





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/ImprovingApacheSparkDownscaling?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Improving Apache Spark Downscaling
分享
点赞
6
收藏
2
下载 0
As more workloads move to severless-like environments, the importance of properly handling downscaling increases. While recomputing the entire RDD makes sense for dealing with machine failure, if your nodes are more being removed frequently, you can end up in a seemingly loop-like scenario, where you scale down and need to recompute the expensive part of your computation, scale back up, and then need to scale back down again.
Even if you aren’t in a serverless-like environment, preemptable or spot instances can encounter similar issues with large decreases in workers, potentially triggering large recomputes. In this talk, we explore approaches for improving the scale-down experience on open source cluster managers, such as Yarn and Kubernetes-everything from how to schedule jobs to location of blocks and their impact (shuffle and otherwise).
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Improving Spark Downscaling Christopher Crosbie, Google Ben Sidhom, Google #UnifiedDataAnalytics #SparkAISummit
3 . Long History of Solving Data Problems Open Source Google Map Flume GFS BigTable Dremel PubSub Millwheel Tensorflow Reduce Java Research Google Cloud Products BigQuery Dataproc Pub/Sub Dataflow Bigtable ML 2000 2010 2020
4 . Cloud ML Engine Cloud Dataflow Cloud Data Fusion Apache Airflow Cloud Composer
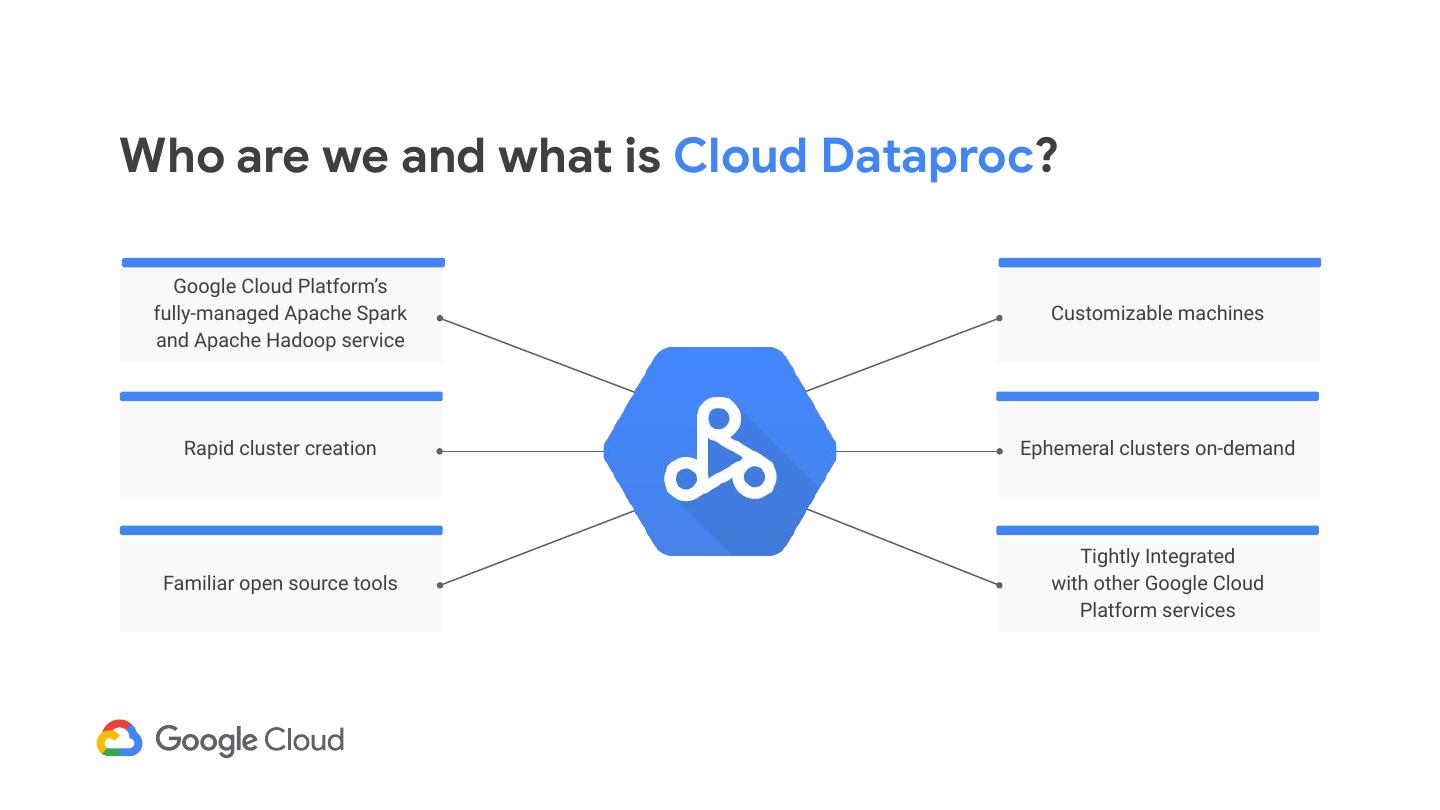
5 .Who are we and what is Cloud Dataproc? Google Cloud Platform’s fully-managed Apache Spark Customizable machines and Apache Hadoop service Rapid cluster creation Ephemeral clusters on-demand Tightly Integrated Familiar open source tools with other Google Cloud Platform services
6 .Cloud Dataproc: Open source solutions with GCP Taking the best of open source And opening up access to the best of GCP Cloud Cloud Compute Kubernetes BigQuery Datastore Bigtable Engine Engine Cloud Cloud Cloud Key Cloud Machine Webhcat Dataflow Dataproc Functions Management Service Learning Engine Cloud Cloud Cloud SQL BQ Transfer Cloud Pub/Sub Spanner Service Translation API Cloud Vision Cloud API Storage
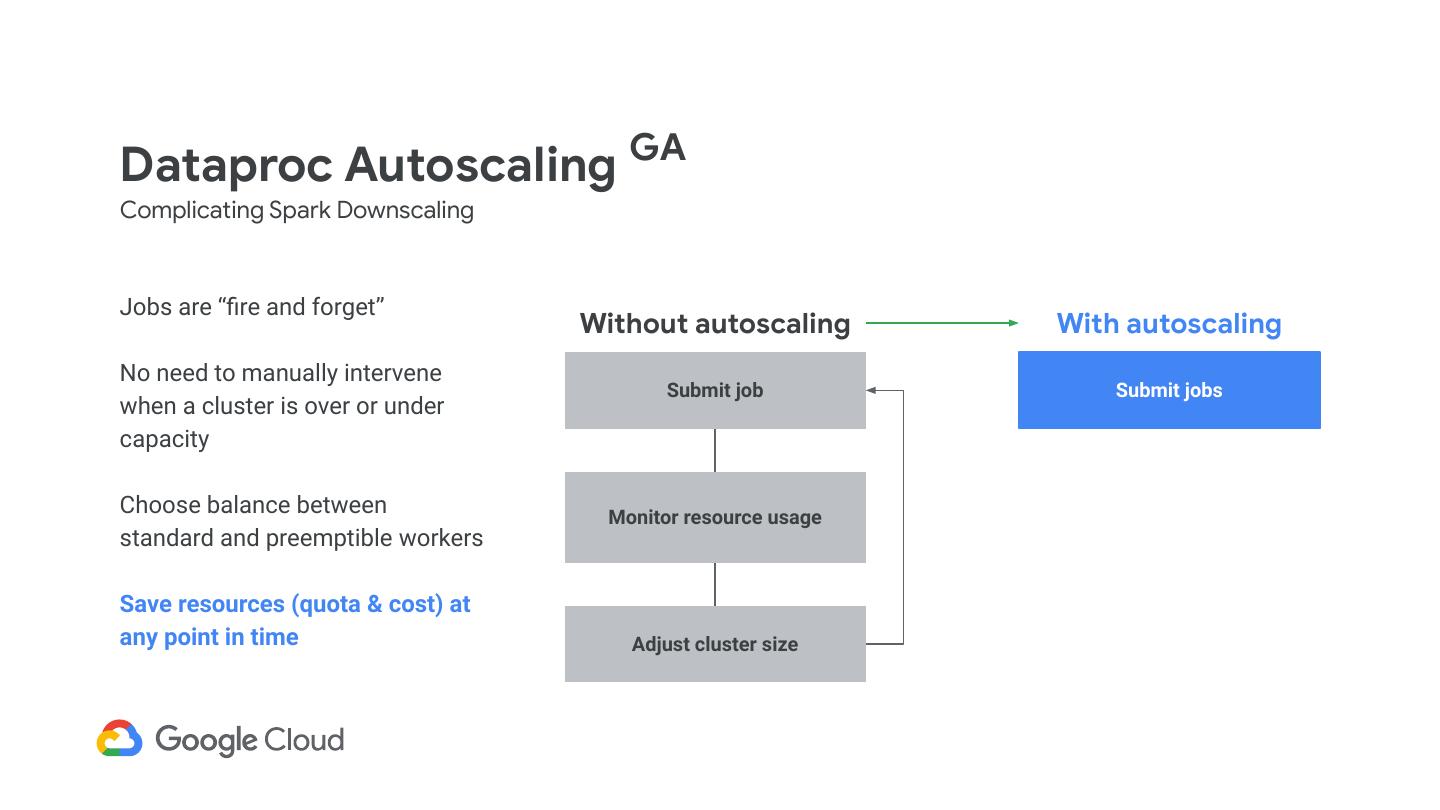
7 .Dataproc Autoscaling GA Complicating Spark Downscaling Jobs are “fire and forget” Without autoscaling With autoscaling No need to manually intervene Submit job Submit jobs when a cluster is over or under capacity Choose balance between Monitor resource usage standard and preemptible workers Save resources (quota & cost) at any point in time Adjust cluster size
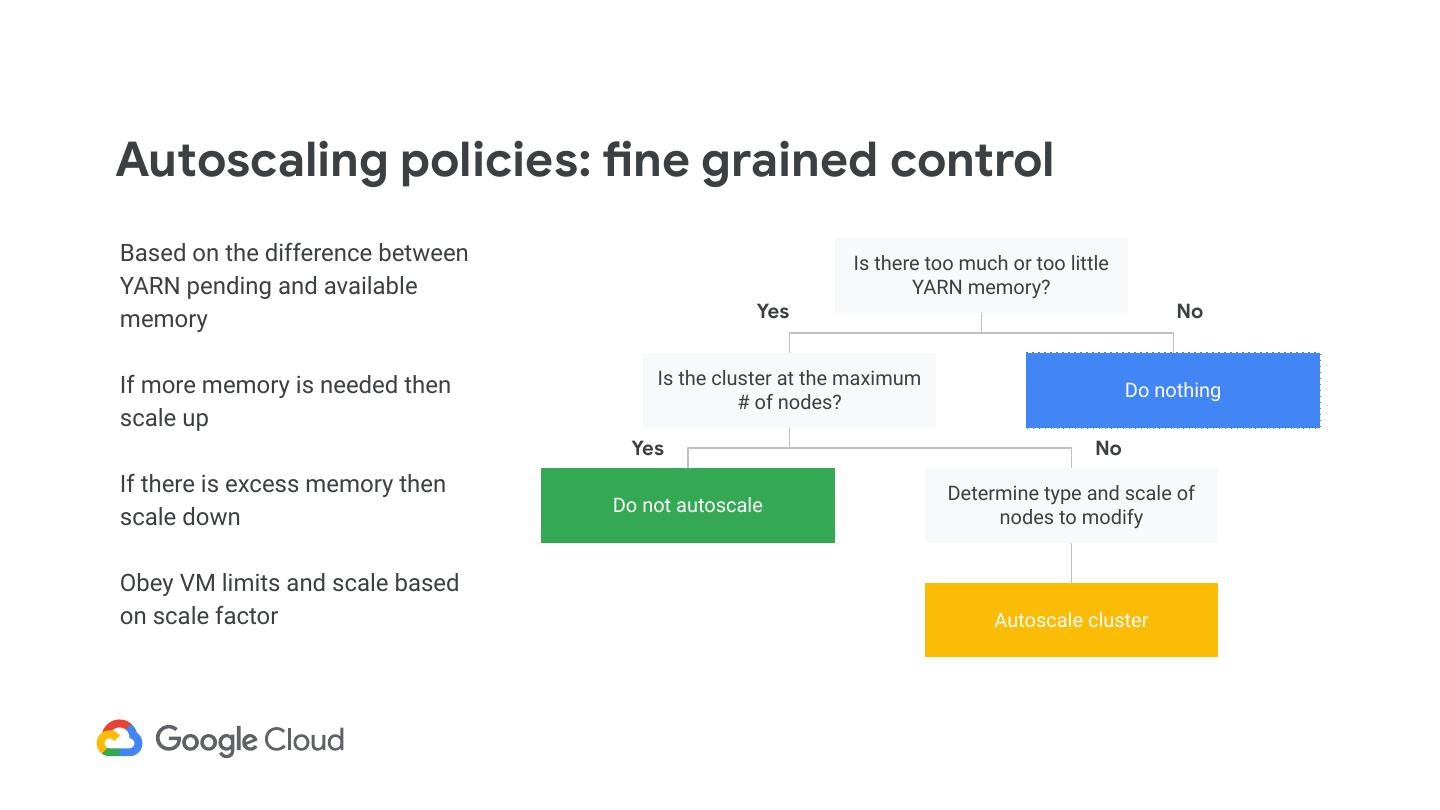
8 .Autoscaling policies: fine grained control Based on the difference between Is there too much or too little YARN pending and available YARN memory? memory Yes No If more memory is needed then Is the cluster at the maximum Do nothing # of nodes? scale up Yes No If there is excess memory then Determine type and scale of Do not autoscale scale down nodes to modify Obey VM limits and scale based on scale factor Autoscale cluster
9 .Spark Autoscaling Challenges YARN Infrastructure Finding processed data Optimizing costs Complexities (shuffle files, cached RDDs, etc)
10 .YARN
11 . YARN-based managed Spark Dataproc Cluster Cluster bucket Cloud Storage Compute engine nodes Dataproc Image Cloud Dataproc API Dataproc Agent Clusters Apache Spark HDFS Persistent Disk Jobs Apache Hadoop Clients ... Apache Hive User Data Cloud Storage ... Clients (SSH)
12 .YARN pain points Management is difficult Clusters are complicated and have to use more components than are required for a job or model. This also requires hard-to-find experts. Complicated OSS software stack Version and dependency management is hard. Have to understand how to tune multiple components for efficiency. Isolation is hard I have to think about my jobs to size clusters, and isolating jobs requires additional steps.
13 .
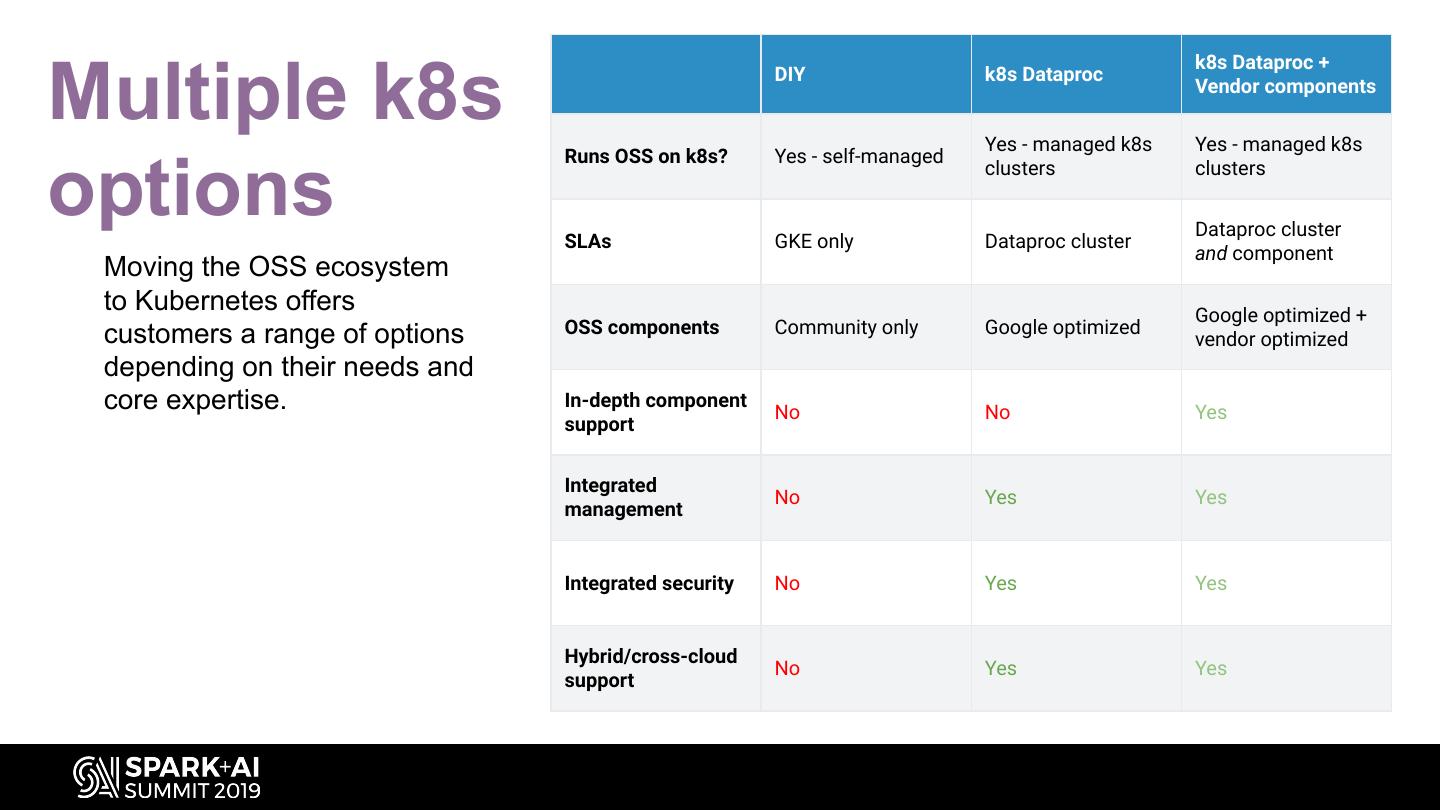
14 . k8s Dataproc + Multiple k8s DIY k8s Dataproc Yes - managed k8s Vendor components Yes - managed k8s Runs OSS on k8s? Yes - self-managed options clusters clusters Dataproc cluster SLAs GKE only Dataproc cluster and component Moving the OSS ecosystem to Kubernetes offers Google optimized + customers a range of options OSS components Community only Google optimized vendor optimized depending on their needs and core expertise. In-depth component No No Yes support Integrated No Yes Yes management Integrated security No Yes Yes Hybrid/cross-cloud No Yes Yes support
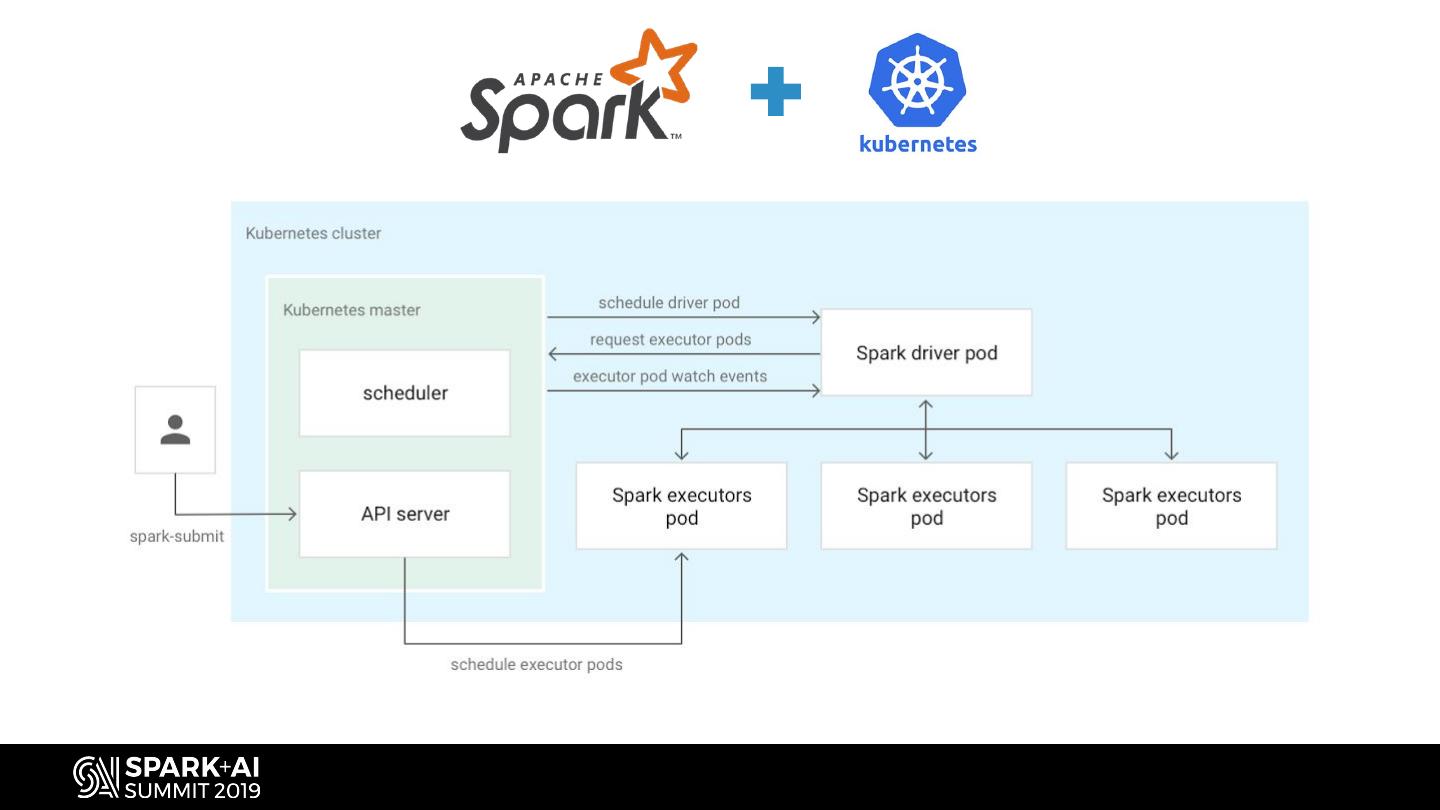
15 . How we are making this happen • Kubernetes Operators - Application control MyApp API plane for complex applications MyApp Control Plane CRUD MyApp ... – The language of Kubernetes allows extending its vocabulary through Kubernetes API Custom Resource Definition (CRD) – Kubernetes Operator is an app-specific control plane running in the cluster Control Plane • CRD: app-specific vocabulary (Master) • CR: instance of CRD • CR Controller: interpreter and reconciliation loop for CRs Data Plane – The cluster can now speak the (Nodes) app-specific words through the Kubernetes API Kubernetes
16 .https://github.com/GoogleCloudPlatform/spark-on-k8s-operator ● Integrates with BigQuery, Google’s Serverless Data Warehouse ● Provides Google Cloud Storage as replacement for HDFS ● Ships logs to Stackdriver Monitoring ○ via Prometheus server with the Stackdriver sidecar ● Contains sparkctl, a command line tool that simplifies client-local application dependencies in a Kubernetes environment.
17 .Deployment options
18 .Key benefits for autoscaling 1. Deploy unified resource management Get away deal from two separate cluster management interfaces to manage open source component. Offers one central view for easy management. 2. Isolate Spark jobs and resources Remove the headaches of version and dependency management; instead, move models and ETL pipelines from dev to production without added work. Build resilient infrastructure Don’t worry about sizing and building clusters, manipulating Docker files, or messing around with Kubernetes networking configurations. It just works.
19 .Helpful but does not solve our core problem…..
20 .Finding the processed data
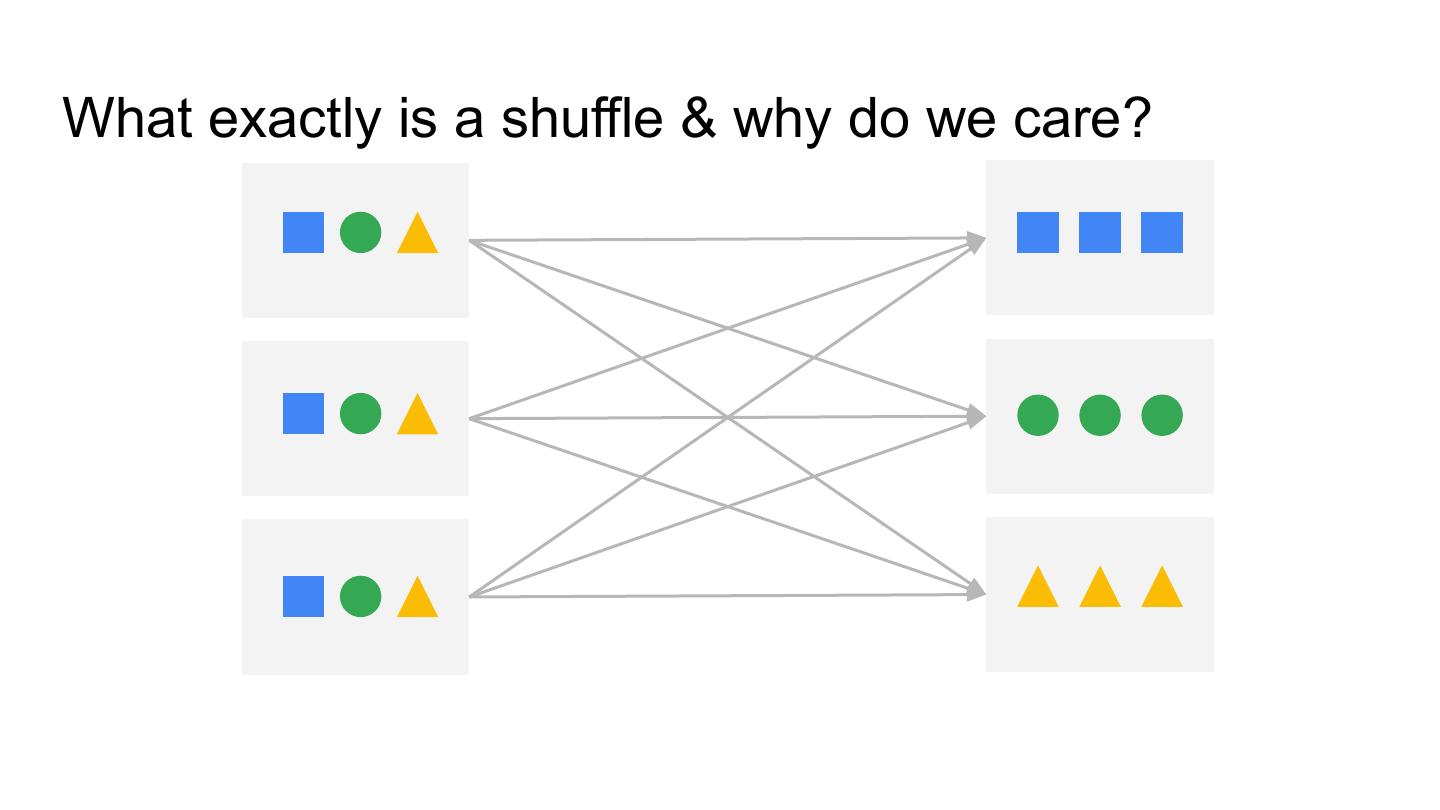
21 .What exactly is a shuffle & why do we care? Rob Wynne
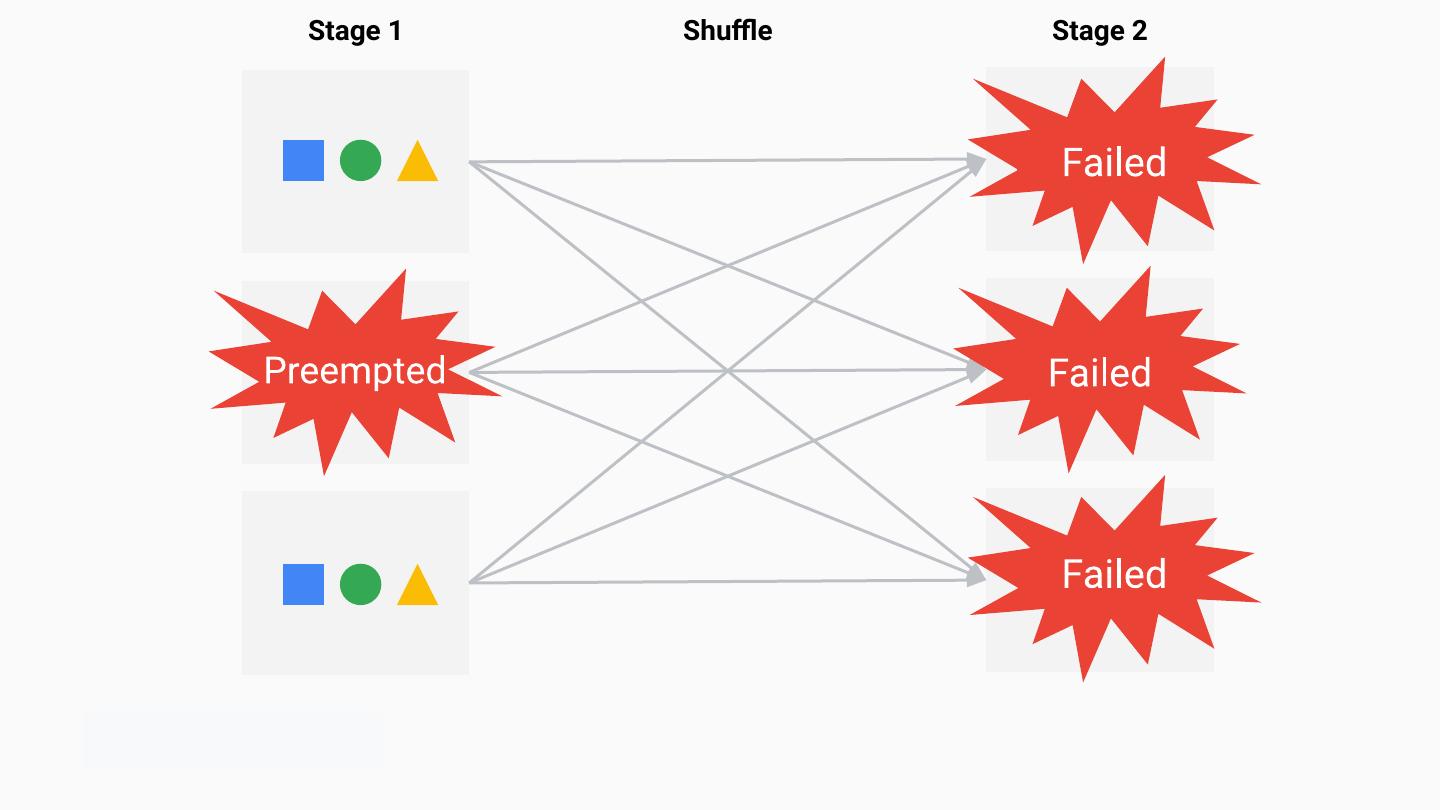
22 .A Brief History of Spark Shuffle ● Shuffle files to local storage on the executors ● Executors responsible for serving the files ● Loss of an executor meant loss of the shuffle files ● Result: poor auto-scaling ○ Pathological loop: scale down, lose work, re-compute, trigger scale up… ● Depended on driver GC event to clean up shuffle files #UnifiedDataAnalytics #SparkAISummit 22
23 .Today: Dynamic allocation and “external” shuffle ● Executors no longer need to serve data ● “External” shuffle is not exactly external ○ Only executors can be released ○ Can scale up & down executors but not the machines ● Still depends on driver GC event to clean up shuffle files #UnifiedDataAnalytics #SparkAISummit 23
24 .Spark’s shuffle code today private[spark] trait ShuffleManager { def registerShuffle[K, V, C](shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext, metrics: ShuffleWriteMetricsReporter): ShuffleWriter[K, V] def getReader[K, C](handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext, metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C] def unregisterShuffle(shuffleId: Int): Boolean def shuffleBlockResolver: ShuffleBlockResolver def stop(): Unit } #UnifiedDataAnalytics #SparkAISummit 24
25 .Continued.. /** * Obtained inside a map task to write out records to the shuffle system. */ private[spark] abstract class ShuffleWriter[K, V] { /** Write a sequence of records to this task's output */ @throws[IOException] def write(records: Iterator[Product2[K, V]]): Unit /** Close this writer, passing along whether the map completed */ def stop(success: Boolean): Option[MapStatus] } #UnifiedDataAnalytics #SparkAISummit 25
26 .Continued.. /** Write a bunch of records to this task's output */ override def write(records: Iterator[Product2[K, V]]): Unit = { sorter = if (dep.mapSideCombine) { new ExternalSorter[K, V, C]( context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer) } else { // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't // care whether the keys get sorted in each partition; that will be done on the reduce side // if the operation being run is sortByKey. new ExternalSorter[K, V, V]( context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer) } sorter.insertAll(records) ... #UnifiedDataAnalytics #SparkAISummit 26
27 .Continued.. // Don't bother including the time to open the merged output file in the shuffle write time, // because it just opens a single file, so is typically too fast to measure accurately // (see SPARK-3570). val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId) val tmp = Utils.tempFileWith(output) try { val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID) val partitionLengths = sorter.writePartitionedFile(blockId, tmp) shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp) mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths) } finally { if (tmp.exists() && !tmp.delete()) { logError(s"Error while deleting temp file ${tmp.getAbsolutePath}") } } } #UnifiedDataAnalytics #SparkAISummit 27
28 .Continued.. / Note: Changes to the format in this file should be kept in sync with // org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getSortBasedShuffleBlockData(). private[spark] class IndexShuffleBlockResolver( conf: SparkConf, _blockManager: BlockManager = null) extends ShuffleBlockResolver ……….. #UnifiedDataAnalytics #SparkAISummit 28
29 .Problems with This ● Rapid downscaling infeasible ○ Scaling down entire nodes hard ● Preemptible VMs & Spot Instances #UnifiedDataAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

