























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Baiyulan/IJCAI2021_Presentation_Plus53630?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
基于因果干预和依赖多任务学习的图像描述生成
分享
点赞
0
收藏
0
下载 0
目前的图像描述生成的工作主要是先对图像提取物体级别的特征序列,然后将此任务制定为单个序列到序列的任务。尽管这些工作取得了很不错的进展,但我们仍然在生成的文本中发现了两个问题:1)内容不一致,模型会生成图文矛盾的事实; 2) 信息量不足,模型会遗漏部分重要信息。从因果关系的角度来看,原因是模型捕获了视觉特征和某些文本之间的虚假统计相关性(例如,图像中的“长发”的视觉特征和文本中的“女人”)。在本文中,我们提出了一个结合因果干预和依赖多任务学习的框架。
首先,在最终任务图像字幕之前,我们引入一个中间任务——物体类别袋生成。此中间任务将帮助模型更好地理解视觉特征,从而缓解内容不一致问题。其次,我们将Judea Pearl因果理论中的do-calculus操作应用到模型上,切断了视觉特征和可能的混杂因素之间的联系,从而让模型专注于因果视觉特征。具体来说,高频概念集被视为代理混杂因素,并在拉式空间中推断出真正的混杂因素。最后,我们使用多智能体强化学习 (MARL) 策略来进行端到端训练并减少任务间错误累积。广泛的实验表明,我们的模型优于基线模型,并在与最先进的模型的比较中达到了具有竞争力的性能。
本工作发表在IJCAI 2021上。
展开查看详情
1 .
2 .Dependent Multi-Task Learning with Causal Intervention for Image Captioning Wenqing Chen, Jidong Tian, Caoyun Fan, Hao He∗, Yaohui Jin∗ MoE Key Lab of Artificial Intelligence, AI Institute, Shanghai Jiao Tong University State Key Lab of Advanced Optical Communication System and Network, Shanghai Jiao Tong University
3 .Background A large white dog is sitting on a bench beside an elderly man. A large white dog sits on a bench with people next to a path. A large dog sits just his bottom on a park bench. A couple of people sitting on a bench next to a dog. A dog sitting on a bench next to an old man. Image Captioning: describing images with syntactically and semantically meaningful sentences. Importance of the task: 1) It plays an essential role in human-machine interactions via connecting vision and language; 2) It already has some valuable applications in E-commerce such as product description generation, cross-modal retrieval, etc.
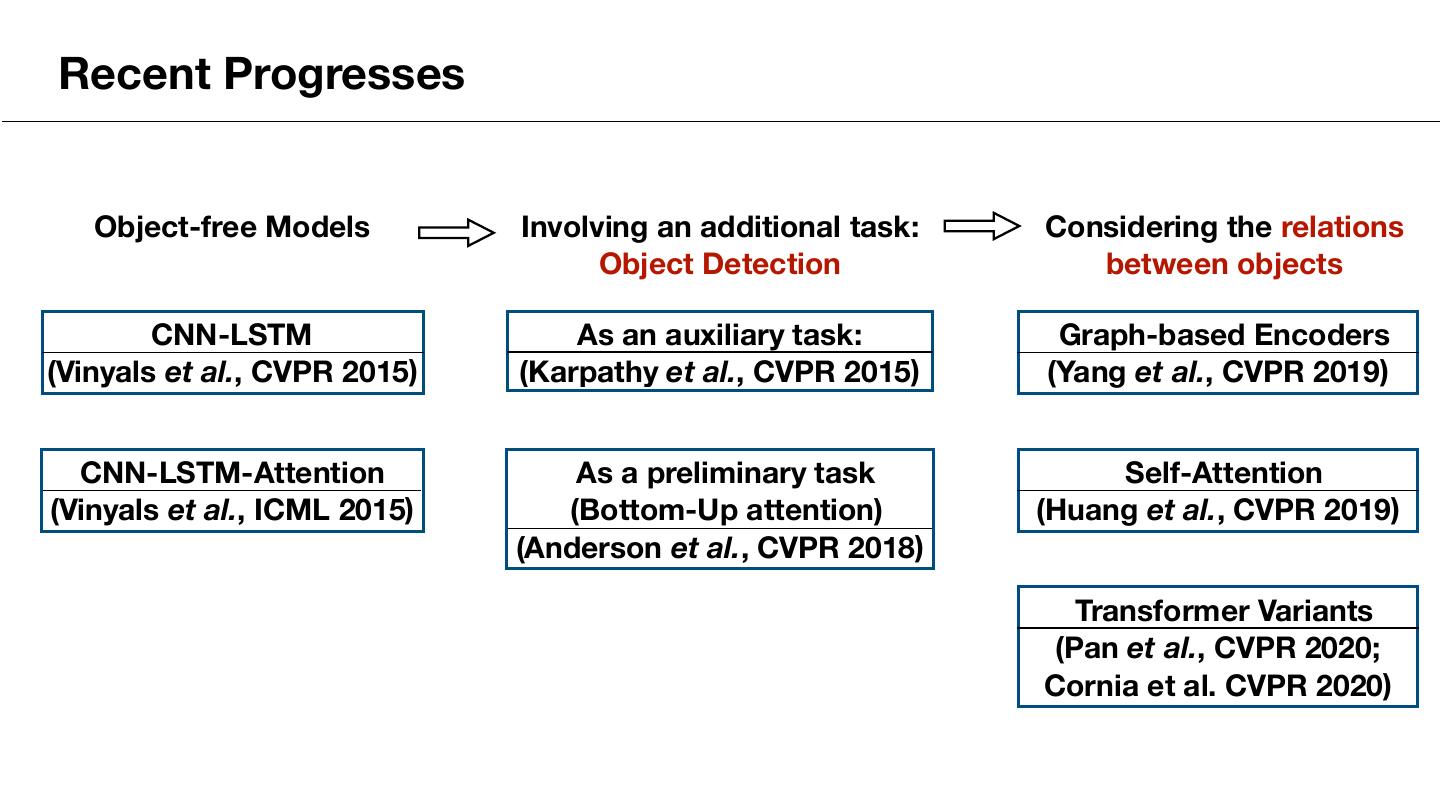
4 .Recent Progresses Object-free Models Involving an additional task: Considering the relations Object Detection between objects CNN-LSTM As an auxiliary task: Graph-based Encoders (Vinyals et al., CVPR 2015) (Karpathy et al., CVPR 2015) (Yang et al., CVPR 2019) CNN-LSTM-Attention As a preliminary task Self-Attention (Vinyals et al., ICML 2015) (Bottom-Up attention) (Huang et al., CVPR 2019) (Anderson et al., CVPR 2018) Transformer Variants (Pan et al., CVPR 2020; Cornia et al. CVPR 2020)
5 .Recent Progresses References in the last slide: [1] Vinyals et al. Show and tell: A neural image caption generator. CVPR 2015. [2] Xu et al. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ICML 2015. [3] Karpathy et al. Deep visual-semantic alignments for generating image descriptions. CVPR 2015. [4] Anderson et al. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. CVPR 2018. [5] Huang et al. Attention on Attention for Image Captioning. CVPR 2019. [6] Yang et al. Auto-encoding scene graphs for image captioning. CVPR 2019. [7] Pan et al. X-Linear Attention Networks for Image Captioning. CVPR 2020. [8] Cornia et al. Meshed-Memory Transformer for Image Captioning. CVPR 2020.
6 . Challenge We still observe some problems in this task when building a Transformer variant: 1)Content Inconsistency: 2)Not Informative Enough:
7 . Challenge Spurious Correlations caused by Confounders. mismatched Confounder “visual features” and “caption words” Image Caption Confounder woman long hair female A woman sitting on the back of a couch next to a man wearing glasses. X Confounder woman A man and a woman sitting on a couch. long hair
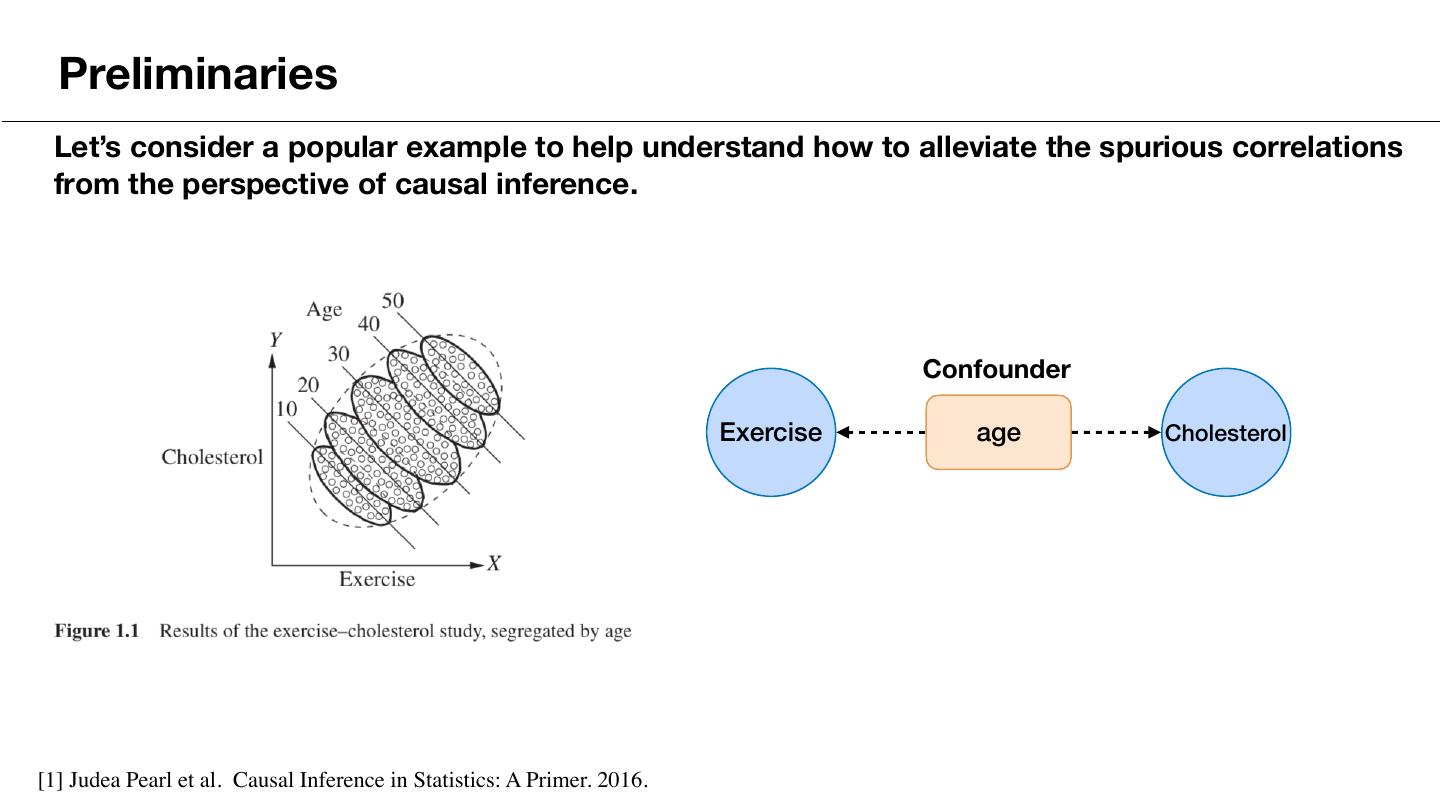
8 . Preliminaries Let’s consider a popular example to help understand how to alleviate the spurious correlations from the perspective of causal inference. Confounder Exercise age Cholesterol [1] Judea Pearl et al. Causal Inference in Statistics: A Primer. 2016.
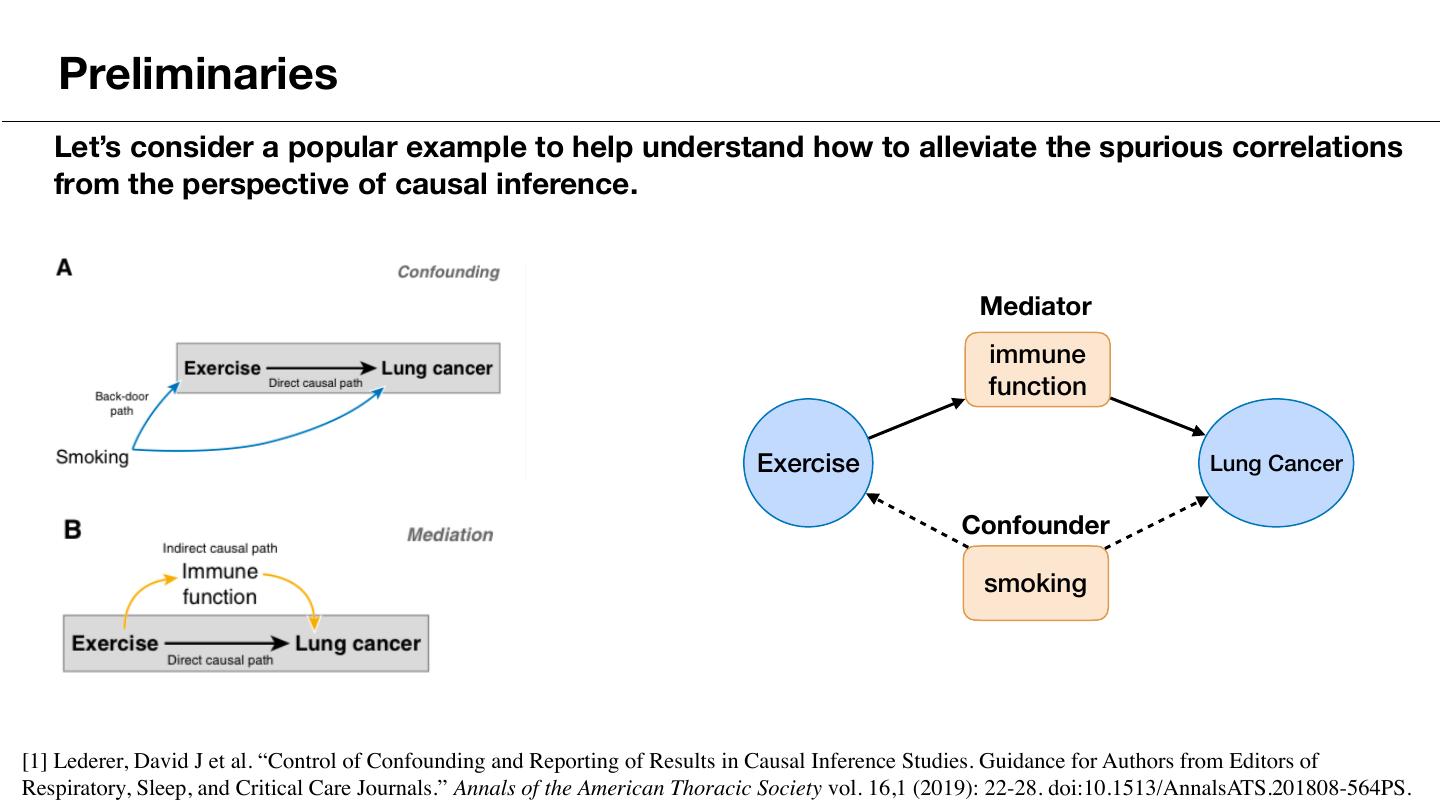
9 . Preliminaries Let’s consider a popular example to help understand how to alleviate the spurious correlations from the perspective of causal inference. Mediator immune function Exercise Lung Cancer Confounder smoking [1] Lederer, David J et al. “Control of Confounding and Reporting of Results in Causal Inference Studies. Guidance for Authors from Editors of Respiratory, Sleep, and Critical Care Journals.” Annals of the American Thoracic Society vol. 16,1 (2019): 22-28. doi:10.1513/AnnalsATS.201808-564PS.
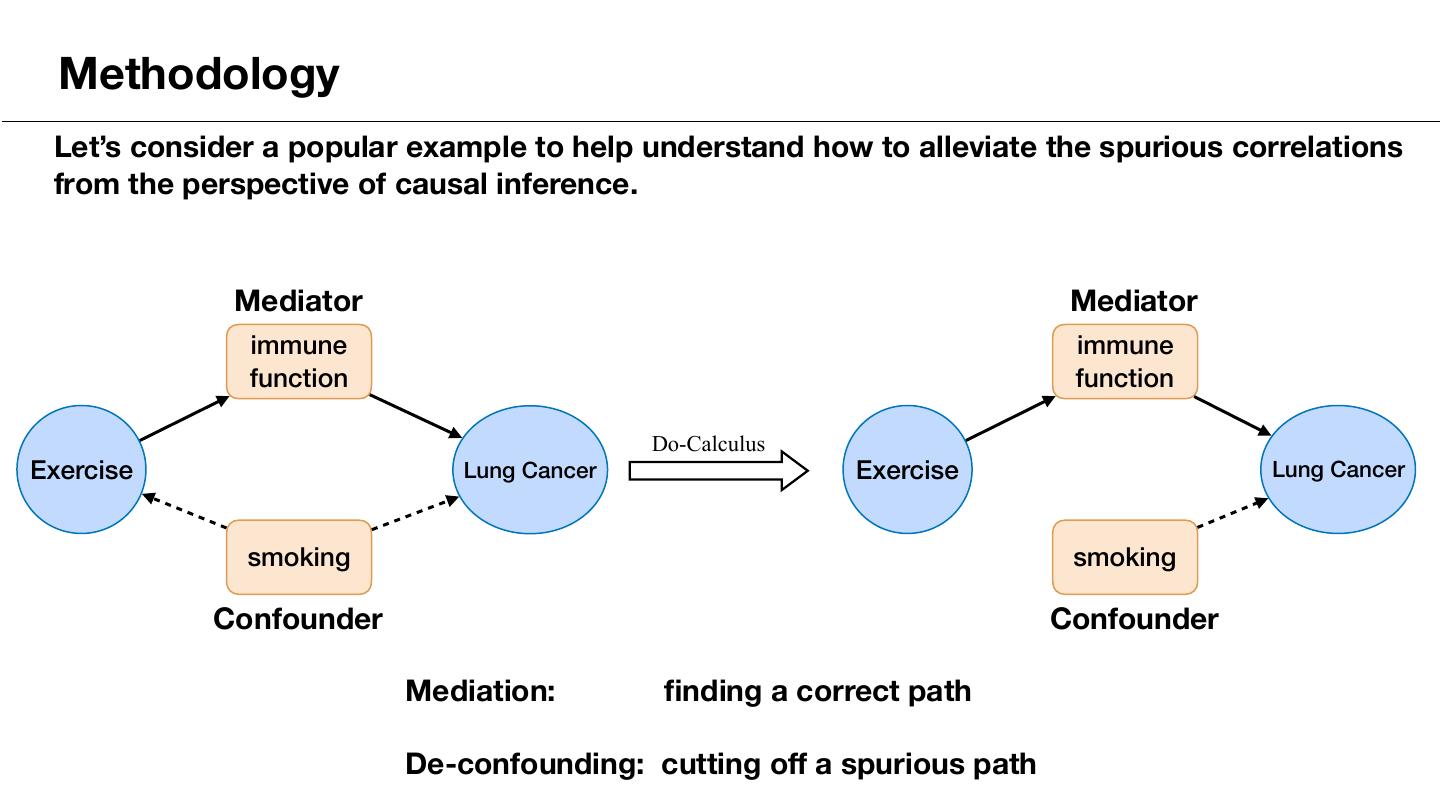
10 . Methodology Let’s consider a popular example to help understand how to alleviate the spurious correlations from the perspective of causal inference. Mediator Mediator immune immune function function Do-Calculus Exercise Lung Cancer Exercise Lung Cancer smoking smoking Confounder Confounder Mediation: finding a correct path De-confounding: cutting off a spurious path
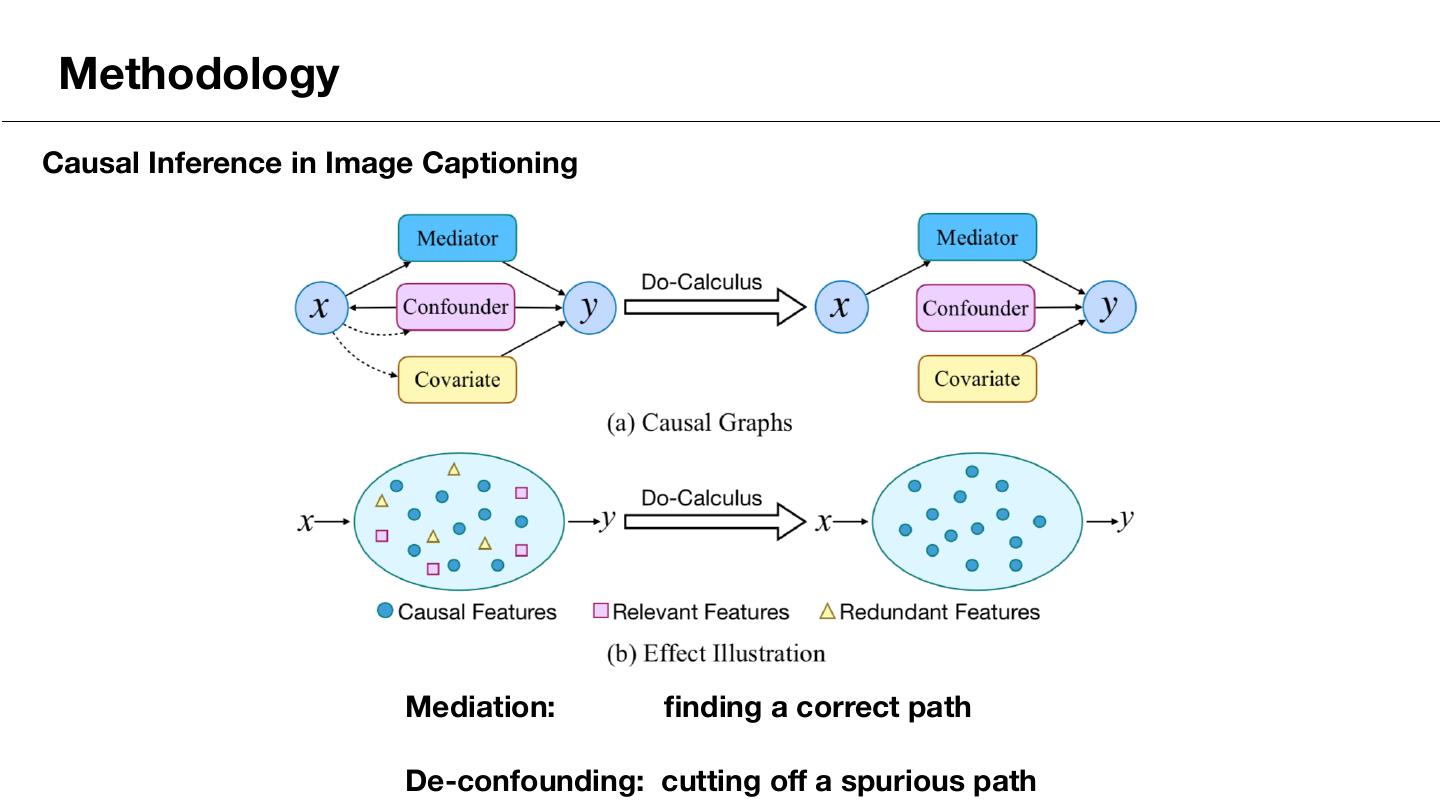
11 . Methodology Causal Inference in Image Captioning Mediation: finding a correct path De-confounding: cutting off a spurious path
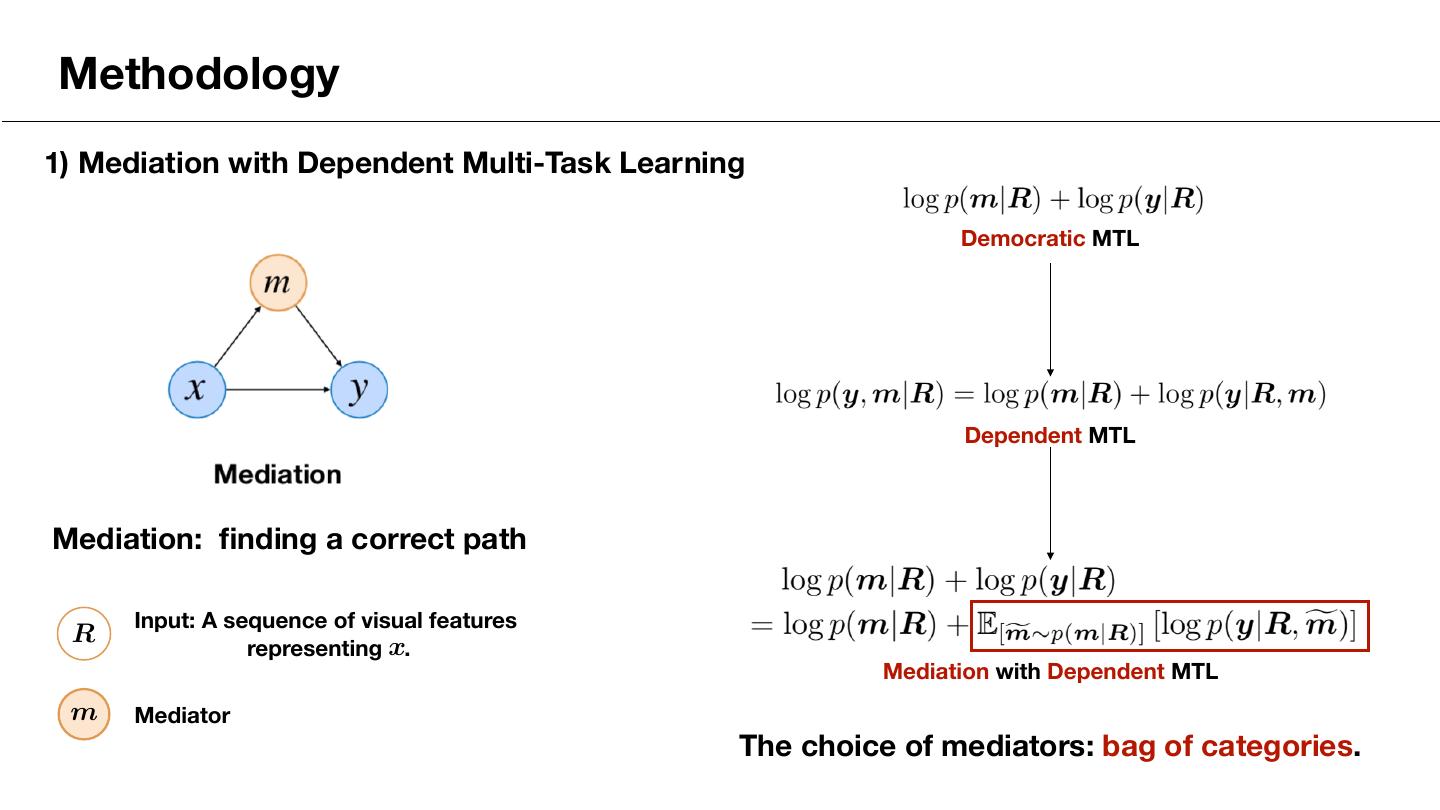
12 .Methodology 1) Mediation with Dependent Multi-Task Learning Democratic MTL Dependent MTL Mediation: finding a correct path Input: A sequence of visual features R <latexit sha1_base64="LDrYFNttM/Qfk5pNSdW/EJ4DhYI=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgQfUhtqBzHaa06dmQ7oCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32I1WaSXFvxgn1YzwQLGIEGys99ALJQz2O7ZXdTfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8OS/Ou/MxG11yip0D+APn8wcbNJLo</latexit> representing x. <latexit sha1_base64="L8I0+8VkoZB8twk/ht5XwWaicL4=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgk+pDaUDmO01p17Mh2gCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32A1WaSXFnxgn1YzwQLGIEGyvd9wLJQz2O7ZU9TfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8Oi/Ou/MxG11yip0D+APn8wdU8pMO</latexit> Mediation with Dependent MTL m <latexit sha1_base64="oBnwf4KvSDL5cUzi3dFystIxSu0=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0mQxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlLKYtwwyn3URRLAJOO8H4Jvc7j1RpJuN7M0moL/AwZhEj2FjpoR9IHuqJsFcmpoNqza27M6Bl4hWkBgWag+pXP5QkFTQ2hGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZGmNBtZ/NUk/RiVVCFEllT2zQTP29kWGh82h2UmAz0oteLv7n9VITXfkZi5PU0JjMH4pSjoxEeQUoZIoSwyeWYKKYzYrICCtMjC2qYkvwFr+8TNpnde+i7t6d1xrXRR1lOIJjOAUPLqEBt9CEFhBQ8Ayv8OY8OS/Ou/MxHy05xc4h/IHz+QNEO5MD</latexit> Mediator
13 .Methodology 1) Mediation with Dependent Multi-Task Learning Democratic MTL Dependent MTL Mediation: finding a correct path Input: A sequence of visual features R <latexit sha1_base64="LDrYFNttM/Qfk5pNSdW/EJ4DhYI=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgQfUhtqBzHaa06dmQ7oCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32I1WaSXFvxgn1YzwQLGIEGys99ALJQz2O7ZXdTfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8OS/Ou/MxG11yip0D+APn8wcbNJLo</latexit> representing x. <latexit sha1_base64="L8I0+8VkoZB8twk/ht5XwWaicL4=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgk+pDaUDmO01p17Mh2gCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32A1WaSXFnxgn1YzwQLGIEGyvd9wLJQz2O7ZU9TfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8Oi/Ou/MxG11yip0D+APn8wdU8pMO</latexit> Mediation with Dependent MTL m <latexit sha1_base64="oBnwf4KvSDL5cUzi3dFystIxSu0=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0mQxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlLKYtwwyn3URRLAJOO8H4Jvc7j1RpJuN7M0moL/AwZhEj2FjpoR9IHuqJsFcmpoNqza27M6Bl4hWkBgWag+pXP5QkFTQ2hGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZGmNBtZ/NUk/RiVVCFEllT2zQTP29kWGh82h2UmAz0oteLv7n9VITXfkZi5PU0JjMH4pSjoxEeQUoZIoSwyeWYKKYzYrICCtMjC2qYkvwFr+8TNpnde+i7t6d1xrXRR1lOIJjOAUPLqEBt9CEFhBQ8Ayv8OY8OS/Ou/MxHy05xc4h/IHz+QNEO5MD</latexit> Mediator The choice of mediators: bag of categories.
14 .Methodology 1) Mediation with Dependent Multi-Task Learning Mediation: finding a correct path Input: A sequence of visual features R <latexit sha1_base64="LDrYFNttM/Qfk5pNSdW/EJ4DhYI=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgQfUhtqBzHaa06dmQ7oCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32I1WaSXFvxgn1YzwQLGIEGys99ALJQz2O7ZXdTfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8OS/Ou/MxG11yip0D+APn8wcbNJLo</latexit> representing x. <latexit sha1_base64="L8I0+8VkoZB8twk/ht5XwWaicL4=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgk+pDaUDmO01p17Mh2gCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32A1WaSXFnxgn1YzwQLGIEGyvd9wLJQz2O7ZU9TfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8Oi/Ou/MxG11yip0D+APn8wdU8pMO</latexit> m <latexit sha1_base64="oBnwf4KvSDL5cUzi3dFystIxSu0=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0mQxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlLKYtwwyn3URRLAJOO8H4Jvc7j1RpJuN7M0moL/AwZhEj2FjpoR9IHuqJsFcmpoNqza27M6Bl4hWkBgWag+pXP5QkFTQ2hGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZGmNBtZ/NUk/RiVVCFEllT2zQTP29kWGh82h2UmAz0oteLv7n9VITXfkZi5PU0JjMH4pSjoxEeQUoZIoSwyeWYKKYzYrICCtMjC2qYkvwFr+8TNpnde+i7t6d1xrXRR1lOIJjOAUPLqEBt9CEFhBQ8Ayv8OY8OS/Ou/MxHy05xc4h/IHz+QNEO5MD</latexit> Mediator
15 . Methodology 2) De-Confounding <latexit sha1_base64="vCfv2kAMNfW4LSrS6MatAQmQrEw=">AAADwXicjVJbi9QwFM60XtZ6m9VHX4KDsoIMrYj6oiwugo+rOLsLTSlpemY2bJKWJFWG0D/pi/hvTGcG2c5MYQ+EfjmX73w9OUUtuLFx/HcUhLdu37l7cC+6/+Dho8fjwydnpmo0gxmrRKUvCmpAcAUzy62Ai1oDlYWA8+LqpIuf/wRteKV+2GUNmaQLxeecUetd+eHoDylgwZWjgi8UlG1UH5GiEqVZSv9xyxYTyUt83fe9fYVffiSmkbljPr4CssU3qXzdu8utO/PMfRY50L+fxQayCIm8UEntZVG4L23uUmK5KGEtm8sdmn0sXuIvXsK6sK9tL8uA5KxNbzigwW6DMdZ6/oiAKv+/Yz6exNN4ZXgXJBswQRs7zce/SVmxRoKyTFBj0iSubeaotpwJaCPSGKgpu6ILSD1UVILJ3GoDW/zCe0o8r7Q/yuKV93qFo9J0Wn1m9xpmO9Y598XSxs4/ZI6rurGg2LrRvBHYVrhbZ1xyDcyKpQeUae61YnZJNWXWL33kh5Bs//IuOHszTd5N429vJ8efN+M4QM/Qc3SEEvQeHaOv6BTNEAs+BWUgAxWehDysQ71ODUabmqeoZ6H7B01dQrw=</latexit> XX p(y | R) = p(y | R, m, c)p(m | R)p(c | R) c m = E[c̃⇠p(c|R),f f, e m⇠p(m|R)] [p(y | R, m c)] <latexit sha1_base64="7id1TMLBhULOfiXa4HHRHgPEqQc=">AAADp3icjVLbjtMwEHUTLku4deGRF4sC2kqoShACXpBWICTECwtsu5XiKHIct2ut7US2A6osfxo/wRt/g9NWiKStxEhJjmfmzBxPpqg50yaOfw+C8Nr1GzePbkW379y9d394/GCmq0YROiUVr9S8wJpyJunUMMPpvFYUi4LTi+LqfRu/+E6VZpU8N6uaZgIvJVswgo135ceDn6igSyYt5mwpaemi+gQVFS/1SviPXTmIBCv9C5tLJWxZuU78qxuP4bO3SDcit8Qnr4Fw8ECZDvV55yx6Z+LGvSpib5V+VstDKPKiWs1FYT+43KbIMF7SjUQmdim+9w9W0k1Wt+leygEtmUv/8+YHux2MEefrR4jK8u/fyoejeBKvDe6CZAtGYGtn+fAXKivSCCoN4VjrNIlrk1msDCOcugg1mtaYXOElTT2UWFCd2fWeOfjUe0q4qJR/pIFr778Mi4VutfrMdvS6H2ud+2JpYxZvMstk3RgqyabRouHQVLBdWlgyRYnhKw8wUcxrheQSK0yMX+3IDyHpX3kXzF5MkleT+MvL0em77TiOwCPwGJyABLwGp+AjOANTQIInwafgW3AejsPP4Sycb1KDwZbzEHQsxH8Aszo3cw==</latexit> XX p(y | do(R)) = p(y | R, m, c)p(m | R)p(c) c m = E[c̃⇠p(c),f f, e m⇠p(m|R)] [p(y | R, m c)] De-confounding: cutting off a spurious path c <latexit sha1_base64="+SHIdft4stYG2E1d2kUMTGULIKg=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0kwxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlTNCWYYbTbqIojgNOO8H4Jvc7j1RpJsW9mSTUj/FQsIgRbKz00A8kD/UktldGpoNqza27M6Bl4hWkBgWag+pXP5QkjakwhGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZKnBMtZ/NUk/RiVVCFElljzBopv7eyHCs82h2MsZmpBe9XPzP66UmuvIzJpLUUEHmD0UpR0aivAIUMkWJ4RNLMFHMZkVkhBUmxhZVsSV4i19eJu2zundRd+/Oa43roo4yHMExnIIHl9CAW2hCCwgoeIZXeHOenBfn3fmYj5acYucQ/sD5/AE1CZL5</latexit> Confounder
16 . Methodology 3) Latent De-Confounding The final objective becomes: log p✓, (y | do(R)) = <latexit sha1_base64="JEEnfSS8IVp9VNaz+zdMAh1ax7o=">AAAD0XicfVNti9NAEN4mvpz1racf/bJYlBakJIeoX4RDEfwk50vvDrqlbDbTdLlNNu5uTmJYEb/67/zmL/BvuGlTba/RgZBh5plnnplMolxwbYLgZ8fzL12+cnXvWvf6jZu3bvf27xxrWSgGYyaFVKcR1SB4BmPDjYDTXAFNIwEn0dnLOn9yDkpzmX0wZQ7TlCYZn3NGjQvN9ju/SAQJzyoqeJJBbLsPiZAJzmcVMQsw9BEm+YLbAYmkiHWZuldVWkxSHmMic1DUSJXRFKpYbqPe2eHwOSbEMabULKKoemUdq4C5mRDDRQwVc0SapzgfsKFrtFH82UHX2Y+uqtawLB20oZZiPvEYVrSbEGYtUTxZmLpBOyS1axmu0TlVO/Om6xbb0614p7YZaWttLWLLVpb/qWpbyT/xfwdtdHUJZPGf7zrr9YNRsDS864SN00eNHc16P0gsWZFCZpigWk/CIDfTiirDmQDbJYWGnLIzmsDEufUJ6Gm1vEiLH7hIjOdSuSczeBndrKhoqmvdDlnfhr6Yq4NtuUlh5s+mFc/ywkDGVo3mhcBG4vq8ccwVMCNK51CmuNOK2YIqyoz7CbpuCeHFkXed44NR+GQUvH3cP3zRrGMP3UP30QCF6Ck6RK/RERoj5r3xjGe9L/57v/S/+t9WUK/T1NxFW+Z//w0rF0u9</latexit> E[c̃⇠p(c),zc ⇠q (z c |e m⇠p' (m|R)] c),f f, z c , e [log p✓ (y | R, m c)] where q! (z c | c) is estimated by VAE: <latexit sha1_base64="ZFcYe2mGhSoNf7NYLNiksnbvER0=">AAACJHicbVDLSsNAFJ3UV62vqks3g0Wom5KIqOCm6MZlBfuApoTJZNIOnTycuRFqyMe48VfcuPCBCzd+i5O2i9p6YJjDOfdy7z1uLLgC0/w2CkvLK6trxfXSxubW9k55d6+lokRS1qSRiGTHJYoJHrImcBCsE0tGAlewtju8zv32A5OKR+EdjGLWC0g/5D6nBLTklC/vndSOBzyzBfOharuR8NQo0F/6mDkpzbAdcA/P6jSzJe8P4NgpV8yaOQZeJNaUVNAUDaf8YXsRTQIWAhVEqa5lxtBLiQROBctKdqJYTOiQ9FlX05AETPXS8ZEZPtKKh/1I6hcCHquzHSkJVL6hrgwIDNS8l4v/ed0E/IteysM4ARbSySA/ERginCeGPS4ZBTHShFDJ9a6YDogkFHSuJR2CNX/yImmd1Kyzmnl7WqlfTeMoogN0iKrIQueojm5QAzURRU/oBb2hd+PZeDU+ja9JacGY9uyjPzB+fgHFHaa4</latexit> <latexit sha1_base64="AsLD8sHmNBV0RI3bN1RBiJL2eSQ=">AAAEDnicpVNLaxRBEO7M+IjjIxs9emlclQR0mRUxuQhBEQQ9RHCTwPaw9PTUzDbp6Z509wTWcX6BF/+KFw+KePXszX9jz+4Qsg8RtKCpouqrrx7dHReCGxuGv9Y8/8LFS5fXrwRXr12/sdHZvHlgVKkZDJgSSh/F1IDgEgaWWwFHhQaaxwIO4+PnTfzwFLThSr61kwKinGaSp5xR61yjTe8uiSHjsqKCZxKSOrhPhMpwMarIKdV2DJY+wKQY83qLxEokZpI7VbF6++kUSLi0Dnsu9K4euXA9R1ETAaldYMAk5wleTiWaZ2O7jYvlpHnAqmRMiBshgxPHTu04jqsXzj9lGq5CG57jEwdoJvxTveVGz3qYqahuCyyu7l/mbikfElWAplZpSXOoXr1uuf6jWUze/3WprQoIyOTsUYw63bAXTgUvG/3W6KJW9kednyRRrMxBWiaoMcN+WNioclvhTEAdkNJAQdkxzWDozGZCE1XT51zje86T4FRpd6TFU+/5jIrmpmndIZsrNouxxrkqNixtuhtVXBalBclmhdJSYKtw8zdwwjUwKybOoExz1ytmY6ops+4HBW4J/cWRl42DR73+k1745nF371m7jnV0G91BW6iPdtAeeon20QAx74P3yfviffU/+p/9b/73GdRba3NuoTnxf/wGKP9m9A==</latexit> Z log p#, (c) = log p# (c | z c ) p (z c ) dz c zc E[zc ⇠q (z c |c)] [log p# (c | z c )] KL (q (z c | c) kp (z c )) In practice, the real confounders are not easy to observe. z c Latent Confounder <latexit sha1_base64="ySNxY54redRjfJdpxfAoe1LfOPw=">AAAB+XicbVC7TsMwFL0pr1JeAUYWiwqJqUoQAsYKFsYi0YfURpHjOK1Vx4lsp1KJ+icsDCDEyp+w8Tc4bQZoOZLlo3PulY9PkHKmtON8W5W19Y3Nrep2bWd3b//APjzqqCSThLZJwhPZC7CinAna1kxz2kslxXHAaTcY3xV+d0KlYol41NOUejEeChYxgrWRfNseBAkP1TQ2V/4084lv152GMwdaJW5J6lCi5dtfgzAhWUyFJhwr1XedVHs5lpoRTme1QaZoiskYD2nfUIFjqrx8nnyGzowSoiiR5giN5urvjRzHqghnJmOsR2rZK8T/vH6moxsvZyLNNBVk8VCUcaQTVNSAQiYp0XxqCCaSmayIjLDERJuyaqYEd/nLq6Rz0XCvGs7DZb15W9ZRhRM4hXNw4RqacA8taAOBCTzDK7xZufVivVsfi9GKVe4cwx9Ynz9MXZQX</latexit> c <latexit sha1_base64="+SHIdft4stYG2E1d2kUMTGULIKg=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0kwxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlTNCWYYbTbqIojgNOO8H4Jvc7j1RpJsW9mSTUj/FQsIgRbKz00A8kD/UktldGpoNqza27M6Bl4hWkBgWag+pXP5QkjakwhGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZKnBMtZ/NUk/RiVVCFElljzBopv7eyHCs82h2MsZmpBe9XPzP66UmuvIzJpLUUEHmD0UpR0aivAIUMkWJ4RNLMFHMZkVkhBUmxhZVsSV4i19eJu2zundRd+/Oa43roo4yHMExnIIHl9CAW2hCCwgoeIZXeHOenBfn3fmYj5acYucQ/sD5/AE1CZL5</latexit> Proxy Confounder
17 . Methodology 3) Latent De-Confounding The choice of proxy confounders: Since we have observed that models over-generated high-frequency expressions, we assume that the proxy confounder c can be sampled from a concept set that includes the high-frequency predicates and fine-grained object categories. In practice, the real confounders are not easy to observe.
18 .Methodology 4) Architecture A woman sitting on the back of Caption Decoder y a couch next to a man wearing <latexit sha1_base64="V+N/0zKAREO15SLtgKyHxqnLYbg=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0kwxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlTNCWYYbTbqIojgNOO8H4Jvc7j1RpJsW9mSTUj/FQsIgRbKz00A8kD/Uktlc2mQ6qNbfuzoCWiVeQGhRoDqpf/VCSNKbCEI617nluYvwMK8MIp9NKP9U0wWSMh7RnqcAx1X42Sz1FJ1YJUSSVPcKgmfp7I8OxzqPZyRibkV70cvE/r5ea6MrPmEhSQwWZPxSlHBmJ8gpQyBQlhk8swUQxmxWREVaYGFtUxZbgLX55mbTP6t5F3b07rzWuizrKcATHcAoeXEIDbqEJLSCg4Ble4c15cl6cd+djPlpyip1D+APn8wdWd5MP</latexit> (LSTM) glasses. zm <latexit sha1_base64="AL8gNTGY4sYDaecahnqDu4Ye/Fk=">AAAB+XicbVBLSwMxGMzWV62vVY9egkXwVHZF1GPRi8cK9gHtsmSz2TY0jyXJFurSf+LFgyJe/Sfe/Ddm2z1o60DIMPN9ZDJRyqg2nvftVNbWNza3qtu1nd29/QP38KijZaYwaWPJpOpFSBNGBWkbahjppYogHjHSjcZ3hd+dEKWpFI9mmpKAo6GgCcXIWCl03UEkWayn3F750yzkoVv3Gt4ccJX4JamDEq3Q/RrEEmecCIMZ0rrve6kJcqQMxYzMaoNMkxThMRqSvqUCcaKDfJ58Bs+sEsNEKnuEgXP190aOuC7C2UmOzEgve4X4n9fPTHIT5FSkmSECLx5KMgaNhEUNMKaKYMOmliCsqM0K8QgphI0tq2ZL8Je/vEo6Fw3/quE9XNabt2UdVXACTsE58ME1aIJ70AJtgMEEPINX8Obkzovz7nwsRitOuXMM/sD5/AFbhZQh</latexit> zc <latexit sha1_base64="ySNxY54redRjfJdpxfAoe1LfOPw=">AAAB+XicbVC7TsMwFL0pr1JeAUYWiwqJqUoQAsYKFsYi0YfURpHjOK1Vx4lsp1KJ+icsDCDEyp+w8Tc4bQZoOZLlo3PulY9PkHKmtON8W5W19Y3Nrep2bWd3b//APjzqqCSThLZJwhPZC7CinAna1kxz2kslxXHAaTcY3xV+d0KlYol41NOUejEeChYxgrWRfNseBAkP1TQ2V/4084lv152GMwdaJW5J6lCi5dtfgzAhWUyFJhwr1XedVHs5lpoRTme1QaZoiskYD2nfUIFjqrx8nnyGzowSoiiR5giN5urvjRzHqghnJmOsR2rZK8T/vH6moxsvZyLNNBVk8VCUcaQTVNSAQiYp0XxqCCaSmayIjLDERJuyaqYEd/nLq6Rz0XCvGs7DZb15W9ZRhRM4hXNw4RqacA8taAOBCTzDK7xZufVivVsfi9GKVe4cwx9Ynz9MXZQX</latexit> Transformer BOC Concepts c ⇠ p(c) <latexit sha1_base64="W35hinOtqDBKkyXj+9Va7Oej2+0=">AAACDnicbVC7TsMwFHXKq5RXgJHFoqpUlipBCBgrWBiLRB9SE1WO47RW7TiyHaQq6hew8CssDCDEyszG3+C0GWjLkSwfnXOv7r0nSBhV2nF+rNLa+sbmVnm7srO7t39gHx51lEglJm0smJC9ACnCaEzammpGeokkiAeMdIPxbe53H4lUVMQPepIQn6NhTCOKkTbSwK55gWChmnDzZXgKPUU5TOqL6tnArjoNZwa4StyCVEGB1sD+9kKBU05ijRlSqu86ifYzJDXFjEwrXqpIgvAYDUnf0Bhxovxsds4U1owSwkhI82INZ+rfjgxxle9mKjnSI7Xs5eJ/Xj/V0bWf0ThJNYnxfFCUMqgFzLOBIZUEazYxBGFJza4Qj5BEWJsEKyYEd/nkVdI5b7iXDef+otq8KeIogxNwCurABVegCe5AC7QBBk/gBbyBd+vZerU+rM95ackqeo7BAqyvX+eFnKQ=</latexit> Encoder Encoder zc <latexit sha1_base64="ySNxY54redRjfJdpxfAoe1LfOPw=">AAAB+XicbVC7TsMwFL0pr1JeAUYWiwqJqUoQAsYKFsYi0YfURpHjOK1Vx4lsp1KJ+icsDCDEyp+w8Tc4bQZoOZLlo3PulY9PkHKmtON8W5W19Y3Nrep2bWd3b//APjzqqCSThLZJwhPZC7CinAna1kxz2kslxXHAaTcY3xV+d0KlYol41NOUejEeChYxgrWRfNseBAkP1TQ2V/4084lv152GMwdaJW5J6lCi5dtfgzAhWUyFJhwr1XedVHs5lpoRTme1QaZoiskYD2nfUIFjqrx8nnyGzowSoiiR5giN5urvjRzHqghnJmOsR2rZK8T/vH6moxsvZyLNNBVk8VCUcaQTVNSAQiYp0XxqCCaSmayIjLDERJuyaqYEd/nLq6Rz0XCvGs7DZb15W9ZRhRM4hXNw4RqacA8taAOBCTzDK7xZufVivVsfi9GKVe4cwx9Ynz9MXZQX</latexit> Transformer m <latexit sha1_base64="oBnwf4KvSDL5cUzi3dFystIxSu0=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0mQxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlLKYtwwyn3URRLAJOO8H4Jvc7j1RpJuN7M0moL/AwZhEj2FjpoR9IHuqJsFcmpoNqza27M6Bl4hWkBgWag+pXP5QkFTQ2hGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZGmNBtZ/NUk/RiVVCFEllT2zQTP29kWGh82h2UmAz0oteLv7n9VITXfkZi5PU0JjMH4pSjoxEeQUoZIoSwyeWYKKYzYrICCtMjC2qYkvwFr+8TNpnde+i7t6d1xrXRR1lOIJjOAUPLqEBt9CEFhBQ8Ayv8OY8OS/Ou/MxHy05xc4h/IHz+QNEO5MD</latexit> Concepts BOC Generator Reconstructor Transformer c <latexit sha1_base64="+SHIdft4stYG2E1d2kUMTGULIKg=">AAAB9XicbVDLSgMxFL1TX7W+qi7dBIvgqsyIqMuiG5cV7APasWQymTY0kwxJRilD/8ONC0Xc+i/u/Bsz7Sy09UDI4Zx7yckJEs60cd1vp7Syura+Ud6sbG3v7O5V9w/aWqaK0BaRXKpugDXlTNCWYYbTbqIojgNOO8H4Jvc7j1RpJsW9mSTUj/FQsIgRbKz00A8kD/UktldGpoNqza27M6Bl4hWkBgWag+pXP5QkjakwhGOte56bGD/DyjDC6bTSTzVNMBnjIe1ZKnBMtZ/NUk/RiVVCFElljzBopv7eyHCs82h2MsZmpBe9XPzP66UmuvIzJpLUUEHmD0UpR0aivAIUMkWJ4RNLMFHMZkVkhBUmxhZVsSV4i19eJu2zundRd+/Oa43roo4yHMExnIIHl9CAW2hCCwgoeIZXeHOenBfn3fmYj5acYucQ/sD5/AE1CZL5</latexit> Mediation with Latent De-confounding Transformer Dependent MTL with VAE x R <latexit sha1_base64="LDrYFNttM/Qfk5pNSdW/EJ4DhYI=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgQfUhtqBzHaa06dmQ7oCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32I1WaSXFvxgn1YzwQLGIEGys99ALJQz2O7ZXdTfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8OS/Ou/MxG11yip0D+APn8wcbNJLo</latexit> <latexit sha1_base64="L8I0+8VkoZB8twk/ht5XwWaicL4=">AAAB9XicbVC7TsMwFL3hWcqrwMhiUSExVQlCwFjBwlgk+pDaUDmO01p17Mh2gCrqf7AwgBAr/8LG3+C0GaDlSJaPzrlXPj5Bwpk2rvvtLC2vrK6tlzbKm1vbO7uVvf2WlqkitEkkl6oTYE05E7RpmOG0kyiK44DTdjC6zv32A1WaSXFnxgn1YzwQLGIEGyvd9wLJQz2O7ZU9TfqVqltzp0CLxCtIFQo0+pWvXihJGlNhCMdadz03MX6GlWGE00m5l2qaYDLCA9q1VOCYaj+bpp6gY6uEKJLKHmHQVP29keFY59HsZIzNUM97ufif101NdOlnTCSpoYLMHopSjoxEeQUoZIoSw8eWYKKYzYrIECtMjC2qbEvw5r+8SFqnNe+85t6eVetXRR0lOIQjOAEPLqAON9CAJhBQ8Ayv8OY8Oi/Ou/MxG11yip0D+APn8wdU8pMO</latexit>
19 . Methodology 5) Multi-Agent Reinforcement Learning (MARL) RL is commonly used for image captioning, especially with the self-critical RL strategy (SCRL). When cooperating with RL, mediation with dependent MTL becomes a MARL problem: SCRL for the BOC Generator: f : Monto-Carlo Sampled BOC; !m: baseline BOC with arg-max operation. <latexit sha1_base64="BQwHX8VqPbWxRpLstD6MKL1mKMY=">AAACA3icbVDLSsNAFJ3UV62vqDvdDBbBVUlE1GXRjcsK9gFNKJPJTTt08mBmopQQcOOvuHGhiFt/wp1/46TNQlsPDHM4517uvcdLOJPKsr6NytLyyupadb22sbm1vWPu7nVknAoKbRrzWPQ8IoGzCNqKKQ69RAAJPQ5db3xd+N17EJLF0Z2aJOCGZBixgFGitDQwD5wH5oNi3IfM8WLuy0movyzM84FZtxrWFHiR2CWpoxKtgfnl+DFNQ4gU5UTKvm0lys2IUIxyyGtOKiEhdEyG0Nc0IiFIN5vekONjrfg4iIV+kcJT9XdHRkJZ7KYrQ6JGct4rxP+8fqqCSzdjUZIqiOhsUJByrGJcBIJ9JoAqPtGEUMH0rpiOiCBU6dhqOgR7/uRF0jlt2OcN6/as3rwq46iiQ3SETpCNLlAT3aAWaiOKHtEzekVvxpPxYrwbH7PSilH27KM/MD5/AIYLmLs=</latexit> m <latexit sha1_base64="eXmTjcH1gMsV9hOdZ0Tbf5gRp40=">AAACAnicbVDLSsNAFJ3UV62vqCtxM1gEVyURUZdFNy4r2FpoQplMJu3QeYSZiVBCceOvuHGhiFu/wp1/46TNQlsvDHM45x7uvSdKGdXG876dytLyyupadb22sbm1vePu7nW0zBQmbSyZVN0IacKoIG1DDSPdVBHEI0buo9F1od8/EKWpFHdmnJKQo4GgCcXIWKrvHgTSyoU7DyLJYj3m9sv5ZNJ3617DmxZcBH4J6qCsVt/9CmKJM06EwQxp3fO91IQ5UoZiRia1INMkRXiEBqRnoUCc6DCfnjCBx5aJYSKVfcLAKfvbkSOui91sJ0dmqOe1gvxP62UmuQxzKtLMEIFng5KMQSNhkQeMqSLYsLEFCCtqd4V4iBTCxqZWsyH48ycvgs5pwz9veLdn9eZVGUcVHIIjcAJ8cAGa4Aa0QBtg8AiewSt4c56cF+fd+Zi1VpzSsw/+lPP5A9QEmFo=</latexit> rewards: SCRL for the Caption Generator: e: Monto-Carlo Sampled caption; !y : baseline caption with greedy decoding. <latexit sha1_base64="iQmv05yukX3dA0u0rlGrqvoTka4=">AAACA3icbVDLSsNAFJ3UV62vqDvdBIvgqiQi6rLoxmUF+4AmlMnkph06mYSZiVJCwI2/4saFIm79CXf+jZM2C209MMzhnHu59x4/YVQq2/42KkvLK6tr1fXaxubW9o65u9eRcSoItEnMYtHzsQRGObQVVQx6iQAc+Qy6/vi68Lv3ICSN+Z2aJOBFeMhpSAlWWhqYB+4DDUBRFkDm+jEL5CTSXzbJ84FZtxv2FNYicUpSRyVaA/PLDWKSRsAVYVjKvmMnysuwUJQwyGtuKiHBZIyH0NeU4wikl01vyK1jrQRWGAv9uLKm6u+ODEey2E1XRliN5LxXiP95/VSFl15GeZIq4GQ2KEyZpWKrCMQKqACi2EQTTATVu1pkhAUmSsdW0yE48ycvks5pwzlv2Ldn9eZVGUcVHaIjdIIcdIGa6Aa1UBsR9Iie0St6M56MF+Pd+JiVVoyyZx/9gfH5A5hTmMc=</latexit> y <latexit sha1_base64="eAq1SPG+FkwYw/1WpgVLWOiv1b8=">AAACAnicbVDLSsNAFJ3UV62vqCtxM1gEVyURUZdFNy4r2FpoQplMJu3QyUyYmQghBDf+ihsXirj1K9z5N07aLLT1wjCHc+7h3nuChFGlHefbqi0tr6yu1dcbG5tb2zv27l5PiVRi0sWCCdkPkCKMctLVVDPSTyRBccDIfTC5LvX7ByIVFfxOZwnxYzTiNKIYaUMN7QNPGLl0514gWKiy2Hx5VhRDu+m0nGnBReBWoAmq6gztLy8UOI0J15ghpQauk2g/R1JTzEjR8FJFEoQnaEQGBnIUE+Xn0xMKeGyYEEZCmsc1nLK/HTmKVbmb6YyRHqt5rST/0wapji79nPIk1YTj2aAoZVALWOYBQyoJ1iwzAGFJza4Qj5FEWJvUGiYEd/7kRdA7bbnnLef2rNm+quKog0NwBE6ACy5AG9yADugCDB7BM3gFb9aT9WK9Wx+z1ppVefbBn7I+fwDmTJhm</latexit> We maximize the rewards of the two agents alternatively.
20 .Experiments Datasets: We experiment on MSCOCO with the Karpathy split, where the train / dev / test number is 113,287 / 5,000 / 5,000. Evaluation We apply five standard metrics for evaluation: CIDEr, BLEU, METROT, ROUGE, and SPICE. All the metrics are computed with the publicly released code [1]. The main metric is CIDEr-D, which can reflect the content consistency and the informativeness based on TF-IDF. Specifically, the TF measures the n-gram consistency to reflect the content consistency, and the IDF measures the rarity of n-grams to reflect the informativeness because rare words are often more informative than high-frequency words. [1] https://github.com/tylin/coco-caption
21 . Experiments 1) Our model DTMCI outperforms baseline TransLSTM a lot; 2) When combined with a trained selector, our model can be further improved to reach SOTA; 3) When gold mediators are fed, the CIDEr can reach 141.9, which is a surprising result.
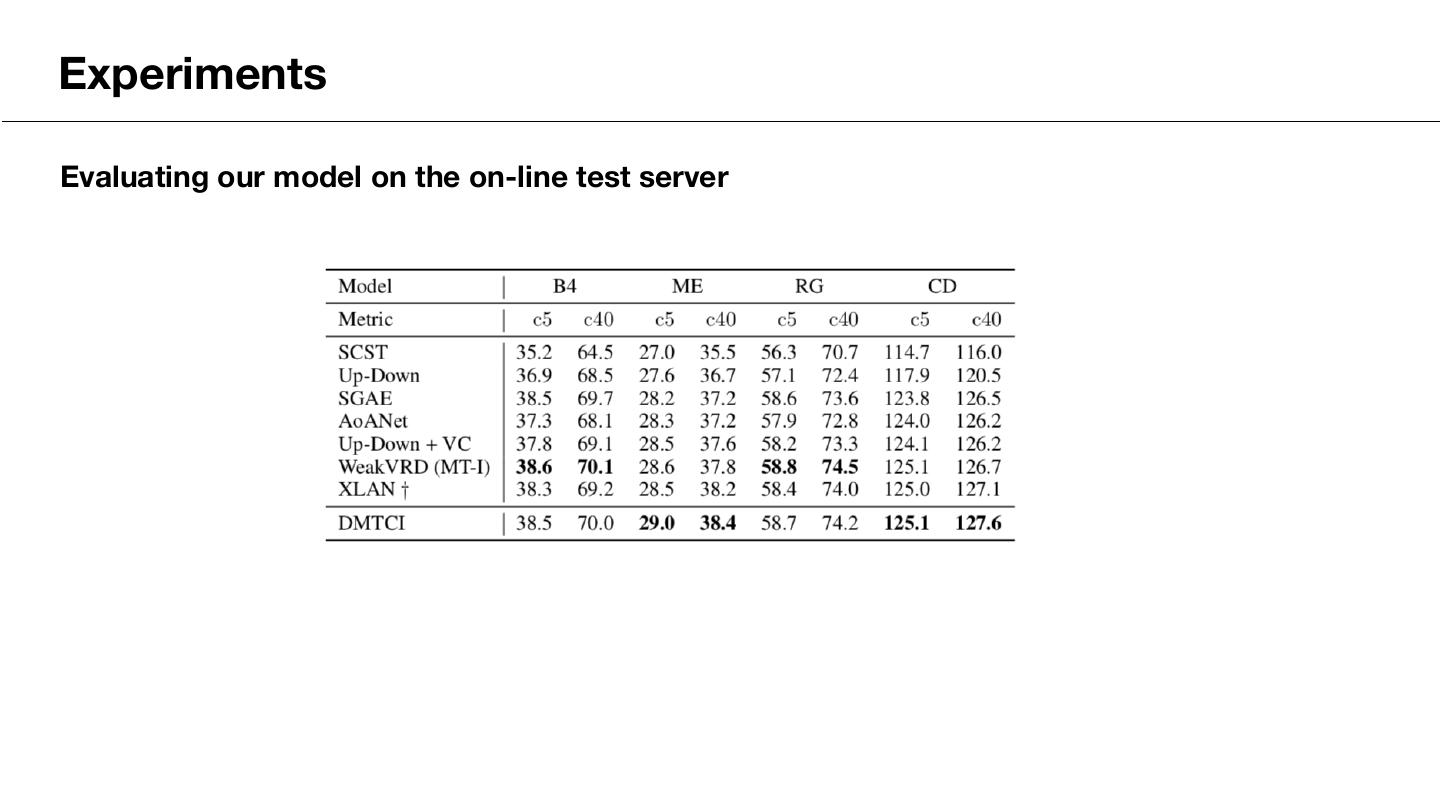
22 .Experiments Evaluating our model on the on-line test server
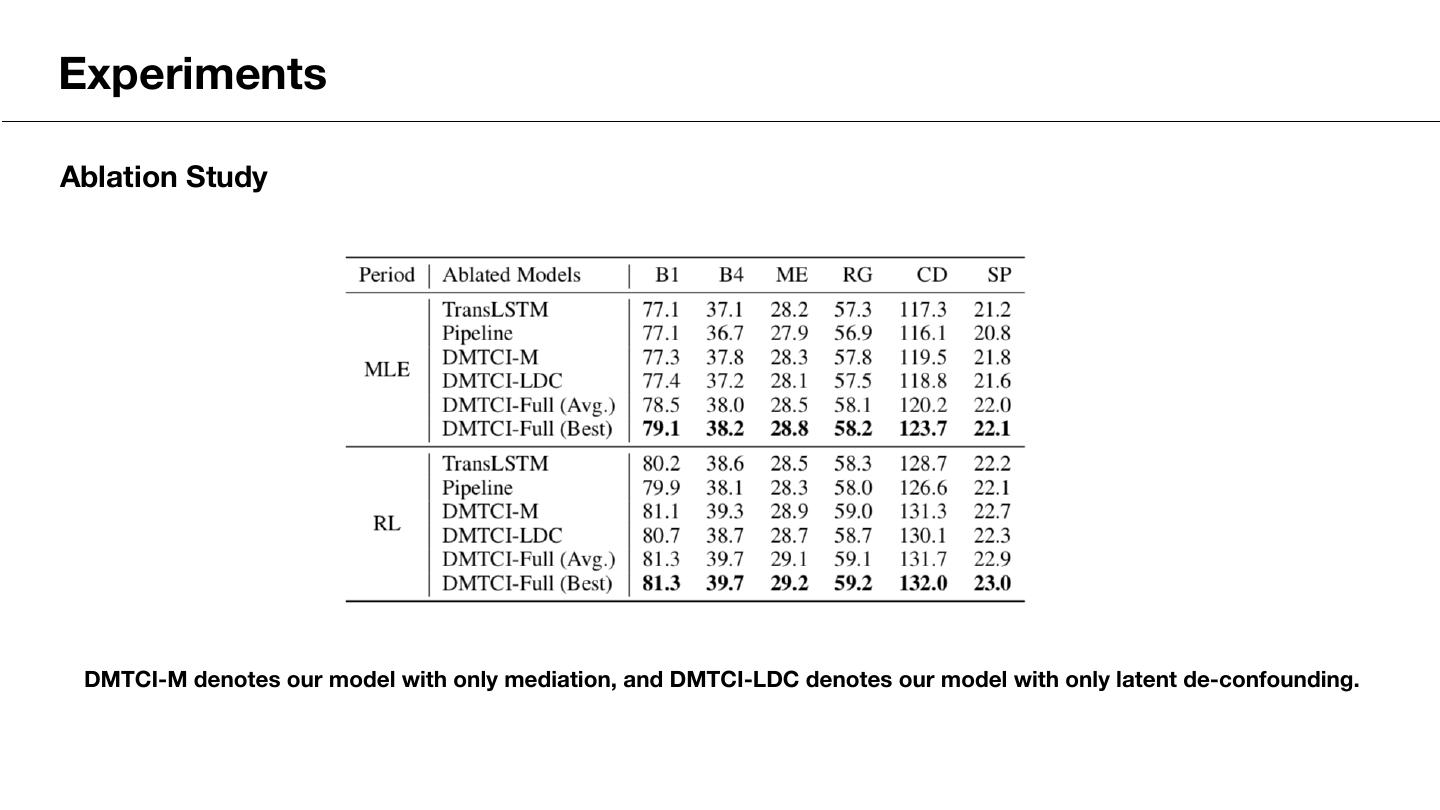
23 .Experiments Ablation Study DMTCI-M denotes our model with only mediation, and DMTCI-LDC denotes our model with only latent de-confounding.
24 .Experiments Case Study
25 .Conclusion • We propose a dependent multi-task framework with causal intervention for image captioning. • We first involve BOC as the mediator to help the model understand the pre-extracted features, then we propose a latent de-confounding approach to alleviate the spurious correlation problem. • Furthermore, we apply a multi-agent reinforcement learning strategy to better utilize the task dependencies and enable end-to-end training. • The experiments show that our model improves content consistency and informativeness over baselines, and yield competitive results with SOTA models.
26 .Thank You !
27 . Our Related Work m n m n m n Y Y Y Y Y Y X : Inputs k Y : Outputs of task k n n n k Tm T Tm T Tm T T : Task-specific layer S : Shared layer !S !S !S X X X (a) Democratic MTL (b) Hierarchical MTL (c) Logically Dependent MTL ( P Y ,Y m n ) ( X =P Y m ) ( X P Y n X ) ( m P Y ,Y n ) ( X =P Y m ) ( X P Y n X ,Y m ) [1] Chen et al. Exploring Logically Dependent Multi-Task Learning with Causal Inference. EMNLP 2020.
28 . Our Related Work [1] Chen et al. Exploring Logically Dependent Multi-Task Learning with Causal Inference. EMNLP 2020.
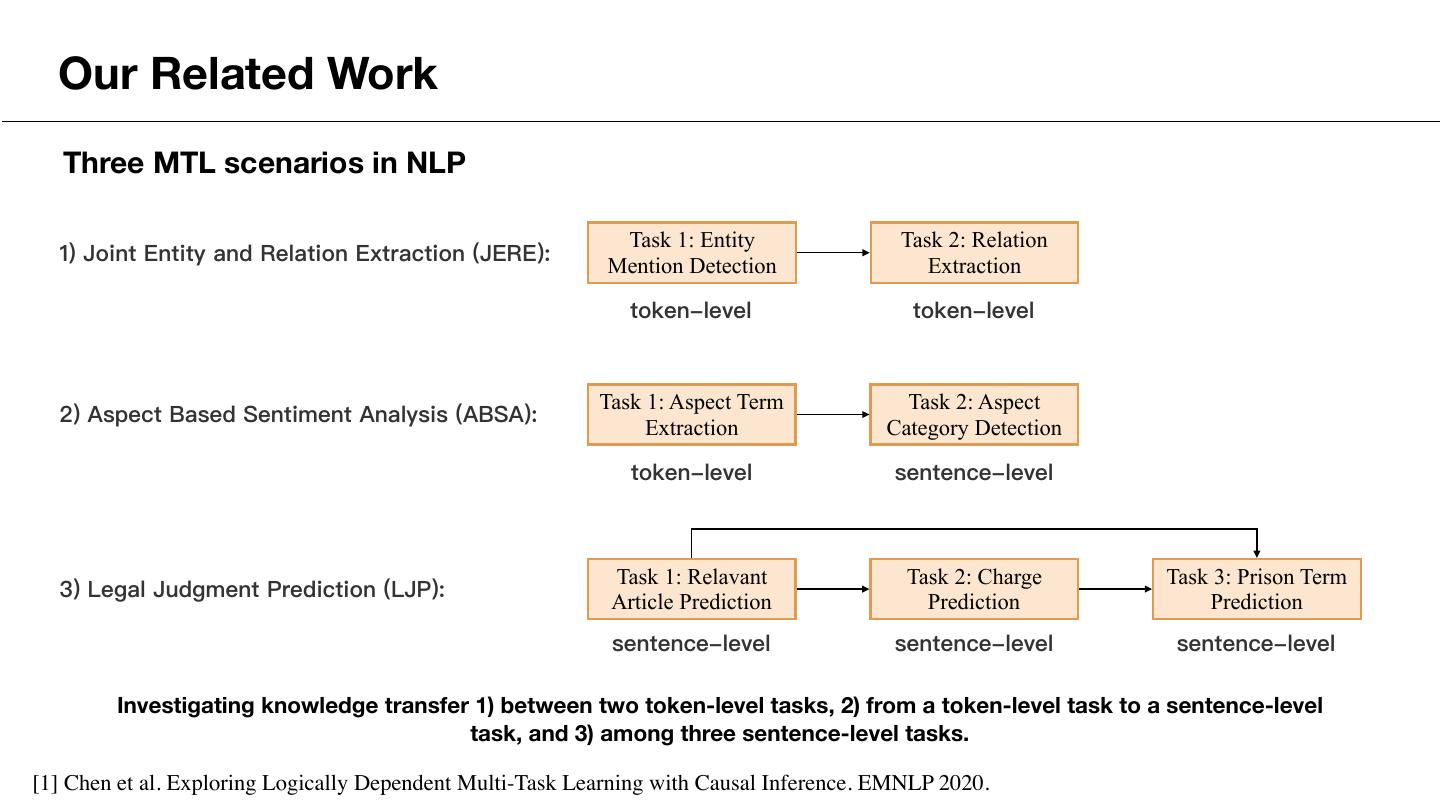
29 . Our Related Work Three MTL scenarios in NLP Task 1: Entity Task 2: Relation 1) Joint Entity and Relation Extraction (JERE): Mention Detection Extraction token-level token-level Task 1: Aspect Term Task 2: Aspect 2) Aspect Based Sentiment Analysis (ABSA): Extraction Category Detection token-level sentence-level Task 1: Relavant Task 2: Charge Task 3: Prison Term 3) Legal Judgment Prediction (LJP): Article Prediction Prediction Prediction sentence-level sentence-level sentence-level Investigating knowledge transfer 1) between two token-level tasks, 2) from a token-level task to a sentence-level task, and 3) among three sentence-level tasks. [1] Chen et al. Exploring Logically Dependent Multi-Task Learning with Causal Inference. EMNLP 2020.
3秒后跳转登录页面
去登陆

