













































































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MongoDB Sharded Cluster Tutorial
-群集组件
-收集碎片
-查询路由
-平衡
-区域
-用例
-备份
-故障排除
展开查看详情
1 .MongoDB Sharded Cluster Tutorial Paul Agombin, Maythee Uthenpong 1
2 .Introductions Paul Agombin paul.agombin@objectrocket.com 2
3 . • Sharded Cluster Components • Collection Sharding Agenda • Query Routing • Balancing • Backups • Troubleshooting • Zones 3
4 .Objectives ● What problems sharding attempts to solve ● When sharding is appropriate ● The importance of the shard key and how to choose a good one ● Why sharding increases the need for redundancy ● Most importantly - how a Sharded Cluster Operates 4
5 .What is Sharding ● Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations. ● What happens when a system is unable to handle the application load? ● It is time to consider scaling. ● There are 2 types of scaling we want to consider: – Vertical scaling – Horizontal scaling 5
6 .Vertical Scaling ● Adding more RAM, faster disks, etc. ● When is this the solution? ● First, consider a concept called the working set. ○ The working set is the portion of your data that clients access most often. ○ Your working set should stay in memory to achieve good performance. Otherwise many random disk IO’s will occur (page faults), and unless you are using SSD, this can be quite slow. 6
7 .Limitations of Vertical Scaling ● There is a limit to how much RAM one machine can support. ● There are other bottlenecks such as I/O, disk access and network. ● Cost may limit our ability to scale up. ● There may be requirements to have a large working set that no single machine could possible support. ● This is when it is time to scale horizontally. 7
8 .Contrast with Replication ● This should never be confused with sharding. ● Replication is about high availability and durability. ○ Taking your data and constantly copying it ○ Being ready to have another machine step in to process requests in case of: ■ Hardware failure ■ Datacenter failure ■ Service interruption 8
9 .Sharding Overview ● MongoDB enables you to scale horizontally through sharding. ● Sharding is about adding more capacity to your system. ● MongoDB’s sharding solution is designed to perform well on commodity hardware. ● The details of sharding are abstracted away from applications. ● Queries are performed the same way as if sending operations to a single server. ● Connections work the same by default. 9
10 .When to Shard ● If you have more data than one machine can hold on its drives ● If your application is write heavy and you are experiencing too much latency. ● If your working set outgrows the memory you can allocate to a single machine. Dividing Up Your Dataset 10
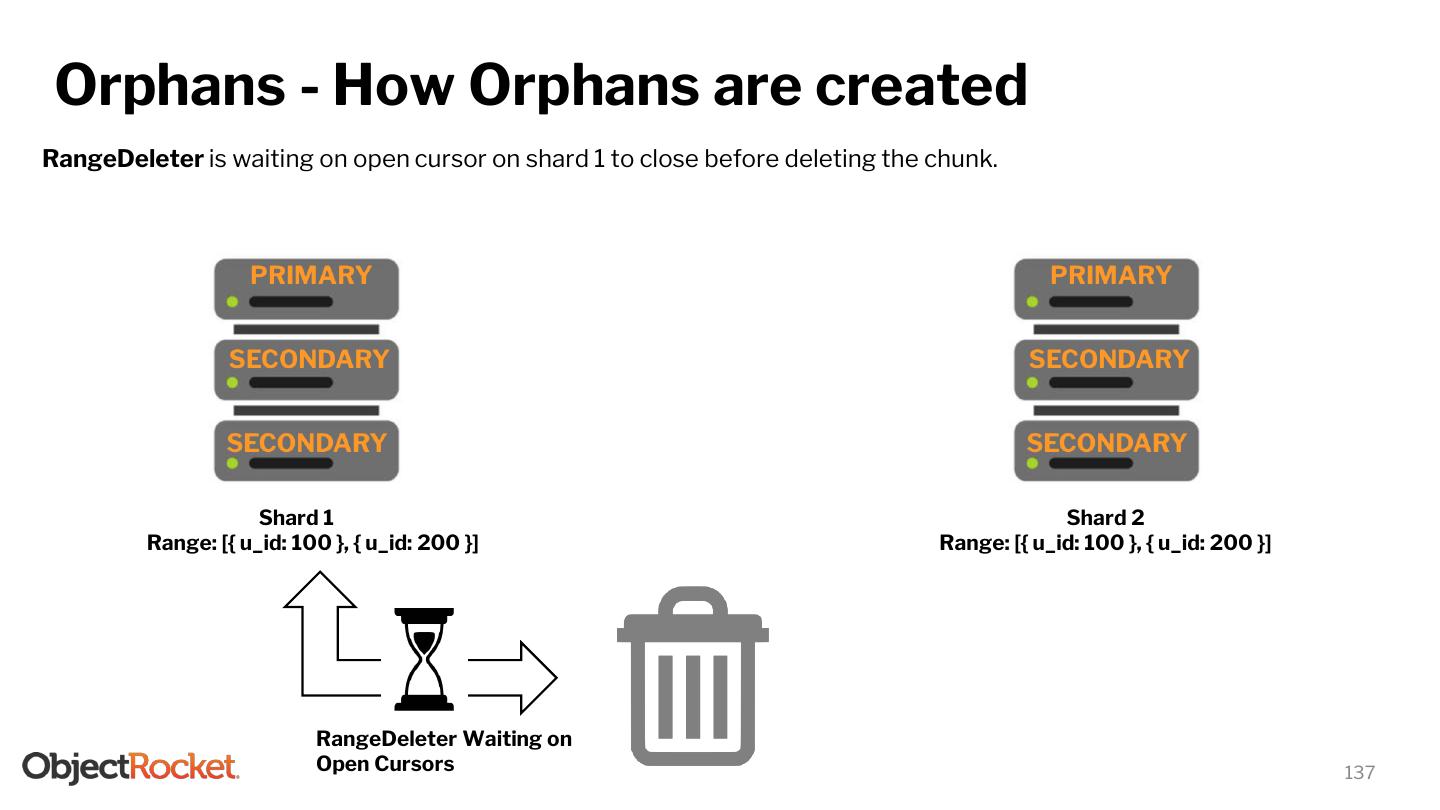
11 .Key Terms ● Replica set - a group of mongod processes instances that share the same data. A replica set comprises of the following: ○ Primary - Node responsible for writes/and reads. ○ Secondaries - Node that holds replicated data from the primary and can be used for reads. ● Sharding - partitioning of data into multiple replica sets which can reside on the same server (vertical sharding) or different servers (horizontal sharding) ● Shard Key - the field of a collection (table) that will be used to partition the data. ● Chunks - Data in mongo is partitioned into chunks. Default size of a chunk is 64MB. ● Balancer - The balancer is a process responsible for distributing the chunks evenly among the shards 11
12 .Sharded Cluster Components CSRS 12
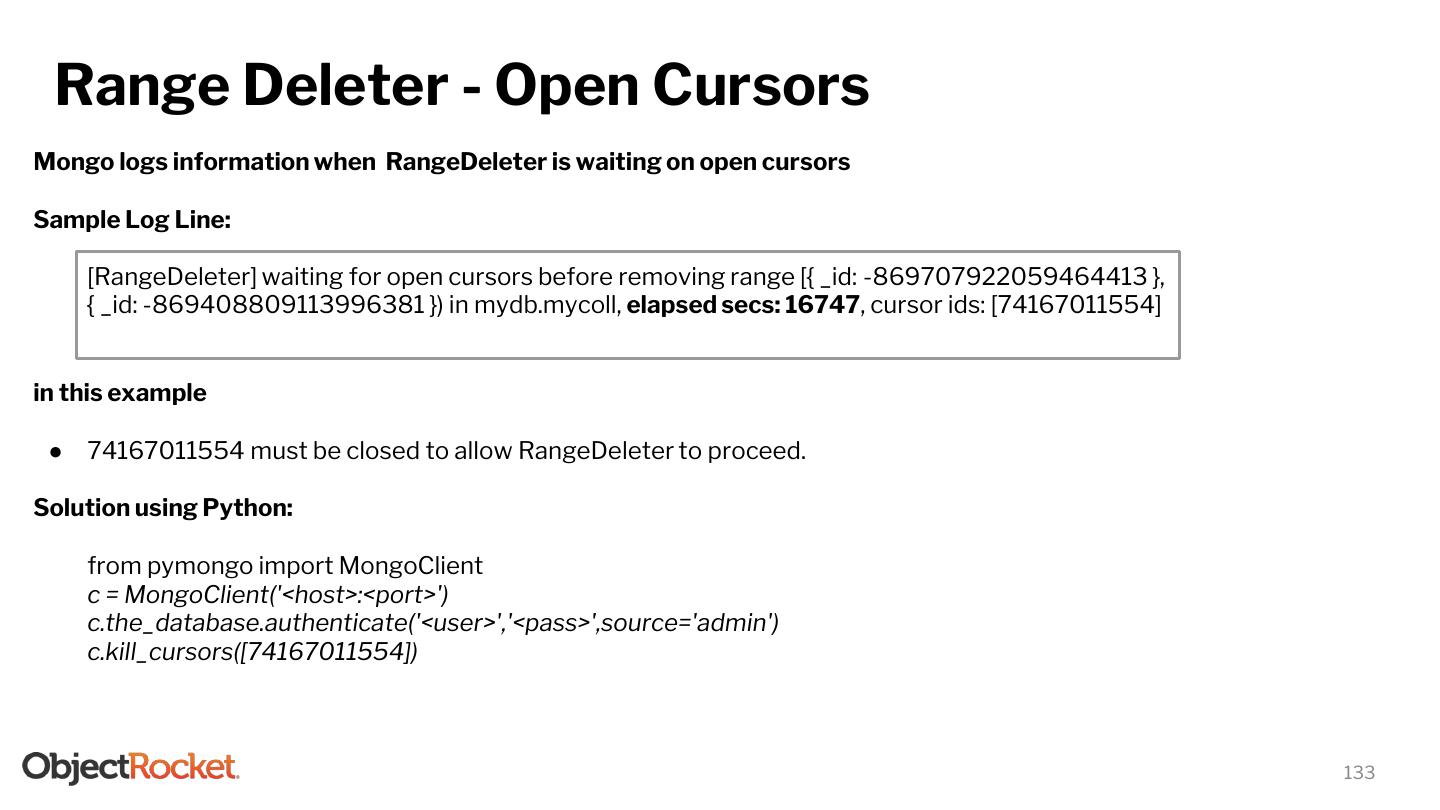
13 .Sharded Cluster Components - Config Server ● Config servers store the metadata for a sharded cluster. ○ The metadata reflects state and organization for all data and components within the sharded cluster. ○ The metadata includes the list of chunks on every shard and the ranges that define the chunks. ● The mongos instances cache this data and use it to route read and write operations to the correct shards and updates the cache when there are metadata changes for the cluster, such as moveChunk, Chunk Splits. ● It holds the admin database that contains collections related to authentication and authorization as well as other system collections that MongoDB uses internally. ● From MongoDB 3.2, config servers for sharded clusters can be deployed as a replica set (CSRS) instead of three mirrored config servers (SCCC) to provide greater consistency. ● Config server replica set must run the WiredTiger Storage Engine. ● From MongoDB 3.4 and above, config servers must run as replica set ● Config server replica set must: ○ Have zero arbiters. ○ Have no delayed members. ○ Build indexes (i.e. no member should have buildIndexes setting set to false). ● If the config server replica set loses its primary and cannot elect a primary, the cluster’s metadata becomes read only. You can still read and write data from the shards, but no chunk migration or chunk splits will occur until the replica set can elect a prim ary. 13
14 .Sharded Cluster Components - Config Server The config database contains the following collections: ● config.changelog The changelog collection stores a document for each change to the metadata of a sharded collection such as moveChunk, split chunk, dropDatabase, dropCollection as well other administrative task like addShard ● config.chunks The chunks collection stores a document for each chunk in the cluster. ● config.collections The collections collection stores a document for each sharded collection in the cluster. It also tracks whether a collection has autoSplit enabled for not using the noBalance flag (This flag doesn’t exist by default) ● config.databases The databases collection stores a document for each database in the cluster, and tracks if the database has sharding enabled with the {"partitioned" : <boolean>} flag. ● config.lockpings The lockpings collection keeps track of the active components in the sharded cluster - the mongos, configsvr, shards ● config.locks Stores the distributed locks. The balancer no longer takes a “lock” starting in version 3.6. 14
15 .Sharded Cluster Components - Config Server ● config.mongos The mongos collection stores a document for each mongos instance that's associated with the cluster. Mongos instances send pings to all members of the cluster every 30 seconds so the cluster can verify that the mongos is active. ● config.settings The settings collection holds sharding configuration settings such as Chunk size, Balancer Status and AutoSplit ● config.shards This collection holds documents that represents each shard in the cluster - one document per shard. ● config.tags The tags collection holds documents for each zone range in the cluster. ● config.version The version collection holds the current metadata version number. ● config.system.sessions Available in MongoDB 3.6, the system.sessions collection stores session records that are available to all members of the deployment. ● config.transactions The transactions collection stores records used to support retryable writes for replica sets and sharded clusters. 15
16 .Sharded Cluster Components - MongoS ● MongoDB mongos instances route queries and write operations to shards in a sharded cluster. It acts as the only interface to a sharded cluster from an application perspective. ● The mongos tracks what data is on which shard by caching the metadata from the config servers then use the metadata to access the shards directly to serve clients request. ● A mongos instance routes a query to a cluster by: ○ Determining the list of shards that must receive the query. ○ Establishing a cursor on all targeted shards. ● The mongos merges the results from each of the targeted shards then return them to the client. ○ Query modifiers such as sort() are performed at the shard level. ○ From MongoDB 3.6, aggregations that run on multiple shards but do not require running on the Primary Shard would route the results back to the mongos where they are then merged. ● There are two cases where a pipeline is not eligible to run on a mongos: ○ An aggregation pipeline contains a stage which must run on a primary shard. For example, the $lookup stage of an aggregation that must access data from an unsharded collection in the same database on which the aggregation is running. The results are merged on the Primary Shard. 16
17 .Sharded Cluster Components - MongoS ○ A pipeline contains a stage which may write temporary data to disk, such as $group, and the client has specified allowDiskUse:true. Assuming that there is no other stage in the pipeline that requires the Primary Shard, the merging of results would take place on a random shard. ● Use explain:true as a parameter to the aggregation() call to see how the aggregation is split among components of a sharded cluster query. ○ mergeType shows where the stage of the merge happens, that is, “primaryShard”, “anyShard”, or “mongos”. The MongoS and Query Modifiers ● Limit: ○ If the query contains a limit() to limit results set, then the mongos would pass the limit to the shards and re- apply the limit before returning results to the client. ● Sort: ○ If the results are not sorted, then the mongos opens a cursor on all the shards to retrieves results in a "round robin" fashion. ● Skip: ○ If the query includes a skip(), then the mongos cannot pass the skip to the shards but rather retrieves the unskipped results and skips the appropriate number of documents when assembling the results. 17
18 .Sharded Cluster Components - MongoS Targeted Vs. BroadCast Operations. Broadcast Operations ● These are queries that do not include the shardkey and as such, the mongos has to query each shard in the cluster, wait for results before returning them to the client. This is also known as “scatter/gather” queries and can be expensive operations. ● Its performance is dependent on the overall load in the cluster, the number of shards involved, the number of documents returned per shard and the network latency. Targeted Operations ● These are queries that include the shardkey or the prefix of a compound shard key. ● The mongos would use the shard key value to locate the chunk whose range includes the shard key value and directs the query at the shard containing that chunk. 18
19 .Sharded Cluster Components - Shards ● Contains a subset of sharded data for a sharded cluster. ● Shard must be deployed as replicasets as of MongoDB 3.6 to provide high availability and redundancy. ● User request should never be driven directly to the shards - unless when performing administrative task. ○ Performing read operations on the shard would only return a subset of data for sharded collections in a multi shard setup. Primary Shard ● All databases in a sharded cluster has a Primary database that holds all un-sharded collections for that database ● Do not confuse the Primary shard with the Primary of a replica set. ● The mongos selects the primary shard when creating a new database by picking the shard in the cluster that has the least amount of data. ○ The Mongos uses the totalSize field returned by the listDatabase command as a part of the selection criteria. ● To change the primary shard for a database, use the movePrimary command. ○ Avoid accessing an un-sharded collection during migration. movePrimary does not prevent reading and writing during its operation, and such actions yield undefined behavior. ○ You must either restart all mongos instances after running movePrimary, or use the flushRouterConfig command on all mongos instances before reading or writing any data to any unsharded collections that were moved. This ensures that the mongos is aware of the new shard for these collections. 19
20 .Deploying ● Minimum requirements: 1 mongos, 1 config server , 1 shard (1 mongod process) - shards must run as a replicaset as of MongoDB 3.6 ● Recommended setup: 2+ mongos, 3 config servers, 1 shard (3 node replica-set) ● Ensure connectivity between machines involved in the sharded cluster ● Ensure that each process has a DNS name assigned - Not a good idea to use IPs ● If you are running a firewall you must allow traffic to and from mongoDB instances Example using iptables: iptables -A INPUT -s -p tcp --destination-port -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -d -p tcp --source-port -m state --state ESTABLISHED -j ACCEPT 20
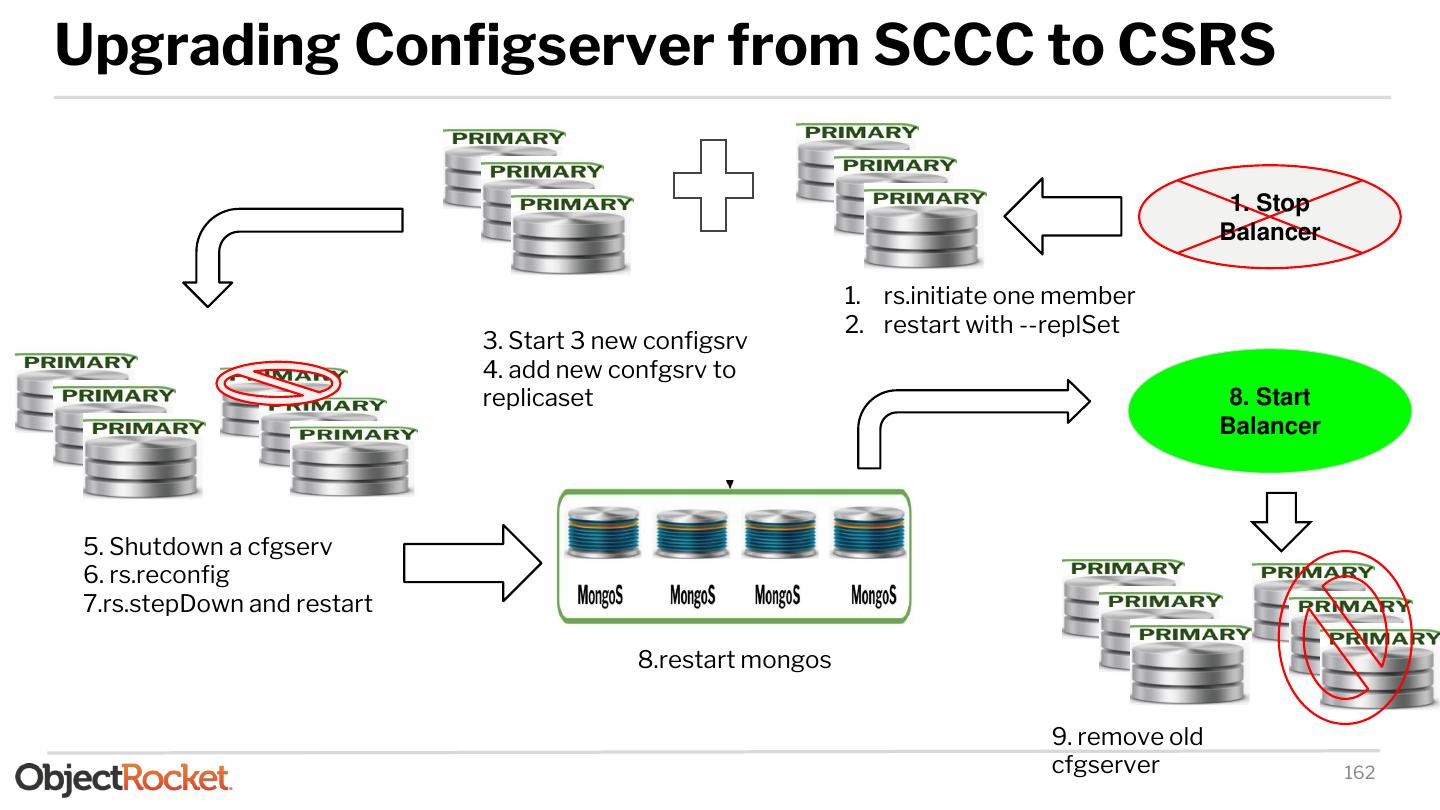
21 .Deploying - Config Servers Create a keyfile: ● keyfile must be between 6 and 1024 characters long ● Generate a 1024 characters key: openssl rand -base64 756 > <path-to-keyfile> ● Secure the keyfile chmod 400 <path-to-keyfile> ● Copy the keyfile to every machine involves to the sharded cluster Create the config servers: ● Before 3.2 config servers could only run on SCCC topology ● On 3.2 config servers could run on either SCCC or CSRS ● On 3.4 only CSRS topology supported ● CSRS mode requires WiredTiger as the underlying storage engine ● SCCC mode may run on either WiredTiger or MMAPv1 Minimum configuration for CSRS mongod --keyFile <path-to-keyfile> --configsvr --replSet <setname> --dbpath <path> 21
22 .Deploying - Config Servers Baseline configuration for config server (CSRS) net: port: '<port>' processManagement: fork: true security: authorization: enabled keyFile: <keyfile location> sharding: clusterRole: configsvr replication: replSetName: <replicaset name> storage: dbPath: <data directory> systemLog: destination: syslog 22
23 .Deploying - Config Servers Login on one of the config servers using the localhost exception. Initiate the replica set: rs.initiate( { _id: "<replSetName>", configsvr: true, members: [ { _id : 0, host : "host:port" }, { _id : 1, host : "host:port" }, { _id : 2, host : "host:port" } ] } ) Check the status of the replica-set using rs.status() 23
24 .Deploying - Shards Create shard(s): ❏ For production environments use a replica set with at least three members ❏ For test environments replication is not mandatory in version prior to 3.6 ❏ Start three (or more) mongod process with the same keyfile and replSetName ❏ ‘sharding.clusterRole’: shardsrv is mandatory in MongoDB 3.4 ❏ Note: Default port for mongod instances with the shardsvr role is 27018 Minimum configuration for shard mongod --keyFile <path-to-keyfile> --shardsvr --replSet <replSetname> --dbpath <path> ❏ Default storage engine is WiredTiger ❏ On a production environment you have to populate more configuration variables , like oplog size 24
25 .Deploying - Shards Baseline configuration for shard net: port: '<port>' processManagement: fork: true security: authorization: enabled keyFile: <keyfile location> sharding: clusterRole: shardsrv replication: replSetName: <replicaset name> storage: dbPath: <data directory> systemLog: destination: syslog 25
26 .Deploying - Shards Login on one of the shard members using the localhost exception. Initiate the replica set: rs.initiate( { _id : <replicaSetName>, members: [ { _id : 0, host : "host:port" }, { _id : 1, host : "host:port" }, { _id : 2, host : "host:port" } ] } ) ● Check the status of the replica-set using rs.status() ● Create local user administrator (shard scope): { role: "userAdminAnyDatabase", db: "admin" } ● Create local cluster administrator (shard scope): roles: { "role" : "clusterAdmin", "db" : "admin" } ● Be greedy with "role" [ { "resource" : { "anyResource" : true }, "actions" : [ "anyAction" ] }] 26
27 .Deploying - Mongos Deploy mongos: - For production environments use more than one mongos - For test environments a single mongos is fine - Start three (or more) mongos process with the same keyfile Minimum configuration for mongos mongos --keyFile <path-to-keyfile> --config <path-to-config> net: port: '50001' processManagement: fork: true security: keyFile: <path-to-keyfile> sharding: configDB: <path-to-config> systemLog: destination: syslog 27
28 .Deploying - Mongos Login on one of the mongos using the localhost exception. ❖ Create user administrator (shard scope): { role: "userAdminAnyDatabase", db: "admin" } ❖ Create cluster administrator (shard scope): roles: { "role" : "clusterAdmin", "db" : "admin" } Be greedy with "role" [ { "resource" : { "anyResource" : true }, "actions" : [ "anyAction" ] }] What about config server user creation? ❖ All users created against the mongos are saved on the config server’s admin database ❖ The same users may be used to login directly on the config servers ❖ In general (with few exceptions), config database should only be accessed through the mongos 28
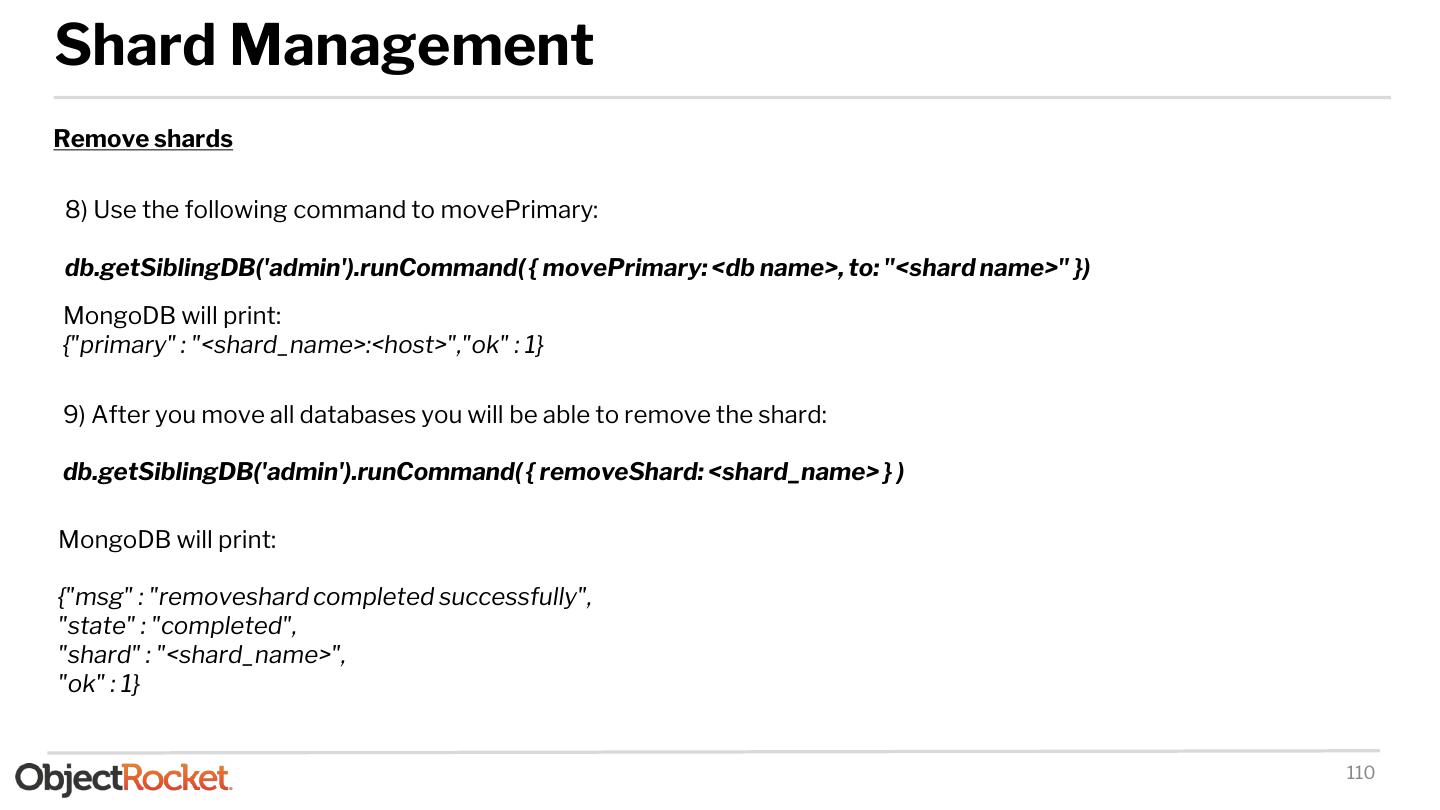
29 .Deploying - Sharded Cluster Login on one of the mongos using the cluster administrator ❏ sh.status() prints the status of the cluster ❏ At this point shards: should be empty ❏ Check connectivity to your shards Add a shard to the sharded cluster: ❏ sh.addShard("<replSetName>/<host:port>") ❏ You don’t have to define all replica set members ❏ sh.status() should now display the newly added shard ❏ Hidden replica-set members are not appear on the sh.status() output You are now ready to add databases and shard collections!!! 29
3秒后跳转登录页面
去登陆

