
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/ApplicationandChallengesofStreamingAnalyticsandMachineLearningonMultiVariateTimeSeriesDataforSmartManufacturing?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

Application and Challenges of Streaming Analytics and Machine Learning on Multi-Variate Time
Application and Challenges of Streaming Analytics and Machine Learning on Multi-Variate Time
Application and Challenges of Streaming Analytics and Machine Learning on Multi-Variate Time
点赞
9
收藏
4
下载 0
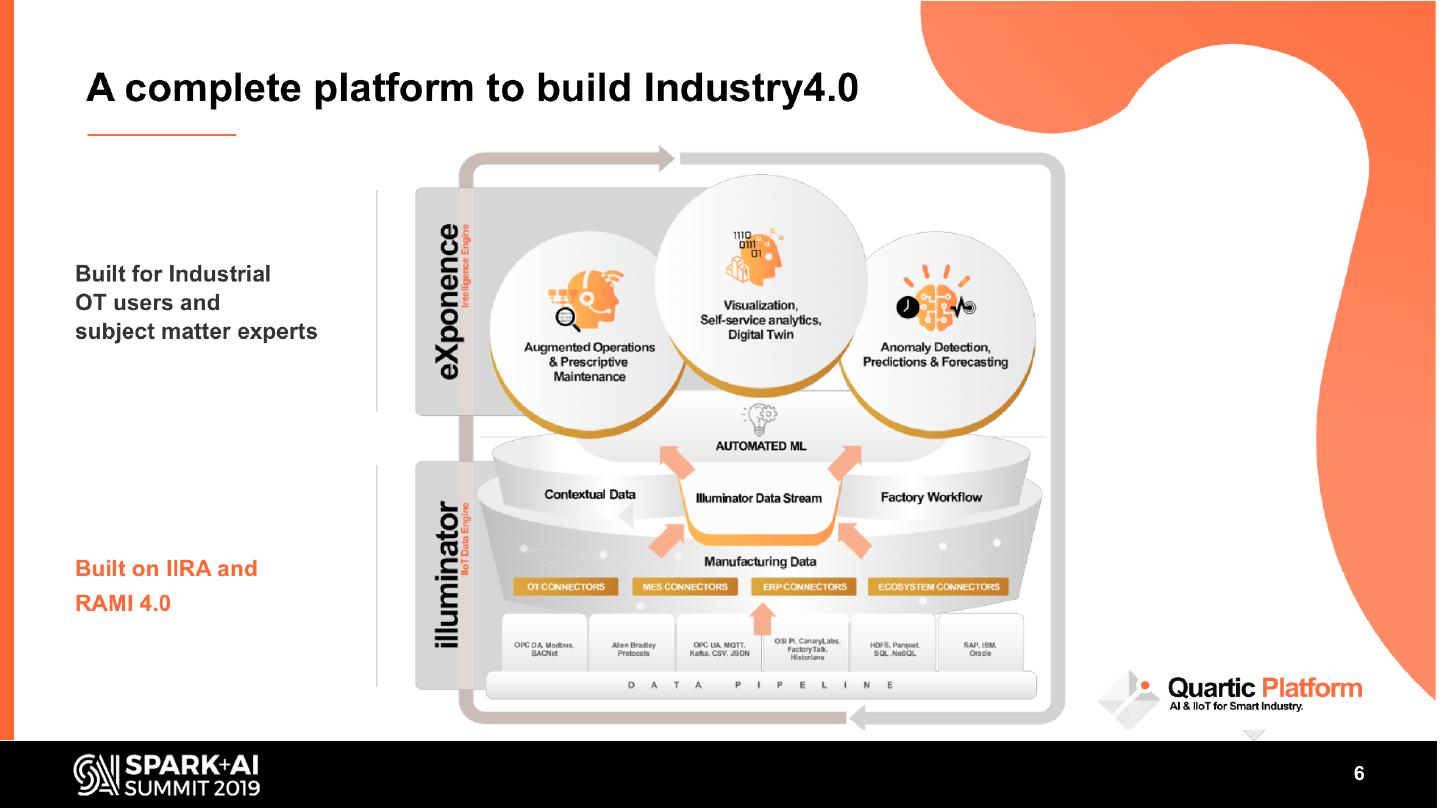
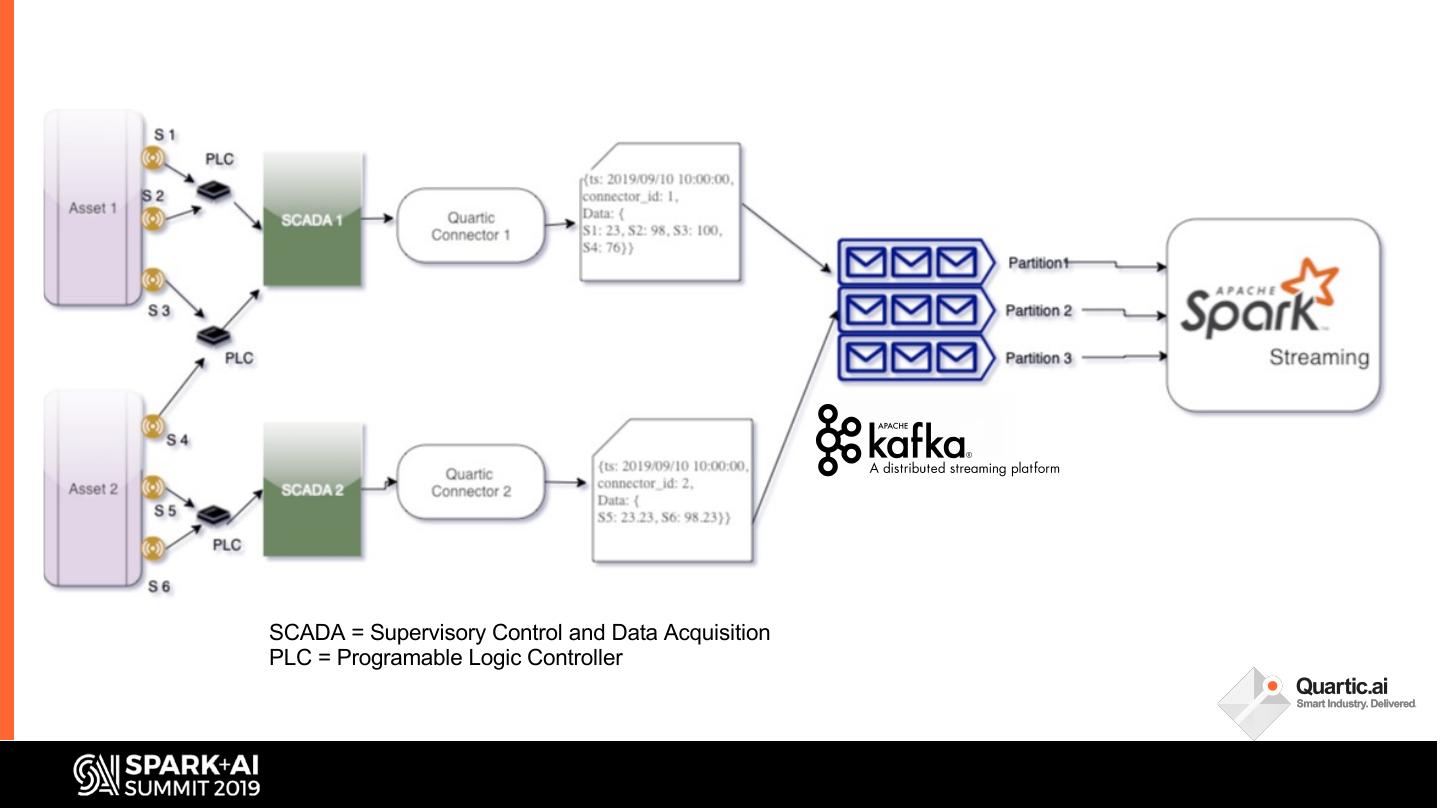
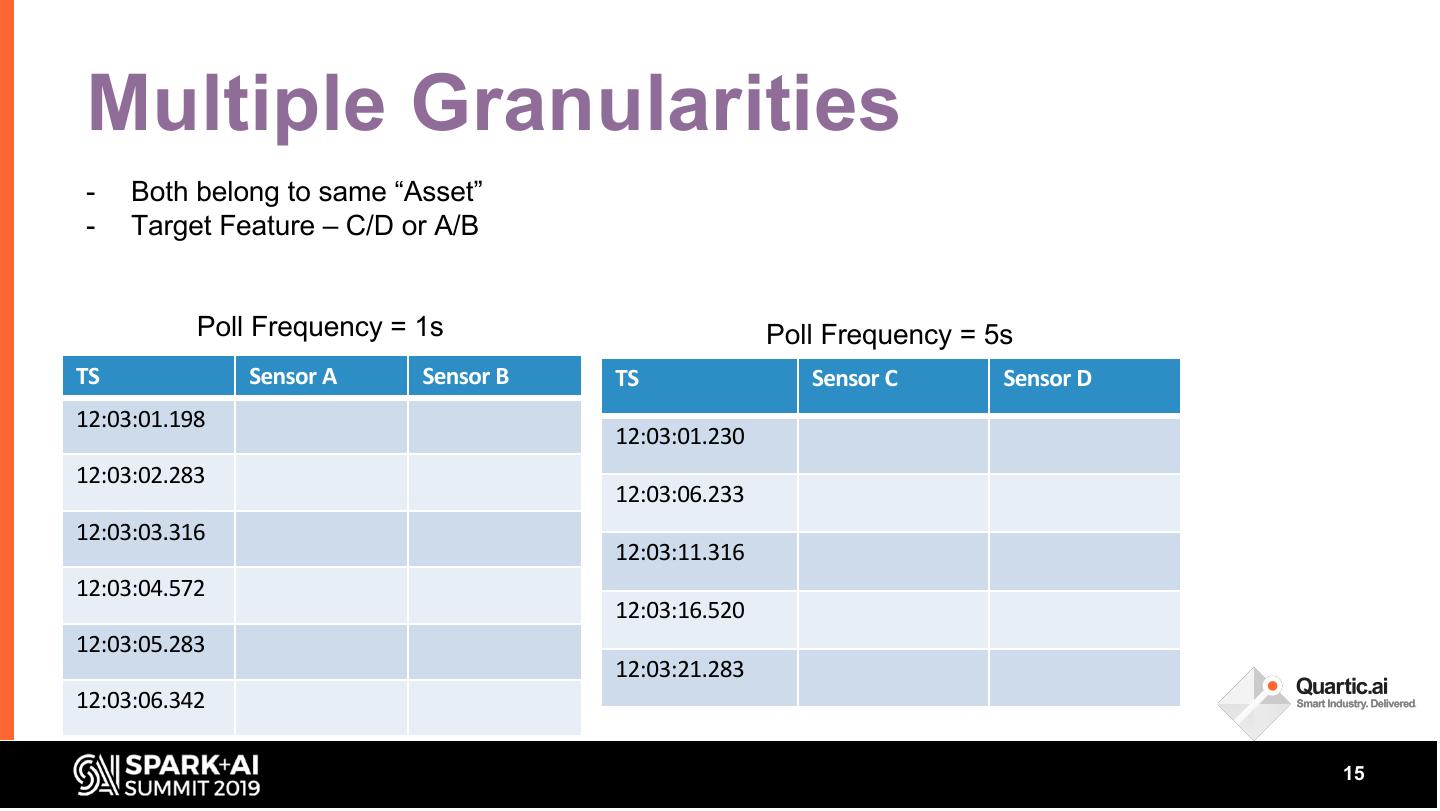
Manufacturing Industries create value by transforming raw materials into products. Many of these processes are automated with sensors and control systems which, along with manufacturing execution systems (MES), generate large volumes of data. The key objective of smart manufacturing is to harness these data to enable data driven, predictive operations to optimize the process for higher throughput, quality and energy efficiency. The complex nature of manufacturing systems poses unique challenges in building a robust data pipeline. Data needs to be collected from multiple sources at different granularities.
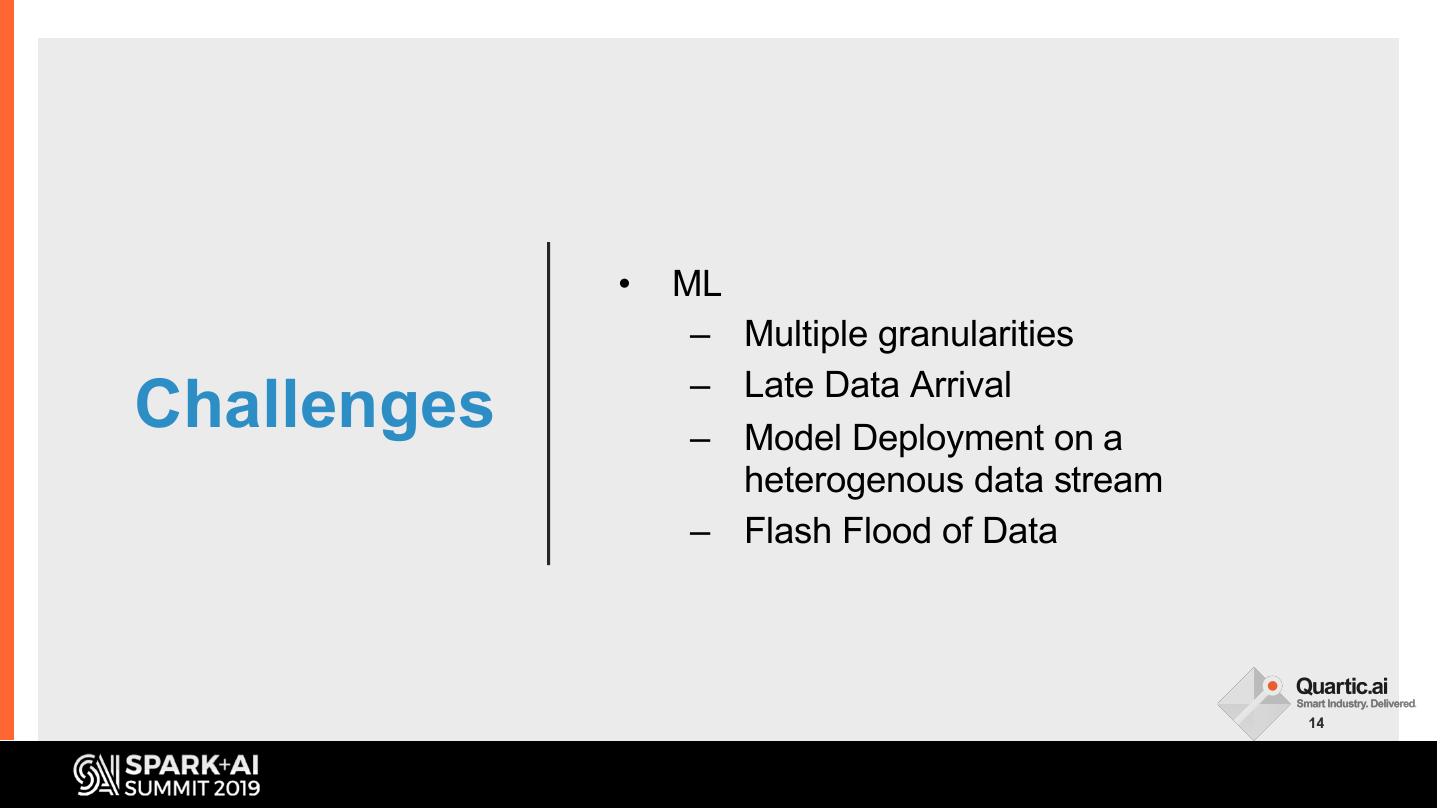
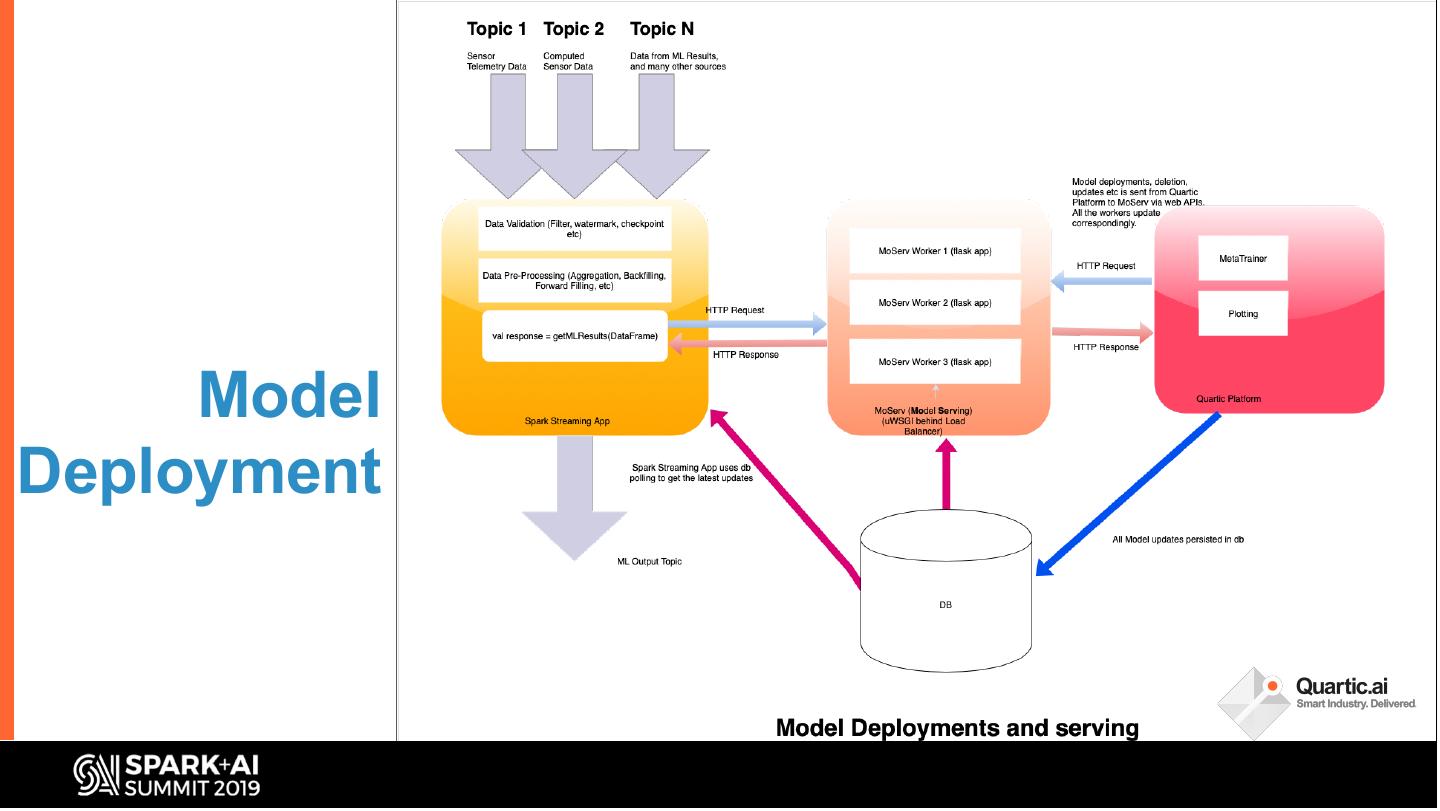
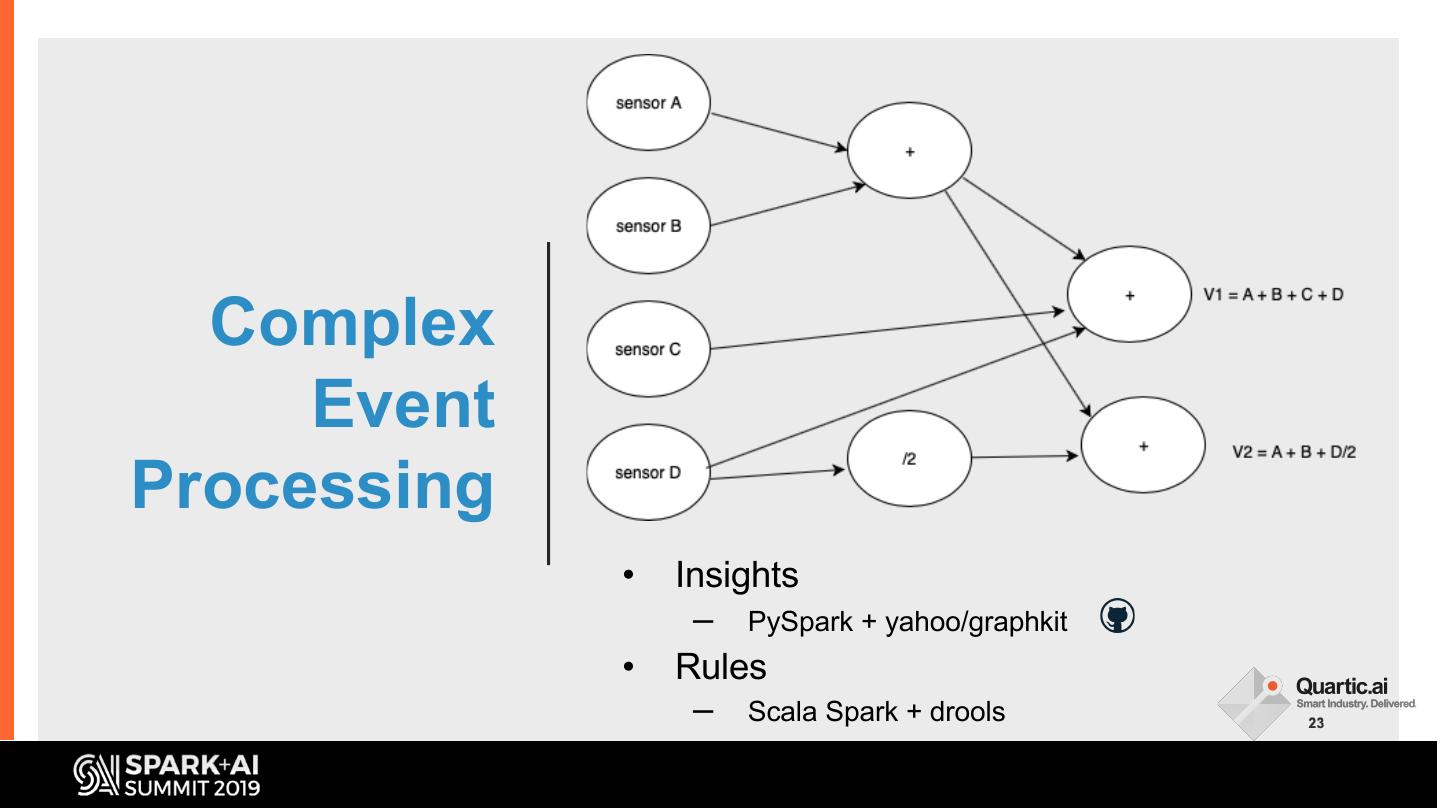
It must be prepared and enriched to make it ML ready and for processing of 1000s of deployed ML models at the edge or cloud. To make machine learning useful, it must also be blended with complex event processing (CEP). The talk will describe the challenges of multivariate time-series data in Smart Manufacturing context, our approaches to dealing with these challenges, and our learnings.
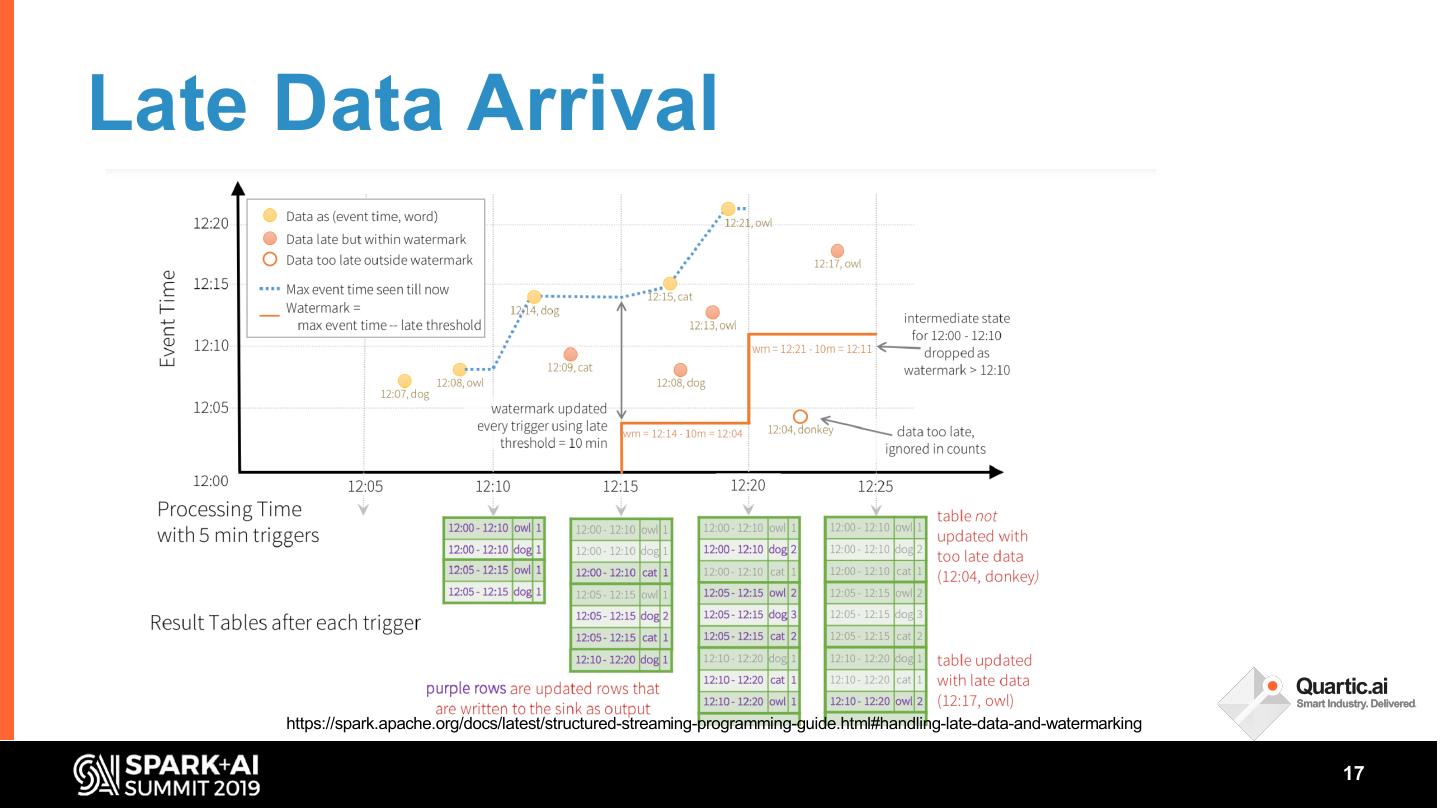
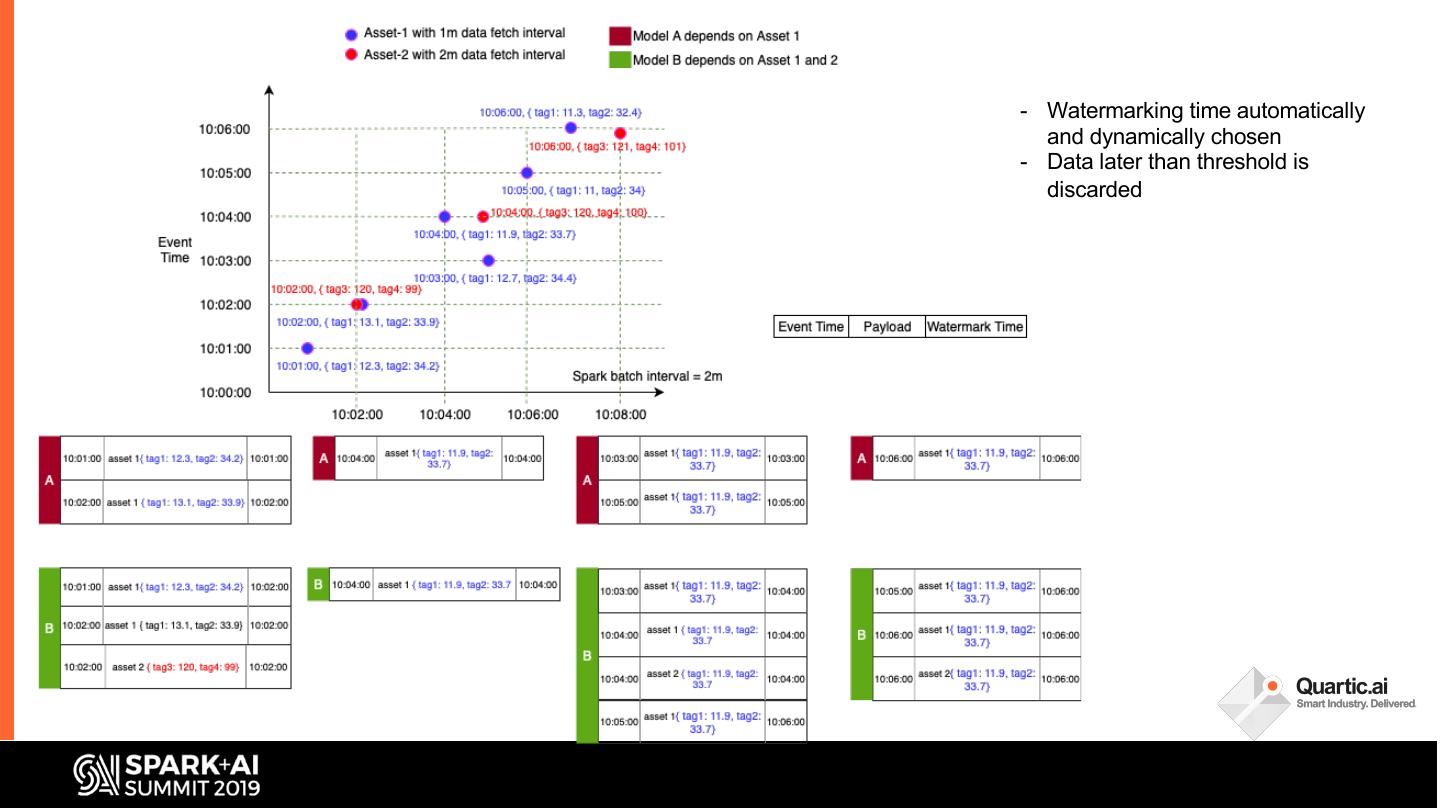
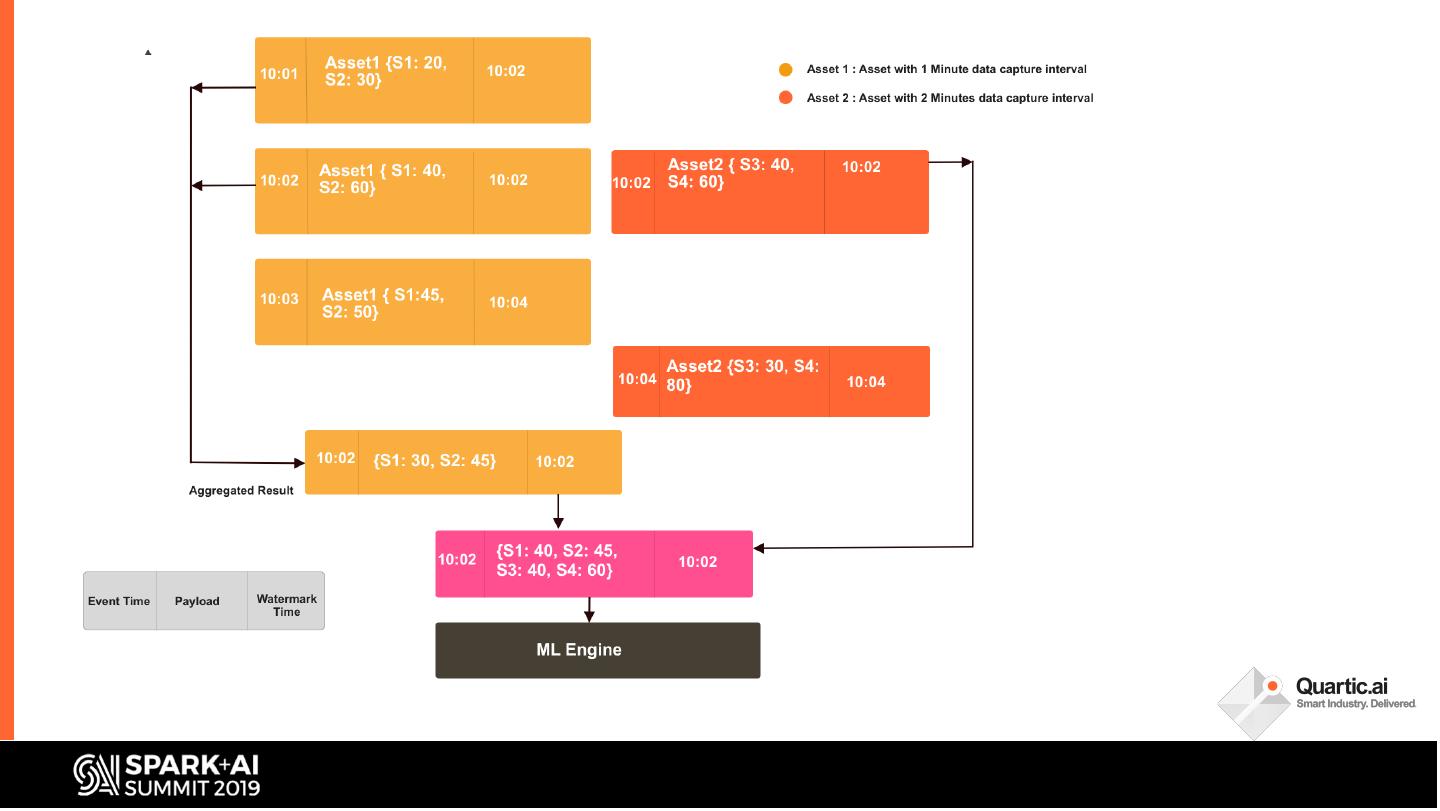
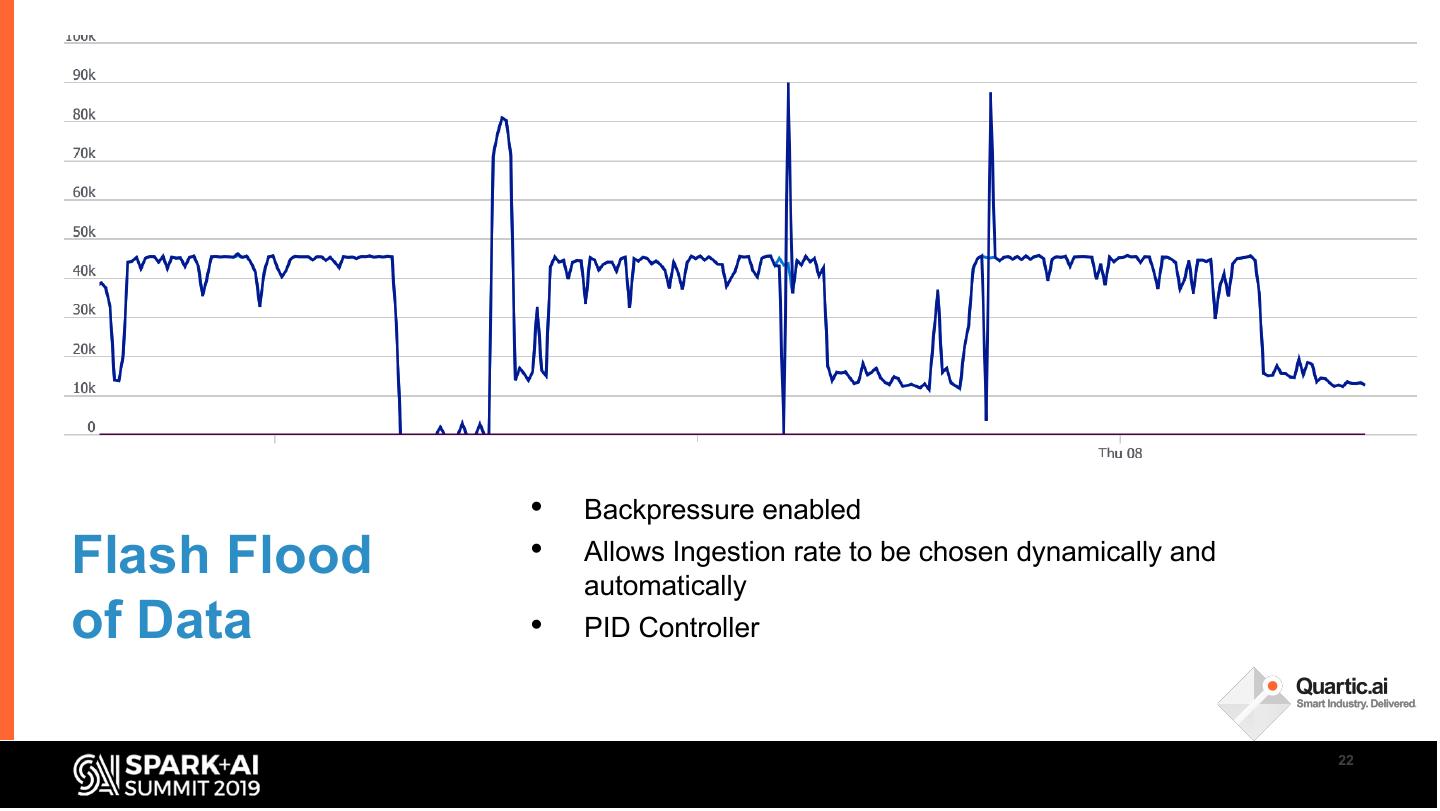
In this talk, we share some of the challenges faced in building a streaming analytics & ML pipeline. More specifically, we discuss handling time series data with different granularities and arrival order. Data spikes are also not uncommon and can pose a serious challenge to the operating SLAs of such a system. We present in detail our streaming data pipeline, which includes production deployments of ML models and CEP on edge and cloud. Using Spark, Kafka and the ecosystem around it, our team has created a platform capable of monitoring thousands of manufacturing equipment assets with millions of data points, in near real time.

