展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Databricks Delta Lake
And Its Benefits
Nagaraj Sengodan, HCL Technologies
Nitin Raj Soundararajan, Cognizant Worldwide Limited
#UnifiedDataAnalytics #SparkAISummit
�
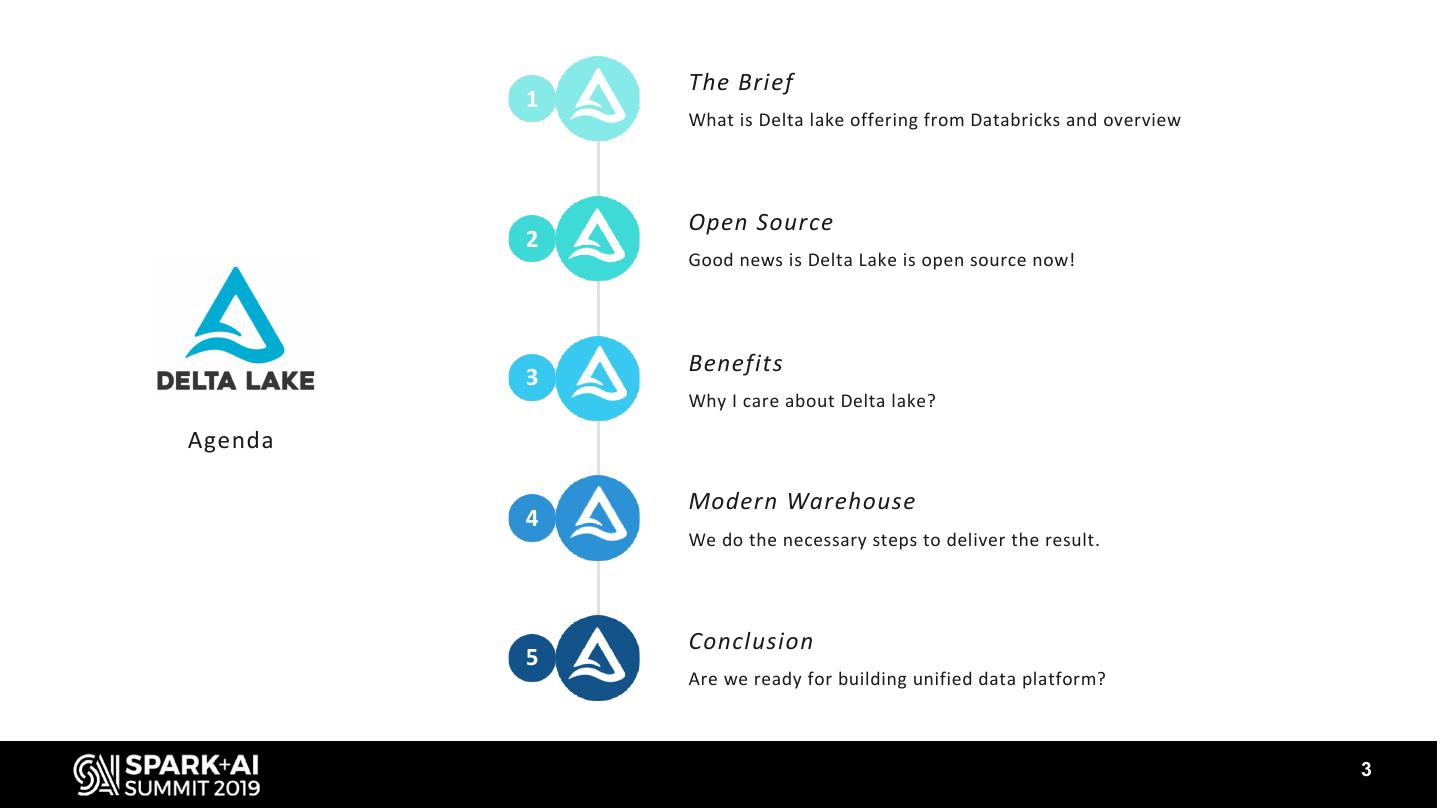
3 . The Brief
1
What is Delta lake offering from Databricks and overview
Open Source
2
Good news is Delta Lake is open source now!
Benefits
3
Why I care about Delta lake?
Agenda
Modern Warehouse
4
We do the necessary steps to deliver the result.
Conclusion
5
Are we ready for building unified data platform?
3
�
4 .Who
are
we ? NAGARAJ NITIN RAJ
SENGODAN SOUNDARARAJAN
Senior Manager – Data Senior Consultant –
and Analytics Data, AI and Analytics
HCL Technologies Cognizant Worldwide Limited
4
�
5 .Common Challenges with Data Lakes
ACID Transaction Metadata Handling
Unsafe Writes Orphan Data Schema Enforcement
Unified Batch and Stream
No Schema Evolution Time Travel Audit History
No Schema
Full DML Support
Hot path for Streaming
Data Lake getting Polluted
5
5
�
6 .Typical Databricks Architecture
DATABRICKS COLLABORATIVE
WORKSPACE
Notebooks
Jobs Models
Apis
Dashboards
Security Integration
DATA ENGINEERS DATA
SCIENTISTS
DATABRICKS RUNTIME
for Big Data for Machine Learning
Batch & Streaming
Data Lakes & Data
Warehouses
DATABRICKS CLOUD SERVICE
6
�
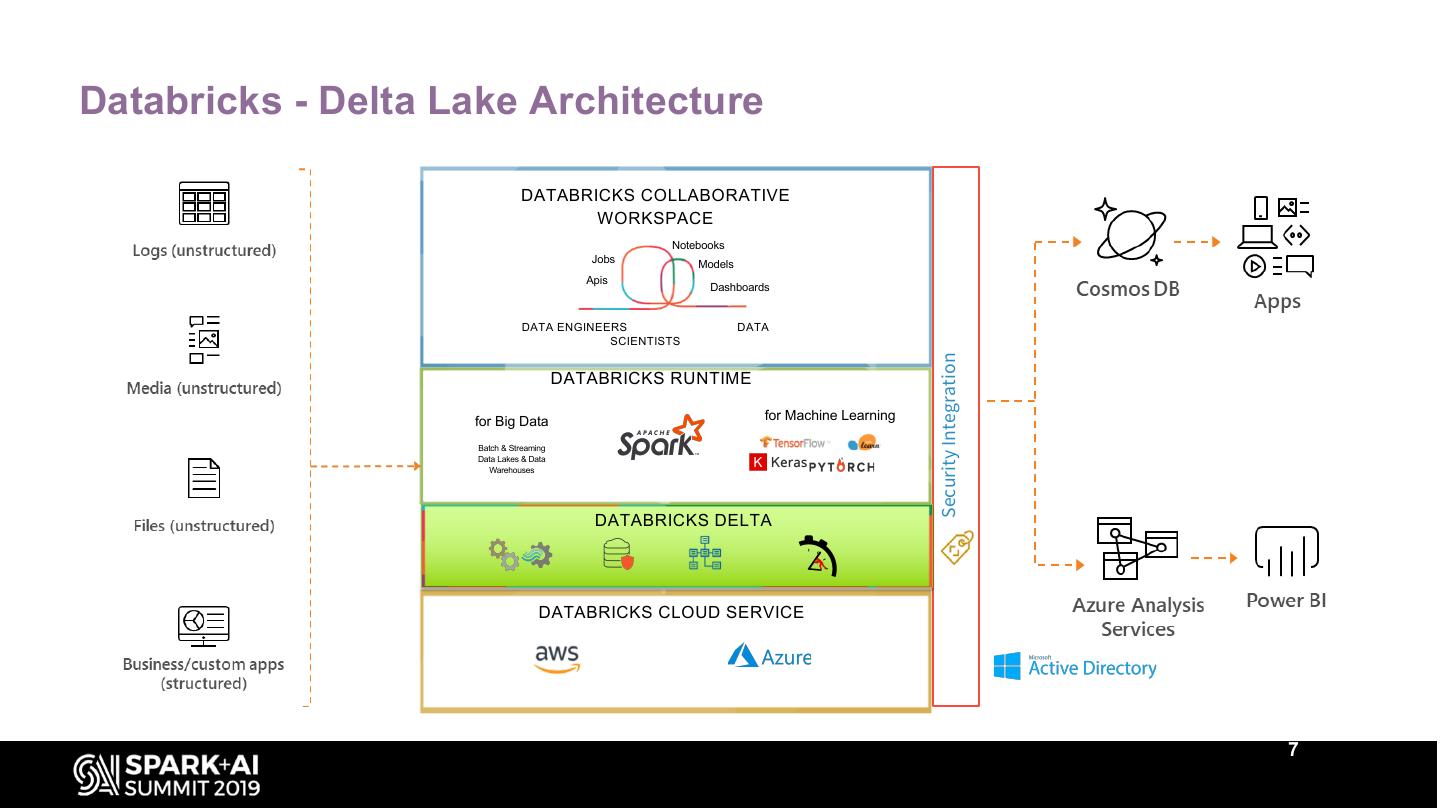
7 .Databricks - Delta Lake Architecture
DATABRICKS COLLABORATIVE
WORKSPACE
Notebooks
Jobs Models
Apis
Dashboards
DATA ENGINEERS DATA
SCIENTISTS
Security Integration
DATABRICKS RUNTIME
for Big Data for Machine Learning
Batch & Streaming
Data Lakes & Data
Warehouses
DATABRICKS DELTA
DATABRICKS CLOUD SERVICE
7
�
8 .The Brief
Delta.io – OPEN SOURCE.
APR. 2019
Announcing Delta Lake Open Source Project | Ali Ghodsi
Delta 0.2 – Cloud storage
JUN. 2019
Support for cloud storage (Amazon S3, Azure Blob Storage) and Improved Concurrency (Append-only
writes ensuring serializability)
Delta 0.3 – Scala/Java API
AUG. 2019
Scala Java APIs and DML Commands, Query Commit History and vacuuming old files
Delta 0.4 – Python APIs and Convert to Delta
OCT. 2019
Python APIs for DML and utility operations, Convert-to-Delta, SQL for Utility Operations
8
�
10 .Benefits
ACID transactions on Spark
Scalable metadata handling
Unified Batch and Streaming Source
Schema enforcement
Time travel
Audit History
Full DML Support
10
�
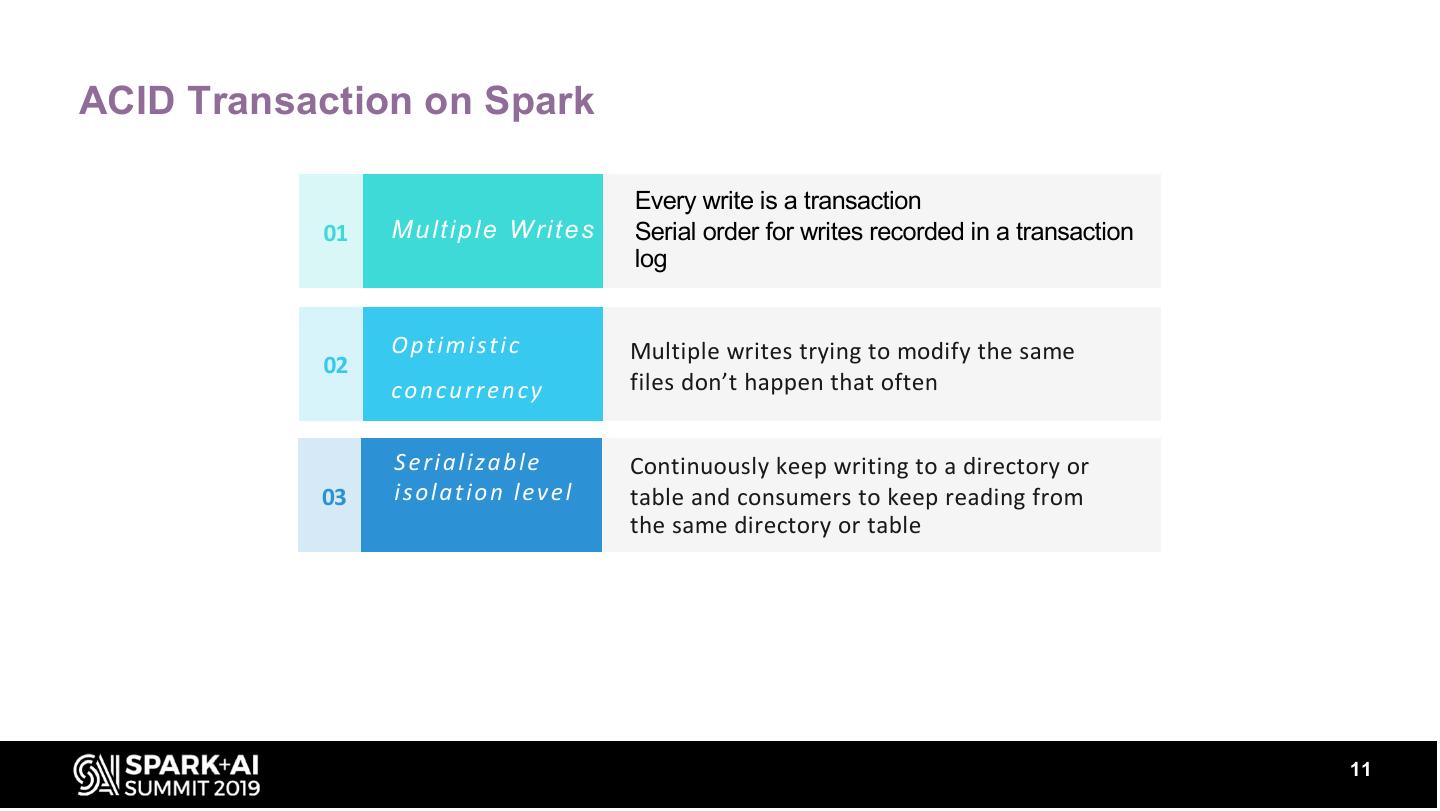
11 .ACID Transaction on Spark
T h e B ri e f
Every write is a transaction
01 M u lt ip le W rit e s Serial order for writes recorded in a transaction
log
O p t im is t ic Multiple writes trying to modify the same
02
c o n c u rre n c y files don’t happen that often
S e ria liz a b le Continuously keep writing to a directory or
03 is o la t io n le v e l table and consumers to keep reading from
the same directory or table
11
�
12 .Scalable Metadata Handling
M e t a d a t a in
Metadata information of a table or directory in the
01 T ra n s a c t io n
transaction log instead of the metastore
Log
E ffi c i e n t D a t a Delta Lake can list files in large directories in
02
Read constant time
12
�
13 .Unified Batch and Streaming Sink
Efficient streaming sink with Apache Spark’s
01 S t re a m in g L in k
structured streaming
with ACID transactions and scalable metadata
Near Real handling, the efficient streaming sink now
02 enables lot of near real-time analytics use
Time
cases without having to maintain a
A n a ly t ic s
complicated streaming and batch pipeline
13
�
14 .Schema enforcement
A u t o m a t ic
Automatically validates the DataFrame’s schema
01 Schema
with schema of the table
V a lid a t io n
Columns that are present in the table but not
in the DataFrame are set to null
C o lu m n
02 V a lid a t io n Exception is thrown when when extra column
present in the DataFrame but not in Table
S e ria liz a b le Delta Lake has DDL to explicitly add new
is o la t io n le v e l columns
03
Ability to update the schema automatically
14
�
15 .Time Travel and Data Versioning
Allows users to read a previous snapshot of the
01 Snapshots
table or directory
Newer version of the files are created when
02 V e rs io n in g the files are modified during writes and older
versions are preserved
Provide a timestamp or a version number to
Apache Spark’s read APIs to read the older
version of the table or directory
Timestamp and
Transaction Delta Lake constructs the full snapshot as of
03 that timestamp or version based on the
Log
information in the transaction log
User can reproduce experiments and reports
and also can revert a table to its older
versions
15
�
16 .Record Update and Deletion (Coming Soon)
M e rg e Will support Merge, Update and Delete
U p d a te Easily upsert and delete records in data lakes
01
simplify their change data capture and GDPR
D e le te
use cases
F ile - le v e l More efficient than reading and overwriting
02 entire partitions or tables
g ra n u la rit y
16
�
17 .Data Expectations (Coming Soon)
API to set data Will support an API to set expectations on tables
01 e x p e c t a t io n s or directories
S e v e rit y t o Engineers will be able to specify a boolean
02 h a n d le condition and tune the severity to handle
expectations data expectations
17
�
18 .Modern Data warehouse
Analytics
Machine Learning
Ingestion Tables Feature/Agg Data Store
Refined Tables
Existing Data Lake
Azure Data Lake Storage
18
�
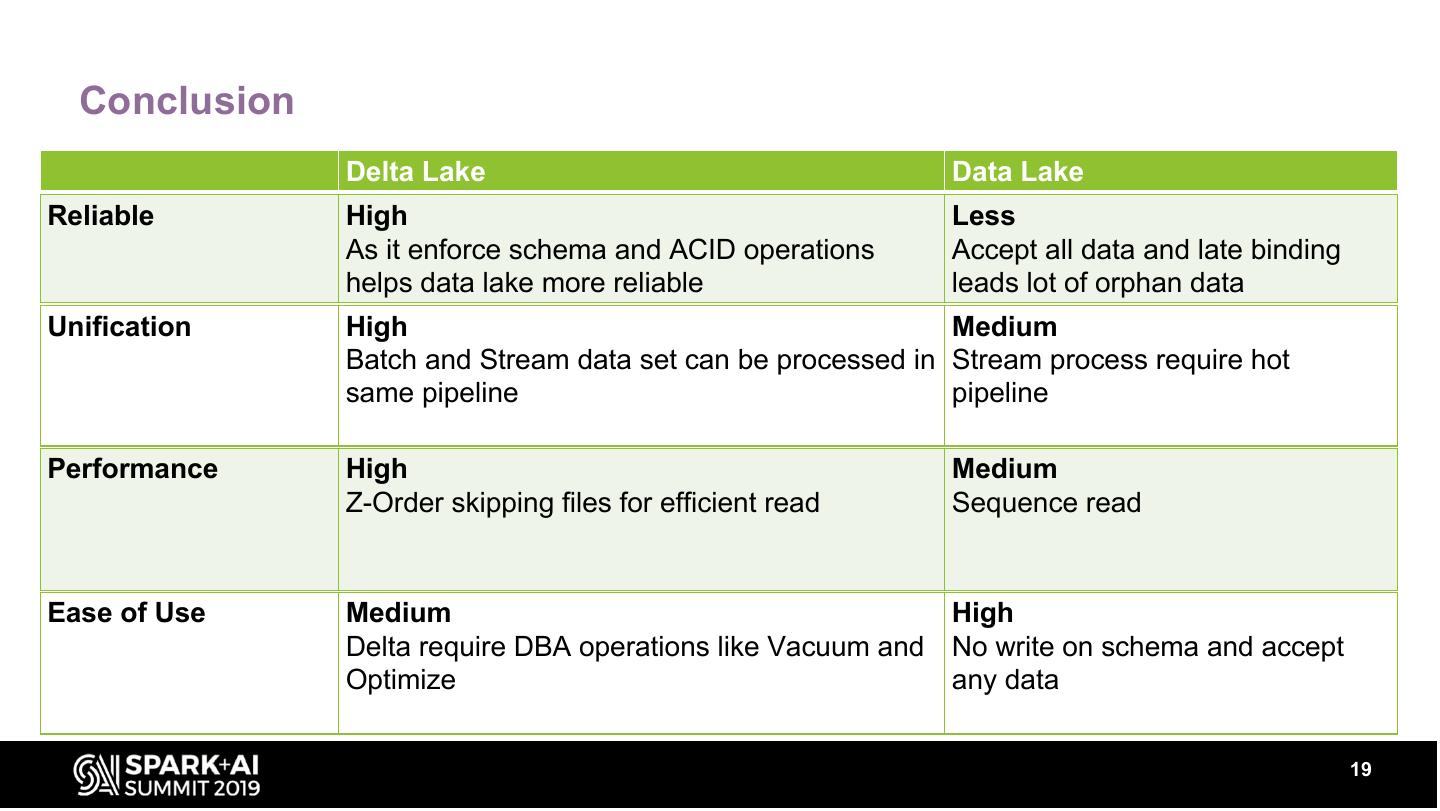
19 . Conclusion
Delta Lake Data Lake
Reliable High Less
As it enforce schema and ACID operations Accept all data and late binding
helps data lake more reliable leads lot of orphan data
Unification High Medium
Batch and Stream data set can be processed in Stream process require hot
same pipeline pipeline
Performance High Medium
Z-Order skipping files for efficient read Sequence read
Ease of Use Medium High
Delta require DBA operations like Vacuum and No write on schema and accept
Optimize any data
19
�
20 . 20
Like to know more?
https://github.com/KRSNagaraj/SparkSummit2019
https://www.linkedin.com/in/NagarajSengodan
https://www.linkedin.com/in/NitinRajS/
�
21 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�