















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ClickHouse Data Warehouse 101 The First Billion Rows
像Clickhouse这样的专栏商店允许用户在几秒钟内从大数据中提取见解,但前提是设置正确。本文将介绍如何使用著名的NY黄色出租车行驶数据实现包含13亿行的数据仓库。我们将从基本的数据实现开始,包括集群和表定义,然后展示如何有效地加载。接下来,我们将讨论字典和物化视图等重要特性,以及它们如何提高查询效率。最后,我们将演示典型的查询,以说明您可以从设计良好的数据仓库中快速得出的推论。这应该足以让你开始——接下来的十亿行取决于你!
展开查看详情
1 .ClickHouse Data Warehouse 101 The First Billion Rows Alexander Zaitsev and Robert Hodges
2 .About Us Robert Hodges - Altinity CEO Alexander Zaitsev - Altinity CTO 30+ years on DBMS plus Expert in data warehouse with virtualization and security. petabyte-scale deployments. Previously at VMware and Altinity Founder; Previously at Continuent LifeStreet (Ad Tech business)
3 .Altinity Background ● Premier provider of software and services for ClickHouse ● Incorporated in UK with distributed team in US/Canada/Europe ● Main US/Europe sponsor of ClickHouse community ● Offerings: ○ Enterprise support for ClickHouse and ecosystem projects ○ Software (Kubernetes, cluster manager, tools & utilities) ○ POCs/Training
4 .ClickHouse Overview
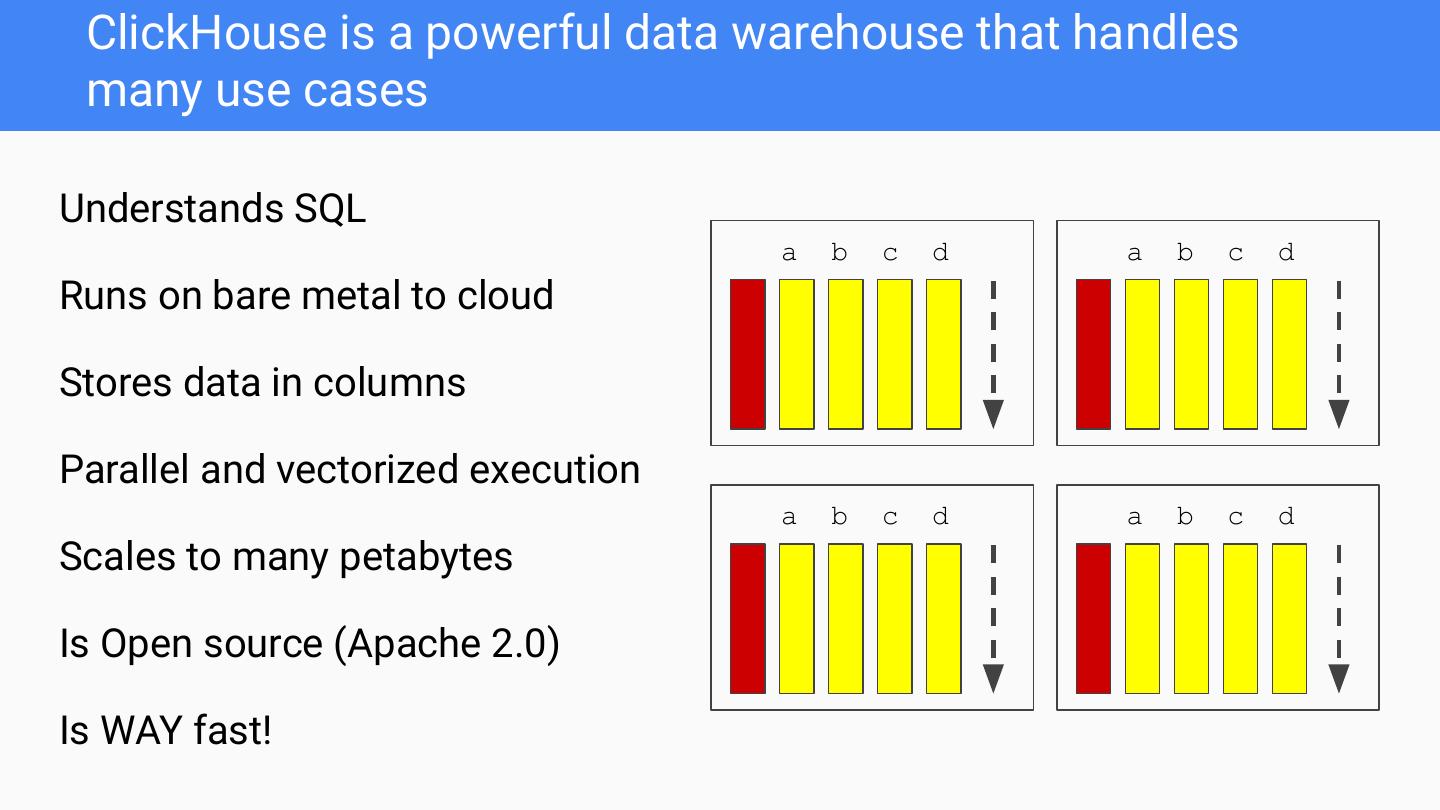
5 . ClickHouse is a powerful data warehouse that handles many use cases Understands SQL a b c d a b c d Runs on bare metal to cloud Stores data in columns Parallel and vectorized execution a b c d a b c d Scales to many petabytes Is Open source (Apache 2.0) Is WAY fast!
6 .Tables are split into indexed, sorted parts for fast queries Index Columns Part Indexed Table Sorted Index Columns Compressed Part Part
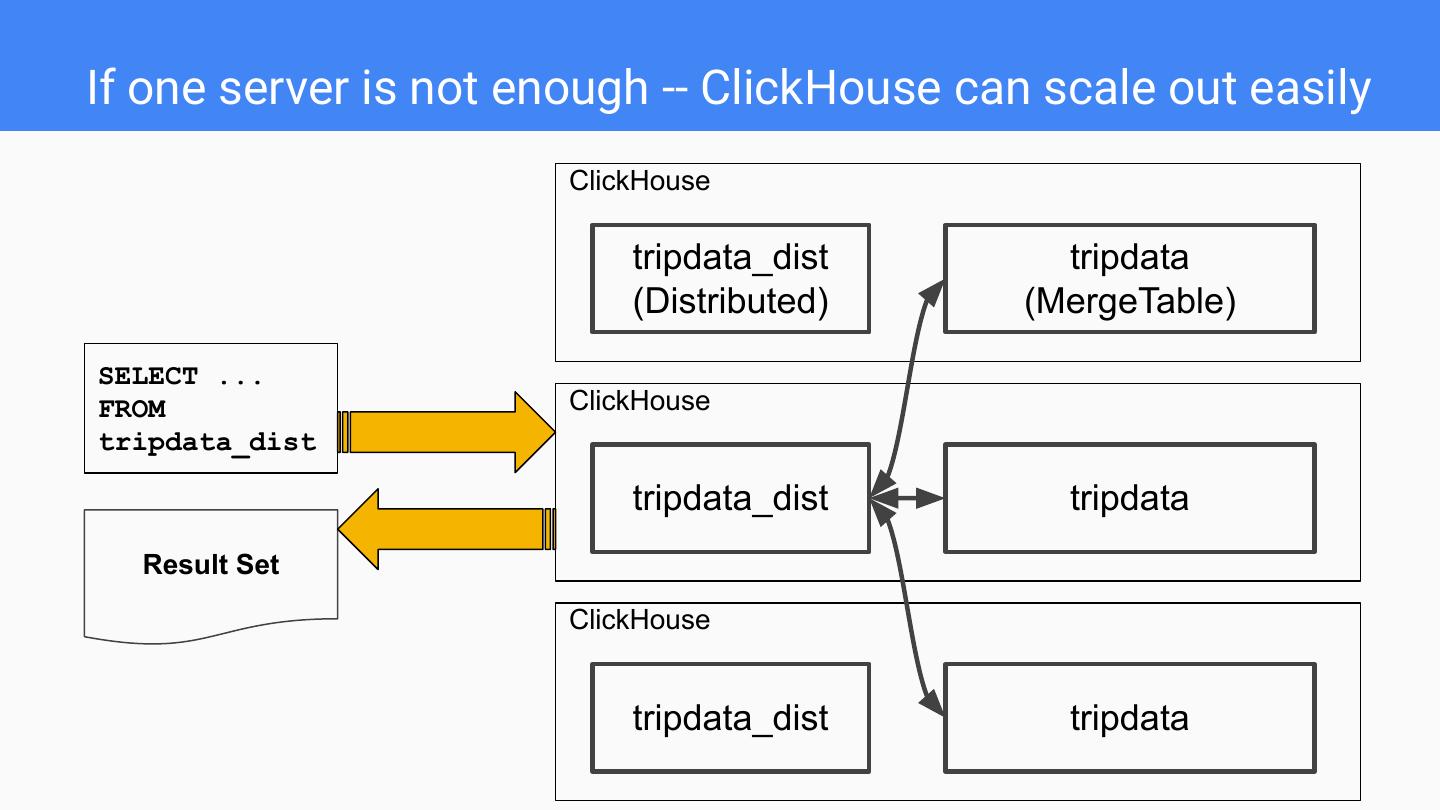
7 .If one server is not enough -- ClickHouse can scale out easily ClickHouse tripdata_dist tripdata (Distributed) (MergeTable) SELECT ... FROM ClickHouse tripdata_dist tripdata_dist tripdata Result Set ClickHouse tripdata_dist tripdata
8 .Getting Started: Data Loading
9 .Installation: Use packages on Linux host $ sudo apt -y install clickhouse-client=19.6.2 \ clickhouse-server=19.6.2 \ clickhouse-common-static=19.6.2 ... $ sudo systemctl start clickhouse-server ... $ clickhouse-client 11e99303c78e :) select version() ... ┌─version()─┐ │ 19.6.2.11 │ └───────────┘
10 .Decision tree for ClickHouse basic schema design Fields Yes Types Yes Use scalar are are columns with fixed? known? specific type No No Use array Use scalar Select columns to columns with partition key store key String type and sort order value pairs
11 . Tabular data structure typically gives the best results CREATE TABLE tripdata ( `pickup_date` Date DEFAULT Scalar columns toDate(tpep_pickup_datetime), `id` UInt64, Specific datatypes `vendor_id` String, `tpep_pickup_datetime` DateTime, Time-based partition key `tpep_dropoff_datetime` DateTime, ... ) ENGINE = MergeTree Sort key to index parts PARTITION BY toYYYYMM(pickup_date) ORDER BY (pickup_location_id, dropoff_location_id, vendor_id)
12 .Use clickhouse-client to load data quickly from files CSV Input Data "Pickup_date","id","vendor_id","tpep_pickup_datetime"… "2016-01-02",0,"1","2016-01-02 04:03:29","2016-01-02… "2016-01-29",0,"1","2016-01-29 12:00:51","2016-01-29… "2016-01-09",0,"1","2016-01-09 17:22:05","2016-01-09… Reading CSV Input with Headers clickhouse-client --database=nyc_taxi_rides --query='INSERT INTO tripdata FORMAT CSVWithNames' < data.csv Reading Gzipped CSV Input with Headers gzip -d -c | clickhouse-client --database=nyc_taxi_rides --query='INSERT INTO tripdata FORMAT CSVWithNames'
13 .Wouldn’t it be nice to run in parallel over a lot of input files? Altinity Datasets project does exactly that! ● Dump existing schema definitions and data to files ● Load files back into a database ● Data dump/load commands run in parallel See https://github.com/Altinity/altinity-datasets
14 . How long does it take to load 1.3B rows? $ time ad-cli dataset load nyc_taxi_rides --repo_path=/data1/sample-data Creating database if it does not exist: nyc_timed Executing DDL: /data1/sample-data/nyc_taxi_rides/ddl/taxi_zones.sql . . . Loading data: table=tripdata, file=data-200901.csv.gz . . . Operation summary: succeeded=193, failed=0 real 11m4.827s user 63m32.854s sys 2m41.235s (Amazon md5.2xlarge: Xeon(R) Platinum 8175M, 8vCPU, 30GB RAM, NVMe SSD)
15 . Do we really have 1B+ table? :) select count() from tripdata; SELECT count() FROM tripdata ┌────count()─┐ │ 1310903963 │ └────────────┘ 1 rows in set. Elapsed: 0.324 sec. Processed 1.31 billion rows, 1.31 GB (4.05 billion rows/s., 4.05 GB/s.) 1,310,903,963/11m4s = 1,974,253 rows/sec!!!
16 .Getting Started on Queries
17 . Let’s try to predict maximum performance SELECT avg(number) FROM ( SELECT number FROM system.numbers LIMIT 1310903963 system.numbers -- internal ) generator for testing ┌─avg(number)─┐ │ 655451981 │ └─────────────┘ 1 rows in set. Elapsed: 3.420 sec. Processed 1.31 billion rows, 10.49 GB (383.29 million rows/s., 3.07 GB/s.)
18 . Now we try with the real data SELECT avg(passenger_count) FROM tripdata ┌─avg(passenger_count)─┐ │ 1.6817462943317076 │ └──────────────────────┘ 1 rows in set. Elapsed: ? Guess how fast?
19 . Now we try with the real data SELECT avg(passenger_count) FROM tripdata ┌─avg(passenger_count)─┐ │ 1.6817462943317076 │ └──────────────────────┘ 1 rows in set. Elapsed: 1.084 sec. Processed 1.31 billion rows, 1.31 GB (1.21 billion rows/s., 1.21 GB/s.) Even faster!!!! Data type and cardinality matters
20 . What if we add a filter SELECT avg(passenger_count) FROM tripdata WHERE toYear(pickup_date) = 2016 ┌─avg(passenger_count)─┐ │ 1.6571129913837774 │ └──────────────────────┘ 1 rows in set. Elapsed: 0.162 sec. Processed 131.17 million rows, 393.50 MB (811.05 million rows/s., 2.43 GB/s.)
21 . What if we add a group by SELECT pickup_location_id AS location_id, avg(passenger_count), count() FROM tripdata WHERE toYear(pickup_date) = 2016 GROUP BY location_id LIMIT 10 ... 10 rows in set. Elapsed: 0.251 sec. Processed 131.17 million rows, 655.83 MB (522.62 million rows/s., 2.61 GB/s.)
22 . What if we add a join SELECT zone, avg(passenger_count), count() FROM tripdata INNER JOIN taxi_zones ON taxi_zones.location_id = pickup_location_id WHERE toYear(pickup_date) = 2016 GROUP BY zone LIMIT 10 10 rows in set. Elapsed: 0.803 sec. Processed 131.17 million rows, 655.83 MB (163.29 million rows/s., 816.44 MB/s.)
23 . Yes, ClickHouse is FAST! https://tech.marksblogg.com/benchmarks.html
24 .Optimization Techniques How to make ClickHouse even faster
25 . You can optimize Server settings Schema Column storage Queries
26 . You can optimize SELECT avg(passenger_count) Default is a half of FROM tripdata SETTINGS max_threads = 1 available cores -- good enough ... 1 rows in set. Elapsed: 4.855 sec. Processed 1.31 billion rows, 1.31 GB (270.04 million rows/s., 270.04 MB/s.) SELECT avg(passenger_count) FROM tripdata SETTINGS max_threads = 8 ... 1 rows in set. Elapsed: 1.092 sec. Processed 1.31 billion rows, 1.31 GB (1.20 billion rows/s., 1.20 GB/s.)
27 . Schema optimizations Data types Index Dictionaries Arrays Materialized Views and aggregating engines
28 . Data Types matter! https://www.percona.com/blog/2019/02/15/clickhouse-performance-uint32-vs-uint64-vs-float32-vs-float64/
29 .MaterializedView with SummingMergeTree CREATE MATERIALIZED VIEW tripdata_mv ENGINE = SummingMergeTree MaterializedView PARTITION BY toYYYYMM(pickup_date) ORDER BY (pickup_location_id, dropoff_location_id, vendor_id) AS works as an INSERT SELECT trigger pickup_date, vendor_id, pickup_location_id, dropoff_location_id, sum(passenger_count) AS passenger_count_sum, sum(trip_distance) AS trip_distance_sum, sum(fare_amount) AS fare_amount_sum, sum(tip_amount) AS tip_amount_sum, sum(tolls_amount) AS tolls_amount_sum, sum(total_amount) AS total_amount_sum, SummingMergeTree count() AS trips_count automatically FROM tripdata GROUP BY aggregates data in pickup_date, the background vendor_id, pickup_location_id, dropoff_location_id
3秒后跳转登录页面
去登陆

