展开查看详情
1 . Koalas tutorial
Niall Turbitt
Tim Hunter
Brooke Wenig
Spark + AI Summit Europe 2019 - Tutorials
1
�
2 .About
Tim Hunter, Software Engineer at Databricks
• Co-creator of the Koalas project
• Contributes to Apache Spark MLlib, GraphFrames, TensorFrames and
Deep Learning Pipelines libraries
• Ph.D Machine Learning from Berkeley, M.S. Electrical Engineering from
Stanford
Niall Turbitt, Data Scientist at Databricks
• Professional services and training
• MSc Statistics University College Dublin, B.A Mathematics & Economics
Trinity College Dublin
�
3 .Typical journey of a data scientist
Education (MOOCs, books, universities) → pandas
Analyze small data sets → pandas
Analyze big data sets → DataFrame in Spark
3
�
4 .pandas
Authored by Wes McKinney in 2008
The standard tool for data manipulation and analysis in Python
Deeply integrated into Python data science ecosystem, e.g. numpy, matplotlib
Can deal with a lot of different situations, including:
- basic statistical analysis
- handling missing data
- time series, categorical variables, strings
4
�
5 .Apache Spark
De facto unified analytics engine for large-scale data processing
(Streaming, ETL, ML)
Originally created at UC Berkeley by Databricks’ founders
PySpark API for Python; also API support for Scala, R and SQL
5
�
6 .Koalas
Announced April 24, 2019
Pure Python library
Aims at providing the pandas API on top of Apache Spark:
- unifies the two ecosystems with a familiar API
- seamless transition between small and large data
6
�
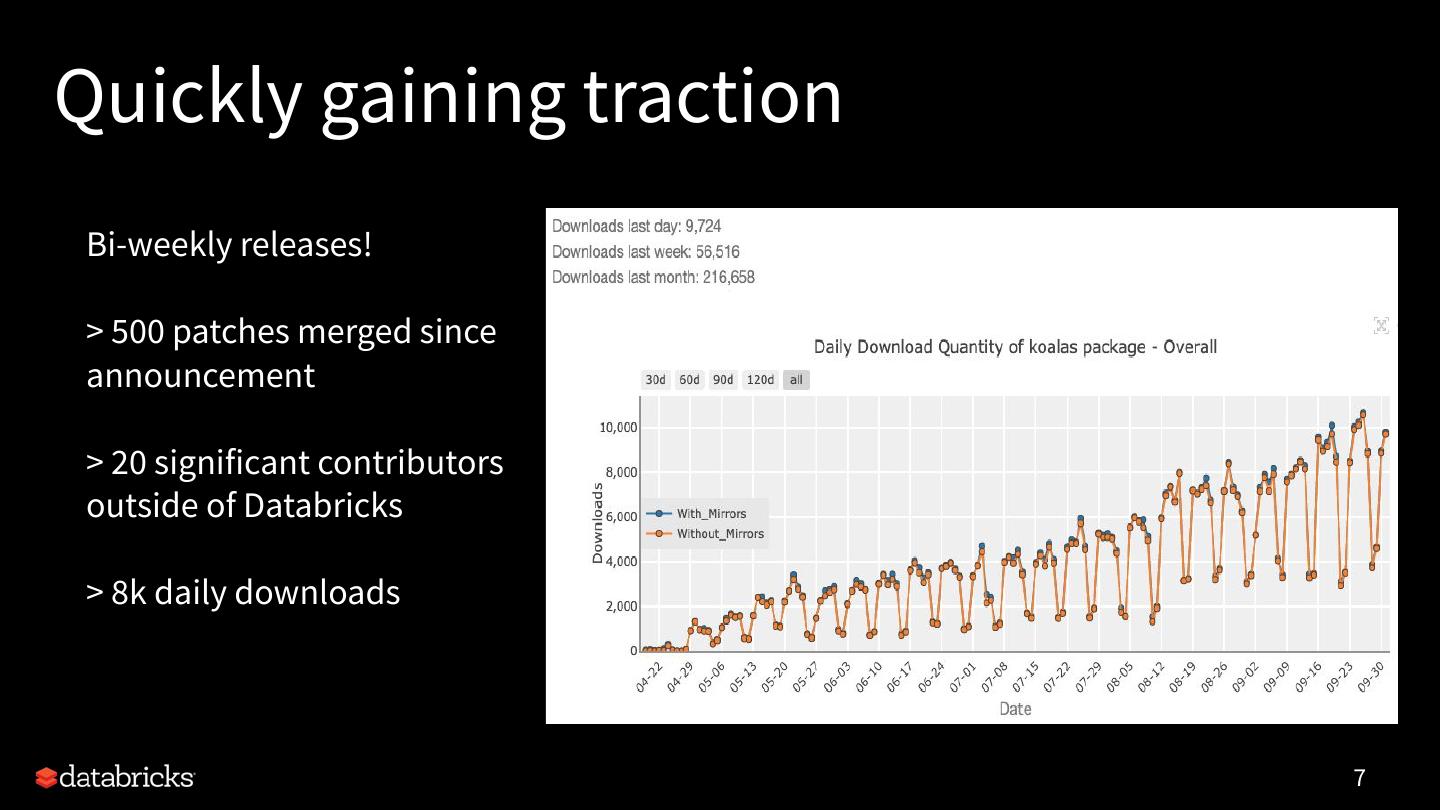
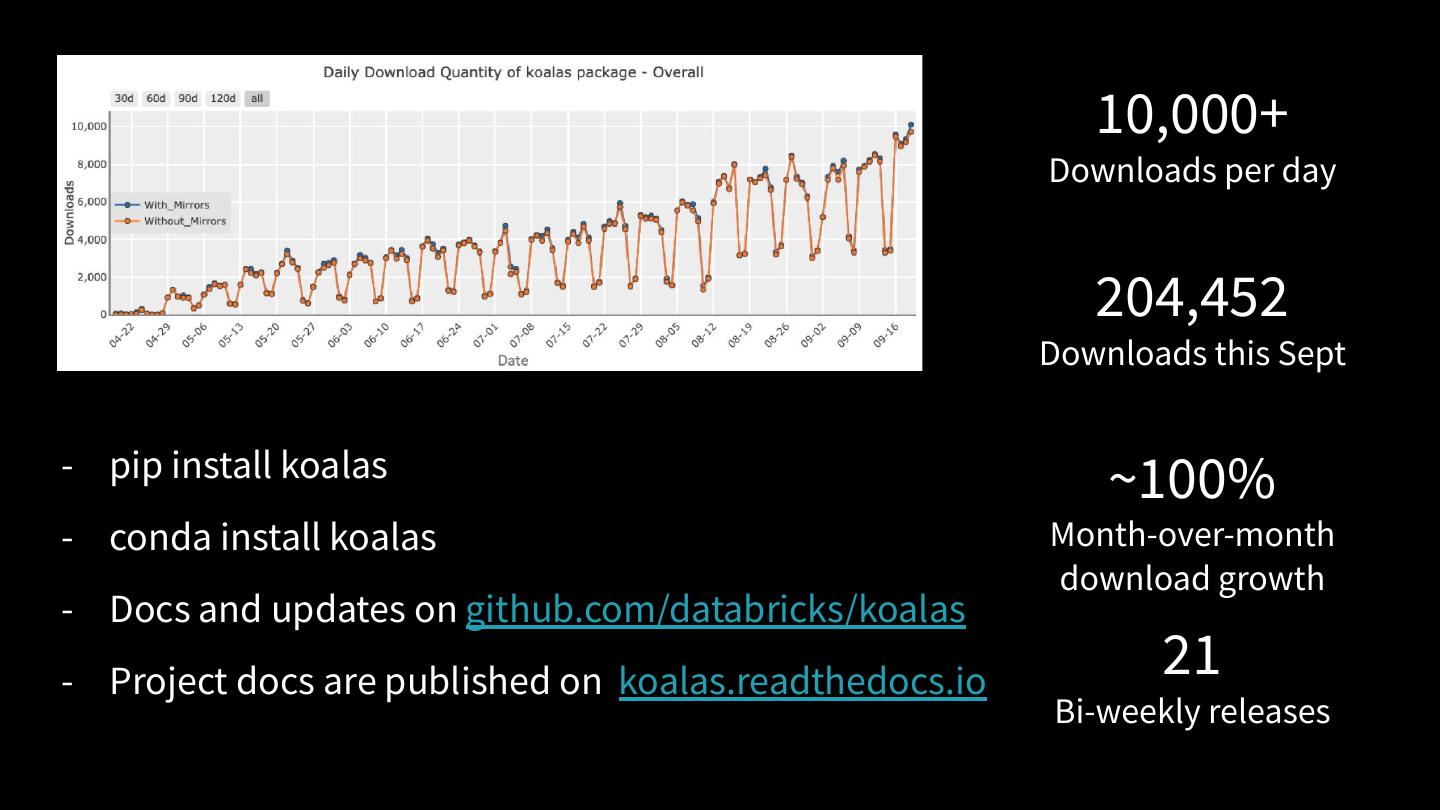
7 .Quickly gaining traction
Bi-weekly releases!
> 500 patches merged since
announcement
> 20 significant contributors
outside of Databricks
> 8k daily downloads
7
�
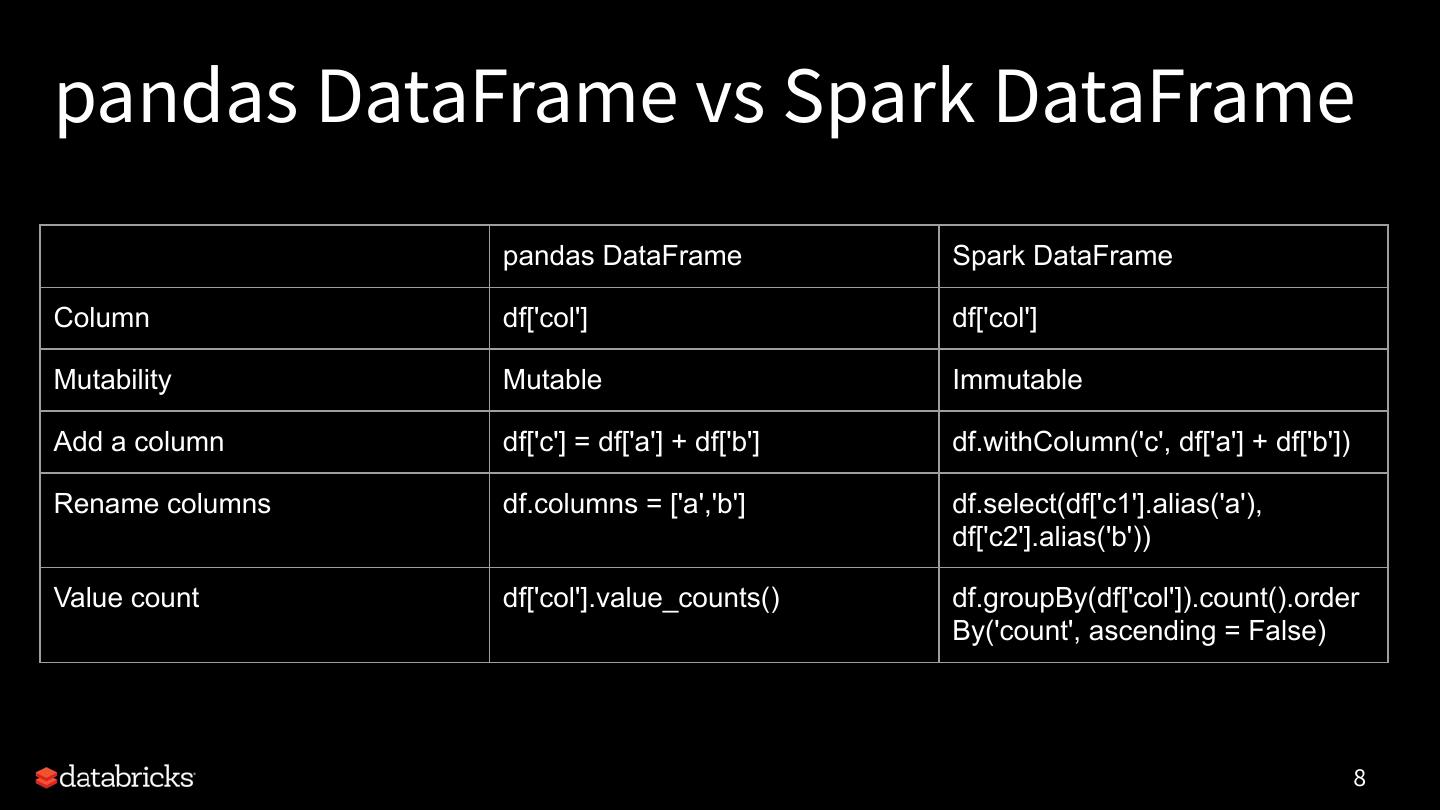
8 .pandas DataFrame vs Spark DataFrame
pandas DataFrame Spark DataFrame
Column df['col'] df['col']
Mutability Mutable Immutable
Add a column df['c'] = df['a'] + df['b'] df.withColumn('c', df['a'] + df['b'])
Rename columns df.columns = ['a','b'] df.select(df['c1'].alias('a'),
df['c2'].alias('b'))
Value count df['col'].value_counts() df.groupBy(df['col']).count().order
By('count', ascending = False)
8
�
9 . A short example
import pandas as pd df = (spark.read
df = pd.read_csv("my_data.csv") .option("inferSchema", "true")
.option("comment", True)
df.columns = ['x', 'y', 'z1'] .csv("my_data.csv"))
df['x2'] = df.x * df.x df = df.toDF('x', 'y', 'z1')
df = df.withColumn('x2', df.x*df.x)
9
�
10 .A short example
import pandas as pd import databricks.koalas as ks
df = pd.read_csv("my_data.csv") df = ks.read_csv("my_data.csv")
df.columns = ['x', 'y', 'z1'] df.columns = ['x', 'y', 'z1']
df['x2'] = df.x * df.x df['x2'] = df.x * df.x
10
�
11 .Current status
Bi-weekly releases, very active community with daily changes
The most common functions have been implemented:
- 60% of the DataFrame / Series API
- 60% of the DataFrameGroupBy / SeriesGroupBy API
- 15% of the Index / MultiIndex API
- to_datetime, get_dummies, …
11
�
12 .New features
- 80% of the plot functions (0.16.0-)
- Spark related functions (0.8.0-)
- IO: to_parquet/read_parquet, to_csv/read_csv, to_json/read_json,
to_spark_io/read_spark_io, to_delta/read_delta, ...
- SQL
- cache
- Support for multi-index columns (90%) (0.16.0-)
- Options to configure Koalas’ behavior (0.17.0-)
12
�
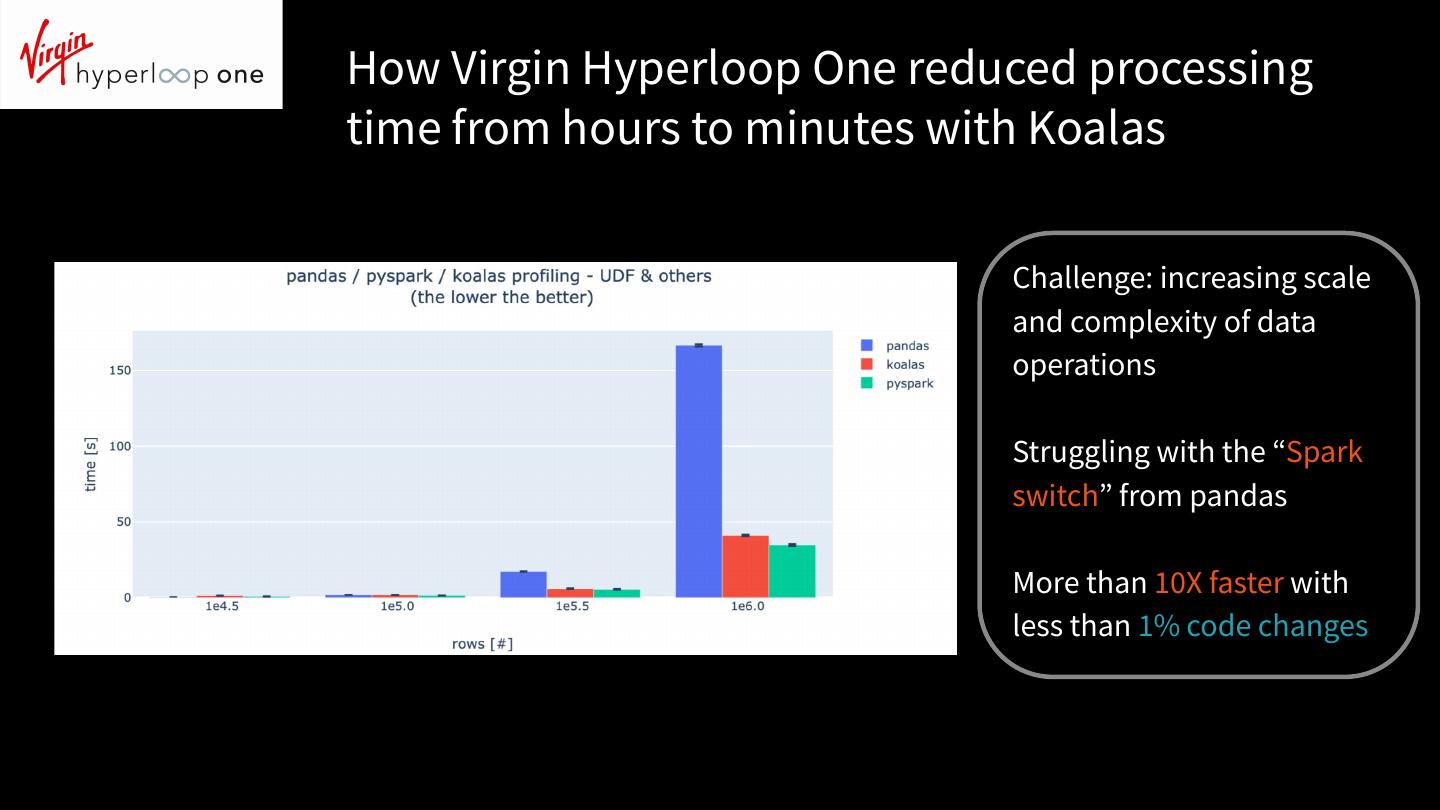
13 .How Virgin Hyperloop One reduced processing
time from hours to minutes with Koalas
Challenge: increasing scale
and complexity of data
operations
Struggling with the “Spark
switch” from pandas
More than 10X faster with
less than 1% code changes
�
14 .Key Differences
Spark is more lazy by nature:
- most operations only happen when displaying or writing a
DataFrame
Spark does not maintain row order
Performance when working at scale
14
�
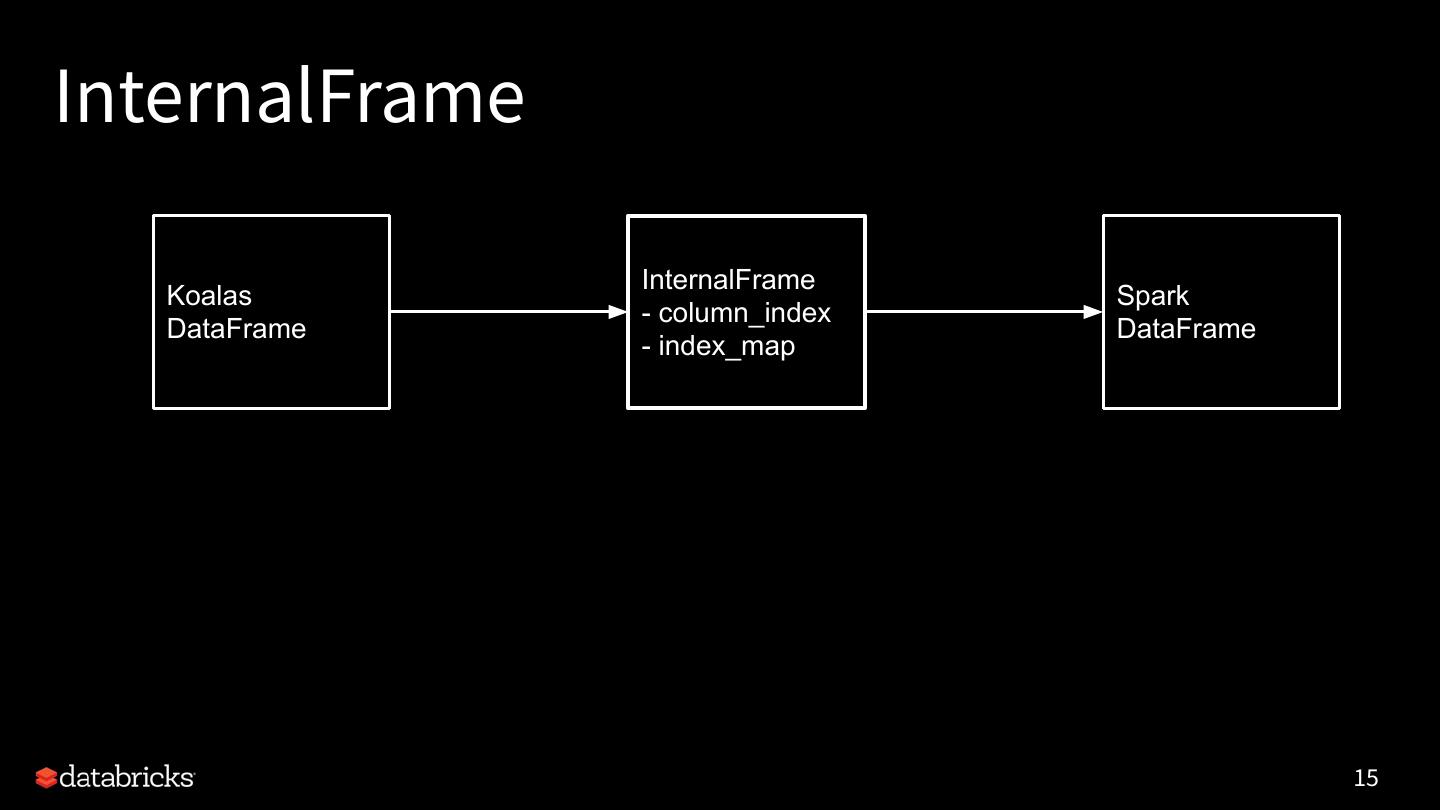
15 .InternalFrame
InternalFrame
Koalas Spark
- column_index
DataFrame DataFrame
- index_map
15
�
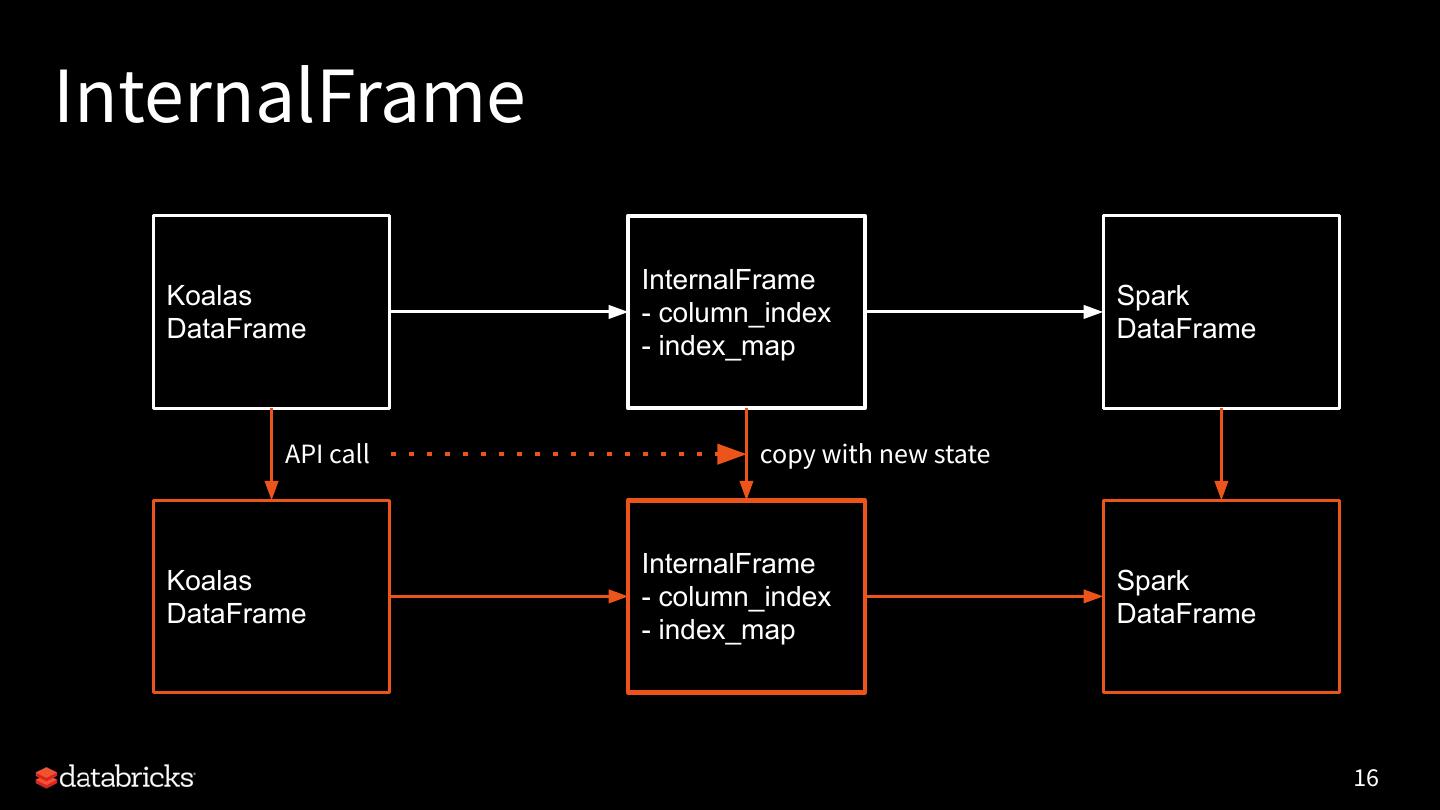
16 .InternalFrame
InternalFrame
Koalas Spark
- column_index
DataFrame DataFrame
- index_map
API call copy with new state
InternalFrame
Koalas Spark
- column_index
DataFrame DataFrame
- index_map
16
�
17 .Notebooks
bit.ly/koalas_1_sseu
bit.ly/koalas_2_sseu
17
�
18 .Thank you!
github.com/databricks/koalas
Get Started at databricks.com/try
18
�
19 .Internal Frame
Internal immutable metadata.
- holds the current Spark DataFrame
- manages mapping from Koalas column names to Spark
column names
- manages mapping from Koalas index names to Spark column
names
- converts between Spark DataFrame and pandas DataFrame
19
�
20 .InternalFrame
InternalFrame
Koalas Spark
- column_index
DataFrame DataFrame
- index_map
API call copy with new state
InternalFrame Only updates metadata
Koalas
- column_index
DataFrame
- index_map kdf.set_index(...)
20
�
21 .InternalFrame
InternalFrame
Koalas Spark
- column_index
DataFrame DataFrame
- index_map
API call copy with new state
e.g., inplace=True
InternalFrame
Spark
- column_index
DataFrame
- index_map
kdf.dropna(...,
inplace=True)
21
�
22 .Operations on different DataFrames
We only allow Series derived from the same DataFrame by default.
OK Not OK
- df.a + df.b - df1.a + df2.b
- df['c'] = df.a * df.b - df1['c'] = df2.a * df2.b
22
�
23 .Operations on different DataFrames
We only allow Series derived from the same DataFrame by default.
OK Not OK
- df.a + df.b - df1.a + df2.b
- df['c'] = df.a * df.b - df1['c'] = df2.a * df2.b
Equivalent Spark code?
???
sdf.select( sdf1.select(
sdf['a'] + sdf['b']) sdf1['a'] + sdf2['b'])
23
�
24 .Operations on different DataFrames
We only allow Series derived from the same DataFrame by default.
OK Not OK
- df.a + df.b - df1.a + df2.b
- df['c'] = df.a * df.b - df1['c'] = df2.a * df2.b
Equivalent Spark code?
???
sdf.select( sdf1.select( ce pt i o n!!
n a ly s i sEx
sdf['a'] + sdf['b']) A
sdf1['a'] + sdf2['b'])
24
�
25 .Operations on different DataFrames
ks.set_option('compute.ops_on_diff_frames', True)
OK OK
- df.a + df.b - df1.a + df2.b
- df['c'] = df.a * df.b - df1['c'] = df2.a * df2.b
Equivalent Spark code?
sdf1.join(sdf2,
sdf.select( on="_index_")
sdf['a'] + sdf['b']) .select('a * b')
25
�
26 .Default Index
Koalas manages a group of columns as index.
The index behaves the same as pandas’.
If no index is specified when creating a Koalas DataFrame:
it attaches a “default index” automatically.
Each “default index” has Pros and Cons.
26
�
27 .Default Indexes
Configurable by the option “compute.default_index_type”
requires to collect data
requires shuffle continuous increments
into single node
sequence YES YES YES
distributed-sequence NO YES / NO YES / NO
distributed NO NO NO
See also: https://koalas.readthedocs.io/en/latest/user_guide/options.html#default-index-type
27
�
28 .What to expect?
• Improve pandas API coverage
- rolling/expanding
• Support categorical data types
• More time-series related functions
• Improve performance
- Minimize the overhead at Koalas layer
- Optimal implementation of APIs
28
�
29 .Getting started
pip install koalas
conda install koalas
Look for docs on https://koalas.readthedocs.io/en/latest/
and updates on github.com/databricks/koalas
10 min tutorial in a Live Jupyter notebook is available from the docs.
29
�