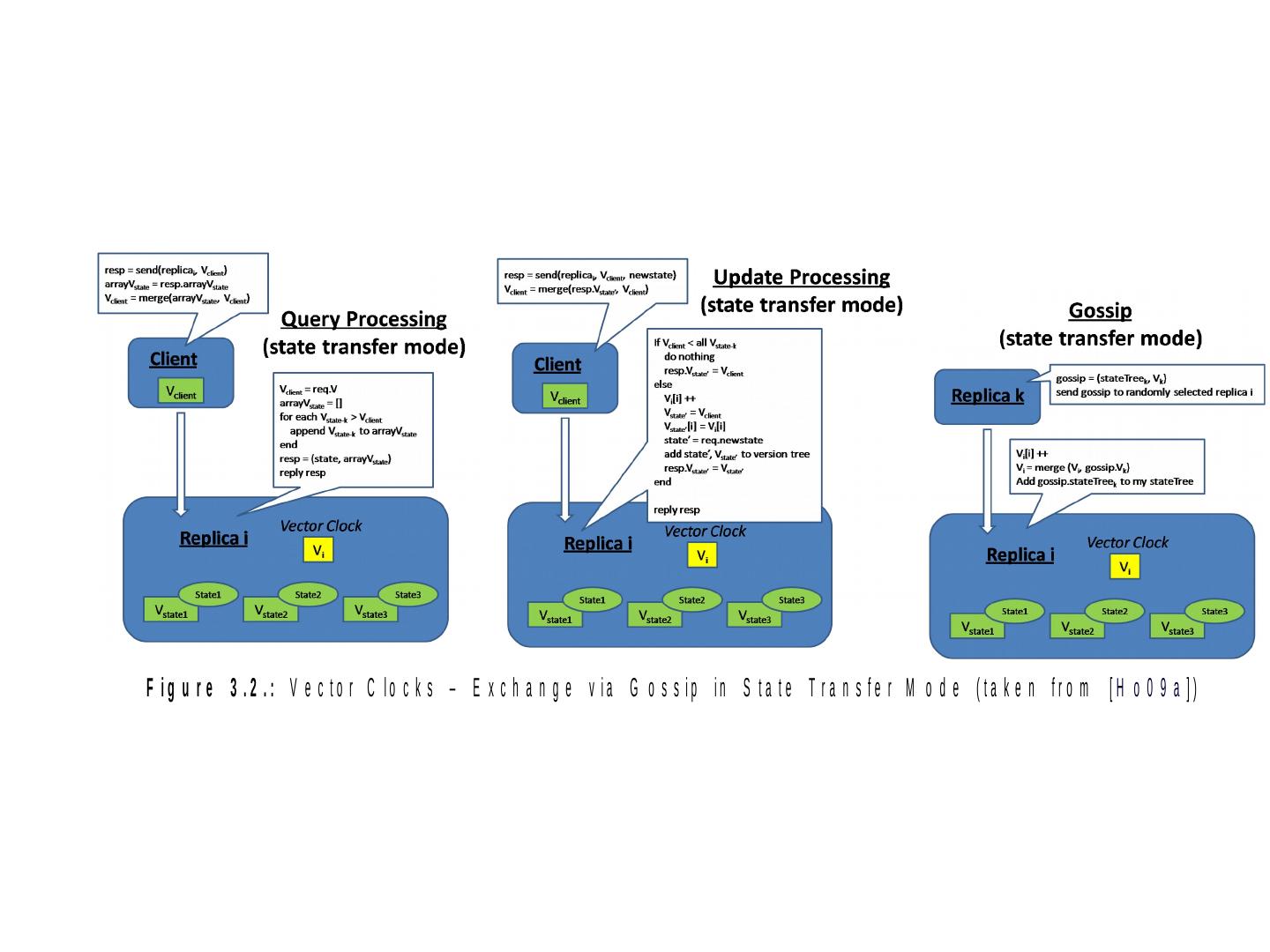
29 .The Usual CAP Table 3.1 ACID vs. BASE Strict and eventual Table 3.2
相关推荐
3秒后跳转登录页面
去登陆

