



































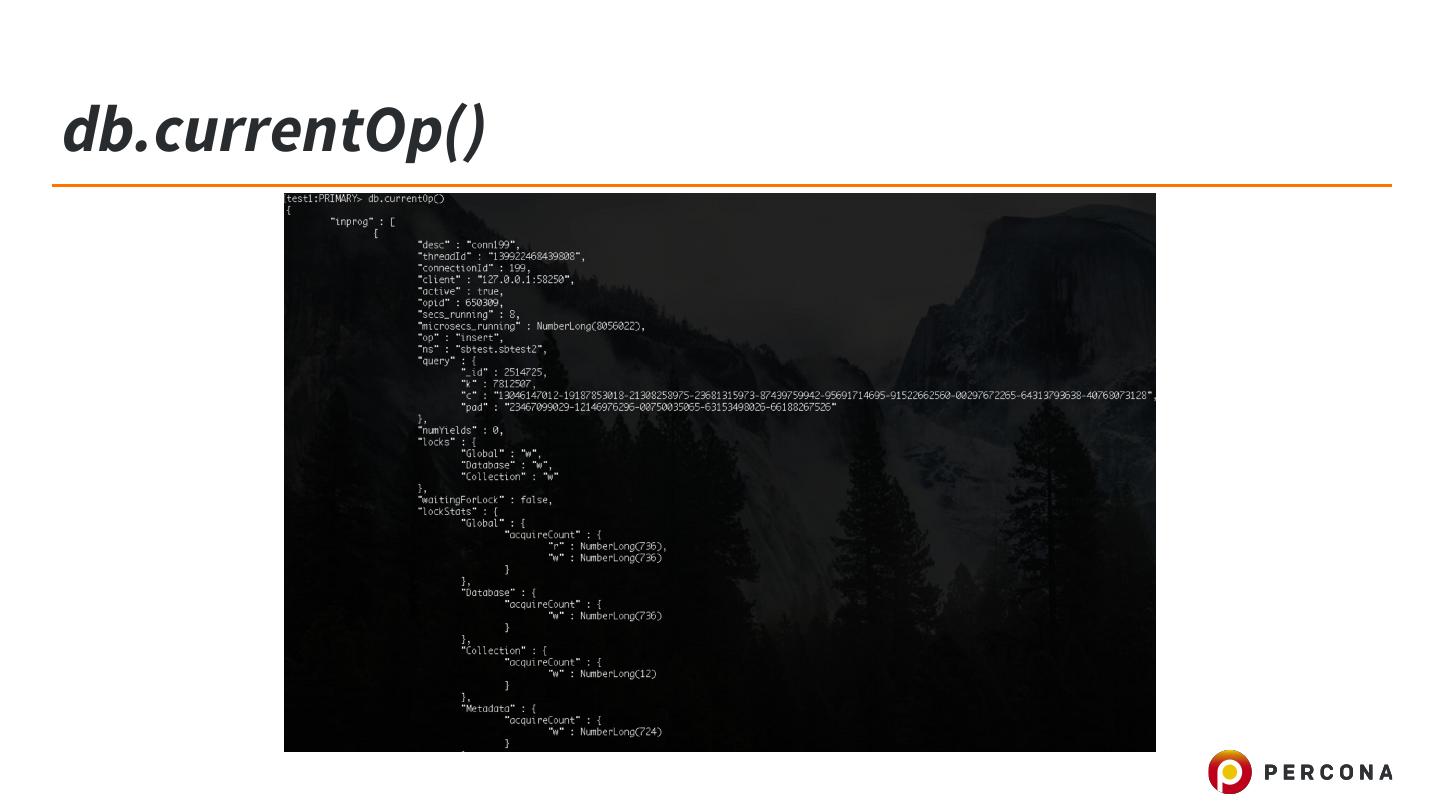


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Develop an App with MongoDB
在开发应用程序时,许多开发人员喜欢使用MongoDB而不是其他开源数据库。但为什么呢?如何使用MongoDB创建功能良好的应用程序?
本次网络研讨会将帮助开发人员了解MongoDB的功能以及它如何处理来自应用程序的请求。
在本次网络研讨会中,我们将介绍:
数据、查询和索引
-有效使用索引
-使用正确的数据类型减少索引和存储大小
-聚合框架
-使用解释和操作分析功能
-要避免的MongoDB功能
-使用读写关注完整性
-性能
-使用读取首选项缩放读取查询
-什么是mongodb sharding?
-使用Percona监控和管理(PMM)可视化数据库使用
-用于应用程序安全的MongoDB用户和内置角色
-使用SRV DNS记录支持
在本课结束时,您将知道如何避免在应用程序阶段与MongoDB之间的常见问题,而不是在生产中修复它。
展开查看详情
1 .Develop an App with MongoDB Tim Vaillancourt Software Engineer, Percona Speaker Name
2 .`whoami` { name: “tim”, lastname: “vaillancourt”, employer: “percona”, techs: [ “mongodb”, “mysql”, “cassandra”, “redis”, “rabbitmq”, “solr”, “mesos” “kafka”, “couch*”, “python”, “golang” ] }
3 .Agenda ● Security ● Schema, Performance, etc ● Aggregation Framework ● Data Integrity ● Monitoring ● Troubleshooting ● Scaling ● Elastic Deployment ● Questions?
4 .Security
5 .Authorization ● Use Auth with 1-user-per App ○ Authorization is default in modern MongoDB ○ Most apps need the “readWrite” built-in role only ● Built-in Roles ○ Database User: Read or Write data from collections ■ “All Databases” or Single-database ○ Database Admin: Non-RW commands (create/drop/list/etc) ○ Backup and Restore: ○ Cluster Admin: Add/Drop/List shards ○ Superuser/Root: All capabilities ○ User-defined roles are also possible
6 .Encryption ● Make sure operations teams are aware of sensitive data in the app! ● MongoDB SSL / TLS Connections ○ Supported since MongoDB 2.6x ○ Minimum of 128-bit key length for security ○ Relaxed and strict (requireSSL) modes ○ System (default) or Custom Certificate Authorities are accepted ● Encryption-at-Rest ○ Possible with: ■ MongoDB Enterprise ($$$) binaries ■ Block device encryption (See Percona Blog)
7 .Source IP Restrictions ● “authenticationRestrictions” added to db.createUser() in MongoDB 3.6 ● Allows access restriction by client source IP(s) and/or IP range(s) ● Example: db.createUser({ user: "admin", pwd: "insertSecurePasswordHere", roles: [ { db: "admin", role: "root" } ], authenticationRestrictions: [ { clientSource: [ "127.0.0.1", "10.10.19.0/24" ] } ] })
8 .Schema, Performance, etc
9 .Data Types ● Strings ○ Only use strings if required ○ Do not store numbers as strings! ○ Look for {field:“123456”} instead of {field:123456} ■ “12345678” moved to a integer uses 25% less space ■ Range queries on proper integers is more efficient ○ Example JavaScript to convert a field in an entire collection db.items.find().forEach(function(x) { newItemId = parseInt(x.itemId); db.items.update( { _id: x._id }, { $set: { itemId: itemId } } ) });
10 .Data Types ● Strings ○ Do not store dates as strings! ■ The field "2017-08-17 10:00:04 CEST" stores in 52.5% less space as a real date! ○ Do not store booleans as strings! ■ “true” -> true = 47% less space wasted ● DBRefs ○ DBRefs provide pointers to another document ○ DBRefs can be cross-collection ● NumberLong (MongoDB 3.4+) ○ Higher precision for floating-point numbers
11 .Indexes ● MongoDB supports BTree, text and geo indexes ○ Btree is default behaviour ● By default, collection lock until indexing completes ● { background:true } Indexing ○ Runs indexing in the background avoiding pauses ○ Hard to monitor and troubleshoot progress ○ Unpredictable performance impact ○ Our suggestion: rollout indexes one node at a time ■ Disable replication and change TCP port, restart. ■ Apply index. ■ Enable replication, restore TCP port.
12 .Indexes ● Avoid drivers that auto-create indexes ○ Use real performance data to make indexing decisions, find out before Production! ● Too many indexes hurts ○ Write performance for an entire collection ○ Optimiser efficiency ○ Disk and RAM is wasted ● Indexes have a forward or backward direction ○ Try to cover .sort() with index and match direction! ● Indexes can be “hinted” and forced if necessary
13 .Indexes ● The size of the indexed fields impacts the size of the index ○ A point so important, it has its own slide!
14 .Indexes ● Compound Indexes ○ Several fields supported ○ Fields can be in forward or backward direction ■ Consider any .sort() query options and match sort direction! ○ Composite Keys are read Left -> Right! ■ Index can be partially-read ■ Left-most fields do not need to be duplicated! ■ All Indexes below are duplicates of the first index: ● {username: 1, status: 1, date: 1, count: -1} ● {username: 1, status: 1, data: 1 } ● {username: 1, status: 1 } ● {username: 1 } ● Use db.collection.getIndexes() to view current Indexes
15 .Query Efficiency ● Query Efficiency Ratios ○ Index: keysExamined / nreturned ○ Document: docsExamined / nreturned ● End goal: Examine only as many Index Keys/Docs as you return! ○ Tip: when using covered indexes zero documents are fetched (docsExamined: 0)! ○ Example: a query scanning 10 documents to return 1 has efficiency 0.1 ○ Scanning zero docs is possible if using a covered index!
16 .Query Efficiency ● Sorting is relatively CPU intensive due to iteration ● Sharding ○ Sorting occurs on the Mongos process when no index on field ○ A mongos often has fewer resources ● Match the direction of the sort direction, ie: 1 or -1 Index: { id: 1, cost: -1 } Query: db.items.find({ id: 1234 }).sort({ cost: -1 }) Index: { id: 1, cost: 1 } Query: db.items.find({ id: 1234 }).sort({ cost: -1 })
17 .Bulk Writes ● Bulk Write operations allow many writes in a single operation ○ Available since 3.2 as the shell operation db.collection.bulkWrite() ○ Operates on a single collection ○ Can improve batch insert performance ■ Helpful for ETL jobs, import/export jobs, etc ○ Ordered Mode ■ Documents are written in order ■ An error stops the Bulk operation ○ Unordered Mode ■ Documents are written unordered ■ An error DOES NOT STOP the Bulk Operation!
18 .Antipatterns / Features to Avoid ● No list of fields specified in .find() ○ MongoDB returns entire documents unless fields are specified ○ Only return the fields required for an application operation! ○ Covered-index operations require only the index fields to be specified ○ Example: db.items.find({ id: 1234 }, { cost: 1, available: 1 }) ● Using $where operators ○ This executes JavaScript with a global lock
19 .Antipatterns / Features to Avoid ● Many $and or $or conditions ○ MongoDB (or any RDBMS) doesn’t handle large lists of $and or $or efficiently ○ Try to avoid this sort of model with ■ Data locality ■ Background Summaries / Views ● .mapReduce() ○ Generally more complex code to read/maintain ○ Performs slower than the Aggregation Framework ○ Performs extraneous locking vs Aggregation Framework ● Unordered Bulk Writes ○ Error handling can be unpredictable
20 .Aggregation Framework
21 .Aggregation Pipeline: .aggregate() ● Run as a pipeline of “stages” on a MongoDB collection ○ Each stage passes it’s result to the next ○ Aggregates the entire collection by default ■ Add a $match stage to reduce the aggregation data ● Runs inside the MongoDB Server code ○ Much more efficient than .mapReduce() operations ● Example stages: ○ $match - only aggregate documents that match this filter (same as .find()) ■ Must be 1st stage to use indexes! ○ $group - group documents by certain conditions ■ Similar to “SELECT …. GROUP BY”
22 .Aggregation Pipeline: .aggregate() ● Example stages: ○ $count - count the # of documents ○ $project - only output specific pieces of the data ○ $bucket and $bucketAuto - Group documents based on specified expression and bucket boundaries ■ Useful for Faceted Search ○ $geoNear - Returns documents based on geo-proximity ○ $graphLookup - Performs a recursive search on a collection ○ $sample - Returns a random sample of documents of a specified size ○ $unwind - Unwinds arrays into many separate documents ○ $facet - Runs many aggregation pipelines within a single stage
23 .Aggregation Pipeline: .aggregate() ● Just a few examples of operators that can be used each stage: ○ $and / $or /$not ○ $add / $subtract / $multiply ○ $gt / $gte / $lt / $lte / $ne ○ $min / $max / $avg / $stdDevPop ○ $log / $log10 ○ $sqrt ○ $floor / $ceil ○ $in (inefficient) ○ $dayOfWeek / $dayOfMonth / $dayOfYear ○ $concat / $split /…
24 .Aggregation Pipeline: .aggregate() ● More on the Aggregation Pipeline: ○ https://docs.mongodb.com/manual/reference/operator/ aggregation-pipeline/ ○ https://docs.mongodb.com/manual/reference/operator/ aggregation/ ○ https://www.amazon.com/MongoDB-Aggregation-Frame work-Principles-Examples-ebook/dp/B00DGKGWE4
25 .Data Integrity
26 .Storage and Journaling ● The Journal provides durability in the event of failure of the server ● Changes are written ahead to the journal for each write operation ● On crash recovery, the server ○ Finds the last point of consistency to disk ○ Searches the journal file(s) for the record matching the checkpoint ○ Applies all changes in the journal since the last point of consistency
27 .Write Concern ● MongoDB Replication is Asynchronous ○ Write Concerns can simulate synchronous operations ● Write Concerns ○ Per-session (or even per-query) tunable ○ Allow control of data integrity of a write to a Replica Set ○ Write Concern Modes ■ “w: <num>” - Writes much acknowledge to defined number of nodes ■ “majority” - Writes much acknowledge on a majority of nodes ■ “<replica set tag>” - Writes acknowledge to a member with the specified replica set tags ○ Journal flag ■ “j: <bool>” - Sets requirement for change to write to journal
28 .Write Concern ● Write Concerns ○ Durability ■ By default write concerns are NOT durable ■ “j: true” - Optionally, wait for node(s) to acknowledge journaling of operation ■ In 3.4+ “writeConcernMajorityJournalDefault” allows enforcement of “j: true” via replica set configuration! ● Must specify “j: false” or alter “writeConcernMajorityDefault” to disable
29 .Read Concern ● Like write concerns, the consistency of reads can be tuned per session or operation ● Levels ○ “local” - Default, return the current node’s most-recent version of the data ○ “majority” - Most recent version of the data that has been ack’d on a majority of nodes. Not supported on MMAPv1. ○ “linearizable” (3.4+) - Reads return data that reflects a “majority” read of all changes prior to the read
3秒后跳转登录页面
去登陆

