






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Doris 的Join实现与调优技巧实践-李昊鹏
Apache Doris 的Join实现与调优技巧实践
Apache Doris是百度贡献给Apache社区的一款高性能企业级的MPP数据库,支持近实时数据分析,亚秒级实时性保证,可高效处理数据的读取和写入。本次将分享 Apache Doris 分布式Join操作的底层实现原理与调优技巧实践。
李昊鹏,Apache Doris 社区 Contributor,数据库内核开发工程师,现就职于百度AI与数据平台部。负责 Apache Doris 查询计算,存储引擎的相关开发工作。
展开查看详情
1 .Apache Doris Join的实现与调优实践 李昊鹏 Apache Doris Contributor 百度 高级研发工程师
2 . 01 02 03 Doris简介 Doris的Join Join的调优实践
3 . 01 Doris简介
4 . 01 Doris简介 系统定位 • 基于MPP(大规模并行处理)架构的分析型数据库 • 性能卓越,PB级别数据毫秒/秒级响应 • 适用于高并发、低延时下的多维分析、实时报表等场景 • 由百度自研,2017年开源,2018年贡献给Apache社区后更名为 Apache Doris • 百度内部统称其为“数据仓库Palo”,百度智能云上提供Palo的企业级托管版本
5 . 01 Doris简介 发展历程 2008 2009 2012 • 1.0版本正式上线 • 进行了通用化改造,开始承 • 随百度业务飞速发展,对 • 应用于百度凤巢统计报表的 接公司内部其他报表系统 Doris的性能、可用性、拓 需求场景,上线后数据更新 • 助力百度统计成为国内最大 展性进行了全面升级 频率从天级提升至分钟级 的中文网站分析工具 • 承担百度所有统计报表业务 01 02 03
6 . 01 Doris简介 2013 2015 2018 2021 • 进行MPP框架的升级,开始 • 精简架构、统一用户客户端, • 2017年正式开源 • 截止目前,Github 2.9k+ star, 支持分布式计算 实现高可用 • 2018年贡献给Apache社区, Contributor 180+ • 全新的数据模型,查询存储 • 正式开始对外提供服务 更名为 Apache Doris • 美团、京东、小米、字节、快手 效率大幅提升 等众多一线互联网公司广泛使用 04 05 06 07
7 . Doris在数据流中的定位 01 Doris简介 数据源 数据集成 数据分析 数据应用 Doris Studio OLTP 实时大屏 业务应用 多维报表 WEB端日志 自助查询 移动端日志 用户画像 本地文件 对象存储
8 . Doris核心特性 01 Doris简介 极致性能 简单易用 流批一体 极简运维 可用性高 生态丰富 • 高效列式存储引擎 • 标准SQL支持 • 批量和实时流式数据导入 • 高度一体,无任何外部 • 主节点高可用 • BOS/HDFS/Kafka等数 • 现代化MPP架构 • 完全兼容MySQL协议 • 行级别数据更新/删除 组件依赖 • 数据多副本存储 据无缝导入 • 向量化执行引擎 • 灵活的数据模型 • 多版本机制解决读写冲突 • 集群规模弹性伸缩 • 节点故障自动副本迁移 • Spark联邦数据分析 • 智能物化视图技术 • 优秀Join表现 • 导入事务支持,保证ACID • 任何节点可线性拓展 • 自动请求路由 • 为ES提供分布式SQL查询 • 无并发瓶颈,100台集 • 在线表结构变更 • 实现Exactly-Once语义 • 无代码即可完成运维 • 数据分片自动均衡 • 主流BI工具适配 群可达10wQPS • Bitmap索引精确去重
9 . 01 Doris简介 MySQL Tools (MySQL Networking) 整体架构简单,产品易用 • 高度兼容MySQL协议 FE FE FE FE (Leader,JAVA) (Follower,JAVA) (Follower,JAVA) (Obsever,JAVA) • 主从架构,不依赖任何其他组件 • FE负责解析/生成/调度查询计划 • BE负责执行查询计划、数据存储 BE BE BE BE (C++) (C++) (C++) (C++) • 任何节点都可线性扩展
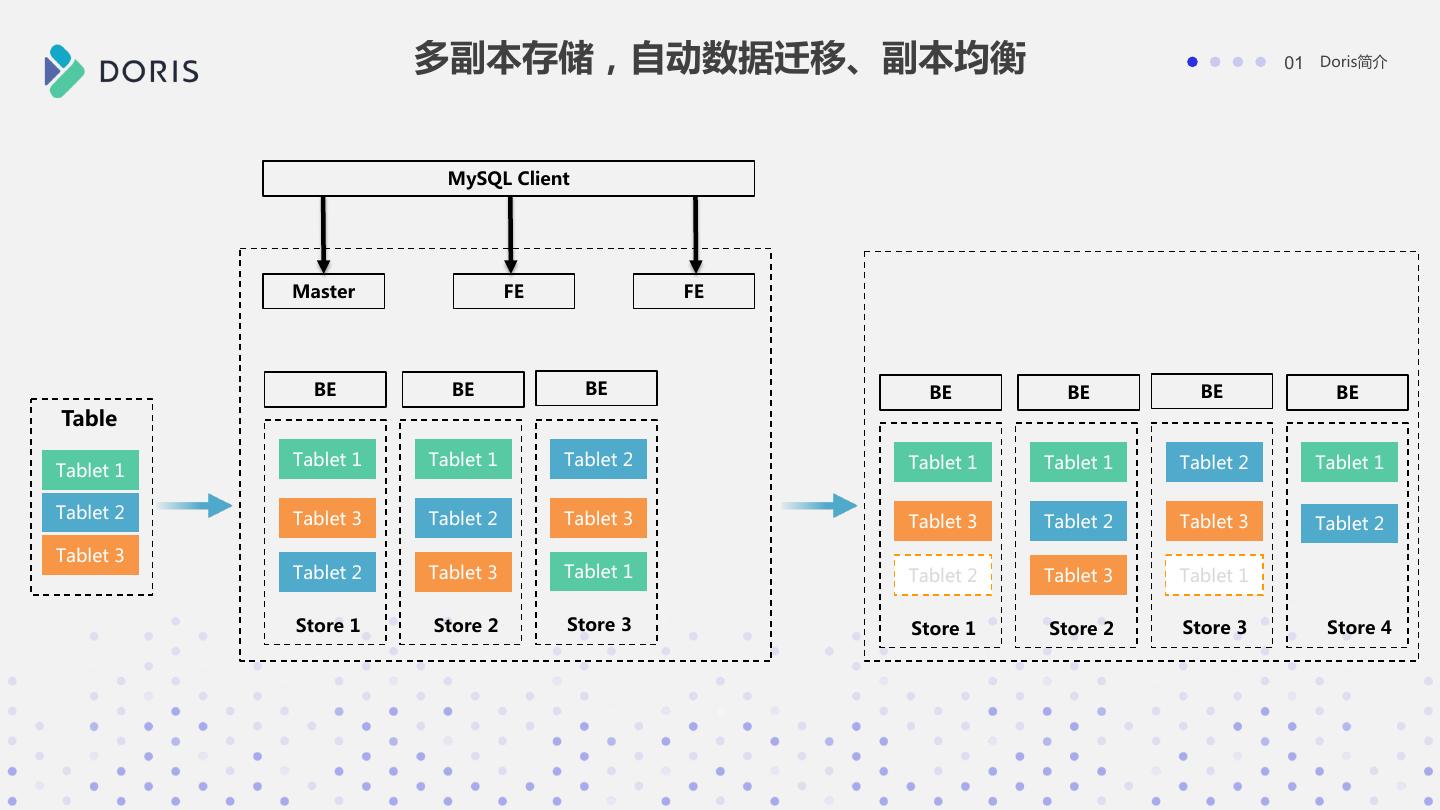
10 . 多副本存储,自动数据迁移、副本均衡 01 Doris简介 MySQL Client Master FE FE BE BE BE BE BE BE BE Table Tablet 1 Tablet 1 Tablet 2 Tablet 1 Tablet 1 Tablet 2 Tablet 1 Tablet 1 Tablet 2 Tablet 3 Tablet 2 Tablet 3 Tablet 3 Tablet 2 Tablet 3 Tablet 2 Tablet 3 Tablet 2 Tablet 3 Tablet 1 Tablet 2 Tablet 3 Tablet 1 Store 1 Store 2 Store 3 Store 1 Store 2 Store 3 Store 4
11 . 02 Doris 的 Join
12 . 02 Doris的Join 物理算子 性能 场景 Hash Join 快 存在等值Join的场景 Join的物理算子 Nest Loop Join 慢 不等值Join或求笛卡尔积的场景
13 . 02 Doris的Join Join数据的Shuffle方式 • 存在S与R关系Join操作: S ⋈ R • N表示参与Join计算的Instance个数 • T(关系) 表示关系的Tuple数目 Shuffle方式 网络开销 物理算子 适用场景 BroadCast N * T(R) Hash Join/Nest Loop Join 通用 Shuffle T(S) + T(R) Hash Join 通用 Bucket Shuffle T(R) Hash Join Join条件中存在左表的分布式列,且左表执行时为单分区 Join条件中存在左表的分布式列,且左右表同属于一个 Colocate 0 Hash Join Colocate Group
14 . 02 Doris的Join Join数据的Shuffle方式 Broadcast Join 左表数据不移动,右表的数据发送到左表数据的扫描节点 Shuffle Join 左右表数据根据分区,计算的结果发送到不同的分区节点上
15 . 02 Doris的Join Join数据的Shuffle方式 Bucket Shuffle Join 左表数据不移动,右表的数据根据分区计算的结果 发送到左表扫描节点 Colocate Join 数据已经预先分区,可以直接进行Join计算
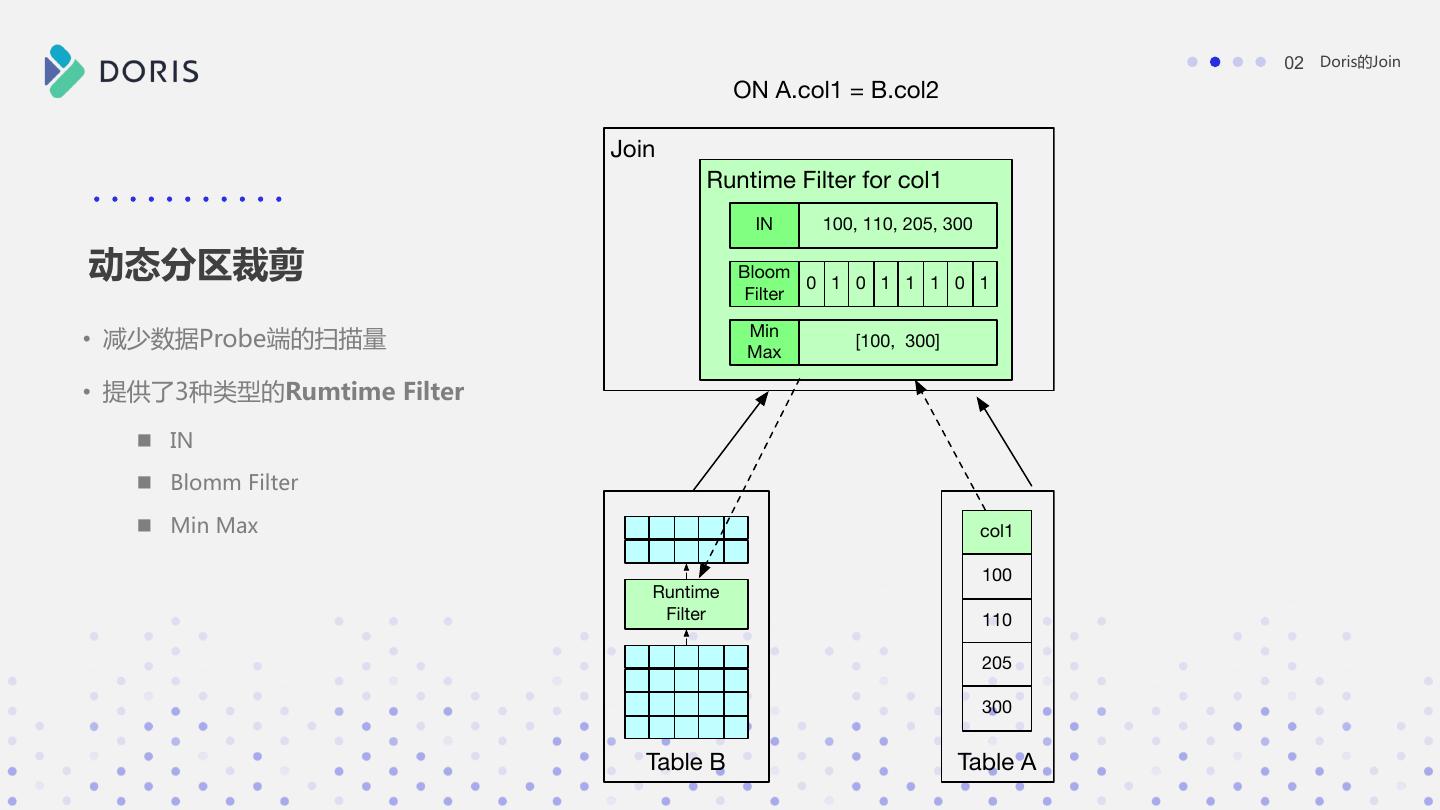
16 . 02 Doris的Join ON A.col1 = B.col2 Join Runtime Filter for col1 IN 100, 110, 205, 300 动态分区裁剪 Bloom 0 1 0 1 1 1 0 1 Filter Min • 减少数据Probe端的扫描量 Max [100, 300] • 提供了3种类型的Rumtime Filter n IN n Blomm Filter n Min Max col1 100 Runtime Filter 110 205 300 Table B Table A
17 . 02 Doris的Join RuntimeFilterMerger Merged 1 2 3 1 2 3 Join Join Join 动态分区裁剪 Merged Merged Merged Probe Build Probe Build Probe Build Table Table Table Table Table Table • Min Max/Bloom Filter在shuffle join时需要filter合并 Join Join Join • Key列的过滤条件会下推到存储引擎,提升延迟物化的效果 Join SELECT A, B, C from tbl where A=2 and C=3 A B C Exchg 0 0 0 Scan1 1 1 1 2 2 2 Agg 3 3 3 4 4 4 5 5 5 6 6 6 Scan2 7 7 7
18 . 02 Doris的Join RuntimeFilter的比较 RuntimeFilter 优点 缺点 适用场景 IN 开销小,效果显著 右表超过一定数据后失效 BroadCast Join MinMax 开销相对较小 仅对数值类型有较好的效果 通用 BloomFilter 适用各种类型,效果好 配置复杂,代价较高 通用
19 . 02 Doris的Join Join Reorder Reorder Join2 Join2 2000 rows Join1 Scan3 10 rows 100 rows Join1 Scan2 100 rows Scan1 Scan2 Scan1 Scan3 1000 rows 100 rows 1000 rows 10 rows
20 . 03 Join调优实践
21 . 03 Join调优实践 使用Profile定位问题 • 根据Doris执行的反馈的信息进行瓶颈定位 Join调优方法论 了解Doris的Join机制 • 通过Doris的Join机制,分析可能的优化方式 利用Session变量改变Join行为 • 利用一些变量参数改变Join的行为,来进行调优 Query Plan的分析 • 分析查询计划,来验证调优是否生效 Join语句的改写/数据分布调整 • 如果上述方式仍然不奏效,需要语句改写与数据分布的调整
22 . 03 Join调优实践 Join Reorder 典型场景 • 从右边的Profile看,左表的数据量远大于右表 • 尝试开启JoinReorder • set enable_cost_based_join_reorder = true; • 该Join耗时从 14s --> 4s,性能提升3.5倍
23 . 03 Join调优实践 RunTimeFilter典型场景 • 从右边的Profile看,Join的结果数据量 • Build Row = 10M • Proble Row = 60M • Filter Ratio = 60M / 60M * 10M • 查看QueryPaln之后,发现仅有 IN 的 Runtime Filter生效, 显然右表数据量大于1024
24 . 03 Join调优实践 RunTimeFilter典型场景 • 由于Join列为INT类型,且为左表的KEY列。所以这里开启了 Bloom Filter set runtime_filter_type = "2" • 左表通过RunTimeFilter过滤了59M的数据,查询耗时 44s --> 13s,性能提升3.4倍
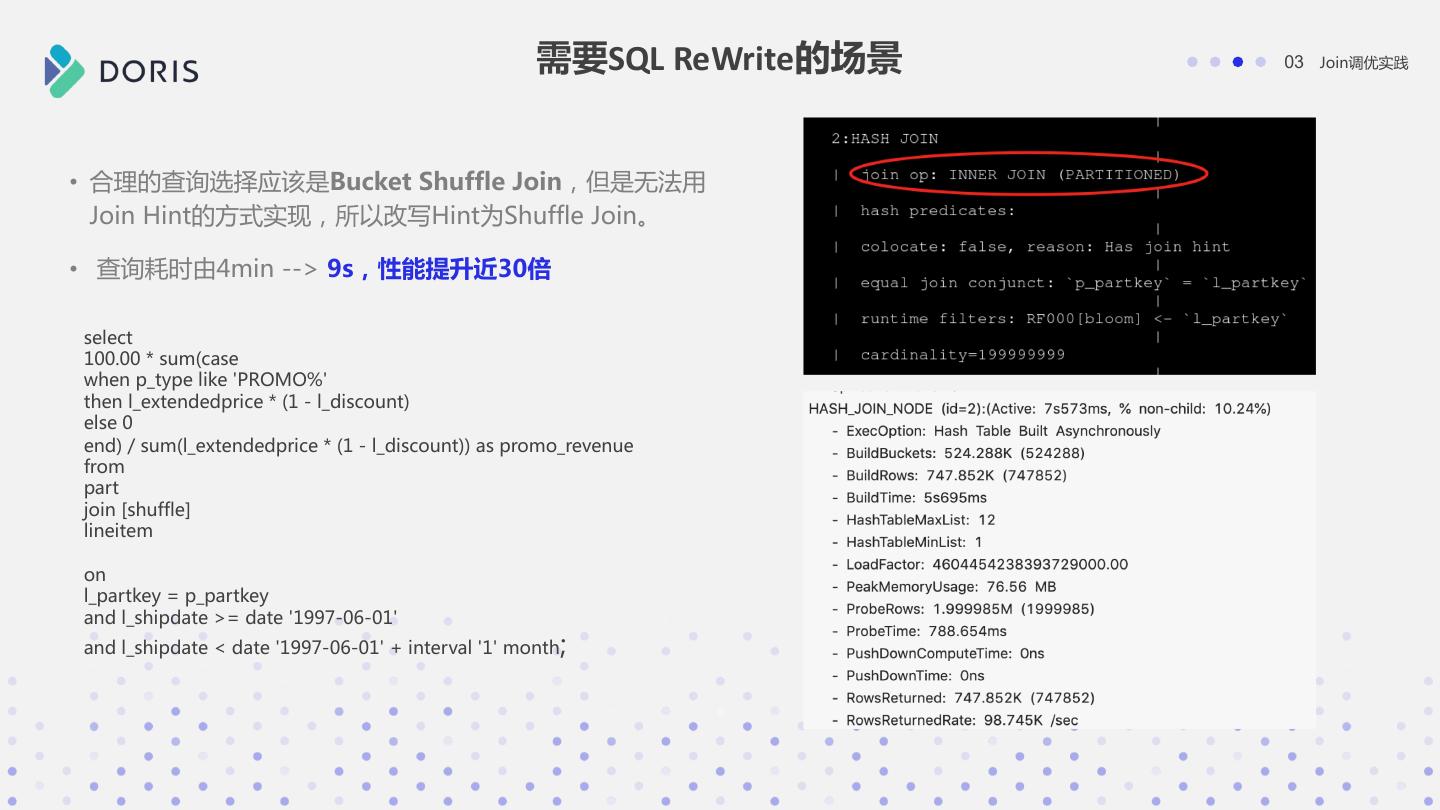
25 . 需要SQL ReWrite的场景 03 Join调优实践 • 左表200M,右表70W,反而选择了BroadCast Join • 原始查询耗时4min
26 . 需要SQL ReWrite的场景 03 Join调优实践 • 合理的查询选择应该是Bucket Shuffle Join,但是无法用 Join Hint的方式实现,所以改写Hint为Shuffle Join。 • 查询耗时由4min --> 9s,性能提升近30倍 select 100.00 * sum(case when p_type like 'PROMO%' then l_extendedprice * (1 - l_discount) else 0 end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue from part join [shuffle] lineitem on l_partkey = p_partkey and l_shipdate >= date '1997-06-01' and l_shipdate < date '1997-06-01' + interval '1' month;
27 . 03 Join调优实践 Join列尽量使用同类型/简单类型 • 减少Cast,提高Join节点本身的效率,更可能得谓词下推 /Key列 最佳实践原则 大表间的Join尽量Colocate • 大表间Join通常会通过Shuffle,Colocate能降低网络开销 • RuntimeFilter在过滤高的场景下效果显著,但是在某些场 合理的使用RuntimeFilter 景可能会有副作用,建议以SQL为粒度进行开关 判断Join的顺序合理性 • 尽量确保左表为大表,右表为小表,必要时使用Hint调整
28 . 03 Join调优实践 下一阶段的工作,手动->自动 • 更加智能的优化器,减少手动调优的心智成本 • 更好的决策依赖更全面的信息:统计信息收集 我们将在Q3完成更细致的统计信息的采集工作,来进一步的提升查询优化器的自动化程度
29 .联系我们 • Apache Doris官方网站:https://doris.apache.org/master/zh-CN/ • GitHub:https://github.com/apache/incubator-doris • Palo发行版:palo.baidu.com • 基于Apache Doris的快速迭代版本 欢迎关注Doris微信公众号 更多技术趋势、实践案例、社区活动
3秒后跳转登录页面
去登陆

