展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Vectorized R Execution
in Apache Spark
Hyukjin Kwon, Databricks
#UnifiedDataAnalytics #SparkAISummit
�
3 .Hyukjin Kwon
• Apache Spark PMC and Committer
• Koalas committer
• PySpark, SparkSQL, SparkR, build, etc.
• Active in Spark dev @HyukjinKwon
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Agenda
• SparkR and R interaction
• Native Implementation
• Apache Arrow
• Vectorized Implementation
• Future Work
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .SparkR and R interaction
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Why?
Scala API
Cool!
R API
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Why?
Scala API
12.5x slower … ?
R API
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Why?
Scala API
40x slower … ???
R API
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .createDataFrame
Create Spark DataFrame from R DataFrame and lists.
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .collect
Collect R DataFrame from Spark DataFrame at Driver.
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .dapply
Apply R native function to each partition
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .gapply
Apply R native function on each group.
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Native Implementation
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .SparkR Architecture
Spark
Driver
JVM
Data Sources
R Backend R R
R JVM
JVM
R R
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .Driver implementation
Backend
R JVM
2. R establishes the socket 1. RBackend opens a server port and
connections waits for connections
3. Each SparkR call sends serialized 4. RBackendHandler handles and
data over the socket and waits for process requests. It sends back row by
response row
#UnifiedDataAnalytics #SparkAISummit 15
�
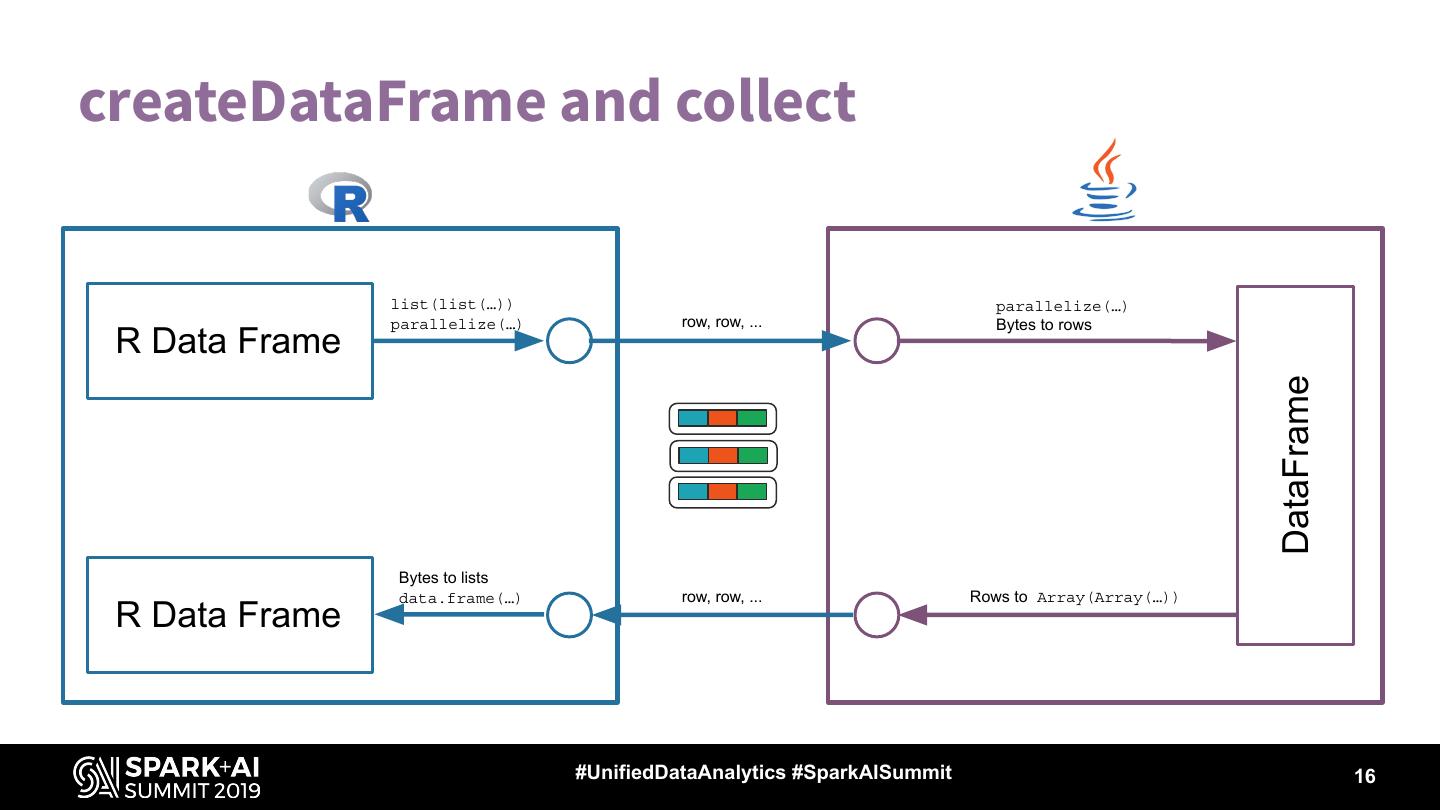
16 .createDataFrame and collect
list(list(…)) parallelize(…)
parallelize(…) row, row, ... Bytes to rows
R Data Frame
DataFrame
Bytes to lists
data.frame(…) row, row, ... Rows to Array(Array(…))
R Data Frame
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Worker Implementation
1. RRunner sends data and serialized R
function through a socket.
JVM 2. R receives the serialized function and
data.
3. R deserializes the function and the
data row by row
4. R executes the function, and send the
R R results back to RRunner.
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .dapply and gapply
row by row row, row, ... serialize row by row
Physical Operator
RRunner
Invoke
R function
row by row row, row, ...
deserialize row by row
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Apache Arrow
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .Apache Arrow
A cross-language development
platform for in-memory data
Columnar In-Memory
SparkR supports Arrow 0.12.1+(?)
#UnifiedDataAnalytics #SparkAISummit 20 20
�
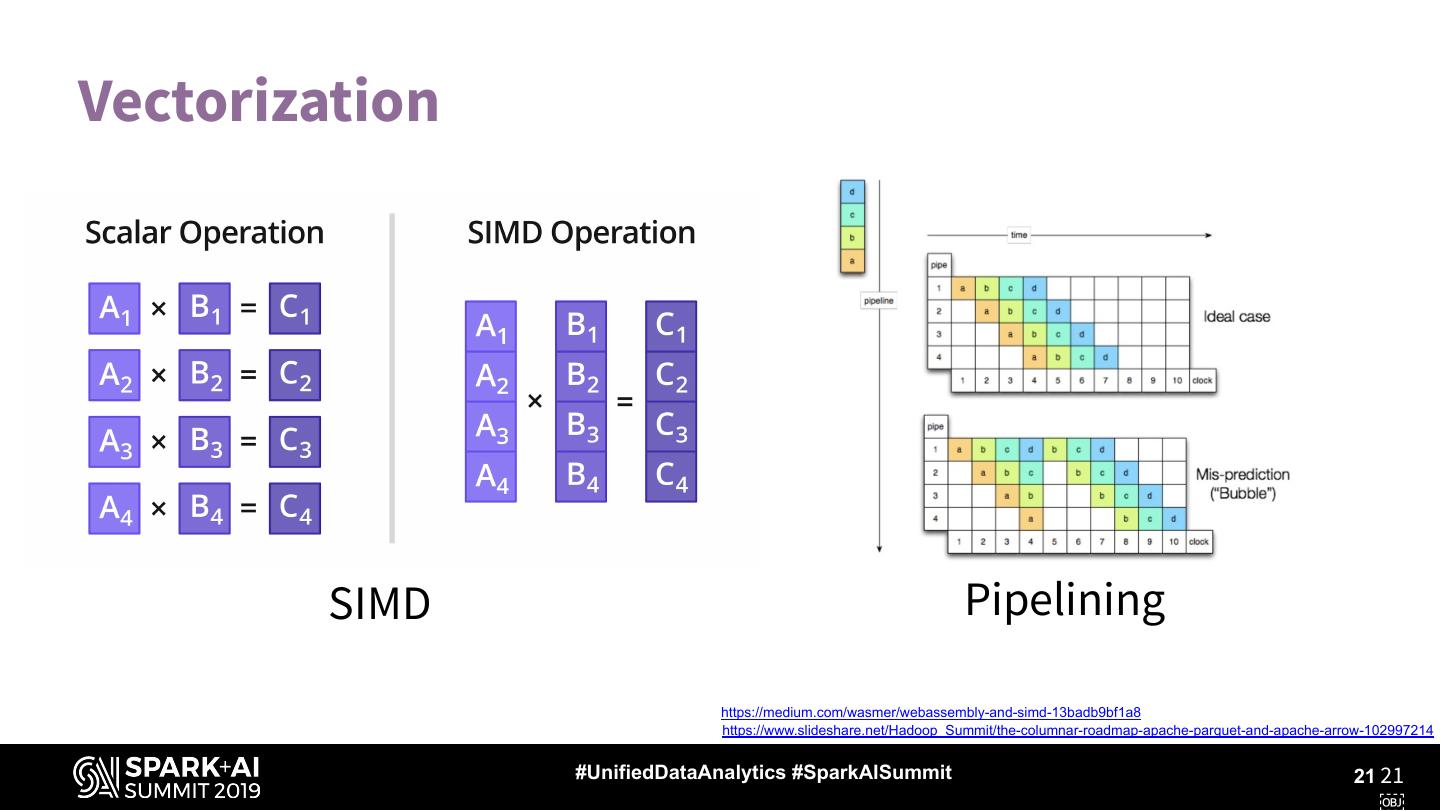
21 .Vectorization
SIMD Pipelining
https://medium.com/wasmer/webassembly-and-simd-13badb9bf1a8
https://www.slideshare.net/Hadoop_Summit/the-columnar-roadmap-apache-parquet-and-apache-arrow-102997214
#UnifiedDataAnalytics #SparkAISummit 21 21
�
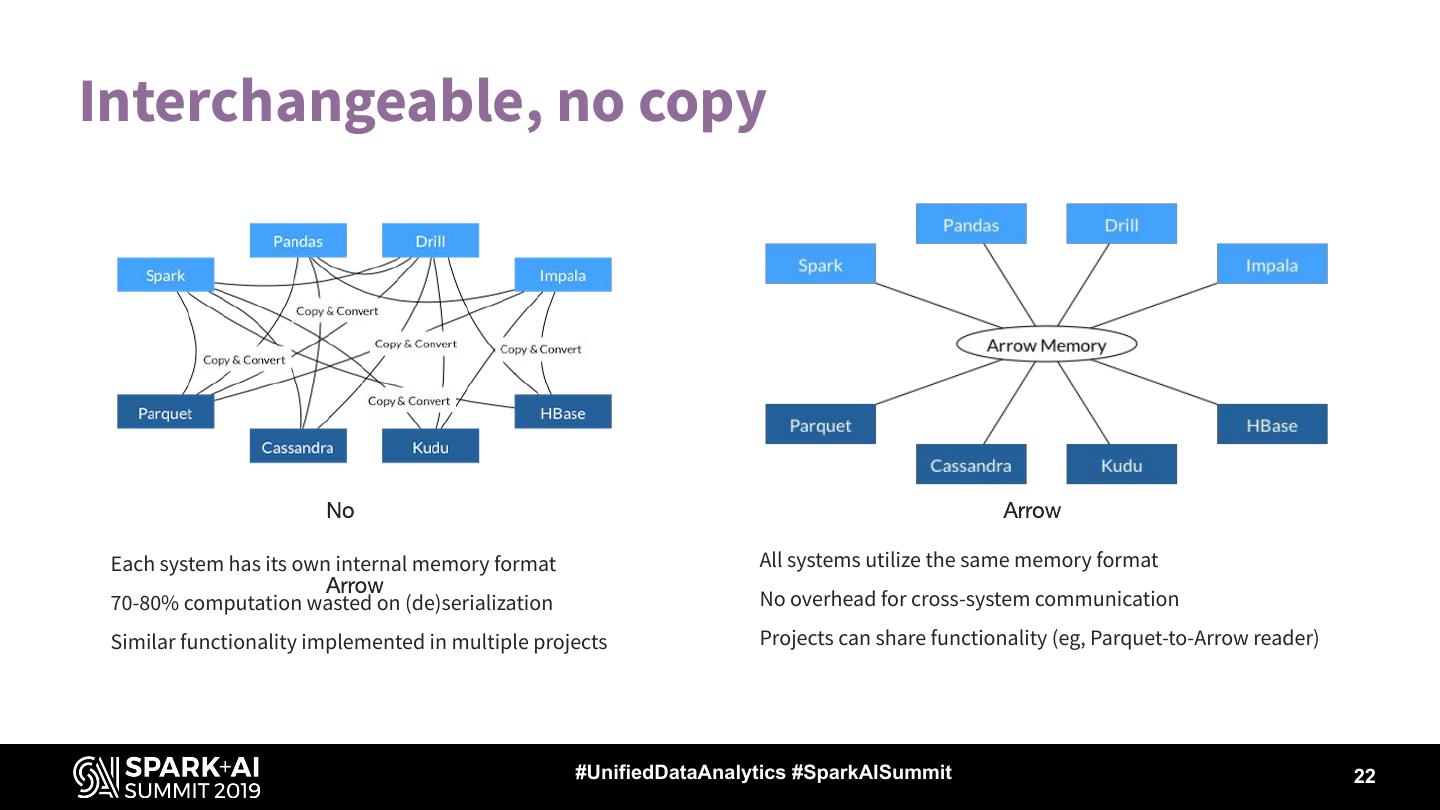
22 .Interchangeable, no copy
Each system has its own internal memory format All systems utilize the same memory format
70-80% computation wasted on (de)serialization No overhead for cross-system communication
Similar functionality implemented in multiple projects Projects can share functionality (eg, Parquet-to-Arrow reader)
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Serialization and deserialization
See also Arrow format
https://sapbr.com/2016/08/15/dictionary-encoding/
https://wesmckinney.com/blog/arrow-streaming-columnar/
#UnifiedDataAnalytics #SparkAISummit 23 23
�
24 ."Portable" Data Frames
Share data and algorithm at ~zero cost
https://www.slideshare.net/wesm/apache-arrow-at-dataengconf-barcelona-2018
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .Vectorized Implementation
#UnifiedDataAnalytics #SparkAISummit 25
�
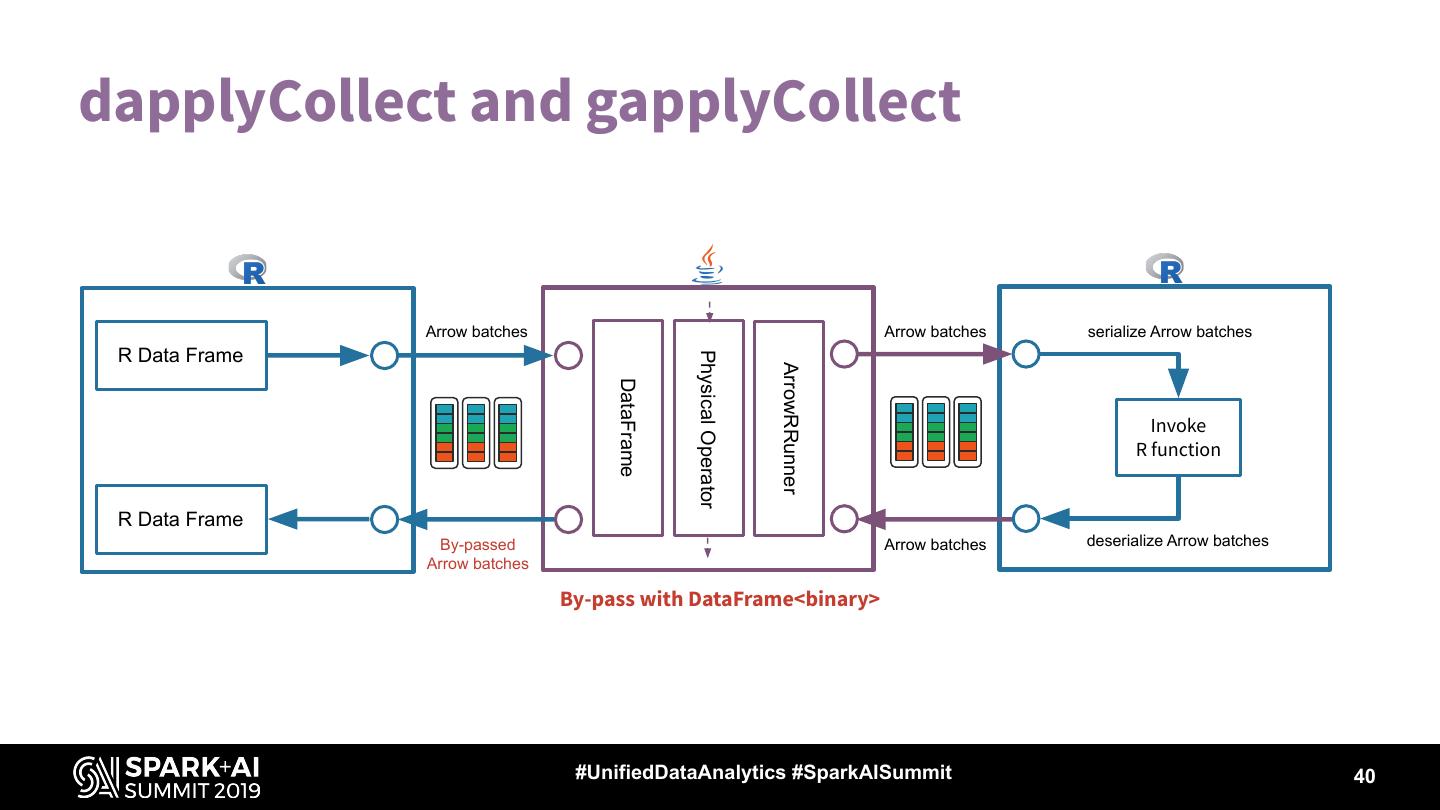
26 .createDataFrame and collect
Use Arrow to Serialize/Deserialize data
Streaming format for Interprocess messaging / communication (IPC)
ArrowWriter and ArrowColumnVector
Communicate JVM and R worker via Socket
createDataFrame in SQLContext.R
readArrowStreamFromFile in SQLUtils.scala
collect in DataFrame.R
collectAsArrowToR in Dataset.scala
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .createDataFrame and collect
list(list(…)) parallelize(…)
parallelize(…) row, row, ... Bytes to rows
R Data Frame
DataFrame
Bytes to lists
data.frame(…) row, row, ... Rows to Array(Array(…))
R Data Frame
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .createDataFrame and collect
Arrow batches Arrow batches Arrow batches to Spark DataFrame
R Data Frame
DataFrame
R Data Frame Arrow batches Arrow batches Spark DataFrame to Arrow bathes
#UnifiedDataAnalytics #SparkAISummit 28
�
29 .Benchmark
createDataFrame collect
No Arrow: 20.85112 secs No Arrow: 240.50508 secs
Arrow: 1.224419 secs Arrow: 5.707062 secs
17x faster 42x faster
#UnifiedDataAnalytics #SparkAISummit 29
�