






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
李铮-openLooKeng Looking back Looking forward
分享
点赞
1
收藏
2
议题
openLooKeng:
Looking Back, Looking Forward
如果您关注openLooKeng的技术分享活动,想必对李铮很熟悉。本次分享,他带我们回顾了openLooKeng针对实际场景所采用的关键技术及优化实践,同时带来了openLooKeng正在开发的核心特性介绍。
展开查看详情
1 .openLooKeng : Looking Back, Looking Forward 李铮 openLooKeng committer
2 .目录 01 openLooKeng介绍 02 Looking back 03 Looking forward 04 总结
3 .目录 01 openLooKeng介绍 02 Looking back 03 Looking forward 04 总结
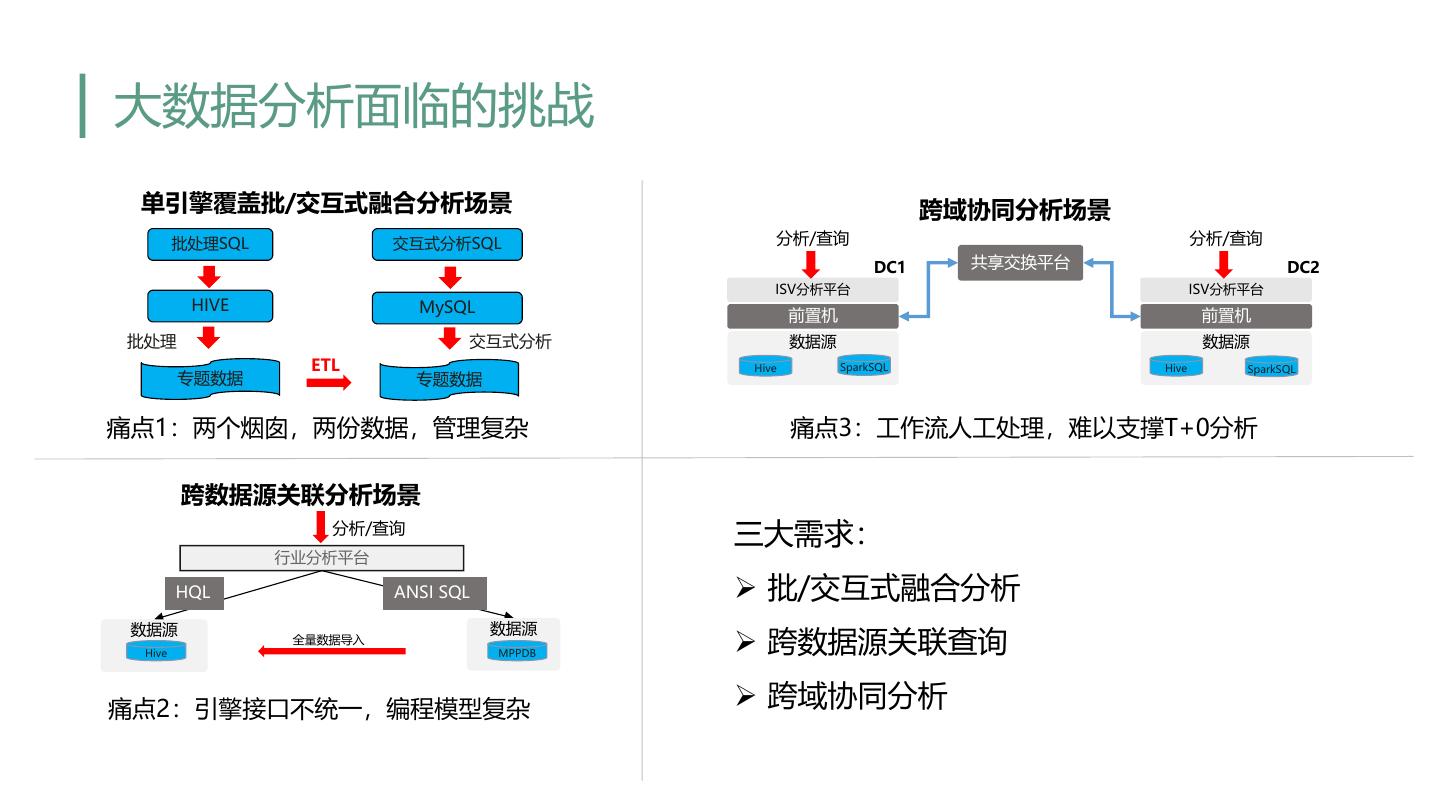
4 .大数据分析面临的挑战 单引擎覆盖批/交互式融合分析场景 跨域协同分析场景 批处理SQL 交互式分析SQL 分析/查询 分析/查询 DC1 共享交换平台 DC2 ISV分析平台 ISV分析平台 HIVE MySQL 前置机 前置机 批处理 交互式分析 数据源 数据源 ETL Hive SparkSQL Hive SparkSQL 专题数据 专题数据 痛点1:两个烟囱,两份数据,管理复杂 痛点3:工作流人工处理,难以支撑T+0分析 跨数据源关联分析场景 分析/查询 三大需求: 行业分析平台 HQL ANSI SQL Ø 批/交互式融合分析 数据源 数据源 Hive 全量数据导入 MPPDB Ø 跨数据源关联查询 痛点2:引擎接口不统一,编程模型复杂 Ø 跨域协同分析
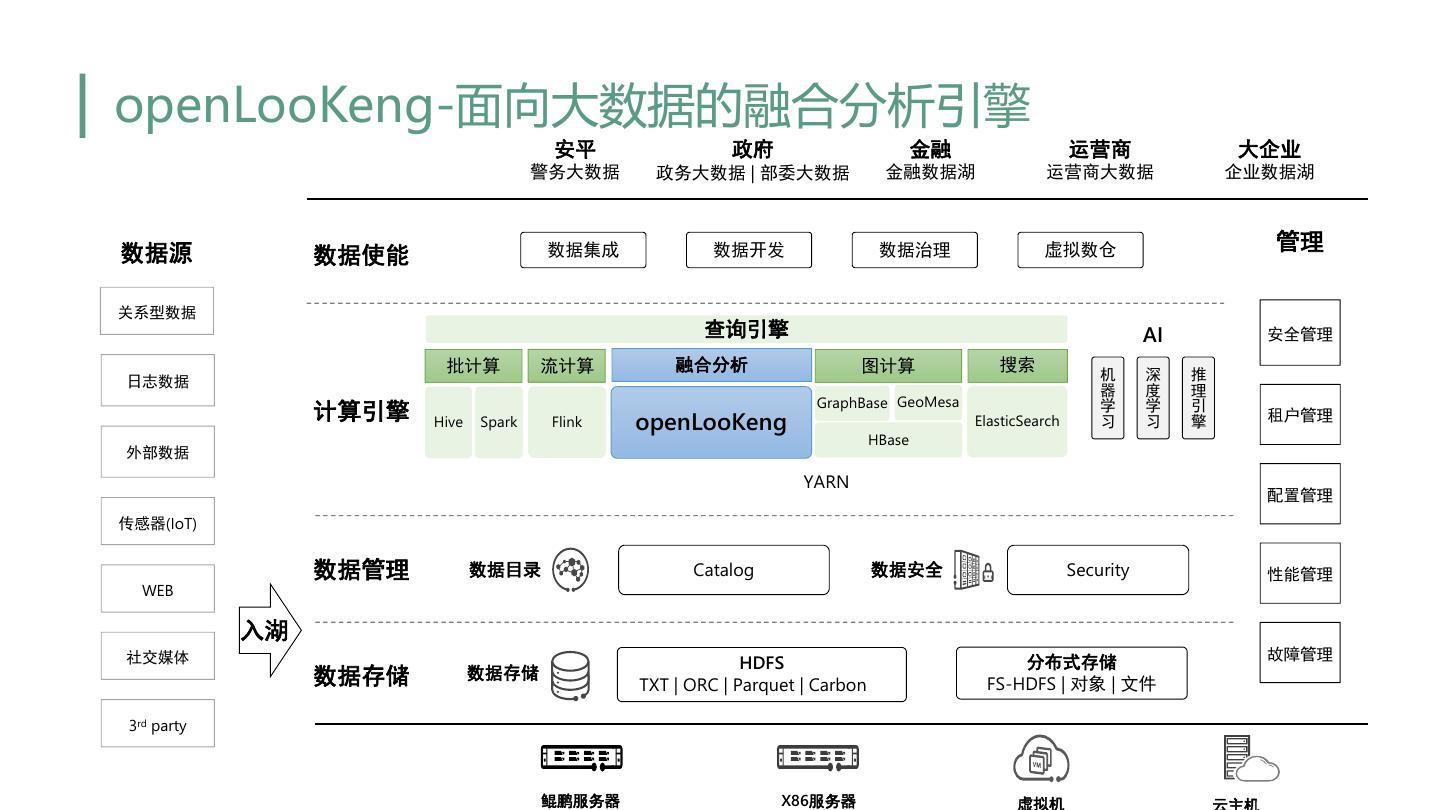
5 .openLooKeng-面向大数据的融合分析引擎 安平 政府 金融 运营商 大企业 警务大数据 政务大数据 | 部委大数据 金融数据湖 运营商大数据 企业数据湖 数据源 数据集成 数据开发 数据治理 虚拟数仓 管理 数据使能 关系型数据 查询引擎 AI 安全管理 机器学习 深度学习 推理引擎 批计算 流计算 融合分析 图计算 搜索 日志数据 GraphBase GeoMesa 计算引擎 Hive Spark Flink openLooKeng ElasticSearch 租户管理 HBase 外部数据 YARN 配置管理 传感器(IoT) 数据管理 数据目录 Catalog 数据安全 Security 性能管理 WEB 入湖 故障管理 社交媒体 HDFS 分布式存储 数据存储 数据存储 TXT | ORC | Parquet | Carbon FS-HDFS | 对象 | 文件 3rd party 鲲鹏服务器 X86服务器 虚拟机
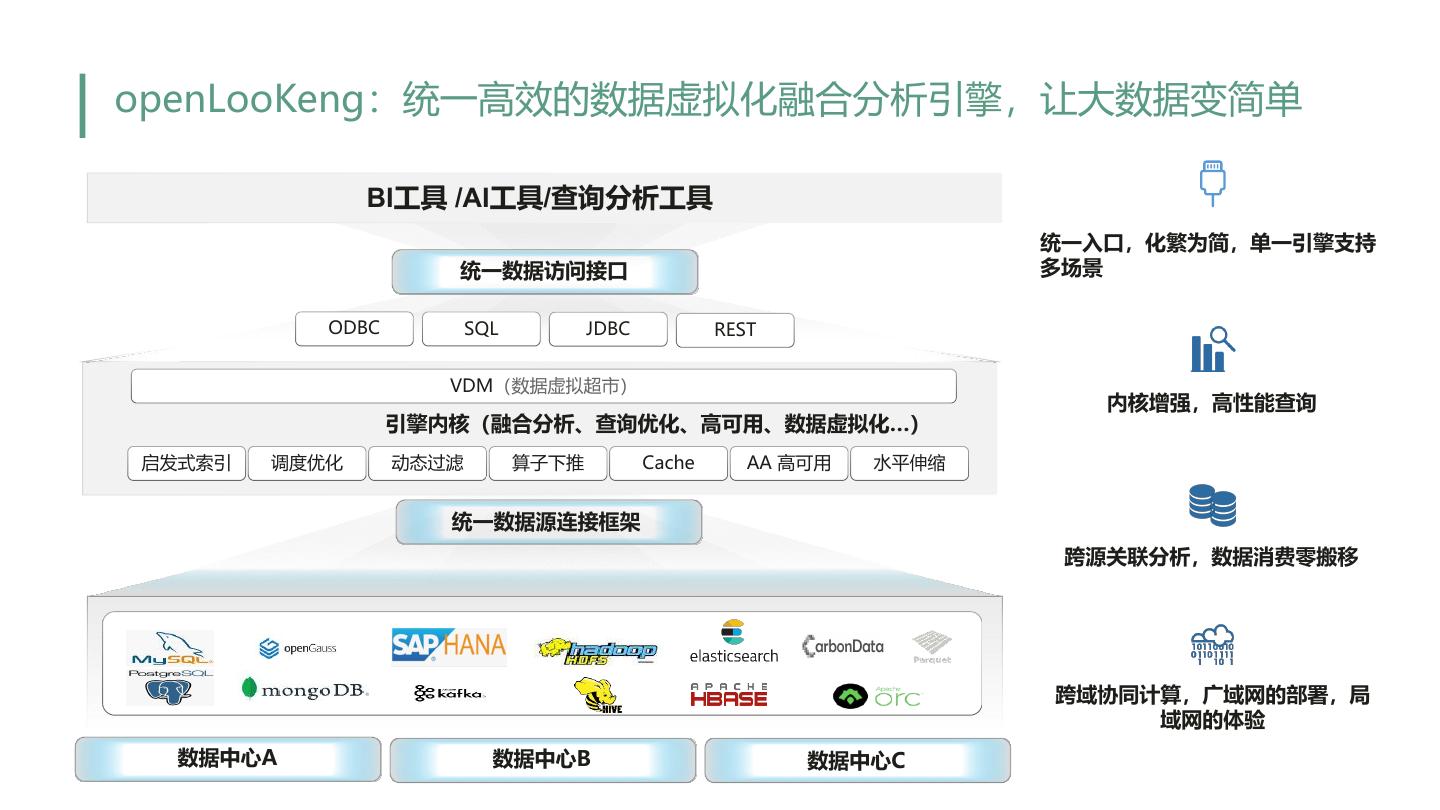
6 .openLooKeng:统一高效的数据虚拟化融合分析引擎,让大数据变简单 BI工具 /AI工具/查询分析工具 统一入口,化繁为简,单一引擎支持 统一数据访问接口 多场景 ODBC SQL JDBC REST VDM(数据虚拟超市) 内核增强,高性能查询 引擎内核(融合分析、查询优化、高可用、数据虚拟化…) 启发式索引 调度优化 动态过滤 算子下推 Cache AA 高可用 水平伸缩 统一数据源连接框架 跨源关联分析,数据消费零搬移 跨域协同计算,广域网的部署,局 域网的体验 数据中心A 数据中心B 数据中心C
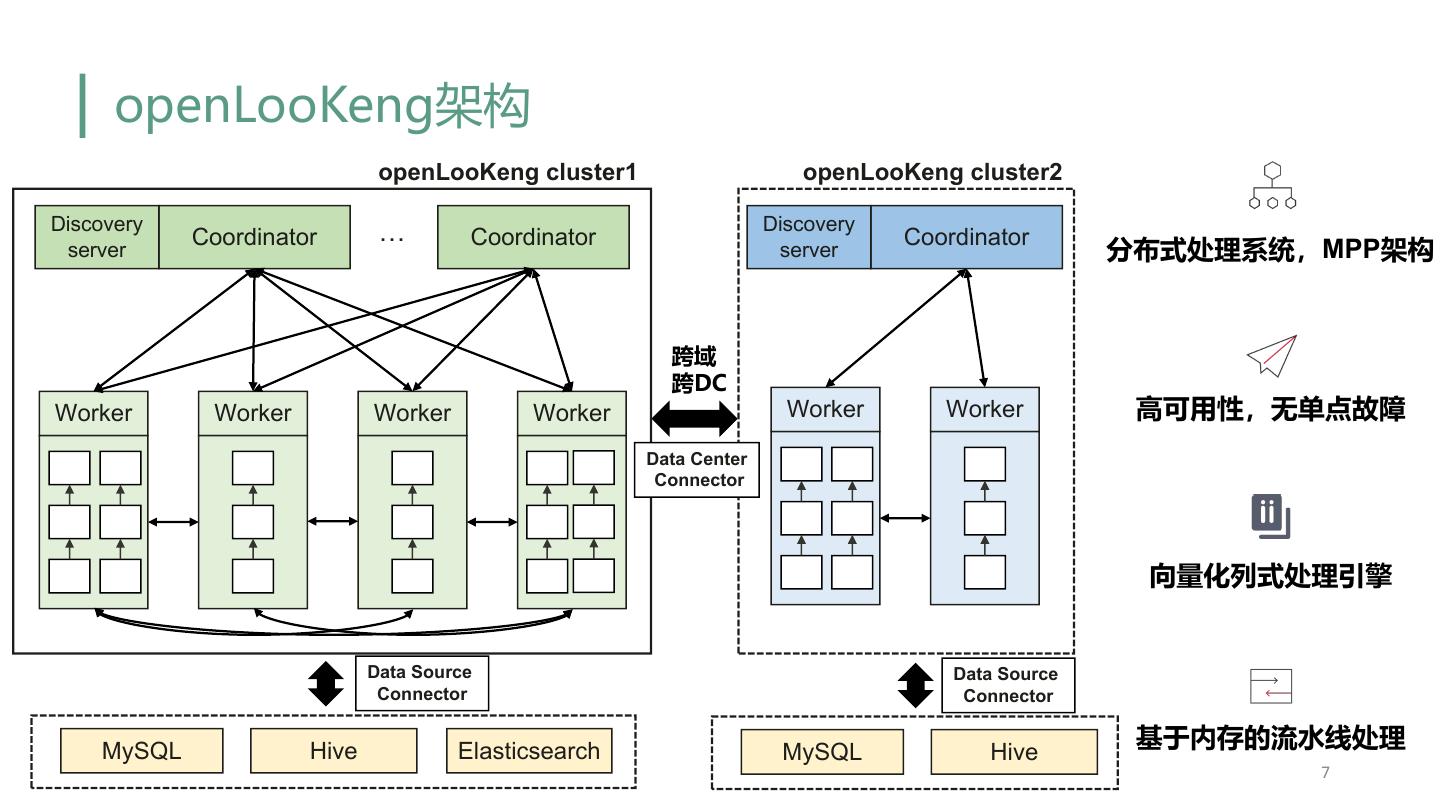
7 . openLooKeng架构 openLooKeng cluster1 openLooKeng cluster2 Discovery … Discovery Coordinator Coordinator Coordinator server server 分布式处理系统,MPP架构 跨域 跨DC Worker Worker Worker Worker Worker Worker 高可用性,无单点故障 Data Center Connector 向量化列式处理引擎 Data Source Data Source Connector Connector MySQL Hive Elasticsearch MySQL Hive 基于内存的流水线处理 7
8 .目录 01 openLooKeng介绍 02 Looking back 03 Looking forward 04 总结
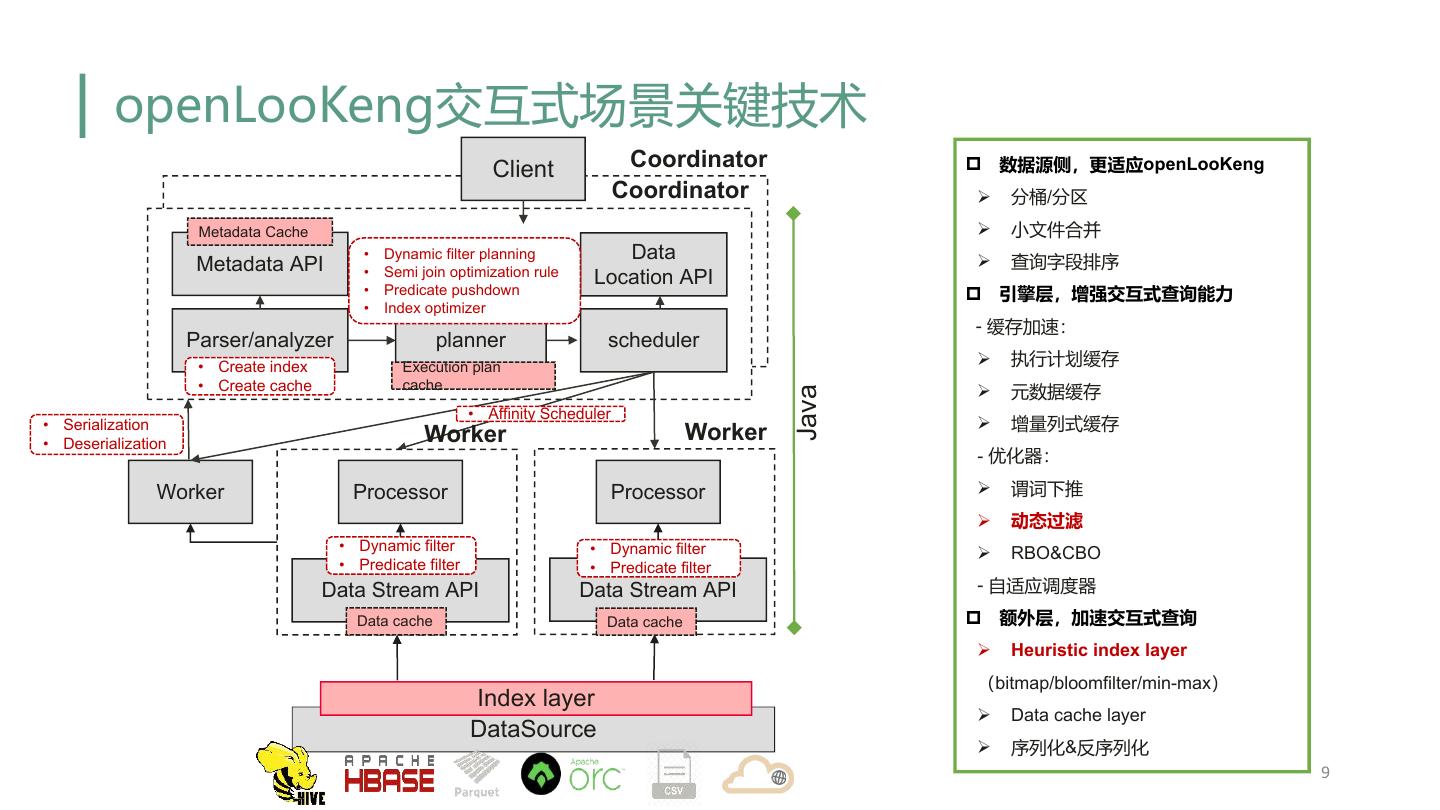
9 . openLooKeng交互式场景关键技术 Client Coordinator p 数据源侧,更适应openLooKeng Coordinator Ø 分桶/分区 Metadata Cache Ø 小文件合并 • Dynamic filter planning Data Metadata API • Semi join optimization rule Ø 查询字段排序 Location API • Predicate pushdown p 引擎层,增强交互式查询能力 • Index optimizer - 缓存加速: Parser/analyzer planner scheduler • Create index Execution plan Ø 执行计划缓存 • Create cache cache Ø 元数据缓存 Java • Affinity Scheduler • Serialization Ø 增量列式缓存 • Deserialization Worker Worker - 优化器: Worker Processor Processor Ø 谓词下推 Ø 动态过滤 • Dynamic filter • Dynamic filter Ø RBO&CBO • Predicate filter • Predicate filter Data Stream API Data Stream API - 自适应调度器 Data cache Data cache p 额外层,加速交互式查询 Ø Heuristic index layer (bitmap/bloomfilter/min-max) Index layer Ø Data cache layer DataSource Ø 序列化&反序列化 9
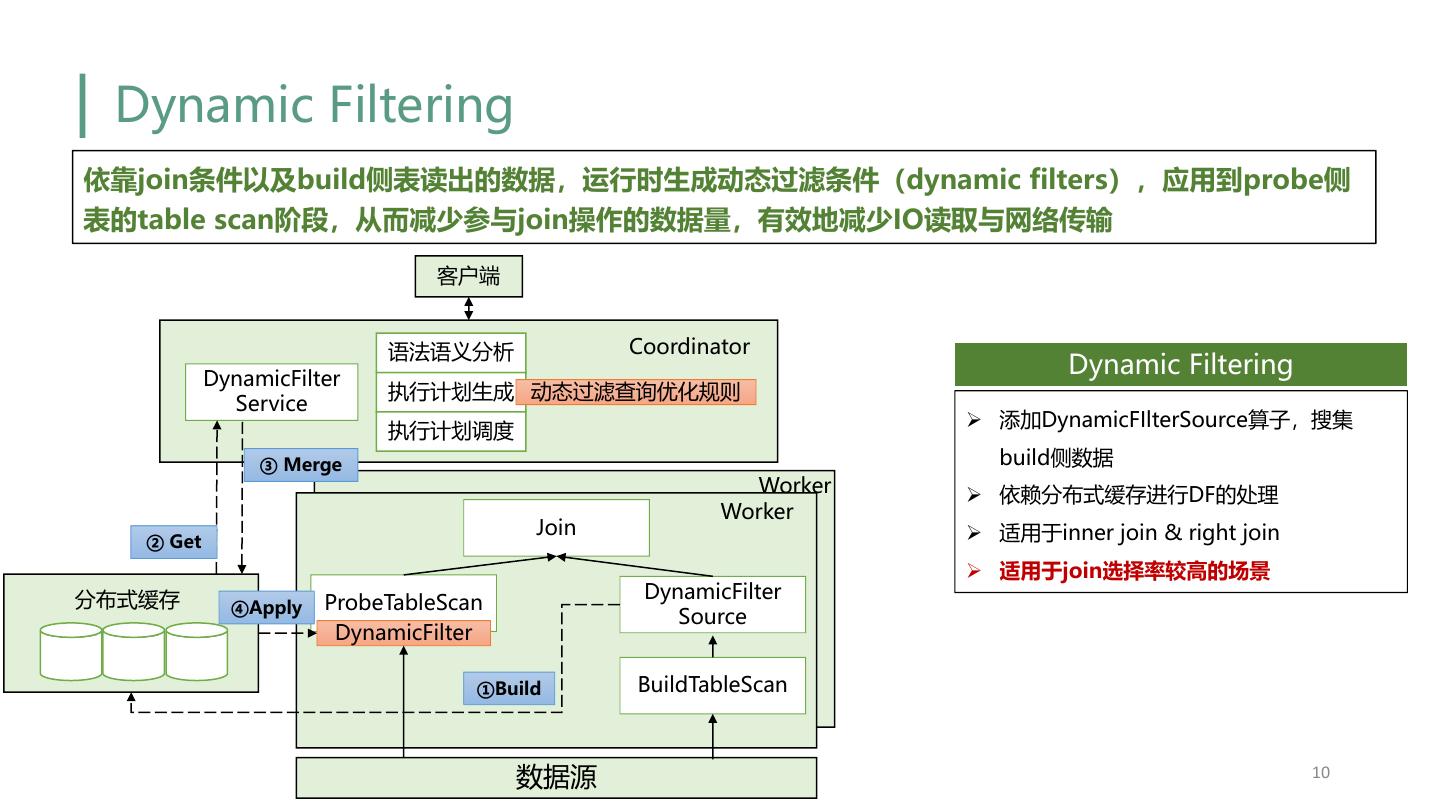
10 . Dynamic Filtering 依靠join条件以及build侧表读出的数据,运行时生成动态过滤条件(dynamic filters),应用到probe侧 表的table scan阶段,从而减少参与join操作的数据量,有效地减少IO读取与网络传输 客户端 语法语义分析 Coordinator DynamicFilter Dynamic Filtering 执行计划生成 动态过滤查询优化规则 Service Ø 添加DynamicFIlterSource算子,搜集 执行计划调度 ③ Merge build侧数据 Worker Ø 依赖分布式缓存进行DF的处理 Worker Join Ø 适用于inner join & right join ② Get Ø 适用于join选择率较高的场景 分布式缓存 DynamicFilter ④Apply ProbeTableScan Source DynamicFilter ①Build BuildTableScan 数据源 10
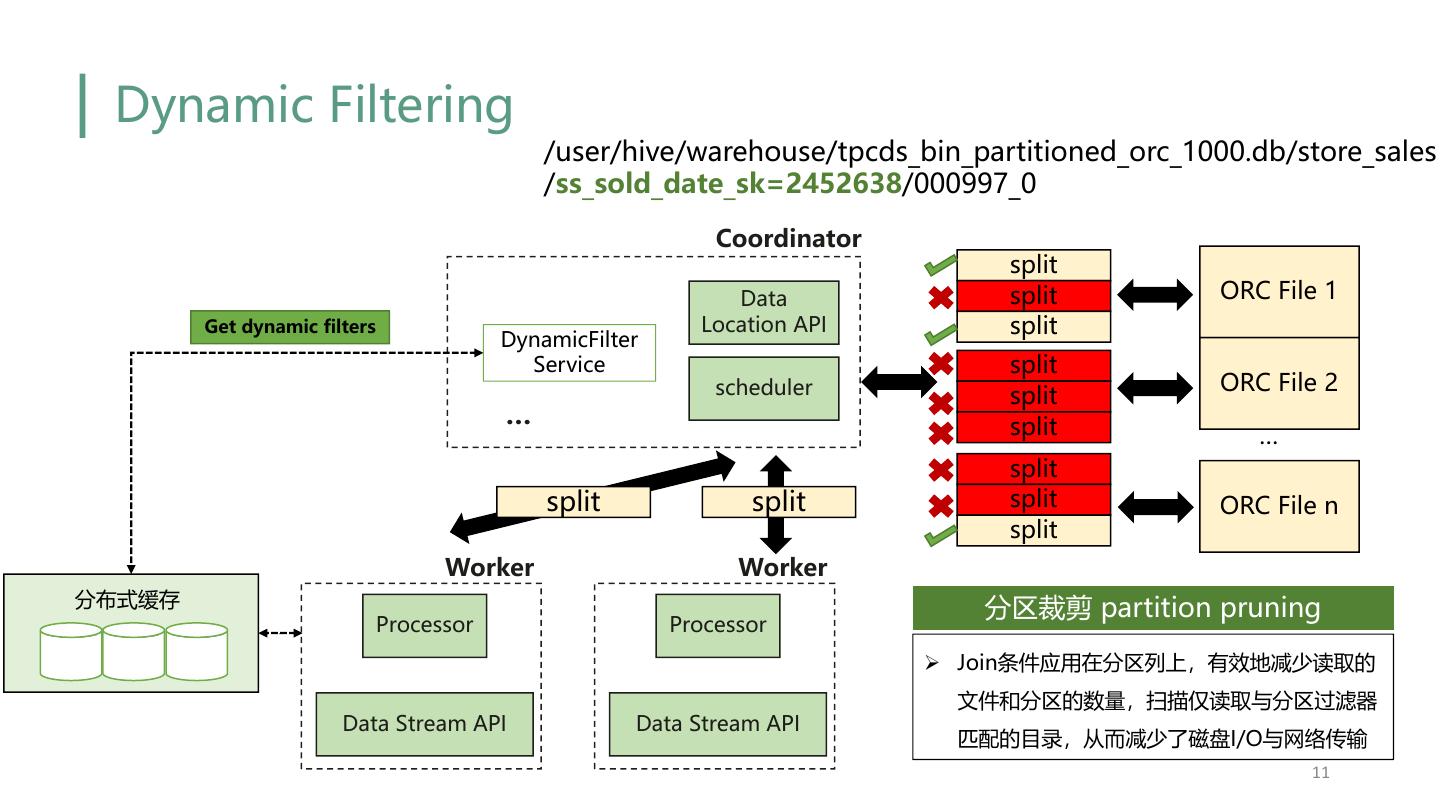
11 . Dynamic Filtering /user/hive/warehouse/tpcds_bin_partitioned_orc_1000.db/store_sales /ss_sold_date_sk=2452638/000997_0 Coordinator split Data split ORC File 1 Get dynamic filters Location API split DynamicFilter Service split scheduler ORC File 2 split … split … split split split split ORC File n split Worker Worker 分布式缓存 分区裁剪 partition pruning Processor Processor Ø Join条件应用在分区列上,有效地减少读取的 文件和分区的数量,扫描仅读取与分区过滤器 Data Stream API Data Stream API 匹配的目录,从而减少了磁盘I/O与网络传输 11
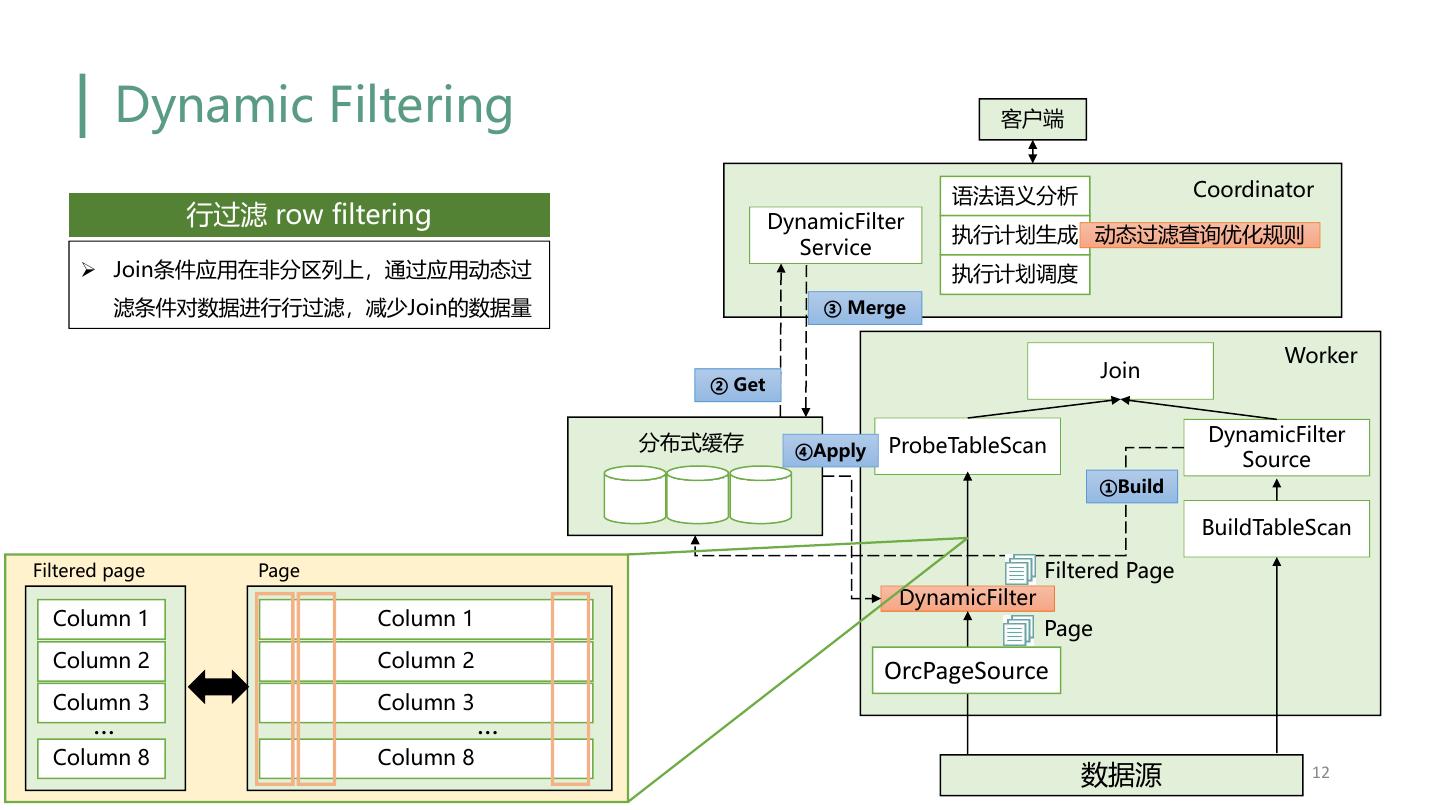
12 . Dynamic Filtering 客户端 语法语义分析 Coordinator 行过滤 row filtering DynamicFilter 执行计划生成 动态过滤查询优化规则 Service Ø Join条件应用在非分区列上,通过应用动态过 执行计划调度 滤条件对数据进行行过滤,减少Join的数据量 ③ Merge Worker Join ② Get 分布式缓存 DynamicFilter ④Apply ProbeTableScan Source ①Build BuildTableScan Filtered page Page Filtered Page DynamicFilter Column 1 Column 1 Page Column 2 Column 2 OrcPageSource Column 3 Column 3 … … Column 8 Column 8 数据源 12
13 . 跨域Dynamic Filtering DC-2 Coordinator:1)将DC-1的BF filter以QueryId为Key存入到hazelcast;2)判断当前query是否存在跨域dynamic filter,存在,设置session中的cross- region-dynamic-filter;3)CN生产执行计划Plan,从Plan中Query的列名到Plan的outputSymbols的映射关系,存入hazelcast;4)判断Plan的 TableScanNode是否存在DC table,如存在,则标记,可能存在继续下推BF filter的可能。 DC-2 Worker:1) CrossRegionDynamicFilterOp从hazelcast中取出BF filter和outputSymbols,判断是否存在过滤列,存在则应用filter对Page进行过滤;2) TableScanOperator应用filter和步骤一类似;3)如果TableScanNode存在DC table,则生成新的BF filter并存入hazelcast,用于发送给下一级DC。
14 . Heuristic index架构 Client Coordinator Coordinator Data Metadata API Location API Heuristic index • Index optimizer HIndex-稀疏索引 Ø 提供统一的索引框架 Parser/analyzer planner scheduler Ø 支持多种索引结构 • Create index Ø 稀疏索引:Bloomfilter、Min-Max • Affinity Scheduler Worker Worker Ø 稠密索引:Bitmap Ø 任务调度阶段: Worker Processor Processor Ø 裁剪Split,减少调度到Worker的任务数 • Index filtering • Index filtering Ø 支持基于索引的亲和性调度 Data Stream API Data Stream API Ø 数据读取阶段: Ø 减少加载到计算侧内存的数据量 HIndex-稠密索引 Index layer DataSource 14
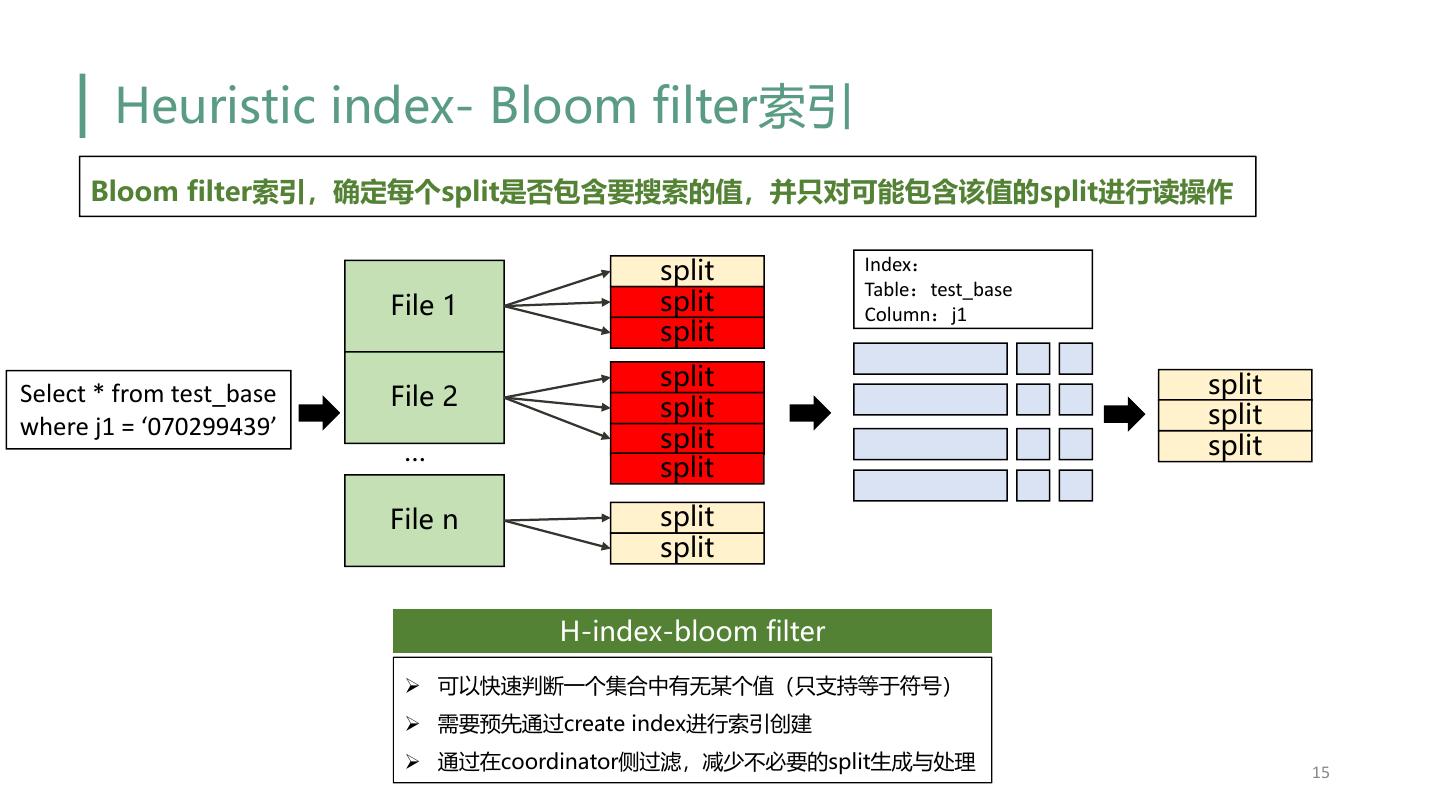
15 . Heuristic index- Bloom filter索引 Bloom filter索引,确定每个split是否包含要搜索的值,并只对可能包含该值的split进行读操作 split Index: Table:test_base File 1 split Column:j1 split split split Select * from test_base File 2 split split where j1 = ‘070299439’ split … split split File n split split H-index-bloom filter Ø 可以快速判断一个集合中有无某个值(只支持等于符号) Ø 需要预先通过create index进行索引创建 Ø 通过在coordinator侧过滤,减少不必要的split生成与处理 15
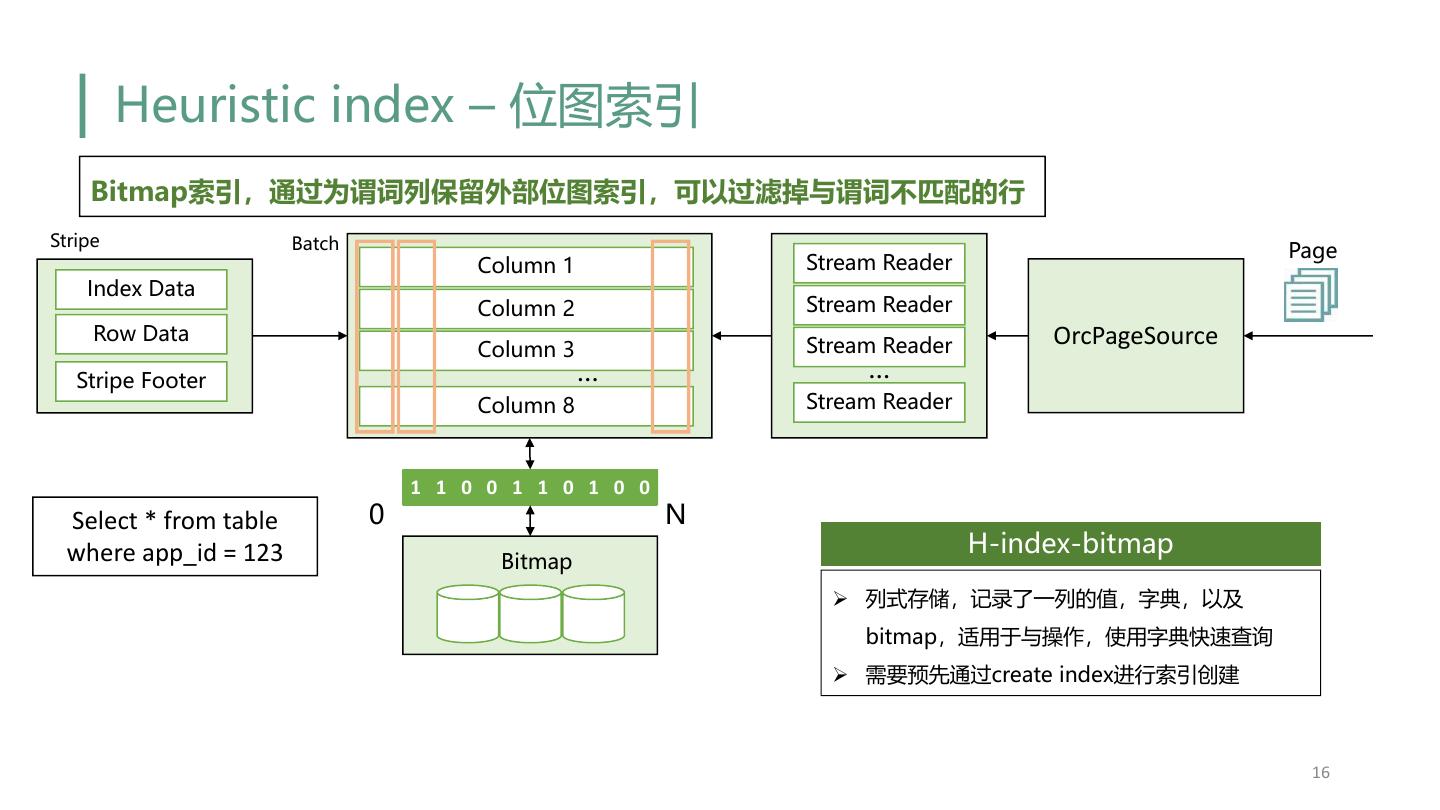
16 . Heuristic index – 位图索引 Bitmap索引,通过为谓词列保留外部位图索引,可以过滤掉与谓词不匹配的行 Stripe Batch Page Column 1 Stream Reader Index Data Column 2 Stream Reader Row Data Column 3 Stream Reader OrcPageSource Stripe Footer … … Column 8 Stream Reader 1 1 0 0 1 1 0 1 0 0 Select * from table 0 N where app_id = 123 H-index-bitmap Bitmap Ø 列式存储,记录了一列的值,字典,以及 bitmap,适用于与操作,使用字典快速查询 Ø 需要预先通过create index进行索引创建 16
17 .Heuristic index – StarTree index 点查场景 Star Tree技术:通过预聚合技术,降低高基维的查 询的延迟,达到ms级别的查询要求
18 .目录 01 openLooKeng介绍 02 Looking back 03 Looking forward 04 总结
19 . 从openLooKeng看大数据引擎性能的优化方向 ① 数据加载: Ø 存算协同:存算间缺乏有效协同 Compute Filter ③ ② Massive ② 数据计算: Partitioned Ø 有效计算:算力消耗在无关控制流上 Join Parallel Execution Ø 加速比:大规模集群的加速比小于0.5 Ø CPU/网络:受限数据处理逻辑无法充分利用 Scan Scan ① ③ 数据交换: Storage Ø 数据交换格式:不能根据网络特性进行自动调整 HDFS | Cloud Storage | S3 | Ceph Ø 序列化:序列化、反序列化的性能损耗 Ø Zero-Copy:内存和操作系统缓冲区的数据拷贝 大数据引擎性能优化方向集中在Optimizer和Runtime两个领域
20 .构筑进一步构建更好大数据生态? 烟囱式优化 统一Runtime底座 OLK Spark Hive Flink Presto Spark Hive Flink ? Local Local Local Local optimization optimization optimization optimization 通用 异构 计算 鲲鹏 X86 昇腾 GPGPU FPGA DPU 计算 计算 各个引擎各自垂直优化 实现native runtime算子 一个底座支撑不同引擎,减少重复优化工作 使用codegen对算子进行优化 充分挖掘通用、异构算力
21 . 现有大数据引擎结构 计算引擎 数据缓存 数据源 数据接入 数据交换 数据处理 数据使用 Hive BI AI … … 数据格式
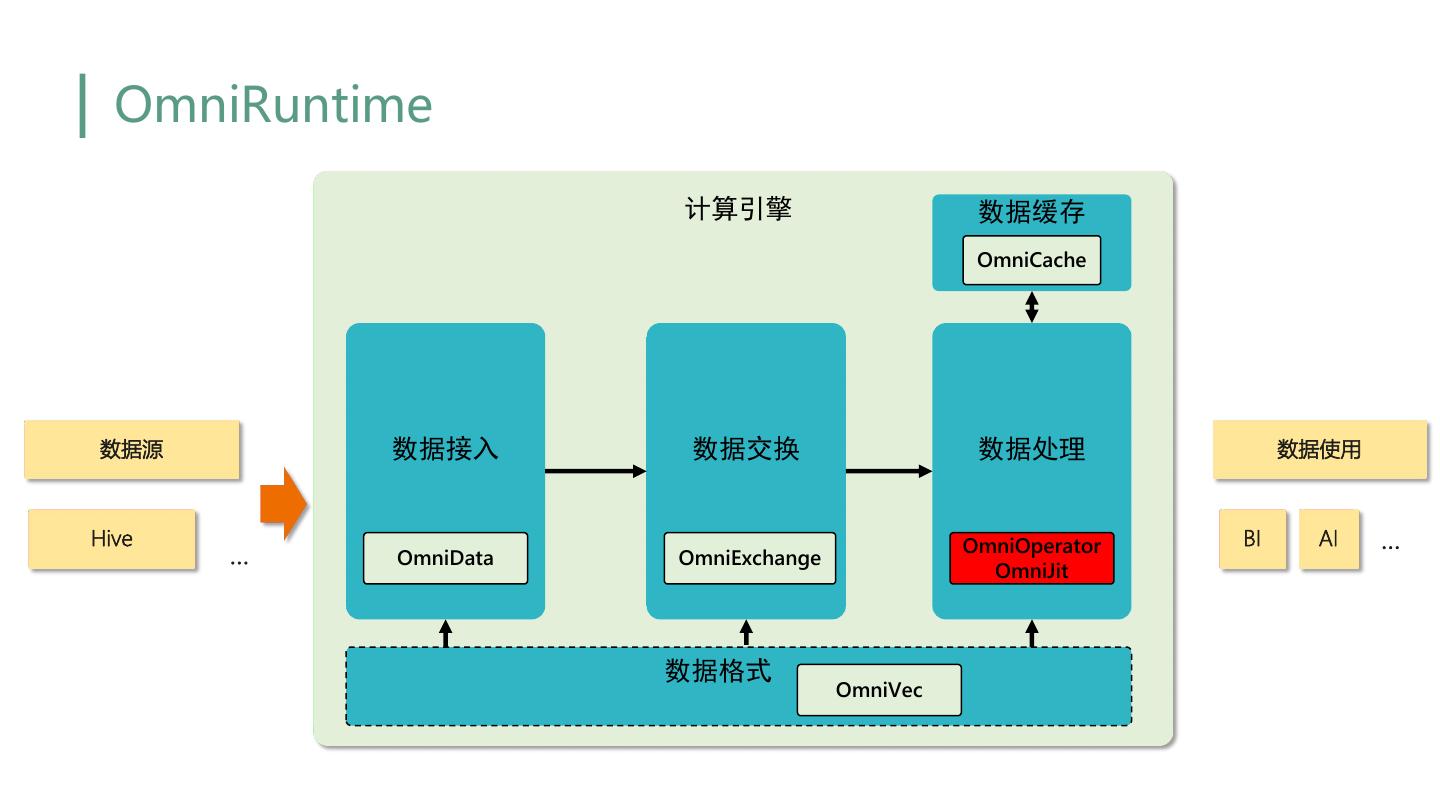
22 . OmniRuntime 计算引擎 数据缓存 OmniCache 数据源 数据接入 数据交换 数据处理 数据使用 Hive OmniOperator BI AI … … OmniData OmniExchange OmniJit 数据格式 OmniVec
23 . OmniRuntime - 大数据的Runtime底座 OmniRuntime - Common Big Data Runtime Java | Scala | C/C++ | Python 多语言支持实现大数据生态完整支撑 Manages the OmniVec to be reuse across queries OmniJit实现鲲鹏硬件垂直优化 OmniCache 关系型缓存,支持跨进程数据共享 Huawei JDK优化实现生态协同 Omni Exchange In memory data structure holding column data OmniVec 列式内存数据格式,支持零拷贝、向量化运算 OmniJit Manages operator hardening OmniOp 编程框架与算子生态,透明数据入参固化 Enable operator pushdown OmniData 存算协同 数据加载: 数据计算: 数据交换: ØOmniData 存算协同,数据过滤 ØOmniOp Native算子 ØOmniExchange TCP/RDMA兼容 ØOmniCache 数据重用 ØOmniJit 数据驱动控制流优化,ARM垂直优化 Ø高速传输,插件式Shuffle框架 ØOmniVec 列式内存数据格式,向量化运算 ØOmniVec 堆外内存,真正零拷贝
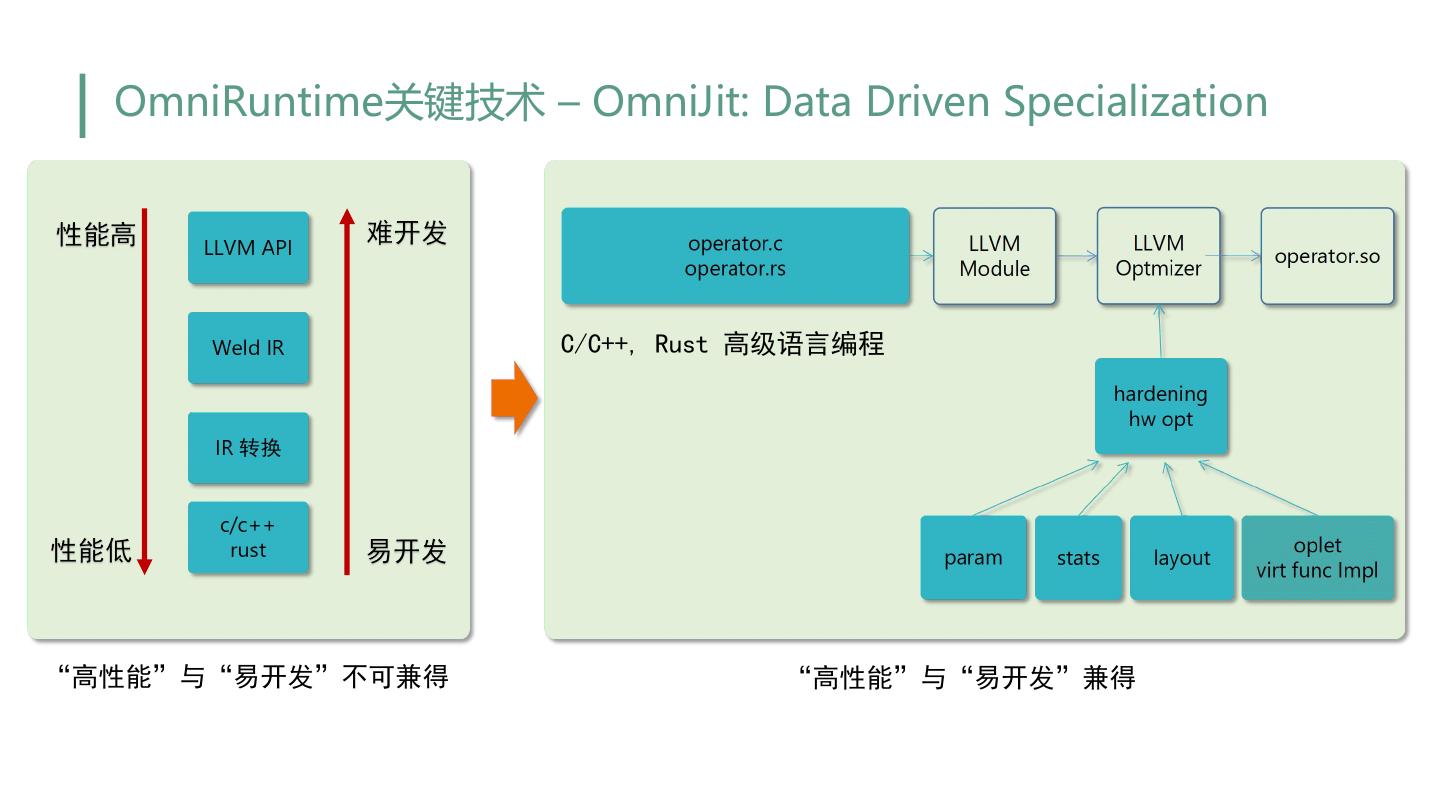
24 . OmniRuntime关键技术 – OmniJit: Data Driven Specialization C/C++, Rust 高级语言编程 “高性能”与“易开发”不可兼得 “高性能”与“易开发”兼得
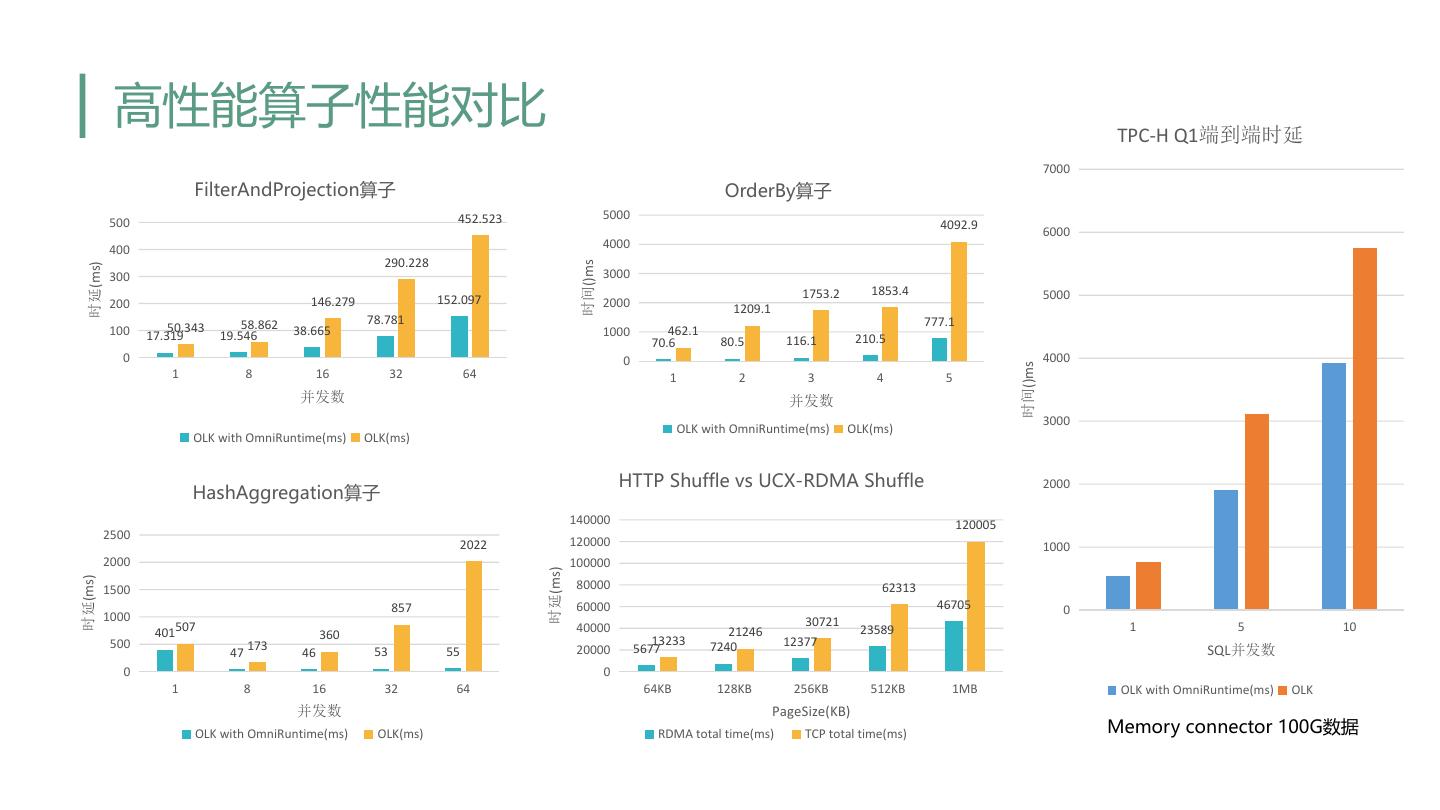
25 . OmniRuntime关键技术 – OmniJit: Data Driven Specialization int HashAggregation算子 优化前后性能对比 for i int dataset { if if type(i) == int {…}; 7 Compiler if type(i) == float {…}; } 6 float exit 5 4 单位:s params OmniJit layout 3 2 1 int 0 wall cpu wall cpu wall cpu wall cpu wall cpu 1 8 16 32 64 并发数 exit Original Optimized
26 . OmniRuntime大数据引擎部署图 OmniRuntime模块 计算引擎coordinator 引擎适配OmniRuntime模块 引擎与其他模块(解耦部分) 计算引擎worker 计算引擎worker JavaRuntime JavaRuntime ① OmniRuntime提供.so文件, OmniRuntime OmniRuntime OmniOperator OmniOperator jar文件,提供C++以及Java接 JavaOperator JavaOperator 口调用API Java Wrapper Java Wrapper ② 操作系统需要提供对LLVM12 JVM JNI JVM JNI 支持,否则需要更新操作系统 ③ Java版本需要对JNI支持 操作系统 OmniRuntime libs 操作系统 OmniRuntime libs ④ 对于硬件解耦,支持X86与 硬件 鲲鹏 X86 硬件 鲲鹏 X86 ARM,操作系统LLVM支持屏 蔽底层硬件差异 26
27 .目录 01 openLooKeng介绍 02 Looking back 03 Looking forward 04 总结
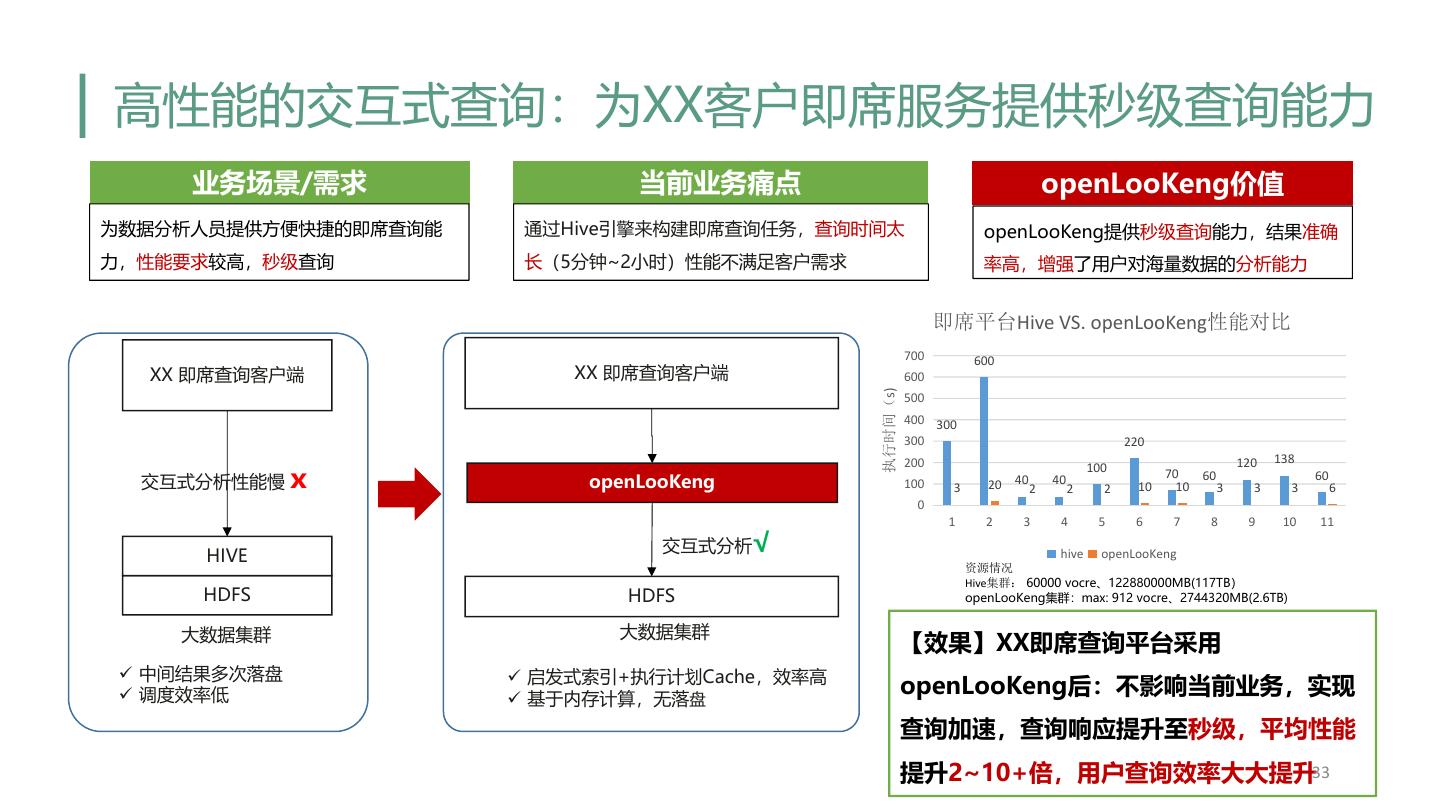
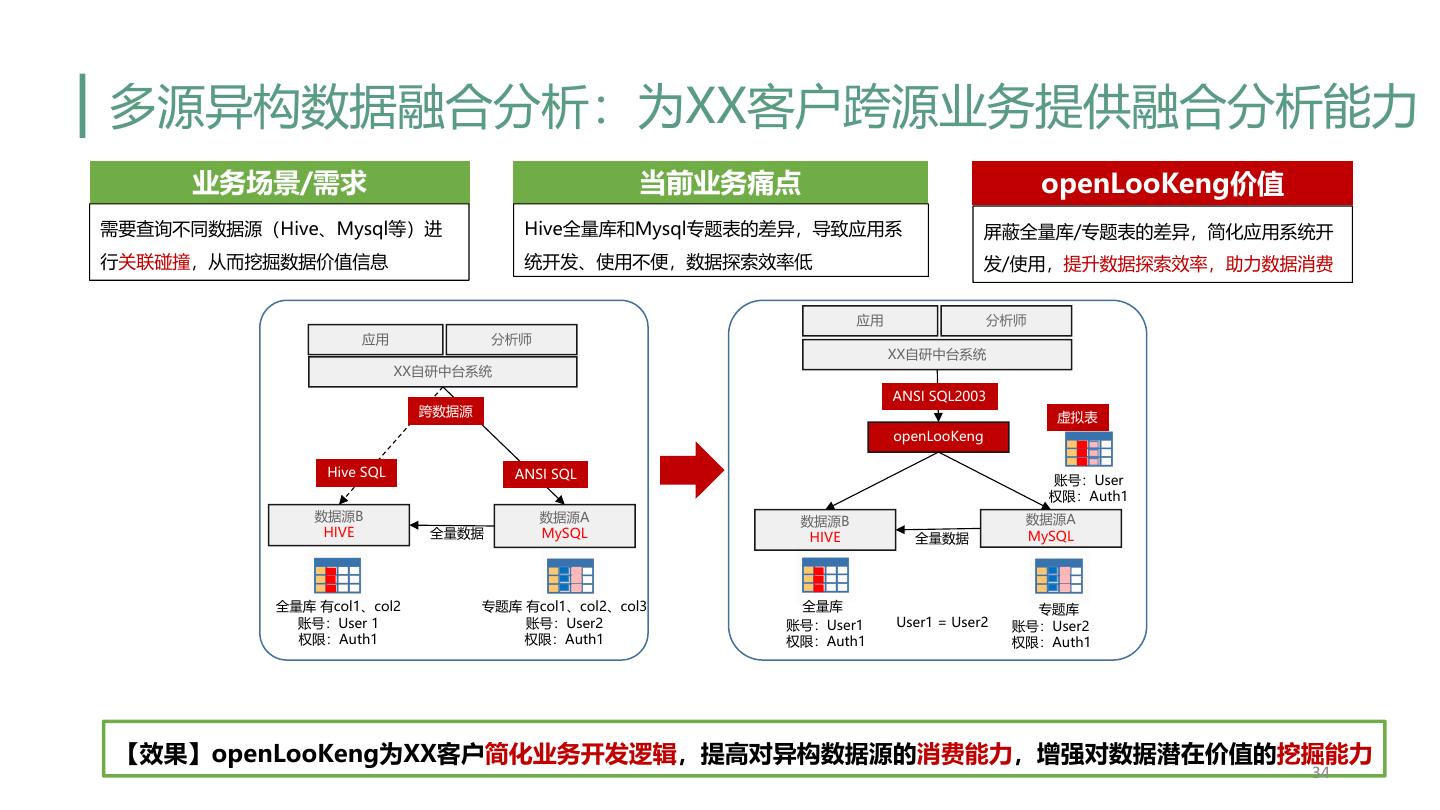
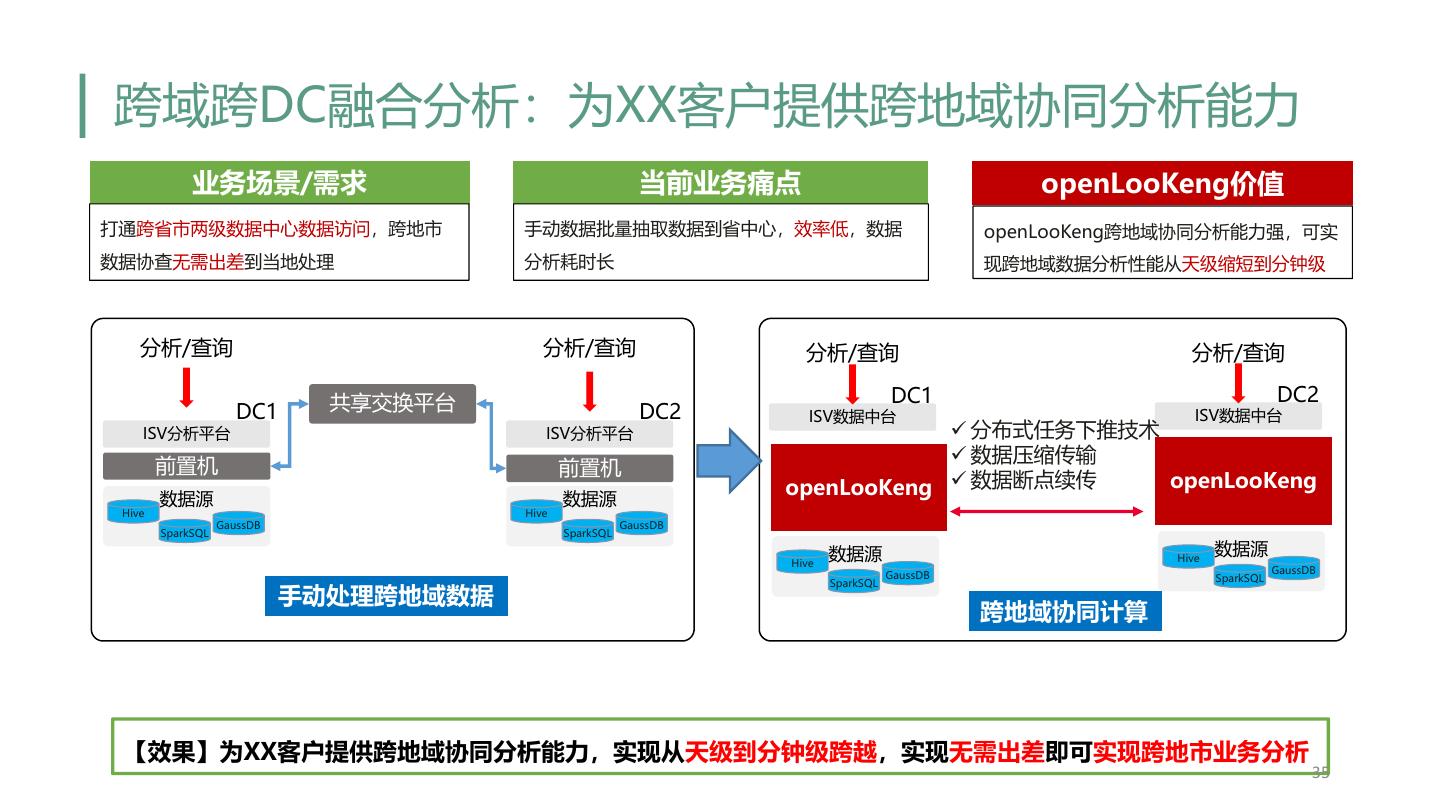
28 . 总结 • openLooKeng愿景是让大数据更简单 • 统一SQL入口,数据免搬迁 • 高性能的交互式查询能力 • 多源异构数据源融合分析 • 跨域跨DC融合分析 • Looking back • openLooKeng从如下三个方面进行交互式查询优化: • 让数据源更好的适配引擎(分区/小文件合并) • 引擎自身优化(动态过滤/RBO/CBO/谓词下推/缓存) • 添加额外层加速(Heuristic index layer/Cache layer/序列化/反序列化) • Looking forward • OmniRuntime构建大数据分析底座 28
29 .Thank you
1点赞
2收藏
3秒后跳转登录页面
去登陆

