展开查看详情
1 .还没用 SparkSql ?你 out 了! 大数据平台研发部 白冰 18211100183 -- SparkSql 原理与优化
2 .Spark SQL 的定义与原理 1 Spark SQL vs Hive on MR vs Hive on Spark 2 如何使用 Spark SQL 3 如何分析 SQL 性能 4 SparkSQL 参数调优 5 目录 6 SparkSQL 高级特性
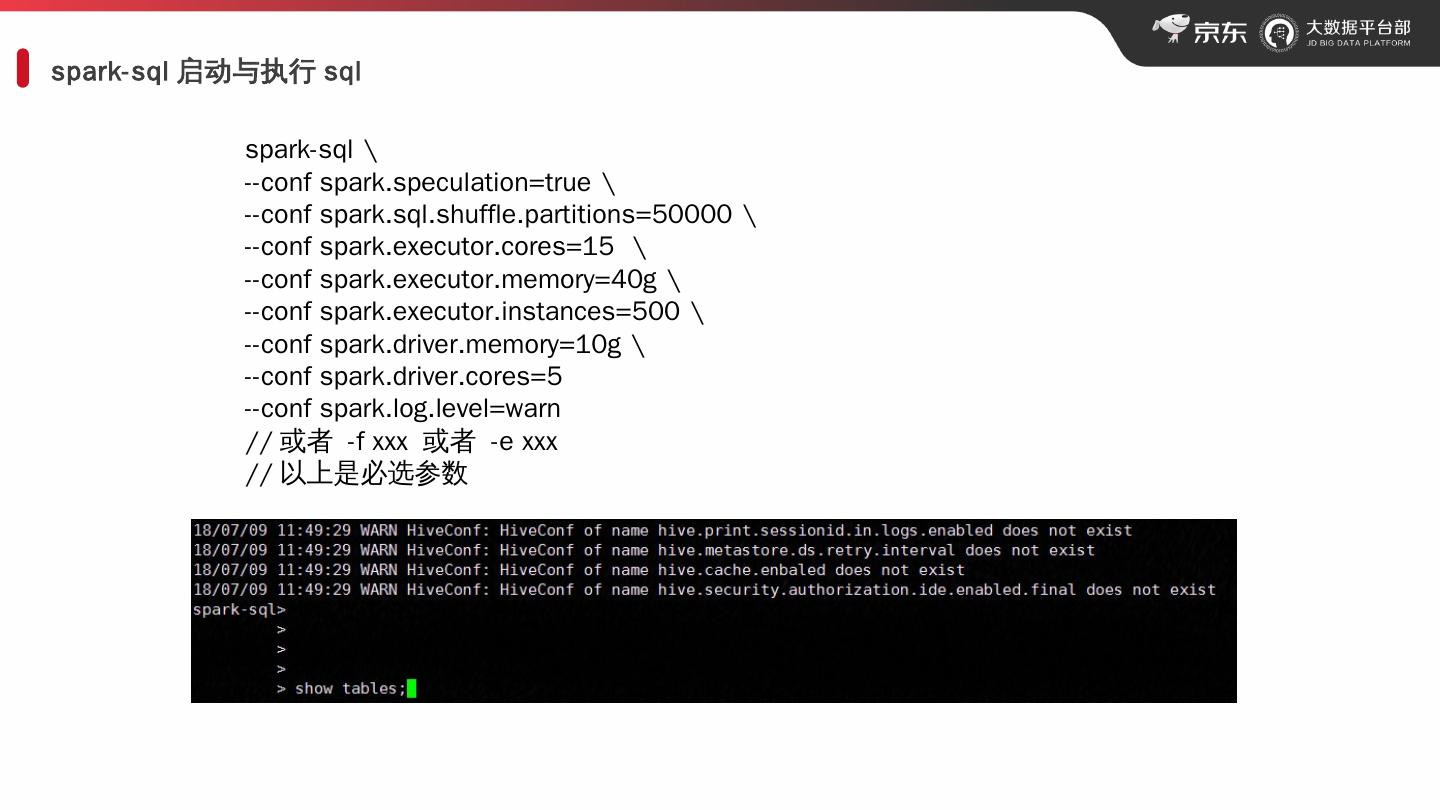
3 .spark- sql 启动与执行 sql spark- sql \ -- conf spark.speculation =true \ -- conf spark.sql.shuffle.partitions =50000 \ -- conf spark.executor.cores = 15 \ -- conf spark.executor.memory = 40g \ -- conf spark.executor.instances =500 \ -- conf spark.driver.memory = 10g \ -- conf spark.driver.cores = 5 -- conf spark.log.level =warn // 或者 -f xxx 或者 -e xxx // 以上是必选参数
4 .1.1 SparkSQL 的定义 Spark SQL 是 Spark 的一个 模块,用来 专门处理结构化 数据 Apache Spark(core) Spark SQL Spark Streaming Spark MLlib Spark Graphx 禁用 SQLContext = SparkSession.builder.getOrCreate () 禁用 HiveContext = SparkSession.builder.enableHiveSupport (). getOrCreate () spark = SparkSession.builder.enableHiveSupport.getOrCreate () results = spark.sql (" SELECT * FROM people") names = results.map ( row => row.name ) SQL 与 编程 无缝衔接 spark.jsonFile ("s3n ://.../ A.json "). registerTempTable (" json table ") results = spark.sql (""" SELECT * FROM people JOIN jsontable ...""") 统一了数据访问 与 hive 整合 Apache Spark(core) Spark SQL Meta Store HiveQL UDFs
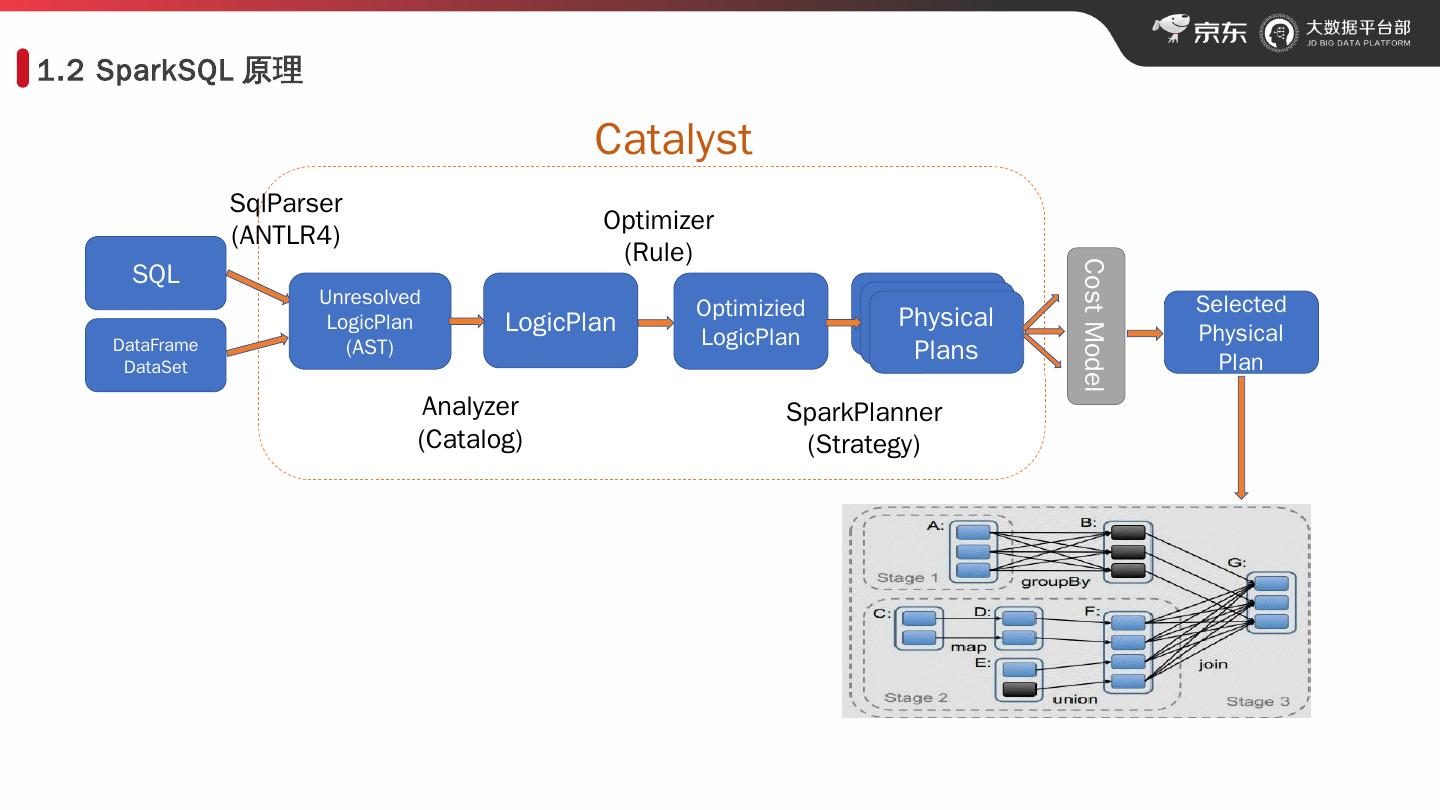
5 .1.2 SparkSQL 原理 SQL DataFrame DataSet Unresolved LogicPlan (AST) LogicPlan Optimizied LogicPlan Physical Plans Cost Model Selected Physical Plan SqlParser (ANTLR4) Analyzer (Catalog) Optimizer (Rule) SparkPlanner (Strategy) Catalyst Optimizer Rule
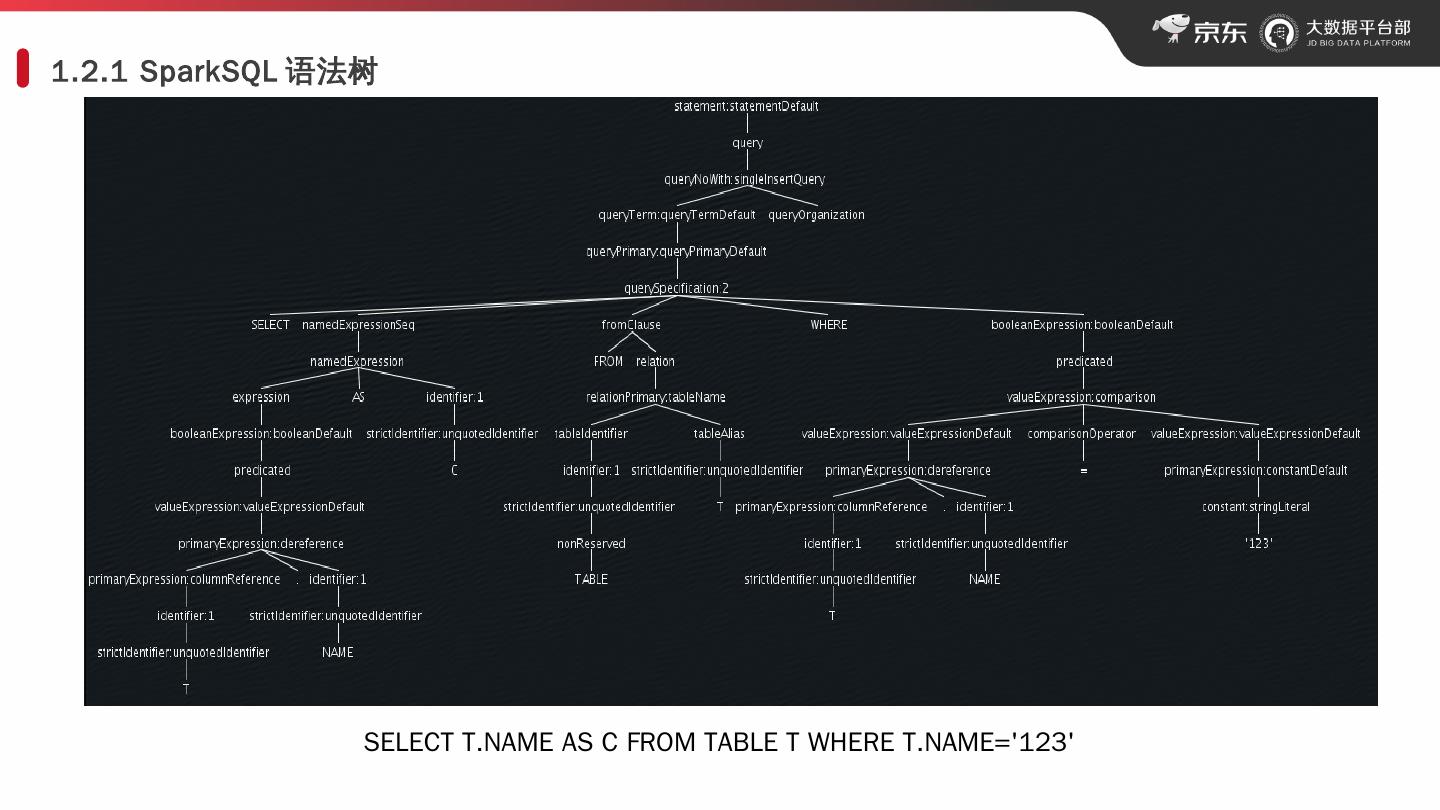
6 .1.2.1 SparkSQL 语法树 SELECT T.NAME AS C FROM TABLE T WHERE T.NAME=123
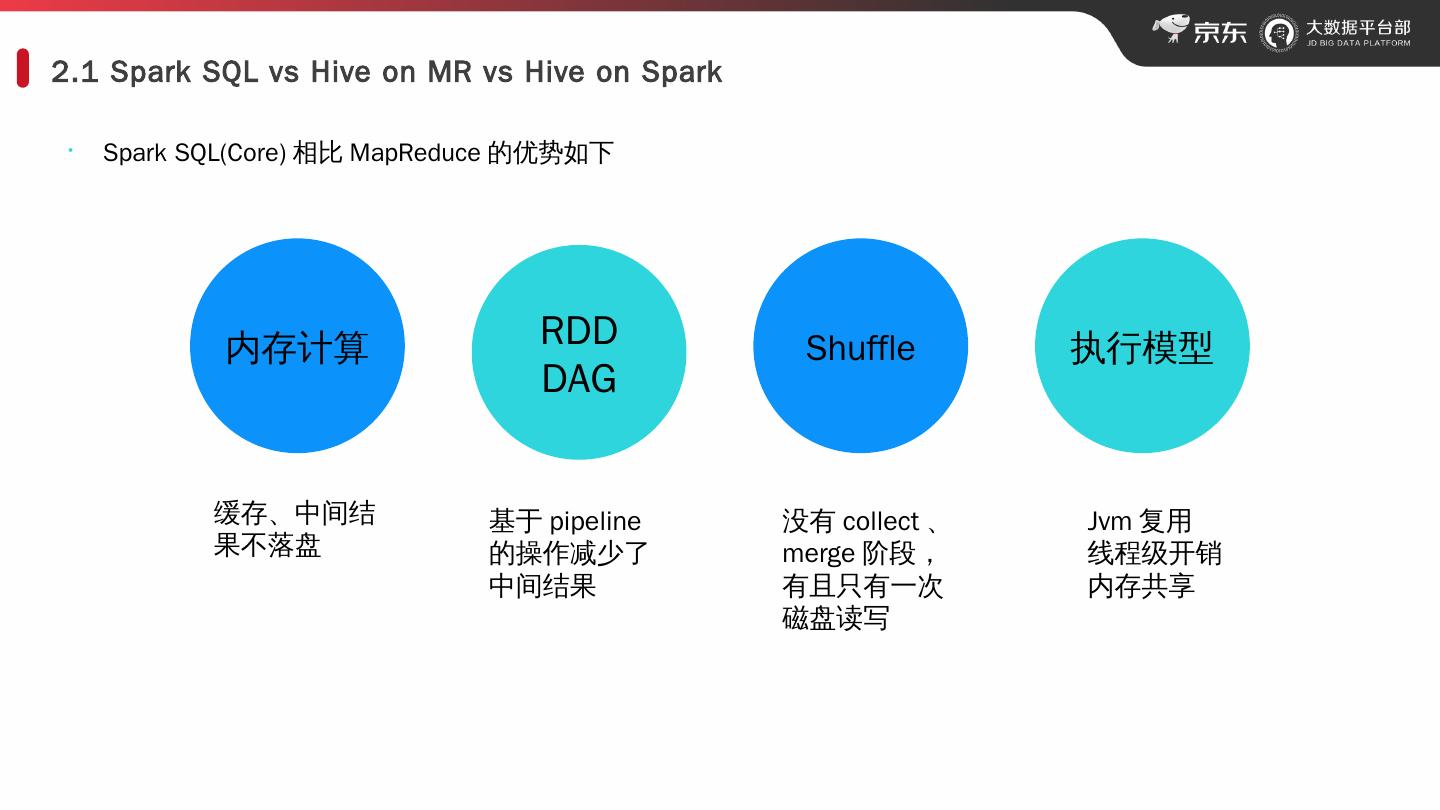
7 .2.1 Spark SQL vs Hive on MR vs Hive on Spark · Spark SQL(Core) 相比 MapReduce 的优势如下 内存计算 RDD DAG Shuffle 执行 模型 缓存、中间结果不落盘 基于 pipeline 的操作减少了中间结果 Jvm 复用 线程级开销 内存共享 没有 collect 、 merge 阶段,有且只有一次磁盘读写
8 .3 如何 使用 Spark SQL 8 spark-sql HiveTask Thrift Server BUFFLO/IDE 用户可以根据不同的场景,最方便地使用 spark- sql 交互式 python 模板 JDBC/ODBC Web 工具
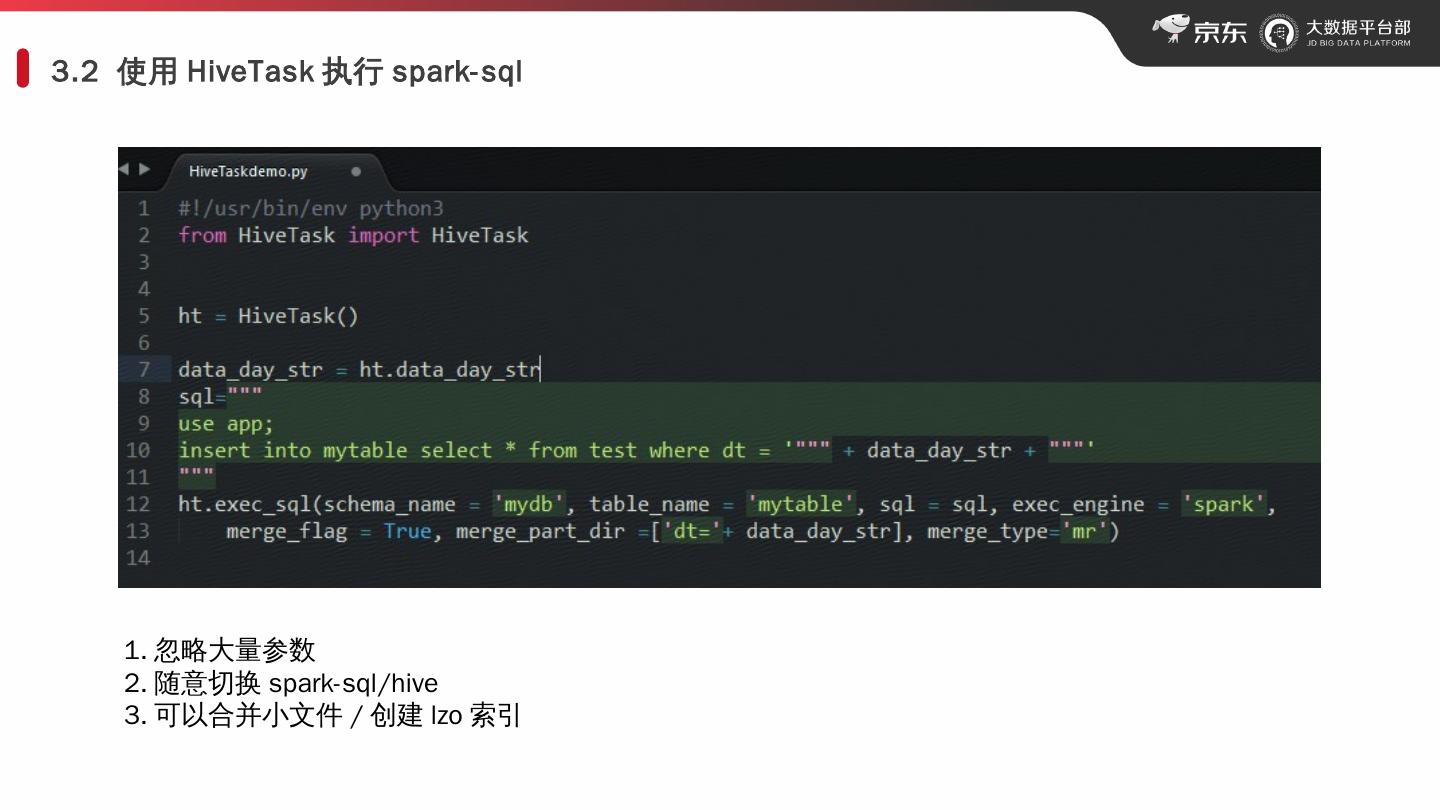
9 .3.2 使用 HiveTask 执行 spark- sql 忽略大量参数 随意切换 spark- sql /hive 可以合并小文件 / 创建 lzo 索引
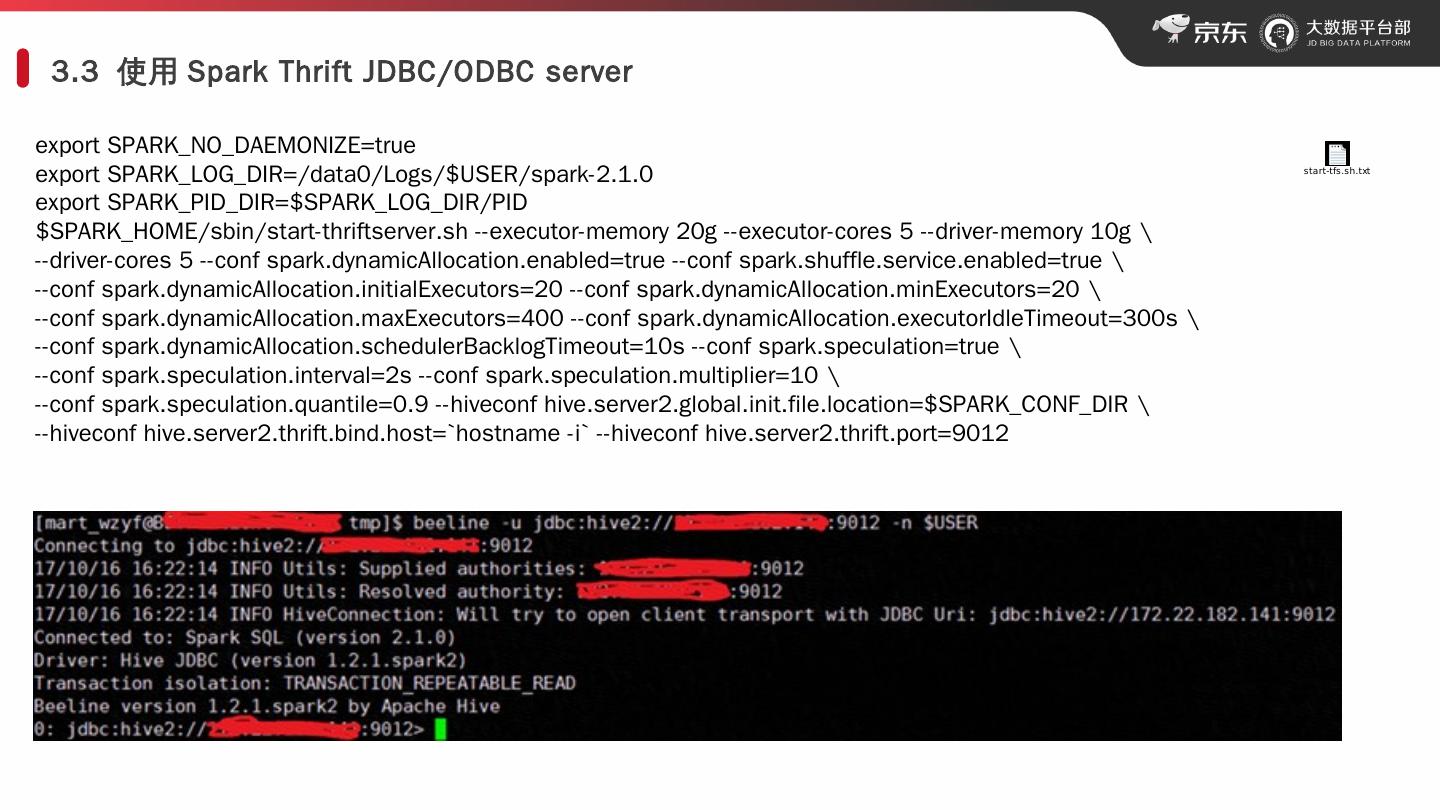
10 .3.3 使用 Spark Thrift JDBC/ODBC server export SPARK_NO_DAEMONIZE=true export SPARK_LOG_DIR=/data0/Logs/$USER/spark-2.1.0 export SPARK_PID_DIR=$SPARK_LOG_DIR/PID $SPARK_HOME/sbin/start-thriftserver.sh -- executor-memory 20g -- executor-cores 5 -- driver-memory 10g \ --driver-cores 5 -- conf spark.dynamicAllocation.enabled =true -- conf spark.shuffle.service.enabled =true \ -- conf spark.dynamicAllocation.initialExecutors =20 -- conf spark.dynamicAllocation.minExecutors =20 \ -- conf spark.dynamicAllocation.maxExecutors =400 -- conf spark.dynamicAllocation.executorIdleTimeout =300s \ -- conf spark.dynamicAllocation.schedulerBacklogTimeout =10s -- conf spark.speculation =true \ -- conf spark.speculation.interval =2s -- conf spark.speculation.multiplier =10 \ -- conf spark.speculation.quantile =0.9 -- hiveconf hive.server2.global.init.file.location=$SPARK_CONF_DIR \ -- hiveconf hive.server2.thrift.bind.host=`hostname - i ` -- hiveconf hive.server2.thrift.port=9012
11 .3.4 使用 Web 工具提交 spark- sql 提交定时任务 BUFFLO 实时查询 IDE
12 .4 如何分析 SQL 性能 与 Hive(on MR) 进行对比,用来调整资源量、 shuffle 并行度等参数 不同框架对比 通过日志查看 job 生成前和 job 结束后 spark 的处理内容,一般有解析文件索引、文件分块、异动文件等操作。 查看日志 explain xxx explain extended xxx explain codegen xxx 查看 DAG 与执行计划 孔明平台 自动化分析
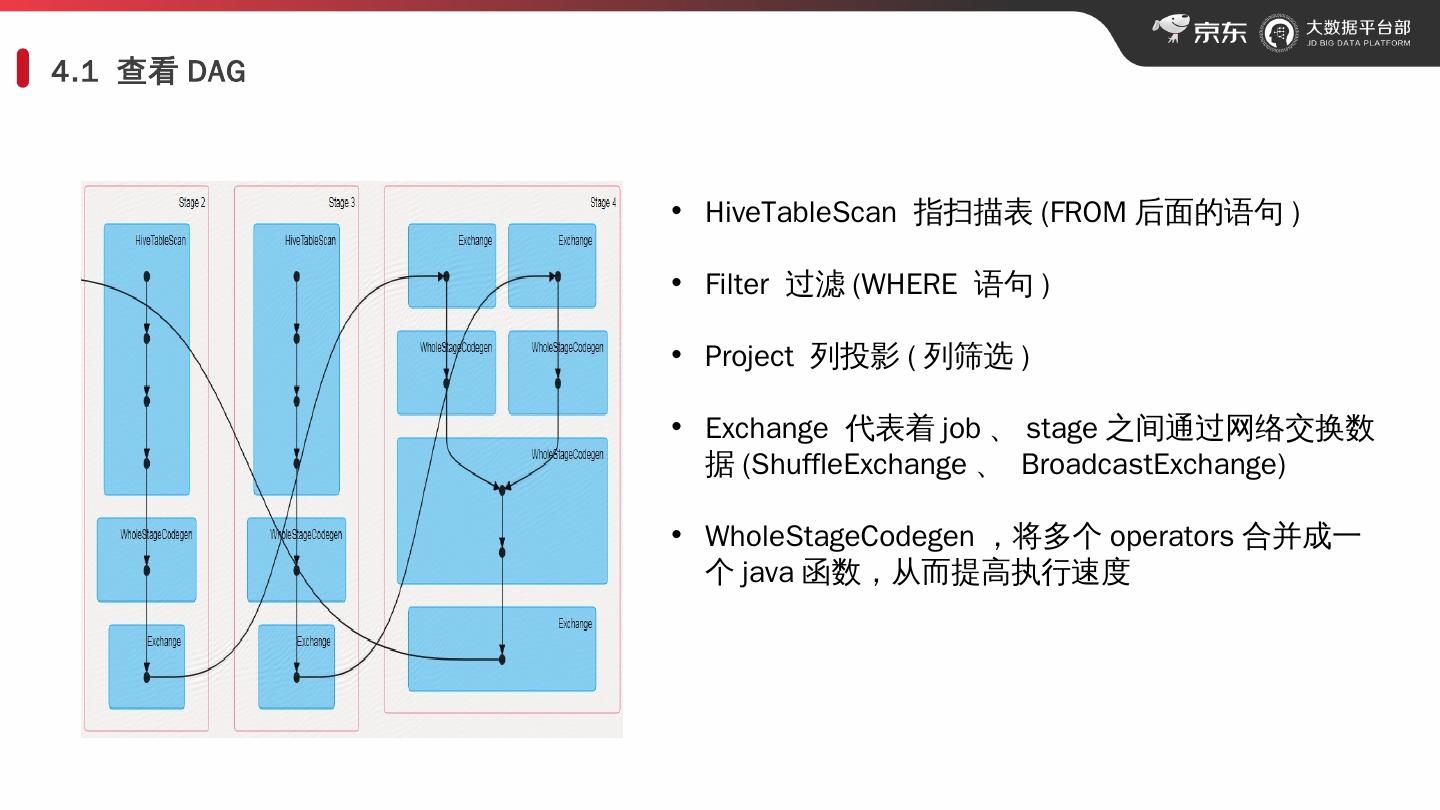
13 .4.1 查看 DAG HiveTableScan 指扫描表 (FROM 后面的语句 ) Filter 过滤 (WHERE 语句 ) Project 列投影 ( 列筛选 ) Exchange 代表着 job 、 stage 之间通过网络交换 数据 ( ShuffleExchange 、 BroadcastExchange ) WholeStageCodegen ,将多个 operators 合并成一个 java 函数,从而提高执行 速度
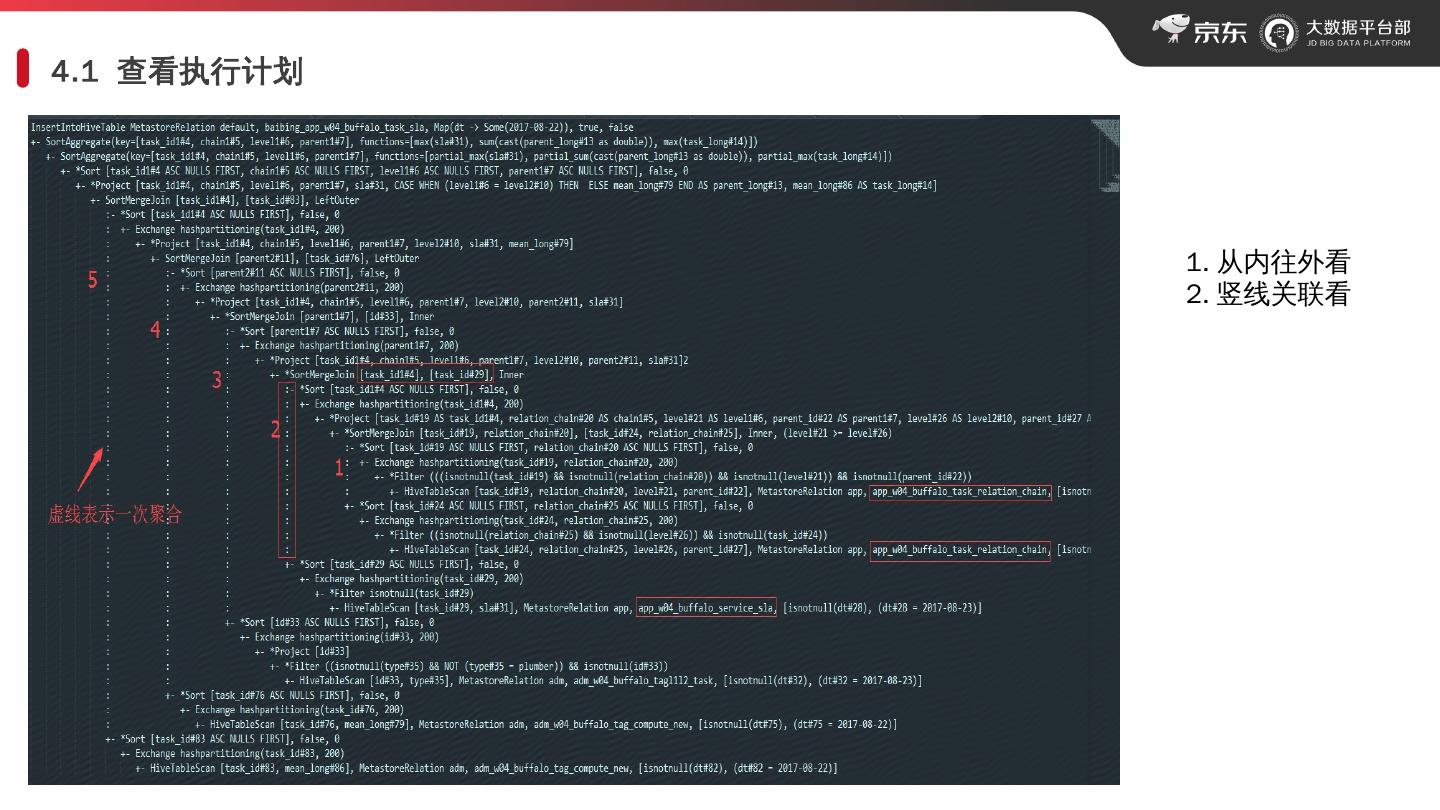
14 .4.1 查看执行计划 1. 从内往外看 2. 竖 线 关联看
15 .5.1 SparkSQL 参数调优 资源参数 sql 参数 高级特性参数 spark- sql --master yarn -- conf spark.executor.instances =100 -- conf spark.executor.cores =8 -- conf spark.executor.memory =20g -- conf spark.driver.memory =10g -- conf spark.driver.cores =5 -- conf spark.dynamicAllocation.enabled =true -- conf spark.dynamicAllocation.minExecutors =5 -- conf spark.dynamicAllocation.maxExecutors =200 -- conf spark.dynamicAllocation.initialExecutors =5 -- conf spark.dynamicAllocation.executorIdleTimeout =60s -- conf spark.shuffle.service.enabled =true -- conf spark.speculation =true -- conf spark.isLoadHivercFile =true -- conf spark.sql.tempudf.ignoreIfExists =true -- conf spark.sql.shuffle.partitions =5000 -- conf spark.sql.crossJoin.enabled =true -- conf spark.sql.hive.mergeFiles =true -- conf spark.sql.autoBroadcastJoinThreshold =52428800 -- conf spark.sql.parser.quotedRegexColumnNames =true -- conf spark.sql.adaptive.enabled =true -- conf spark.sql.adaptiveBroadcastJoinThreshold =524288000 -- conf spark.sql.adaptive.allowAdditionalShuffle =true -- conf spark.sql.adaptive.join.enabled =true -- conf spark.sql.adaptive.skewedJoin.enabled =true -- conf spark.sql.adaptive.minNumPostShufflePartitions =1 -- conf spark.sql.adaptive.maxNumPostShufflePartitions =5000 -- conf spark.sql.cbo.enabled =true -- conf spark.sql.cbo.joinReorder.card.weight =0.8 -- conf spark.hadoop.hive.exec.stagingdir =/ tmp /spark -- hiveconf hive.exec.orc.split.strategy =BI
16 .6 SparkSQL 高级特性 16 01 0 2 0 3 0 4 SQL DAG 0 5 0 6 0 7 CBO Broadcast Join Auto Merge Adaptive Exception HBO Cache Table
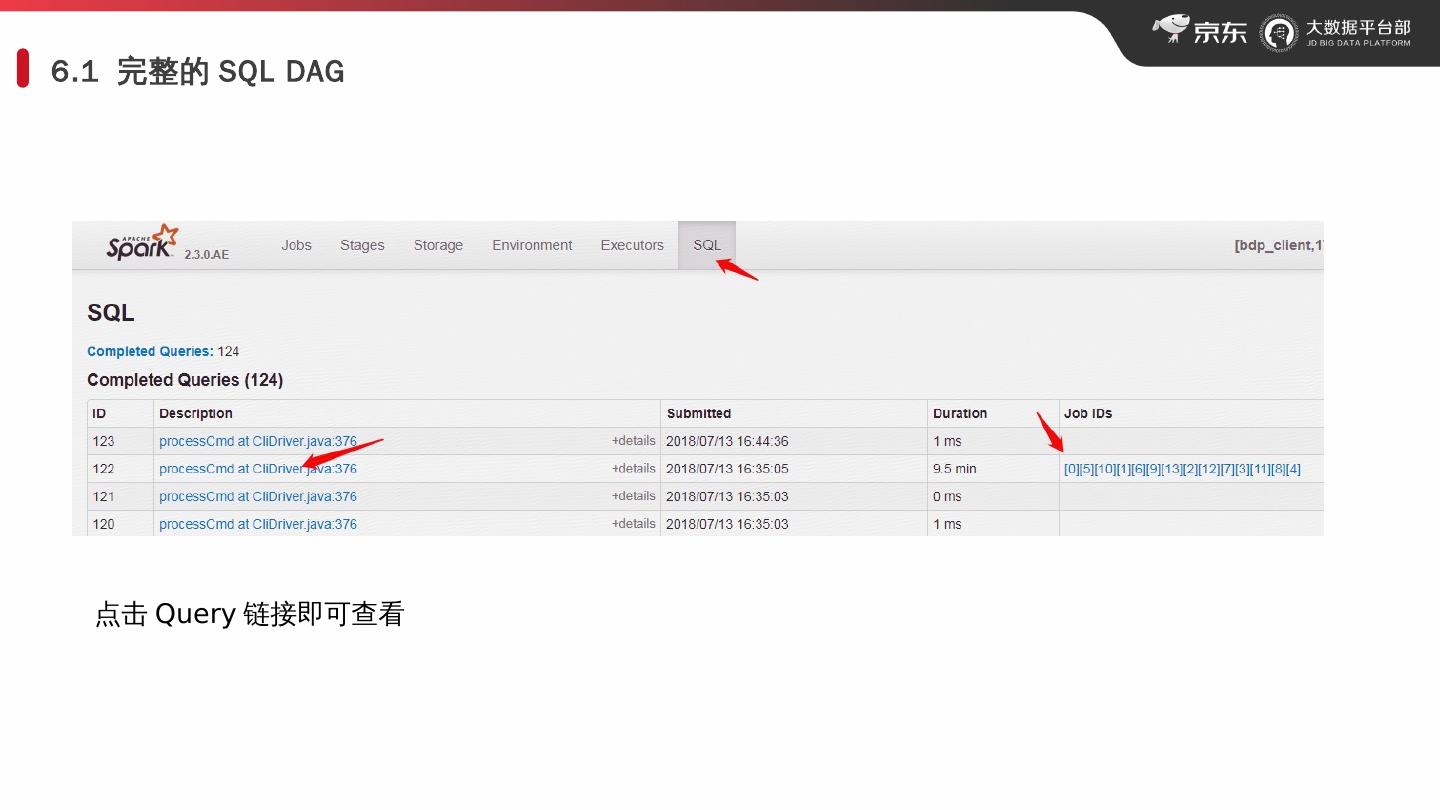
17 .6.1 完整的 SQL DAG 点击 Query 链接即可查看
18 .6.2 完整的 SQL DAG HiveTableScan : 读表( from ) Filter: 过滤条件 ( wher ) Project: 列筛选 (select) SMJ: Join Exchange:Shuffle read/write
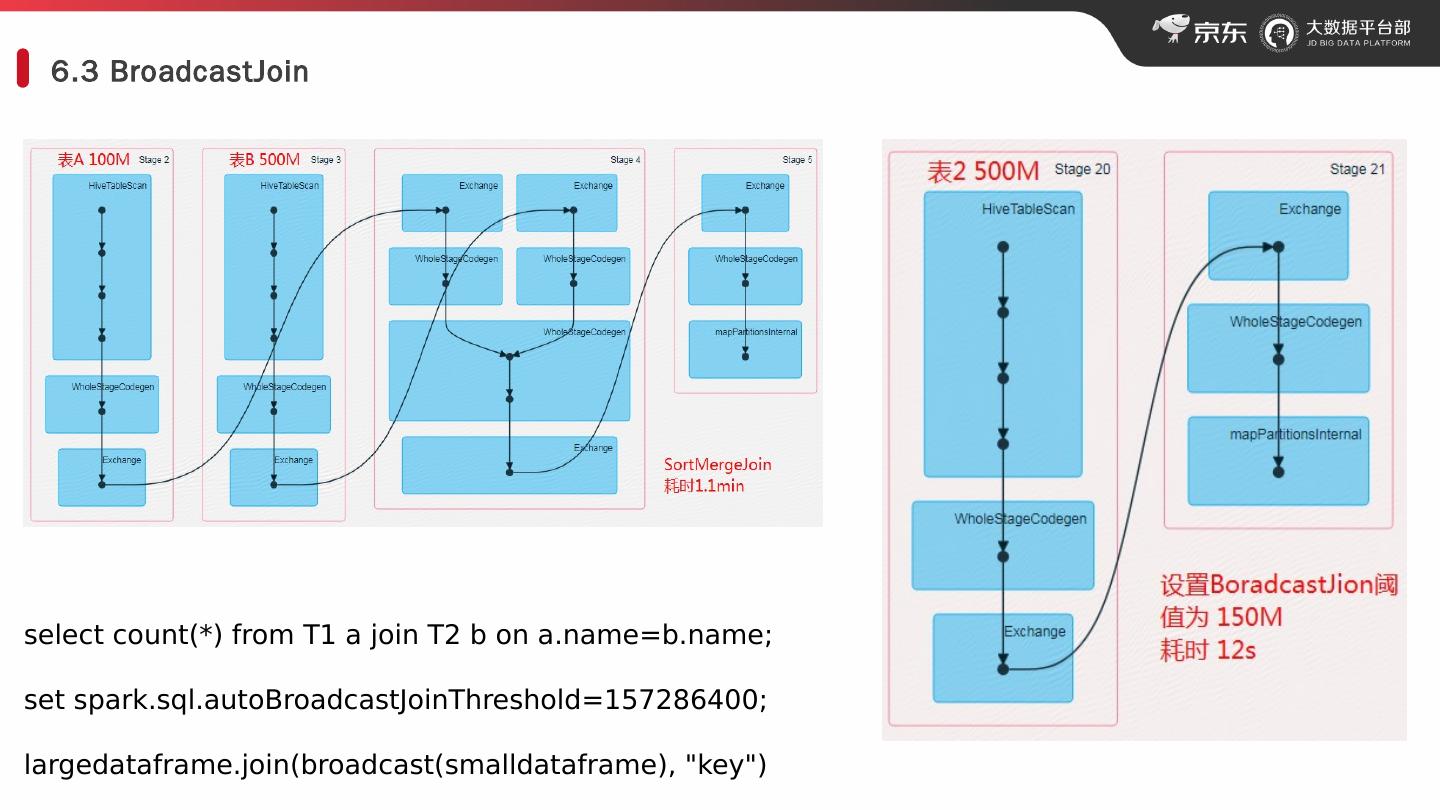
19 .6.3 BroadcastJoin select count(*) from T1 a join T2 b on a.name=b.name; set spark.sql.autoBroadcastJoinThreshold =157286400 ; largedataframe.join (broadcast( smalldataframe ), "key")
20 .6.4 Cache Table 自带 Alluxio ! cache (lazy) table XXX cache table A as select * from XXX where … uncache table XXX spark.catalog.cacheTable () spark.catalog.uncacheTable () spark.catalog.clearCache ()
21 .6.5 CBO 基于代价 ( 成本 ) 的优化 ANALYZE TABLE baibing_orc partition( dt =xxx) COMPUTE STATISTICS; ANALYZE TABLE baibing_orc COMPUTE STATISTICS for columns name; 收集信息 1 2 优化内容 优化过滤过程 选择 Join 类型 选择 Join 顺序
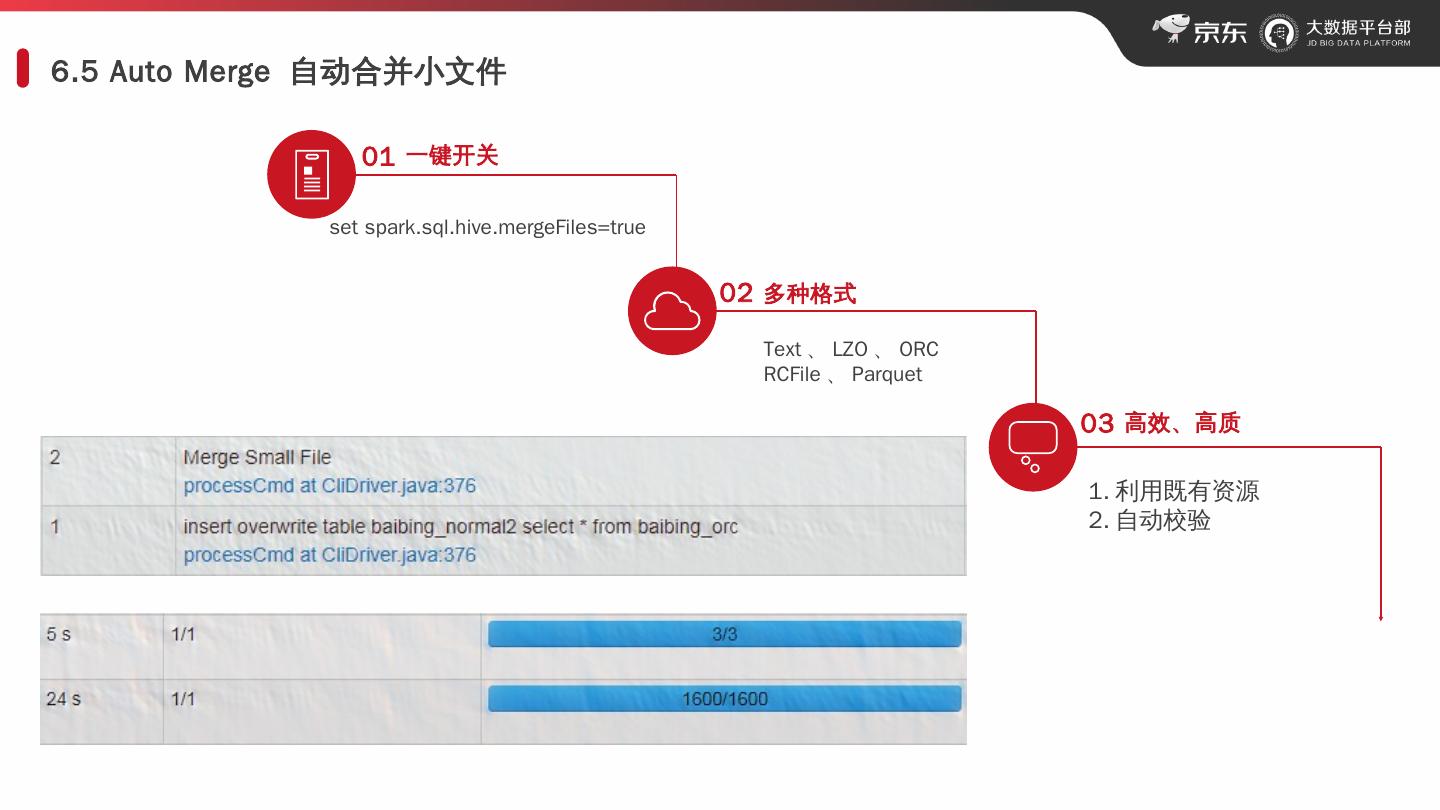
22 .6.5 Auto Merge 自动合并小文件 01 一键开关 set spark.sql.hive.mergeFiles =true 02 多种格式 Text 、 LZO 、 ORC RCFile 、 Parquet 03 高效、高质 利用既有资源 自动校验
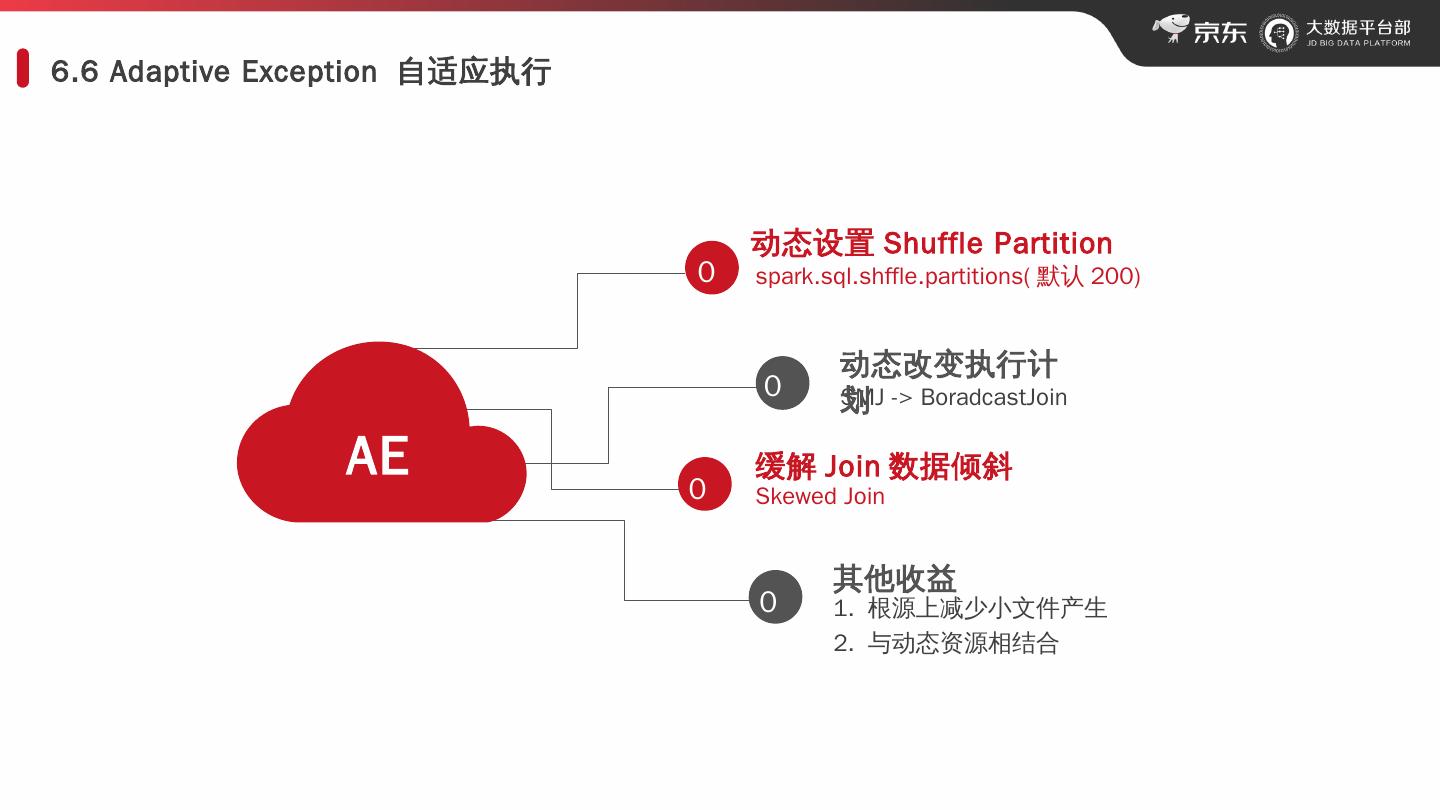
23 .6.6 Adaptive Exception 自适应执行 AE 在此录入上述图表的描述说明,在此录入上述图表的描述说明。 动态设置 Shuffle Partition spark.sql.shffle.partitions ( 默认 200 ) SMJ -> BoradcastJoin 缓解 Join 数据倾斜 Skewed Join 其他收益 1. 根源上减少小文件产生 2. 与动态资源相结合 动态 改变 执行计划 01 0 2 0 3 0 4
24 .平台技术 交流 群 :7090874 Spark 技术交流群 :7263427 欢迎加入