






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/DriverLocationIntelligenceatScaleusingApacheSparkDeltaLakeandMLflowonDatabricks?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

Driver Location Intelligence at Scale using Apache Spark, Delta Lake, and MLflow on Databricks
Driver Location Intelligence at Scale using Apache Spark, Delta Lake, and MLflow on Databricks
Driver Location Intelligence at Scale using Apache Spark, Delta Lake, and MLflow on Databricks
点赞
10
收藏
4
下载 0
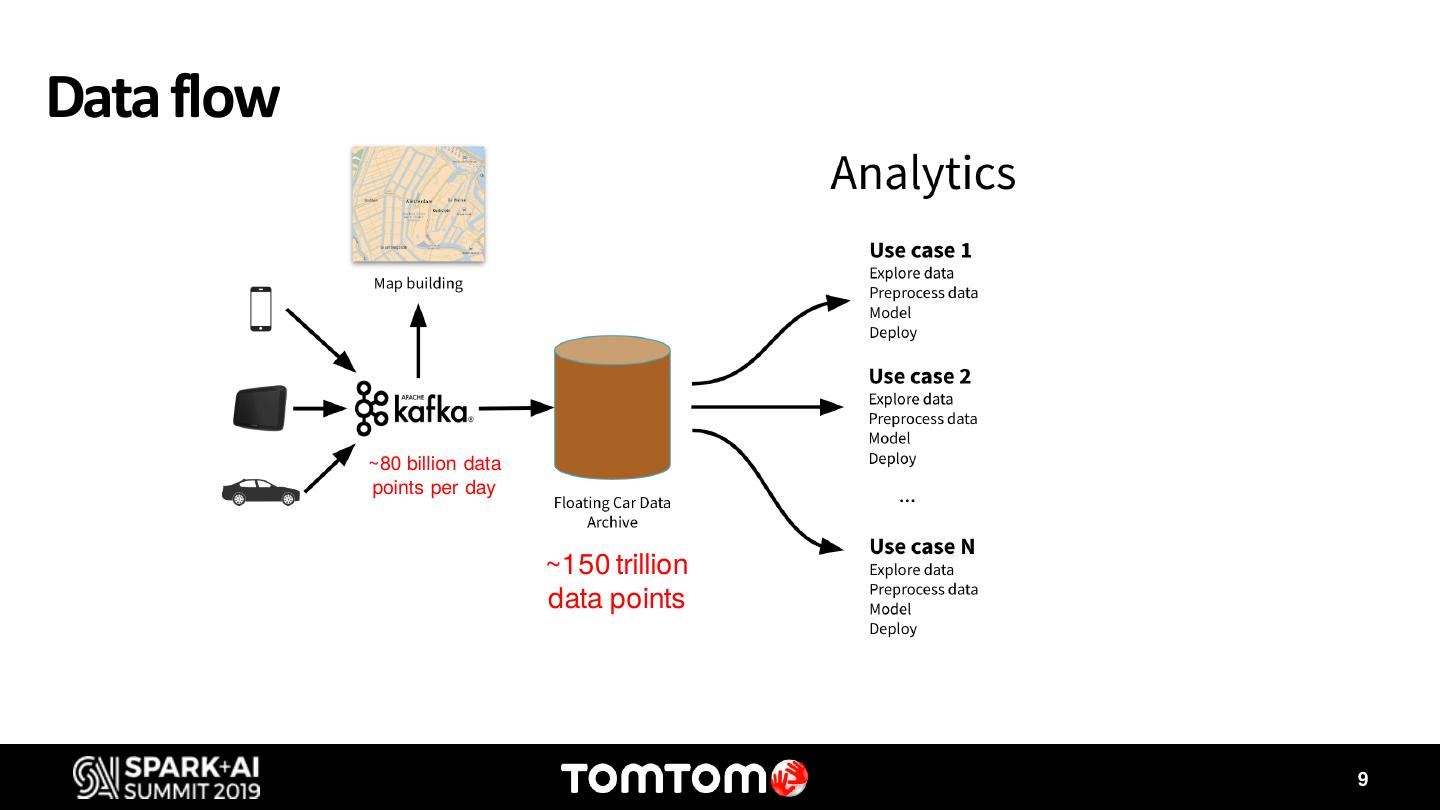
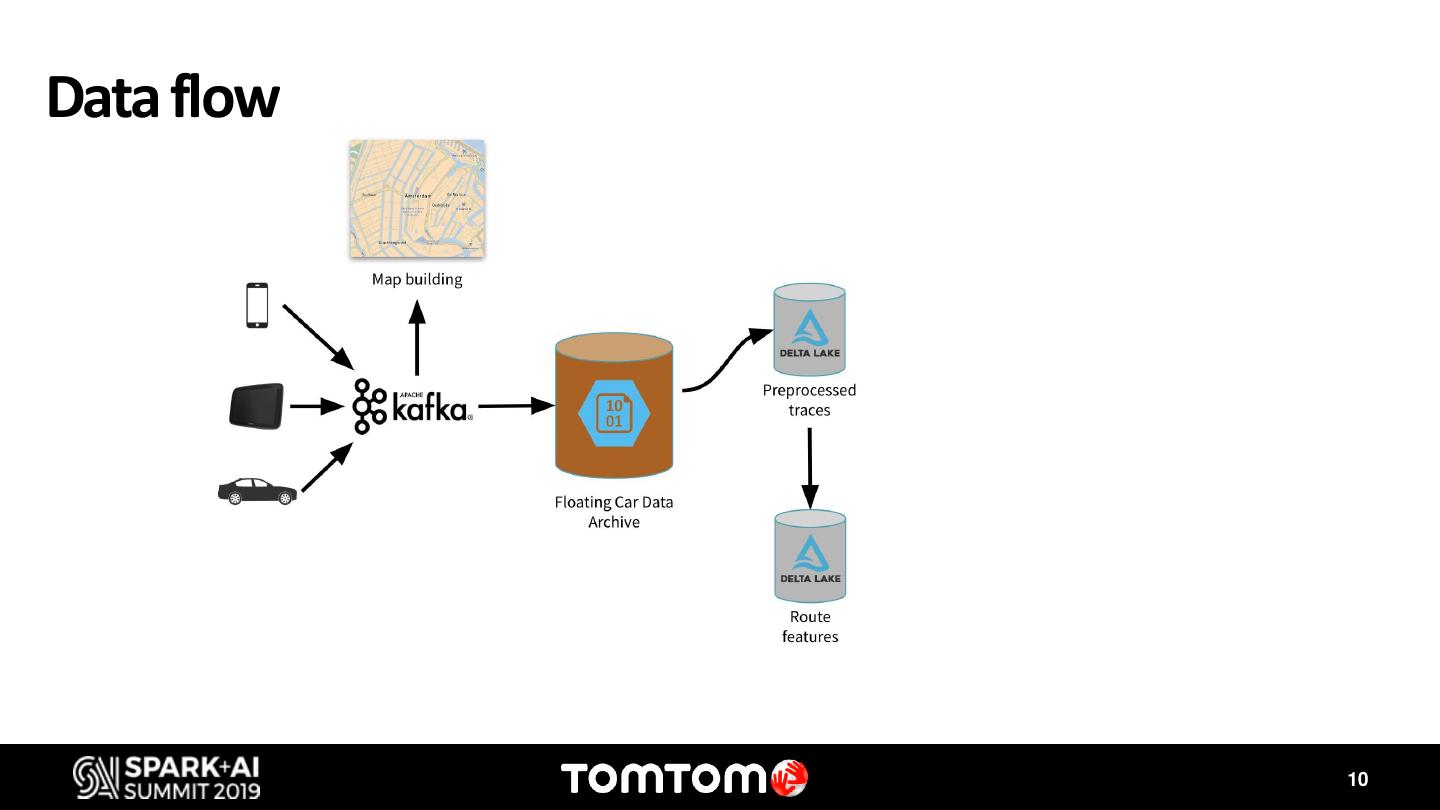
TomTom has the mission of creating a world free of congestion and better driving experience. In order to do that, we need to understand driving behavoiur from end users, at the same time that we optimize the operational costs of our services. However, due to the large scale of our probe data from vehicles providing insights and performing advanced analytics can can be quite challenging.
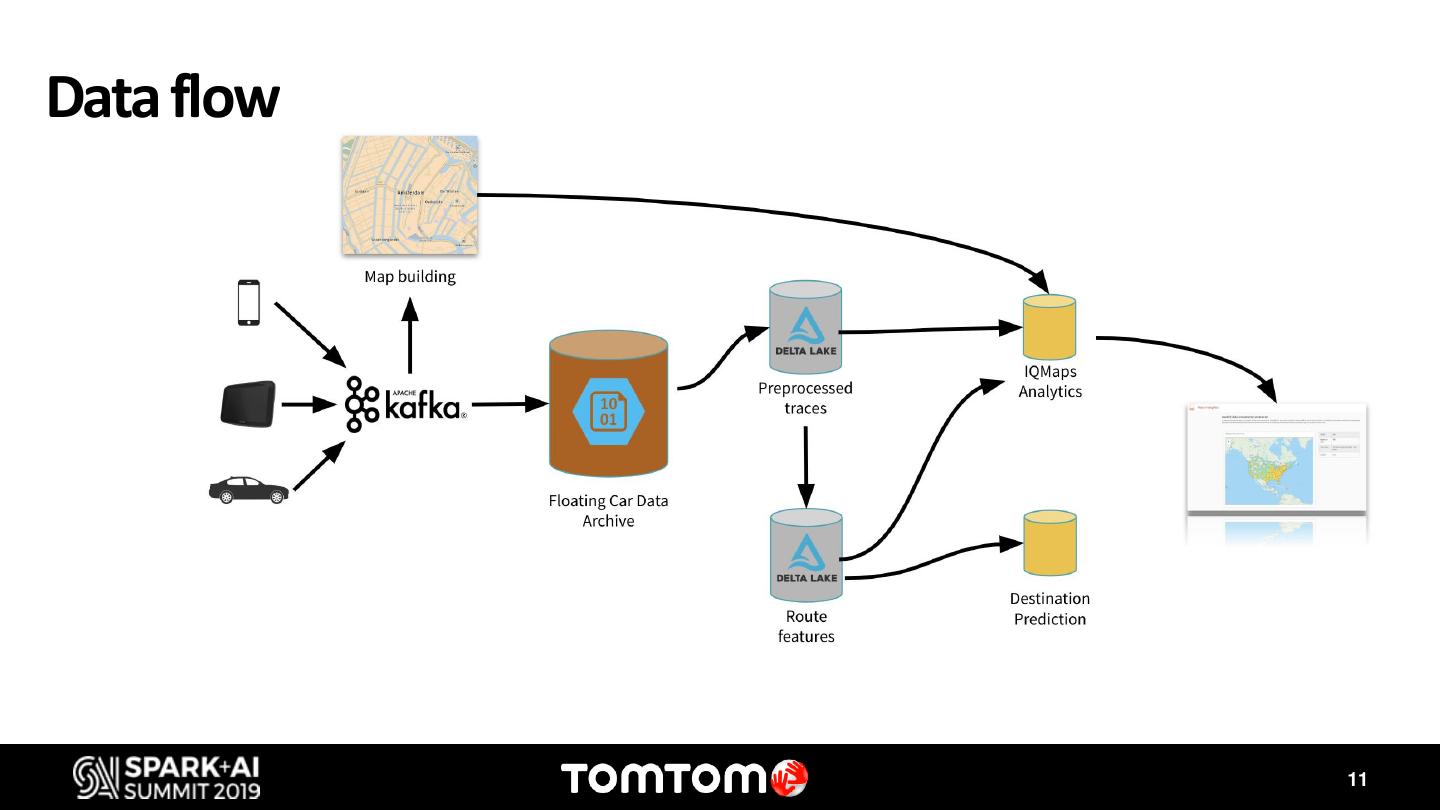
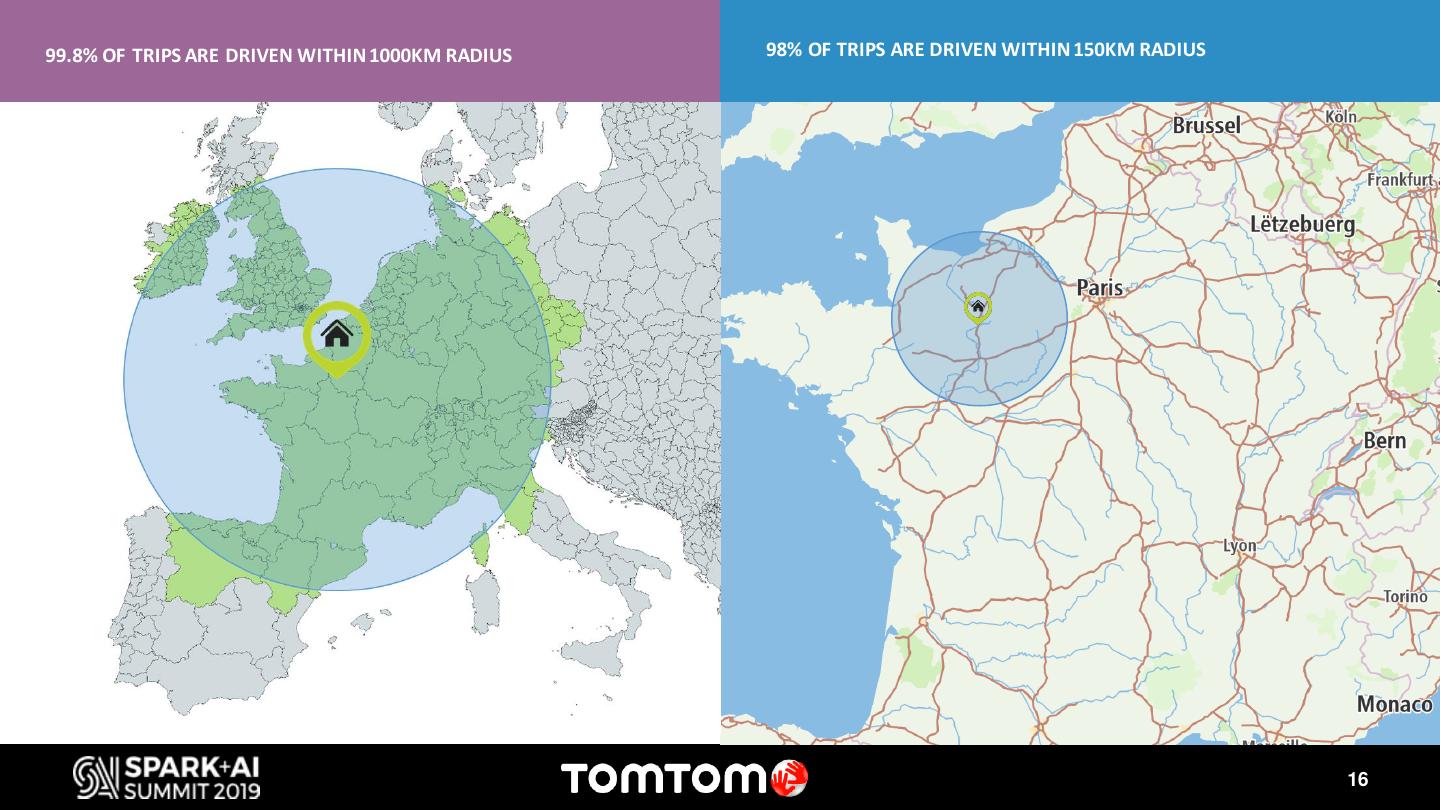
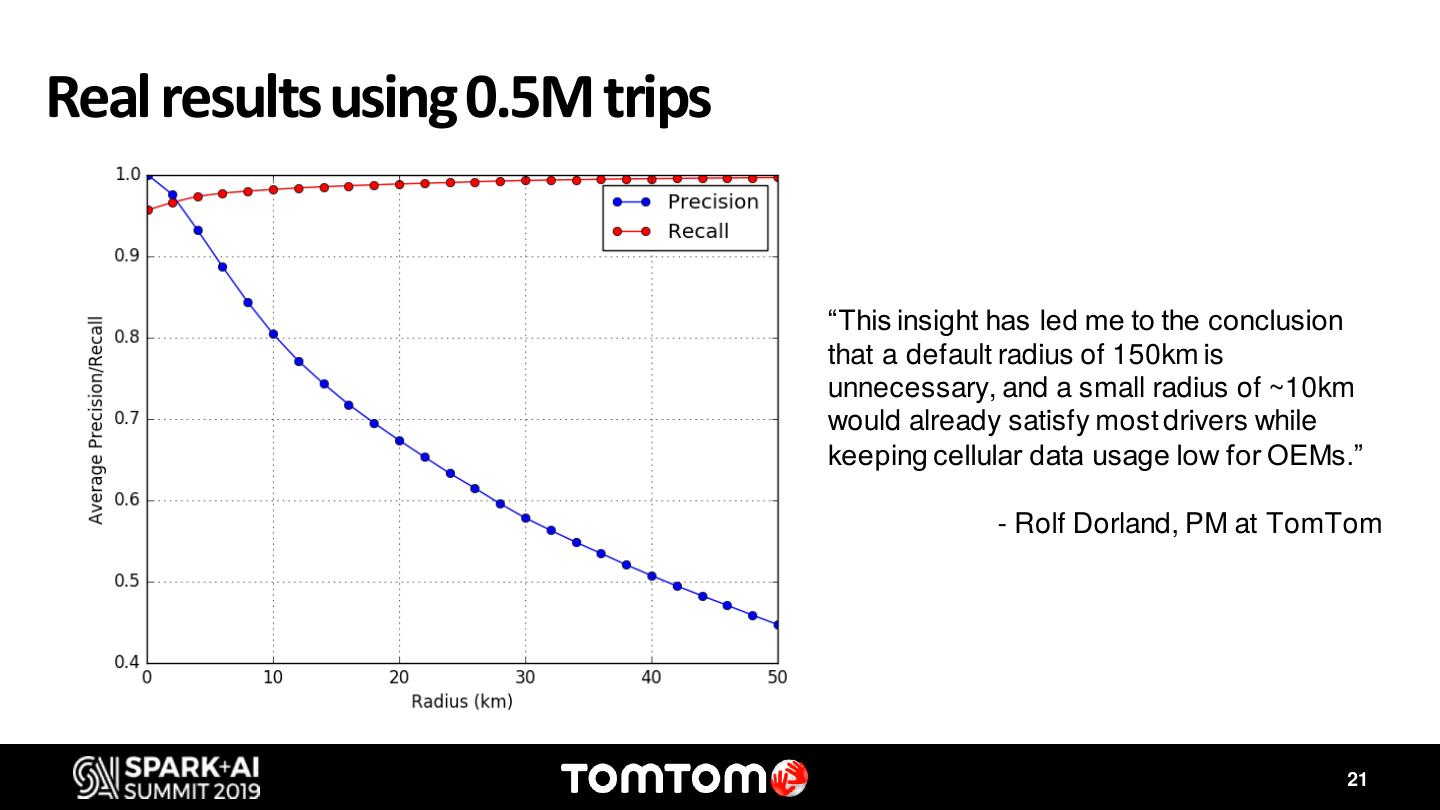
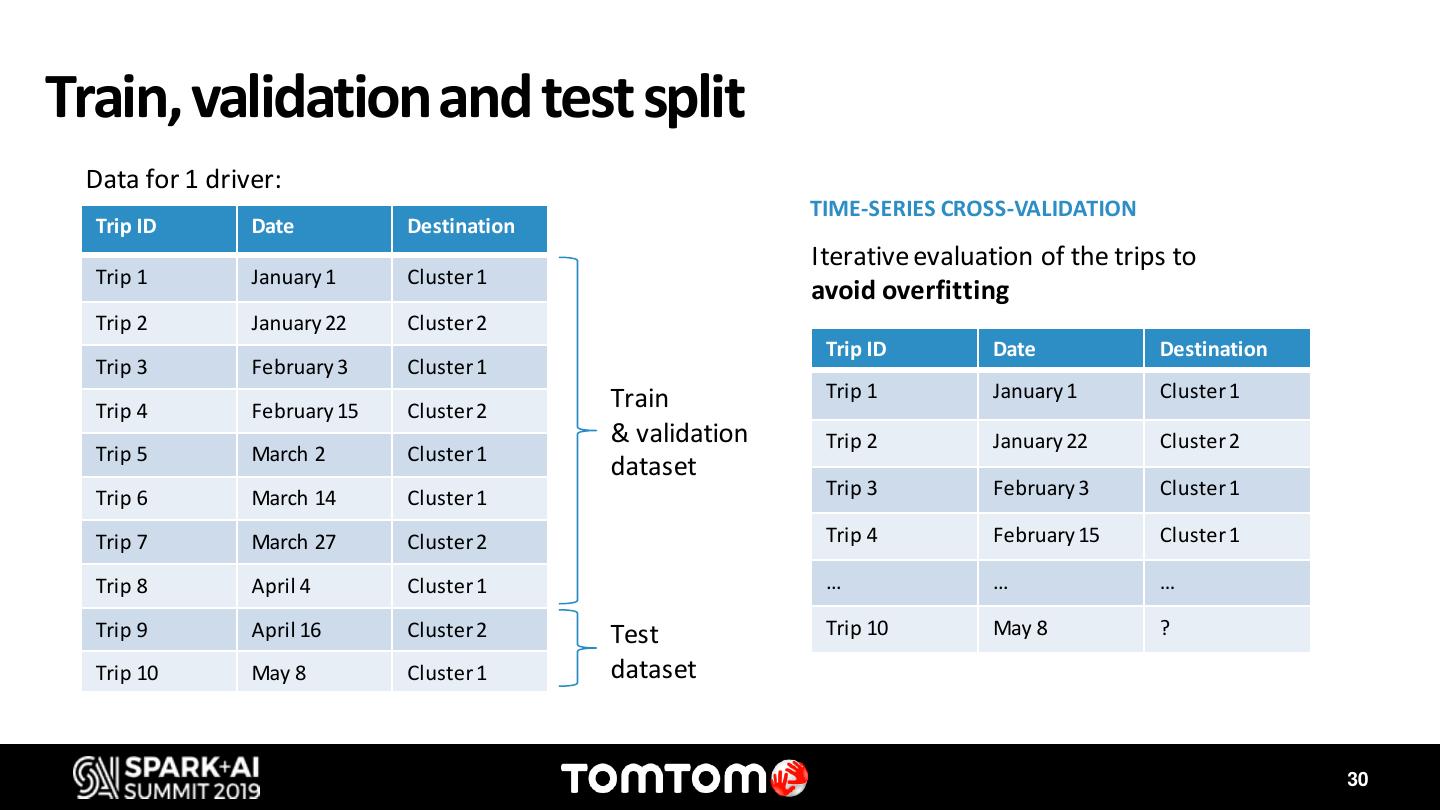
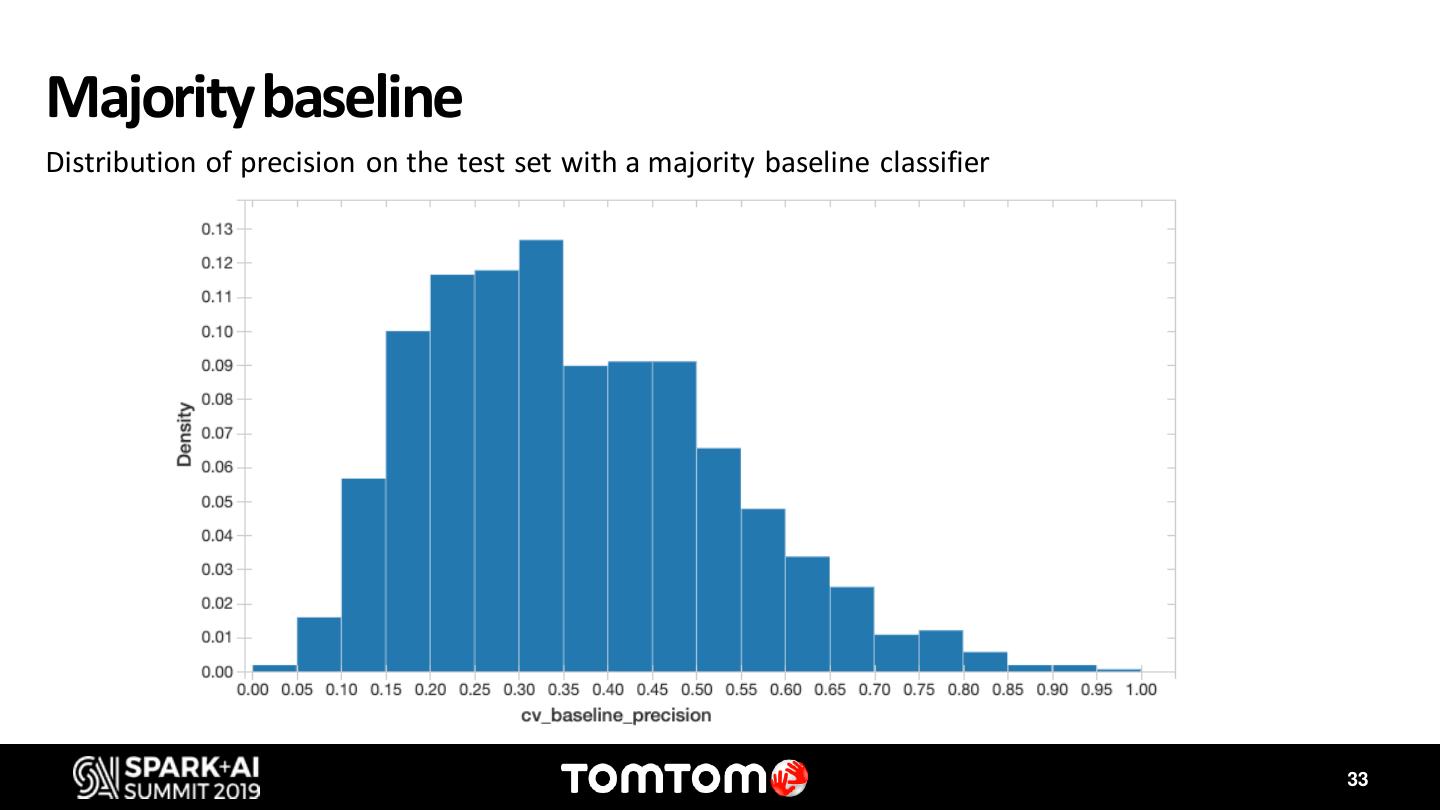
During this discussion I will showcase two use cases where Databricks, Delta Lake and MLflow has enabled us to accelerate innovation. The first one is the IQMaps usecase. IQMaps is a system designed specifically for in-dash systems – taking the same up-to-date user experience you expect from navigation apps and bringing it to reliable, in-car navigation. IQ Maps learn the drivers’ driving patterns and updates the map regions that are most relevant to the user, using Wi-Fi or 4G. However, optimizing the data network consumption, which can have a high cost, while keeping the best driving experience, by having the map updated, requires complex simulations using millions of locations traces from vehicles. Apache Spark has been our key instrument to find the best balance to this trade off. The second use case is Destination Prediction. For many years, we have offered a personalized feature on our navigation products that predicts with high accuracy the driver’s next destination. Nonetheless, with the exponential increase and availability of data, and the access to more sophisticated Machine Learning models, we have revisited this feature to take it to the next level. Both us ecases take advantage of the latest frameworks and tools available on Databricks. With MLflow and Delta we have been able to find the best models that predict the destination for each individual driver, and to track each one of the KPIs.
相关推荐

基于SeaTunnel快速集成SAP进入Redshift
SeaTunnel

联通数科基于Apache Dolphinscheduler构建Dataops一体化能力
DolphinScheduler社区

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

