





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/TheParquetFormatandPerformanceOptimizationOpportunities?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享

The Parquet Format and Performance Optimization Opportunities
The Parquet Format and Performance Optimization Opportunities
The Parquet Format and Performance Optimization Opportunities
点赞
6
收藏
2
下载 13
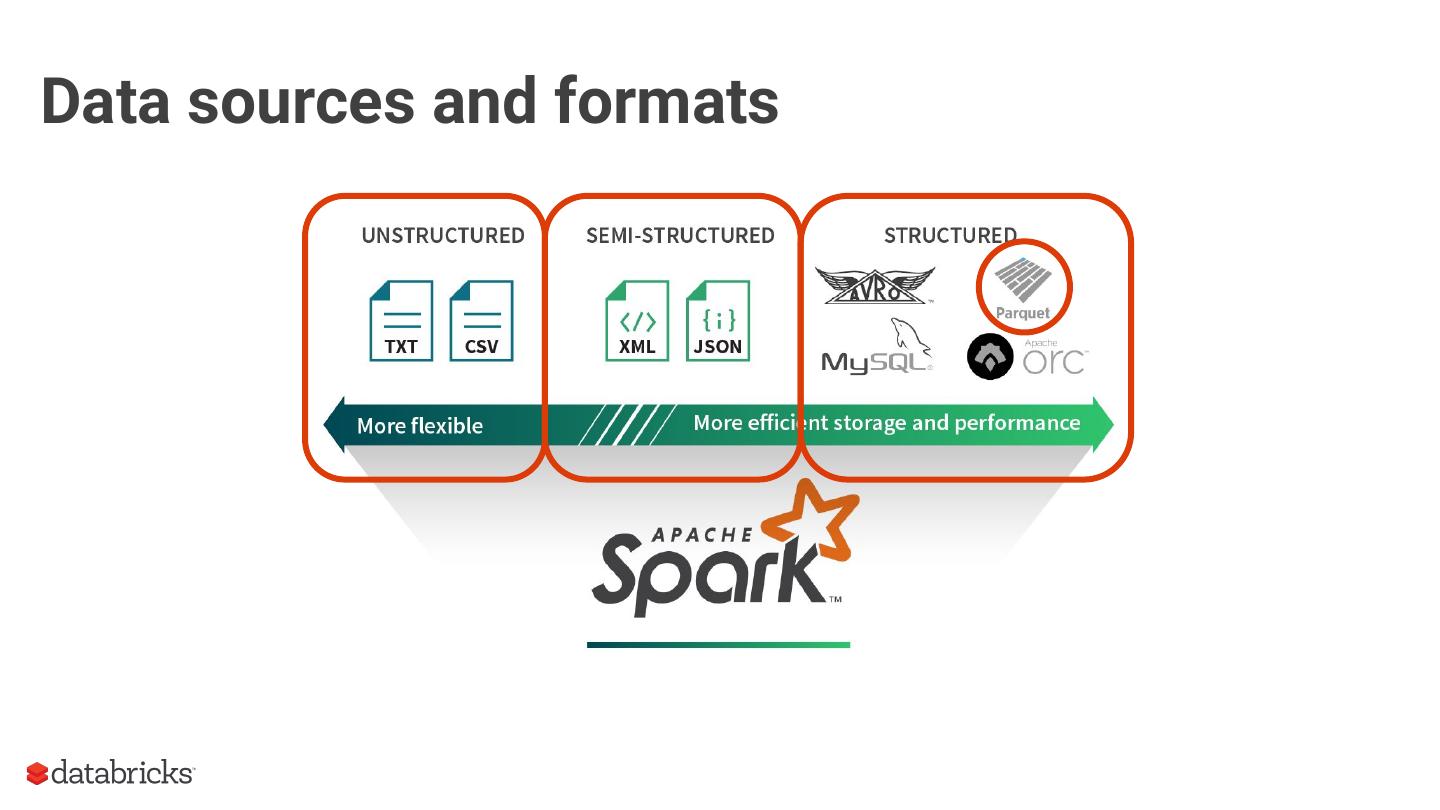
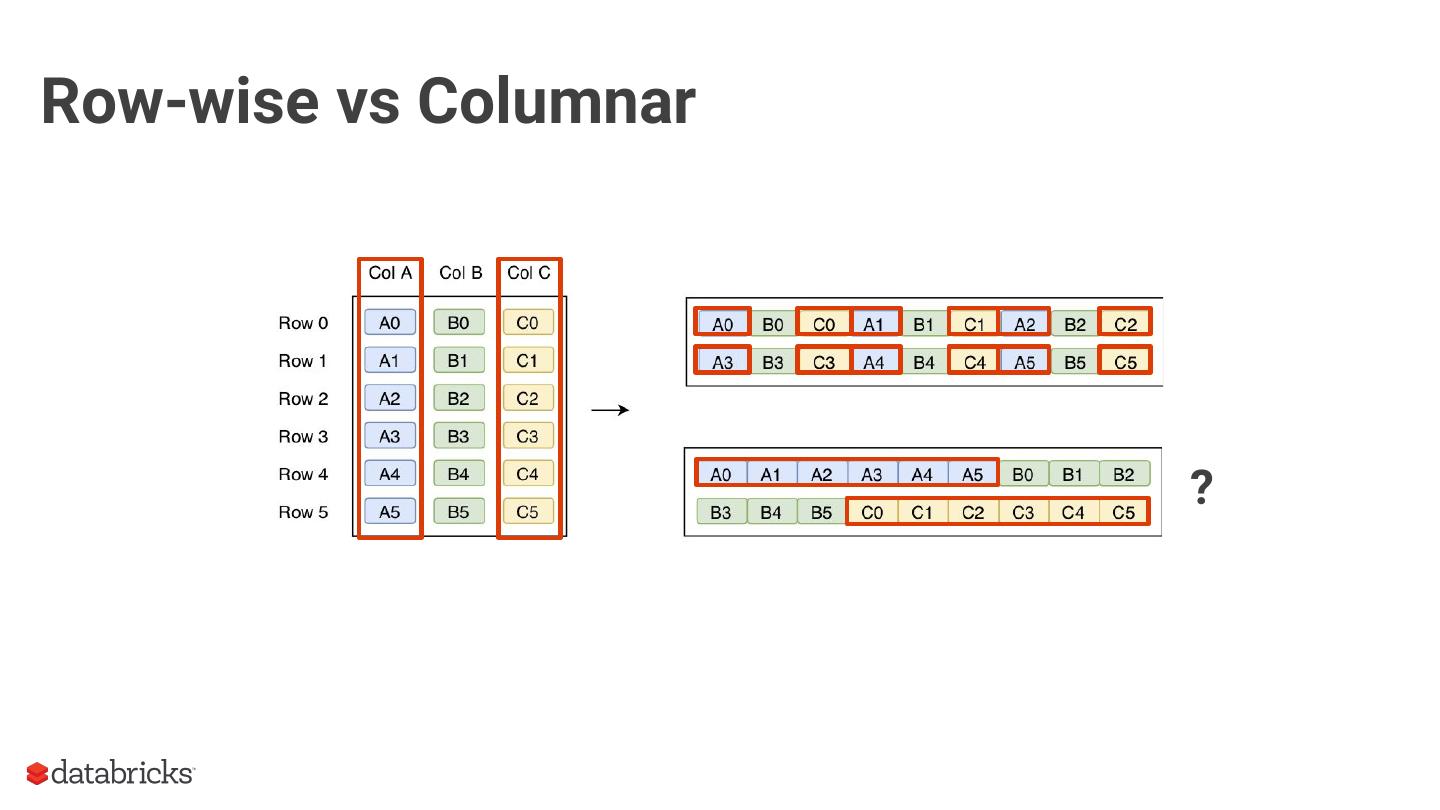
The Parquet format is one of the most widely used columnar storage formats in the Spark ecosystem. Given that I/O is expensive and that the storage layer is the entry point for any query execution, understanding the intricacies of your storage format is important for optimizing your workloads.
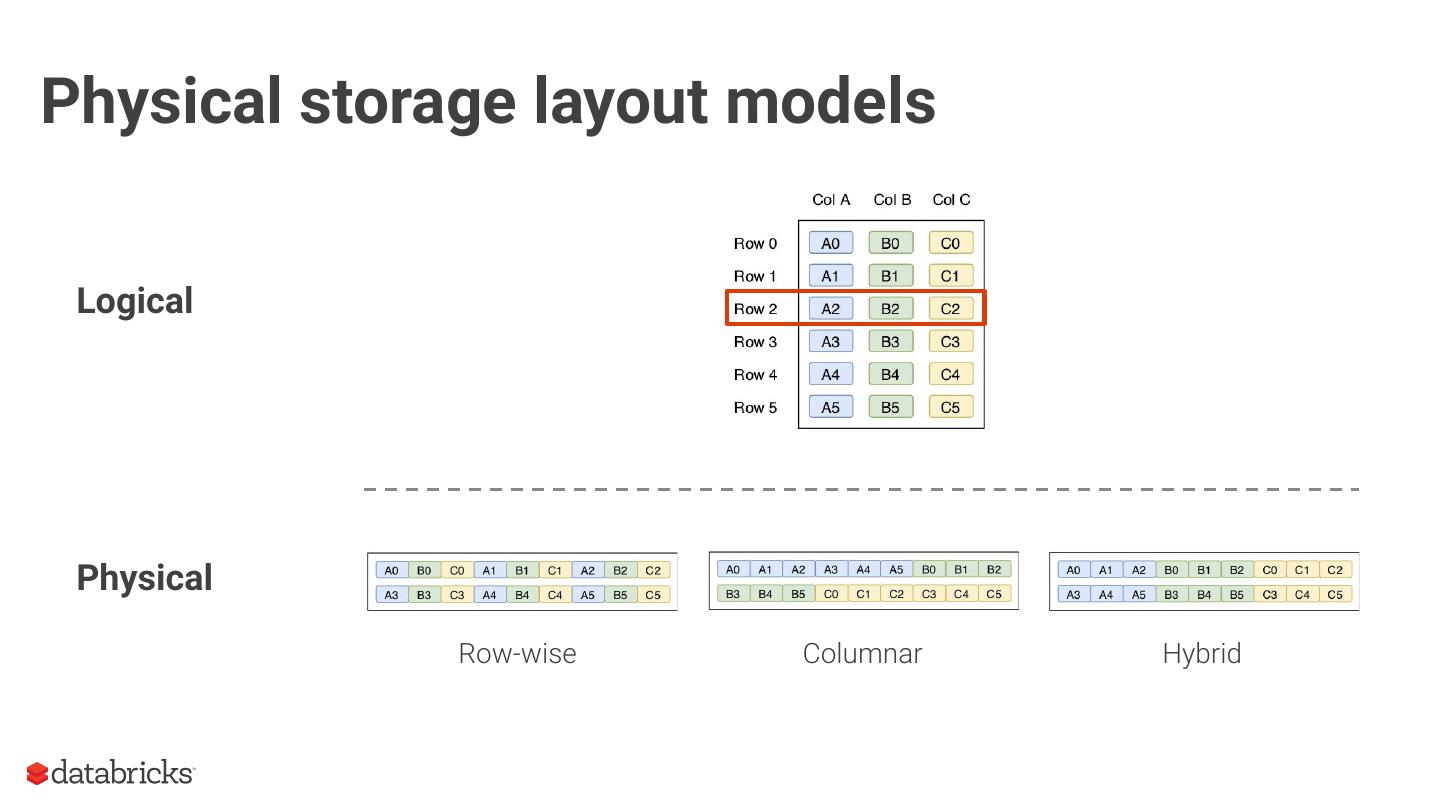
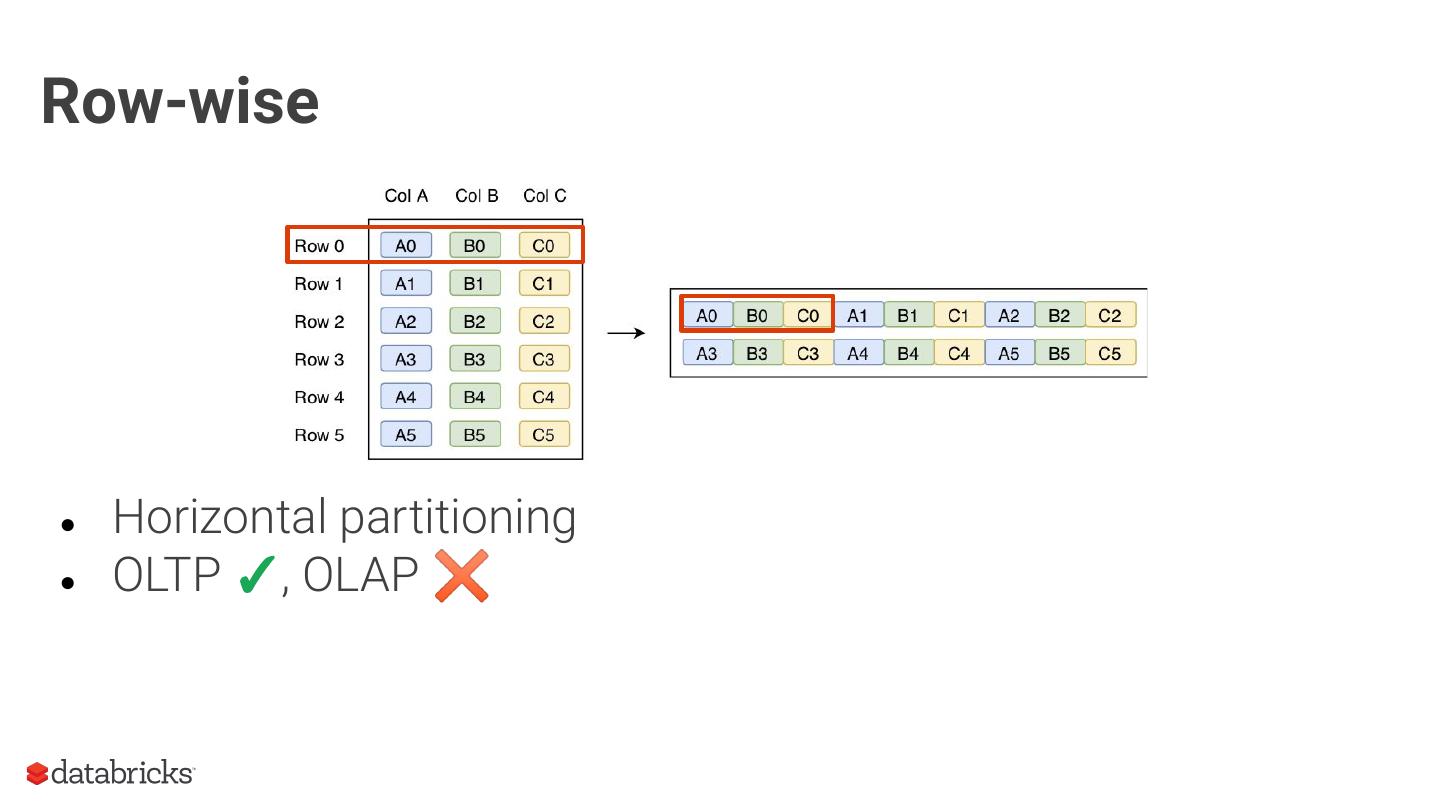
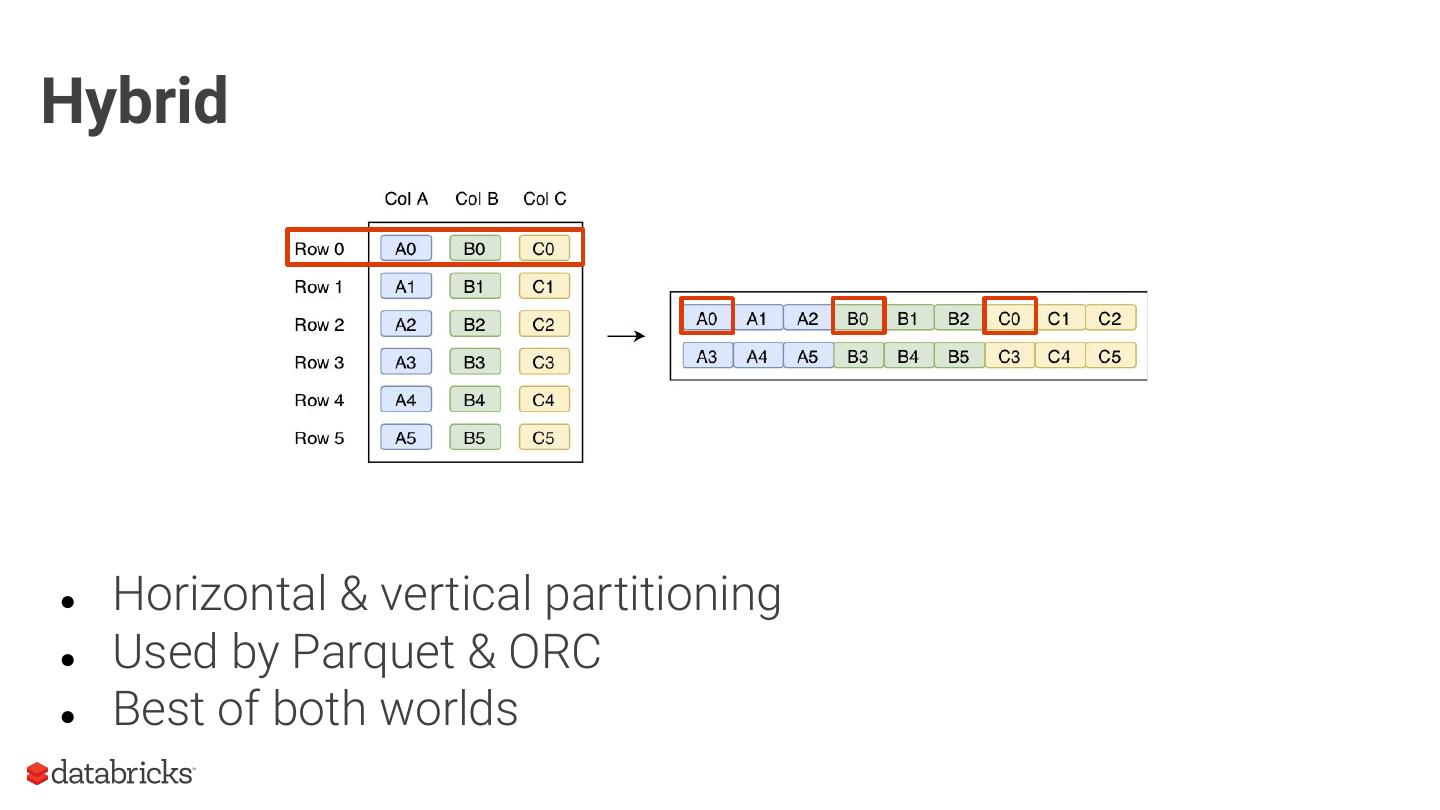
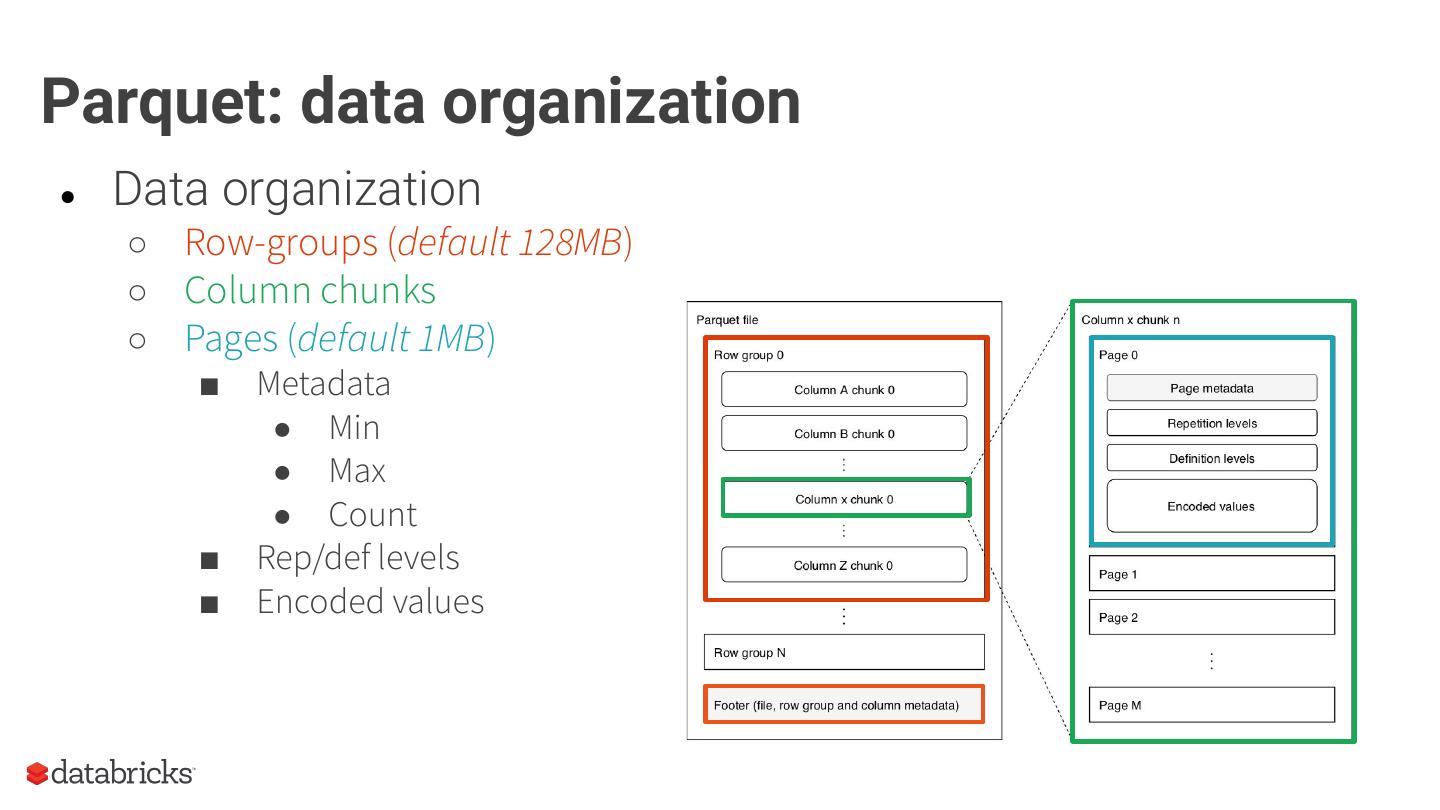
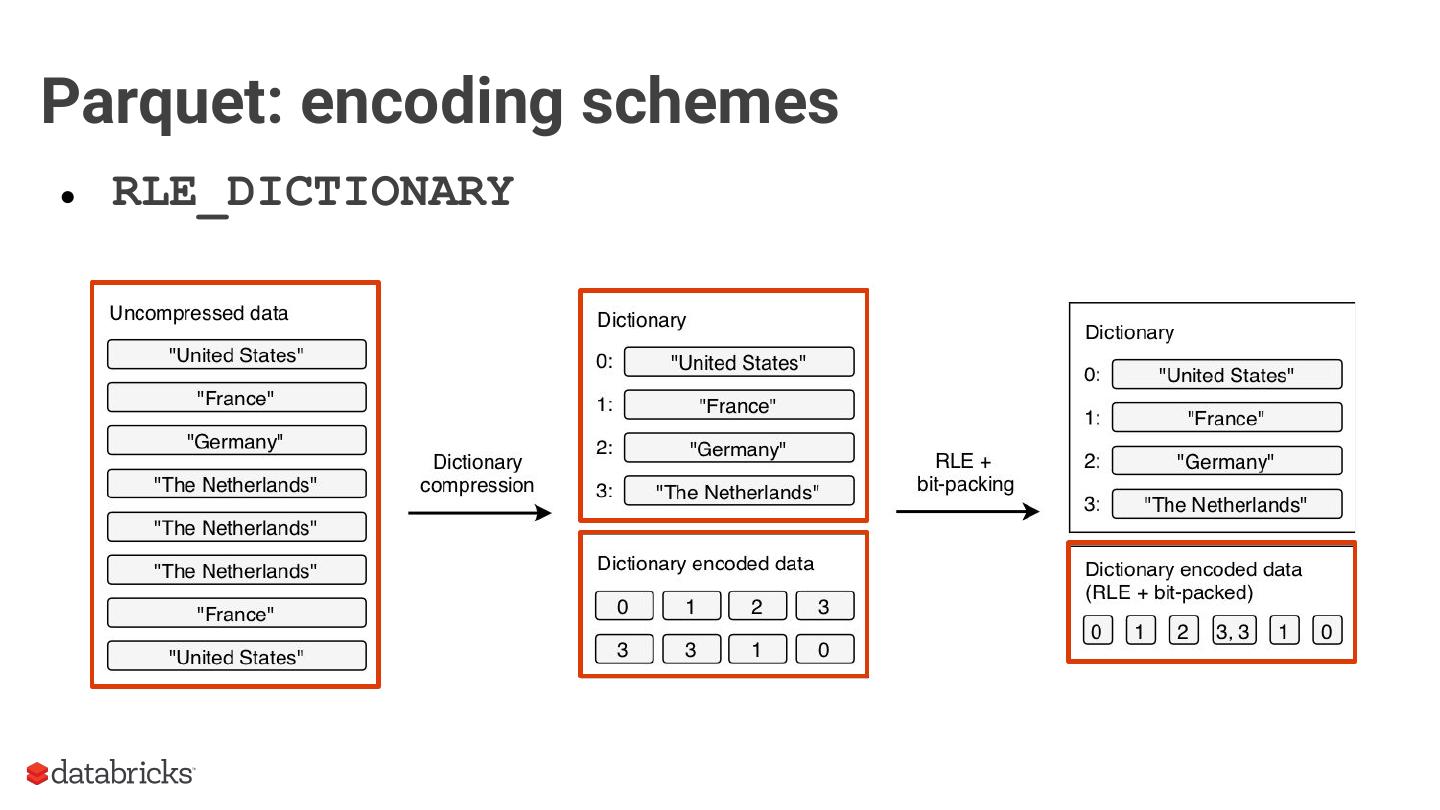
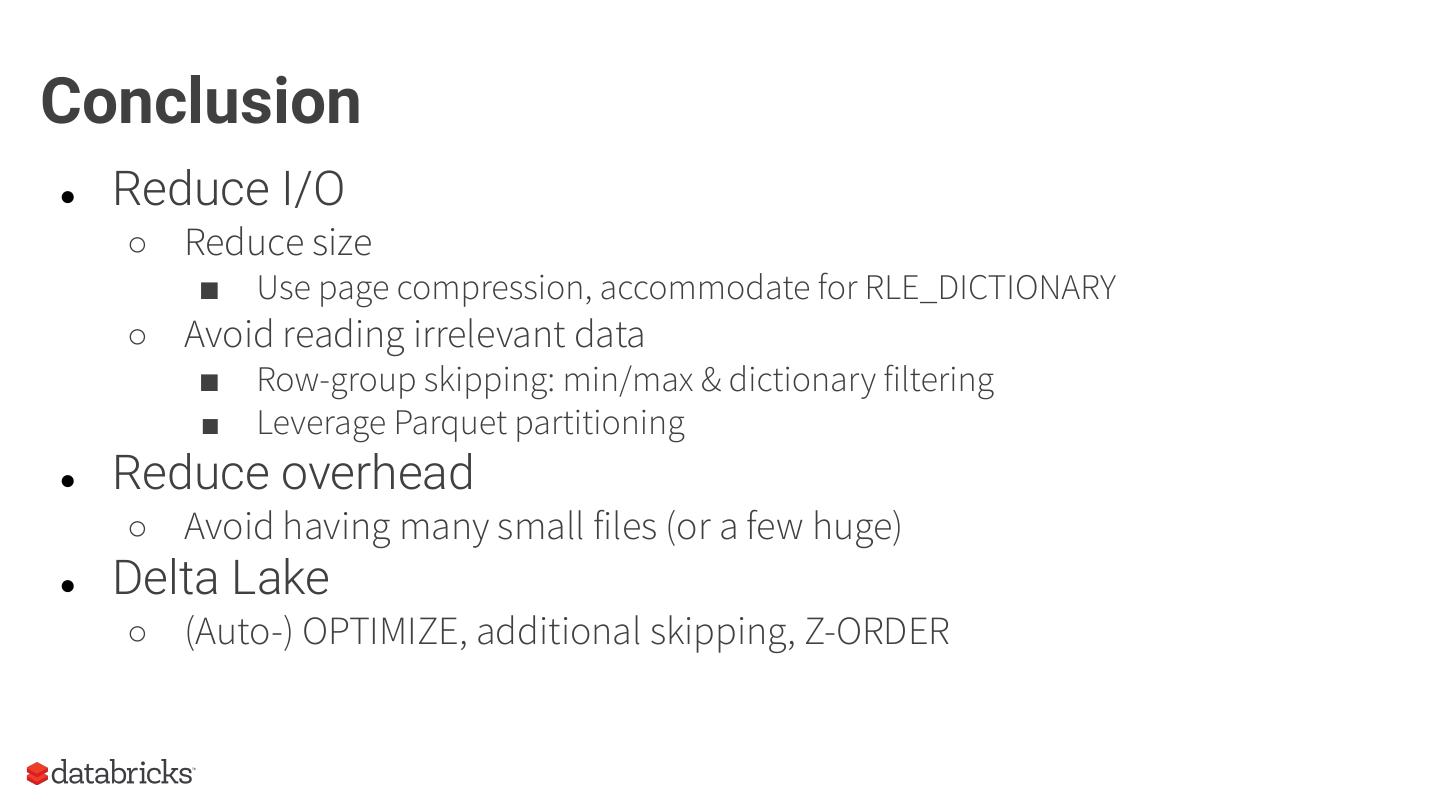
As an introduction, we will provide context around the format, covering the basics of structured data formats and the underlying physical data storage model alternatives (row-wise, columnar and hybrid). Given this context, we will dive deeper into specifics of the Parquet format: representation on disk, physical data organization (row-groups, column-chunks and pages) and encoding schemes. Now equipped with sufficient background knowledge, we will discuss several performance optimization opportunities with respect to the format: dictionary encoding, page compression, predicate pushdown (min/max skipping), dictionary filtering and partitioning schemes. We will learn how to combat the evil that is ‘many small files’, and will discuss the open-source Delta Lake format in relation to this and Parquet in general.
This talk serves both as an approachable refresher on columnar storage as well as a guide on how to leverage the Parquet format for speeding up analytical workloads in Spark using tangible tips and tricks.
相关推荐

基于SeaTunnel快速集成SAP进入Redshift
SeaTunnel

联通数科基于Apache Dolphinscheduler构建Dataops一体化能力
DolphinScheduler社区

DolphinScheduler在铁骑力士集团的落地应用实践
DolphinScheduler社区

Apache DolphinScheduler发版流程与避坑指南
DolphinScheduler社区

Apache SeaTunnel 2.3.8版本更新抢先看!
SeaTunnel

轻松搭建云上数仓 - DolphinScheduler + Serverless Spark
DolphinScheduler社区

Apache DolphinScheduler在BMR中的实践
DolphinScheduler社区

agentUniverse X 浙大太乙平台,开源共建招募令来啦,3万奖金等你拿!
agentUniverse

