













































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
基于自监督的人体姿态估计、模拟与生成的协同进化研究
现有的自监督三维人体姿势估计方法在很大程度上依赖于consistency loss等弱监督来指导学习,这不可避免地导致在真实场景中,对没有见过的pose的结果较差。在本文中,作者提出了一种新的自监督方法,该方法允许通过self-enhancing dual-loop学习框架显式生成2D-3D pose pair来增强监督。这可以通过引入基于强化学习的imitator来实现,该imitator与pose estimator和pose hallucinator一起学习,这三个组件在训练过程中形成两个循环,相互补充和加强。具体来说,姿态估计器(pose estimator)将输入的2D pose序列转换为低质量的3D pose输出,然后由实施物理约束的imitator进行优化增强。经过优化的3D pose随后被输入到pose hallucinator,以产生更加多样化的数据,而这些数据又被imitator强化,并进一步用于训练姿态估计器。在实践中,这种协同进化方案能够在不依赖任何给定3D数据的情况下,根据自生成的运动数据训练姿势估计器。在各种基准的广泛实验表明,作者的方法产生的结果显著优于现有自监督技术,并且在某些情况下,甚至与完全监督方法的结果一致。
龚克洪,新加坡国立大学电子与计算机工程学院在读博士生,指导老师是王鑫超老师。主要研究兴趣是人体姿态估计与动作生成,以及基于强化学习的动作模拟、基于数据增强的模型泛化性研究。 目前以一作身份发表论文两篇, 分别是CVPR2021的PoseAug (Oral, Best Paper Candidate)和CVPR2022的PoseTriplet (Oral)。
展开查看详情
1 .PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision CVPR 2022 (Oral)
2 .Content • Introduction • Method • Result • Future development • Conclusion
3 .Introduction • Background • Application • Conventional method • Challenge • Existing SSL method • Methodology • Limitation • Our solution • Inspiration • Related work
4 .Background • 3D human pose estimation: • videos ==> 3D pose sequences Pavllo et al, CVPR 2019 • Applications: • action recognition • virtual try-on • mixed reality Cashman et al, CVPR tutorial 2021
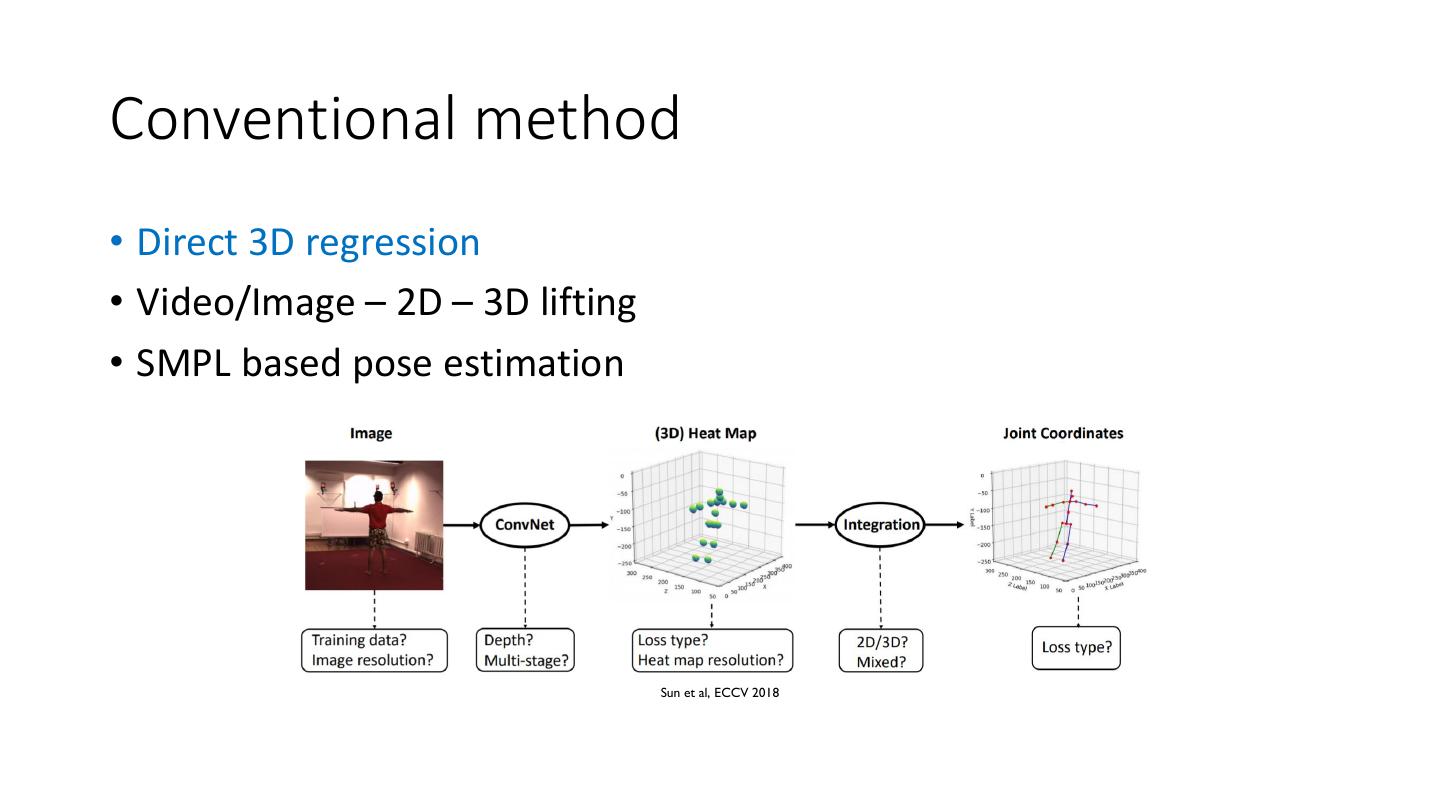
5 .Conventional method • Direct 3D regression • Video/Image – 2D – 3D lifting • SMPL based pose estimation Sun et al, ECCV 2018
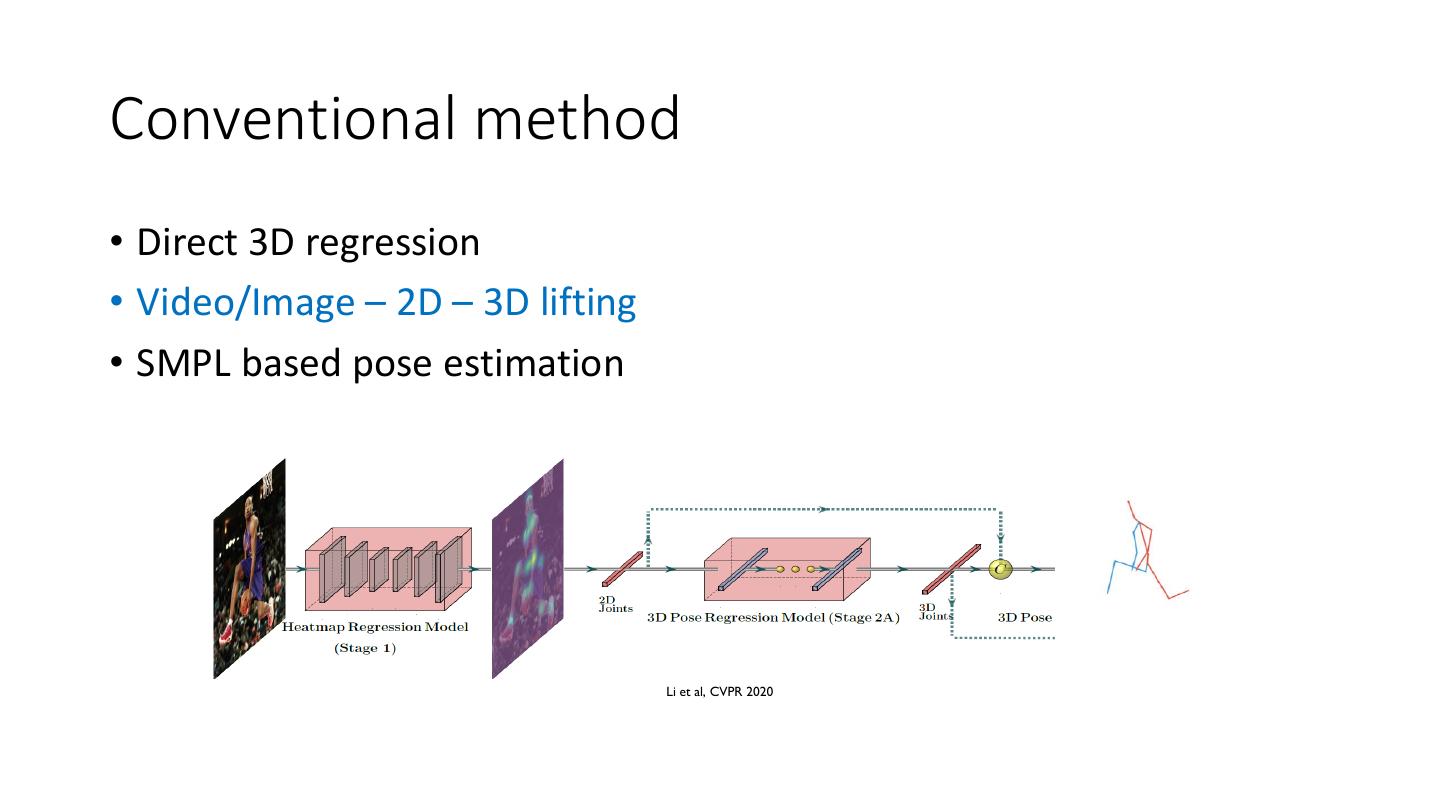
6 .Conventional method • Direct 3D regression • Video/Image – 2D – 3D lifting • SMPL based pose estimation Li et al, CVPR 2020
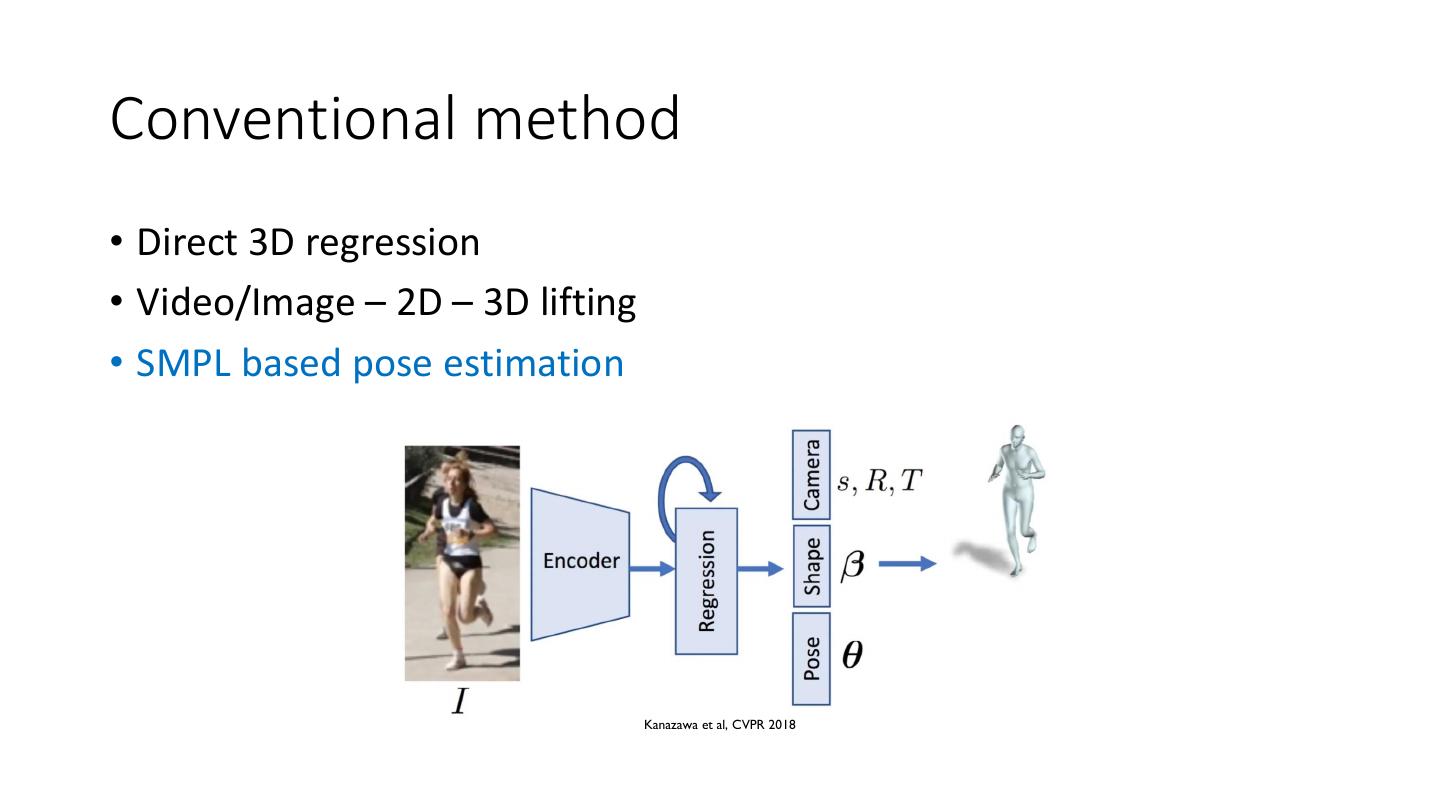
7 .Conventional method • Direct 3D regression • Video/Image – 2D – 3D lifting • SMPL based pose estimation Kanazawa et al, CVPR 2018
8 .Challenge • The supervised training requires large amount of data • Capturing 3D pose data is cost-intensive and time-consuming • The Mocap system is hard to deployed to in-the-wild scenarios Ionescu et al, TPAMI 2014 Motion Capture System
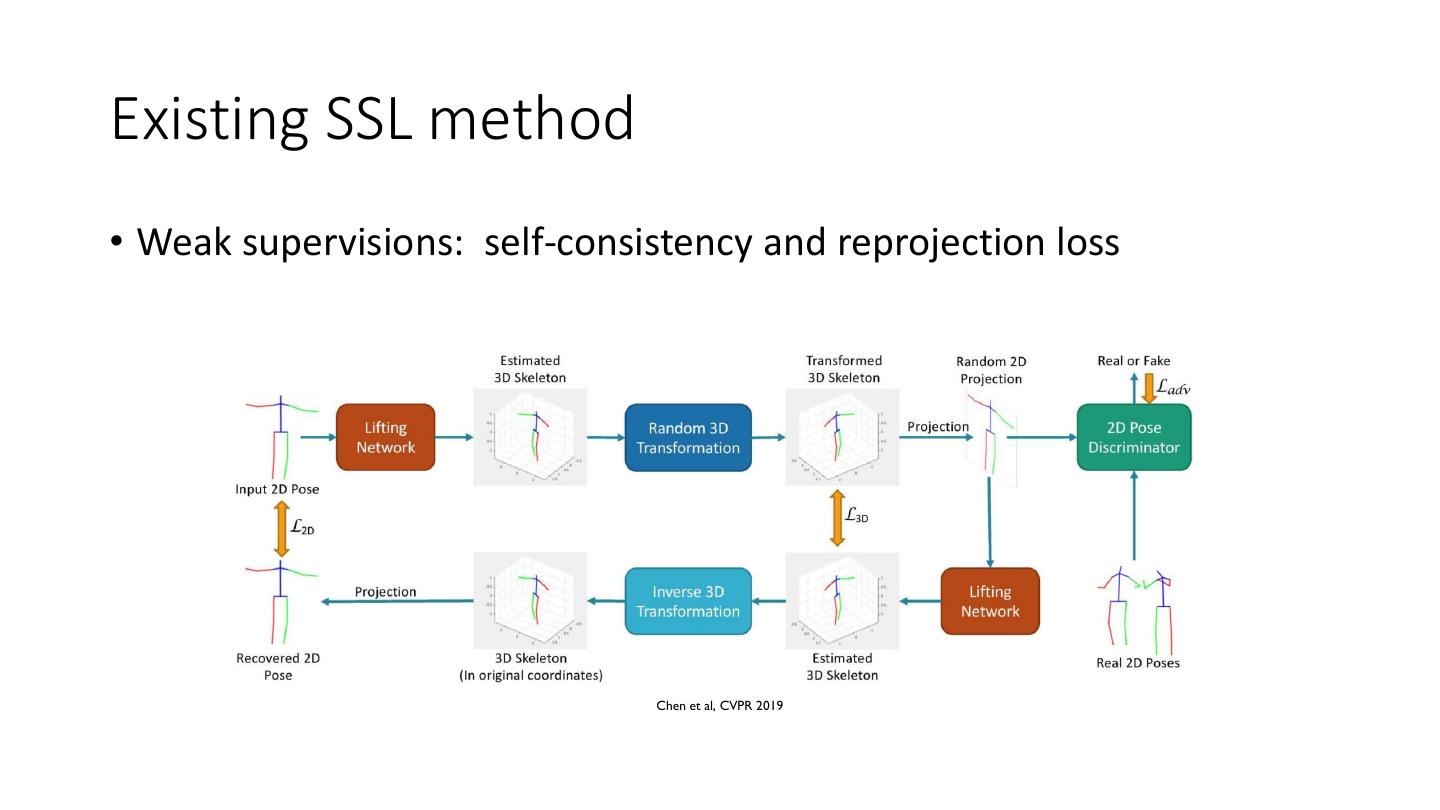
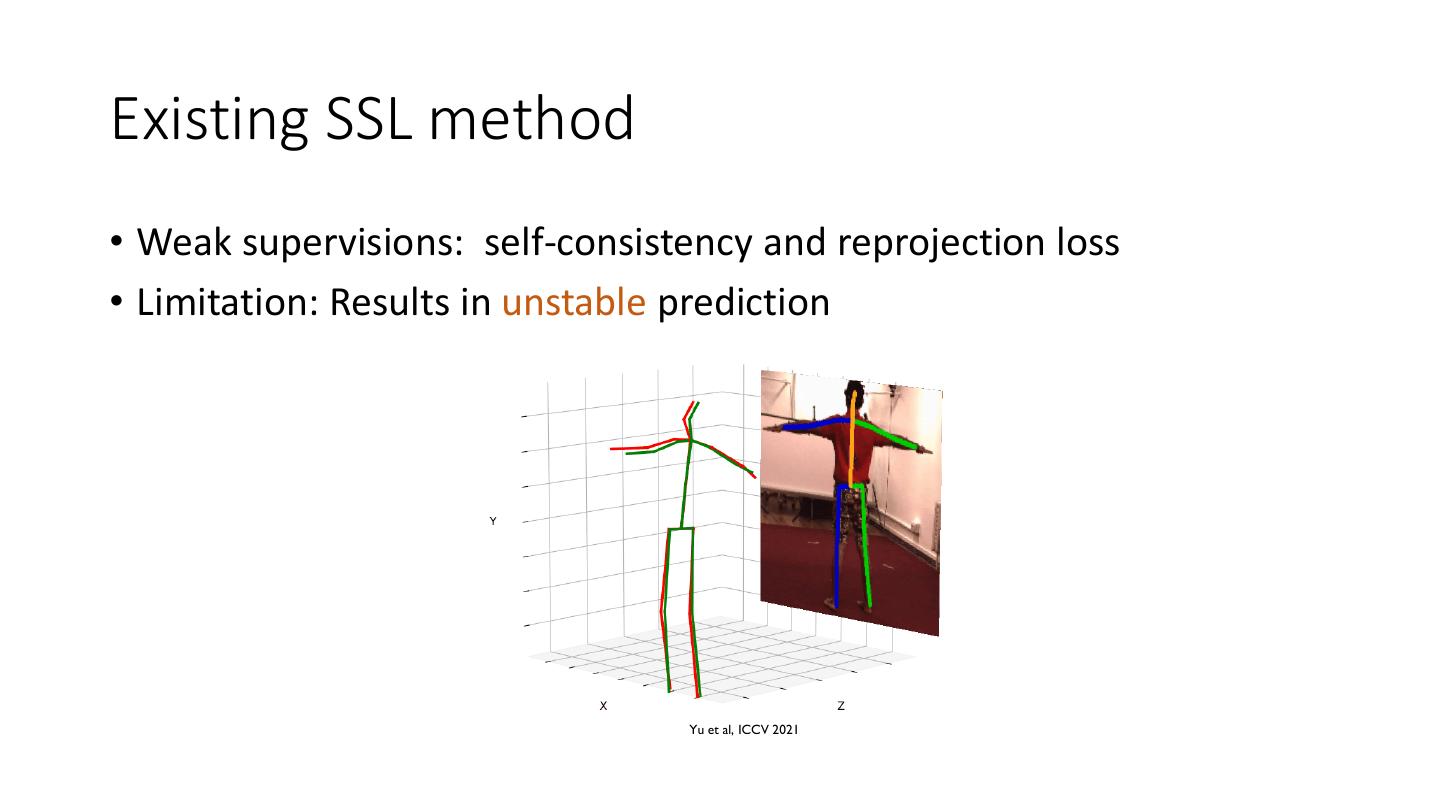
9 .Existing SSL method • Weak supervisions: self-consistency and reprojection loss Chen et al, CVPR 2019
10 .Existing SSL method • Weak supervisions: self-consistency and reprojection loss Yu et al, ICCV 2021
11 .Existing SSL method • Weak supervisions: self-consistency and reprojection loss • Limitation: Results in unstable prediction Yu et al, ICCV 2021
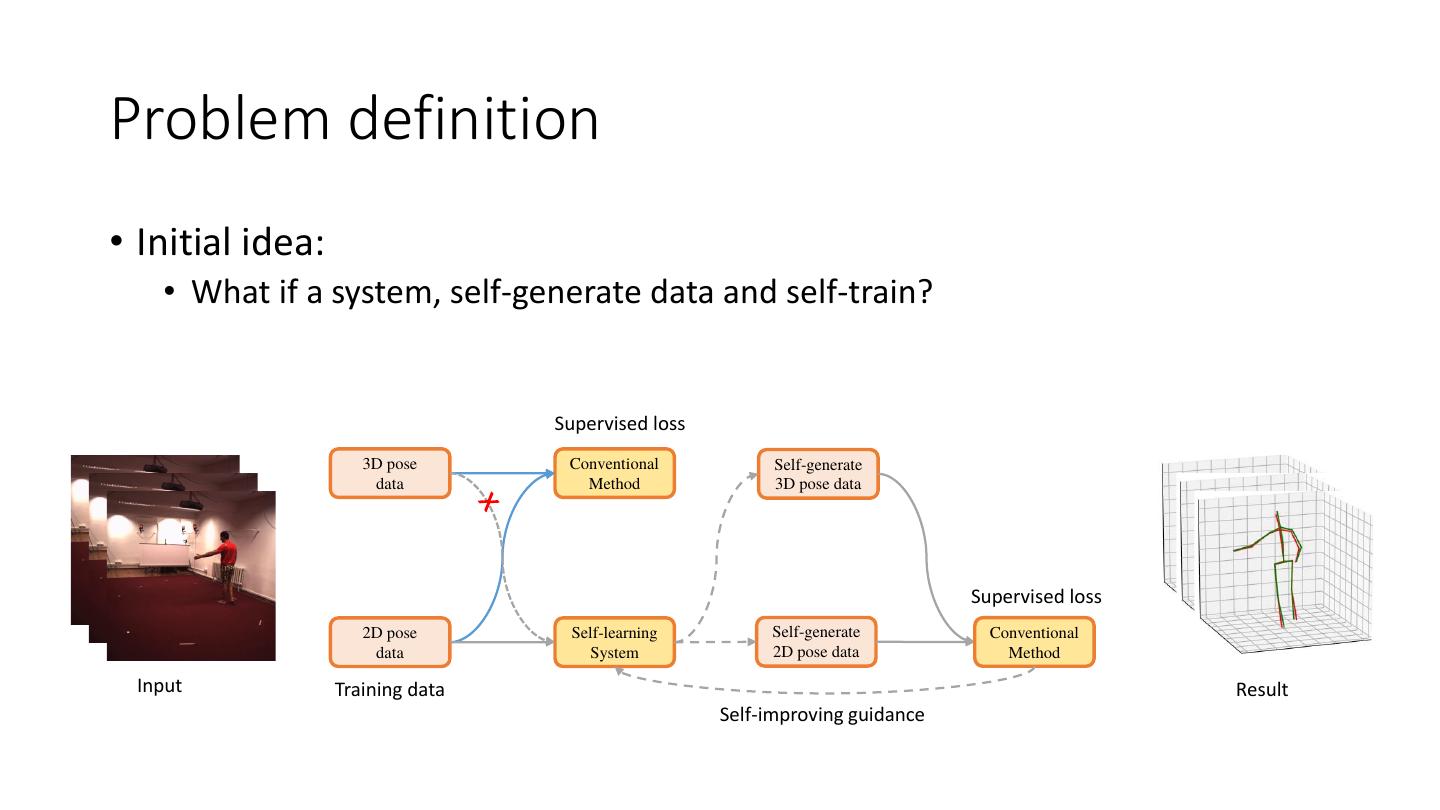
12 .Problem definition • Initial idea: • What if a system, self-generate data and self-train? Supervised loss 3D pose Conventional Self-generate data Method 3D pose data Supervised loss 2D pose Self-learning Self-generate Conventional data System 2D pose data Method Input Training data Result Self-improving guidance
13 .Inspiration • What if a virtual world? • The Matrix • What data required? • Diversity • Plausibility • Can I build the matrix? • No! • Can I build a simulation world with only joint? • Yes! • How to ensure the diversity and plausibility? The Matrix, movie 1999 • Physical simulator • Motion generator
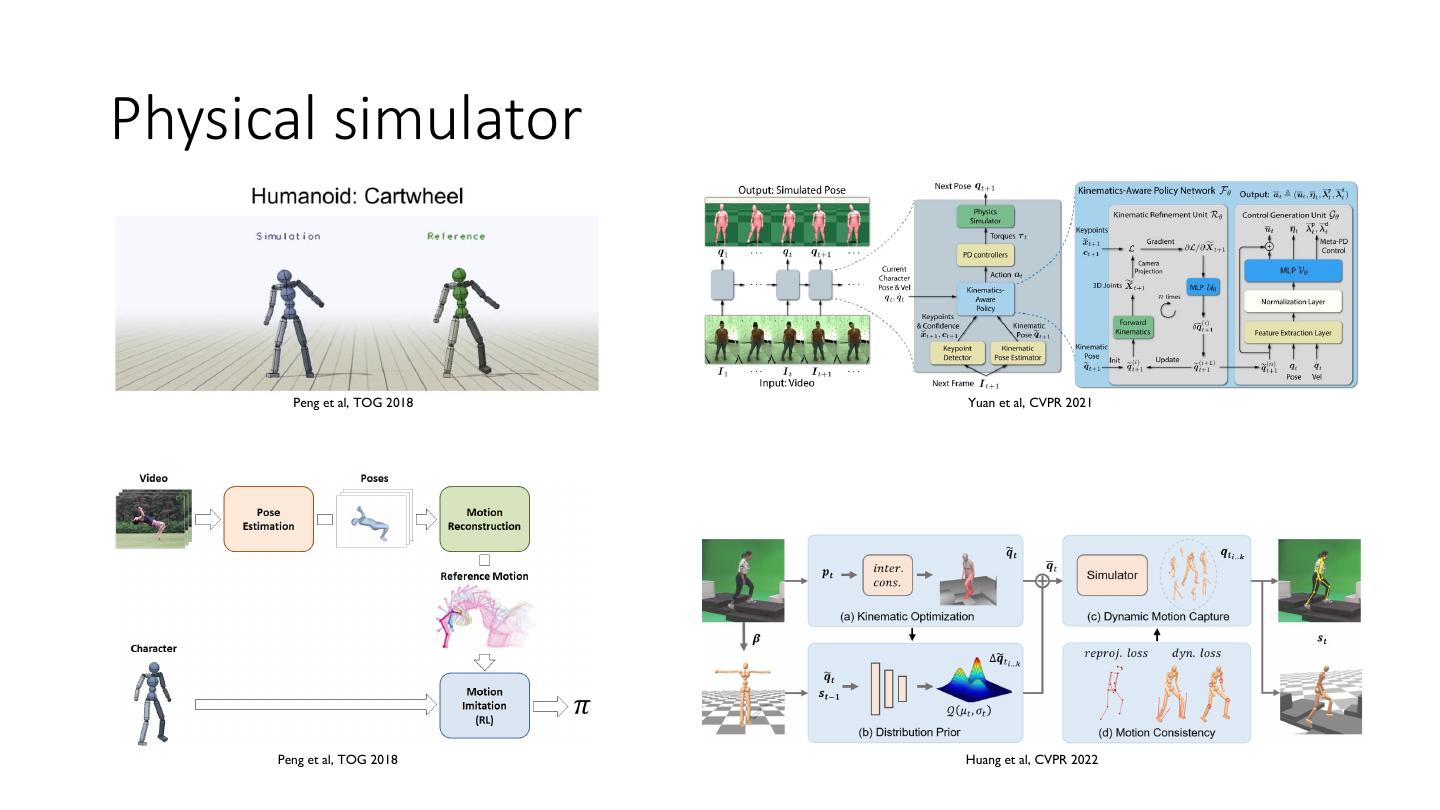
14 .Physical simulator Peng et al, TOG 2018 Yuan et al, CVPR 2021 Peng et al, TOG 2018 Huang et al, CVPR 2022
15 .Motion generator • Action conditioned • Prediction • Infilling Harvey et al, TOG 2020 Petrovich et al, ICCV 2021 Zhang et al, CVPR 2021
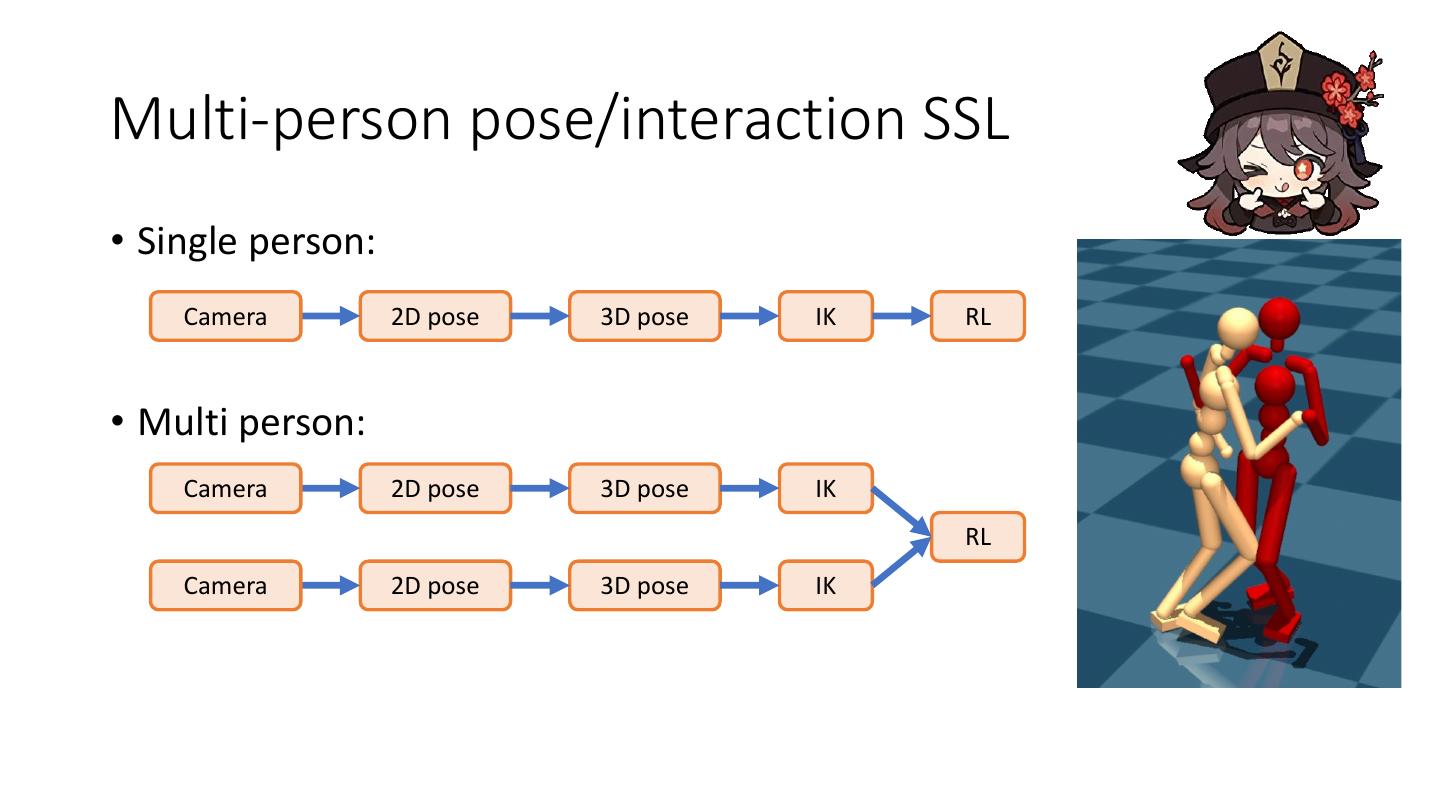
16 .Method • Overview • Framework • Estimator • 2D detector • 3D lifting • 2D-3D augmentation • Imitator • Hallucinator • Our approach • Motivation • Detail • Training implementation • Loop starting
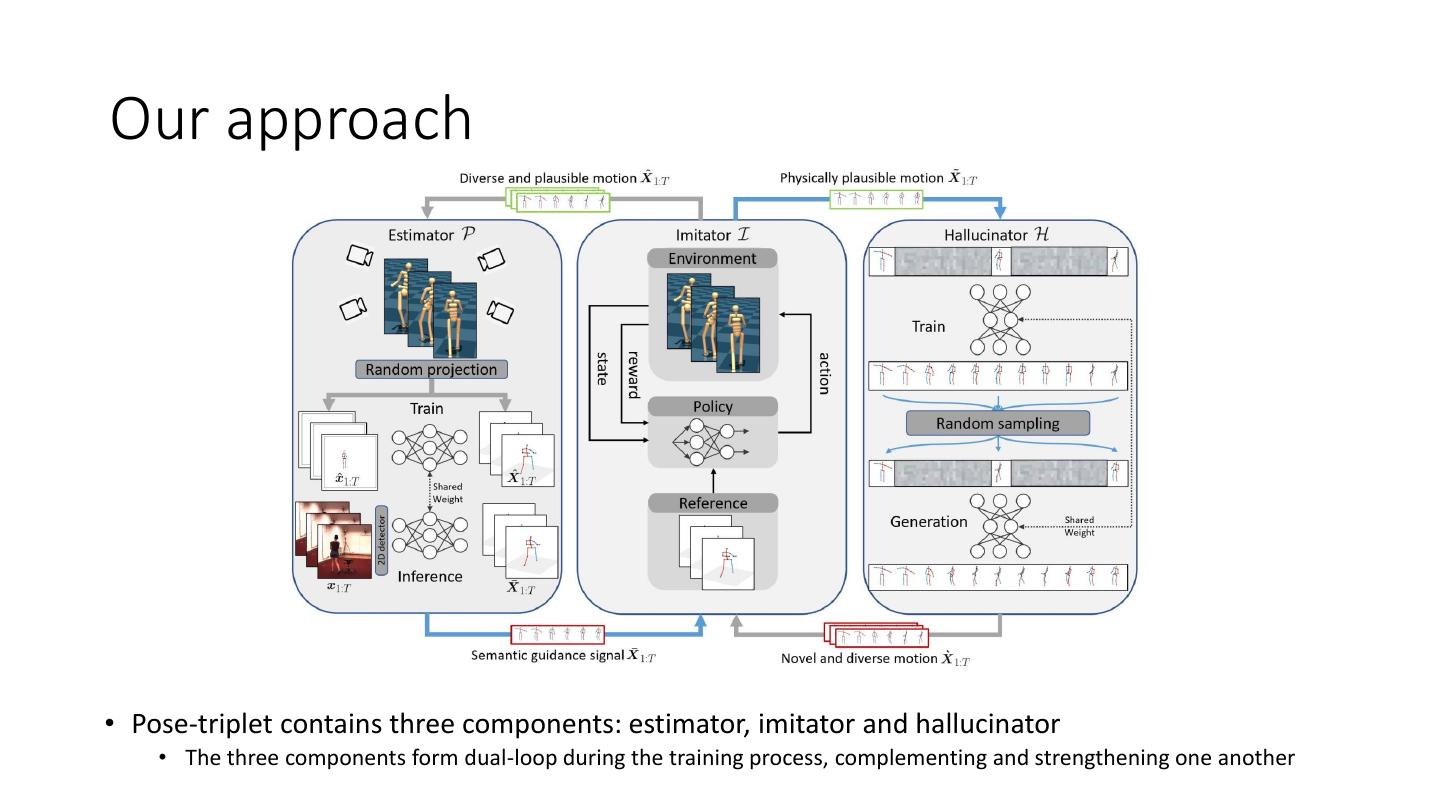
17 .Framework • Pose-triplet contains three components: estimator, imitator and hallucinator • The three components form dual-loop during the training process, complementing and strengthening one another
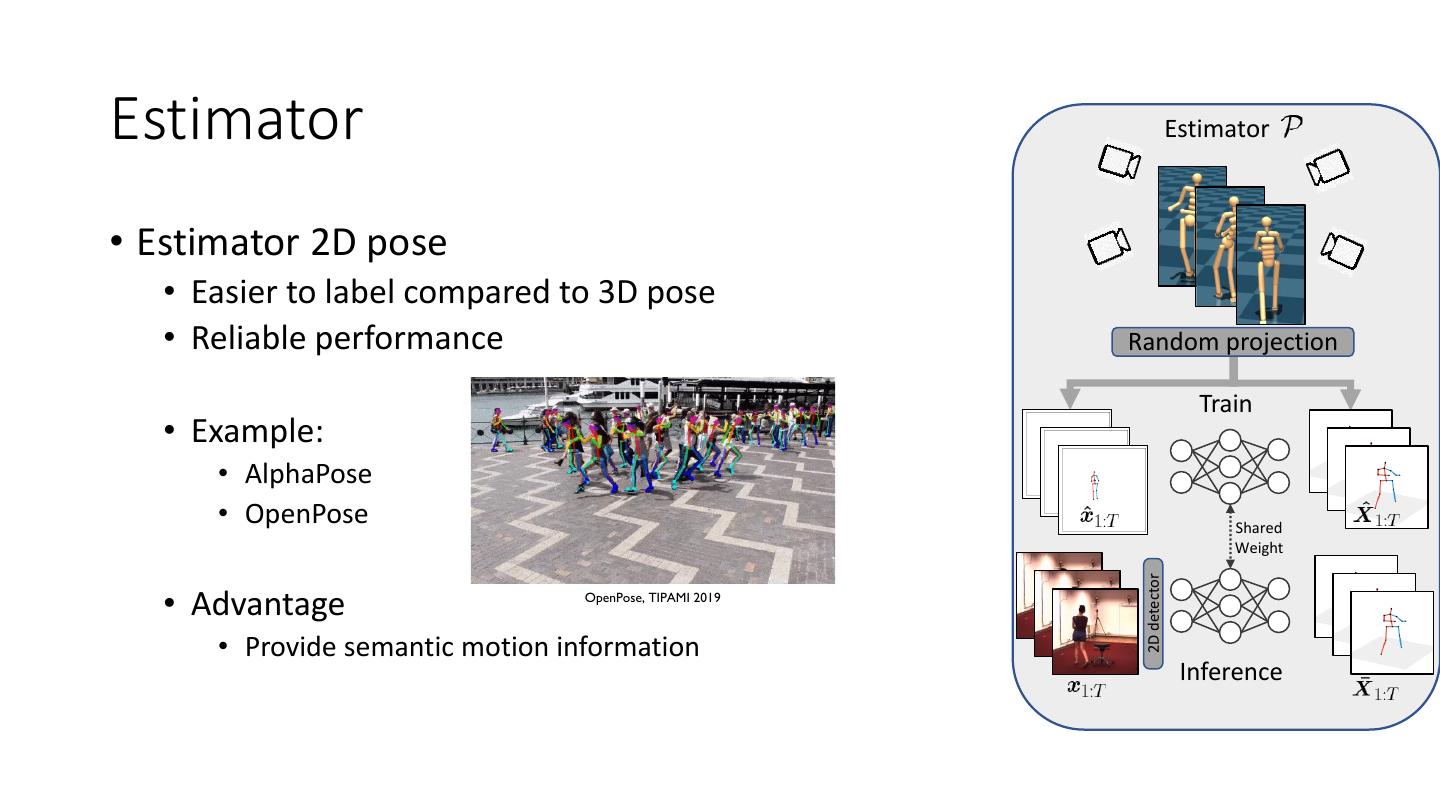
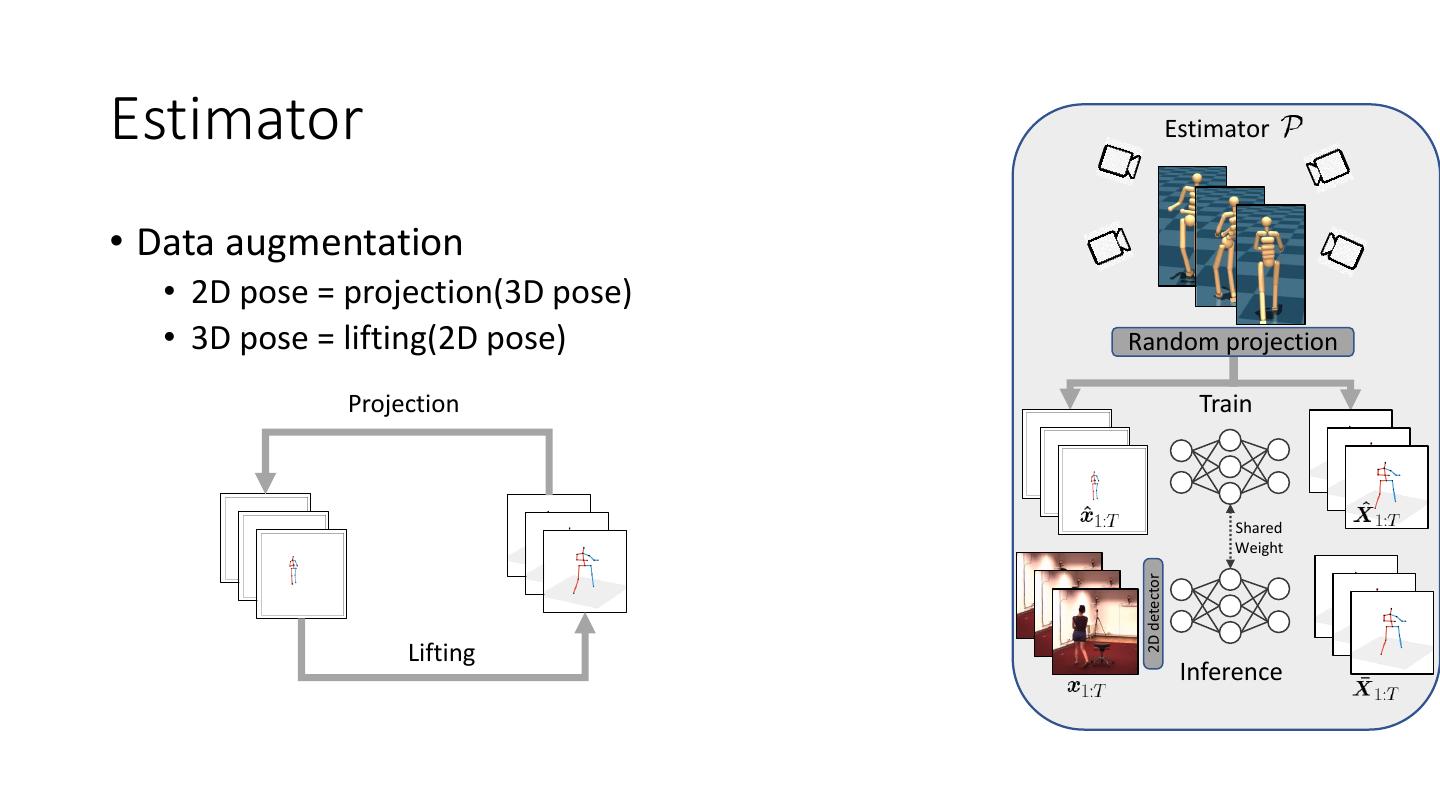
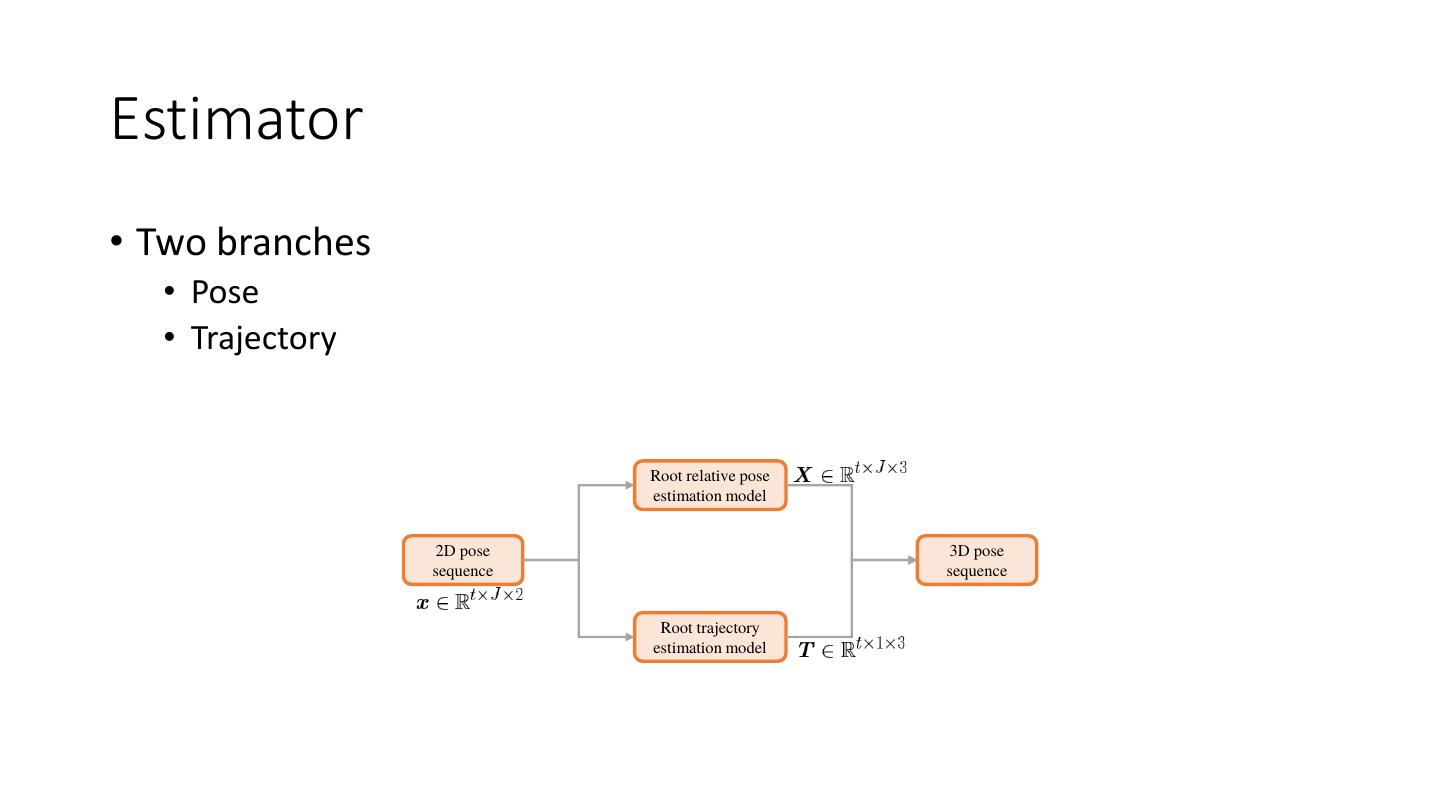
18 .Estimator Estimator • Estimator 2D pose • Easier to label compared to 3D pose • Reliable performance Random projection Train • Example: • AlphaPose • OpenPose Shared Weight 2D detector • Advantage OpenPose, TIPAMI 2019 • Provide semantic motion information Inference
19 .Estimator Estimator • Estimator 3D pose • VideoPose • Input: t x 16 x 2 Random projection • Output: t x 16 x 3 Pavllo et al, CVPR 2019 Train • Advantage • Capable to unseen motion with limited performance Shared • Limitation Weight 2D detector • Foot skating • Ground penetration • Jittering Inference
20 .Estimator Estimator • Data augmentation • 2D pose = projection(3D pose) • 3D pose = lifting(2D pose) Random projection Projection Train Shared Weight 2D detector Lifting Inference
21 .Imitator Imitator Environment • Imitator • Input: Noisy motion reference • Output: Physical plausible motion reward state action • Advantage Policy • Provide physical correction • <video SFV> Peng et al, TOG 2018 https://youtu.be/4Qg5I5vhX7Q?t= 173 Reference • Limitation • Require semantic plausible signal • With only direction/velocity signal • Results in semantic implausible motion: Peng et al, TOG 2018
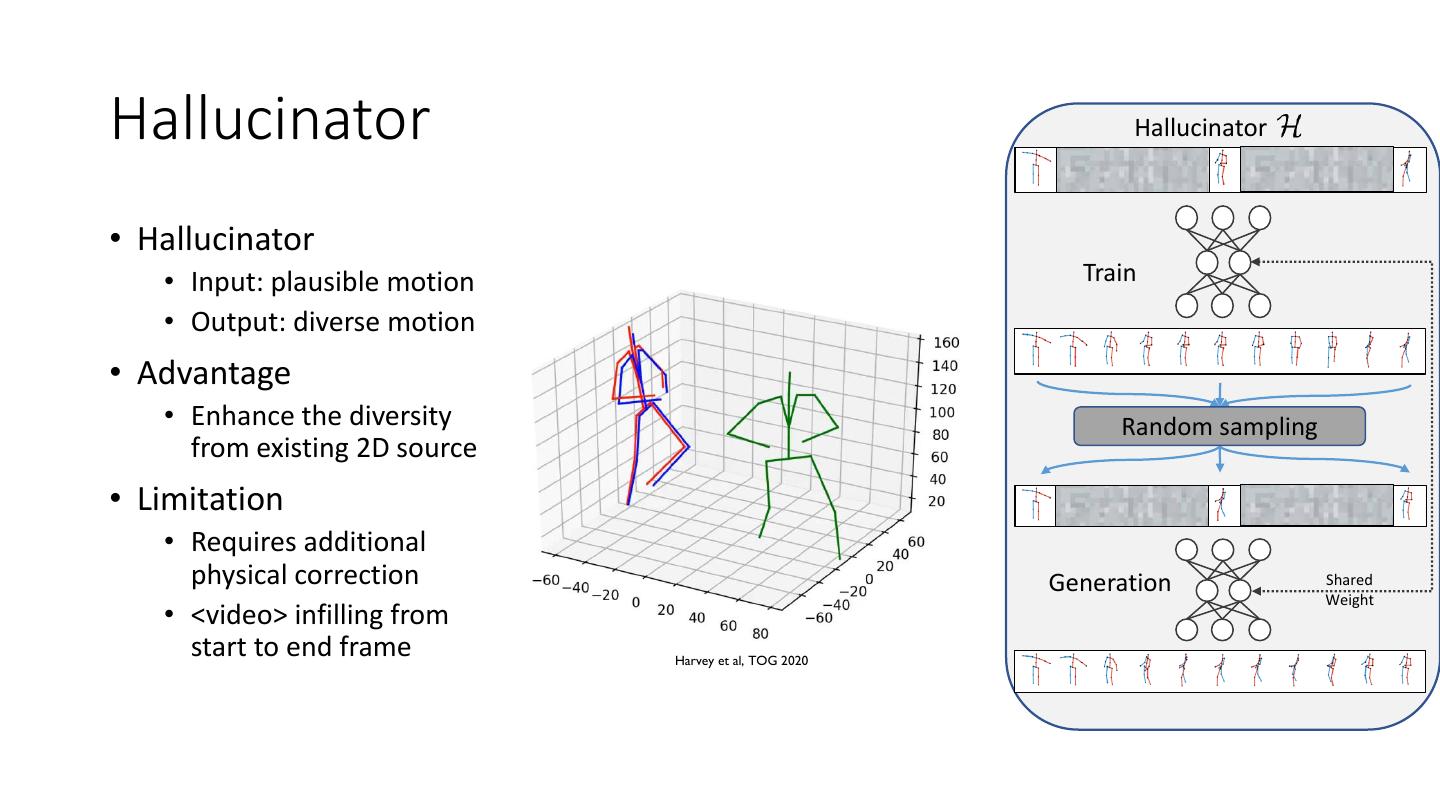
22 .Hallucinator Hallucinator • Hallucinator • Input: plausible motion Train • Output: diverse motion • Advantage • Enhance the diversity Random sampling from existing 2D source • Limitation • Requires additional physical correction Generation Shared Weight • <video> infilling from start to end frame Harvey et al, TOG 2020
23 .Our approach • Motivation: • Estimator • predict motion with reasonable semantics but implausible dynamics • Imitator • correct the implausible dynamics but require semantics motion guidance • Hallucinator • enhances data diversity (better generalization) but require motion database. • estimator, imitator and hallucinator are complementary to each other.
24 .Our approach • Motivation: • Estimator • predict motion with reasonable semantics but implausible dynamics • Imitator • correct the implausible dynamics but require semantics motion guidance • Hallucinator • enhances data diversity (better generalization) but require motion database. • estimator, imitator and hallucinator are complementary to each other.
25 .Our approach • Pose-triplet contains three components: estimator, imitator and hallucinator • The three components form dual-loop during the training process, complementing and strengthening one another
26 .Training implementation Loop starting • Reason: • Estimator, Imitator, Hallucinator all need 3D data • Our problem setting is: 2D data only • To fake some 3D data: • Generate random trajectory Roboschool, OpenAI • Guide the character to following trajectory • Get the semantic implausible, but physical plausible motion data • Start the loop:
27 .Training implementation Pseudocode 1. Prepare 3D motion from loop starting or imitation: 2. Estimator: a. Train estimator by 3D motion projection b. Inference the available H36M 2D pose to 3D motion reference 3. Imitator a. Train RL policy by the 3D motion reference b. Inference the whole 3D motion reference to physical plausible motion 4. Hallucinator a. Train masked generator with the plausible motion b. Inference diverse motion through random sampling 5. Imitator a. Do motion correction as Step 3, i.e. train -> inference 6. Back to step 1 …
28 .Result • In training set (seen case): • Improvement through co-evolving • Imitation result • Hallucination result • In test set (unseen case): • Estimation result • Estimation + imitation result • Result compared with SOTA • Quantitative result • Qualitative result
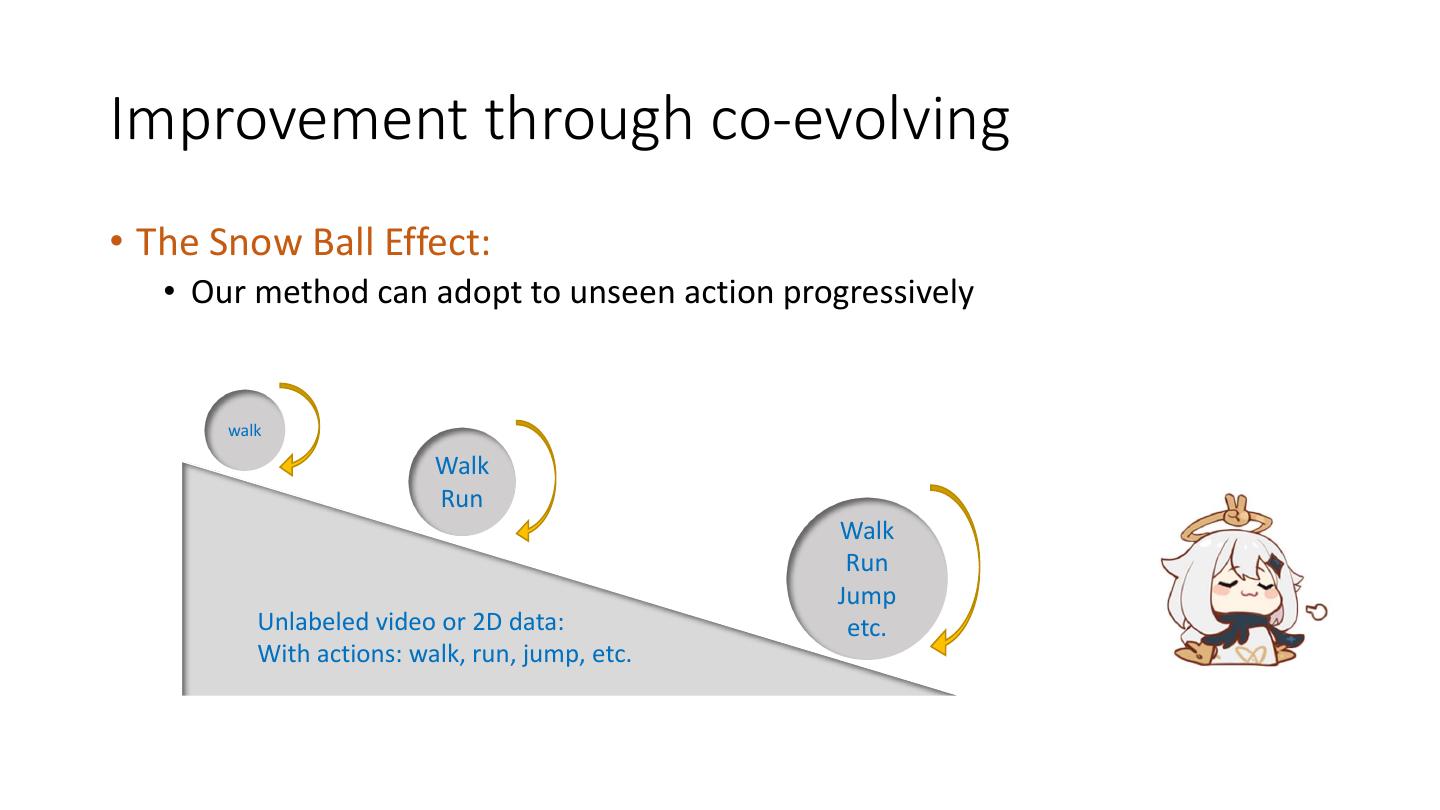
29 .Improvement through co-evolving • The imitated motion becomes more accurate and realistic from round 1 to 3. • Q: Why the agent can imitate the action never seen before? • A: We enhanced the generalization capacity of estimator such that it can predict on unseen action (with artifacts), which then corrected by imitator.
3秒后跳转登录页面
去登陆

