


















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/NearRealTimeDataWarehousingwithApacheSparkandDeltaLake?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

Near Real-Time Data Warehousing with Apache Spark and Delta Lake
Near Real-Time Data Warehousing with Apache Spark and Delta Lake
Near Real-Time Data Warehousing with Apache Spark and Delta Lake
点赞
6
收藏
2
下载 4
Timely data in a data warehouse is a challenge many of us face, often with there being no straightforward solution.
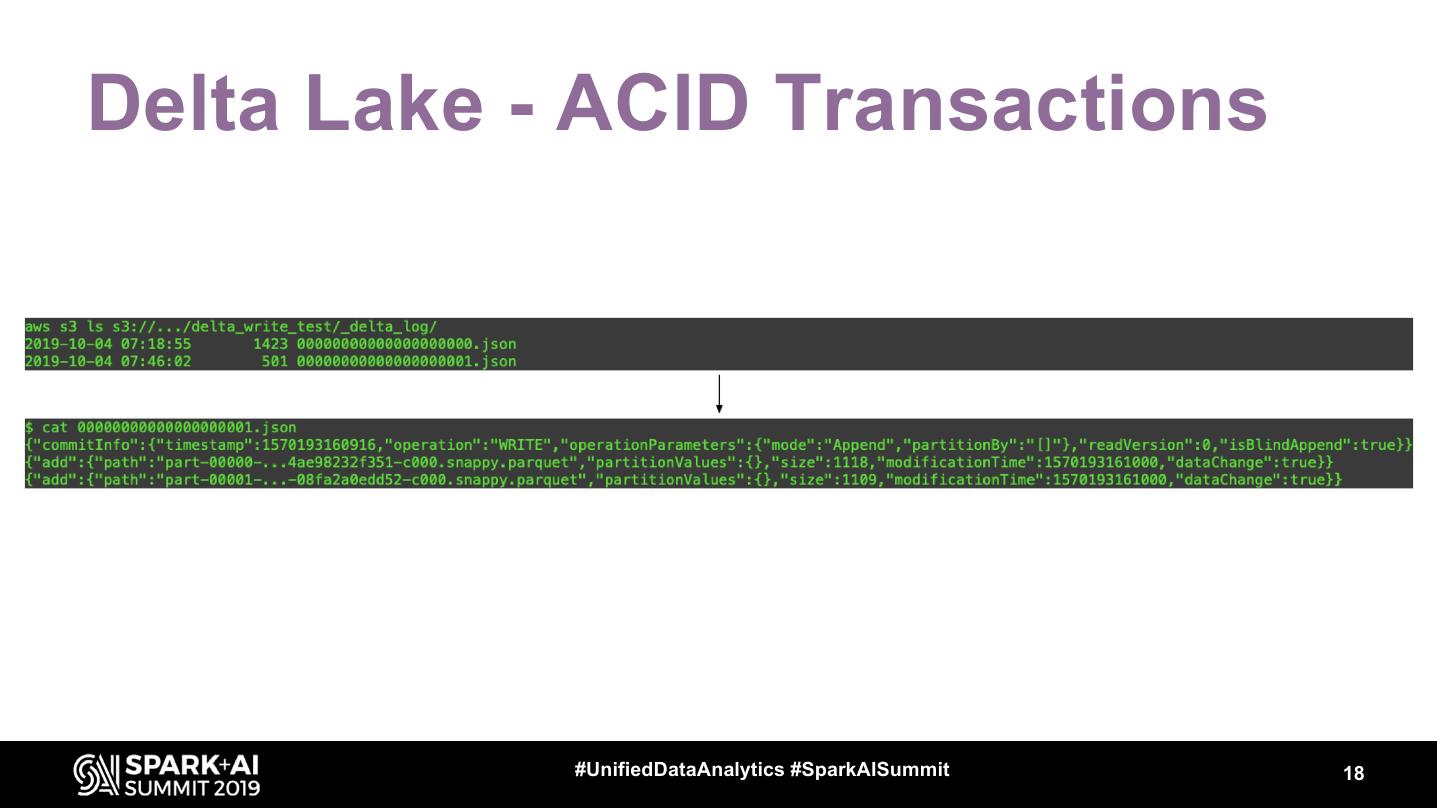
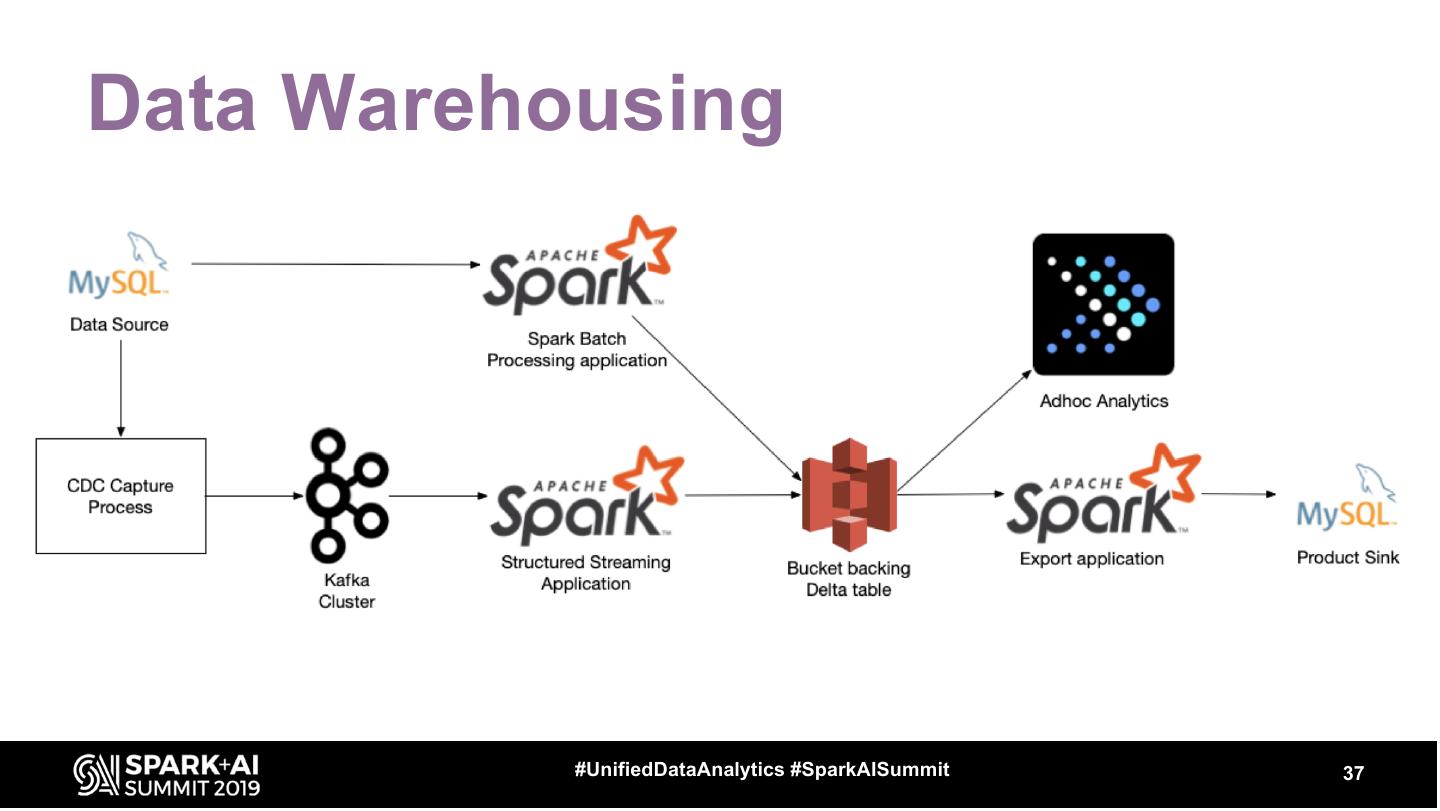
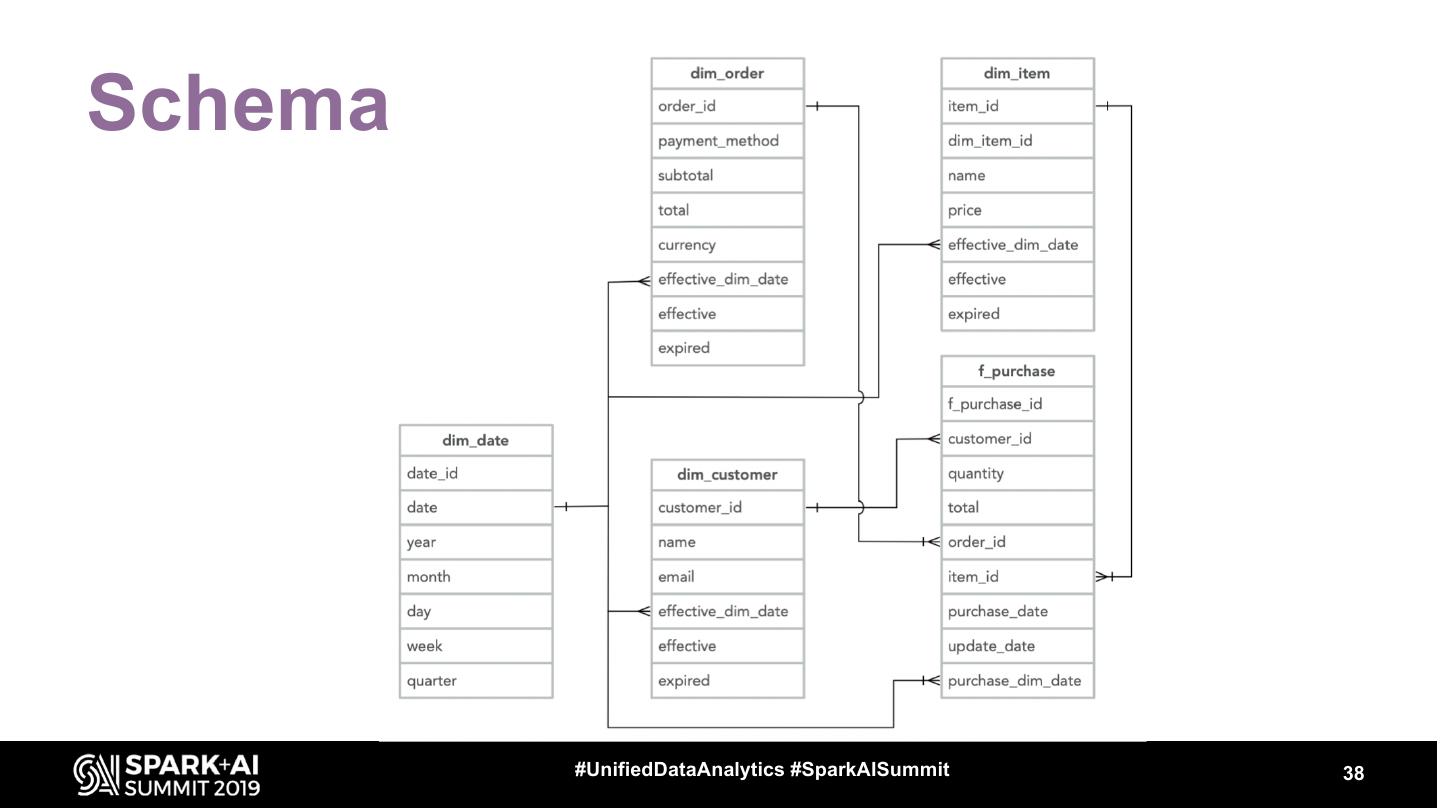
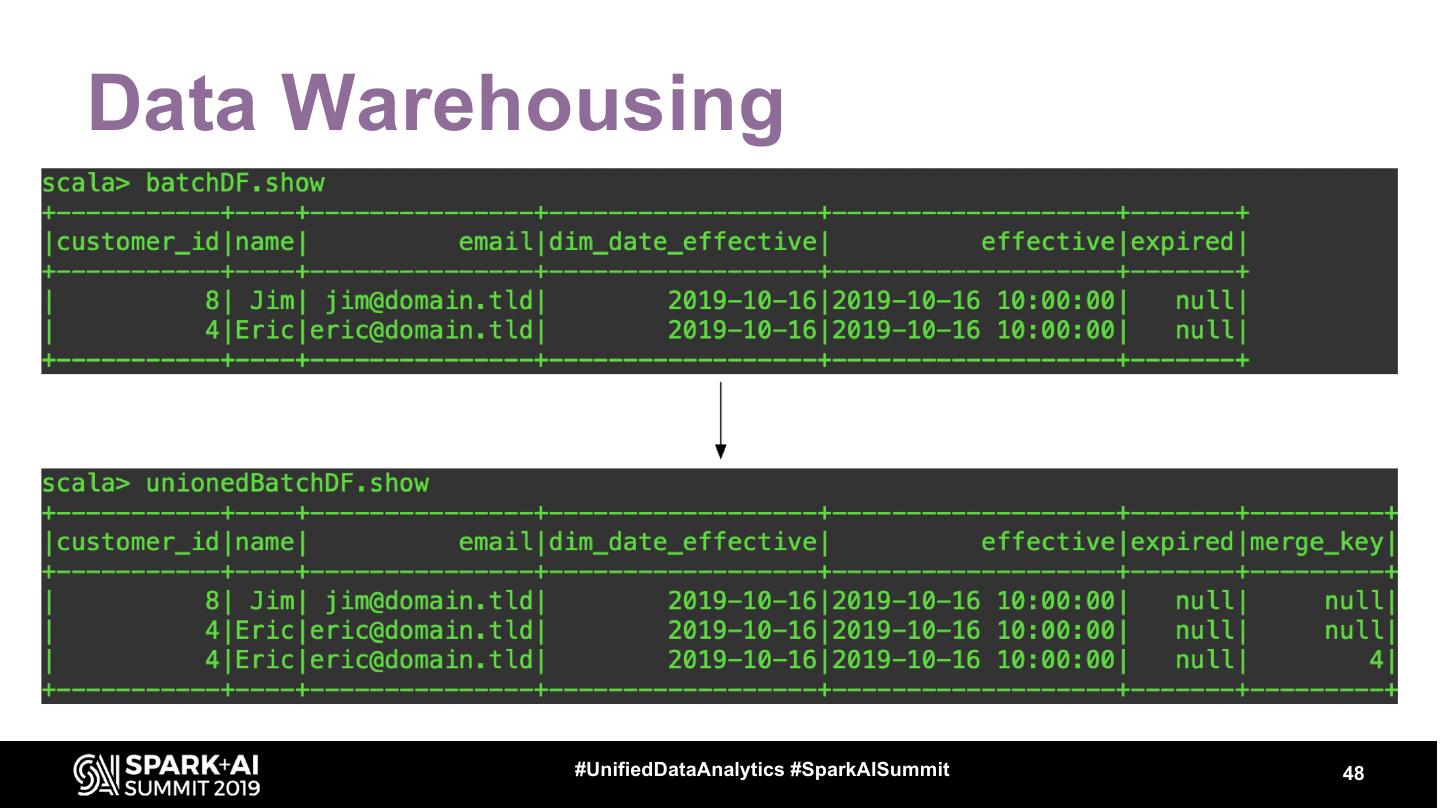
Using a combination of batch and streaming data pipelines you can leverage the Delta Lake format to provide an enterprise data warehouse at a near real-time frequency. Delta Lake eases the ETL workload by enabling ACID transactions in a warehousing environment. Coupling this with structured streaming, you can achieve a low latency data warehouse. In this talk, we’ll talk about how to use Delta Lake to improve the latency of ingestion and storage of your data warehouse tables. We’ll also talk about how you can use spark streaming to build the aggregations and tables that drive your data warehouse.
相关推荐

基于SeaTunnel快速集成SAP进入Redshift
SeaTunnel

联通数科基于Apache Dolphinscheduler构建Dataops一体化能力
DolphinScheduler社区

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

