




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u9501/Demystifying_MySQL_Replication_Crash_Safety?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Demystifying MySQL Replication Crash Safety
分享
点赞
0
收藏
0
下载 0
在MySQL5.5之前,复制不具有崩溃安全性:崩溃后,复制将失败,并出现“Duplicate key”或“Row not found”错误,或者可能会导致静默数据损坏。看起来5.6好多了,对吧?简短的答案可能是:在最简单的情况下,可以实现复制崩溃安全,但这不是默认设置。MySQL5.7并没有太好,8.0有更安全的默认值,但仍然很容易出错。
崩溃安全受复制定位(文件+pos或gtid)、类型(单线程或mts)、mts设置(数据库或逻辑时钟,有或没有slave preserve commit顺序)、中继日志的同步、二进制日志的存在、日志slave更新及其同步的影响。这是非常复杂的事情,甚至手册都很困惑。
在本次演讲中,我将解释上述影响,并帮助您找到碰撞安全涅盘的道路。我还将提供有关复制内部的详细信息,因此您可能会学到一两件事。
展开查看详情
1 . Demystifying MySQL Replication Crash Safety Presented at Percona Live Europe 2018 in Frankfurt by Jean-François Gagné Senior Infrastructure Engineer / System and MySQL Expert jeanfrancois AT messagebird DOT com
2 .Introducing MessageBird 225+ Direct-to-Carrier Agreements With operators from around the world MessageBird is a cloud communications platform founded in Amsterdam 2011. 15,000+ Customers Examples of our messaging and voice SaaS: In over 60+ countries SMS in and out, call in (IVR) and out (alert), SIP, WhatsApp, Facebook, Telegram, Twitter, WeChat, … 180+ Employees Omni-Channel Conversation Engineering office in Amsterdam Sales and support offices worldwide Details at www.messagebird.com We are expanding : {Software, Front-End, Infrastructure, Data, Security, Telecom, QA} Engineers {Team, Tech, Product} Leads, Product Owners, Customer Support {Commercial, Connectivity, Partnership} Managers www.messagebird.com/careers 2
3 .Summary (Demystifying MySQL Replication Crash Safety – PLEU2018) • Helicopter view of – and then Zoom in – Replication and Crash Safety • MySQL 5.6 solution (and its problems) • Complexifying things with GTIDs and Multi-Threaded Slave (MTS) • Impacts of reducing / compromising durability (sync_binlog != 1 and trx_commit != 1) • Overview of related subjects: Semi-Sync, MariaDB & Pseudo-GTIDs • Closing, links, bugs and questions 3
4 .Overview of MySQL Replication (Demystifying MySQL Replication Crash Safety – PLEU2018) One master with one or more slaves: • The master records transactions in a journal (binary logs); each slave: • Downloads the journal and saves it locally in the relay logs (IO thread) • Executes the relay logs on its local database (SQL thread) • Could also produce binary logs to be a master (log-slave-updates – lsu)
5 .Replication Crash Safety (Demystifying MySQL Replication Crash Safety – PLEU2018) What do I mean by Replication Crash Safety ? • When a slave crashes, it is able to resume replication after recovery (OK if rewinds its state after recovery, as long as it is eventually consistent) • When a master crashes, slaves are able to resume replicating from it • All above without sacrificing data consistency • In other words: ACID is not compromised by a slave or a master crash (Discussion limited to transactional SE: InnoDB, TokuDB, MyRocks; obviously not MyISAM) Intermediate masters (IM) qualify both as master and slave Slaves are potential master (and IM) in some failover strategy (Proving replication crash un-safety is easy, proving safety is hard) 5
6 .State of the Dolphin and of the Sea Lion (Demystifying MySQL Replication Crash Safety – PLEU2018) State of the Dolphin in Replication Crash Safety: • MySQL 5.5 is not crash safe • MySQL 5.6 can be made crash safe (it is not by default) • MySQL 5.7 is mostly the same as 5.6 (with complexity added by Logical Lock parallel replication) • MySQL 8.0 is crash safe by default (but it can be made unsafe by “tuning” the configuration) Quick state of the Sea Lion: • MariaDB 5.5 is not replication crash safe • MariaDB 10.x can be made crash safe 6
7 .Zoom in the details [1 of 3] (Demystifying MySQL Replication Crash Safety – PLEU2018) More details about replication: • The IO Thread stores its state in master info (also configuration stored there) • The SQL Thread in relay log info slave1 [localhost] {msandbox} ((none)) > show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event [...] Master_Log_File: mysql-bin.000001 <-------+-- master info (persisted state) Read_Master_Log_Pos: 25489 <-------+ Relay_Log_File: mysql-relay.000002 <--+ Relay_Log_Pos: 10788 <--+ Relay_Master_Log_File: mysql-bin.000001 <--+-- relay log info (persisted state) [...] | Exec_Master_Log_Pos: 10575 <--+ [...] 7 1 row in set (0.00 sec)
8 .Zoom in the details [2 of 3] (Demystifying MySQL Replication Crash Safety – PLEU2018) More parameters: sync_master_info, sync_relay_log and sync_relay_log_info In MySQL 5.5, master info and relay log info are files: • No atomicity of “making progress” and “state tracking” for IO & SQL Threads • Consistency of actual vs registered state is compromised after a crash 8 Ø This is why replication is not crash-safe in MySQL 5.5
9 .Zoom in the details [3 of 3] (Demystifying MySQL Replication Crash Safety – PLEU2018) Even more parameters: • sync_binlog (and innodb_flush_log_at_trx_commit – trx_commit): • Binlogs are synchronised to disk after every N writes/transactions (default 0 in My|SQL 5.5 and 5.6; and in 5.7 and 8.0 it is 1 which is full ACID) • trx_commit = 1: logs written and flushed each trx (full ACID and default) = 0: written and flushed once per second (not crash safe) = 2: written after each trx and flushed once per second (mysqld crash safe, not OS crash safe) 9
10 .MySQL 5.6 solution [1 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) Reminder: problems making MySQL 5.5 Replication Crash Un-Safe: • The position of the SQL Thread cannot be trusted • The position of the IO Thread cannot be trusted • The content of the Relay Logs cannot be trusted 10
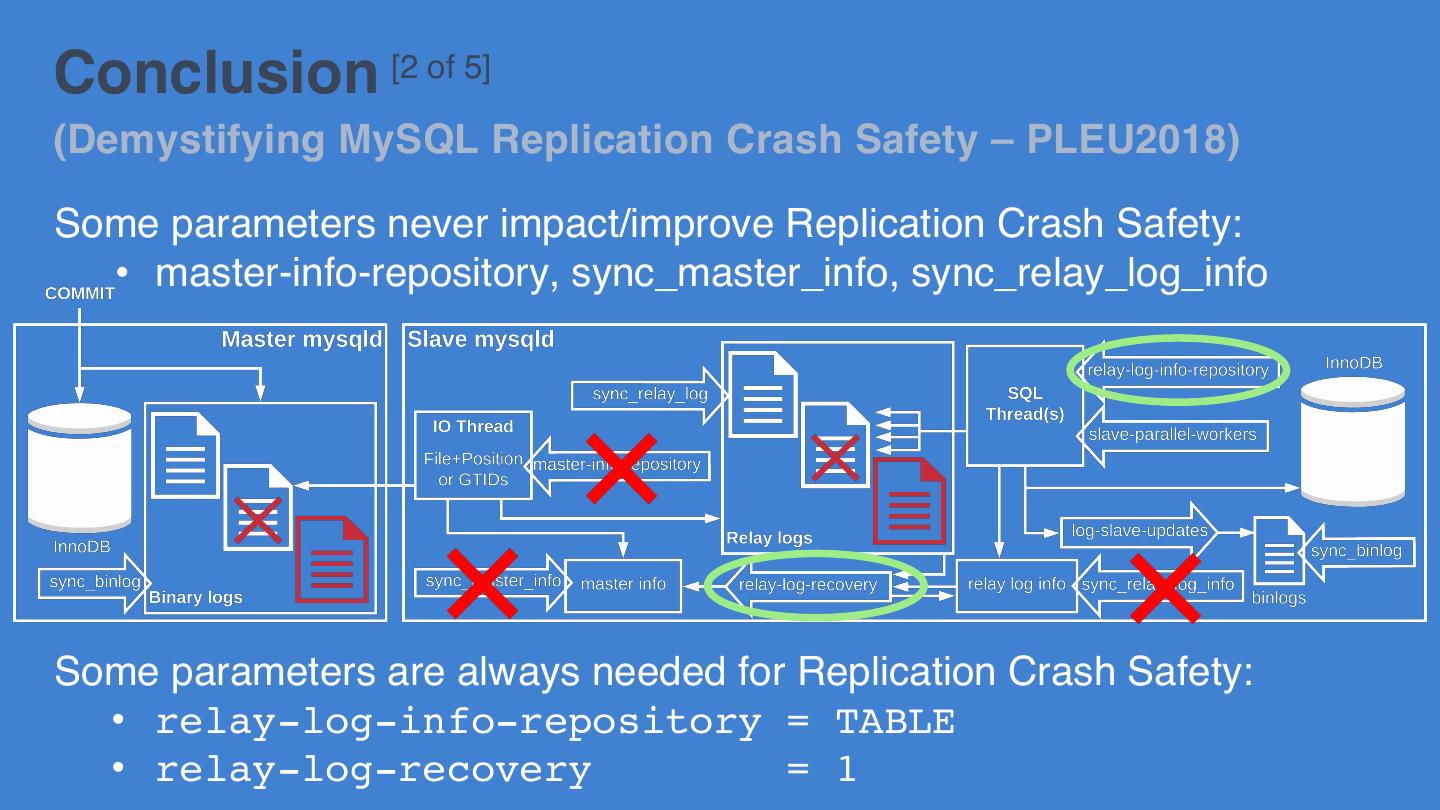
11 .MySQL 5.6 solution [2 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) The MySQL 5.6 solution • Atomicity for SQL Thread: relay-log-info-repository = TABLE (default = FILE) • Useless for crash safety: a parameter to store master info in a table: • master-info-repository = TABLE (default = FILE) • Providing a way to “fix” the relay logs: relay-log-recovery = 1 (default = 0)
12 .MySQL 5.6 solution [3 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) More details about Relay Log Recovery: • relay-log-recovery is only used on mysqld startup (dynamic would be useless) • If relay-log-recovery = 0, nothing special done (and a new relay log is created) • If relay-log-recovery = 1: • The position of the IO Thread is set to the position of the SQL Thread • The position of the SQL Thread is set to the newly created relay log • If relay-log-purge = 1: the old relay logs will be deleted on SQL Thread startup (relay-log-recovery does not delete anything: easy to test with skip-slave-start) Ø Said otherwise, the previous relay logs are skipped ! (those relay logs are considered improper for SQL Thread consumption) • This will happen even if MySQL (or the IO Thread) did not crash OK for 1st implementation but a waste of perfectly good relay logs 12
13 .MySQL 5.6 solution [4 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) In MySQL 5.7: • No change of defaults (for replication crash safety) • Relay log recovery still simplistic K In MySQL 8.0: • Still simplistic relay log recovery L • New defaults: • relay-log-info-repository = TABLE J • relay-log-recovery = 1 J • master-info-repository = TABLE (not sure this is very useful) Bug#74323: Avoid overloading the master NIC on relay-log-recovery of a lagging slave Bug#74321: Execute relay-log-recovery only when needed 13
14 .Adding complexity with GTIDs [1 of 2] (Demystifying MySQL Replication Crash Safety – PLEU2018) Not only MySQL 5.6 introduces replication crash safety, it also introduced Global Transaction IDs (GTIDs) • This tags every transaction with an ID when writing to the binlogs • The GTID state of the master and slaves are tracked in the binlogs Ø IO and SQL Thread states are now partially in the binlogs (and relay logs) • Optionally, slaves can use GTID to replicate (instead of file+position) • This allows easier repointing of slaves to a new master (including fail over) • This heavily relies on precise tracking of GTID states on master and slaves Ø As this tracking is in the binlogs, this is impeded when sync_binlog != 1 Bug#70659: Make crash safe slave with gtid + less durable settings 14
15 .Adding complexity with GTIDs [2 of 2] (Demystifying MySQL Replication Crash Safety – PLEU2018) To make replication crash safe with GTIDs in MySQL 5.6: • relay-log-info-repository = TABLE (default = FILE) • relay-log-recovery = 1 (default = 0) – (Bug#92093) • sync_binlog = 1 (default = 0) • In 5.7, the default is sync_binlog = 1 J (two other unchanged K) • In 8.0, all the defaults are good for crash safe replication with GTID J J • MySQL 5.7 adds a table for storing the GTID state of slaves: • Allows GTIDS slaves without log-slave-updates (lsu) • With lsu, this table (mysql.gtid_executed) is not updated after each trx Ø Missed opportunity for OS crash safety with sync_binlog != 1 L L L Bug#92109: Make GTID replication crash safe with less durable setting 15
16 .Master Replication Crash Safety [1 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) Relaxing durability of the binlogs implies losing GTID state (after an OS crash) • What about the consequence on the master ? With and without GTID ? • If sync_binlog != 1 on the master, an OS crash will lose binlogs • With sync_binlog != 1, usually trx_commit != 1 (normally 2, but can be 0) • trx_commit = 2 preserves data on mysqld crashes, 0 does not (à 2 is better) Ø InnoDB will also lose transactions on an OS crash Ø After an OS crash, InnoDB will be out-of-sync with the binlogs Ø And we cannot trust the binlogs on such master (trx gap or ghost trx) The failure mode will be different depending on the configuration 16
17 .Master Replication Crash Safety [2 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) With file+position • IO Thread in vanished binlogs • So slaves executed phantom trx (ghost in binlogs, maybe not in InnoDB) • When the master is restarted: • It records trx in new binlog file • Most slaves are broken, and they might be out-of-sync with each-others • Some lagging slave might skip vanished binlogs 17
18 .Master Replication Crash Safety [2 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) With file+position • IO Thread in vanished binlogs • So slaves executed phantom trx (ghost in binlogs, maybe not in InnoDB) • When the master is restarted: • It records trx in new binlog file • Most slaves are broken, and they might be out-of-sync with each-others • Some lagging slave might skip vanished binlogs Ø Broken slaves have more data than the master (à data drift) Ø And different data drift on “lucky” lagging slaves that might not break 18
19 .Master Replication Crash Safety [3 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) With GTID enabled • Slave also executed ghost trx vanished from binlogs • But those are in their GTID state • A recovered master reuses GTIDs of the vanished trx • Slaves magically reconnect to the master (MASTER_AUTO_POSITION = 1) 1. If master has not reused all ghost GTIDs, then the slave breaks 2. If it has, then the slave skips the new transactions à more data drift (in illustration, the slave will skip new 50 to 58 as it has the old one) 19
20 .Master Replication Crash Safety [4 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) With GTID enabled but MASTER_AUTO_POSITION = 0 • Left as an exercise to the reader… On the consequences of sync_binlog != 1 (part #1) https://jfg-mysql.blogspot.com/2018/10/consequences-sync-binlog-neq-1-part-1.html (more posts to be published in the series) 20
21 .Master Replication Crash Safety [5 of 5] (Demystifying MySQL Replication Crash Safety – PLEU2018) Summary of running with sync_binlog != 1: • The binlogs – of the master or slave – cannot be trusted after an OS crash • On a master, having mysqld normally restarts after such a crash leads to data drift Ø After an OS crash, make sure no slaves reconnect to the recovered master (OFFLINE_MODE = ON in config file – failing-over to a slave is the way forward) • On slaves, having mysqld restarts after such a crash leads to truncated binlogs Ø After an OS crash, consider purging all binlogs on the recovered slave • Intermediate Masters (IM) are both master and slaves Ø After an OS crash make sure no slaves reconnect to the recovered IM Ø And consider purging all binary logs on it • Remember: GTID state corrupted on slaves after OS crash (Bug#92109) 21
22 .Adding complexity with MTS [1 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) Multi-Threaded Slave (MTS) in MySQL 5.6 is doing out-of-order committing • Same for MySQL 5.7 with DATABASE and LOGICAL_CLOCK types • LOGICAL_CLOCK also has the slave_preserve_commit_order option (OFF by default in 5.7 and 8.0 K, with ON requiring log-slave-updates L) (Bug#75396: Allow slave_preserve_commit_order without log-slave-updates) Example: transactions A, B, C, D, E on the master • On a slave, SHOW SLAVE STATUS points to B, so A is committed • C and E are also committed, B is running and D is pending scheduling (maybe B and D are in the same schema with DATABASE type) With out-of-order commit, a file+position in relay log info is not enough • GTID allows tracking complex position (generating temporary holes on slaves) • And there is the mysql.slave_worker_info table 22 (https://dev.mysql.com/worklog/task/?id=5599: for more details)
23 .Adding complexity with MTS [2 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) Without GTID, resuming replication after a crash needs filling the gap in trx • Manual, error-prone, and not always possible before 5.6.31 and 5.7.13 (Bug#77496) • Now, automated by doing START SLAVE UNTIL SQL_AFTER_MTS_GAPS • But this needs relay logs, which might have vanished after an OS crash (Bug#81840) 23
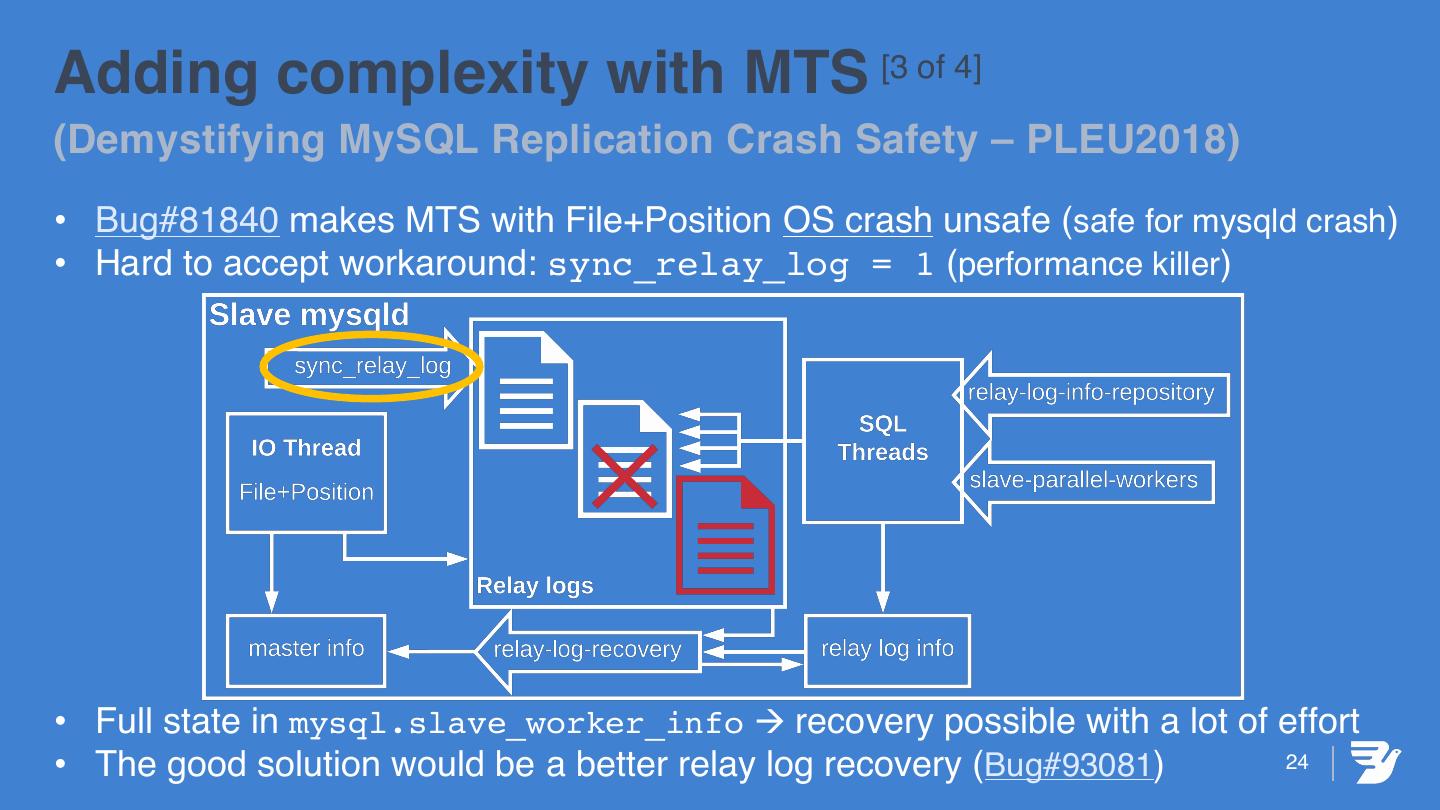
24 .Adding complexity with MTS [3 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) • Bug#81840 makes MTS with File+Position OS crash unsafe (safe for mysqld crash) • Hard to accept workaround: sync_relay_log = 1 (performance killer) • Full state in mysql.slave_worker_info à recovery possible with a lot of effort • The good solution would be a better relay log recovery (Bug#93081) 24
25 .Adding complexity with MTS [4 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) With GTID, MTS in MySQL 5.6, 5.7 & 8.0 is replication crash safe: • But it needs MASTER_AUTO_POSITION = 1 (and relay log recovery Bug#92093) • And it comes with all the GTID “goodies” (rogue transactions, lsu for 5.6, …) • Also needs sync_binlog = 1 (if 5.7+, also works without binlogs or lsu off) • And care with sync_binlog != 1 on the master (need to fail over if OS crash) (sync_binlog != 1 should not be needed in 95% of cases) (Group Commit and MTS make this optimisation almost obsolete) Example: A, B, C, D, E on the master with GTID 10, 11, 12, 13, 14: • GTID executed on the slave is 1-10:12:14 before a crash • Replication resumes by fetching 11:13:15… (after relay log recovery) 25
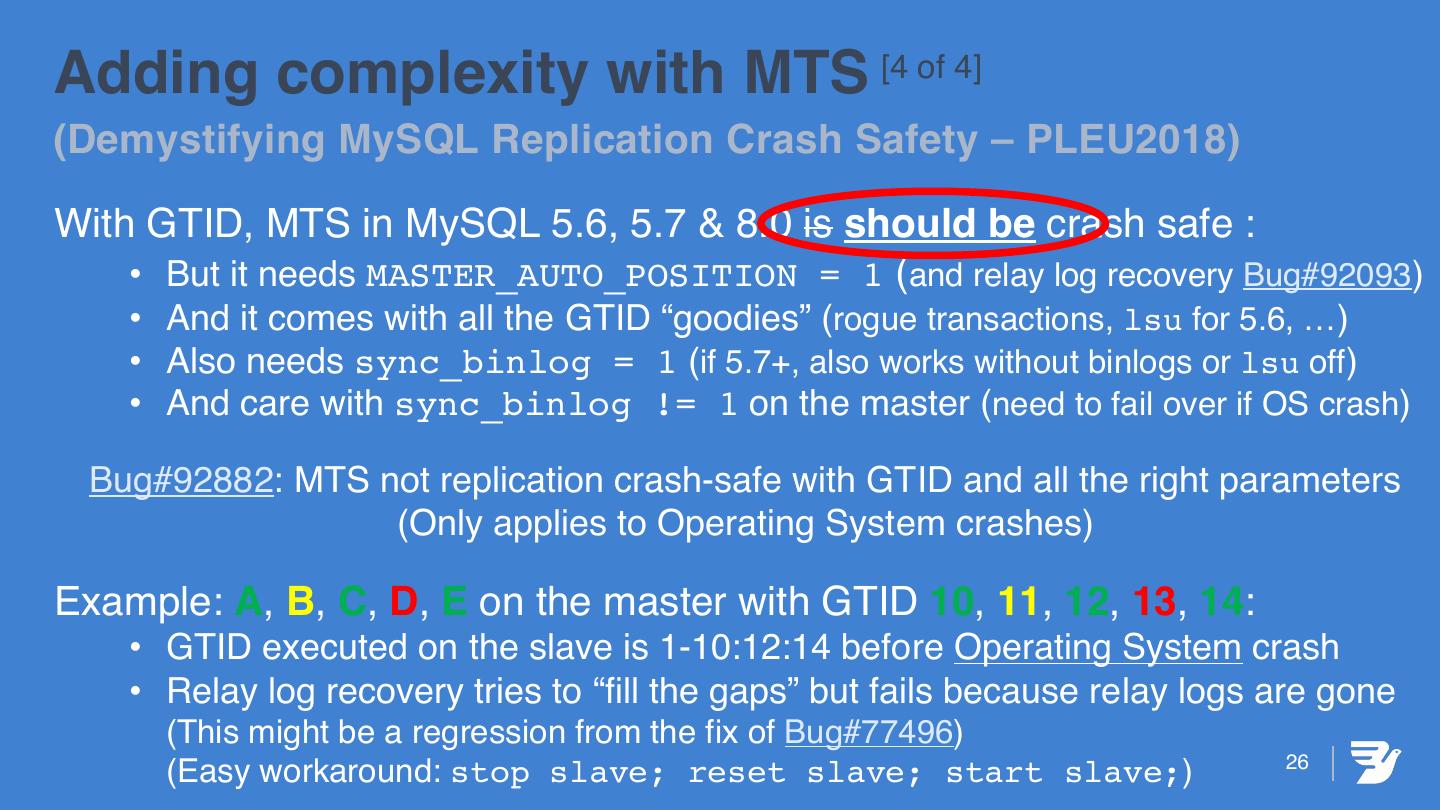
26 .Adding complexity with MTS [4 of 4] (Demystifying MySQL Replication Crash Safety – PLEU2018) With GTID, MTS in MySQL 5.6, 5.7 & 8.0 is should be crash safe : • But it needs MASTER_AUTO_POSITION = 1 (and relay log recovery Bug#92093) • And it comes with all the GTID “goodies” (rogue transactions, lsu for 5.6, …) • Also needs sync_binlog = 1 (if 5.7+, also works without binlogs or lsu off) • And care with sync_binlog != 1 on the master (need to fail over if OS crash) Bug#92882: MTS not replication crash-safe with GTID and all the right parameters (Only applies to Operating System crashes) Example: A, B, C, D, E on the master with GTID 10, 11, 12, 13, 14: • GTID executed on the slave is 1-10:12:14 before Operating System crash • Relay log recovery tries to “fill the gaps” but fails because relay logs are gone (This might be a regression from the fix of Bug#77496) 26 (Easy workaround: stop slave; reset slave; start slave;)
27 .Related subjects – Semi-Sync (Demystifying MySQL Replication Crash Safety – PLEU2018) In this talk, we did not cover master failover explicitly, when a master crashes in an unrecoverable way, failover needs to happen When failing-over to a slave, committed transactions can be lost (Some transactions on the crashed master might not have reached slaves) à violation of durability (ACID) in the replication topology (distributed system) Except if lossless semi-sync is used, more details in: Question about Semi-Synchronous Replication: the Answer with All the Details https://www.percona.com/community-blog/2018/08/23/question-about-semi-synchronous- replication-answer-with-all-the-details/ 27
28 .Related subjects – MariaDB (Demystifying MySQL Replication Crash Safety – PLEU2018) MariaDB still stores its master info and relay log info in files • But it stores GTID state of slaves in the mysql.gtid_slave_pos table Ø MariaDB is replication crash safe when using GTID slave positioning Also, it has an interesting feature: • If using more than one storage engine, a single state table is not optimal • Having one such table per storage engine could be better Improving replication with multiple storage engines (MariaDB 10.3) https://kristiannielsen.livejournal.com/19223.html 28
29 .Related subjects – Pseudo GTIDs (Demystifying MySQL Replication Crash Safety – PLEU2018) Pseudo-GTIDs: • A way to get GTID-like features without GTIDs • They work with any version of MySQL/MariaDB (even 5.5) • But they assume in-order-commit à does not work with MTS They can provide slave replication crash safety: • With log-slave-updates and sync_binlog = 1 • Even on MySQL 5.5 or MariaDB 5.5 https://github.com/github/orchestrator/blob/master/docs/pseudo-gtid.md 29
3秒后跳转登录页面
去登陆

