




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Baiyulan/VOLT56339?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
2.内存数据库VOLT特性与实现机制-李军
分享
点赞
2
收藏
0
下载 1
嘉宾介绍
李军,VOLT中国数据库内核架构师,VOLT开源社区贡献者,有丰富的通信网络系统和互联网平台研发和架构经验。早年毕业于国防科技大学,曾在华为、爱立信等企业担任研发及系统架构设计工作,近些年兴趣爱好转向分布式数据库系统,开源产品和开源技术开发者和重度用户。
议题介绍
VOLTDB是由ACM图灵奖得主Michael Stonebraker博士领导的世界一流数据库专家团队所创建的开源产品,它是一款性能出色的分布式内存数据库和数据处理引擎。得益于原生分布式的架构设计,以及基于JVM的分布式协调组件,VOLTDB具备优秀的扩容能力、丰富的生态支持能力。
展开查看详情
1 .VOLT ACTIVE DATA 关键特性与实现机制
2 .内容 01 定位和出发点 02 技术折衷 03 设计实现
3 .VOLT ACTIVE DATA 简介
4 . VOLT ACTIVE DATA(VOLTDB)是唯一支持完整事务、云原生并开源的分布式内存数据库 VOLTDB是由2014图灵奖得主、 冯诺依曼奖获得者 、 美 国国家工程院院士 、Postgres和Vertica等产品的联合创始人 Mike Stonebraker博士领导开发的下一代关系型、内存数据库 原生虚拟化和开源社区 管理系统,面向毫秒级实时事务处理、实时数据分析、边缘计算 和复杂流处理计算等应用。 完整事务和ACID VOLTDB大幅降低了服务器资源开销,首先实现在廉价 x86服务器集群或虚拟环境上实现每秒数百万次数据处理。单节 点每秒数据处理远远高于其它数据库管理系统。 VOLTDB提供开源版本和商业发行版本。 原生分布式数据库 VOLTDB于2017年官方正式进入中国市场,已经建立了本 土团队,包括销售、研发、售前售后和市场推广等职能。国内团 队目前分布在北京、上海、南京、成都。VOLTDB承诺可为国内 内存数据库 商业客户提供7X24的远程和现场售后支持服务。 4
5 .技术探索 Mike Stonebraker博士的研究团队通过对传统数据 库进行分析,发现数据只有12%左右的CPU时间在 做真 正有意义的数据操作,而其他绝大部分时间都被缓存,并 发控制等消耗了。 传统数据库有约88%的CPU时间都消耗在这些对于 实际操作无意义的步骤上,要提升数据库性能,只有从根 本上减少这些冗余的步骤,集中进行数据运算,才能完全 利用 CPU。 https://www.voltdb.com/wp-content/uploads/2018/10/VoltDB_LookingGlass_WP.pdf
6 . VOLT的定位和关注点 6
7 . ACID ACID,是指数据库管理系统(DBMS)在写入或更新资料的过 一个非标准答案的理解角度: 程中,为保证事务(transaction)是正确可靠的,所必须具备 重要的不是标准答案,而是明确业务场景、系统设计的构想,在客观 的四个特性 条件和构想之间做恰如其分的取舍和折衷 Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么 ACID是大家(业务方、系统提供方)对DBMS的共同的预期 全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复( • 从使用者角度,希望这个系统的机制、配套工具,能提供ACID支持手段并满足需要 Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 • 从DBMS设计者角度,是用系统来表达ACID、并对系统机制施加约束以满足业务需要 Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破 Atomicity(事务视角):不大有理解偏差,提交机制、失败回滚是对应机制 坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及 后续数据库可以自发性地完成预定的工作。 Isolation(并发事务管理的视角):重要性弱于Atomicity,更像是一种特征、 Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力, 灵活性。在不同的隔离级别下,设计者可以在性能vs.正确之间做不同的折衷 隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不 Durability(系统功能视角):是基本功能,业界理解偏差也不大。不过在系 同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复 统实现时,仍然在介质、频度方面有性能vs.正确的取舍 读(repeatable read)和串行化(Serializable)。 Consistency在ACID四个特性中鹤立鸡群 Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不 • 对C的需求贯穿AID,几乎是AID的出发点本身 会丢失。 • C不是DBMS系统方闭门造车就能提供的。约束什么、怎么表达约束、怎么使用? • 使用者能容忍的不一致 vs 系统能容忍的不一致 • 如何评价一个DBMS对C的支持的完善程度? VoltDB对ACID都有对应的机制保证 The value of ACID transactions is argued in the seminal Google F1 paper: The system must provide ACID transactions, and must always present applications with consistent and correct data. Designing applications to cope with concurrency anomalies in their data is very error- prone, time-consuming, and ultimately not worth the performance gains. 7
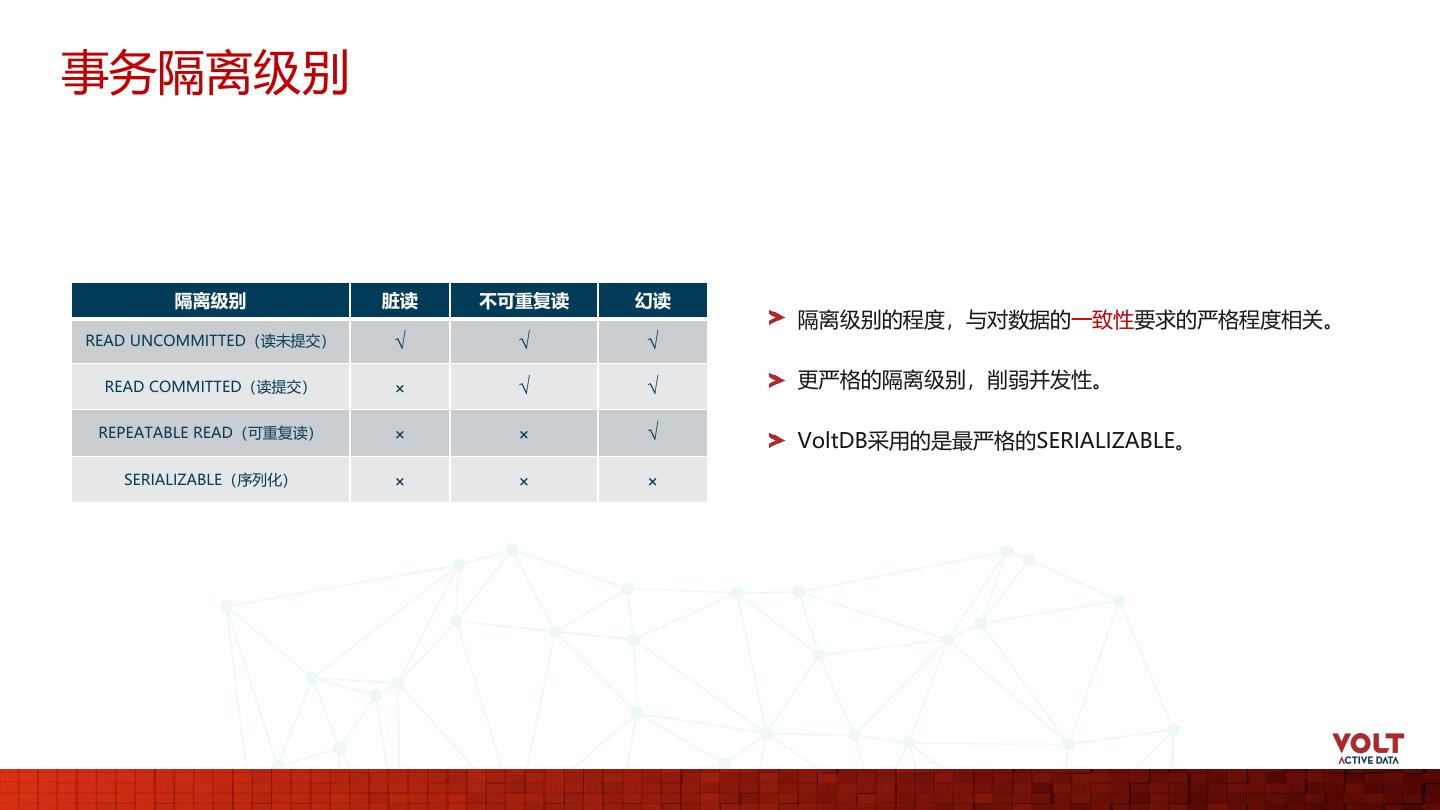
8 . 事务隔离级别 隔离级别 脏读 不可重复读 幻读 隔离级别的程度,与对数据的一致性要求的严格程度相关。 READ UNCOMMITTED(读未提交) √ √ √ READ COMMITTED(读提交) × √ √ 更严格的隔离级别,削弱并发性。 REPEATABLE READ(可重复读) × × √ VoltDB采用的是最严格的SERIALIZABLE。 SERIALIZABLE(序列化) × × × 8
9 . CAP CAP原则又称CAP定理,指的是在一个分布式系统中,C、A、P这三 一个理解角度: 个基本需求,最多只能同时满足其中的2个 CAP不是你能做什么,而是做不到什么?如何选择取舍? 常见理解: • 一致性:同一份数据的多个副本在整个分布式系统内保持一致 • Consistency(一致性): • 可用性:分布式系统所有活跃的子节点都能处理请求并正确响应 数据在多个副本之间能够保持一致的特性 • 分区容错性:分布式系统的副本互联、外联建立在不能假设为可靠 • Availability(可用性): 的网络上。分区容错性可以包括: 系统提供的服务一直处于可用的状态,每次请求都能获得正确的响应 部分副本崩溃的情况下的应对策略(如:活跃的副本提供服务) 多副本活跃但同步失效情况下的应对策略(如:VoltDB提供brain-split侦测) • Partition tolerance(分区容错性): 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足 • 当探讨异常情况的时候,想同时要求C+A是不可能的,因为活跃的 一致性和可用性的服务 副本(局部)的可用就意味着整体的不一致 CAP is a tool to explain trade-offs in distributed systems. It was presented as a conjecture by Eric Brewer at the 2000 Symposium on Principles of Distributed Computing and formalized and proven by Gilbert and Lynch in 2002. 9
10 . Lock&Latch 传统RDBMS大约有30%的CPU开销在Lock&Latch上 Lock Latch 持续时间 整个事务过程 临界资源 实现 保存在lock表中,通过哈希表定位 位于它们保护的资源附近的内存中,并通过直接寻址进行访问 跟踪 Lock是有跟踪的,有lock table,随事务创建、清除 Latch闩是无跟踪的,如果出错,可能无法释放 死锁 Lock允许死锁,辅以检测机制并通过重启事务来解决死锁 内部实现差异 机制 内部实现 一般用原子硬件指令实现,极端情况下用OS机制 效率 几百个CPU周期 几十个CPU周期 10
11 . 并发Concurrent vs. 并行Parallel VoltDB用分区并行策略与事务队列串行化策略相辅相成,实现了惊人的 TPS吞吐能力 • 不同的单分区事务,在不同的CPU上并行完成,同时满足了事务并 行的需要和串行的事务隔离级别 • 通过单分区事务的机制,几乎避免了Lock&Latch的开销 11
12 . 设计思路的落地 12
13 . VOLTDB技术架构 分布式集群 VoltDB的技术特点 VoltDB 节点1 VoltDB节点2 VoltDB节点N ● 全内存计算 计算引擎 计算引擎 计算引擎 ● 无锁化设计 表/索引数据 表/索引数据 表/索引数据 ● 按CPU内核分区 数据库模式 数据库模式 数据库模式 ● 多分区并行计算 ● 数据库内事务控制 分区1 分区2 分区5 分区6 分区7 分区8 ● 无共享设计 分区3 分区4 分区 分区 分区9 分区 7’ 1’ 4’ 分区 分区 分区 分区 分区 分区 9’ 8’ 2’ 3’ 5’ 6’ 13
14 . 逻辑架构 VOLT是完全分布式内存数据库,每个 节点-a 节点-c 节点都是逻辑对等的,没有主节点的概念, 分区-1 也就避免了主节点瓶颈和单点故障风险。 分区-2 物化视图 VOLT节点内部数据存储和处理分成逻 辑分区(对应物理分区),逻辑分区间采用 分区-n 优化MPP方式,独立运行处理计算。 事务处理 每个节点都可以接受客户端的请求, 业务逻辑 并负责解析执行计划并分发对应的任务给本 数据表 节点或者其他节点的执行层。 节点-b 数据落盘 数据落盘等持久化任务在每个节点并 行执行,集群间同步在对应分区间并行完成 ,实现性能的最大化。 import streams database calls export/migrate streams ML models Kafka, JDBC, Language SDKs, Hadoop, RabbitMQ, Elastic, PMML, … 数据管道 14
15 . 性能测试比较 VoltDB经过和传统数据库进行的性能对比,实测结果如下表,VoltDB单节点即带来比传统数据库数十倍性能的优势。 测试环境:Dell R610, 2x 2.66Ghz Quad-Core Xeon 5550 with 12x 4GB (48GB) DDR3-1333 Registered ECC DIMMs, 3x 72GB 15K RPM 2.5in Enterprise SAS 6GBPS Drives. 15
16 . 线性扩容 VOLT线性扩容测试 VOLT性能会随着集群节点数量的增加而线性 • 16核CPU, 64G内存 增长,随着应用端性能需求的增长,VOLT集群可以简 • 320万TPS/集群/27节点 单地增加节点数量来解决。 • 延迟<5ms •性能线性增长 •横向+纵向扩展 •一键无痛扩容 •数据自动均衡 •对应用无影响 16
17 . VOLTDB关键特性 VOLT、NoSQL和传统关系型数据库的对比如下所示: 17
18 .实现机制
19 . 原生的基于分区的分布式设计 分布式集群 Site VoltDB 节点1 VoltDB节点N 分布式集群的基本运行单位,逻辑上与 Partition一一对应。 Site1 分区1 分区2 分区7 分区8 SPI1 ZK1 SPI Single Partition Initiator。负责本Partition 的事务执行。 Site3 分区3 分区4 分区9 分区 SPI3 ZK3 4’ ZK Zookeeper node。每个SPI都对应一个ZK Site9’ 分区 分区 分区 分区 node。运用ZooKeeper的分布式协调功能,实现 9’ SPI9’ ZK9’ 8’ 5’ 6’ Partition的多个副本的Leader选举、监控等。 19
20 . Frontend主要分布式组件 20
21 . SQL执行过程对比:1-MYSQL 21
22 . SQL执行过程对比: 2-ADHOC OF VOLT 22
23 . BACKEND组件 23
24 . 索引与存储结构 B+树 HashMap 红黑树 • 目前Volt的表存储结构主要是HashMap+红黑树 思考: • 减少IO? 减少内存碎片? 24
25 . BACKEND组件-STORAGE 25
26 . 关键特性一览 易用性 • 存储模式:关系型行式数据存储 • 无专门编码语言: 标准SQL 实现复杂计算,无二次学习成本 • 存储过程/UDF: JAVA + SQL + PMML = 实时规则执行引擎 • 原生TTL支持:数据时效性周期自动删除和数据转储 • 集成机器学习:JAVA-ML / PMML 热加载运算 • 支持任务式调度:可以在 VoltDB定义各种定时执行的批任务 • 支持流式计算:支持按Topic订阅和发布,兼容Kafka API,并在流中完成复杂计算 安全性 • 无数据丢失: 强ACID、内生数据持久化、立即一致性 • 无安全隐患:授权用户、支持SSL加密通讯 运维 • 图形化监控: 自带图形化管理工具,可与普罗米修斯等集成,开放监控接口 • 工具丰富:细粒度显示集群各种指标,部署方便操作简便 云化部署 • 云原生数据库:支持容器化、虚拟化部署,支持Kubernetes Operator,自动编排、自动扩缩容 高可用 • 数据冗余:集群内可配置多个副本 • 多集群复制: 原生支持多数据中心同步(主-主、主-备) • 在线扩展: 无共享架构、性能线性增长 26
27 .谢谢!
3秒后跳转登录页面
去登陆

