














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
云上大数据的一种高性能数据湖存储方案
分享
点赞
7
收藏
5
主讲人:
殳鑫鑫,花名辰石,阿里巴巴计算平台事业部EMR团队技术专家,目前从事大数据存储以及Spark相关方面的工作。
徐铖, Intel大数据团队软件开发经理
简介:大数据上云是业界普遍共识,存储和计算分离的趋势日益显著,如何为云上蓬勃发展的大数据处理和分析引擎提供坚实的存储基础?这个 session 会主要讨论 EMR 技术团队重磅推出的一种新型混合存储解决方案,该方案基于云平台和云存储,面向新的存储硬件和计算发展趋势,为 EMR 弹性计算量身打造,在成本,弹性和性能上追求极佳平衡。技术上是如何实现的?性能如何?覆盖了哪些典型场景,最佳实践是什么?敬请期待!
展开查看详情
1 . JindoFS: 云上大数据的高性能数据湖 存储方案 JindoFS: A High-Performance Data Lake on Cloud 殳鑫鑫 徐铖 阿里巴巴 - 技术专家 Intel - 软件开发经理
2 . 01 EMR JindoFS 背景 EMR JindoFS Background Contents 目录 02 EMR JindoFS 介绍 EMR JindoFS Introduction 03 EMR JindoFS+ DCPM 性能 EMR JindoFS + DCPM Performance
3 .EMR JindoFS 背景 EMR JindoFS Background 01
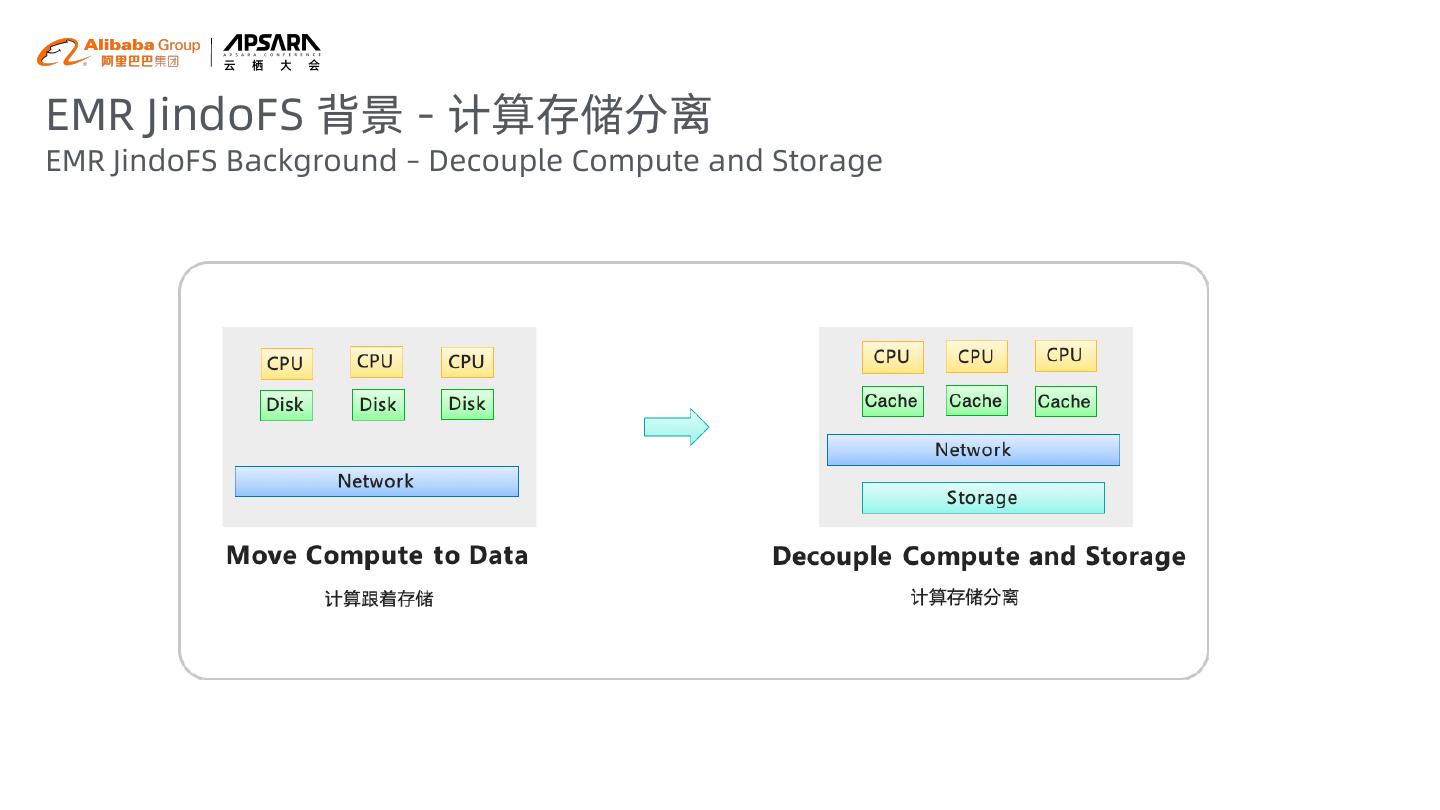
4 .EMR JindoFS 背景 - 计算存储分离 EMR JindoFS Background – Decouple Compute and Storage
5 .计算存储分离 – OSS Decouple Compute and Storage - OSS - 海量massive - 安全 Safety - 低成本 Low Cost 数据访问 Data Access + - 高可靠 High reliability - 文件移动较慢 Slow rename - 长作业 Long-running Job - 列式存储 Column-based 元数据访问 Storage Metadata Access - 带宽限制 Limited bandwidth - 高频访问 High frequency access
6 .EMR JindoFS 介绍 EMR JindoFS Introduction 02
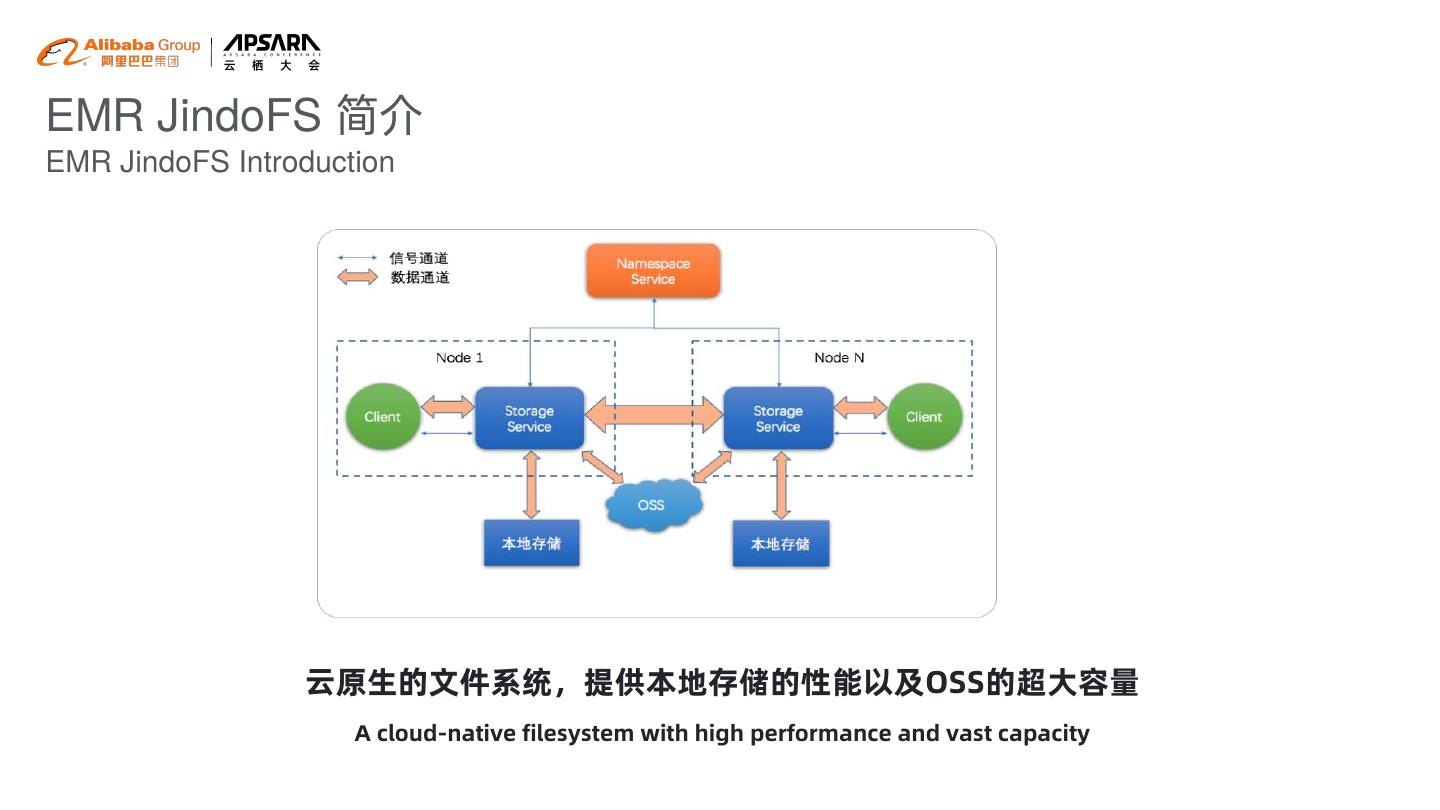
7 .EMR JindoFS 简介 EMR JindoFS Introduction 云原生的文件系统,提供本地存储的性能以及OSS的超大容量 A cloud-native filesystem with high performance and vast capacity
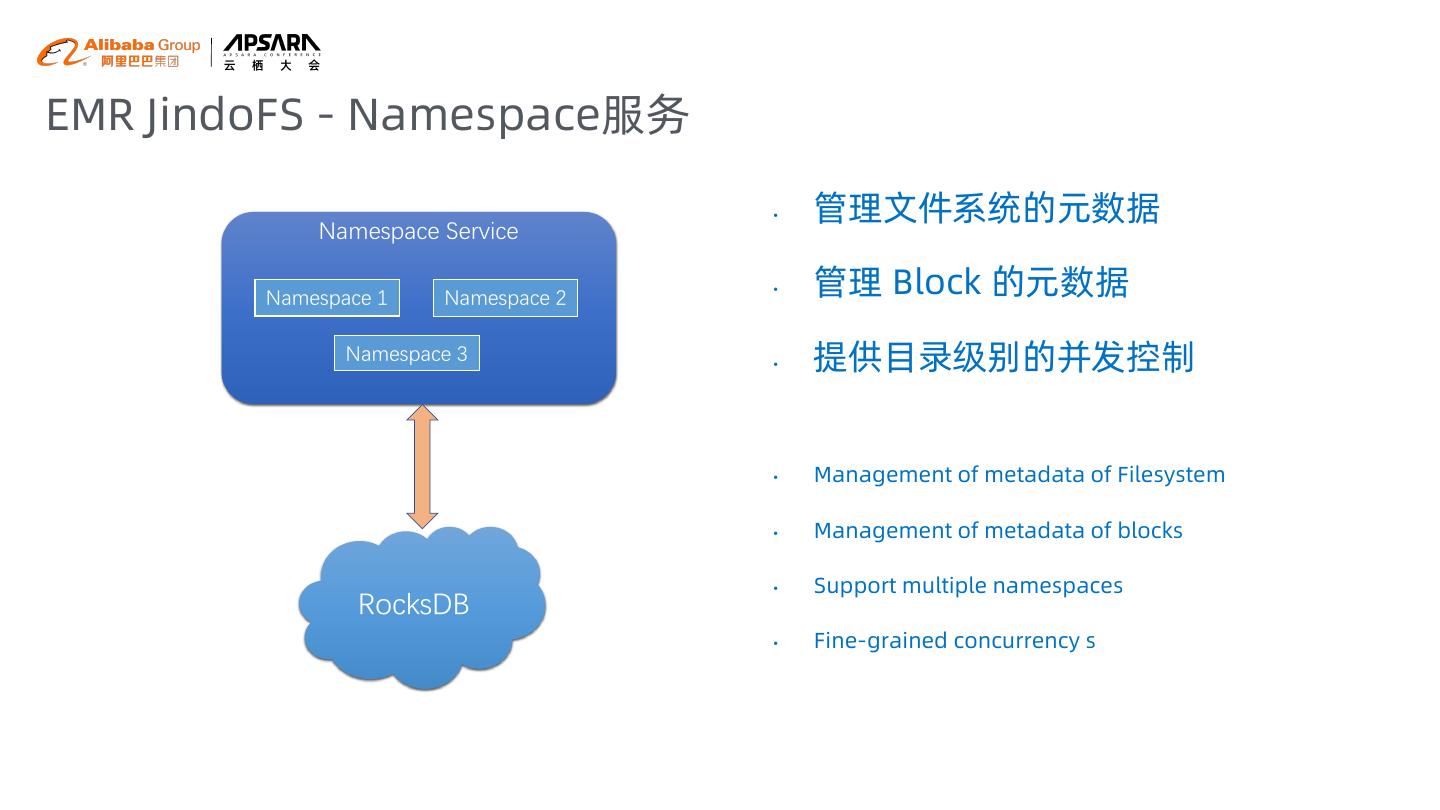
8 .EMR JindoFS - Namespace服务 • 管理文件系统的元数据 Namespace Service Namespace 1 Namespace 2 • 管理 Block 的元数据 Namespace 3 • 提供目录级别的并发控制 • Management of metadata of Filesystem • Management of metadata of blocks • Support multiple namespaces RocksDB • Fine-grained concurrency s
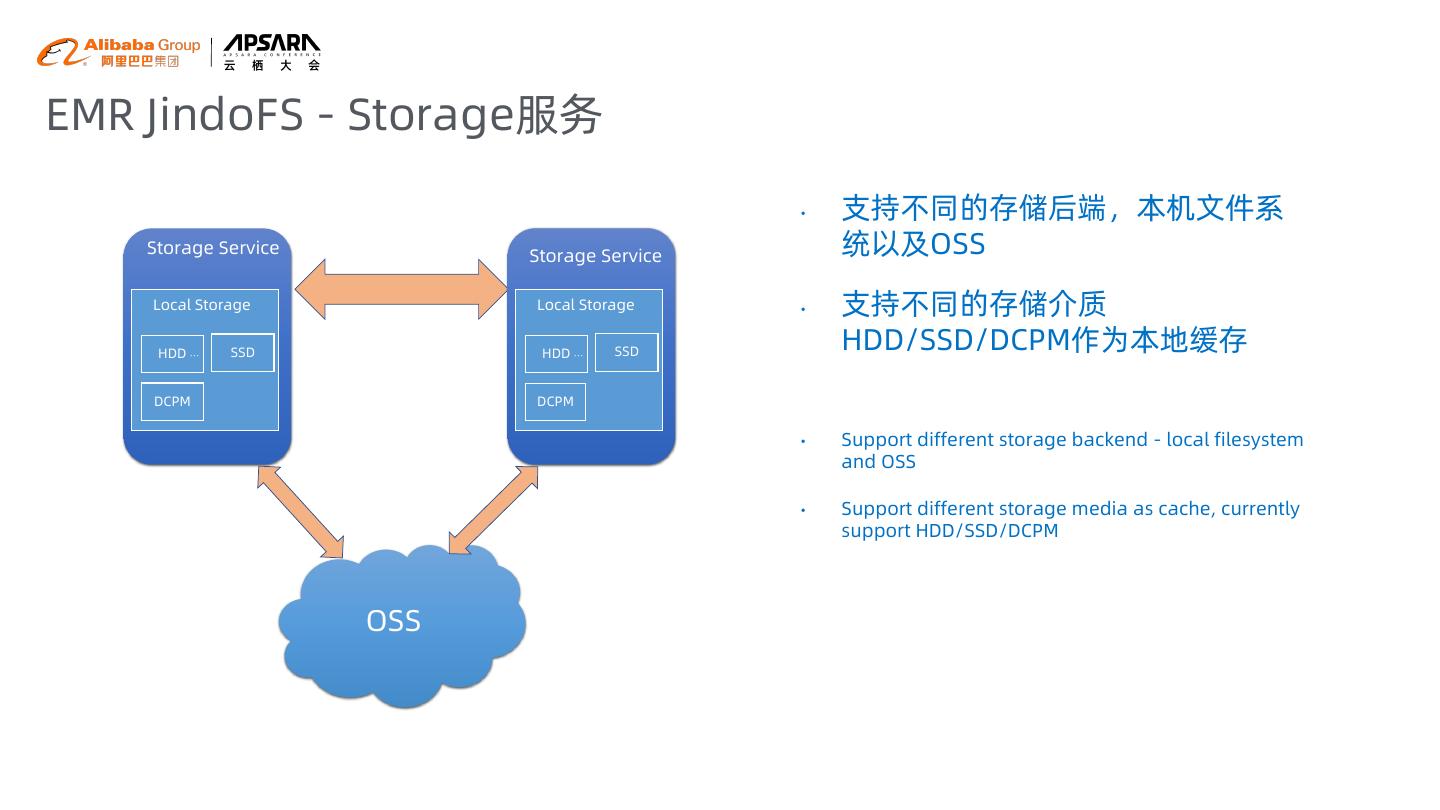
9 .EMR JindoFS - Storage服务 • 支持不同的存储后端,本机文件系 Storage Service Storage Service 统以及OSS Local Storage Local Storage • 支持不同的存储介质 HDD … SSD HDD … SSD HDD/SSD/DCPM作为本地缓存 DCPM DCPM • Support different storage backend - local filesystem and OSS • Support different storage media as cache, currently support HDD/SSD/DCPM OSS
10 .EMR JindoFS 生态 EMR JindoFS Ecosystem EMR 生态 EMR JindoFS • 用户访问JindoFS 只需要替换访问路径scheme • 机器学习支持,下个版本很快会提供高性能 Python SDK,方便机器学习生态高效率读写 JindoFS 上数据 • 和 EMR Spark 高度集成优化,支持基于 Spark 的物化视图/cube 优化,实现秒级 adhoc 分析,系统简单 可维护 • Minor change to integrate with JindoFS, only replace scheme with “jfs” • Support machine learning,will provide a high-performance python SDK to upload/download data from/to JindoFS in next release • Optimized with EMR Spark, support material view and cube optimization
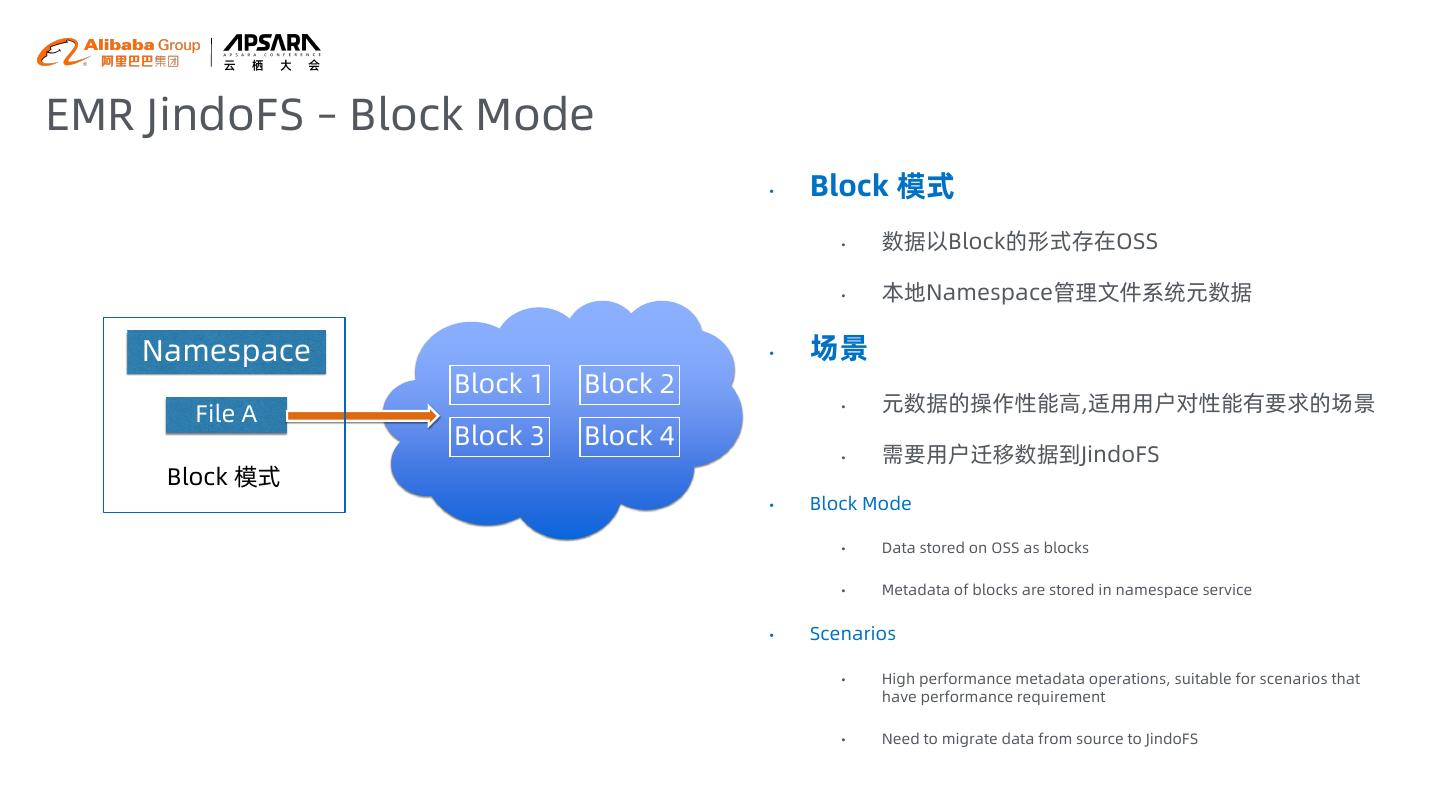
11 .EMR JindoFS – Block Mode • Block 模式 • 数据以Block的形式存在OSS • 本地Namespace管理文件系统元数据 Namespace • 场景 Block 1 Block 2 File A • 元数据的操作性能高,适用用户对性能有要求的场景 Block 3 Block 4 • 需要用户迁移数据到JindoFS Block 模式 • Block Mode • Data stored on OSS as blocks • Metadata of blocks are stored in namespace service • Scenarios • High performance metadata operations, suitable for scenarios that have performance requirement • Need to migrate data from source to JindoFS
12 .EMR JindoFS – Block Mode JindoFS 提供不同存储策略支持不同的应用场景 • COLD:数据仅有一个备份存在 OSS 上,没有本地备份,适用于冷数据存储 • WARM:此为默认策略,数据在 OSS 和本地分别有一个备份, 本地备份能够有效的提供后续的读取加速 • HOT:数据在 OSS 上一个备份,本地多个备份,针对一些最热的数据提供更进一步的加速效果 • TEMP:数据仅有一个本地备份,针对一些临时性数据,提供高性能的读写,但牺牲了数据的高可靠性,适 用于一些临时数据存取 Storage Policies to fit into different scenarios • COLD Policy:only one replica on OSS, no replica on local disks, suitable for archive data • WARM Policy: default policy, one replica on local disks and one replica on OSS, local replica provides high performance • HOT Policy: multiple replicas (> 2) on local disks and one replica on OSS • TEMP Policy: only one replica on local disks, suitable for scenarios that provide short-term storage, such as shuffle data
13 .EMR JindoFS – Block Mode • 对比HDFS优势 • 利用OSS 的廉价和无限容量 JindoFS 提可以 OSS 优势成本以及容量的优势 • 冷热数据自动分离,计算透明,冷热数据自动迁移的时候逻辑位置不变,无须修改表元数据 location 信息 • 维护简单,无须 decommission,节点坏掉或者下掉就去掉,数据 OSS 上有,不会丢失 • 系统快速升级/重启/恢复,没有 block report • 原生支持小文件,避免小文件过程造成文件系统过大的压力 • JindoFS vs. HDFS • OSS backend provides Low cost and infinite capacity • Cold data and hot data are separated automatically, it is transparent to computation • No need to decommission when nodes fail due to data always has one replica on OSS • Rapidly reboot/recover/upgrade system, do not wait for block report • Support many small files natively to avoid too much pressure on local file system
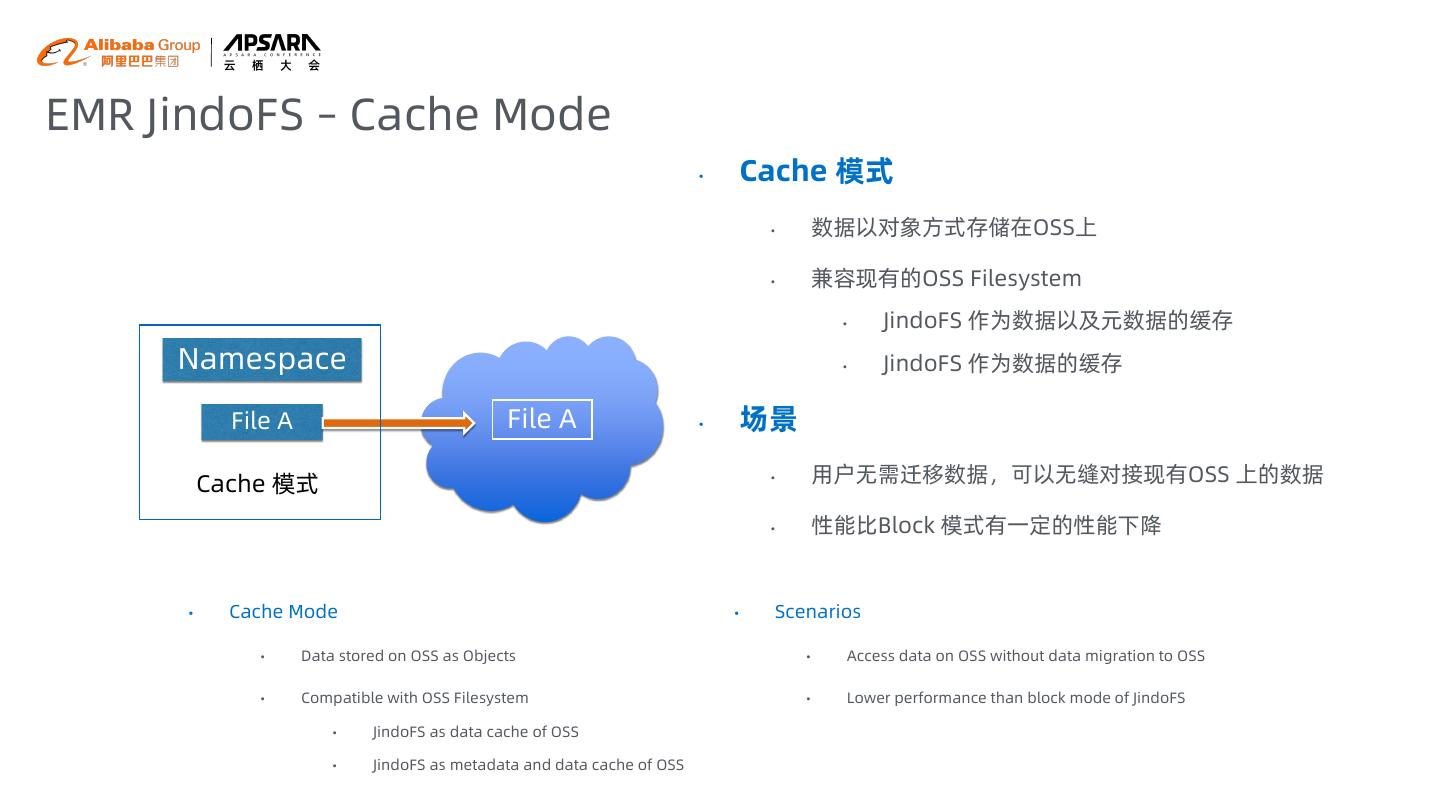
14 .EMR JindoFS – Cache Mode • Cache 模式 • 数据以对象方式存储在OSS上 • 兼容现有的OSS Filesystem • JindoFS 作为数据以及元数据的缓存 Namespace • JindoFS 作为数据的缓存 File A File A • 场景 Cache 模式 • 用户无需迁移数据,可以无缝对接现有OSS 上的数据 • 性能比Block 模式有一定的性能下降 • Cache Mode • Scenarios • Data stored on OSS as Objects • Access data on OSS without data migration to OSS • Compatible with OSS Filesystem • Lower performance than block mode of JindoFS • JindoFS as data cache of OSS • JindoFS as metadata and data cache of OSS
15 .EMR JindoFS – Cache Mode • 兼容OssFS 文件系统 • JindoFS作为数据以及元数据的缓存 • 需要从OSS上同步元数据以及数据,元数据同步支持不同的Sync以及Load元数据策略 • 性能相对 Block 模式存在一定损失 • JindoFS作为数据缓存 • 无需同步OSS元数据, 只缓存数据到JindoFS • Compatible with OssFS. • For JindoFS as data and metadata cache, need to sync data & metadata from OSS • Support different policies to sync data and metadata from OSS • Lower performance than block mode • For JindoFS as data cache, a pure data cache layer of OssFS • No need to sync metadata from OSS, only store data on local disks as data cache
16 .EMR JindoFS – Cache Mode • 对比OssFS优势 • 由于本地备份存在,读写吞吐与HDFS相当 • 能够支持全部 HDFS 接口, 支持更多的场景,如Delta Lake,支持 HBase on JindoFS • JindoFS作为数据以及元数据的缓存, 用户在读写数据以及List/Status操作相对OssFS有性能提升 • JindoFS作为数据缓存, 可以加速用户的数据读写 • JindoFS vs. OssFS • JindoFS cache mode provide higher performance than OssFS due local replicas • Compatible wit HDFS, support delta lake, HBase on JindoFS and so on • For JindoFS as data and metadata cache, get higher performance of read/write/list/status than OssFS • For JindoFS as data cache, only store data on JindoFS as data cache to boost performance
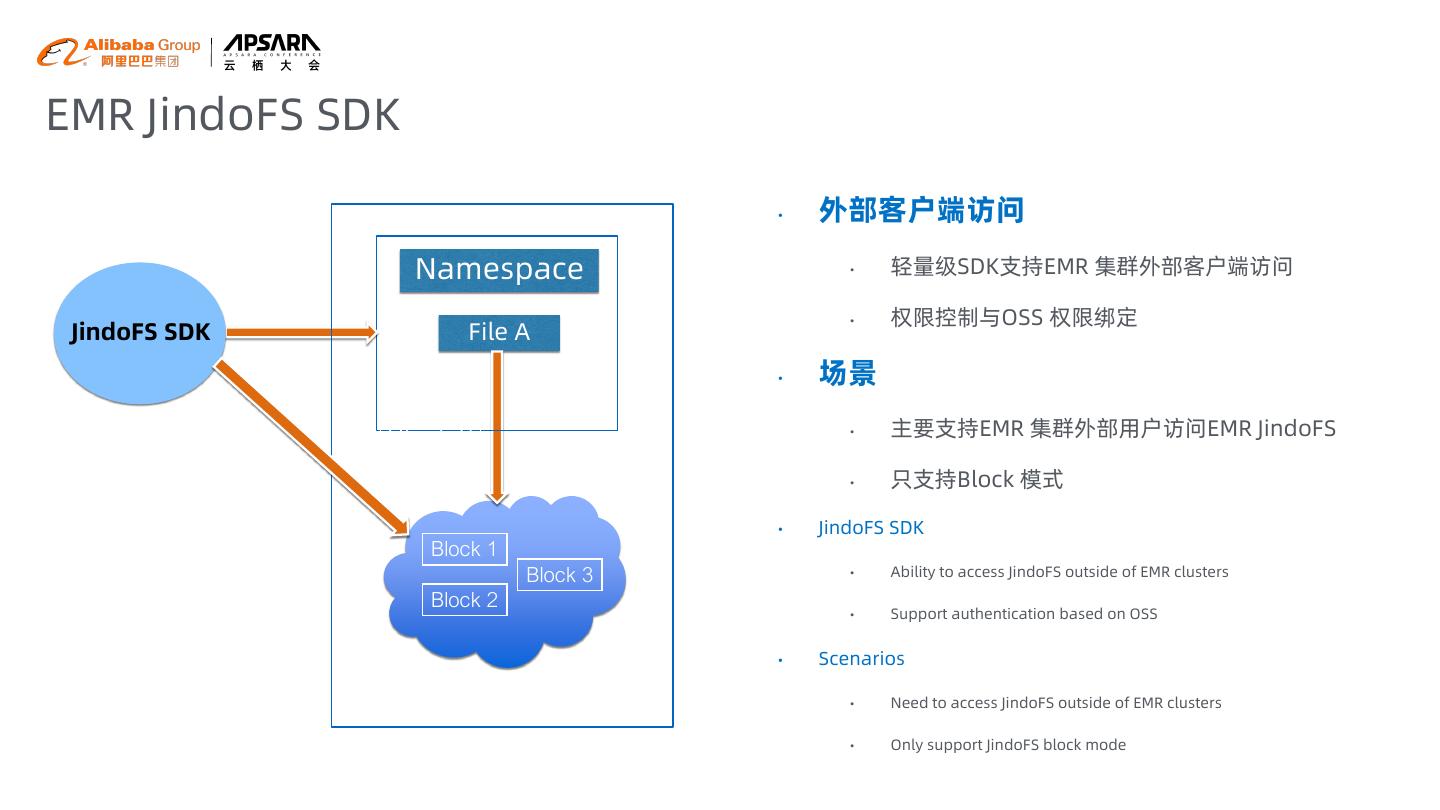
17 .EMR JindoFS SDK • 外部客户端访问 Namespace • 轻量级SDK支持EMR 集群外部客户端访问 • 权限控制与OSS 权限绑定 JindoFS SDK File A Block 1 Block 2 • 场景 Block 3 • 主要支持EMR 集群外部用户访问EMR JindoFS • 只支持Block 模式 • JindoFS SDK Block 1 Block 3 • Ability to access JindoFS outside of EMR clusters Block 2 • Support authentication based on OSS • Scenarios • Need to access JindoFS outside of EMR clusters • Only support JindoFS block mode
18 .EMR JindoFS + DCPM 性能 EMR JindoFS + DCPM Performance 03
19 .英特尔傲腾数据中心级可持久化内存的典型使用场景 Use case for Intel Optane DC persistent memory
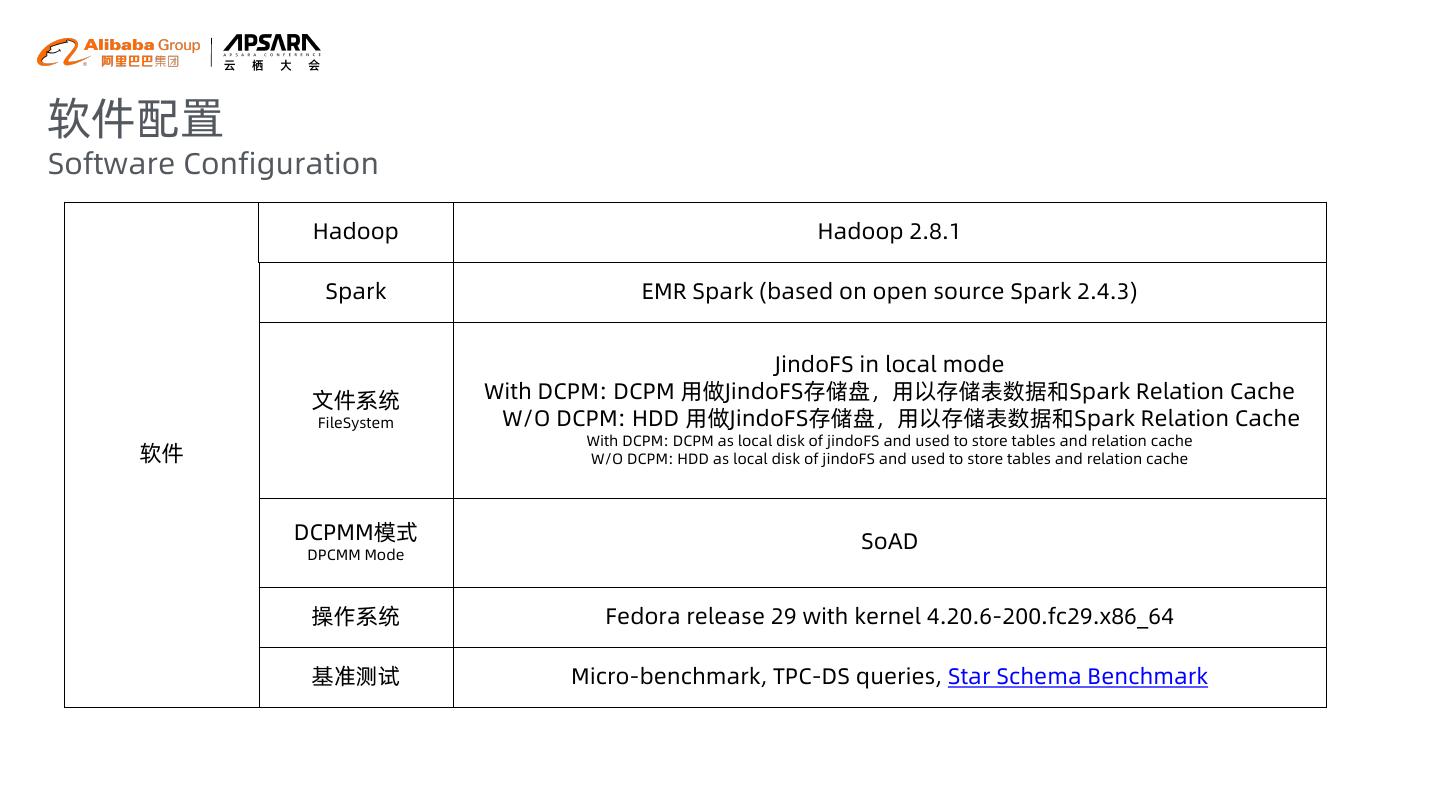
20 .软件配置 Software Configuration Hadoop Hadoop 2.8.1 Spark EMR Spark (based on open source Spark 2.4.3) JindoFS in local mode 文件系统 With DCPM: DCPM 用做JindoFS存储盘,用以存储表数据和Spark Relation Cache FileSystem W/O DCPM: HDD 用做JindoFS存储盘,用以存储表数据和Spark Relation Cache With DCPM: DCPM as local disk of jindoFS and used to store tables and relation cache 软件 W/O DCPM: HDD as local disk of jindoFS and used to store tables and relation cache DCPMM模式 SoAD DPCMM Mode 操作系统 Fedora release 29 with kernel 4.20.6-200.fc29.x86_64 基准测试 Micro-benchmark, TPC-DS queries, Star Schema Benchmark
21 .性能总结 Performance Summary • DCPM为小文件读带来显著性能提升,特别是在更大文件以及更多读进程场景下,性能提升更 为明显。 • 使用决策支持相关查询作为基准测试,2TB数据下,DCPM为99个查询执行带来1.53倍性能提 升。 • 同样在2TB数据下,DCPM为 SSB with spark relational cache带来总体2.7倍的性能提升。 • Obvious performance benefit from DCPM in micro-benchmark, especially when file size becomes larger and with more multi-threads reading. • 1.53X performance improvement gained in TPC-DS 99 queries execution with data scale factor 2TB. • For SSB with relational cache, DCPM brings about overall 2.7X performance improvement.
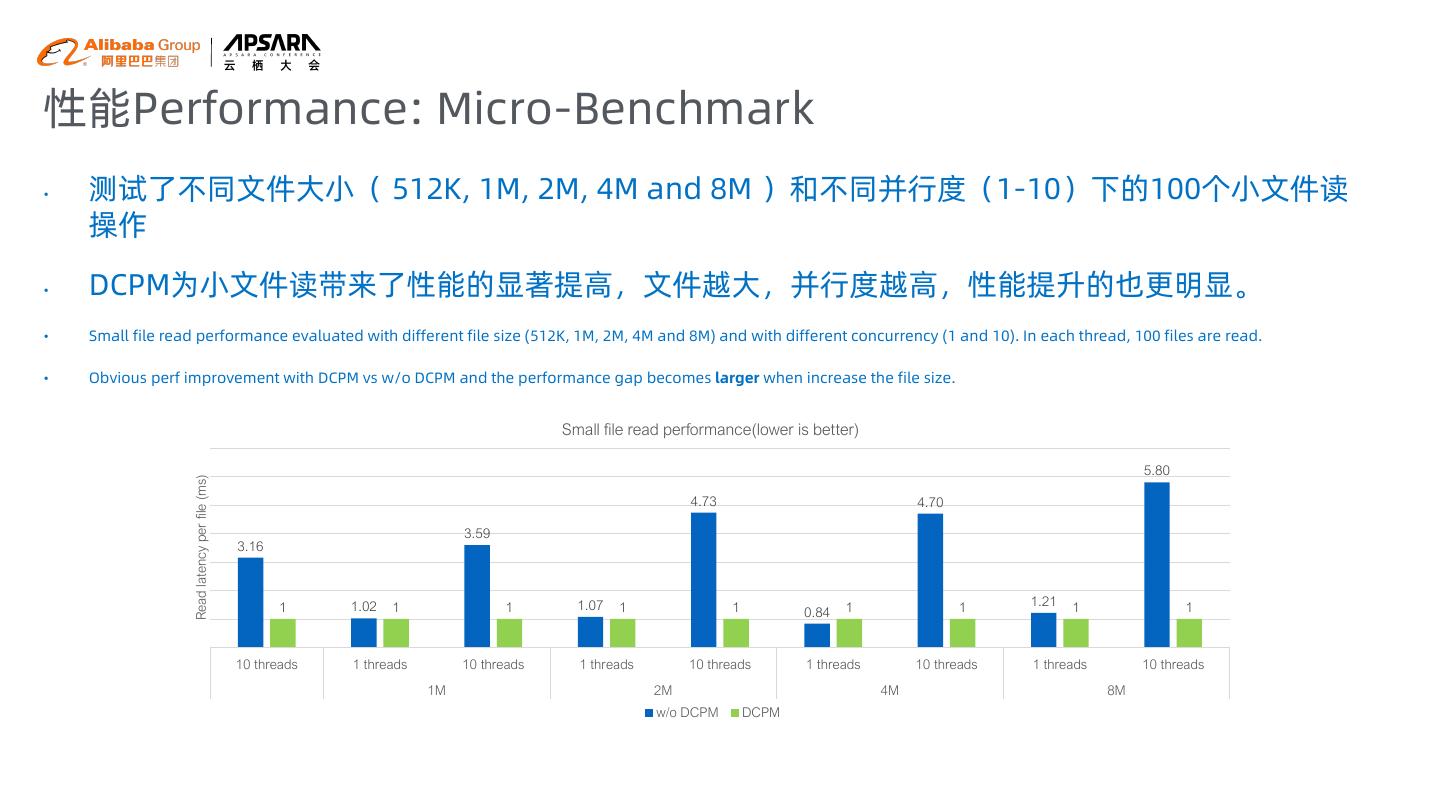
22 .性能Performance: Micro-Benchmark • 测试了不同文件大小( 512K, 1M, 2M, 4M and 8M )和不同并行度(1-10)下的100个小文件读 操作 • DCPM为小文件读带来了性能的显著提高,文件越大,并行度越高,性能提升的也更明显。 • Small file read performance evaluated with different file size (512K, 1M, 2M, 4M and 8M) and with different concurrency (1 and 10). In each thread, 100 files are read. • Obvious perf improvement with DCPM vs w/o DCPM and the performance gap becomes larger when increase the file size. Small file read performance(lower is better) 5.80 Read latency per file (ms) 4.73 4.70 3.59 3.16 1 1.02 1 1 1.07 1 1 1 1 1.21 1 1 0.84 10 threads 1 threads 10 threads 1 threads 10 threads 1 threads 10 threads 1 threads 10 threads 1M 2M 4M 8M w/o DCPM DCPM
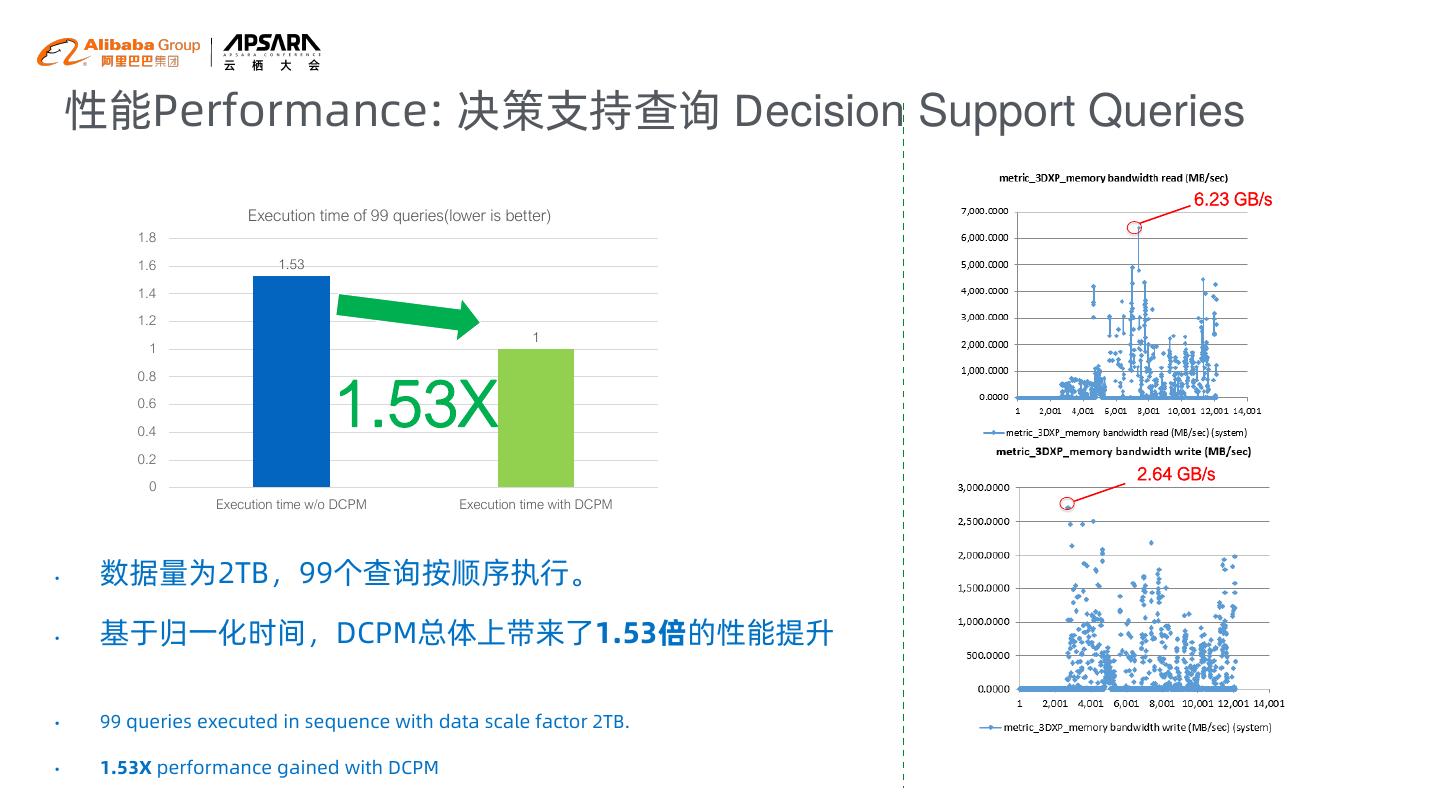
23 . 性能Performance: 决策支持查询 Decision Support Queries 6.23 GB/s Execution time of 99 queries(lower is better) 1.8 1.6 1.53 1.4 1.2 1 1 1.53X 0.8 0.6 0.4 0.2 2.64 GB/s 0 Execution time w/o DCPM Execution time with DCPM • 数据量为2TB,99个查询按顺序执行。 • 基于归一化时间,DCPM总体上带来了1.53倍的性能提升 • 99 queries executed in sequence with data scale factor 2TB. • 1.53X performance gained with DCPM
24 .性能Performance: SSB with Spark Relational Cache • SSB( 星型基准测试 )是基于TPC-H的针对星型数据库系统性能的测试基准。 • Relational Cache是EMR Spark支持的一个重要特性,主要通过对数据进行预组织和预计算 加速数据分析,提供了类似传统数据仓库物化视图的功能。 • 在SSB测试中,使用1TB数据来单独执行每个查询,并在每个查询之间清除系统cache。 • The Star Schema Benchmark, or SSB, was devised to evaluate database system performance of star schema data warehouse queries. A modified form of TPC-H benchmark with less queries. • Relational cache is a query-boost feature provided by Ali EMR spark by storing intermediate data in memory, disk or any data source that Spark supports. • For the ‘with DCPM’ scenario, cache is stored in JindoFS using DCPM as the storage backend. • Data scale factor 1TB and query executed one by one with cache cleaned for each in this case.
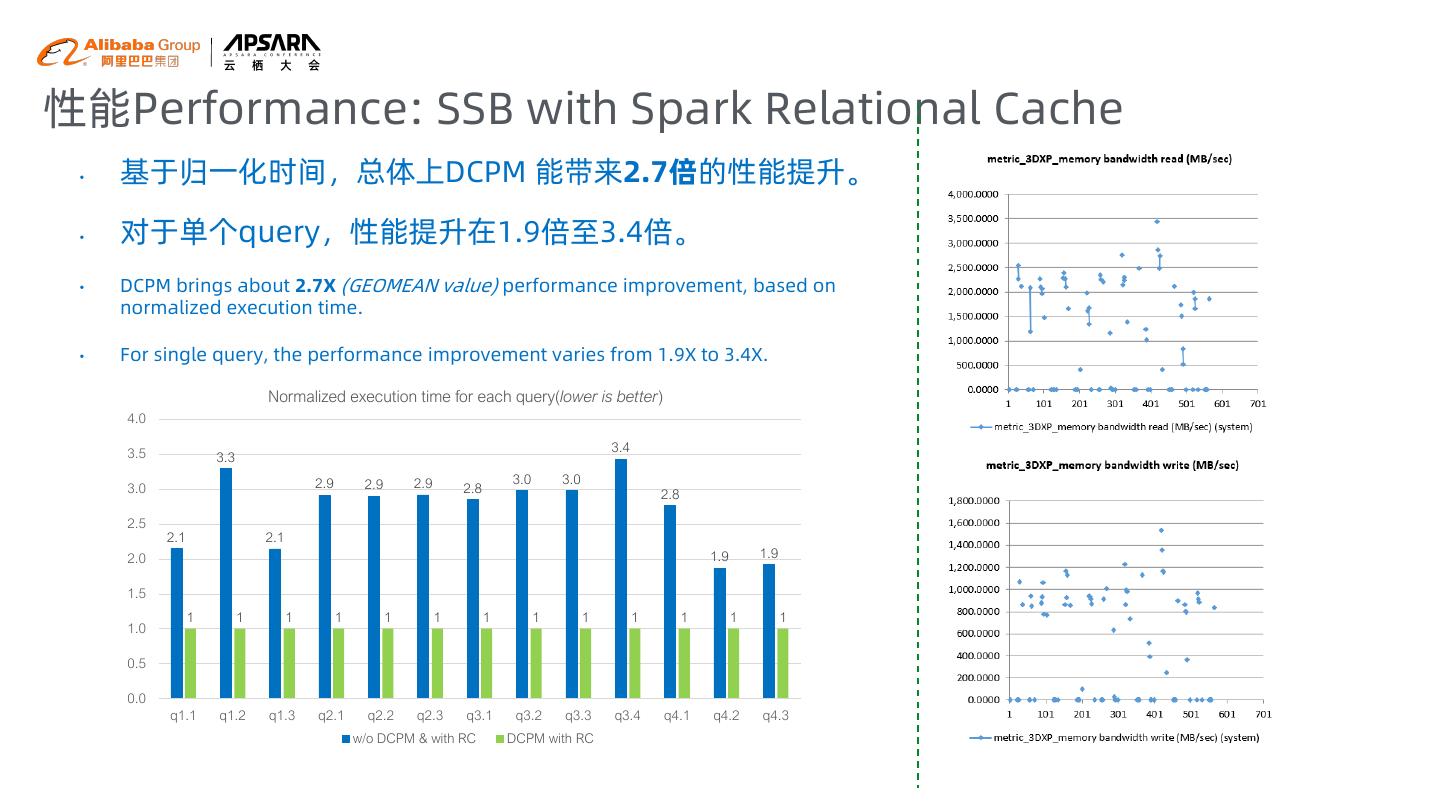
25 .性能Performance: SSB with Spark Relational Cache • 基于归一化时间,总体上DCPM 能带来2.7倍的性能提升。 • 对于单个query,性能提升在1.9倍至3.4倍。 • DCPM brings about 2.7X (GEOMEAN value) performance improvement, based on normalized execution time. • For single query, the performance improvement varies from 1.9X to 3.4X. Normalized execution time for each query(lower is better) 4.0 3.5 3.4 3.3 2.9 2.9 2.9 3.0 3.0 3.0 2.8 2.8 2.5 2.1 2.1 2.0 1.9 1.9 1.5 1 1 1 1 1 1 1 1 1 1 1 1 1 1.0 0.5 0.0 q1.1 q1.2 q1.3 q2.1 q2.2 q2.3 q3.1 q3.2 q3.3 q3.4 q4.1 q4.2 q4.3 w/o DCPM & with RC DCPM with RC
26 .THANKS !
7点赞
5收藏
3秒后跳转登录页面
去登陆

