
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

使用Intel BigDL2.0为pytorch/tensorflow/deeprec人工智能应用加速-邓珺玮
使用Intel BigDL2.0为pytorch/tensorflow/deeprec人工智能应用加速-邓珺玮
使用Intel BigDL2.0为pytorch/tensorflow/deeprec人工智能应用加速-邓珺玮
人工智能应用在各行业已经拥有了成功的使用案例,并取得了更优秀的业务指标。但人工智能应用通常所需计算资源较多,运行速度慢,限制了模型的开发,迭代以及部署时的速度;英特尔BigDL2.0提供了统一的AI大数据架构,并为AI应用在CPU上的加速给出了解决方案:bigdl-nano项目无缝式的模型训练与推理加速帮助用户在不改动或改动很少代码的情况下取得显著的加速。本次分享中将会展示bigdl-nano的使用方法以及在多个使用案例中的效果。
邓珺玮,Intel人工智能框架工程师。他目前专注于BigDL大数据与人工智能平台上对自动机器学习, 机器学习框架性能加速组件以及时间序列分析框架的研发。他曾在NIPS,WSDM等人工智能会议上发表论文。在加入intel之前,他分别在密歇根大学安娜堡分校和上海交通大学获得了硕士与学士学位。
展开查看详情
1 .BigDL 2.0 BigDL-Nano: Transparently accelerate pytorch/tensorflow pipeline with modern CPU optimization Junwei Deng Intel/SATG/ML Solution Platform 1
2 .Content • Intel AI software stack and BigDL2.0 • Intel AI Software stack overview • Bigdl 2.0 overview • BigDL-nano Introduction • Overview • API introduction • BigDL-nano use-cases • Overview • Image classification training • Image style change inferencing • Hyperparameter optimization (AutoML) • Reinforcement Learning training • Capgemini 5G intelligent MAC scheduler with bigdl-chronos • Recommendation model acceleration • More benchmark results 2
3 .Intel AI Software 3
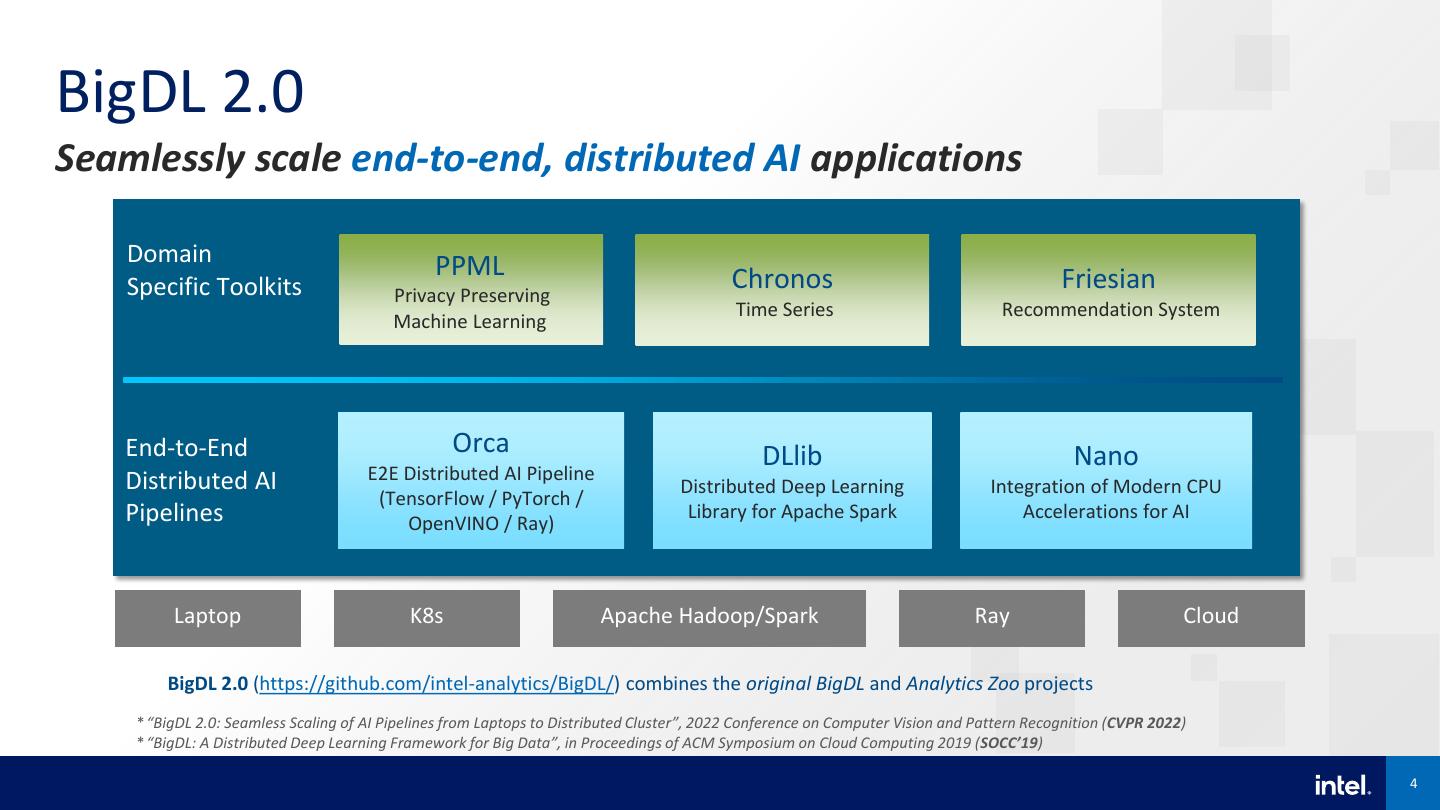
4 .BigDL 2.0 Seamlessly scale end-to-end, distributed AI applications Domain PPML Specific Toolkits Privacy Preserving Chronos Friesian Time Series Recommendation System Machine Learning End-to-End Orca DLlib Nano Distributed AI E2E Distributed AI Pipeline Distributed Deep Learning Integration of Modern CPU (TensorFlow / PyTorch / Pipelines OpenVINO / Ray) Library for Apache Spark Accelerations for AI Laptop K8s Apache Hadoop/Spark Ray Cloud BigDL 2.0 (https://github.com/intel-analytics/BigDL/) combines the original BigDL and Analytics Zoo projects *“BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster”, 2022 Conference on Computer Vision and Pattern Recognition (CVPR 2022) *“BigDL: A Distributed Deep Learning Framework for Big Data”, in Proceedings of ACM Symposium on Cloud Computing 2019 (SOCC’19) 4
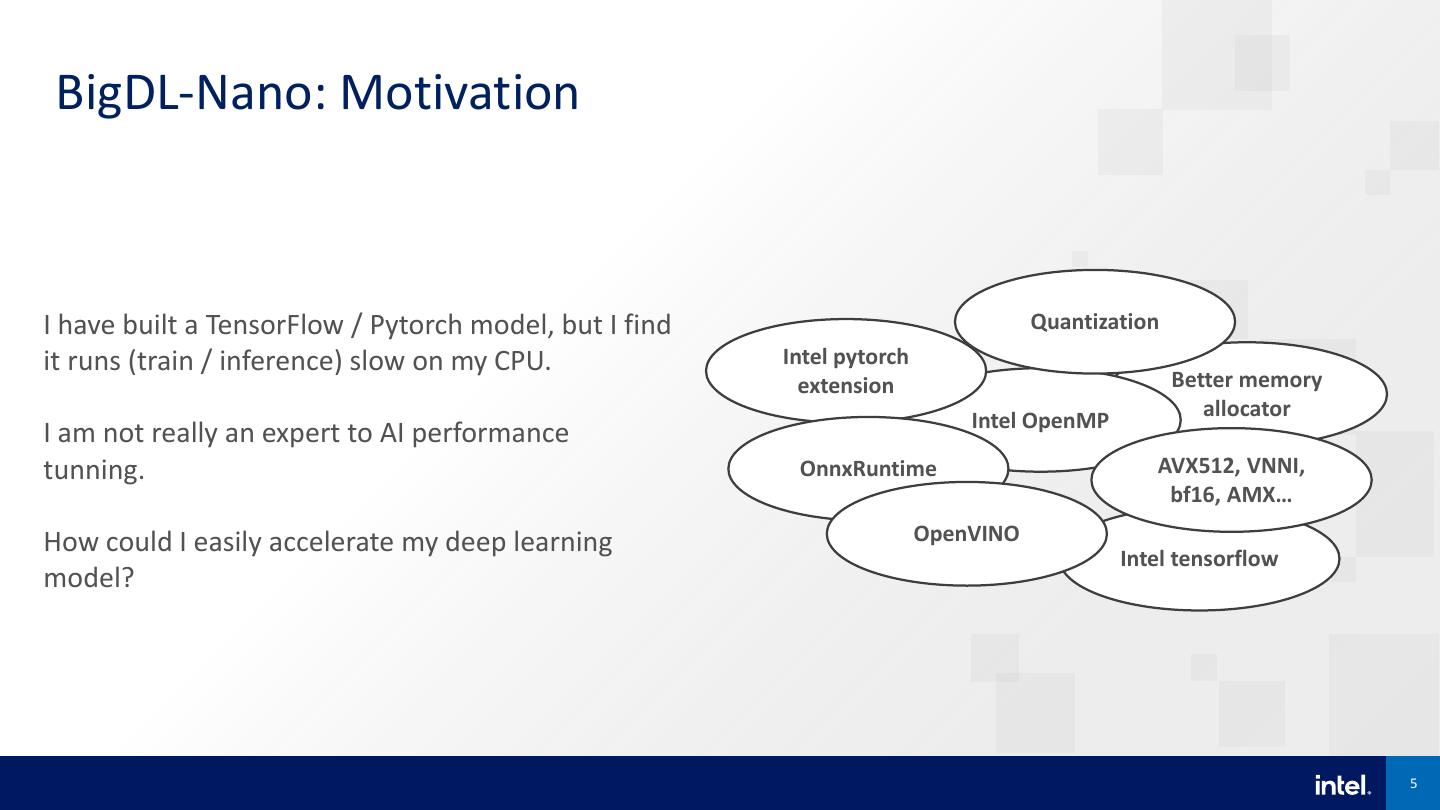
5 . BigDL-Nano: Motivation I have built a TensorFlow / Pytorch model, but I find Quantization it runs (train / inference) slow on my CPU. Intel pytorch extension Better memory Intel OpenMP allocator I am not really an expert to AI performance tunning. OnnxRuntime AVX512, VNNI, bf16, AMX… How could I easily accelerate my deep learning OpenVINO Intel tensorflow model? 5
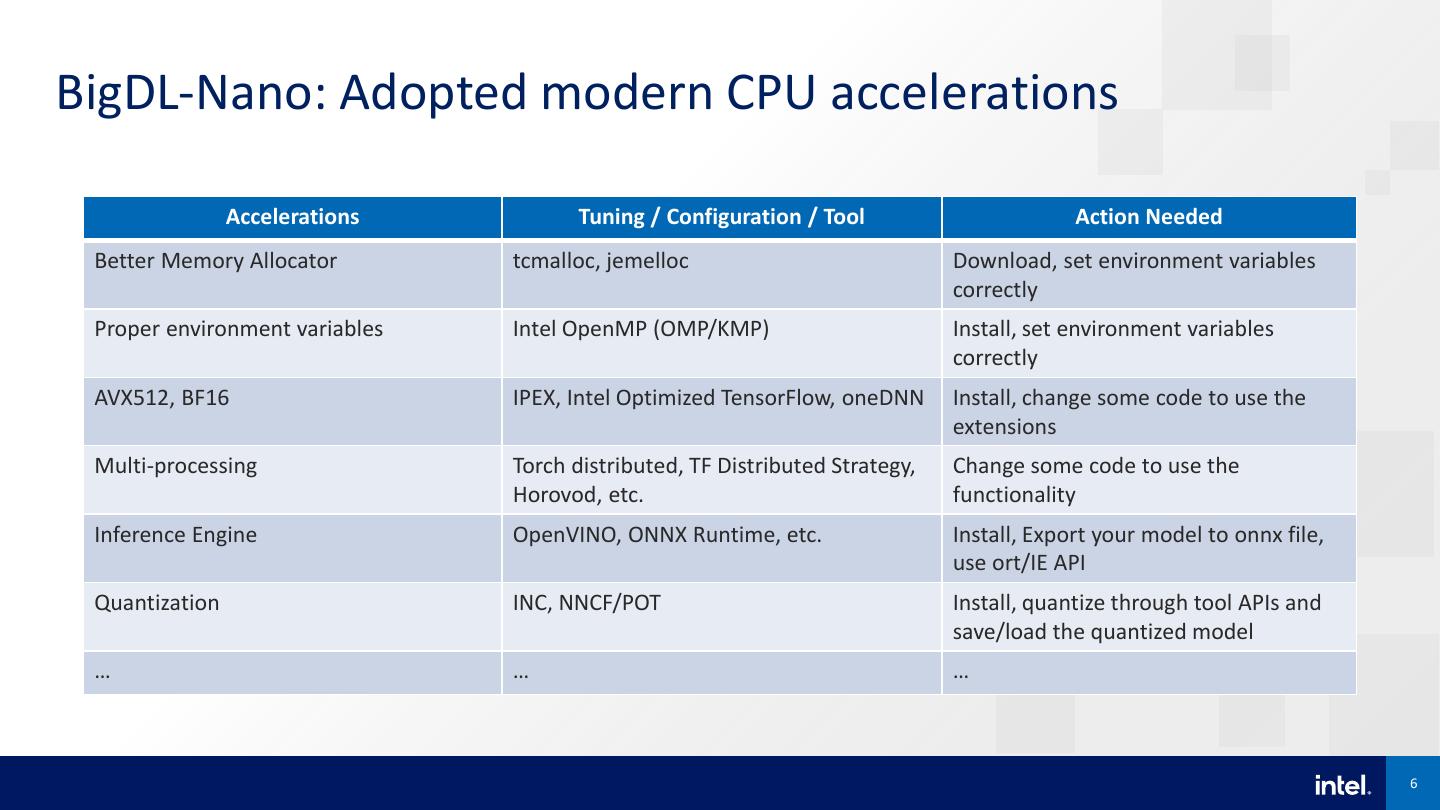
6 .BigDL-Nano: Adopted modern CPU accelerations Accelerations Tuning / Configuration / Tool Action Needed Better Memory Allocator tcmalloc, jemelloc Download, set environment variables correctly Proper environment variables Intel OpenMP (OMP/KMP) Install, set environment variables correctly AVX512, BF16 IPEX, Intel Optimized TensorFlow, oneDNN Install, change some code to use the extensions Multi-processing Torch distributed, TF Distributed Strategy, Change some code to use the Horovod, etc. functionality Inference Engine OpenVINO, ONNX Runtime, etc. Install, Export your model to onnx file, use ort/IE API Quantization INC, NNCF/POT Install, quantize through tool APIs and save/load the quantized model … … … 6
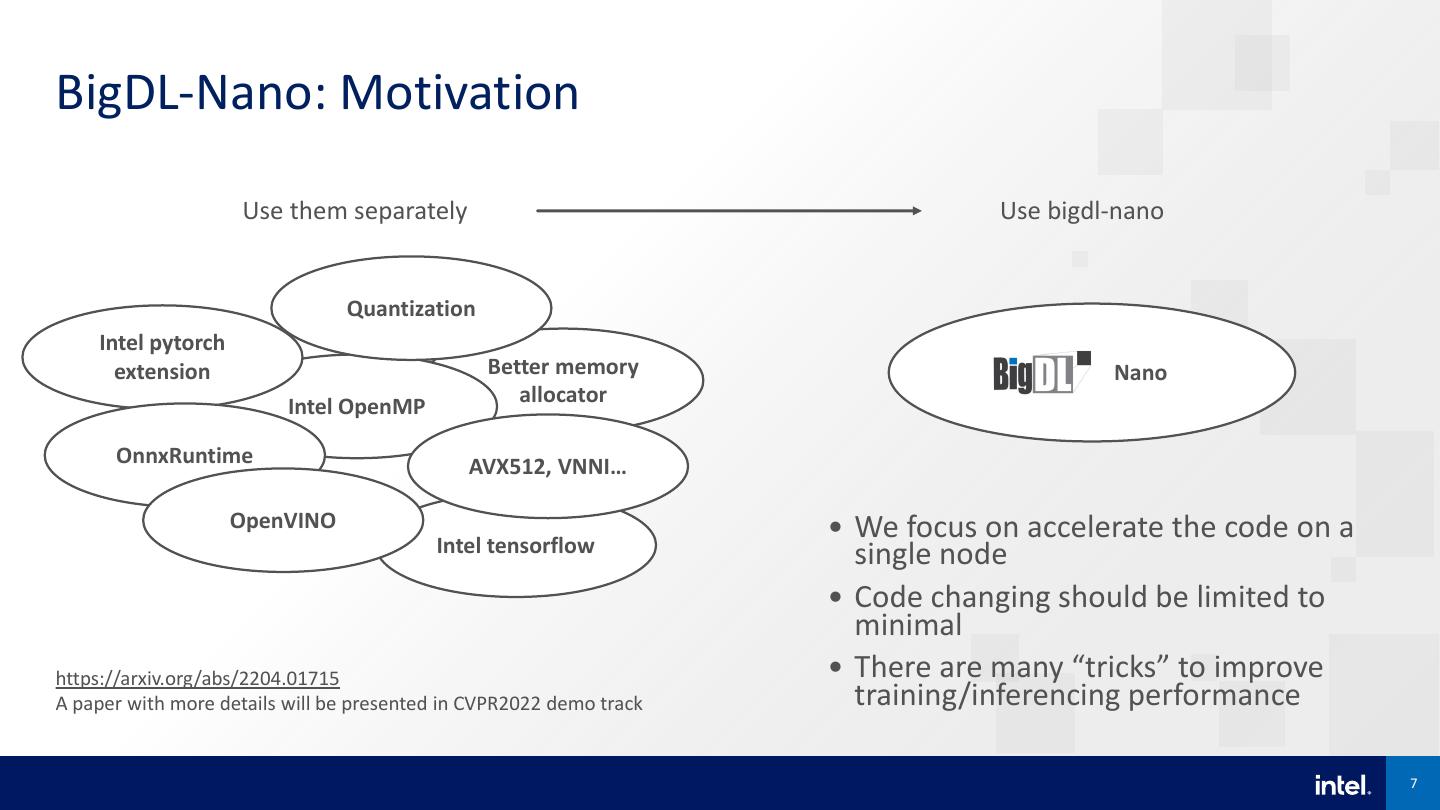
7 .BigDL-Nano: Motivation Use them separately Use bigdl-nano Quantization Intel pytorch extension Better memory Nano Intel OpenMP allocator OnnxRuntime AVX512, VNNI… OpenVINO • We focus on accelerate the code on a Intel tensorflow single node • Code changing should be limited to minimal https://arxiv.org/abs/2204.01715 • There are many “tricks” to improve A paper with more details will be presented in CVPR2022 demo track training/inferencing performance 7
8 .BigDL-Nano: Automatic Integration of Modern CPU Accelerations for TensorFlow & PyTorch • One command install • pip install bigdl-nano[pytorch] • pip install bigdl-nano[tensorflow] • Minimum code changes (more details in following pages) Training (ipex + multi-instance) Inference (openvino) Quantization (inc + onnxrt) 2 lines code change 2 lines code change 3 lines code change • Substantial speedup • Up to ~5.8x training speedup, and ~9.6x inference speedup For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 8
9 .BigDL-Nano: Transparently accelerate PyTorch-lightning 0 python my_script.py my_script.py from bigdl.nano.pytorch import Trainer #1. Define a pytorch lightning model or transform from a nn.module Suppport either: # define a pytorch lightning model 1 1. User defined lightning module 2. A pytorch nn.module with loss and model = PL_Model(…) optim run through Trainer.compile # or trans from a nn.module model = Trainer.compile(Model(…), Loss(…), Optim(…)) Simply switch on ipex and multi- #2. Train the model with bigdl-nano trainer processes training by parameters and trainer = Trainer(use_ipex=True, num_processes=8, …) 2 follow the exact same API as pytorch- Trainer.fit(model, train_dataloader) lightning trainer #3. Inference with bigdl-nano optimizations # Quantize you model to int8 to increase throughput model_quan = Trainer.quantize(model, precision=“int8”/”bf16”, We design a runtime replacement accelerator=None/“onnxruntime”/”openvino”) mechanism to help user accelerate their inference to base on other inference model_quan(x) 3 engine(e.g. onnxrt, openvino) or # Trace you model to onnx/openvino to decrease latency quantized model by only call one-line model_trace = Trainer.trace(model, transformation. accelerator=“onnxruntime”/”openvino”) model_trace(x) 9
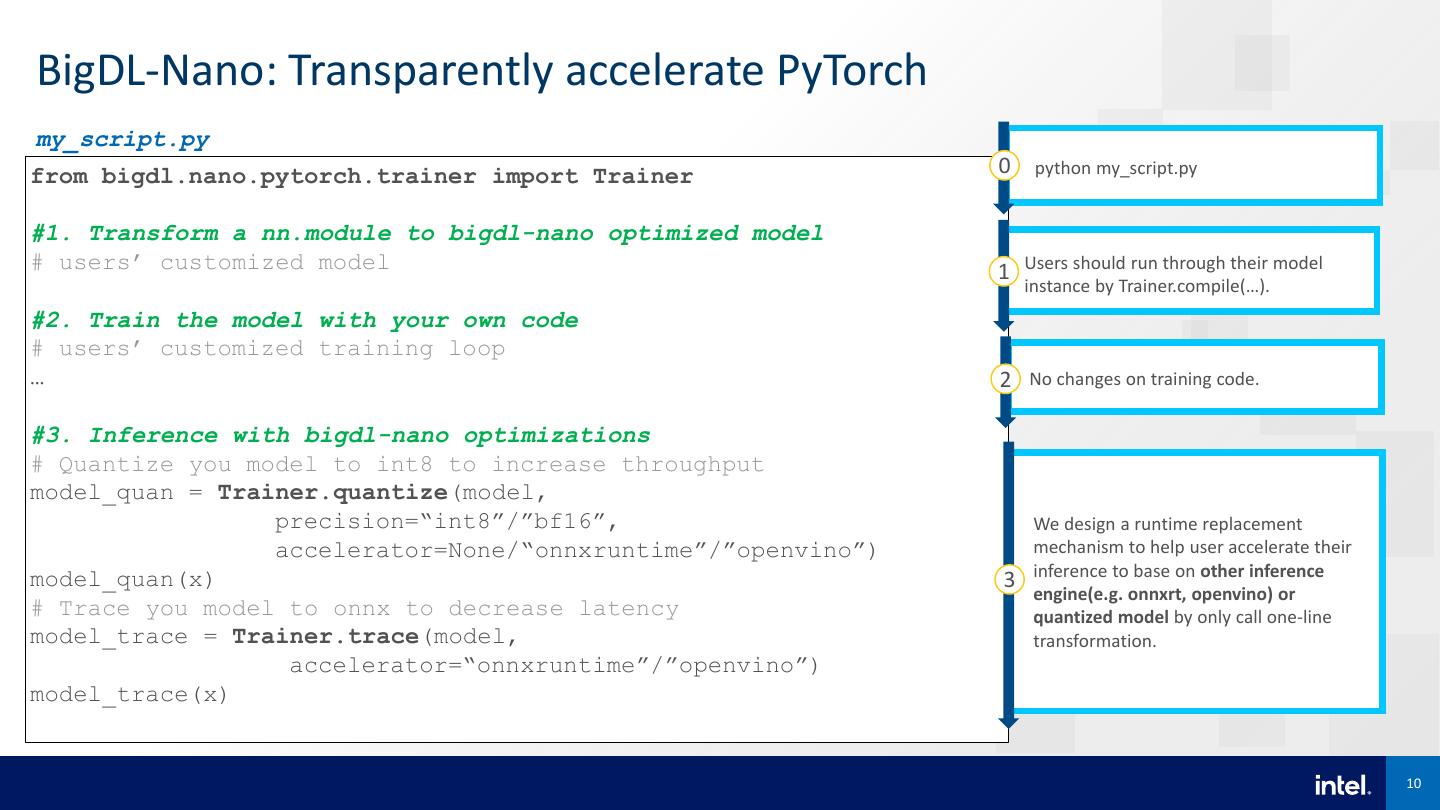
10 .BigDL-Nano: Transparently accelerate PyTorch my_script.py from bigdl.nano.pytorch.trainer import Trainer 0 python my_script.py #1. Transform a nn.module to bigdl-nano optimized model # users’ customized model 1 Users should run through their model instance by Trainer.compile(…). #2. Train the model with your own code # users’ customized training loop … 2 No changes on training code. #3. Inference with bigdl-nano optimizations # Quantize you model to int8 to increase throughput model_quan = Trainer.quantize(model, precision=“int8”/”bf16”, We design a runtime replacement accelerator=None/“onnxruntime”/”openvino”) mechanism to help user accelerate their model_quan(x) inference to base on other inference 3 engine(e.g. onnxrt, openvino) or # Trace you model to onnx to decrease latency quantized model by only call one-line model_trace = Trainer.trace(model, transformation. accelerator=“onnxruntime”/”openvino”) model_trace(x) 10
11 . BigDL-Nano: Transparently accelerate Keras my_script.py 0 python my_script.py from bigdl.nano.tf.keras import Sequential from bigdl.nano.tf.keras import Model #1. Define and Train the model with your own code # users’ own customized training loop 1 Minor changes on training code. model = Sequential([…]) model.compile(…) model.fit(…, num_processes=8) Currently, we only support quantization in #2. Inference with bigdl-nano optimizations 2 tensorflow’s optional optimization q_model = model.quantize(train_dataset) q_model(x) 11
12 .BigDL Nano Use Case • Students & Data Scientist • Accelerate their model’s training and tunning • Accelerate their model’s inference to get a better online experience • AI application framework Engineer • Accelerate their library to transparently accelerate on intel hardware 12
13 .Image classification training - Better env variables - Intel OpenMP - Intel pytorch extension - Multi-process training Training (ipex + multi-instance) > 15X speed up! 2 lines code change For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 13
14 . Demo Image style change inferencing - Better env variables - Intel neural compressor - ONNX Runtime - AVX512_VNNI usage Training (ipex + multi-instance) > 35% latency drop! 2 lines code change https://huggingface.co/spaces/CVPR/BigDL-Nano_inference For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 14
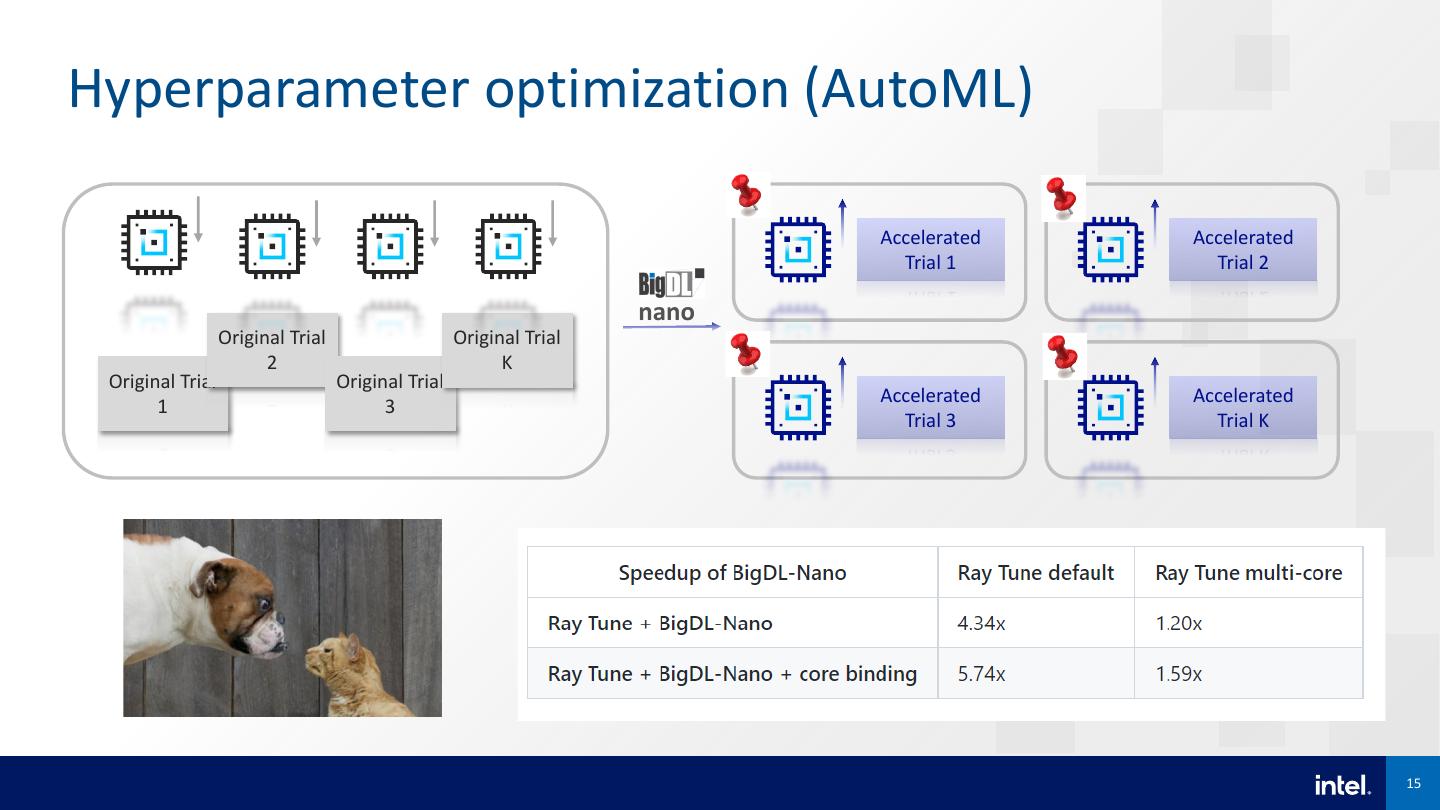
15 .Hyperparameter optimization (AutoML) Accelerated Accelerated Trial 1 Trial 2 nano Original Trial Original Trial 2 K Original Trial Original Trial Accelerated Accelerated 1 3 Trial 3 Trial K 15
16 .Reinforcement Learning training • Pong • https://www.gymlibrary.ml/pages/environments/atari/pong • Collect 2000 samples a time Total time Model Training Time Sampling (Simulation) Sampling workers If Nano is enabled Time 115.65s 107.22s 8.43s 1 False 107.54s 105.48s 2.06s 4 False 30.76s 22.90s 7.86s 1 True 24.62s 26.80s 2.18s 4 True (~4X speed up) For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 16
17 .Capgemini 5G intelligent MAC scheduler using Chronos • Forecast UE’s mobility to assist the MAC scheduler in efficient link adaptation on 2 key KPIs. https://networkbuilders.intel.com/solutionslibrary/intelligent-5g-l2-mac-scheduler-powered- by-capgemini-netanticipate-5g-on-intel-architecture For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 17
18 .Recommendation model acceleration • Change tf.keras.Model -> bigdl.nano.tf.keras.Model server1 server2 • Change tf.keras.layers.Embedding -> bigdl.nano.tf.keras.layers.Embedding server1 server2 For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 18
19 .BigDL-Nano Benchmarking Results Training Throughput 10 8 6 4 2 0 TCN Seq2Seq LSTM DoppelGANger ResNet50 ResNet50 MobileNet_v2 MobileNet_v2 facefast finetune finetune stock pytorch bigdl-nano Inference Throughput 15 10 5 0 TCN ResNet50 LSTM Seq2Seq facefast stock pytorch bigdl-nano bigdl-nano-int8 For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 19
20 .
21 .Summary • BigDL 2.0 (https://github.com/intel-analytics/bigdl) • E2E distributed AI pipelines (seamless scaling from laptop to cluster) • Domain-specific AI toolkits (PPML, Time Series, Recommender) • Reference • CVPR 2021 demo paper: https://arxiv.org/abs/2204.01715 • CVPR 2021 tutorial: https://jason-dai.github.io/cvpr2021/ • ACM SoCC 2019 paper: https://arxiv.org/abs/1804.05839 • Use case: https://bigdl.readthedocs.io/en/latest/doc/Application/powered-by.html • Talks: https://bigdl.readthedocs.io/en/latest/doc/Application/presentations.html 21
3秒后跳转登录页面
去登陆

