













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/DetectingFinancialFraudatScalewithMachineLearning64541?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

Detecting Financial Fraud at Scale with Machine Learning
Detecting Financial Fraud at Scale with Machine Learning
Detecting Financial Fraud at Scale with Machine Learning
点赞
6
收藏
2
下载 0
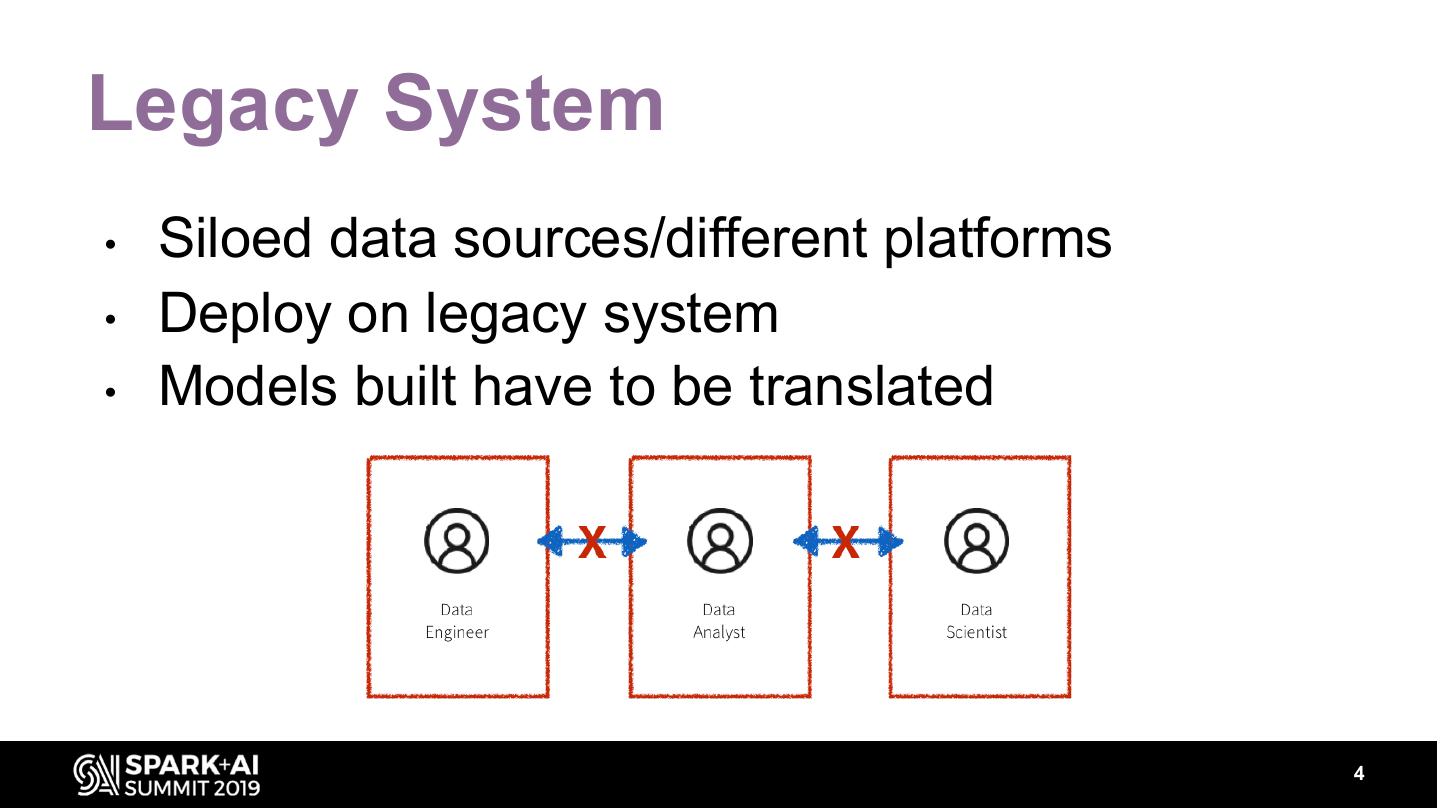
Detecting fraudulent patterns at scale is a challenge given the massive amounts of data to sift through, the complexity of the constantly evolving techniques, and the very small number of actual examples of fraudulent behavior. In finance, added security concerns and the importance of explaining how fraudulent behavior was identified further increases the difficulty of the task. Legacy systems rely on rule-based detection that is difficult to implement and run at scale. The resulting code is very complex and brittle, making it difficult to update to keep up with new threats.
In this talk, we will go over how to convert a rule based financial fraud detection program to use machine learning on Spark as part of a scalable, modular solution. We will examine how to identify appropriate features and labels and how to create a feedback loop that will allow the model to evolve and improve overtime. We will also look at how MLflow may be leveraged throughout this effort for experiment tracking and model deployment.
Specifically, we will discuss:
-How to create a fraud-detection data pipeline
-How to leverage a framework for building features from large datasets
-How to create modular code to re-use and maintain new machine learning models
-How to choose appropriate models and algorithms for a given fraud-detection problem

