展开查看详情
1 .基于AzureML的大规模深度学习:
数据管理与缓存
Chao Wang, Mickey Zhang, Qianjun Xu
�
2 .Overview Machine Learning Requirements
End-to-End lifecycle and processes
Data Scientist Workflow
Deep Learning on Azure Machine Learning
Deep Learning: Additional Requirements
Distributed Training with Azure ML Compute
Kubernetes + Alluxio
�
3 . Requirements of an
advanced ML Platform
�
4 .Machine Learning
Typical E2E Process
Prepare Experiment Deploy
…
Orchestrate
�
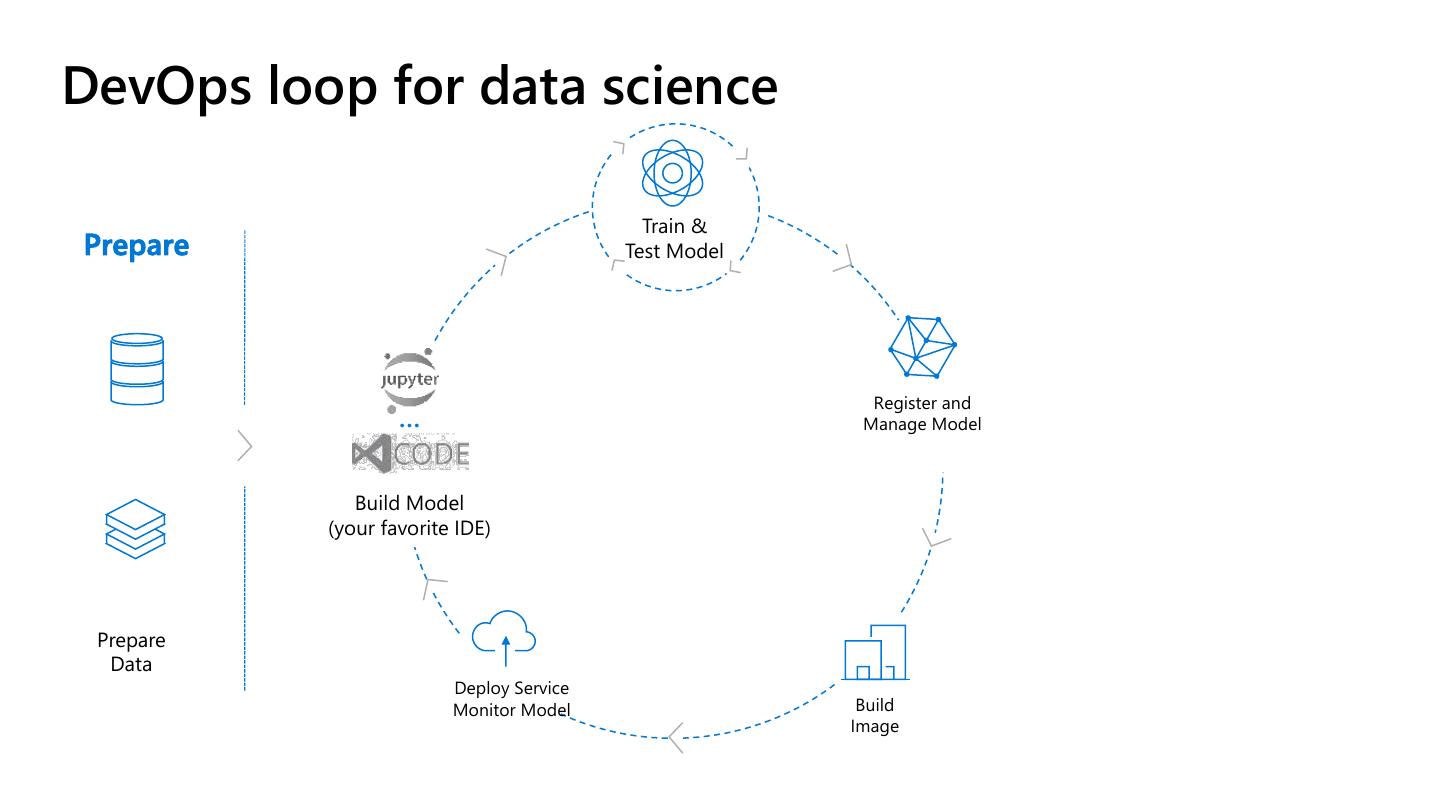
5 .DevOps loop for data science
Train &
Prepare Test Model
Register and
… Manage Model
Build Model
(your favorite IDE)
Prepare
Data
Deploy Service
Monitor Model Build
Image
�
6 . Deep Learning on
Azure Machine Learning
�
7 .Characteristics of Deep Learning
�
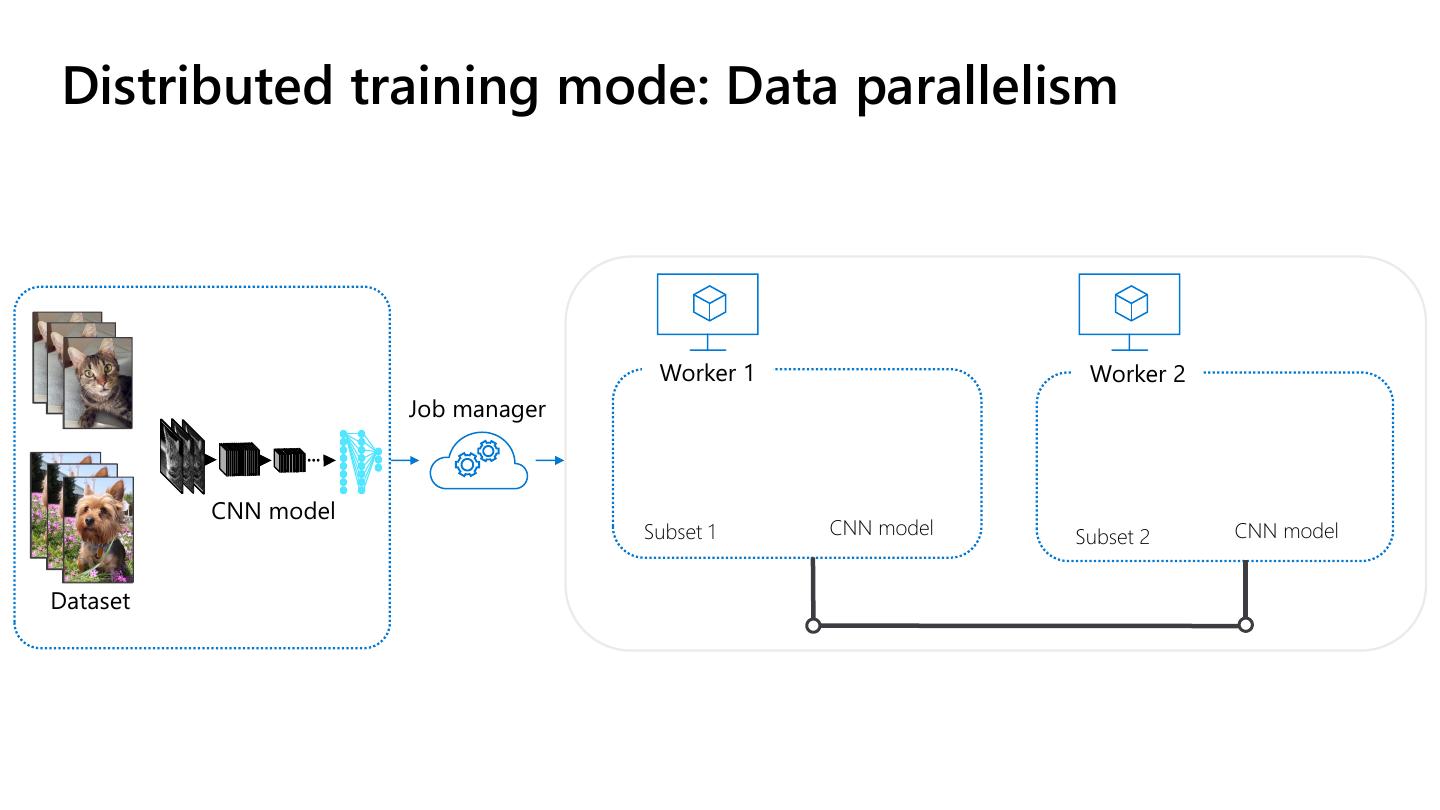
8 .Distributed training mode: Data parallelism
Worker 1 Worker 2
Job manager
CNN model
Subset 1 CNN model Subset 2 CNN model
Dataset
�
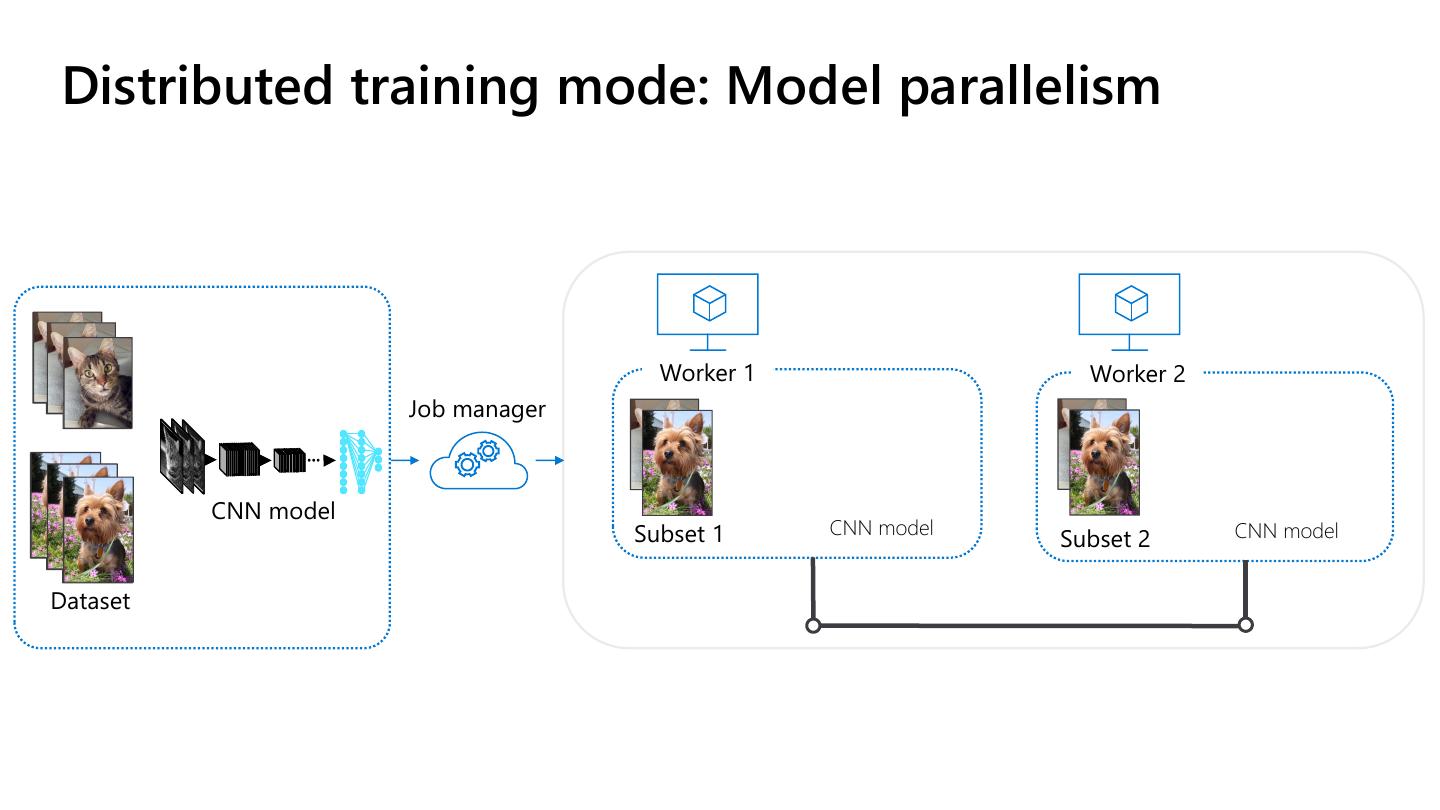
9 .Distributed training mode: Model parallelism
Worker 1 Worker 2
Job manager
CNN model
Subset 1 CNN model CNN model
Subset 2
Dataset
�
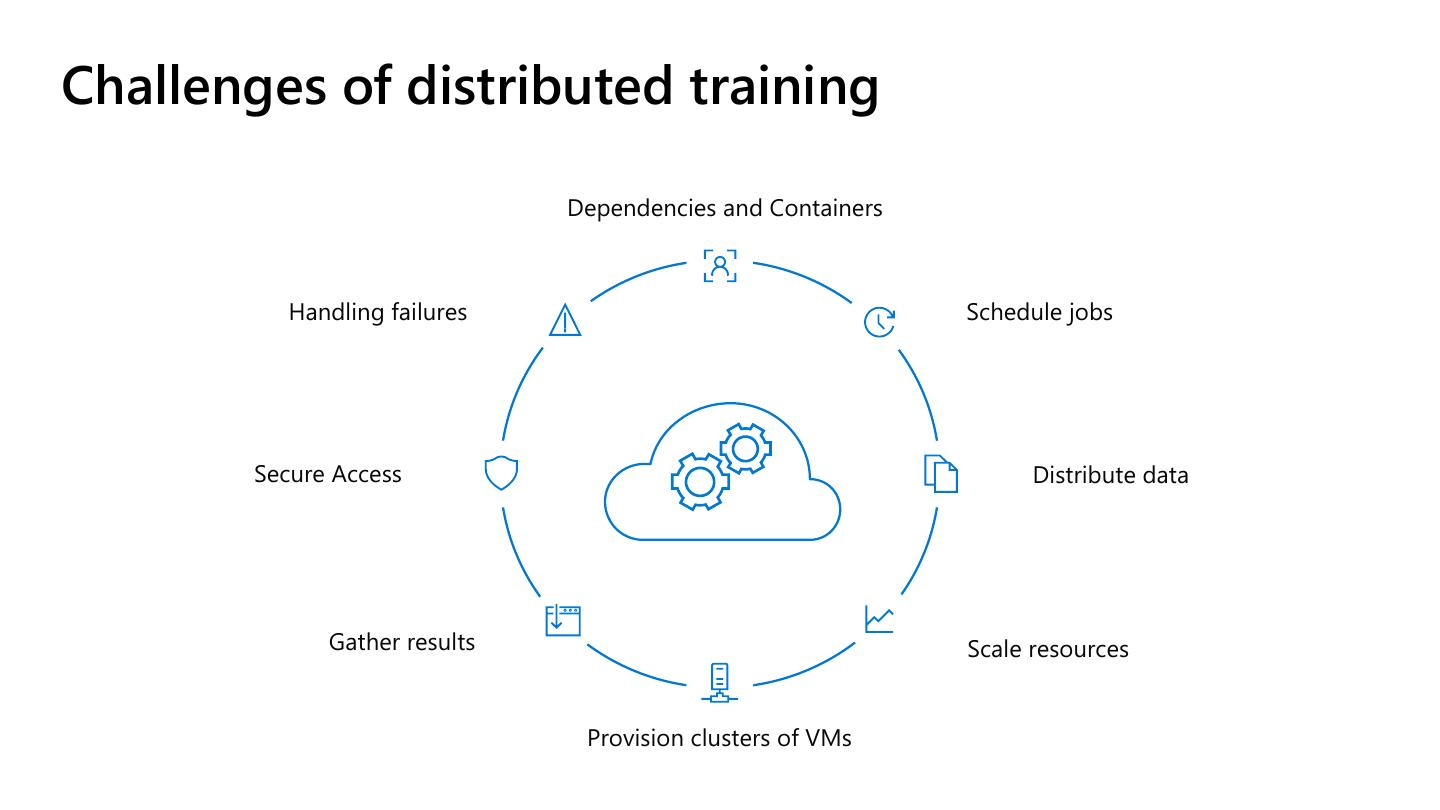
10 .Challenges of distributed training
Dependencies and Containers
Handling failures Schedule jobs
Secure Access Distribute data
Gather results Scale resources
Provision clusters of VMs
�
11 .Kubernetes and Alluxio
�
12 .Deep Learning Scenarios
1.
2.
3.
�
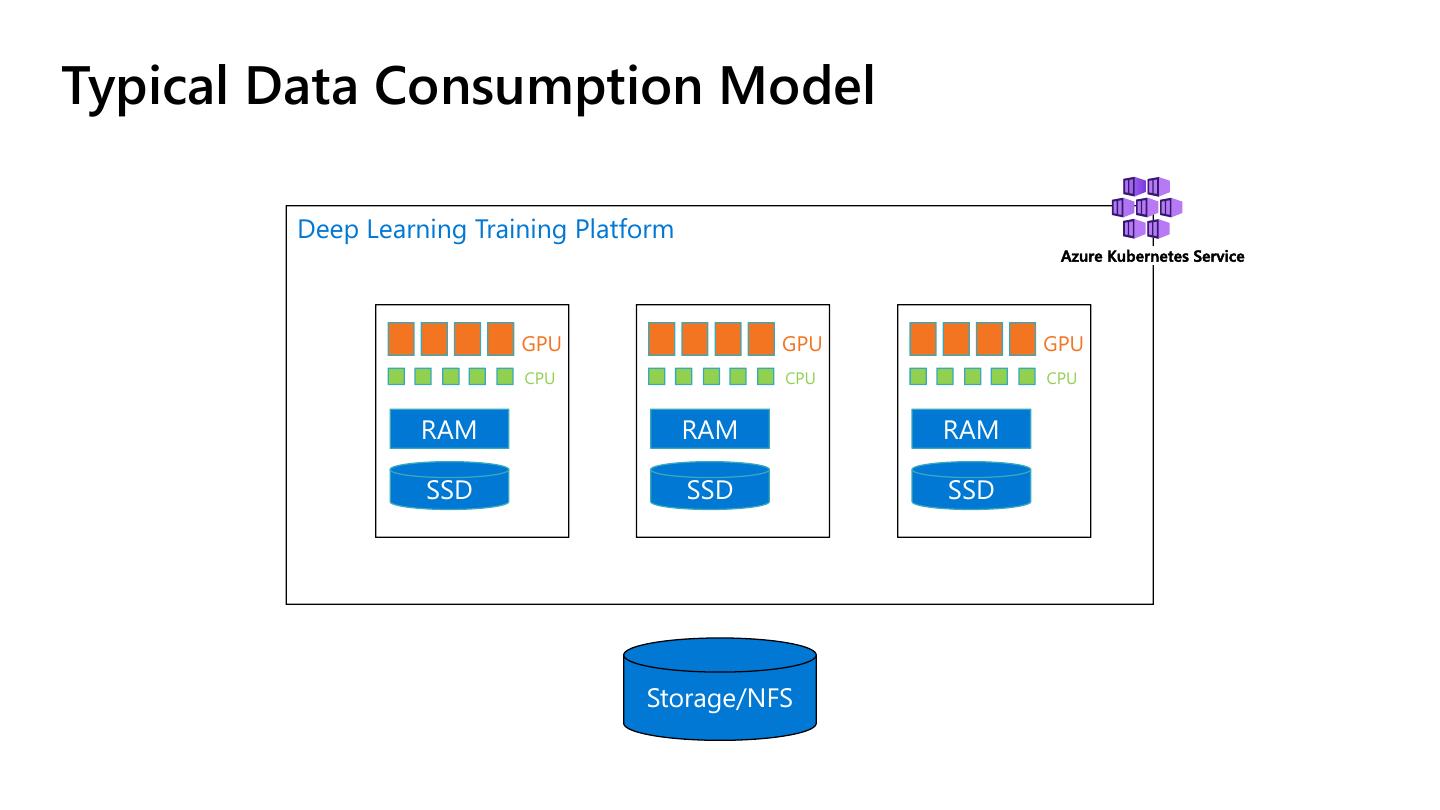
13 .Typical Data Consumption Model
Deep Learning Training Platform
Azure Kubernetes Service
GPU GPU GPU
CPU CPU CPU
RAM RAM RAM
SSD SSD SSD
Storage/NFS
�
14 .Why Alluxio?
Performance Flexibility
Improve data access throughput by Manage multiple data sources in a
distributing across nodes unified namespace
Lower Cost Scalable
Leverage idle resources in the cluster Performance is scalable based on the
cluster size
�
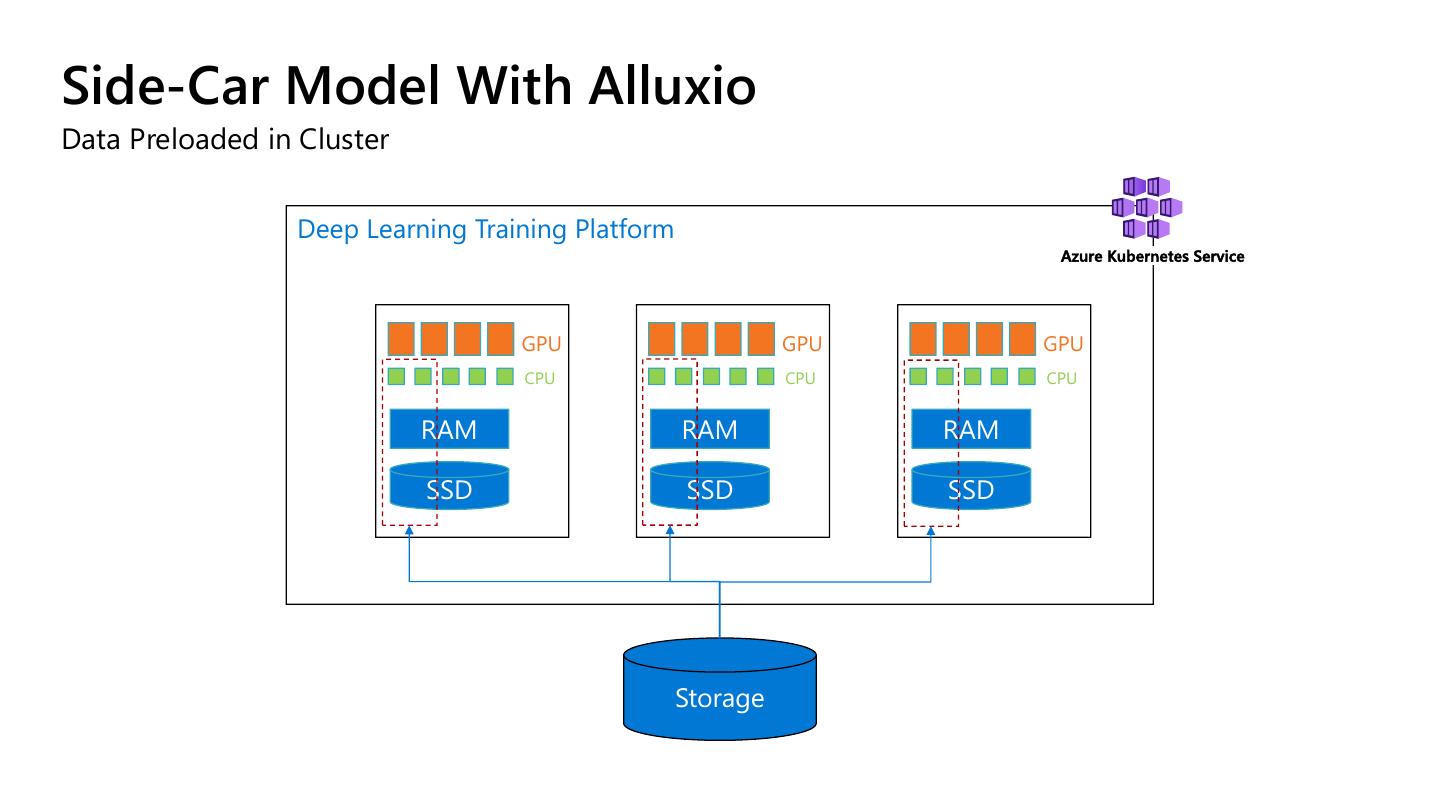
15 .Side-Car Model With Alluxio
Data Preloaded in Cluster
Deep Learning Training Platform
Azure Kubernetes Service
GPU GPU GPU
CPU CPU CPU
RAM RAM RAM
SSD SSD SSD
Storage
�
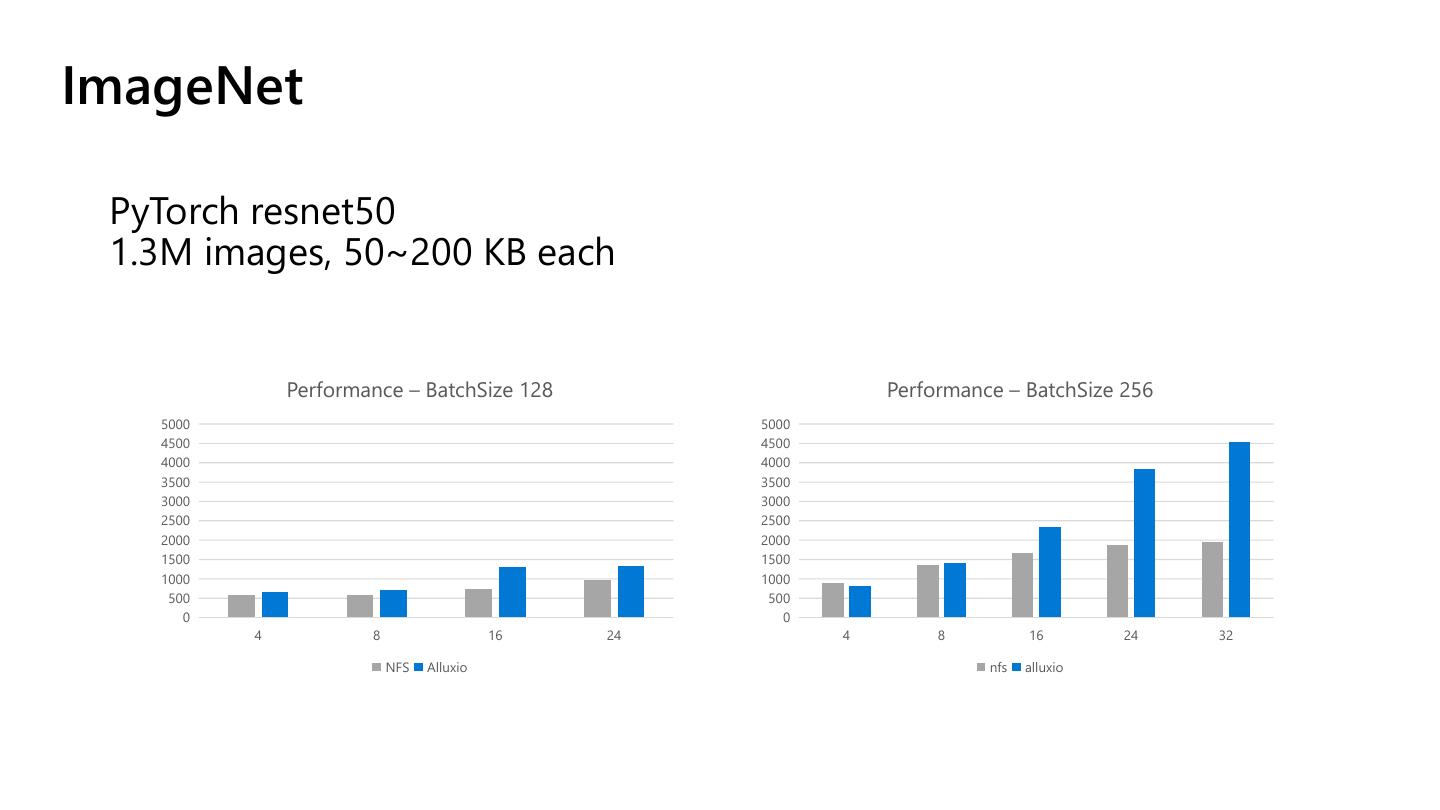
16 .ImageNet
PyTorch resnet50
1.3M images, 50~200 KB each
Performance – BatchSize 128 Performance – BatchSize 256
5000 5000
4500 4500
4000 4000
3500 3500
3000 3000
2500 2500
2000 2000
1500 1500
1000 1000
500 500
0 0
4 8 16 24 4 8 16 24 32
NFS Alluxio nfs alluxio
�
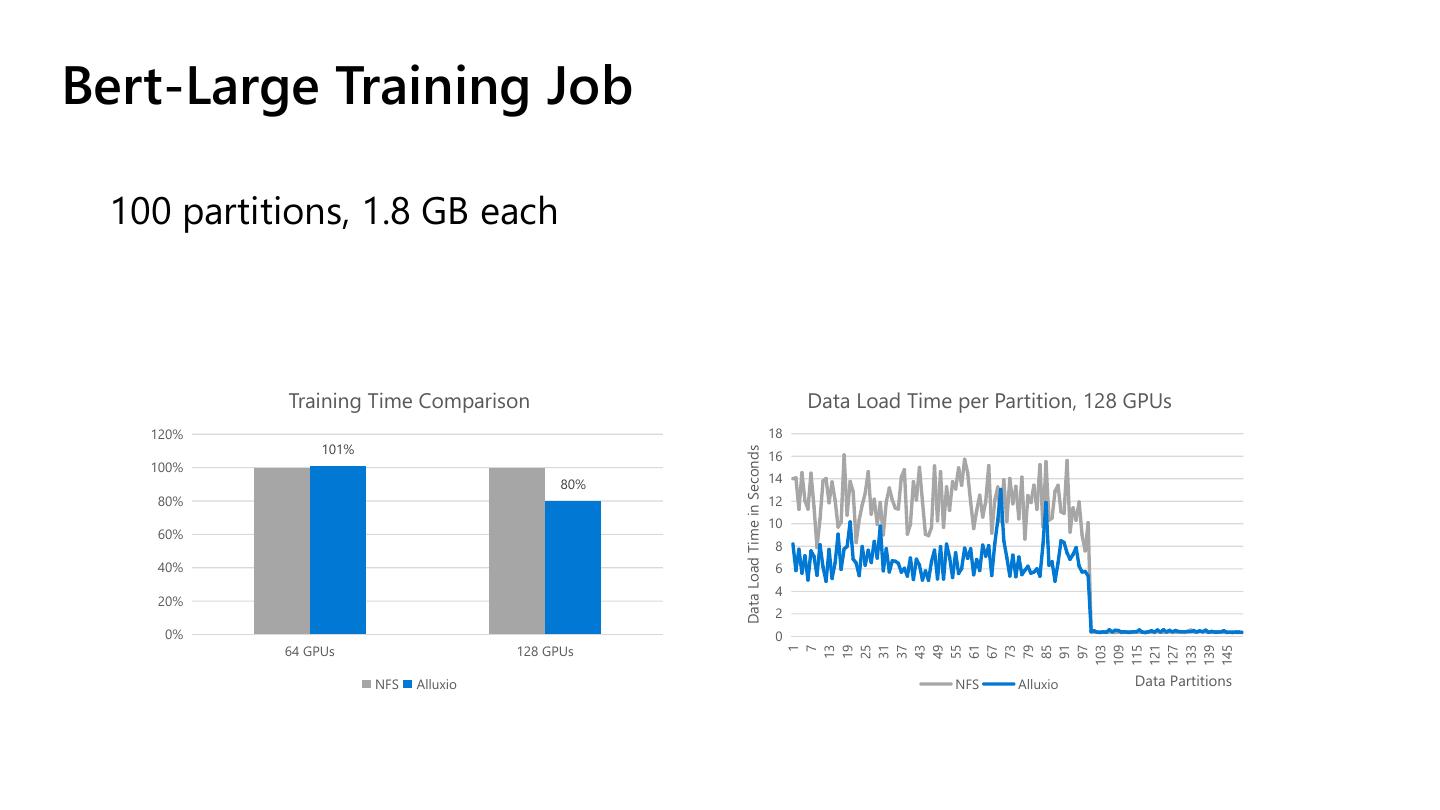
17 .Bert-Large Training Job
100 partitions, 1.8 GB each
Training Time Comparison Data Load Time per Partition, 128 GPUs
120% 18
101%
16
Data Load Time in Seconds
100%
80% 14
80% 12
10
60%
8
40% 6
4
20%
2
0% 0
64 GPUs 128 GPUs
1
7
103
109
115
121
127
133
139
145
13
19
25
31
37
43
49
55
61
67
73
79
85
91
97
NFS Alluxio NFS Alluxio Data Partitions
�
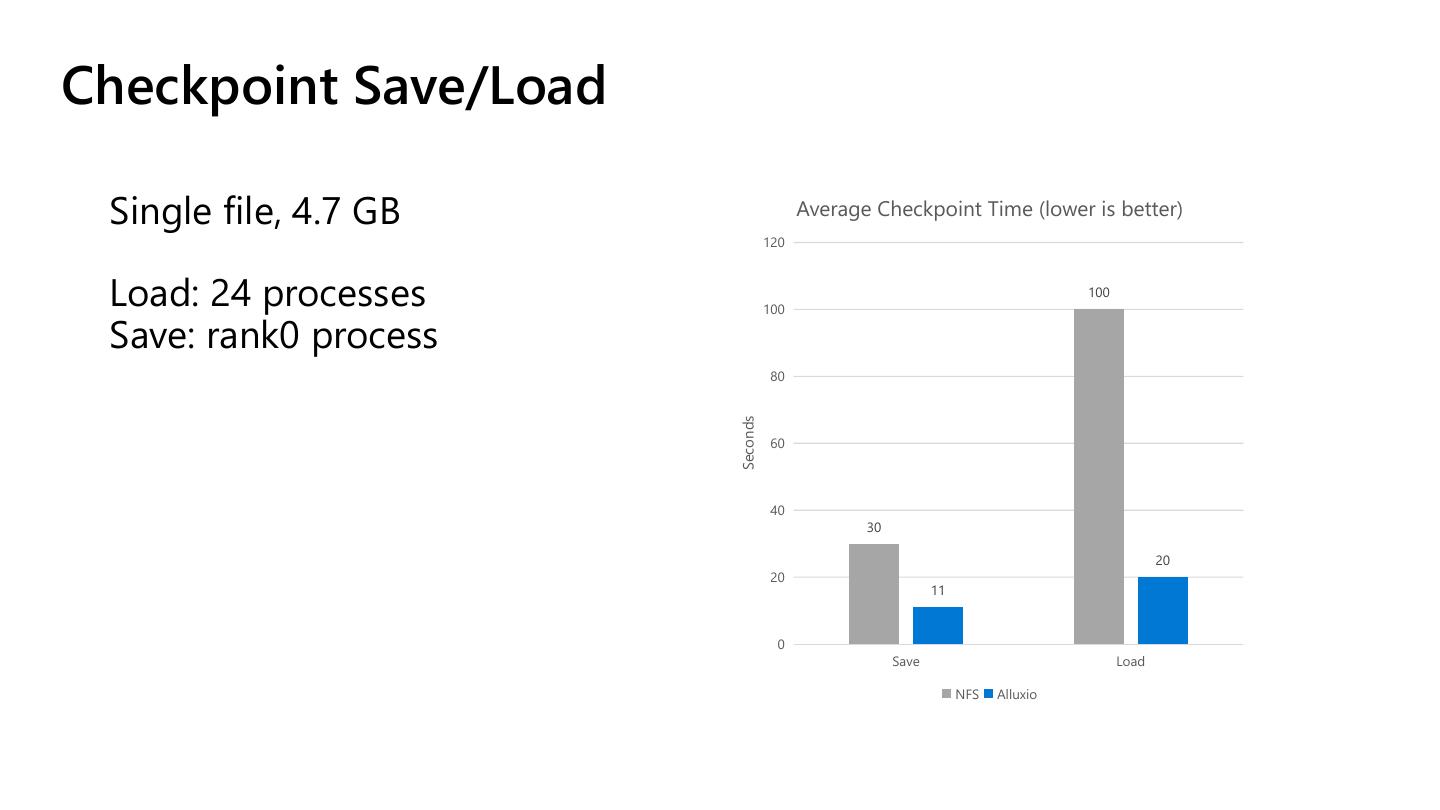
18 .Checkpoint Save/Load
Single file, 4.7 GB Average Checkpoint Time (lower is better)
120
Load: 24 processes 100
100
Save: rank0 process
80
Seconds
60
40
30
20
20
11
0
Save Load
NFS Alluxio
�
19 .Looking Forward
• Build pilot experience for customers
• Make alluxio more stable on K8S
• Enable IB support for better performance
�
20 .Thank you!
© Copyright Microsoft Corporation. All rights reserved.
�