展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Augmenting Machine Learning
with Databricks Labs AutoML
Toolkit
Denny Lee, Databricks
#UnifiedDataAnalytics #SparkAISummit
�
3 .Agenda
• Discuss traditional ML pipeline problem and all of
its stages
• How AutoML Toolkit solves these problems
• Hyperparameter Optimization
• Choosing Models
• Scaling AutoML Toolkit Best Practices
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .About Speaker
Denny Lee
Developer Advocate, Databricks
• Worked with Apache Spark™ since 0.5
• Former Senior Director Data Science Engineering at
Concur
• On Project Isotope incubation team that built what
is now known as Azure HDInsight
• Former SQLCAT DW BI Lead at Microsoft
#UnifiedDataAnalytics #SparkAISummit 4
�
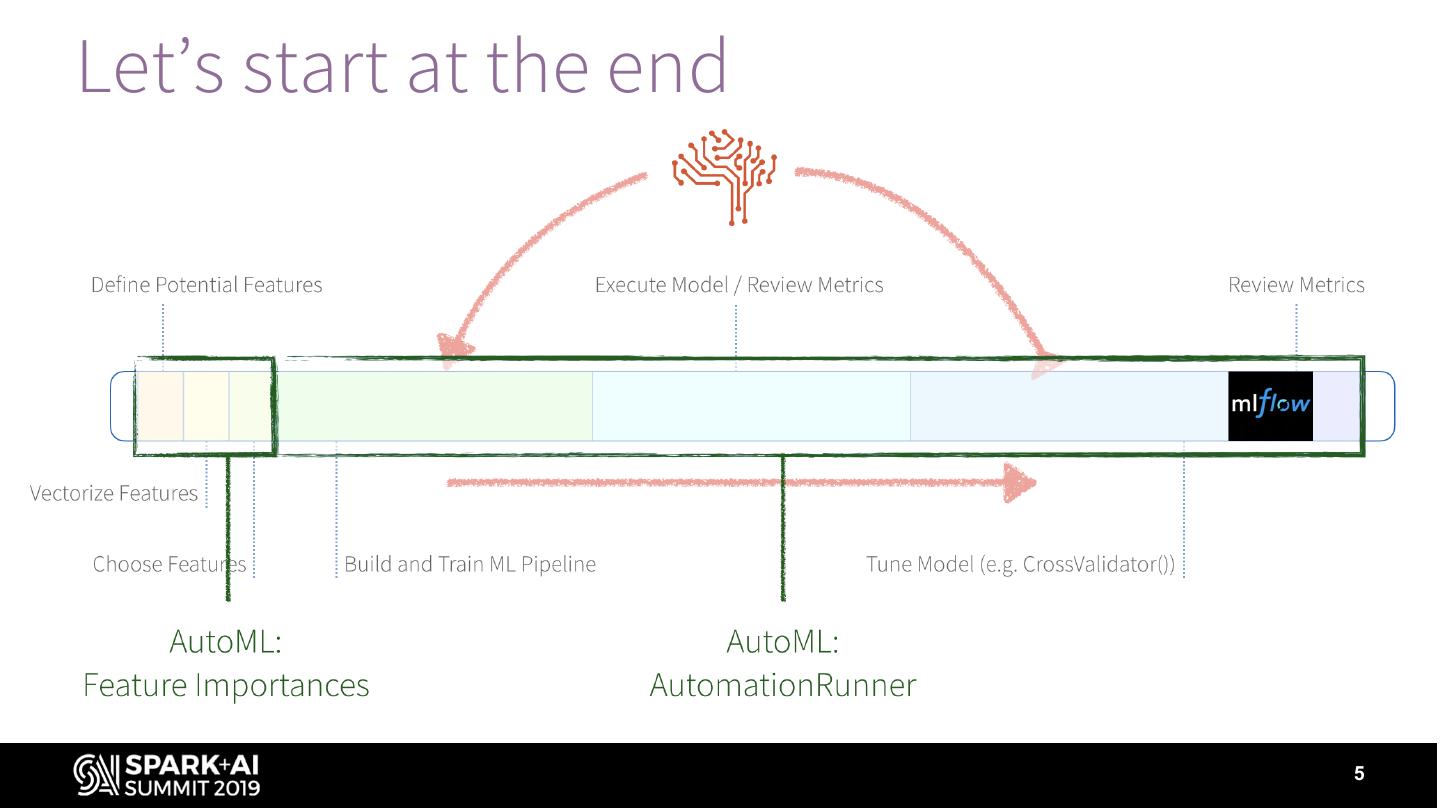
5 .Let’s start at the end
5
�
6 .Let’s start at the end
• AutoML’s FeatureImportances automates the discovery
of which feature discovery
• AutoML’s AutomationRunner automates the building,
training, execution, and tuning of a Machine Learning pipeline
to create an optimal ML model.
• Improved AUC from 0.6732 to 0.995!
• Business value: $23.22M to $267.24M saved!
• Less code, faster!
6
�
9 .Identify Important Features
Traditional ML Pipelines
9
�
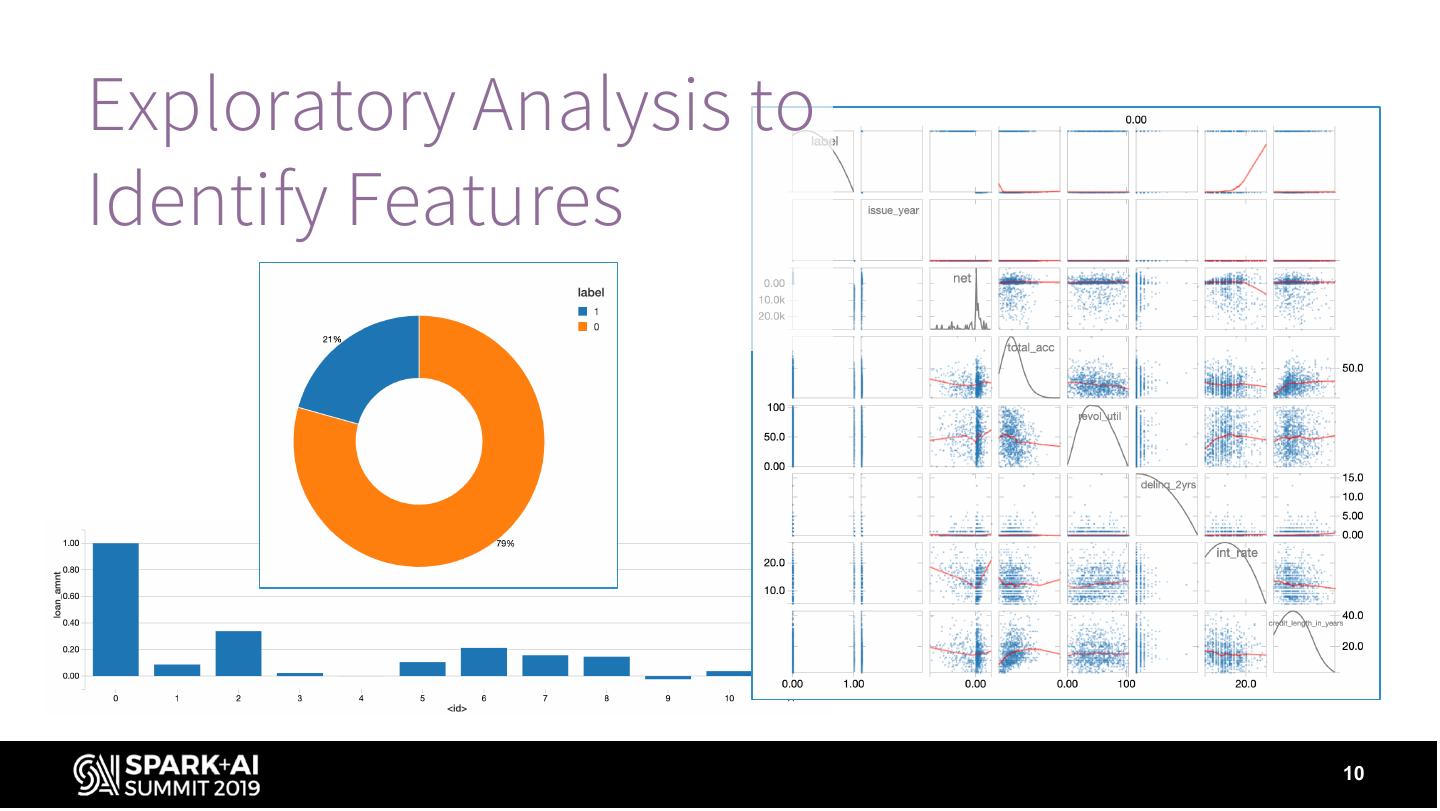
10 .Exploratory Analysis to
Identify Features
10
�
11 .Identify Important Features
AutoML Toolkit
11
�
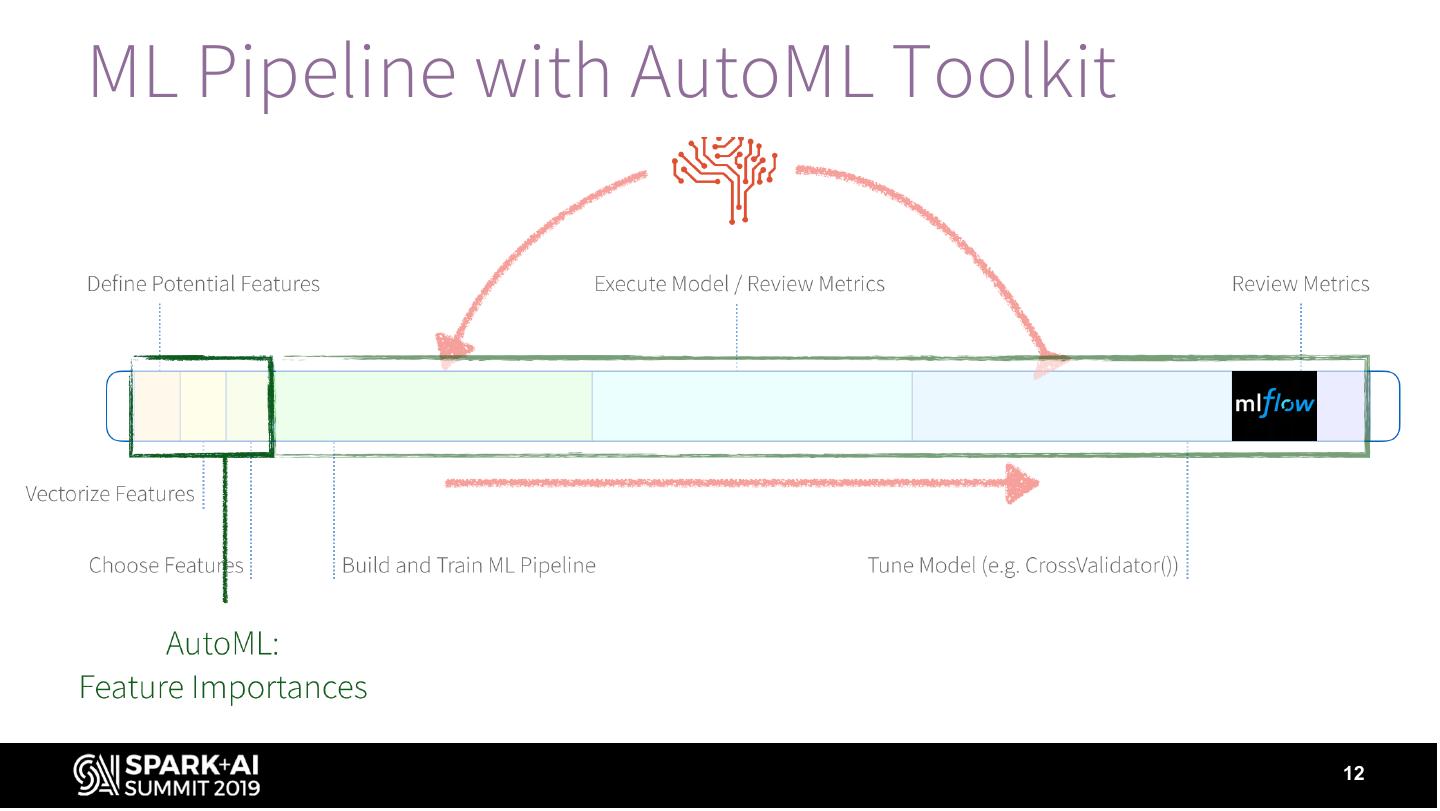
12 .ML Pipeline with AutoML Toolkit
12
�
13 .AutoML | FeatureImportances
// Calculate Feature Importance (fi)
val fiConfig = ConfigurationGenerator.generateConfigFromMap("XGBoost",
"classifier", genericMapOverrides)
// Since we're using XGBoost, set parallelism <= 2x number of nodes
fiConfig.tunerConfig.tunerParallelism = nodeCount * 2
val fiMainConfig =
ConfigurationGenerator.generateFeatureImportanceConfig(fiConfig)
// Generate Feature Importance
val importances = new FeatureImportances(sourceData, fiMainConfig, "count", 20.0)
.generateFeatureImportances()
13
�
14 .AutoML | FeatureImportances
14
�
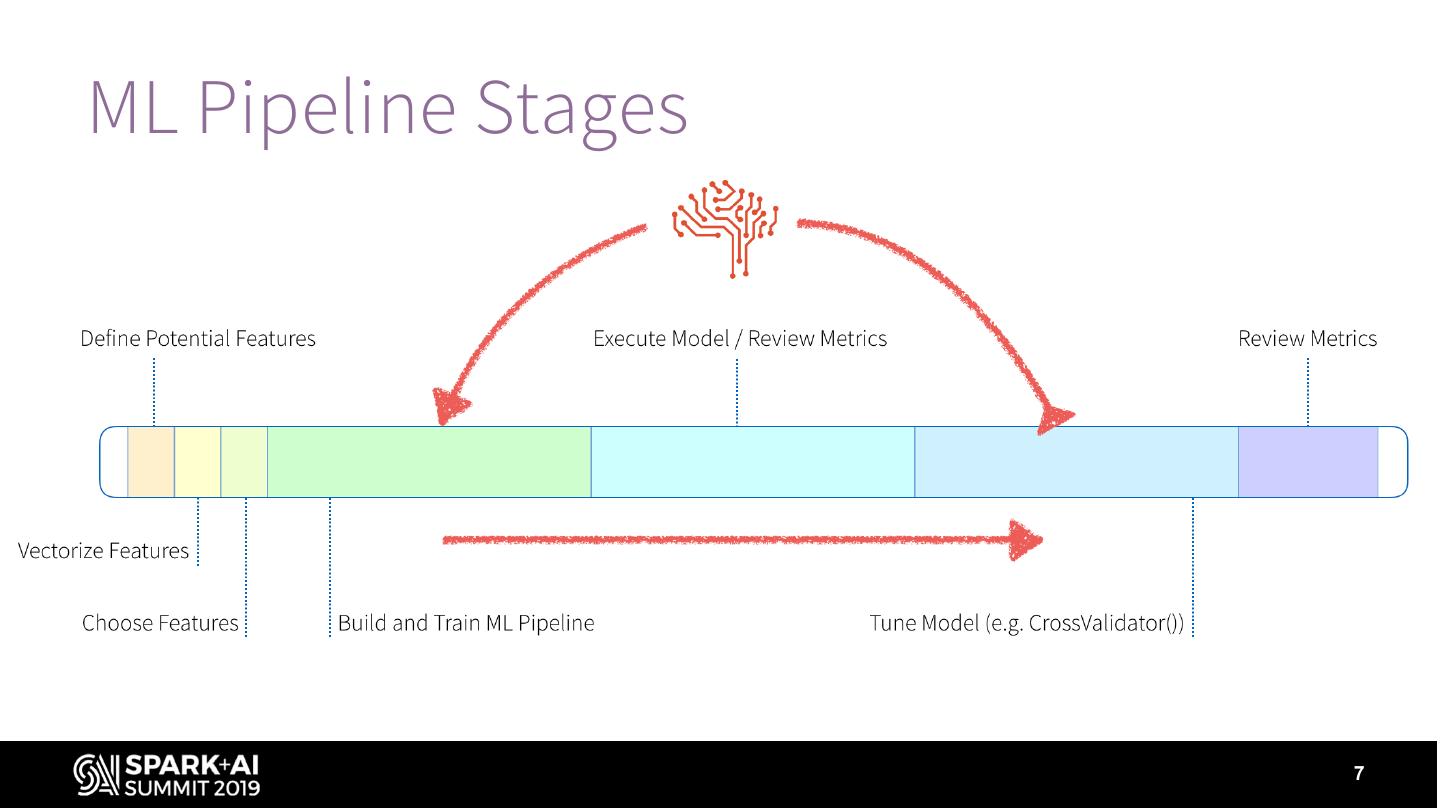
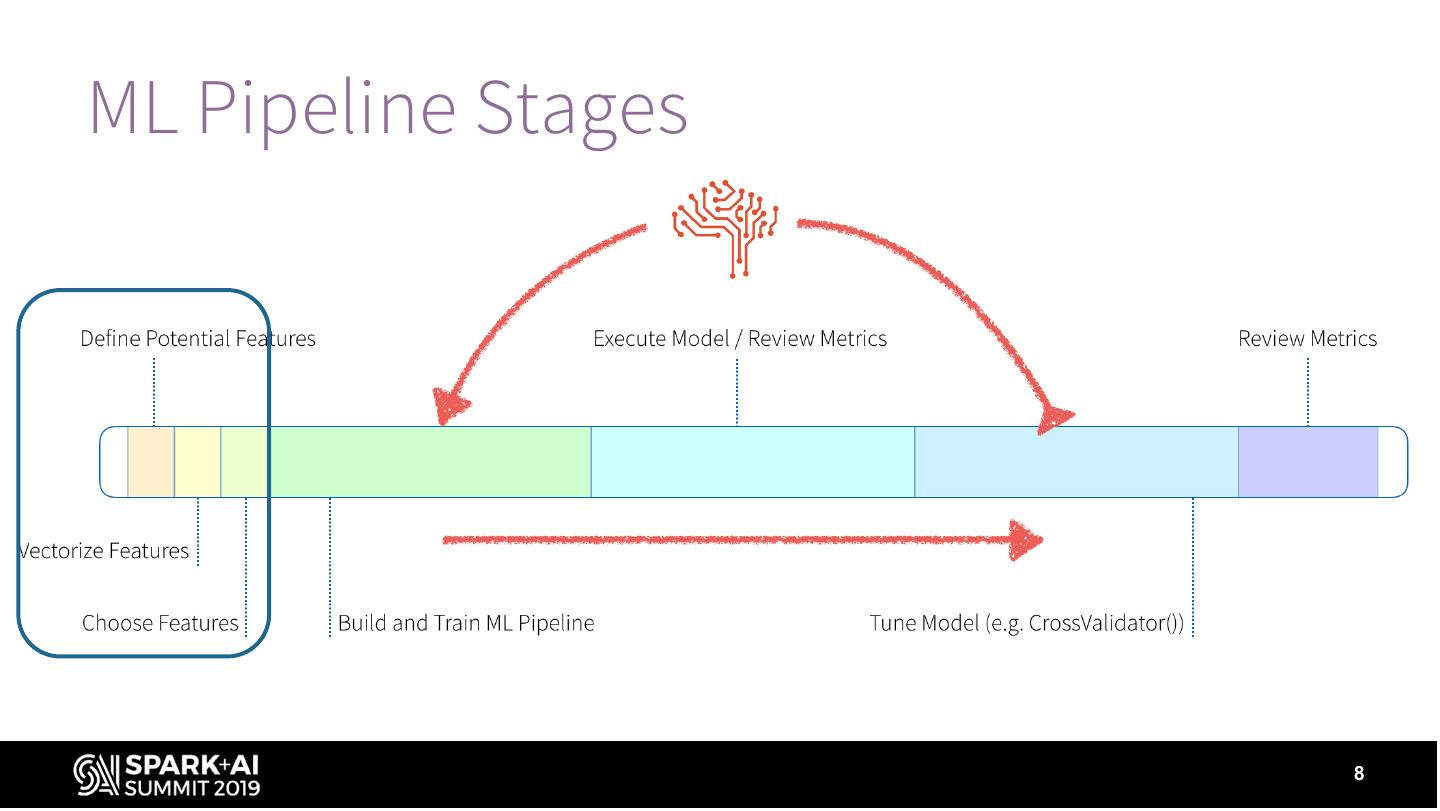
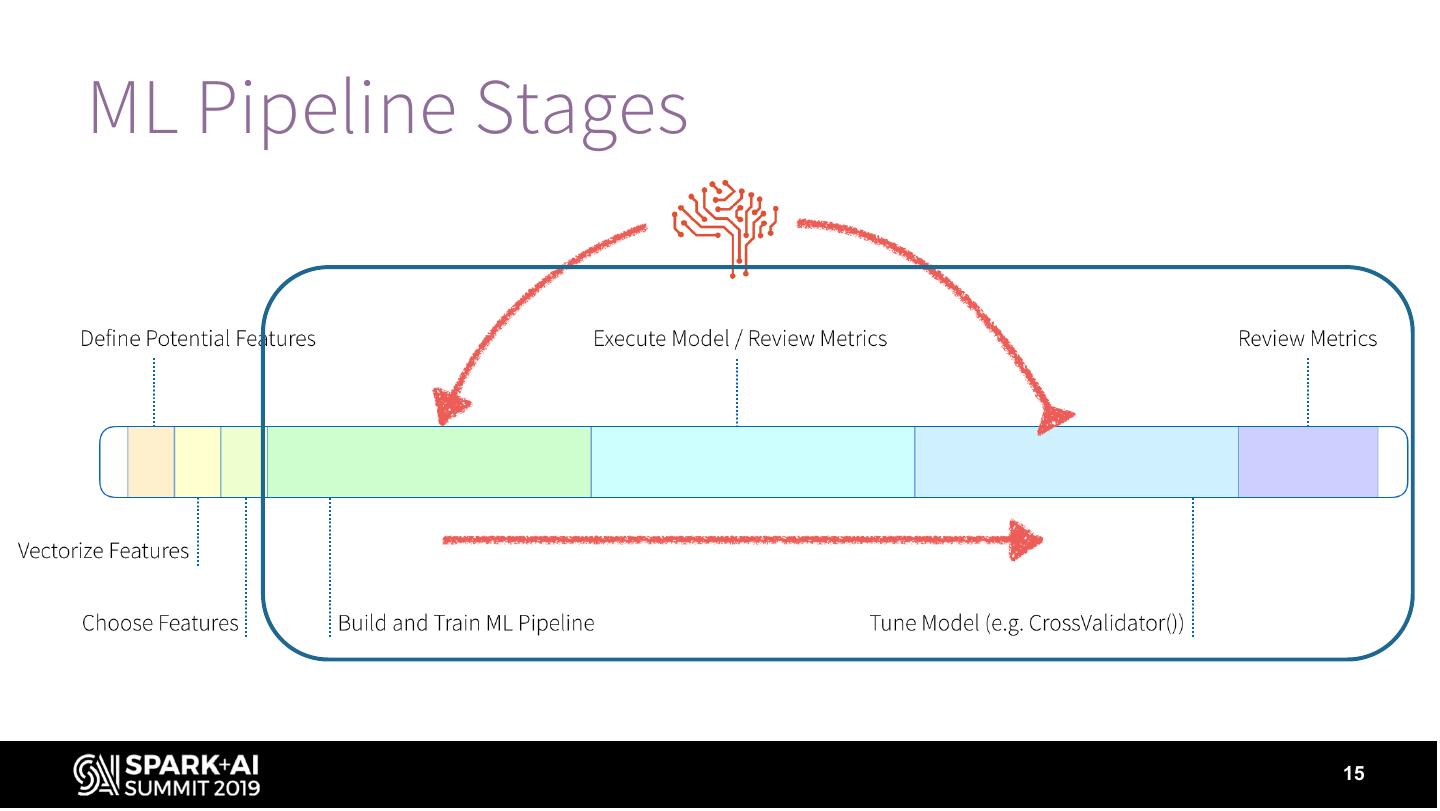
15 .ML Pipeline Stages
15
�
16 .Building and Tuning Models
Traditional Model Building and Tuning
16
�
17 .Hand-made Model
• Traditionally, when we build a ML pipeline, we will need to a number of tasks including:
• Defining our category (text-based) and numeric columns
• Based on previous analysis, you can determine which features (i.e. which columns to include for your ML model)
• For numeric columns, ensure they are double or float data types
• For category columns, convert them using a stringIndexer and one-hot encoding to create a numeric representation of the category data
• Build and train our ML pipeline to create our ML model (in this case, an XGBoost mode)
• For example, put together imputer, stringIndexer, One-Hot encoding of category data
• Create a vector (e.g. vectorAssembler) to put together these features
• Apply a standard scaler to the values to minimize the impact of outliers
• Execute the model against our dataset
• Review the metrics (e.g., AUC)
• Tune the model using a Cross Validator
• The better you understand the model, the more likely you will provide better hyperparameters for cross validation
• i.e. need to choose a solid set of parameters (e.g. paramGrid)
• Review the metrics again (e.g. AUC)
• Review confusion matrix (in the case of binary classification)
• Review business value
17
�
18 .Hand-made Model
• er?
•
a i
Traditionally, when we build a ML pipeline, we will need to a number of tasks including:
s
Defining our category (text-based) and numeric columns
•
•
s e
Based on previous analysis, you can determine which features (i.e. which columns to include for your ML model)
For numeric columns, ensure they are double or float data types
•
• hi
For category columns, convert them using a stringIndexer and one-hot encoding to create a numeric representation of the category data
t
Build and train our ML pipeline to create our ML model (in this case, an XGBoost mode)
•
•
ake
For example, put together imputer, stringIndexer, One-Hot encoding of category data
Create a vector (e.g. vectorAssembler) to put together these features
•
• m
Apply a standard scaler to the values to minimize the impact of outliers
e
• w
Execute the model against our dataset
Can
Review the metrics (e.g., AUC)
• Tune the model using a Cross Validator
• The better you understand the model, the more likely you will provide better hyperparameters for cross validation
• i.e. need to choose a solid set of parameters (e.g. paramGrid)
• Review the metrics again (e.g. AUC)
• Review confusion matrix (in the case of binary classification)
• Review business value
18
�
19 .Building and Tuning Models
AutoML Model Building and Tuning
19
�
20 .ML Pipeline with AutoML Toolkit
20
�
21 .AutoML | AutomationRunner
val modelingType = "XGBoost"
val conf = ConfigurationGenerator.generateConfigFromMap(modelingType,…)
// Adjust model tuner configuration
conf.tunerConfig.tunerParallelism = nodeCount
// Generate configuration
val XGBConfig = ConfigurationGenerator.generateMainConfig(conf)
// Select on the important features
val runner = new AutomationRunner(sourceData).setMainConfig(XGBConfig)
.runWithConfusionReport()
21
�
22 .Model, Metrics, Configs Saved
AUC from 0.6732 to 0.995!
22
�
23 .Clearing up the Confusion
Hand-Made Model AutoML Model
Predicted Label Predicted Label
23
�
24 .Business Value
From $23.22M to $267.24M saved!
24
�
25 .Let’s end at the end
• AutoML’s FeatureImportances automates the discovery
of which feature discovery
• AutoML’s AutomationRunner automates the building,
training, execution, and tuning of a Machine Learning pipeline
to create an optimal ML model.
• Improved AUC from 0.6732 to 0.995!
• Business value: $23.22M to $267.24M saved!
• Less code, faster!
25
�
26 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�