展开查看详情
1 . Dynamic Partition Pruning
in Apache Spark
Bogdan Ghit and Juliusz Sompolski
Spark + AI Summit, Amsterdam
1
�
2 . About Us
BI Experience team in the
Databricks Amsterdam European Development Centre
● Working on improving the experience and performance of
Business Intelligence / SQL analytics workloads using
Bogdan Ghit Databricks
○ JDBC / ODBC connectivity to Databricks clusters
○ Integrations with BI tools such as Tableau
○ But also: core performance improvements in
Apache Spark for common SQL analytics query
Juliusz Sompolski patterns
2
�
3 .How to Make a Query 100x Faster?
TPCDS Q98 on 10 TB
�
4 .Static Partition Pruning
SELECT * FROM Sales WHERE day_of_week = ‘Mon’
Filter Scan Scan
Scan Filter Filter
Basic data-flow Filter Push-down
Partition files with
multi-columnar data
�
5 .Table Denormalization
SELECT * FROM Sales JOIN Date
WHERE Date.day_of_week = ‘Mon’
Scan
Join
Filter
Join day_of_week = ‘mon’
Scan Scan
Sales Date
Scan Scan
Filter Sales Date
day_of_week = ‘mon’
Static pruning not possible
Simple workaround
�
6 .This Talk
SELECT * FROM Sales JOIN Date
WHERE Date.day_of_week = ‘Mon’
Join
Scan Scan
Sales Countries
Filter
day_of_week = ‘mon’
Dynamic pruning
�
7 .Spark In a Nutshell
Query Logical Plan Physical Plan
Optimization Selection
APIs Rule-based Stats-based RDD batches
transformations cost model
Cluster slots
�
8 . Optimization Opportunities
Join on partition id
Query Shape
Filter DIM
Scan FACT TABLE Scan DIM TABLE
Data Layout
Partition files with Non-partitioned dataset
multi-columnar data
�
9 .A Simple Approach
Join on partition id
Scan FACT TABLE
Work duplication may be expensive
Filter DIM Filter DIM
Scan DIM TABLE Scan DIM TABLE Heuristics based on inaccurate stats
Non-partitioned dataset
Partition files with
multi-columnar data
�
10 . Broadcast Hash Join
Broadcast Hash Join
Execute the join
locally without
a shuffle
BroadcastExchange
FileScan FileScan with Dim Filter Execute the build side
of the join
Place the result in a
Broadcast the build broadcast variable
side results
Non-partitioned dataset
�
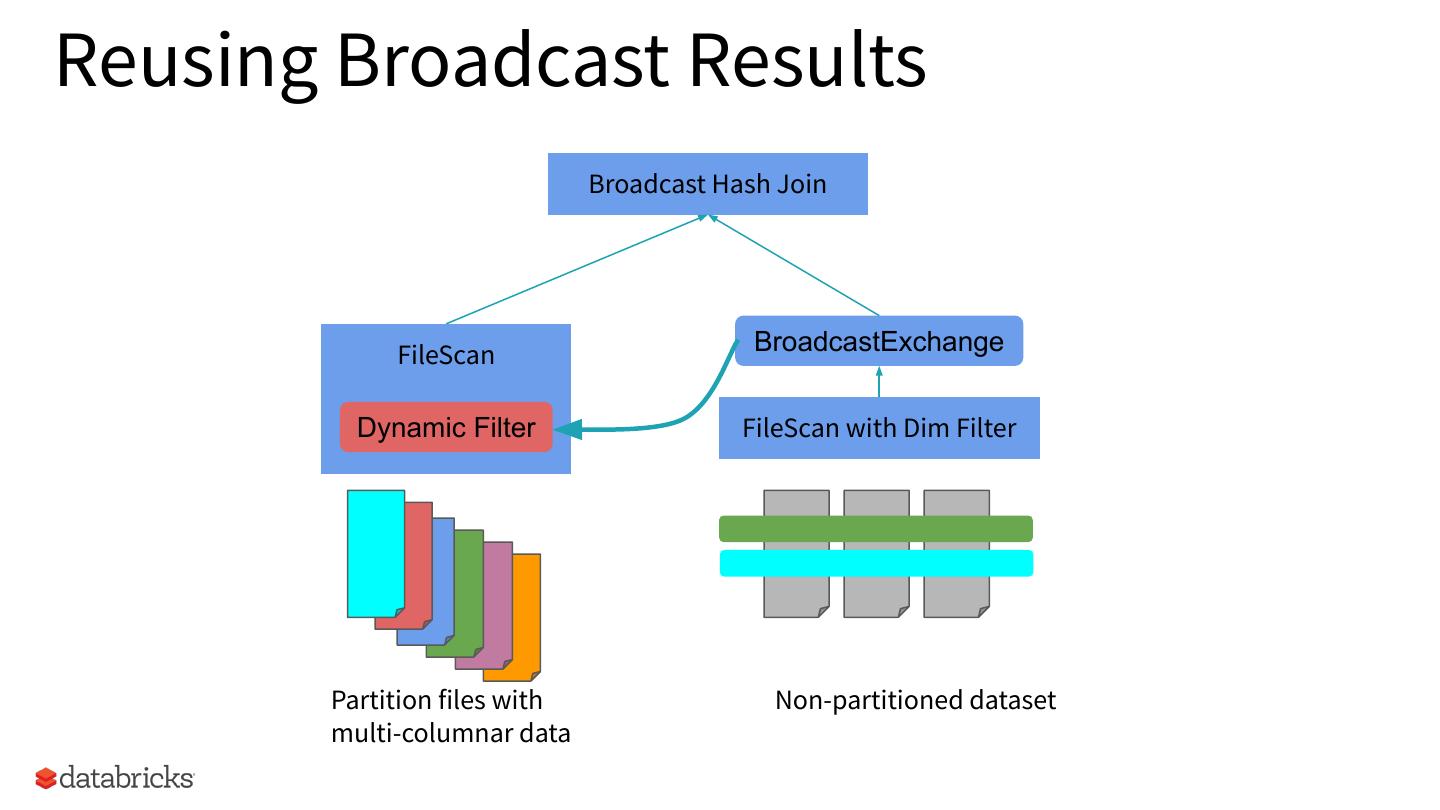
11 .Reusing Broadcast Results
Broadcast Hash Join
FileScan BroadcastExchange
Dynamic Filter FileScan with Dim Filter
Partition files with Non-partitioned dataset
multi-columnar data
�
12 .Experimental Setup
Workload Selection
- TPC-DS scale factors 1-10 TB
Cluster Configuration
- 10 i3.xlarge machines
Data-Processing Framework
- Apache Spark 3.0
�
13 .TPCDS 1 TB
60 / 102 queries speedup between 2 and 18
�
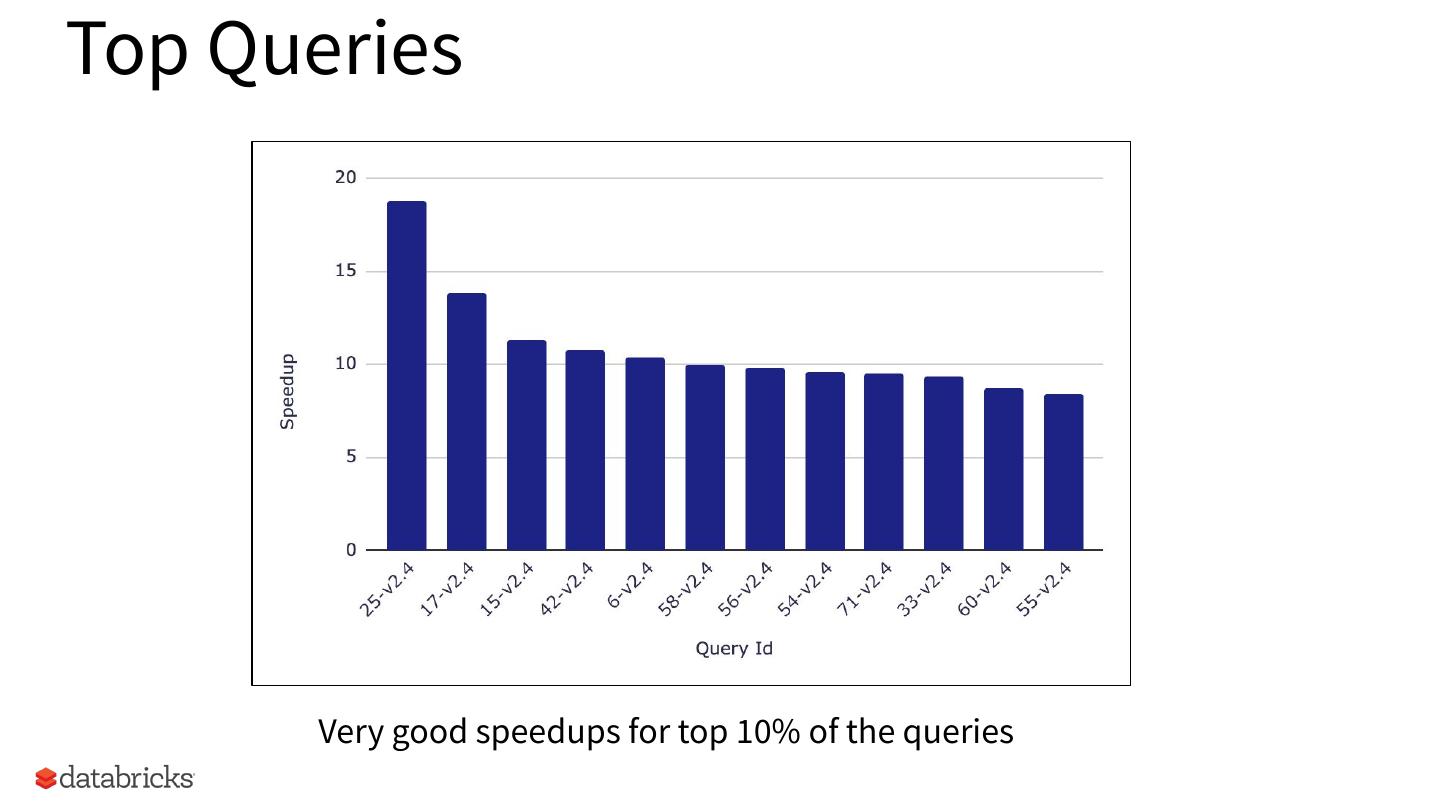
14 .Top Queries
Very good speedups for top 10% of the queries
�
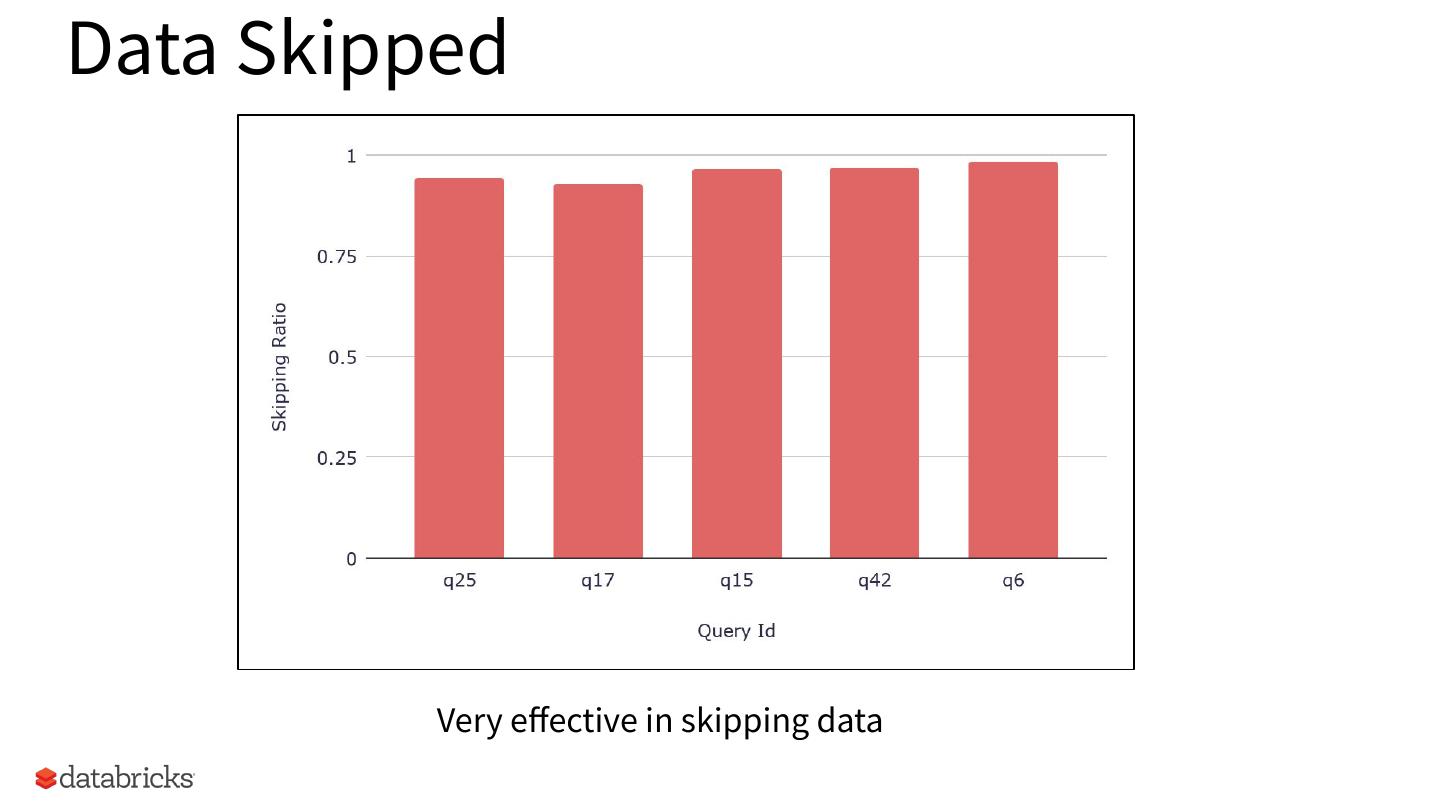
15 .Data Skipped
Very effective in skipping data
�
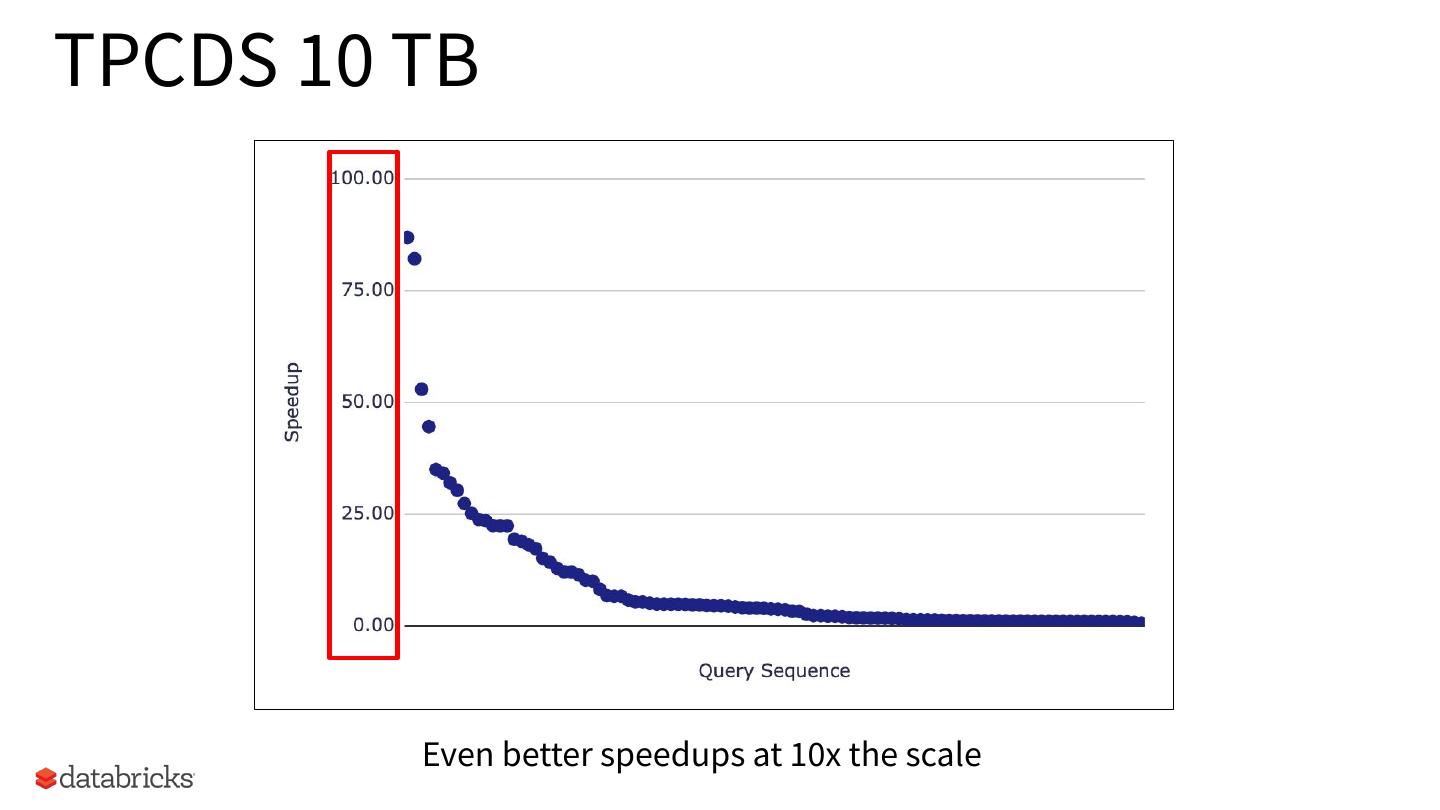
16 .TPCDS 10 TB
Even better speedups at 10x the scale
�
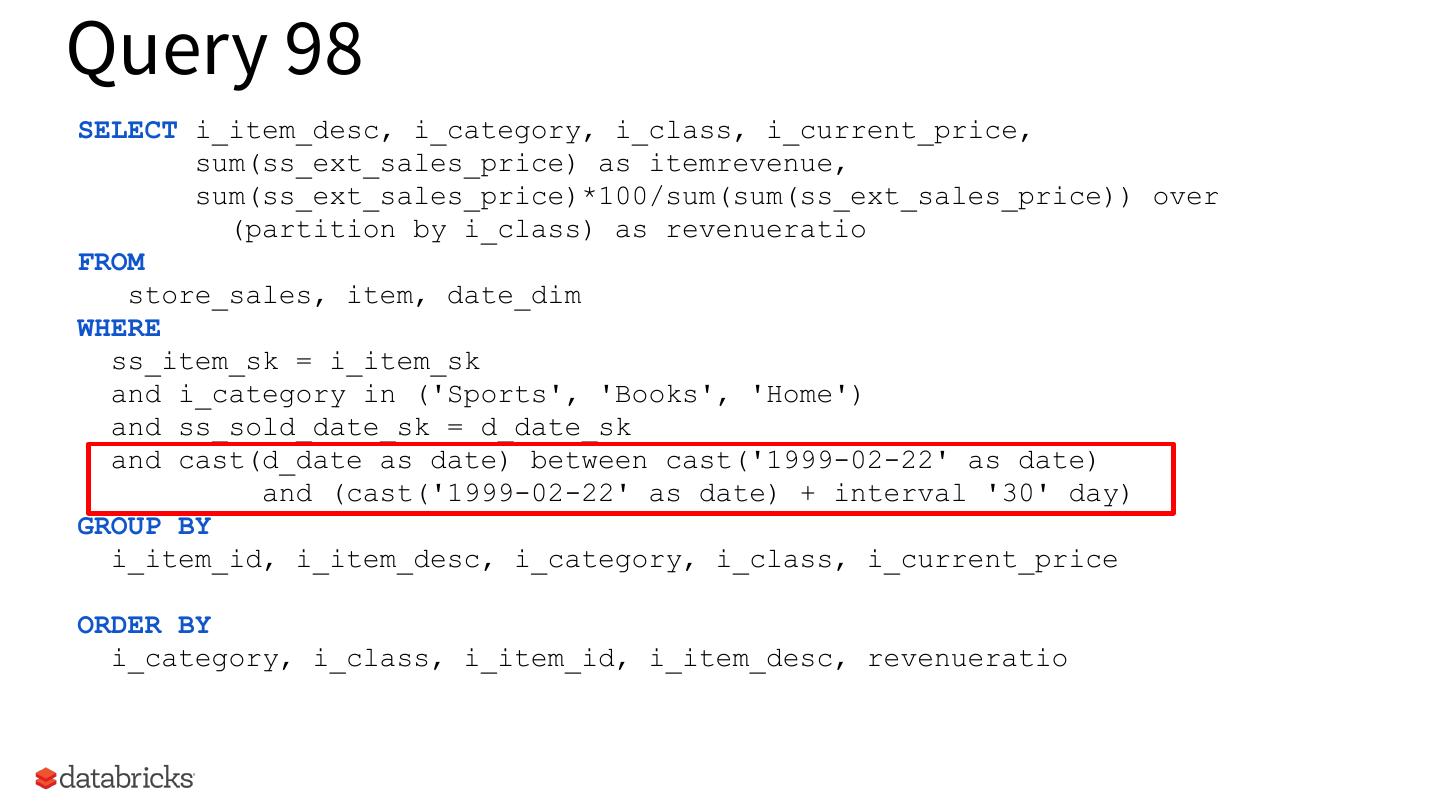
17 .Query 98
SELECT i_item_desc, i_category, i_class, i_current_price,
sum(ss_ext_sales_price) as itemrevenue,
sum(ss_ext_sales_price)*100/sum(sum(ss_ext_sales_price)) over
(partition by i_class) as revenueratio
FROM
store_sales, item, date_dim
WHERE
ss_item_sk = i_item_sk
and i_category in ('Sports', 'Books', 'Home')
and ss_sold_date_sk = d_date_sk
and cast(d_date as date) between cast('1999-02-22' as date)
and (cast('1999-02-22' as date) + interval '30' day)
GROUP BY
i_item_id, i_item_desc, i_category, i_class, i_current_price
ORDER BY
i_category, i_class, i_item_id, i_item_desc, revenueratio
�
18 .TPCDS 10 TB
Highly selective dimension filter that retains only
one month out of 5 years of data
�
19 .Conclusion
Apache Spark 3.0 introduces Dynamic Partition Pruning
- Strawman approach at logical planning time
- Optimized approach during execution time
Significant speedup, exhibited in many TPC-DS queries
With this optimization Spark may now work good with
star-schema queries, making it unnecessary to ETL
denormalized tables.
�
20 . Thanks!
Bogdan Ghit - linkedin.com/in/bogdanghit
Juliusz Sompolski - linkedin.com/in/juliuszsompolski
20
�