





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Intel OpenVINO Model Server: AI推理服务快速部署实战及案例分享-赵朝卿
Intel OpenVINO Model Server: AI推理服务快速部署实战及案例分享-赵朝卿
Intel OpenVINO Model Server: AI推理服务快速部署实战及案例分享-赵朝卿
Intel OpenVINO Model Server: AI推理服务快速部署实战及案例分享-赵朝卿
我们身处一个AI无处不在的世界,无论是生产,还是生活,亦或者物流和娱乐,无不充斥着AI的身影。高效且快速的部署好AI服务成了考验算法和工程团队的一个重要环节,这里介绍了英特尔的AI推理服务部署工具OpenVINO Model Server,展示了如何快速且高效的部署AI模型到云-边-端环境中,主要包含四部分内容:
- AI部署的工程化挑战与应对策略
- OpenVINO Model Server工具介绍
- OpenVINO Model Server推理部署实战
- OpenVINO Model Server客户案例分享
赵朝卿 ,英特尔人工智能架构师。人工智能行业深耕十余年,曾供职多家人工智能研究院,从事计算机视觉和语音识别系统的架构设计工作,积累了丰富的实战经验。现任职于英特尔担任AI架构师,从事基于英特尔架构的AI解决方案优化工作。
展开查看详情
1 .Openvino™ Model Server AI推理服务快速部署实战及案例分享 赵朝卿 英特尔人工智能架构师
2 .想象一个 无处不在的世界 2 2
3 .农业 能源 教育 政务 金融 健康 Analytics & AI Everywhere Part of every top 10 strategic technology trend 工业 媒体 零售 智能家居 电信 交通 3 3
4 .议题 1. AI部署的工程化挑战与应对策略 2. OpenVINO™ Model Server工具介绍 3. OpenVINO™ Model Server推理部署实战 4. OpenVINO™ Model Server客户案例分享 4
5 .
6 .深度学习工作流程 人 自行车 算力要求 开 前向 “草莓” 发 阶 训练 ? “自行车” 高 段 反向 误差 草莓 模型权重 部 署 前向 低 阶 推理 “自行车”? 段 6 ?????? 6
7 .推理模型部署 研究 & 开发 生产环境 有了训练好的模型,部署才正式开始 在生产环境中产生实际价值 7
8 .深度学习部署挑战 INTEL® DISTRIBUTION OF OPENVINO™ TOOLKIT 独特的推理需求 集成挑战 没有一刀切方法 训练和部署模型之间存在性能 没有简化的端到端开发工 对多种用例的不同要求需要独 和精度差异 作流程 特的方法 低性能,低精度的模型部署 解决方案慢,部署上线慢 不能满足用例特定的需求 8
9 .AI算力思考 How do you determine the right computing for your AI needs? 工作负载 要求 需求 ASIC/ 1 FPGA/ Utilization GPU 2 3 CPU Scale 工作负载配置是什么? 用例需求是什么? AI在我的环境中有多普遍? 9
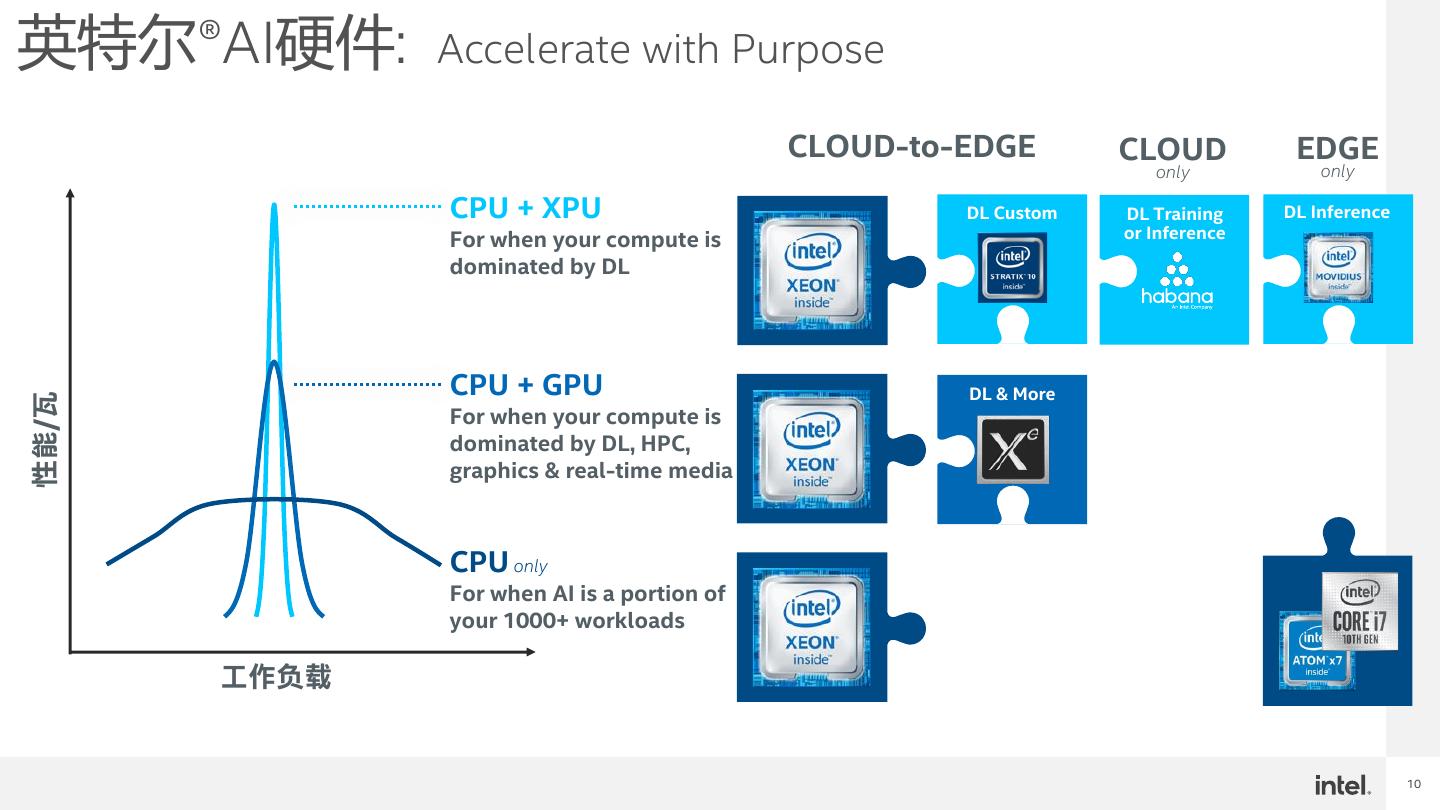
10 .英特尔®AI硬件: Accelerate with Purpose CLOUD-to-EDGE CLOUD EDGE only only CPU + XPU DL Custom DL Training DL Inference For when your compute is or Inference dominated by DL CPU + GPU DL & More 性能/瓦 For when your compute is dominated by DL, HPC, graphics & real-time media CPU only For when AI is a portion of your 1000+ workloads 工作负载 10
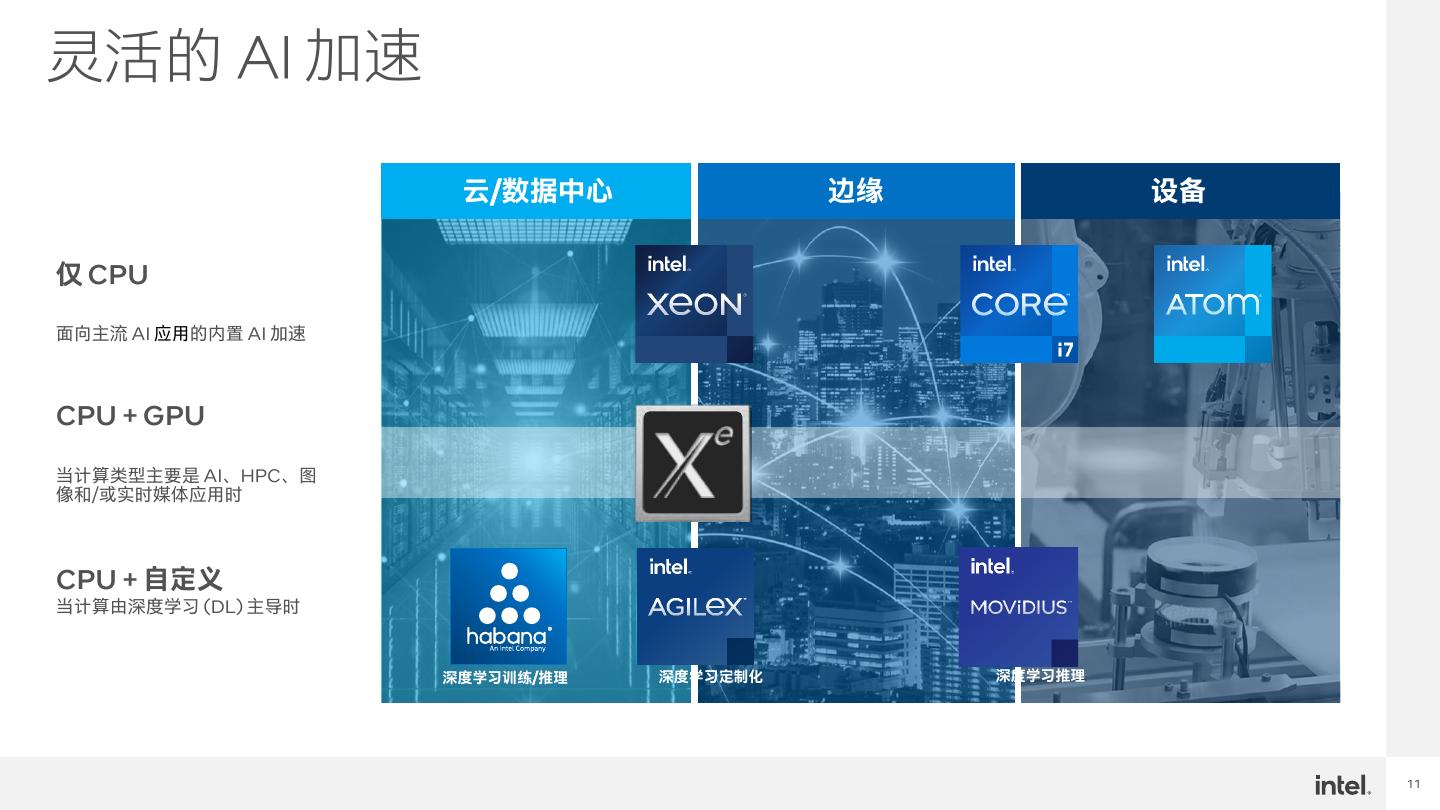
11 .灵活的 加速 云/数据中心 边缘 设备 仅 CPU 面向主流 AI 应用的内置 AI 加速 CPU + GPU 当计算类型主要是 AI、HPC、图 像和/或实时媒体应用时 CPU + 自定义 当计算由深度学习 (DL) 主导时 深度学习训练/推理 深度学习定制化 深度学习推理 11
12 .
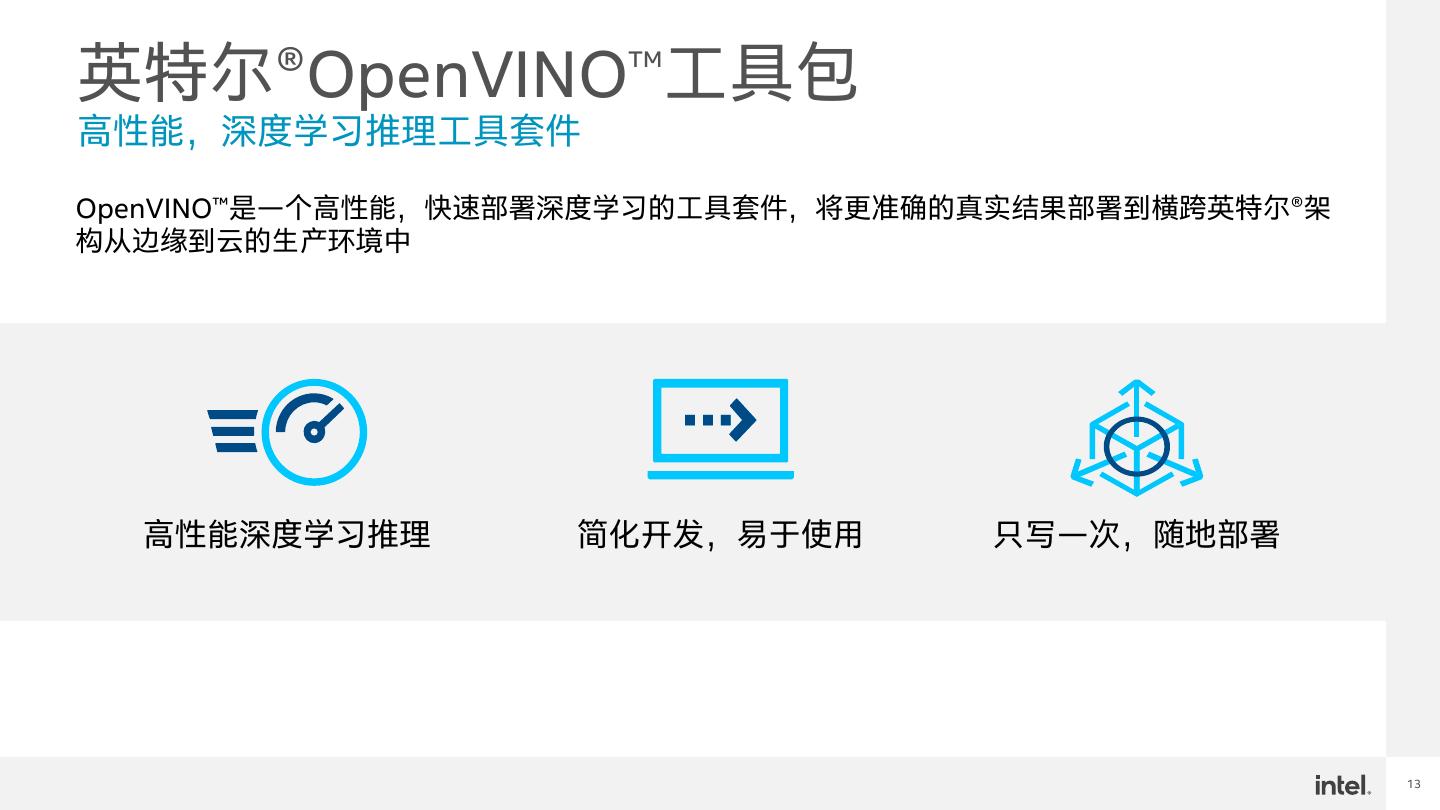
13 .英特尔®OpenVINO™工具包 高性能,深度学习推理工具套件 OpenVINO™是一个高性能,快速部署深度学习的工具套件,将更准确的真实结果部署到横跨英特尔®架 构从边缘到云的生产环境中 高性能深度学习推理 简化开发,易于使用 只写一次,随地部署 13
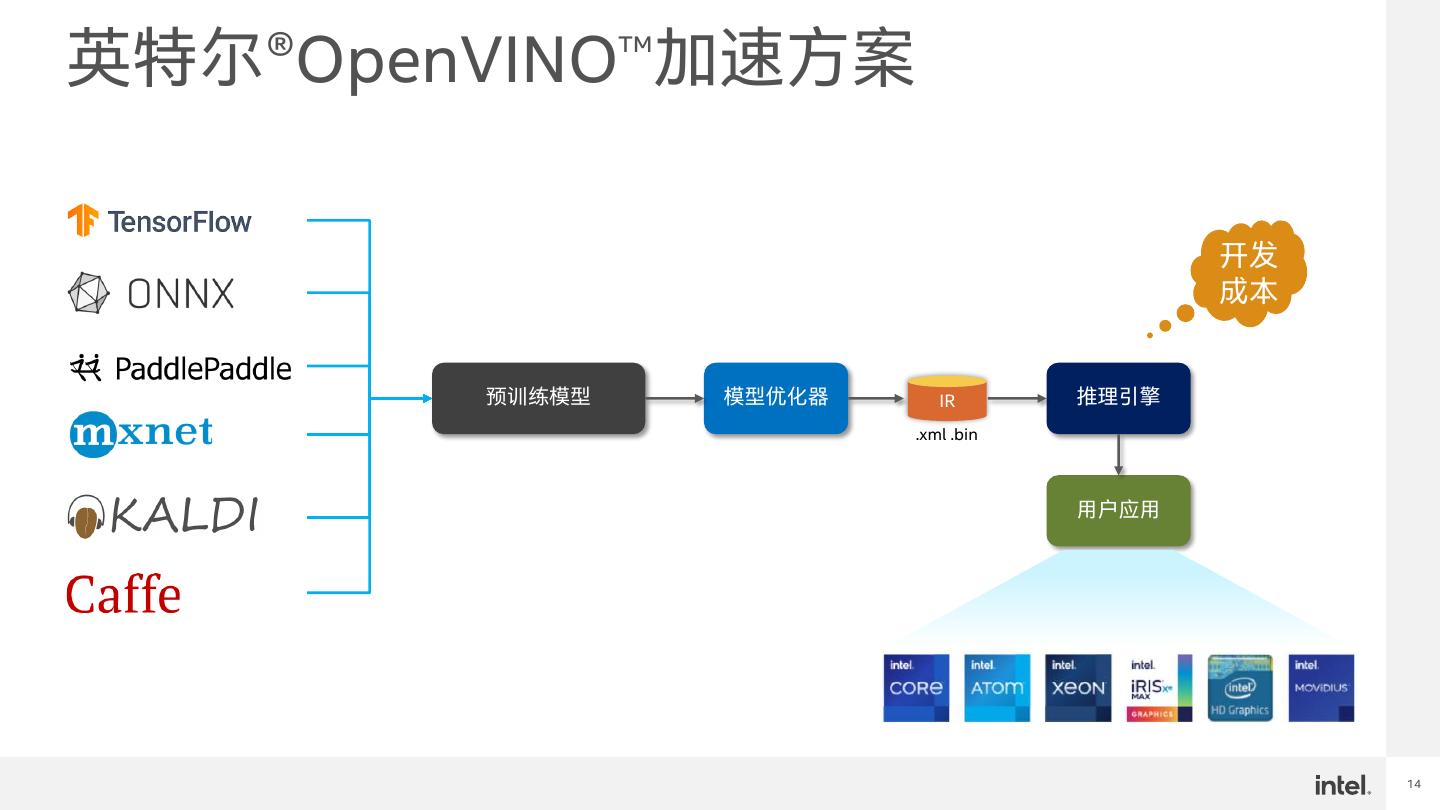
14 .英特尔®OpenVINO™加速方案 开发 成本 预训练模型 模型优化器 IR 推理引擎 .xml .bin 用户应用 14
15 . 英特尔®OpenVINO™ Model Server 一个英特尔开发的,开源的,工业产品级的 模型服务推理平台 OpenVINO™ Model Server • 通过便捷的推理API接口来部署一组模型 gRPC RESTful 是什么? • 推理引擎库来自OpenVINO™工具套件 • 扩展工作负载到英特尔的各种硬件,如CPU,GPU,VPU等 15
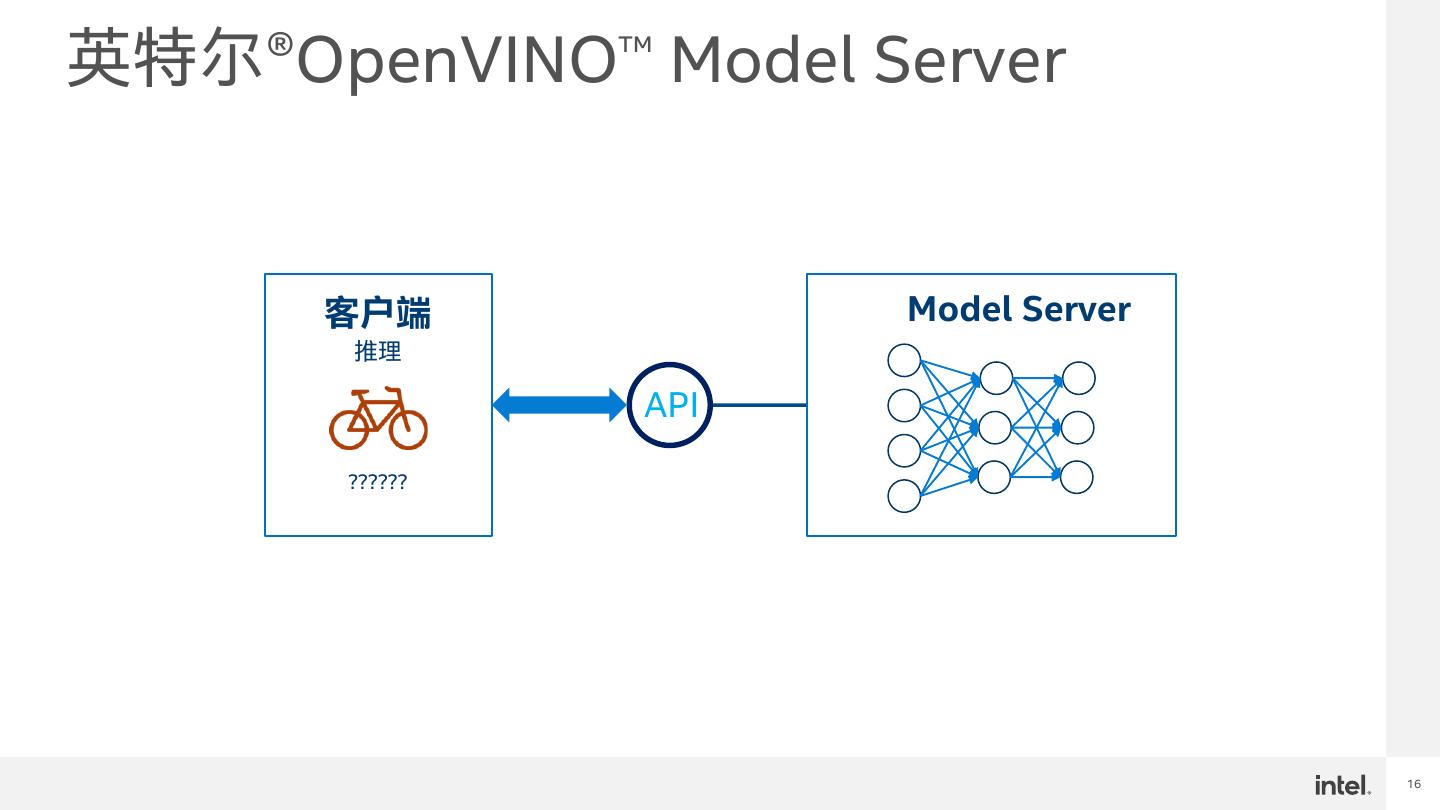
16 .英特尔®OpenVINO™ Model Server 客户端 Model Server 推理 API ?????? 16
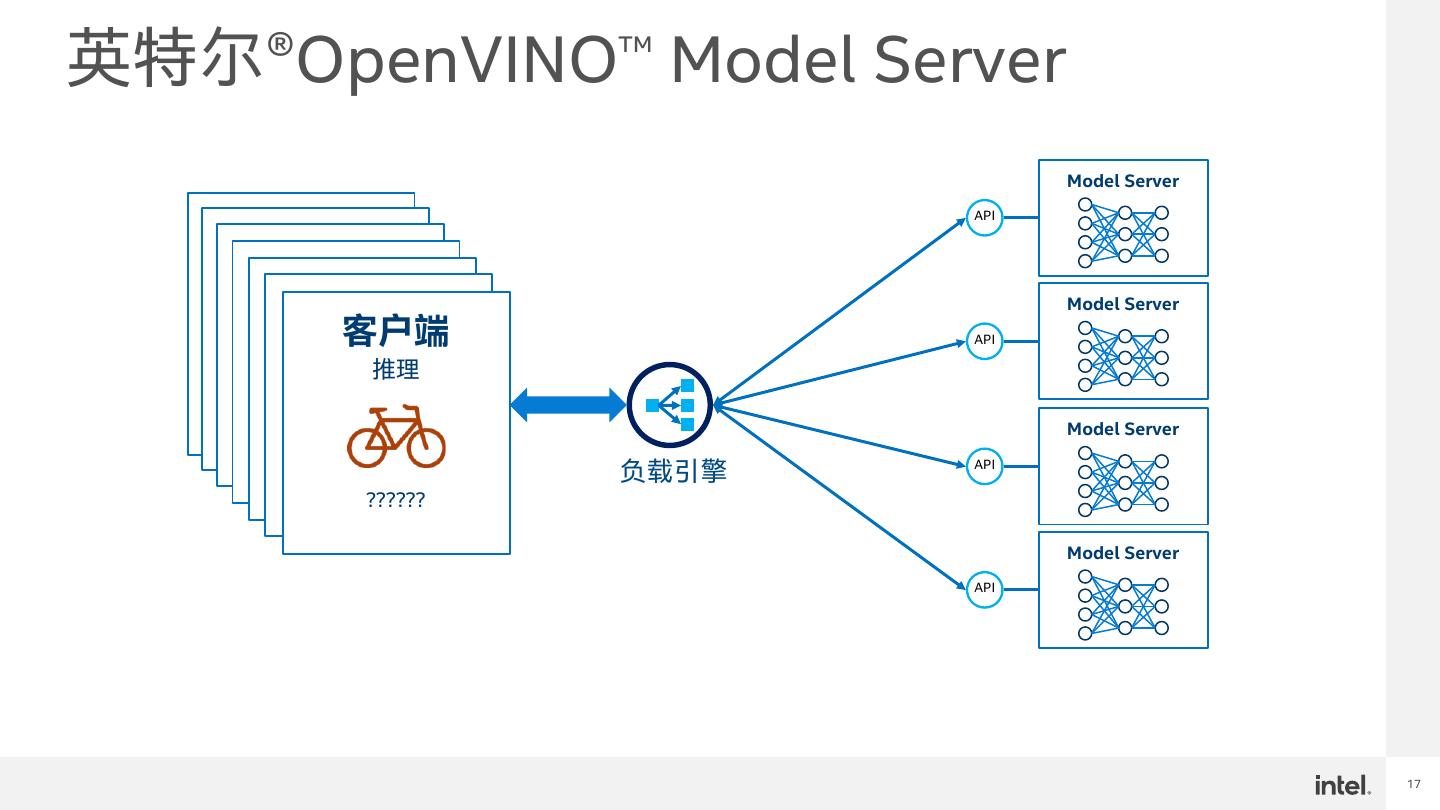
17 .英特尔®OpenVINO™ Model Server Model Server API 客户端 客户端 客户端 推理 客户端 推理 客户端 推理 Model Server 客户端 推理 推理 客户端 推理 API 推理 ?????? ?????? ?????? Model Server ?????? ?????? 负载引擎 API ?????? ?????? Model Server API 17
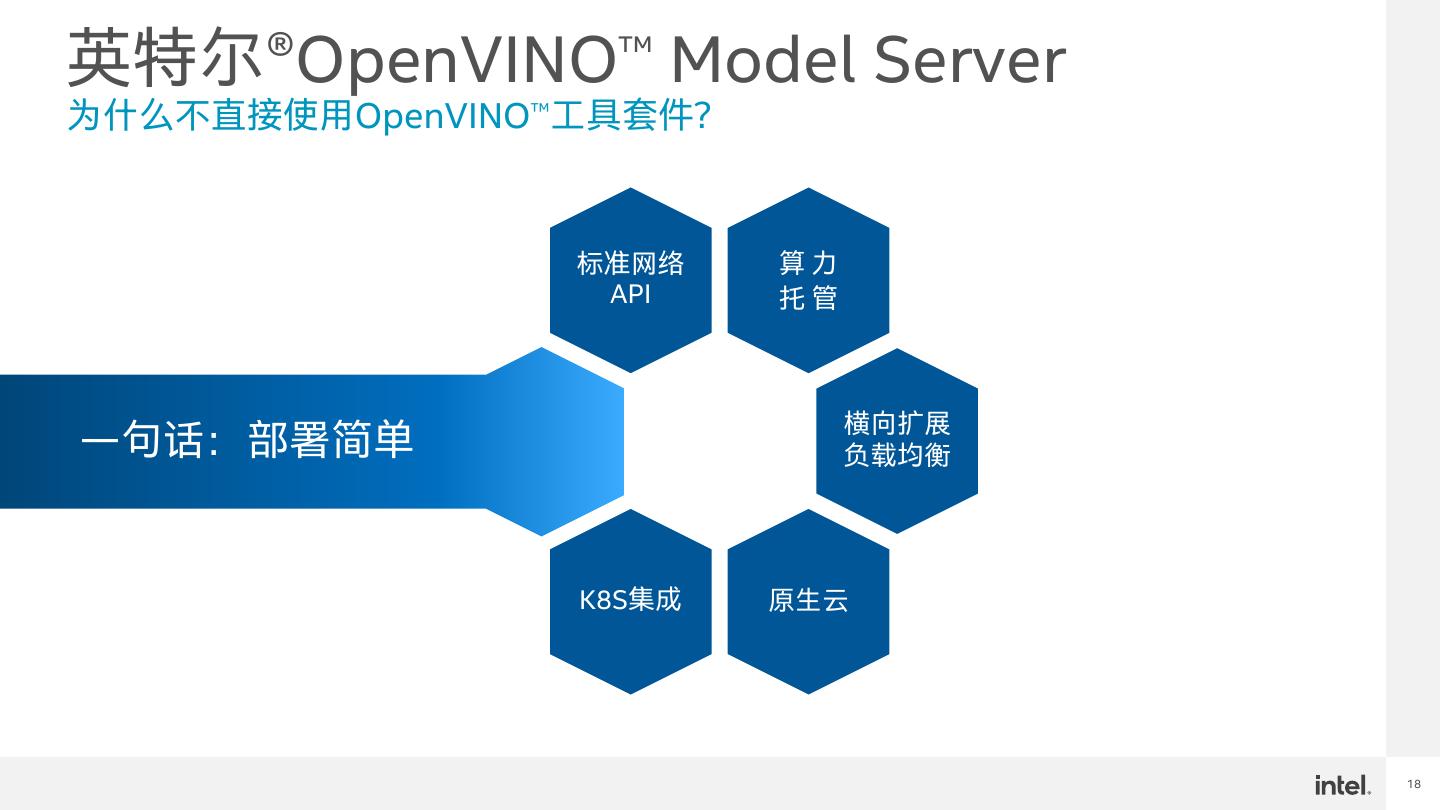
18 .英特尔®OpenVINO™ Model Server 为什么不直接使用OpenVINO™工具套件? 标准网络 算力 API 托管 横向扩展 一句话:部署简单 负载均衡 K8S集成 原生云 18
19 .英特尔®OpenVINO™ Model Server OpenVINO™ Model Server架构 客户端 gRPC endpoint REST endpoint 调度器 配置 模型 管理 管理 容器 OpenVINO 推理 引擎 OpenVINO CPU GPU FPGA HDDL ... 设备插件 OS 处理器 19
20 .英特尔®OpenVINO™ Model Server 主要特性 本地/远程模型 在线配置更新 - 支持本地仓库,也可接远程仓库:GCS,S3,Mino和Azure Blob - 推理线程数,请求处理线程数,BatchSize和算力分配方式等 兼容TF Serving 模型Reshaping - 客户端无需修改,可无缝迁移 -支持auto,单个固定shape,和多个固定shape列表 模型版本策略 Pipeline策略 - 指定一个或多个版本,支持版本热更新 - 可以将多个模型组成一个Pipeline,以整体对外提供推理服务 框架无关 支持带状态的服务 - 可部署多种框架训练的模型,如Tensorflow, PyTorch等 - 支持时序数据的推理,如语音交互,实时翻译等场景 后端无关 支持自定义处理 - 只训练一次,到处运行,如CPU,Myriad, iGPU和HDDL - 级联模型之间或者前后处理的操作可以定制化开发 支持多种部署环境 支持jpeg/png直接请求 - 支持裸金属,虚机和容器方式部署服务 - 客户端可以直接以jpg,jpeg,png格式直接请求服务,减少网络传输开销 注意:裸金属部署只在Ubuntu20.04版本上测过,其他平台建议用容器方式部署 20
21 .
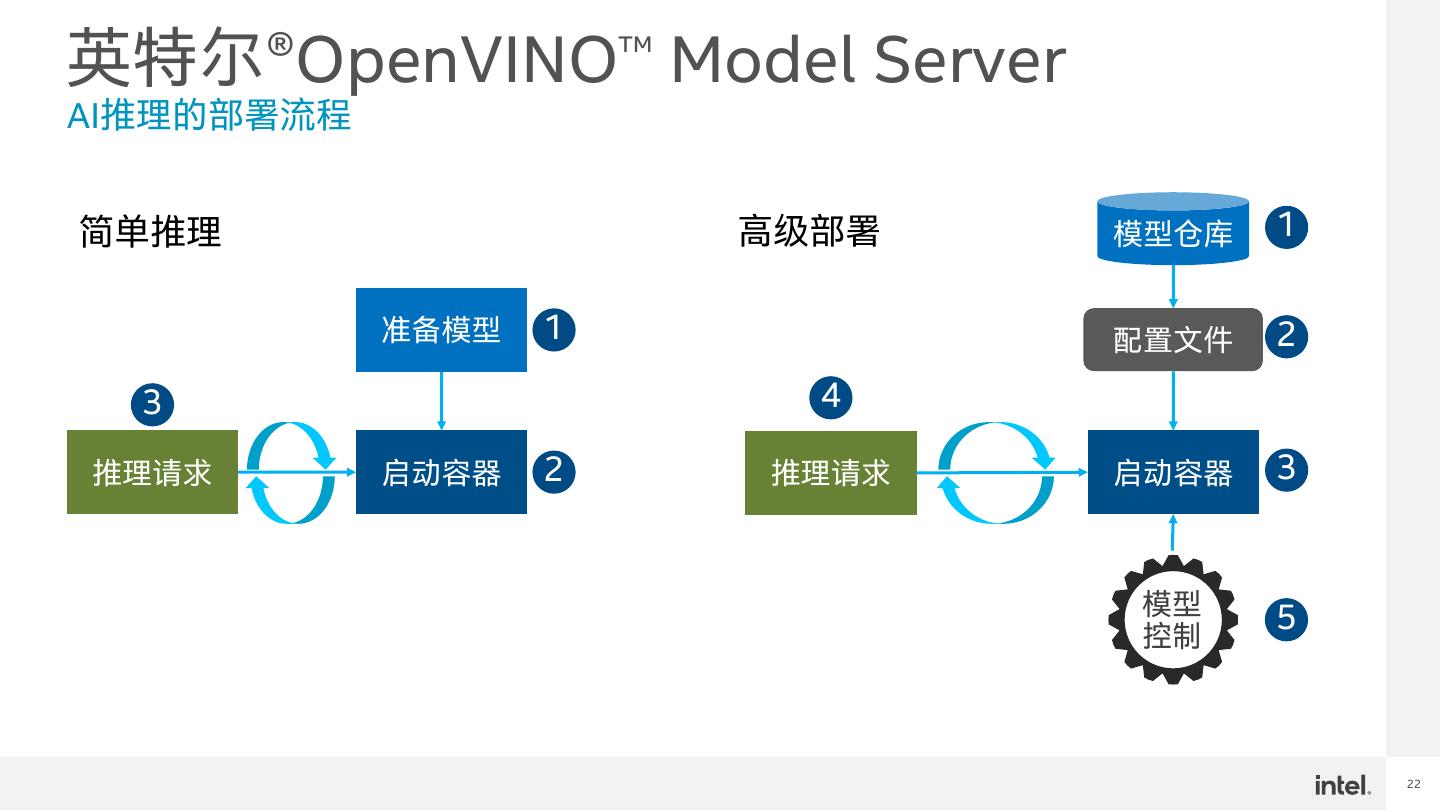
22 .英特尔®OpenVINO™ Model Server AI推理的部署流程 简单推理 高级部署 模型仓库 1 准备模型 1 配置文件 2 3 4 推理请求 启动容器 2 推理请求 启动容器 3 模型 5 控制 22
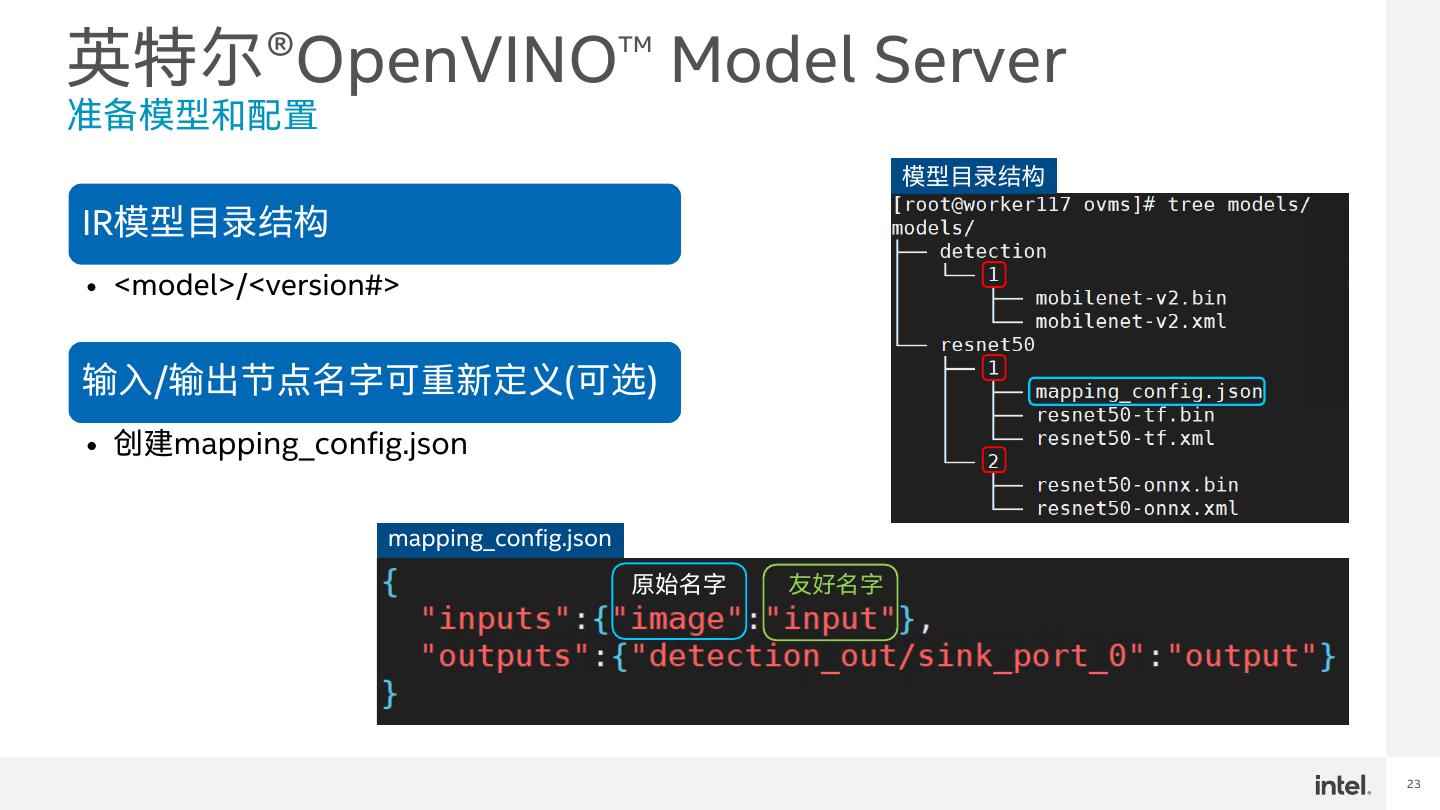
23 .英特尔®OpenVINO™ Model Server 准备模型和配置 模型目录结构 IR模型目录结构 • <model>/<version#> 输入/输出节点名字可重新定义(可选) • 创建mapping_config.json mapping_config.json 原始名字 友好名字 23
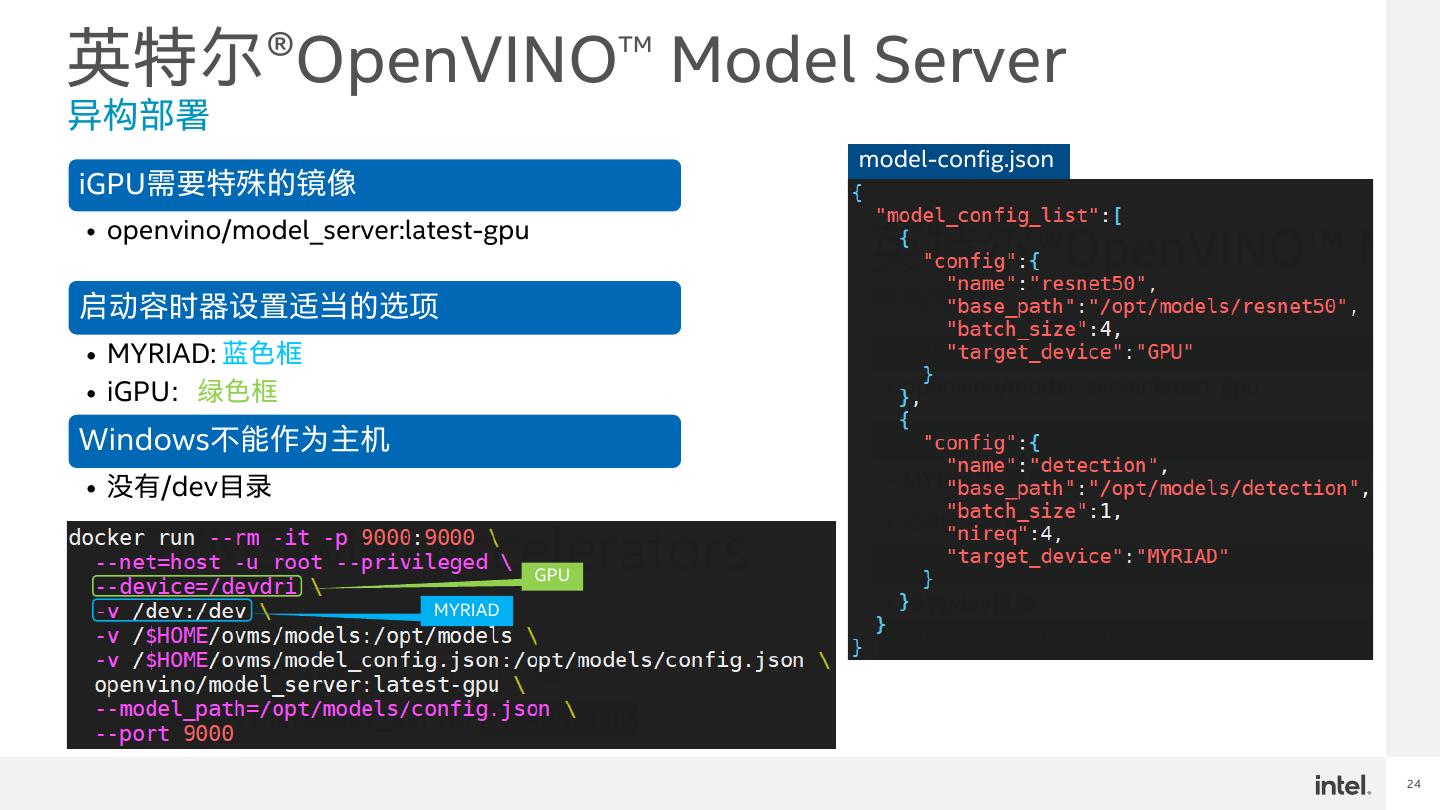
24 .英特尔®OpenVINO™ Model Server 异构部署 model-config.json iGPU需要特殊的镜像 • openvino/model_server:latest-gpu 启动容时器设置适当的选项 • MYRIAD: 蓝色框 • iGPU:绿色框 Windows不能作为主机 • 没有/dev目录 GPU MYRIAD 24
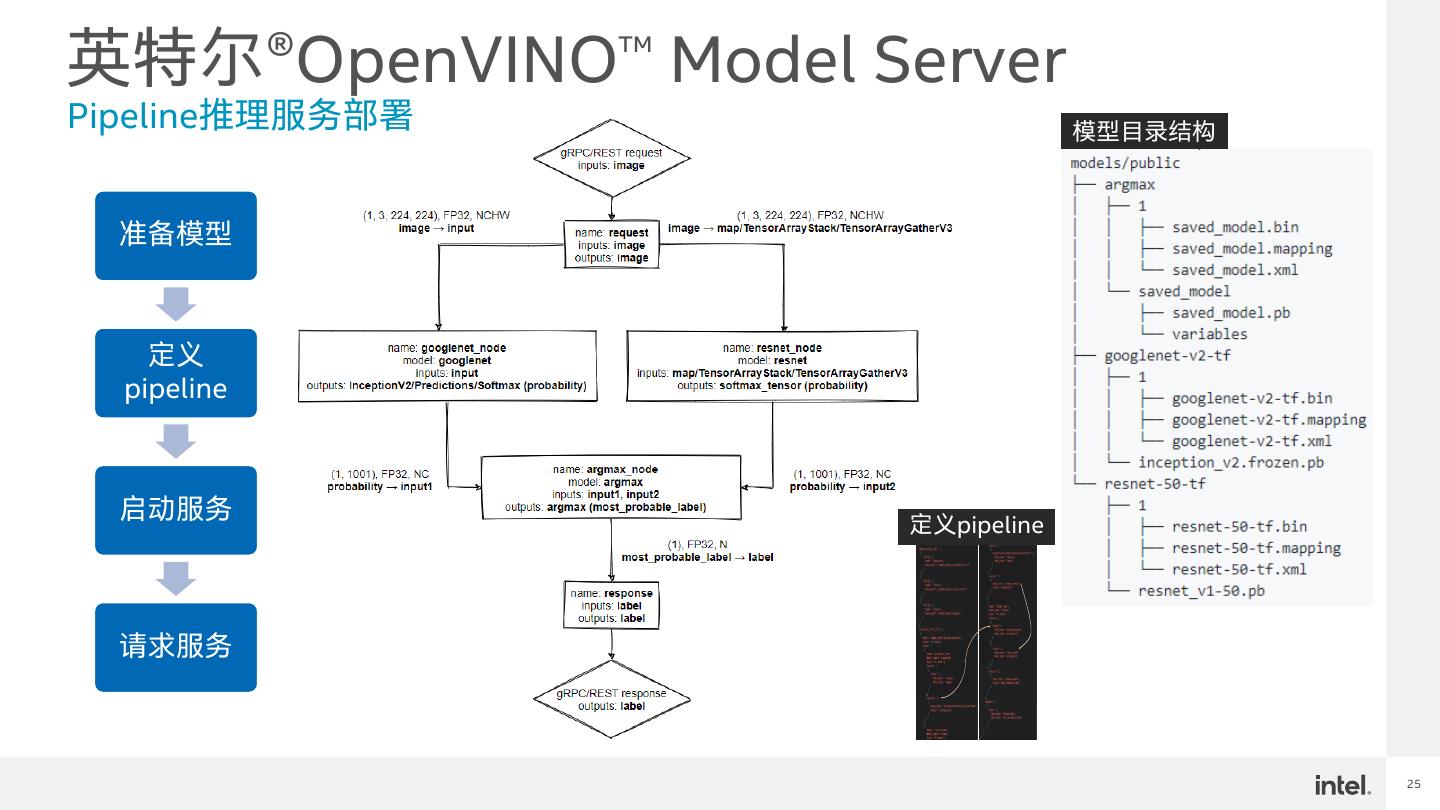
25 .英特尔®OpenVINO™ Model Server Pipeline推理服务部署 模型目录结构 准备模型 定义 pipeline 启动服务 定义pipeline 请求服务 25
26 .26
27 .英特尔®OpenVINO™ Model Server Makefile 自定义节点开发 Docker方式编译 前处理 后处理 … 业务逻辑 docker build -f Dockerfile.$(BASE_OS) \ -t custom_node_build_image:latest \ --build-arg http_proxy=${http_proxy} \ 实现API接口 custom_node_interface.h --build-arg https_proxy=${https_proxy} \ --build-arg no_proxy=${no_proxy} \ 创建预测时可复用的资源,可选的 --build-arg OPENCV_DOWNLOAD_FOLDER=$(OPENCV_DOWNLOAD_FOLDER) . int initialize(void** customNodeLibraryInternalManager, const struct CustomNodeParam* params, int paramsCount); model-config.json 释放两次预测之间的资源,可选的 int deinitialize(void* customNodeLibraryInternalManager); 自定义节点逻辑或业务处理实现接口 int execute(const struct CustomNodeTensor*, int, struct CustomNodeTensor**, int*, const struct CustomNodeParam*, int, void*); 返回预期输入的信息,可用于逻辑验证和调试 int getInputsInfo(struct CustomNodeTensorInfo**, int*, const struct CustomNodeParam*, int, void*); 返回预期输出的信息,可用于逻辑验证和调试 int getOutputsInfo(struct CustomNodeTensorInfo**, int*, const struct CustomNodeParam*, int, void*); 级联模型调用结束时释放资源的接口 int release(void* ptr, void* customNodeLibraryInternalManager); https://github.com/openvinotoolkit/model_server/blob/releases/2022/1/src/custom_nodes/east_ocr/Makefile 27
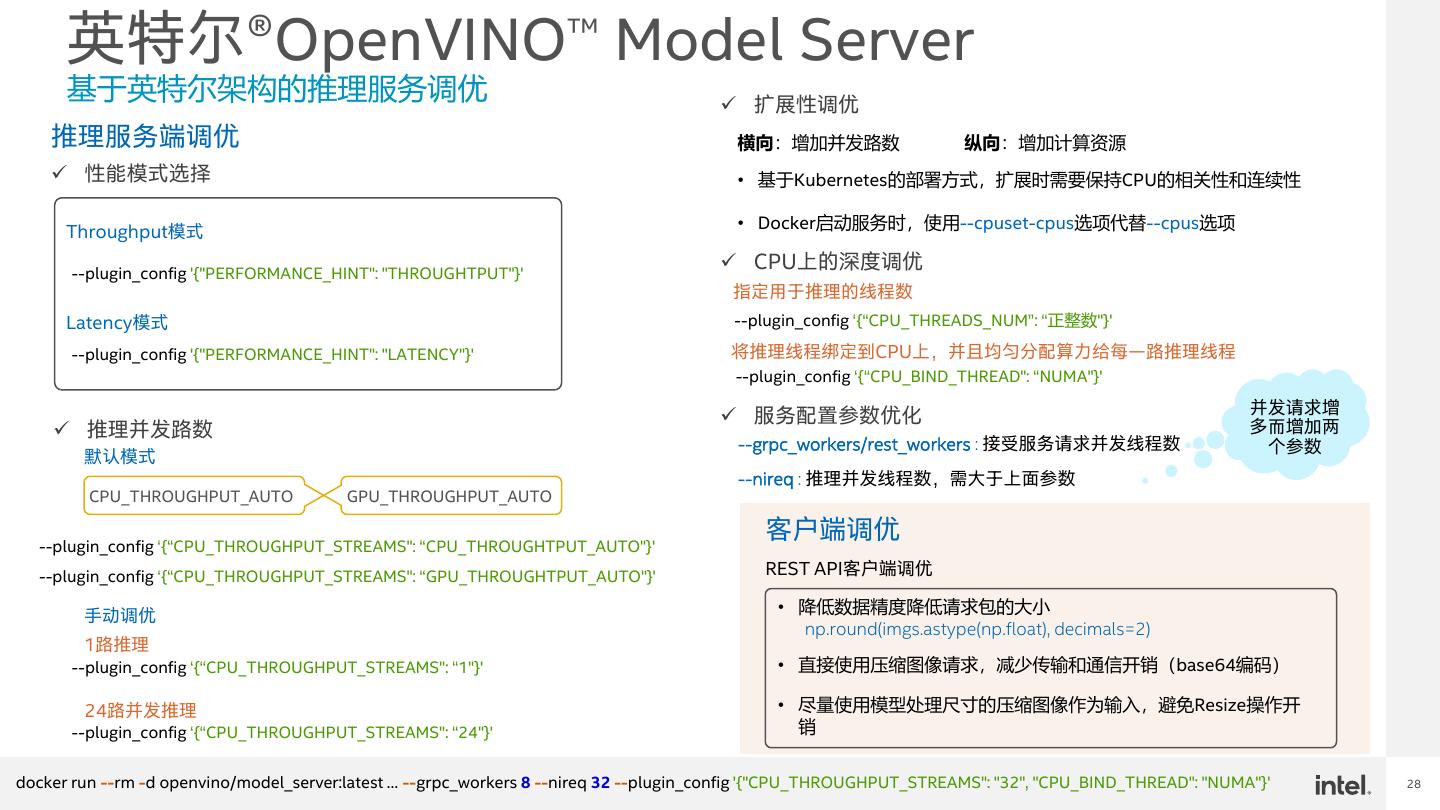
28 . 英特尔®OpenVINO™ Model Server 基于英特尔架构的推理服务调优 ✓ 扩展性调优 推理服务端调优 横向:增加并发路数 纵向:增加计算资源 ✓ 性能模式选择 • 基于Kubernetes的部署方式,扩展时需要保持CPU的相关性和连续性 Throughput模式 • Docker启动服务时,使用--cpuset-cpus选项代替--cpus选项 --plugin_config '{"PERFORMANCE_HINT": "THROUGHTPUT"}' ✓ CPU上的深度调优 指定用于推理的线程数 Latency模式 --plugin_config ‘{“CPU_THREADS_NUM”: “正整数"}' --plugin_config '{"PERFORMANCE_HINT": "LATENCY"}' 将推理线程绑定到CPU上,并且均匀分配算力给每一路推理线程 --plugin_config ‘{“CPU_BIND_THREAD": “NUMA"}' ✓ 服务配置参数优化 并发请求增 ✓ 推理并发路数 多而增加两 --grpc_workers/rest_workers : 接受服务请求并发线程数 个参数 默认模式 --nireq : 推理并发线程数,需大于上面参数 CPU_THROUGHPUT_AUTO GPU_THROUGHPUT_AUTO --plugin_config ‘{“CPU_THROUGHPUT_STREAMS": “CPU_THROUGHTPUT_AUTO"}' 客户端调优 --plugin_config ‘{“CPU_THROUGHPUT_STREAMS": “GPU_THROUGHTPUT_AUTO"}' REST API客户端调优 手动调优 • 降低数据精度降低请求包的大小 np.round(imgs.astype(np.float), decimals=2) 1路推理 --plugin_config ‘{“CPU_THROUGHPUT_STREAMS": “1"}' • 直接使用压缩图像请求,减少传输和通信开销(base64编码) 24路并发推理 • 尽量使用模型处理尺寸的压缩图像作为输入,避免Resize操作开 --plugin_config ‘{“CPU_THROUGHPUT_STREAMS": “24"}' 销 docker run --rm -d openvino/model_server:latest … --grpc_workers 8 --nireq 32 --plugin_config '{"CPU_THROUGHPUT_STREAMS": "32", "CPU_BIND_THREAD": "NUMA"}' 28
29 .
3秒后跳转登录页面
去登陆

