























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/ContinuousEvaluationofDeployedModelsinProduction?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

Continuous Evaluation of Deployed Models in Production
Continuous Evaluation of Deployed Models in Production
Continuous Evaluation of Deployed Models in Production
点赞
6
收藏
2
下载 0
Many high-tech industries rely on machine-learning systems in production environments to automatically classify and respond to vast amounts of incoming data. Despite their critical roles, these systems are often not actively monitored. When a problem first arises, it may go unnoticed for some time. Once it is noticed, investigating its underlying cause is a time-consuming, manual process. Wouldn’t it be great if the model’s output were automatically monitored? If they could be visualized, sliced by different dimensions? If the system could automatically detect performance degradation and trigger alerts? In this presentation, we describe our experience from building such a core machine-learning services: Model Evaluation.
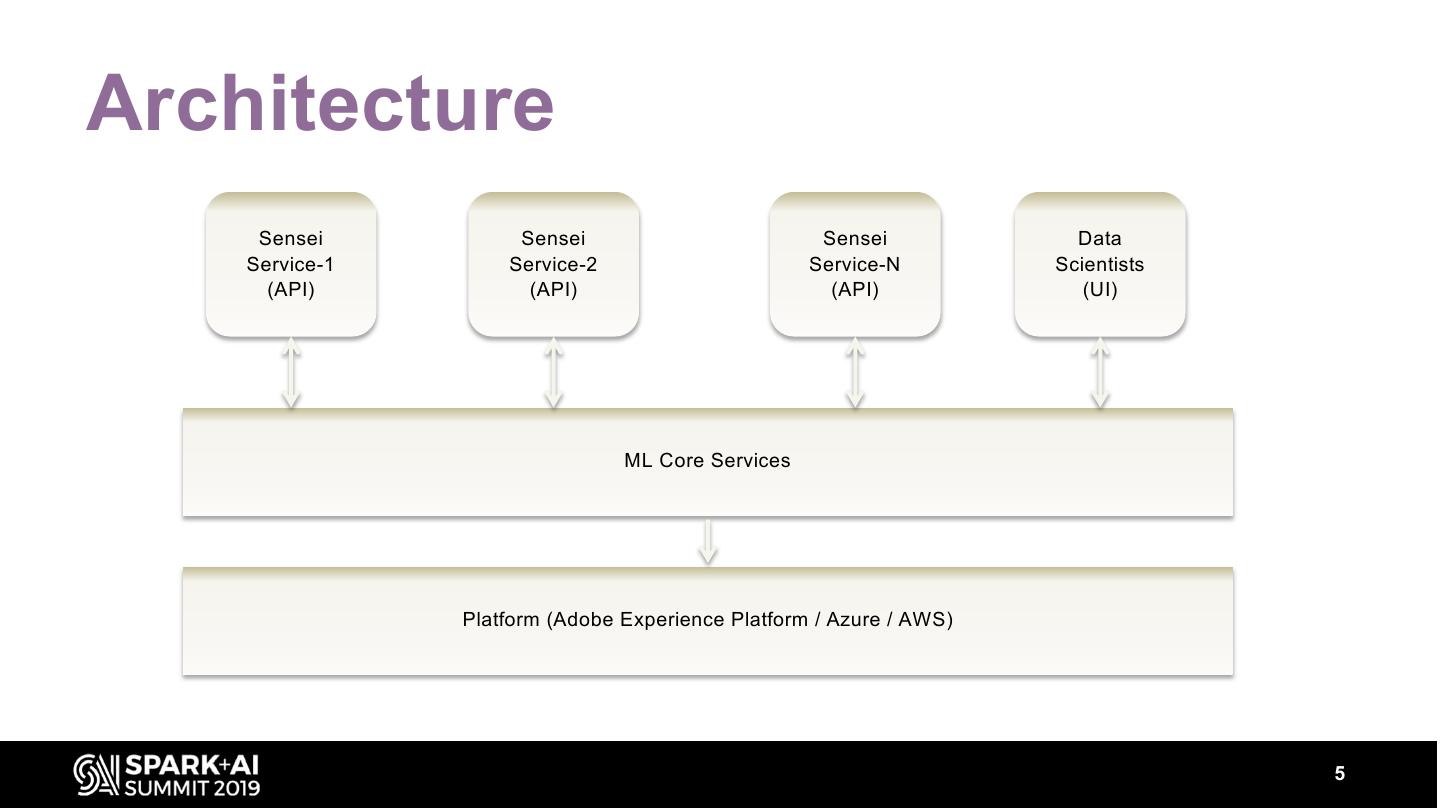
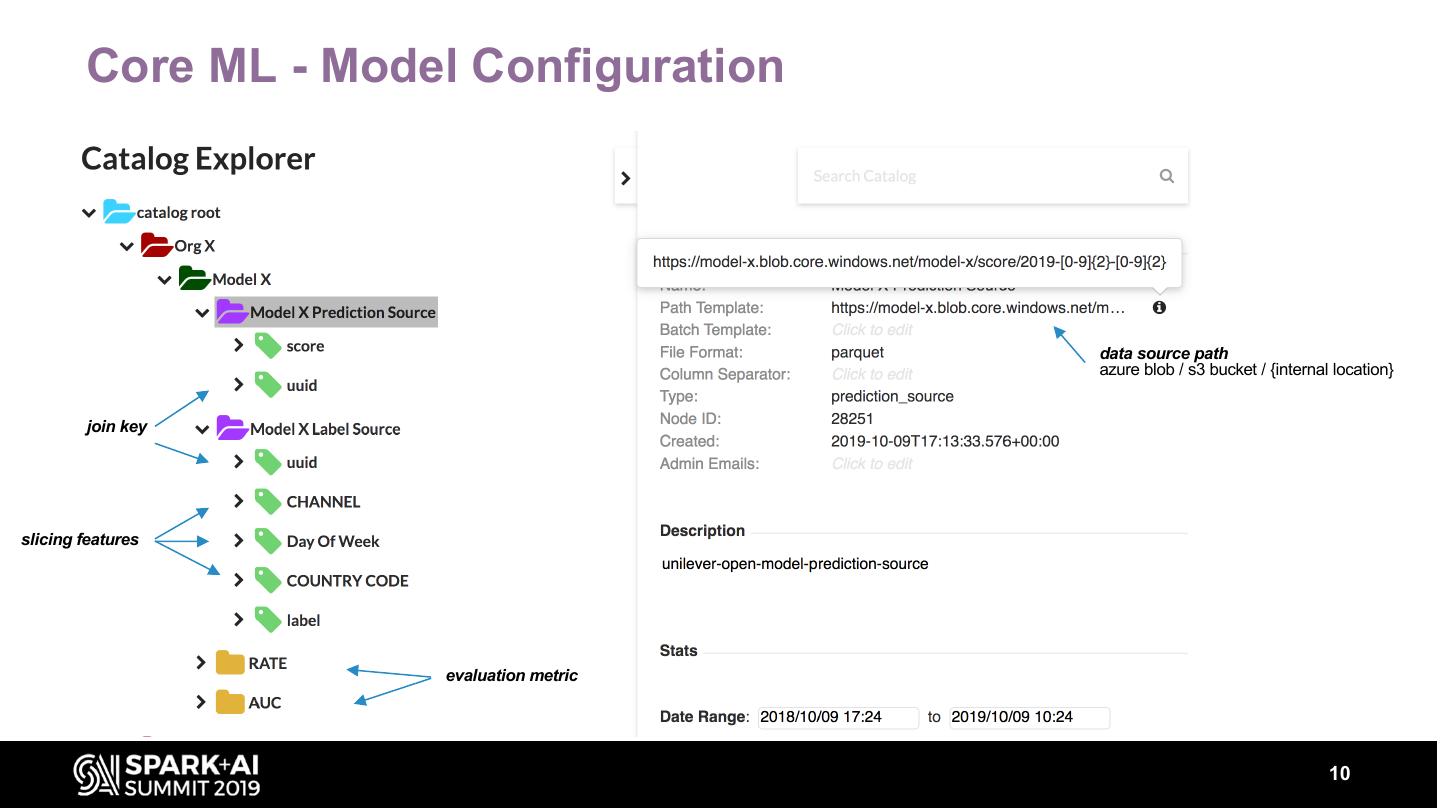
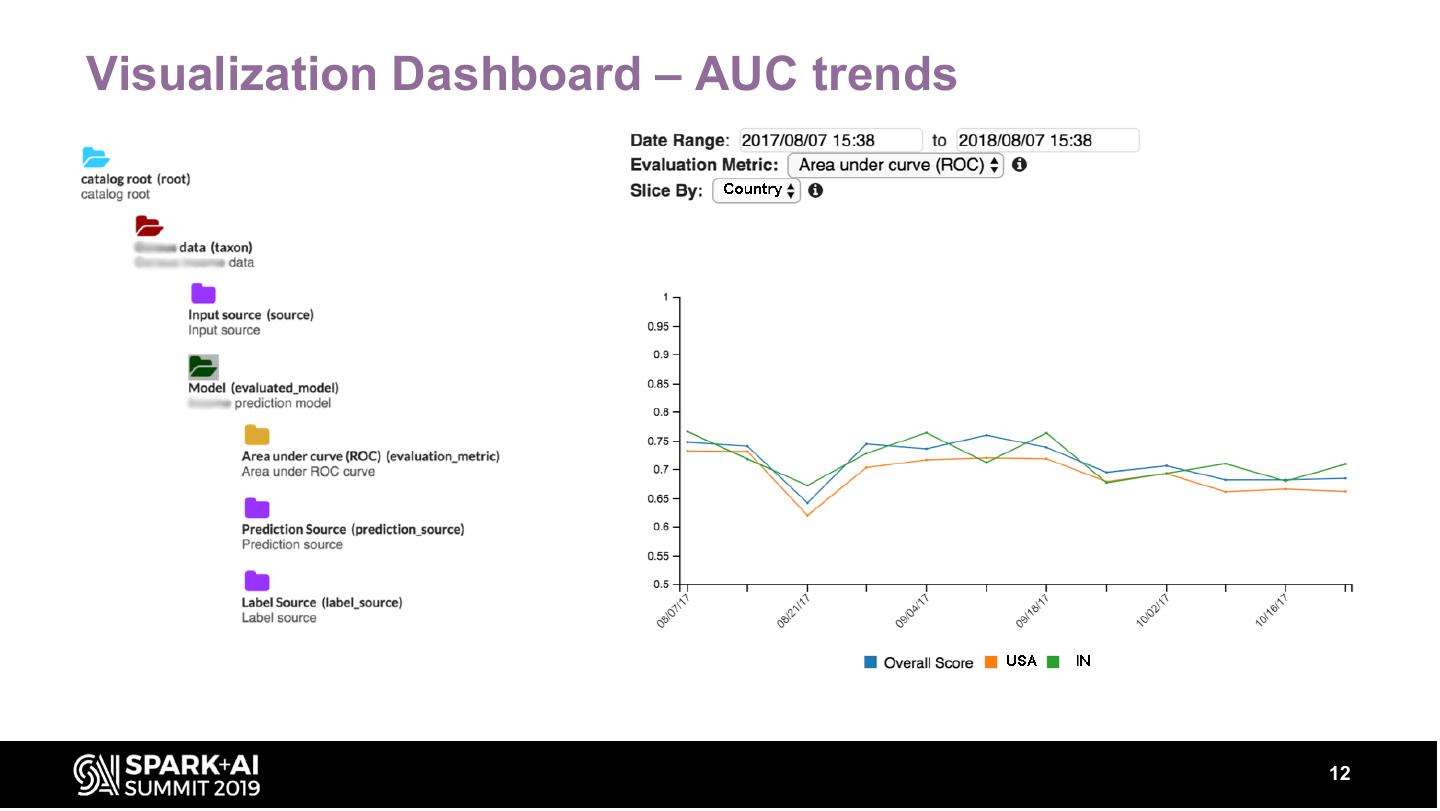
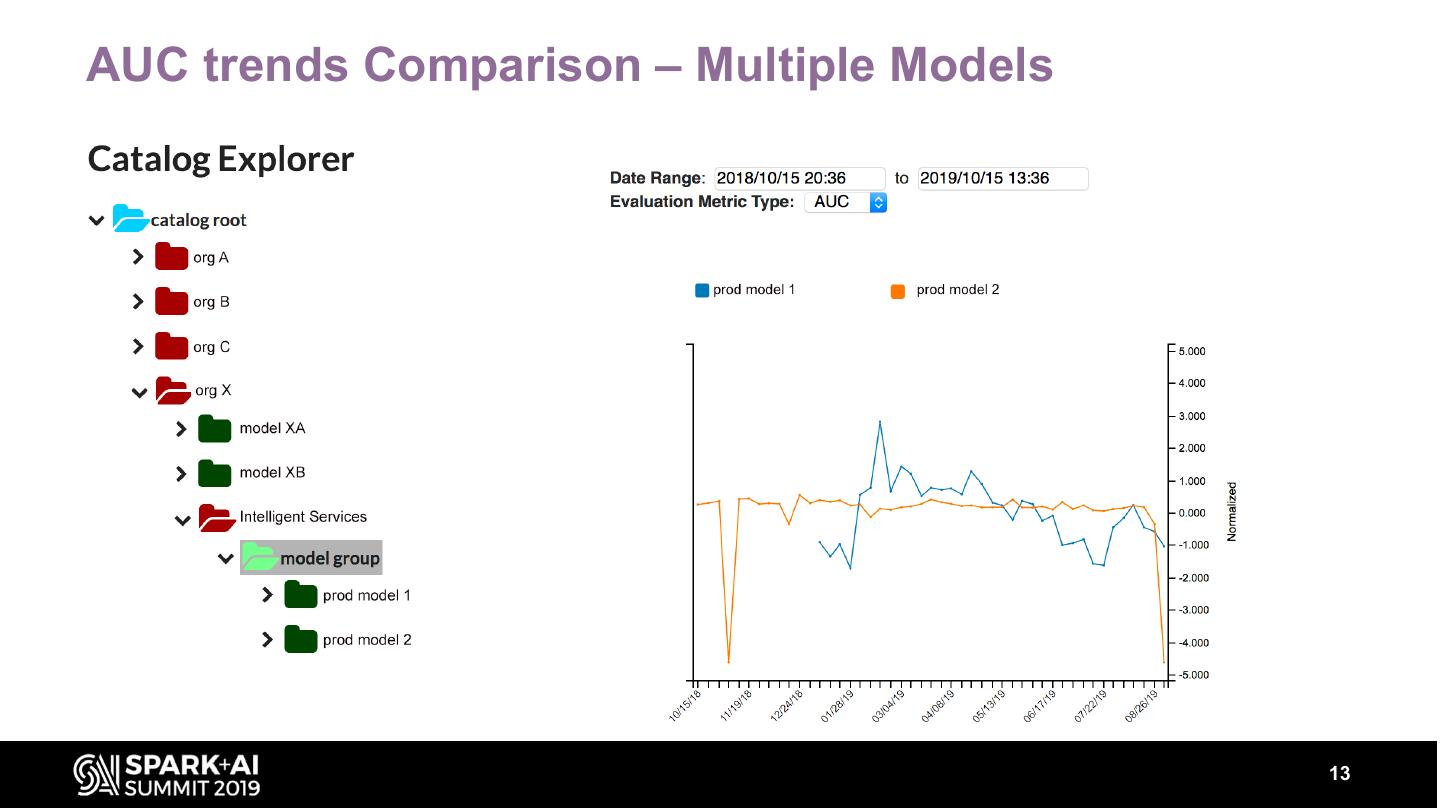
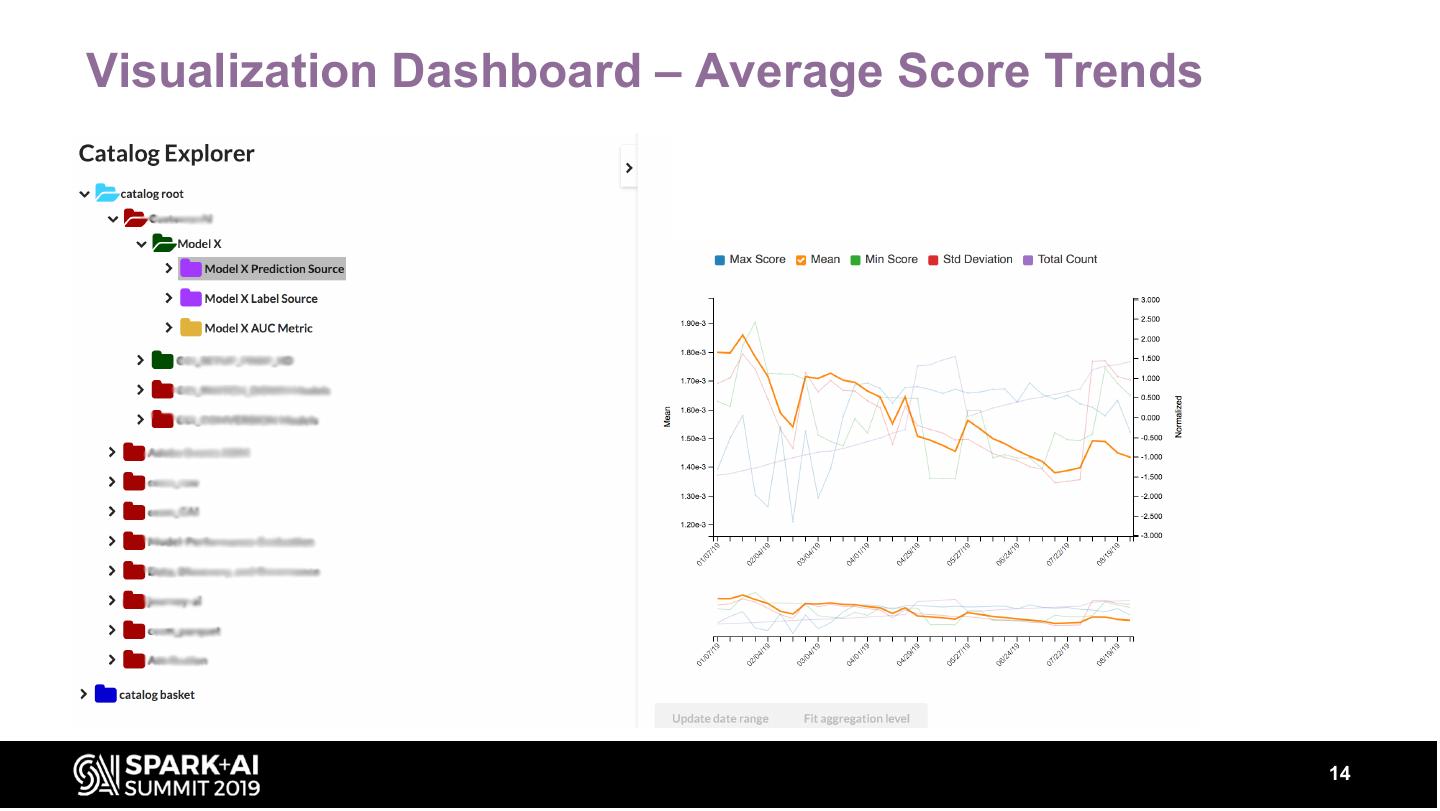
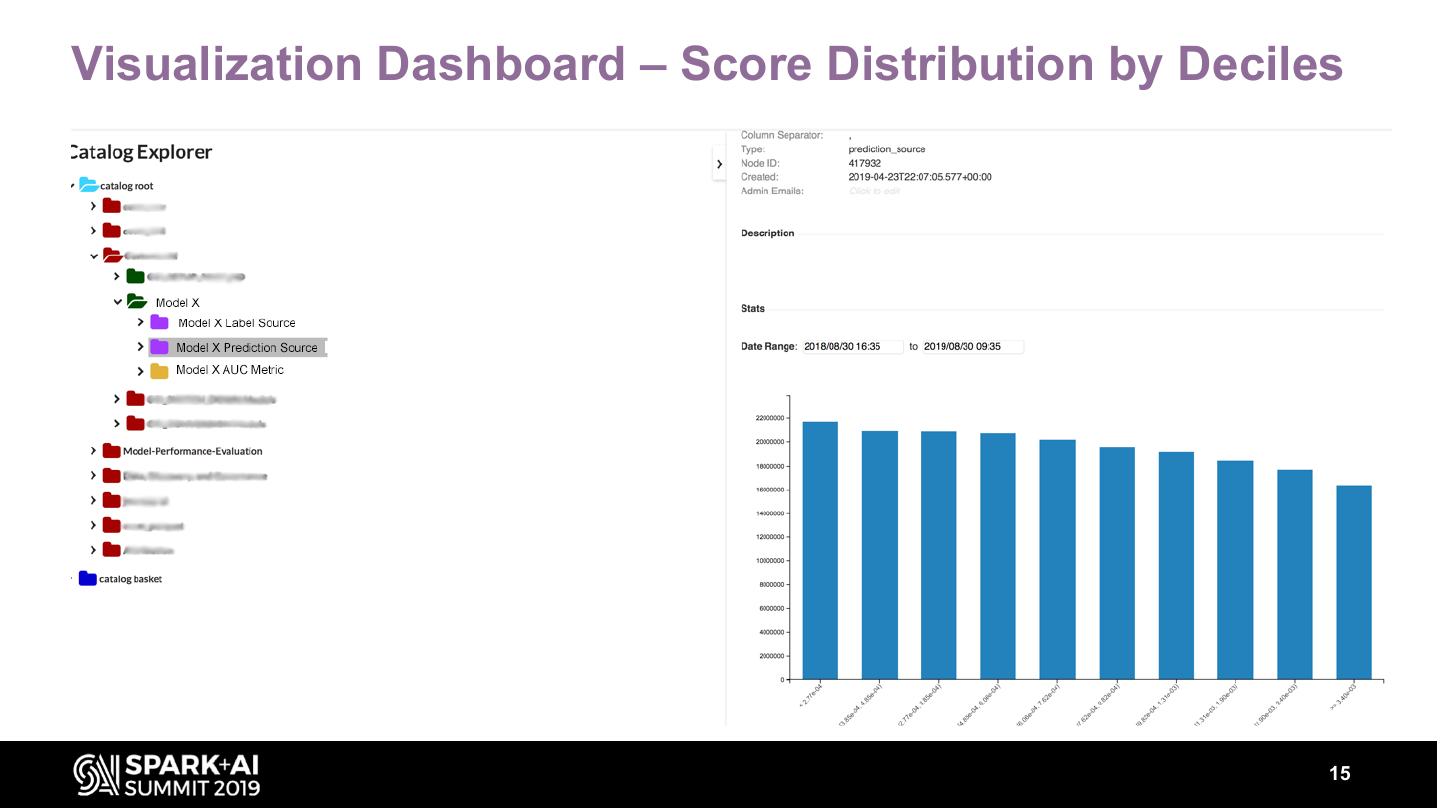
Our service provides automated, continuous evaluation of the performance of a deployed model over commonly-used metrics like the area-under-the-curve (AUC), root-mean-square-error (RMSE) etc. In addition, summary statistics about the model’s output, their distributions are also computed. The service also provides a dashboard to visualize the performance metrics, summary statistics and distributions of a model over time along with REST APIs to retrieve these metrics programmatically.
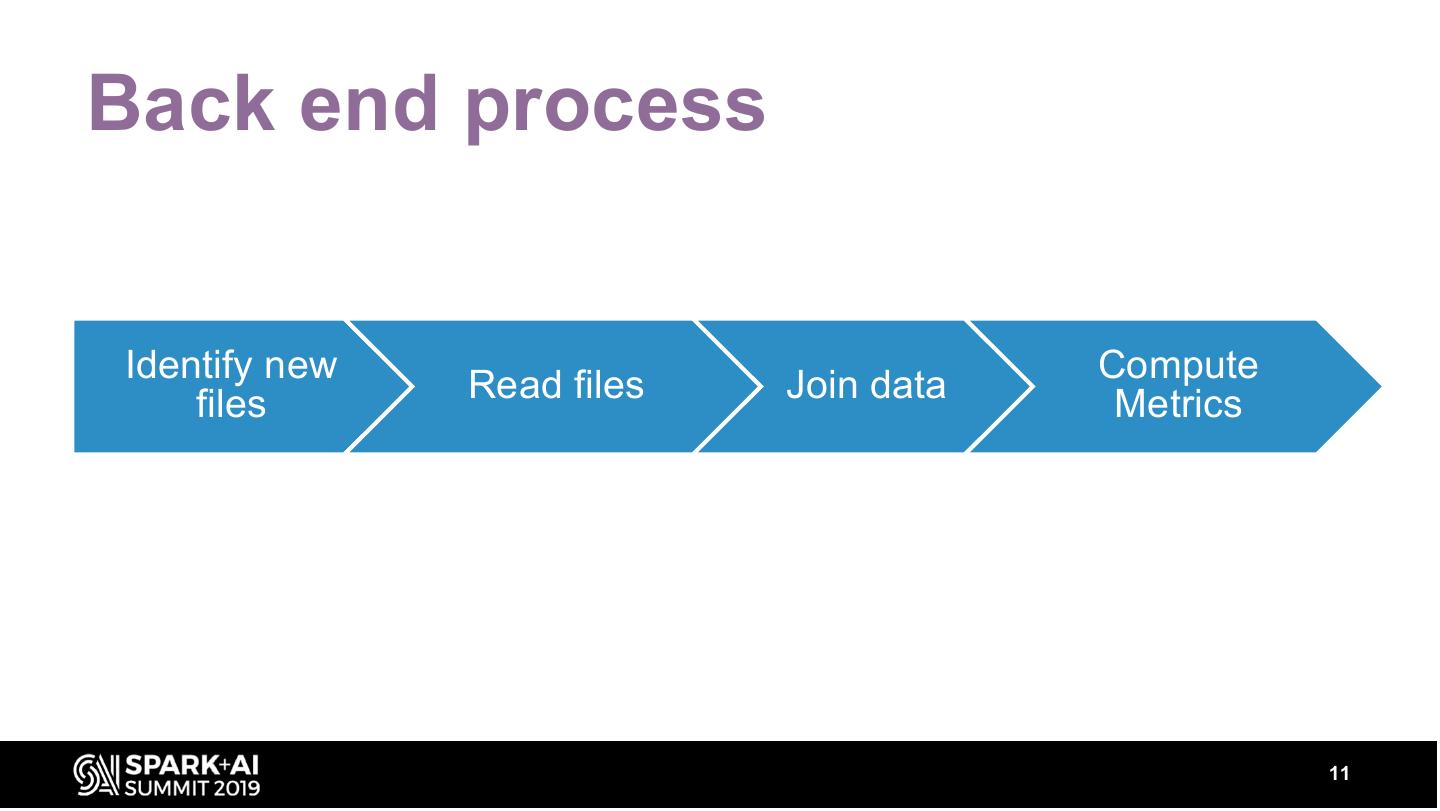
These metrics can be sliced by input features (e.g. Geography, Product type) to provide insights into model performance over different segments. The talk will describe various components that are required in building such a service and metrics of interest. Our system has a backend component built with spark on Azure Databricks. The backend can scale to analyze TBs of data to generate model evaluation metrics.
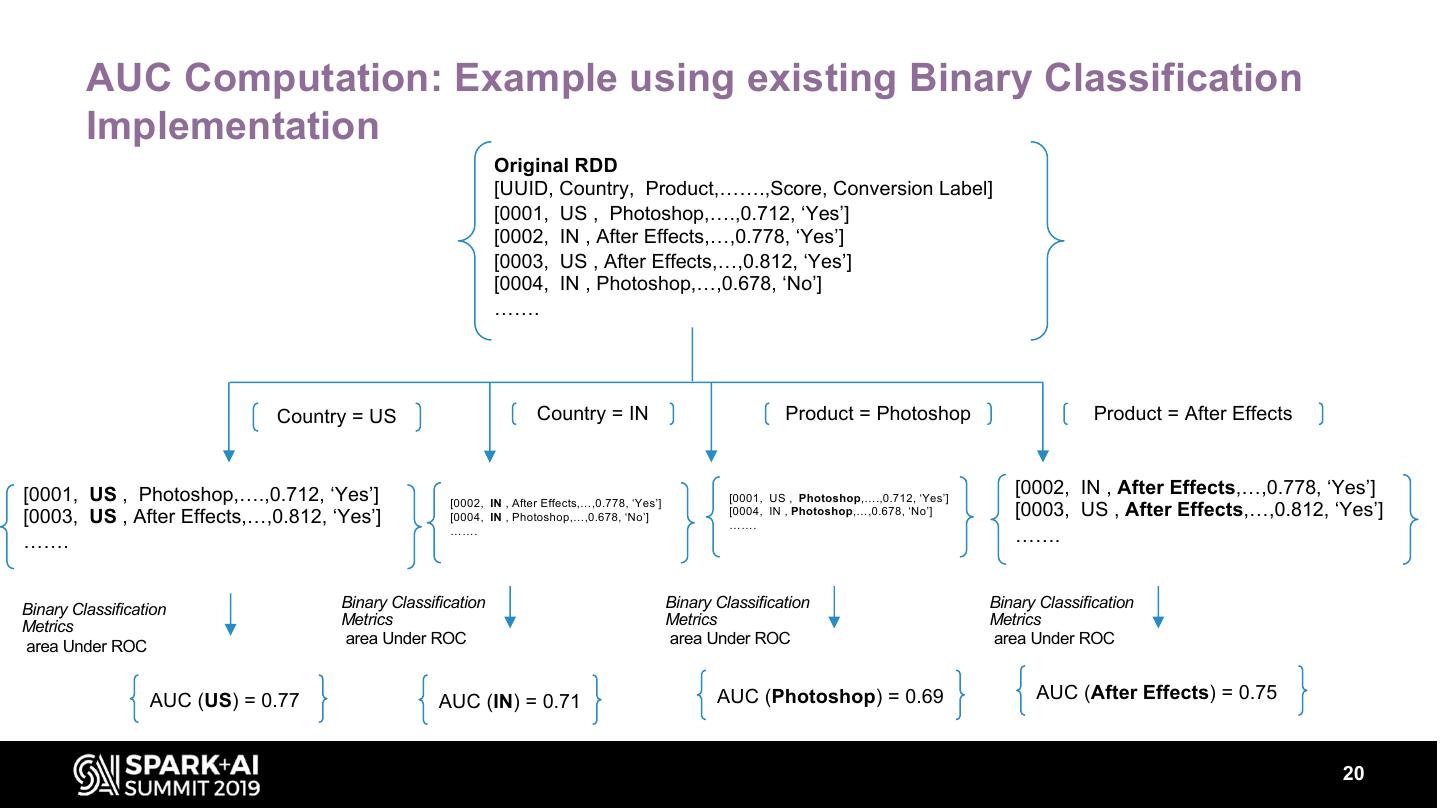
We will talk about how we modified Spark MLLib for computing AUC sliced by different dimensions and other optimizations in Spark to improve compute and performance. Our front-end and middle-tier, built with Docker and Azure Webapp provides visuals and REST APIs to retrieve the above metrics. This talk will cover various aspects of building, deploying and using the above system.
相关推荐

基于SeaTunnel快速集成SAP进入Redshift
SeaTunnel

联通数科基于Apache Dolphinscheduler构建Dataops一体化能力
DolphinScheduler社区

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

