
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/CloudCommunity/Bilibili_HA_best_practice?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
B站高可用架构的实践
点赞
3
收藏
1
下载 1
背景介绍
流量洪峰下要做好高服务质量的架构是一件具备挑战的事情,从Google SRE的系统方法论以及实际业务的应对过程中出发,分享一些体系化的可用性设计。对我们了解系统的全貌上下游的联防有更进一步的了解。
课程大纲
1、负载均衡
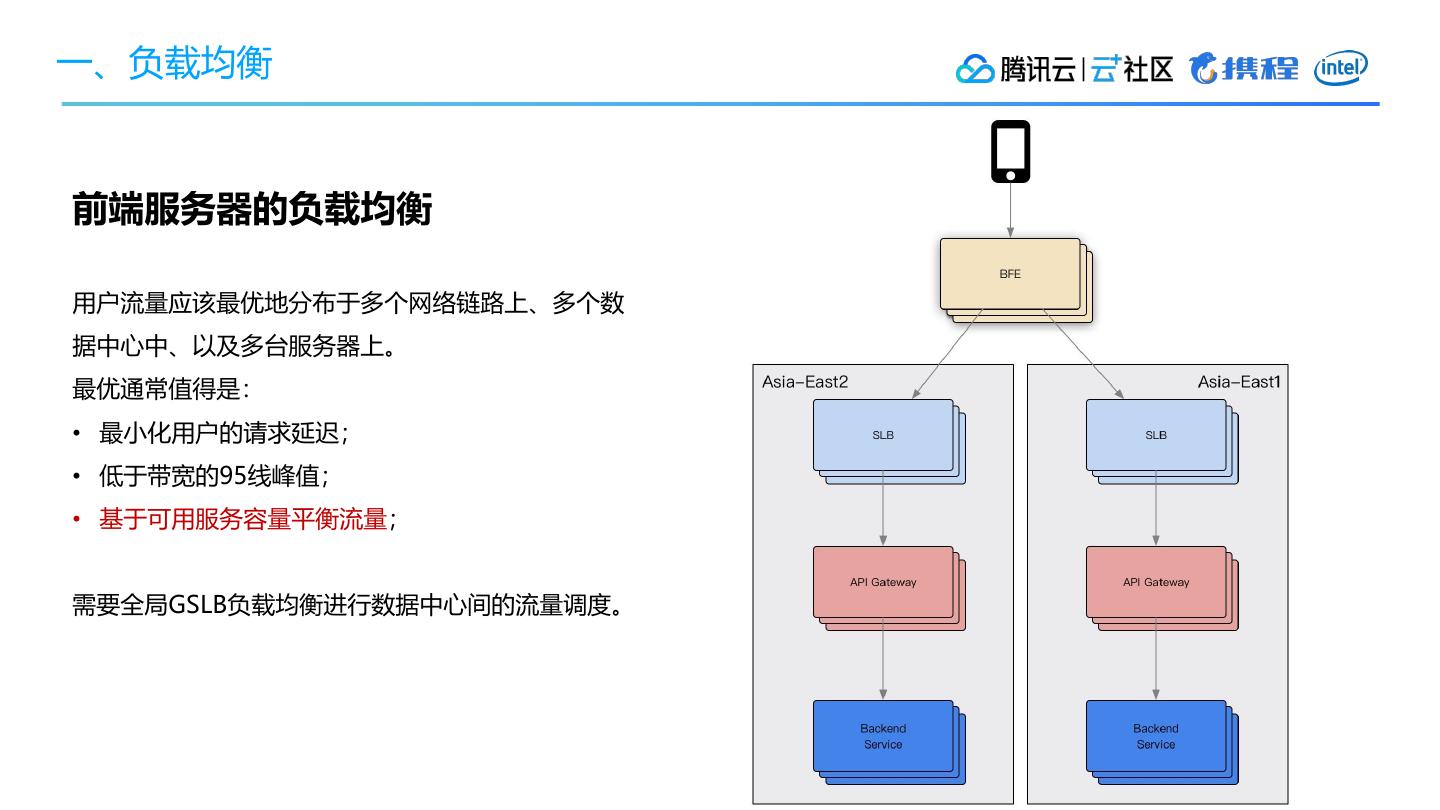
• 前端服务器的负载均衡
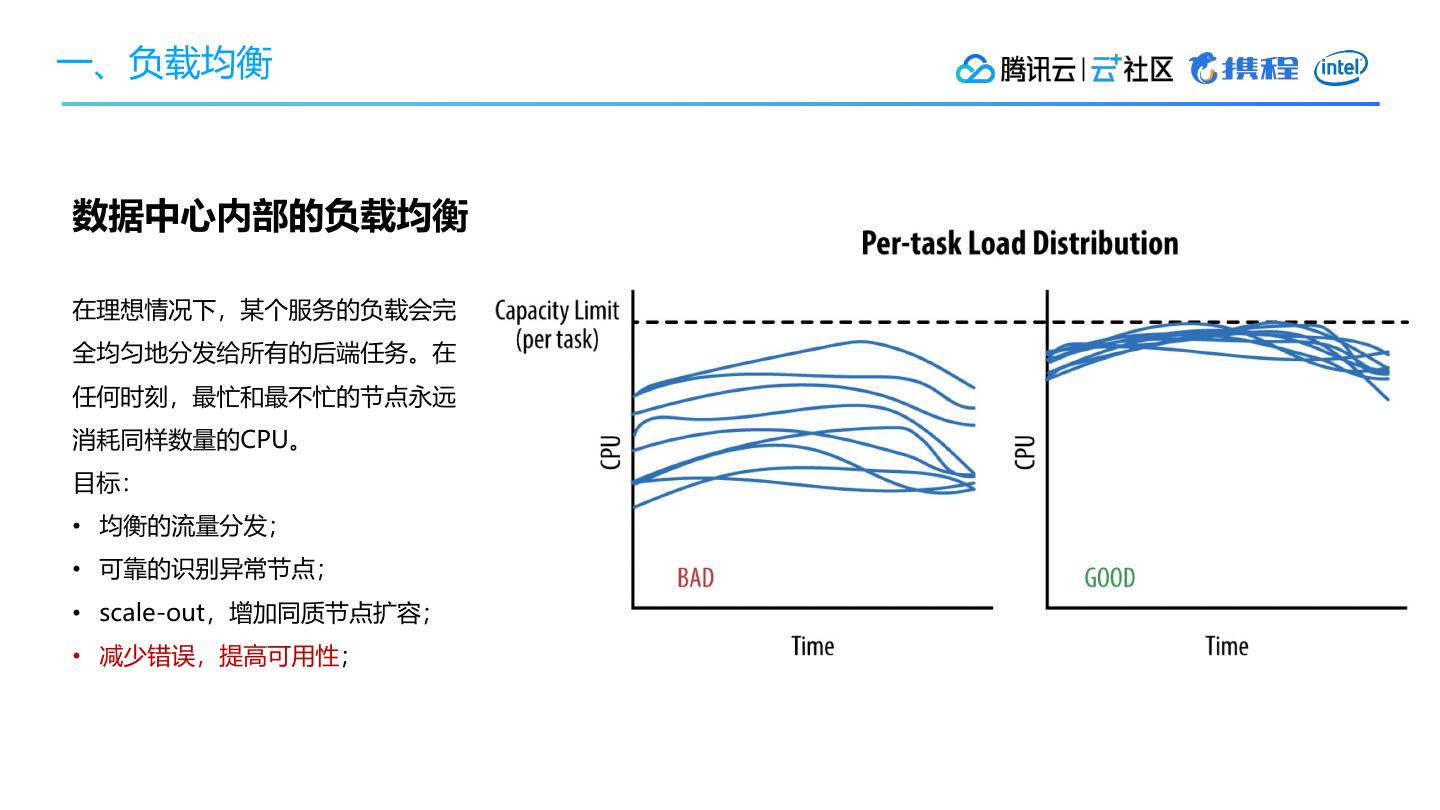
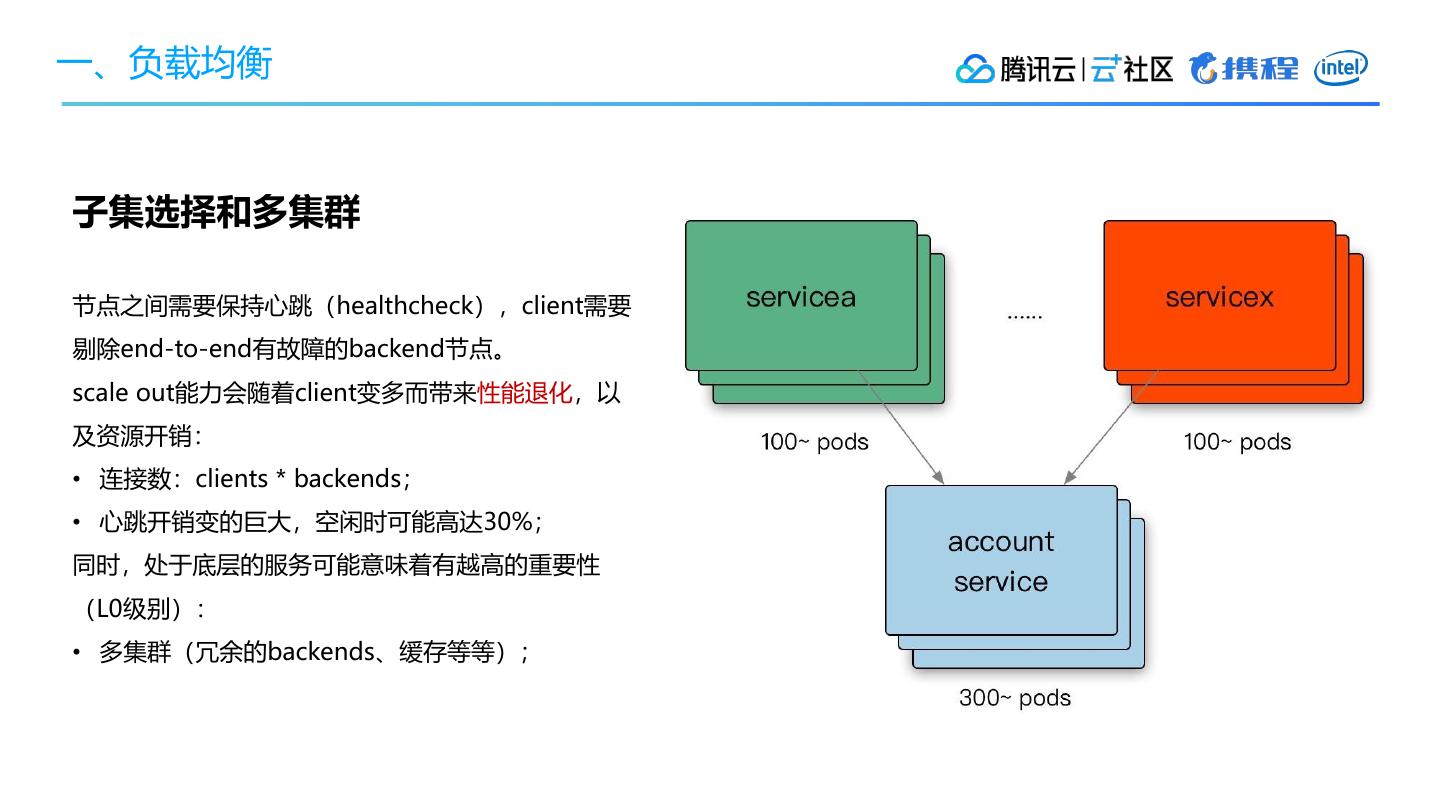
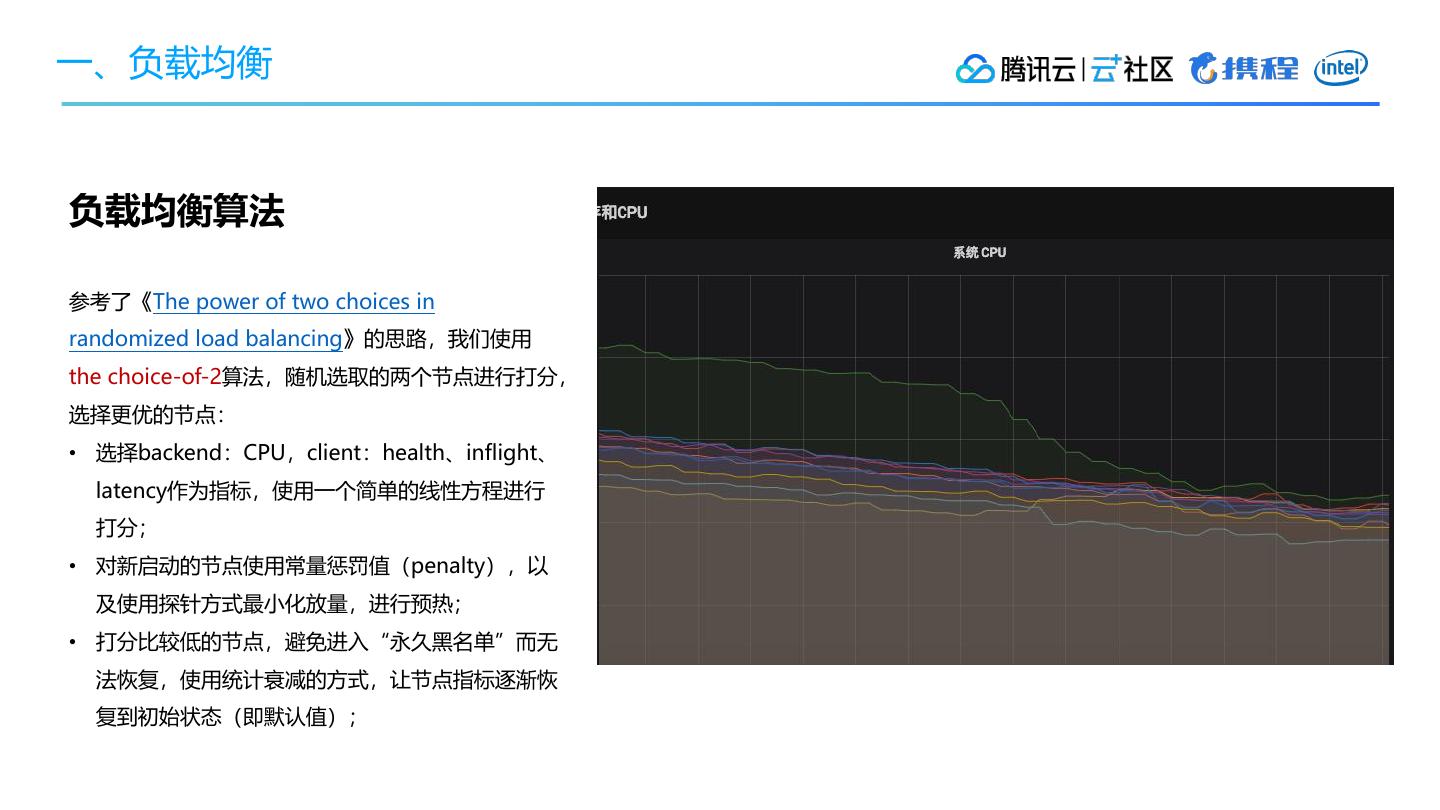
• 数据中心内部的负载均衡
2、优雅降级
• 低质量回复
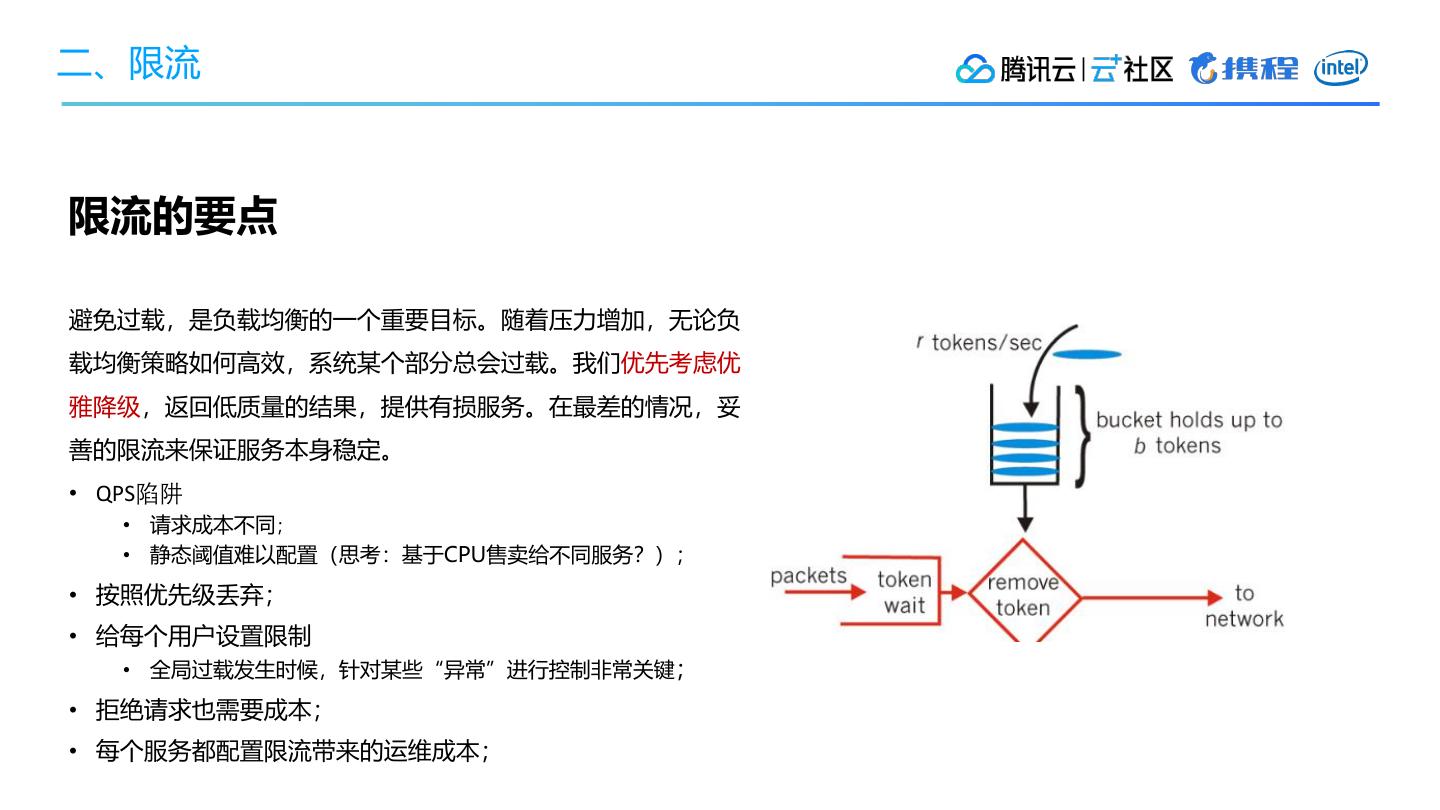
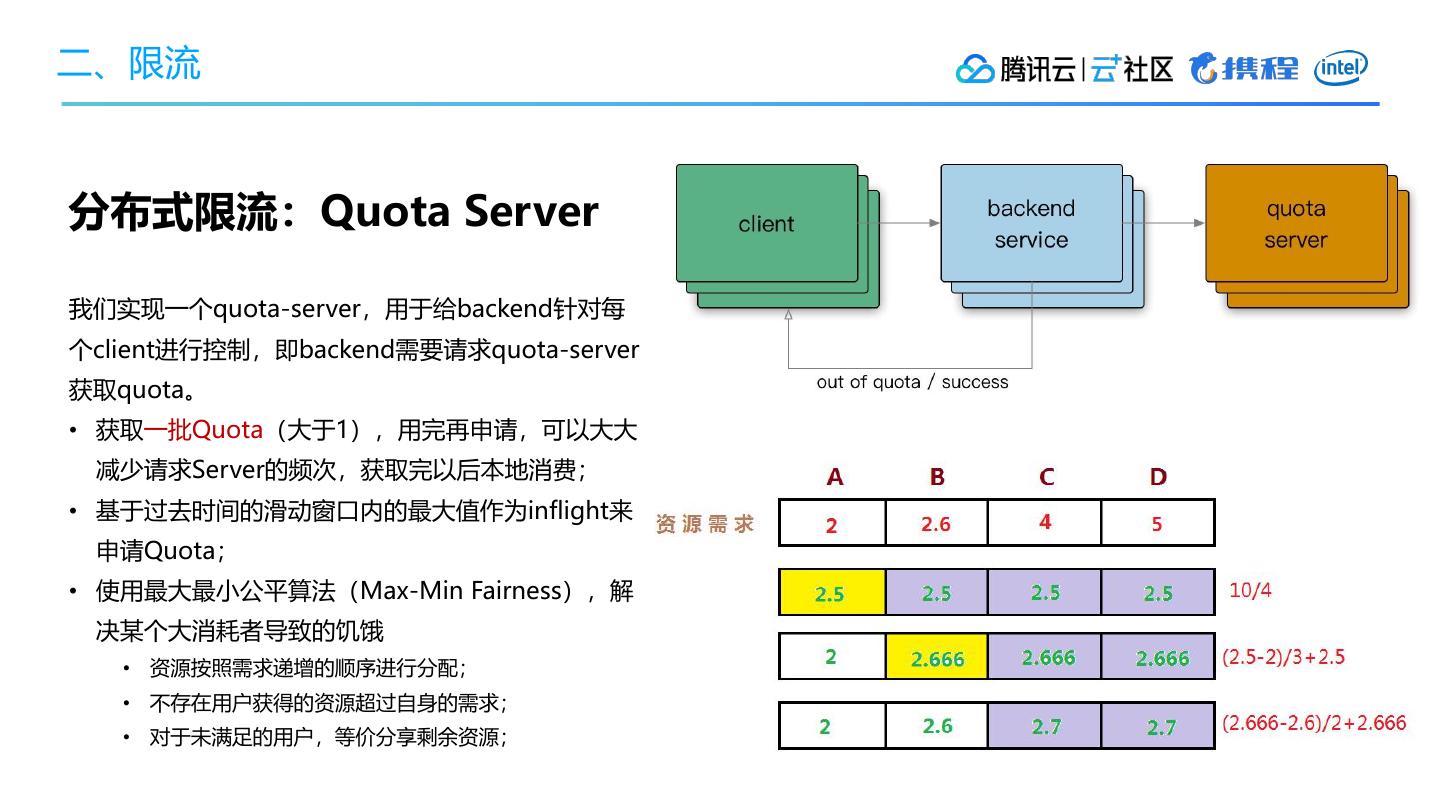
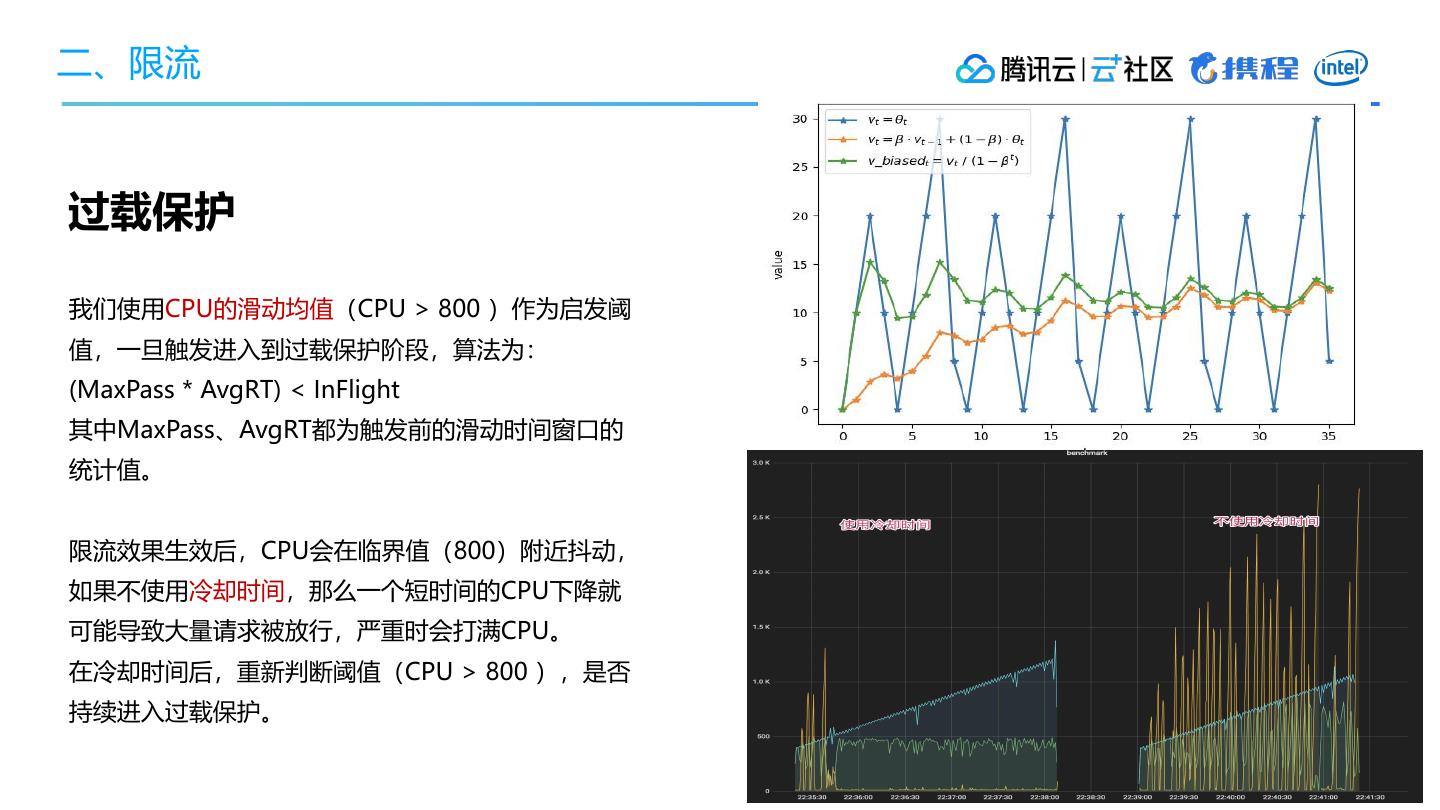
3、限流
• 每个用户设置限制
• 客户端侧的节流机制
• 自适应过载保护
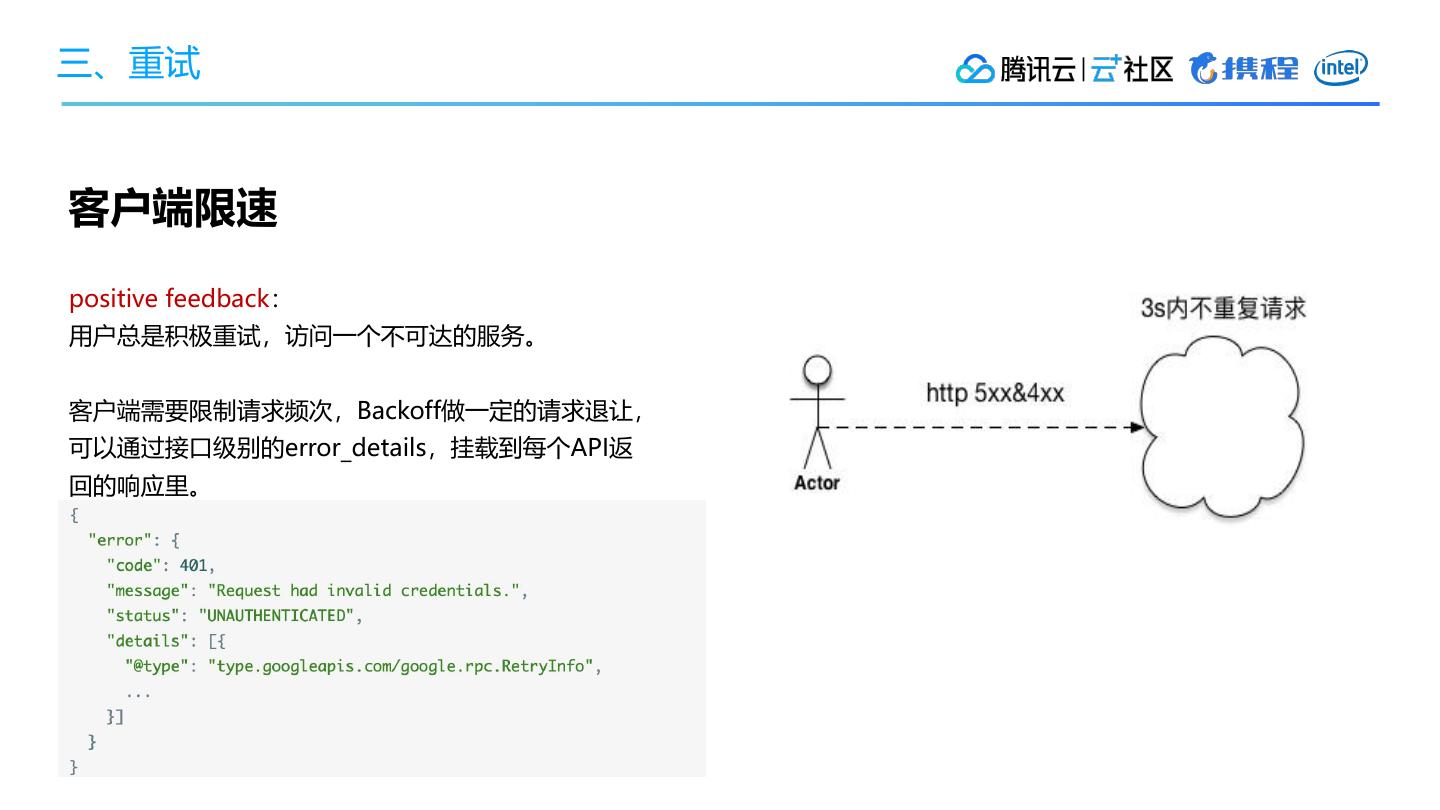
4、重试
• 重试策略
• 正反馈循环
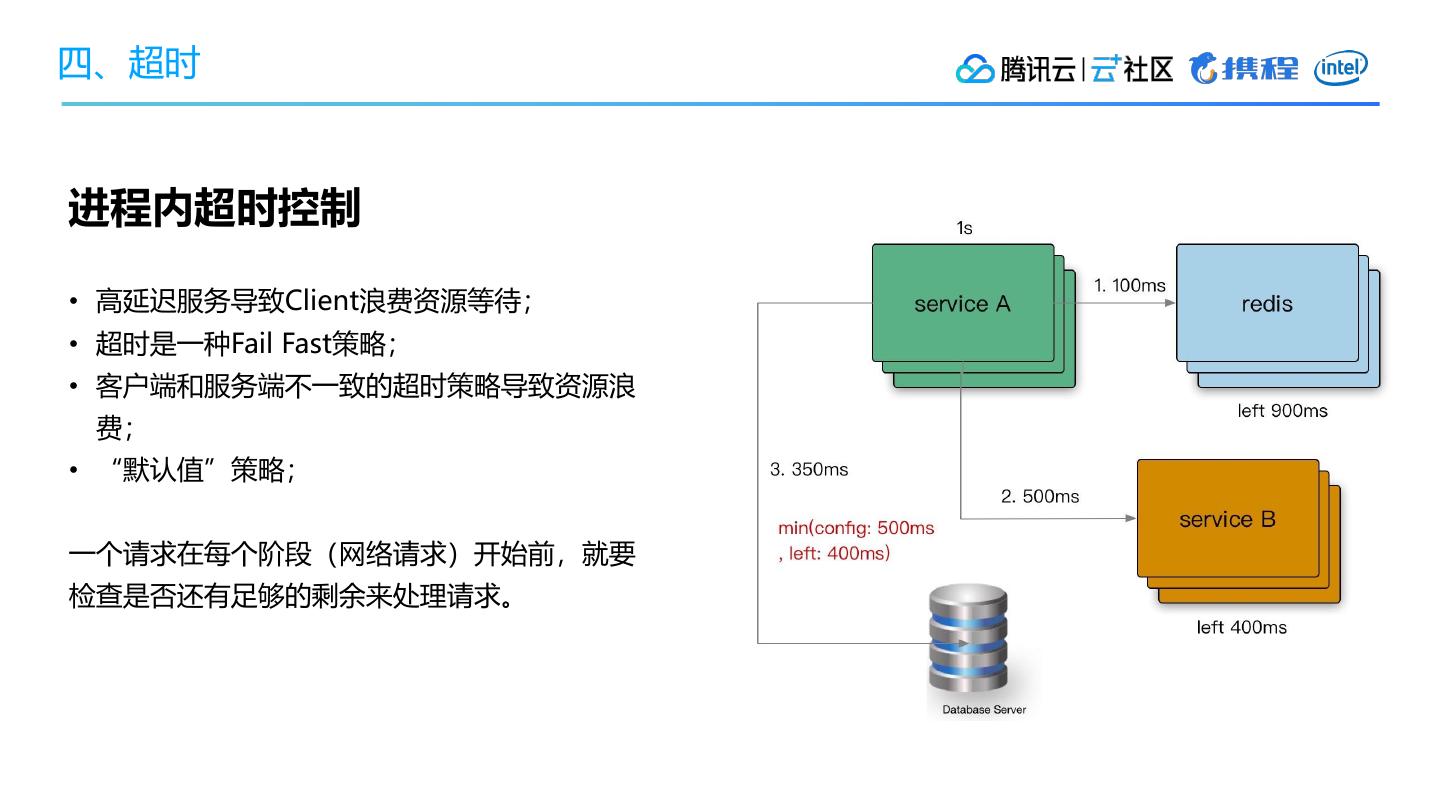
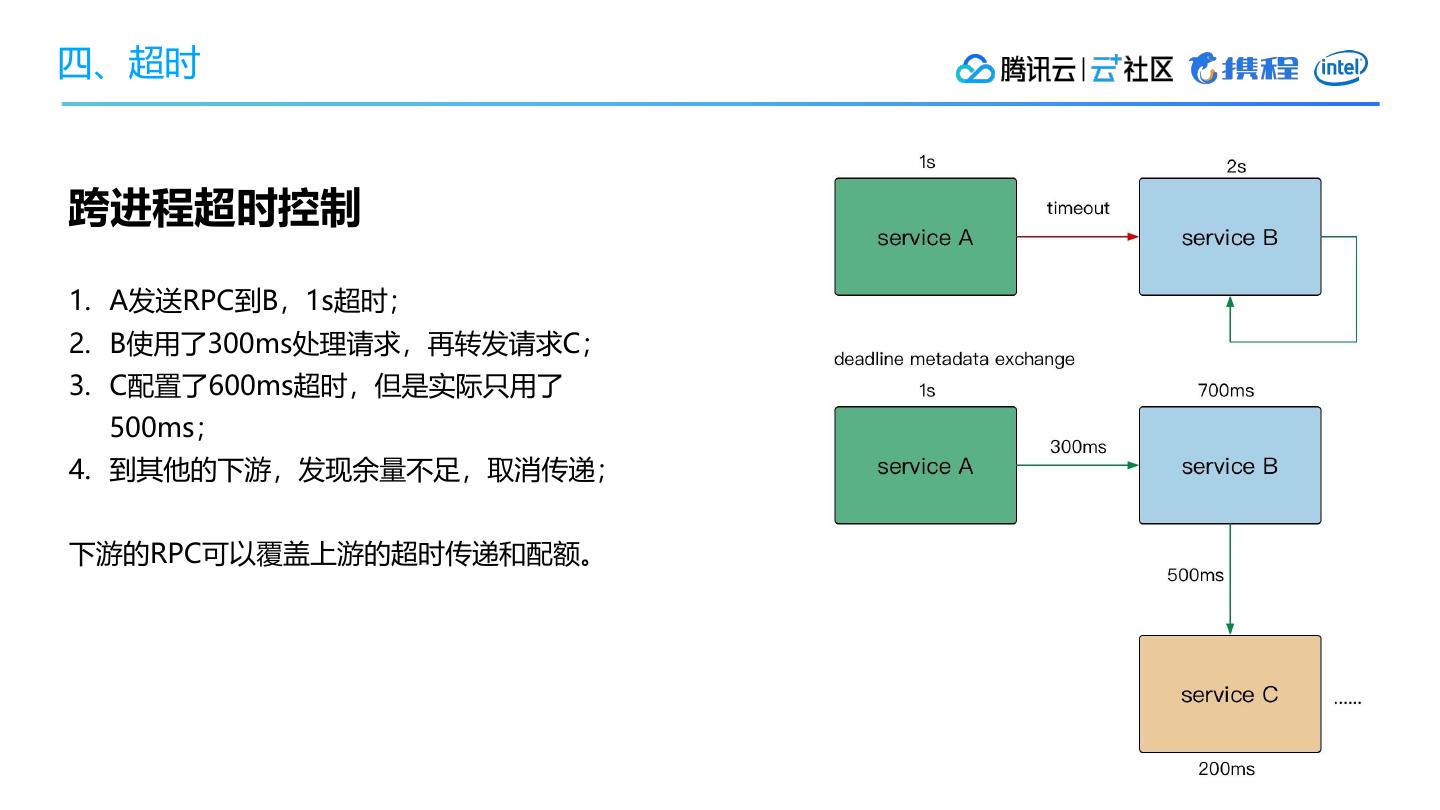
5、超时
• 请求截止
• 超时传递
6、应对连锁故障
相关推荐

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

开源之夏DolphinScheduler项目讲解-Apache Dolphinscheduler新增gRPC任务插件
DolphinScheduler社区

开源之夏2025 DolphinScheduler项目讲解-k8s任务链接优化课题
DolphinScheduler社区

