





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
微软Azure平台利用Intel Analytics Zoo构建AI客服支持实践
1月10日【微软Azure平台利用Intel Analytics Zoo构建AI客服支持实践】
讲师:
黄凯——Intel大数据技术团队软件工程师。
卫雨青——Microsoft C+AI 团队软件工程师。
简介:本次分享将为大家介绍Intel的Analytics Zoo工具包,并分享微软Azure智能客服平台使用Intel Analytics Zoo的实践经验。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .Use Intel Analytics Zoo to build an intelligent QA Bot for Microsoft Azure Jan 10th, 2019
2 . Kai Huang Software Engineer from Intel Data Analytics Technology Team About Us Yuqing Wei Software Engineer from Microsoft C+AI Team
3 . Introduction to Analytics Zoo. How to develop NLP modules using Analytics Zoo. Outline Engineering experience in building a chat bot. Bot Demo.
4 . Bringing Deep Learning To Big Data Platform • Distributed deep learning framework for Apache Spark. • Make deep learning more accessible to big data users and data scientists o Write deep learning applications as standard Spark programs. o Run on existing Spark/Hadoop clusters (no changes needed). BigDL • High performance (on CPU) • Powered by Intel MKL and multi-threaded programming. • Efficient scale-out • Leveraging Spark for distributed training & inference. https://github.com/intel-analytics/BigDL https://bigdl-project.github.io/
5 . A unified analytics + AI platform for distributed TensorFlow, Keras and BigDL on Apache Spark Feature transformations for Feature Engineering • Image, 3D images, text, time series, speech, etc. • Keras, autograd and transfer learning APIs for model definition. • Native deep learning support in Spark DataFrames and ML High-Level Pipeline APIs Pipelines. Analytics • POJO style API for model serving/inference pipelines. Zoo Built-In Deep Learning Models Image classification, object detection, text classification, recommendations, text matching, anomaly detection, seq2seq etc. Seamlessly unites Spark, TensorFlow, Keras and BigDL programs into Backends an integrated pipeline. https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
6 . 1. Read images as ImageSet from zoo.common.nncontext import init_nncontext from zoo.feature.image import * sc = init_nncontext() local_image_set = ImageSet.read(image_path) distributed_image_set = ImageSet.read(image_path, sc, 2) Feature 2. Built-in ImageProcessing operations Engineering transformer = ChainedPreprocessing([ImageBytesToMat(), ImageColorJitter(), ImageExpand(max_expand_ratio=2.0), ImageResize(300, 300, -1), ImageHFlip()]) new_local_image_set = transformer(local_image_set) new_distributed_image_set = transformer(distributed_image_set) Image Augmentations Using Built-in Image Transformations (w/ OpenCV on Spark) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
7 . Use Keras-Style API to create an Analytics Zoo model and train, evaluate or tune it in a distributed fashion. from zoo.pipeline.api.keras.models import Sequential from zoo.pipeline.api.keras.layers import * model = Sequential() model.add(Reshape((1, 28, 28), input_shape=(28, 28, 1))) Keras-Style model.add(Convolution2D(6, 5, 5, activation="tanh", name="conv1_5x5")) model.add(MaxPooling2D()) model.add(Convolution2D(12, 5, 5, activation="tanh", name="conv2_5x5")) API model.add(MaxPooling2D()) model.add(Flatten()) model.add(Dense(100, activation="tanh", name="fc1")) model.add(Dense(10, activation="softmax", name="fc2")) model.compile(optimizer, loss, metrics) model.fit(x, batch, epoch) model.predict(x, batch) model.evaluate(x, batch) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
8 . Autograd API provides automatic differentiation for math operations to easily define custom layers or losses. import zoo.pipeline.api.autograd as A Autograd log = A.log(in_node + 1.0) dot = A.batch_dot(embed1, embed2, axes=[2, 2]) API from zoo.pipeline.api.autograd import * def mean_absolute_error(y_true, y_pred): result = mean(abs(y_true - y_pred), axis=1) return result https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
9 . Use transfer learning APIs to easily customize pretrained models for feature extraction or fine-tuning: from zoo.pipeline.api.net import * from zoo.pipeline.api.keras.layers import Dense, Input, Flatten from zoo.pipeline.api.keras.models import Model Transfer # Load a pretrained model full_model = Net.load_caffe(def_path, model_path) Learning # Remove the last few layers model = full_model.new_graph(outputs=["pool5"]).to_keras()) API # Freeze the first few layers model.freeze_up_to(["res4f"]) # Append a few layers input = Input(shape=(3, 224, 224)) resnet = model.to_keras()(input) flatten = Flatten()(resnet) logits = Dense(2)(flatten) new_model = Model(input, logits) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
10 . Running TensorFlow model on Spark for distributed training and inference. 1. Data wrangling and analysis using PySpark from zoo.common.nncontext import init_nncontext from zoo.pipeline.api.net import TFDataset sc = init_nncontext() Distributed # Each record in the train_rdd consists of a list of NumPy ndrrays TensorFlow train_rdd = sc.parallelize(file_list)\ .map(lambda x: read_image_and_label(x)) .map(lambda image_label: decode_to_ndarrays(image_label)) # TFDataset represents a distributed set of elements, # in which each element contains one or more TensorFlow Tensor objects. dataset = TFDataset.from_rdd(train_rdd, names=["features", "labels"], shapes=[[28, 28, 1], [1]], types=[tf.float32, tf.int32], batch_size=BATCH_SIZE) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
11 . Running TensorFlow model on Spark in a distributed fashion. 2. Deep learning model development using TensorFlow import tensorflow as tf slim = tf.contrib.slim images, labels = dataset.tensors Distributed labels = tf.squeeze(labels) with slim.arg_scope(lenet.lenet_arg_scope()): logits, end_points = lenet.lenet(images, num_classes=10, is_training=True) TensorFlow loss = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(logits=logits, labels=labels)) 3. Distributed training on Spark and BigDL from zoo.pipeline.api.net import TFOptimizer from bigdl.optim.optimizer import MaxIteration, Adam, MaxEpoch, TrainSummary optimizer = TFOptimizer(loss, Adam(1e-3)) optimizer.set_train_summary(TrainSummary("/tmp/az_lenet", "lenet")) optimizer.optimize(end_trigger=MaxEpoch(5)) saver = tf.train.Saver() https://github.com/intel-analytics/analytics-zoo saver.save(optimizer.sess, "/tmp/lenet/") https://analytics-zoo.github.io/
12 . Running TensorFlow model on Spark in a distributed fashion. 4. Distributed inference dataset = TFDataset.from_rdd(testing_rdd, names=["features"], shapes=[[28, 28, 1]], types=[tf.float32]) Distributed predictor = TFPredictor.from_outputs(sess, [logits]) TensorFlow predictions_rdd = predictor.predict() For Keras users: optimizer = TFOptimizer.from_keras(keras_model, dataset) predictor = TFPredictor.from_keras(model, dataset) predictions_rdd = predictor.predict() https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
13 . Native DL support in Spark DataFrames and ML Pipelines 1. Load images into DataFrames using NNImageReader from zoo.common.nncontext import * from zoo.pipeline.nnframes import * sc = init_nncontext() imageDF = NNImageReader.readImages(image_path, sc) NNFrames 2. Process loaded data using DataFrame transformations API getName = udf(lambda row: ...) df = imageDF.withColumn("name", getName(col("image"))) 3. Processing image using built-in feature engineering operations from zoo.feature.image import * transformer = ChainedPreprocessing( [RowToImageFeature(), ImageChannelNormalize(123.0, 117.0, 104.0), ImageMatToTensor(), ImageFeatureToTensor()]) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
14 . Native DL support in Spark DataFrames and ML Pipelines 4. Define model using Keras-style API from zoo.pipeline.api.keras.layers import * from zoo.pipeline.api.keras.models import Sequential model = Sequential() NNFrames model.add(Convolution2D(32, 3, 3, activation='relu', input_shape=(1, 28, 28))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()).add(Dense(10, activation='softmax'))) API 5. Train model using Spark ML Pipelines Estimater = NNEstimater(model, CrossEntropyCriterion(), transformer) \ .setLearningRate(0.003).setBatchSize(40).setMaxEpoch(1) \ .setFeaturesCol("image") nnModel = estimater.fit(df) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
15 . • Load existing TensorFlow, Keras, Caffe, Torch, ONNX model • Useful for inference and model fine-tuning. • Allows for transition from single-node for distributed application deployment. • Allows for model sharing between data scientists and production engineers. Models Interoperability from zoo.pipeline.api.net import Net Net.load_tf(path, inputs=None, outputs=None, Support byte_order=“little_endian”, bin_file=None) Net.load_keras(hdf5_path, json_path=None, by_name=False) Net.load_caffe(def_path, model_path) Net.load_torch(path) https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
16 . • Object detection API • High-level API and pretrained models (e.g., SSD, Faster-RCNN, etc.) for object detection. • Image classification API Built-in • High-level API and pretrained models (e.g., VGG, Inception, ResNet, MobileNet, etc.) for image classification. Deep Learning • Recommendation API • High-level API and pre-defined models (e.g., Neural Collaborative Filtering, Wide and Deep Models Learning, etc.) for recommendation. • Text classification API • High-level API and pre-defined models (using CNN, LSTM, etc.) for text classification. https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
17 . 1. Load pretrained model in Detection Model Zoo from zoo.common.nncontext import init_nncontext from zoo.models.image.objectdetection import * sc = init_nncontext() Object model = ObjectDetector.load_model(model_path) 2. Off-the-shell inference using the loaded model Detection image_set = ImageSet.read(img_path, sc) API output = model.predict_image_set(image_set) 3. Visualize detection results config = model.get_config() visualizer = Visualizer(config.label_map(), encoding="jpg") visualized = visualizer(output).get_image(to_chw=False).collect() https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
18 . • Anomaly Detection • Using LSTM network to detect anomalies in time series data. • Fraud Detection • Using feed-forward neural network to detect frauds in credit card transaction data. • Recommendation Reference • Use Analytics Zoo Recommendation API (i.e., Neural Collaborative Filtering, Wide and Deep) for recommendations on data with explicit feedback. Use Cases • Sentiment Analysis • Sentiment analysis on movie reviews using neural network models (e.g. CNN, LSTM, GRU, Bi-LSTM). • Variational AutoEncoder • Use VAE to generate digital numbers and faces. https://github.com/intel-analytics/analytics-zoo/tree/master/apps https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
19 . Deployed on AliCloud* E-MapReduce* https://yq.aliyun.com/articles/73347 Listed in Microsoft* Azure* Marketplace* https://azure.microsoft.com/en-us/blog/bigdl-spark-deep-learning-library-vm-now-available-on-microsoft-azure-marketplace/ Available on Google* Cloud Dataproc* Public Cloud https://cloud.google.com/blog/big-data/2018/04/using-bigdl-for-deep-learning-with-apache-spark-and-google-cloud-dataproc Deployment Optimized for Amazon* EC2* C5 instanced, and listed in AWS* Marketplace* https://aws.amazon.com/blogs/machine-learning/leveraging-low-precision-and-quantization-for-deep-learning-using-the-amazon-ec2-c5-instance-and-bigdl/ Deployed on IBM* Data Science Expetience* https://medium.com/ibm-data-science-experience/using-bigdl-in-data-science-experience-for-deep-learning-on-spark-f1cf30ad6ca0 Available on Telefonica* Open Cloud* https://support.telefonicaopencloud.com/en-us/ecs/doc/download/20180329/20180329111611_166372a698.pdf https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
20 . Industrial Inspection Platform in Midea* and KUKA* https://software.intel.com/en-us/articles/industrial-inspection-platform-in-midea-and-kuka-using-distributed- tensorflow-on-analytics Object Detection and Image Feature Extraction in JD Customer https://software.intel.com/en-us/articles/building-large-scale-image-feature-extraction-with-bigdl-at-jdcom Use Cases Image Similarity Based House Recommendation for MLSlistings https://software.intel.com/en-us/articles/using-bigdl-to-build-image-similarity-based-house- recommendations 3D Medical Image Analysis in UCSF https://conferences.oreilly.com/strata/strata-ca/public/schedule/detail/64023 https://github.com/intel-analytics/analytics-zoo https://analytics-zoo.github.io/
21 . Chat Bot is often used for recent intelligent customer platforms. To enhance user experience and relieve human workload. Background To provide technical support for Azure users effectively and efficiently. AI modules provided by Analytics Zoo: text classification, question answering, intent extraction, named entity recognition, etc.
22 . Neural networks are easier for feature extraction. TextClassifier module can be modified for sentiment analysis. Why neural Neural networks generally have better performance, networks? especially on QA tasks and when we lack data. Common parts can share for different AI modules.
23 . Analytics Zoo provides pipeline APIs, prebuilt models and use cases for NLP tasks. Why To provide practical experience for Azure big Analytics Zoo data users to build AI applications. Preinstalled image on Azure Marketplace for for NLP? easy deployment.
24 . Read cleaned text data as RDD where each record contains two columns (text, label). Common Steps Tokenization: https://github.com/fxsjy/jieba Stopwords removal Data Sequence aligning Preprocessing Word2Vec: https://github.com/facebookresearch/fastText Conversion to BigDL Sample -> RDD[Sample]
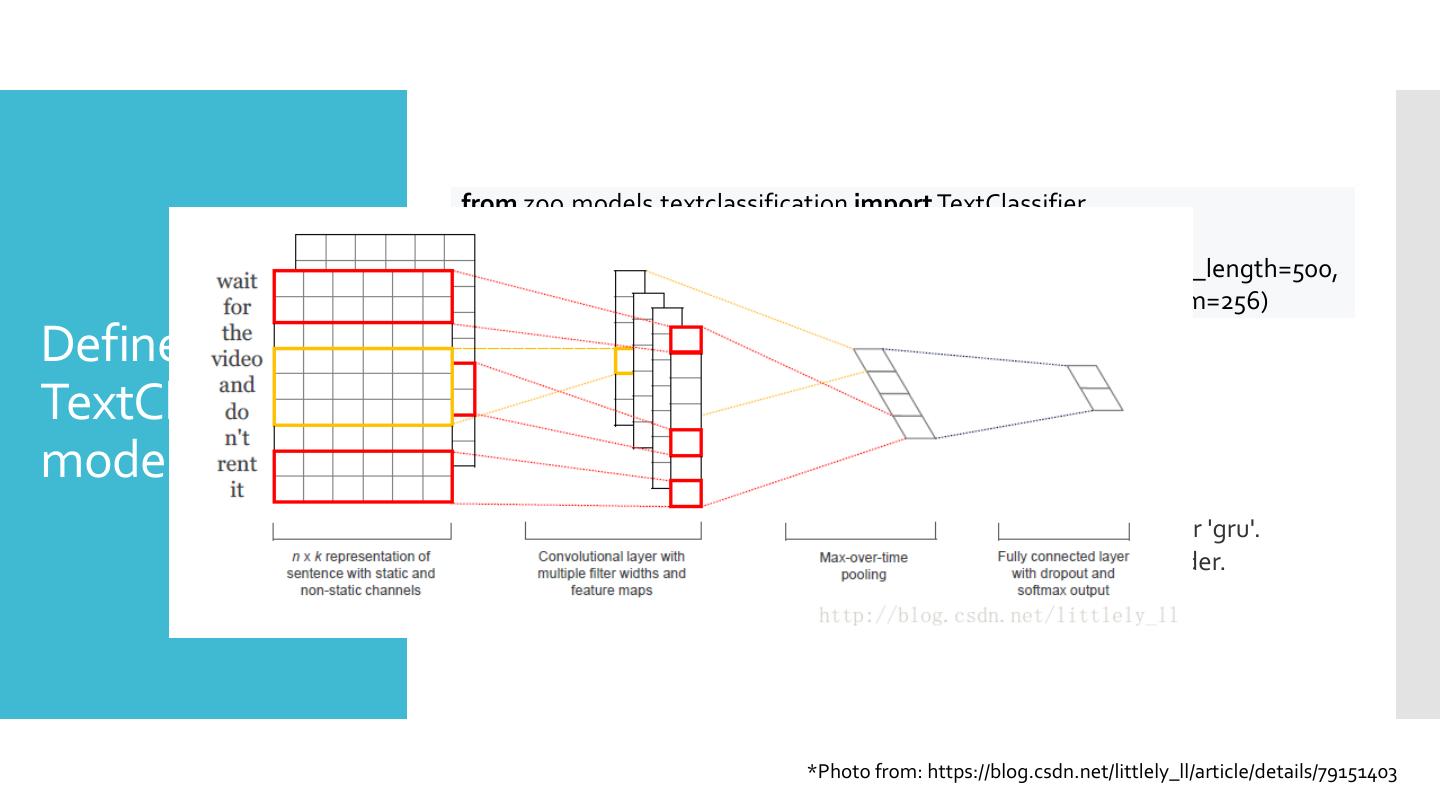
25 . from zoo.models.textclassification import TextClassifier text_classifier = TextClassifier(class_num, token_length, sequence_length=500, encoder="cnn", encoder_output_dim=256) Define a TextClassifier • class_num: The number of text categories to be classified. model • token_length: The size of each word vector. • sequence_length: The length of a sequence. • encoder: The encoder for input sequences. 'cnn' or 'lstm' or 'gru'. • encoder_output_dim: The output dimension for the encoder. *Photo from: https://blog.csdn.net/littlely_ll/article/details/79151403
26 . Keras-Style API for distributed training: text_classifier.compile(optimizer=Adagrad(learning_rate, decay), loss="sparse_categorical_crossentropy", metrics=["accuracy"]) Training, text_classifier.set_checkpoint(path) prediction and text_classifier.set_tensorboard(log_dir, app_name) evaluation text_classifier.fit(train_rdd, batch_size=…, nb_epoch=…, validation_data=val_rdd) text_classifier.save_model(model_path) text_classifier.predict(test_rdd) text_classifier.predict_classes(test_rdd)
27 . Check your data first (quality, quantity, etc.). Use custom dictionary for tokenization if necessary. Ways for Train word2vec for unknown words if necessary. improvement Hyper parameters tuning (learning rate, etc.). Add character embedding, etc.
28 . Prediction service implemented in Java POJO-like API for low-latency local inference public class TextClassificationModel extends AbstractInferenceModel { public JTensor preProcess(String text) { Service } //Preprocessing steps using Java API Integration } TextClassificationModel model = new TextClassificationModel(); model.load(path); String sampleText = "text content"; JTensor input = model.preProcess(sampleText); List<JTensor> inputList = new ArrayList<>(); inputList.add(input); List<List<JTensor>> result = model.predict(inputList); WebService example: https://github.com/intel-analytics/analytics-zoo/tree/master/apps/web-service-sample
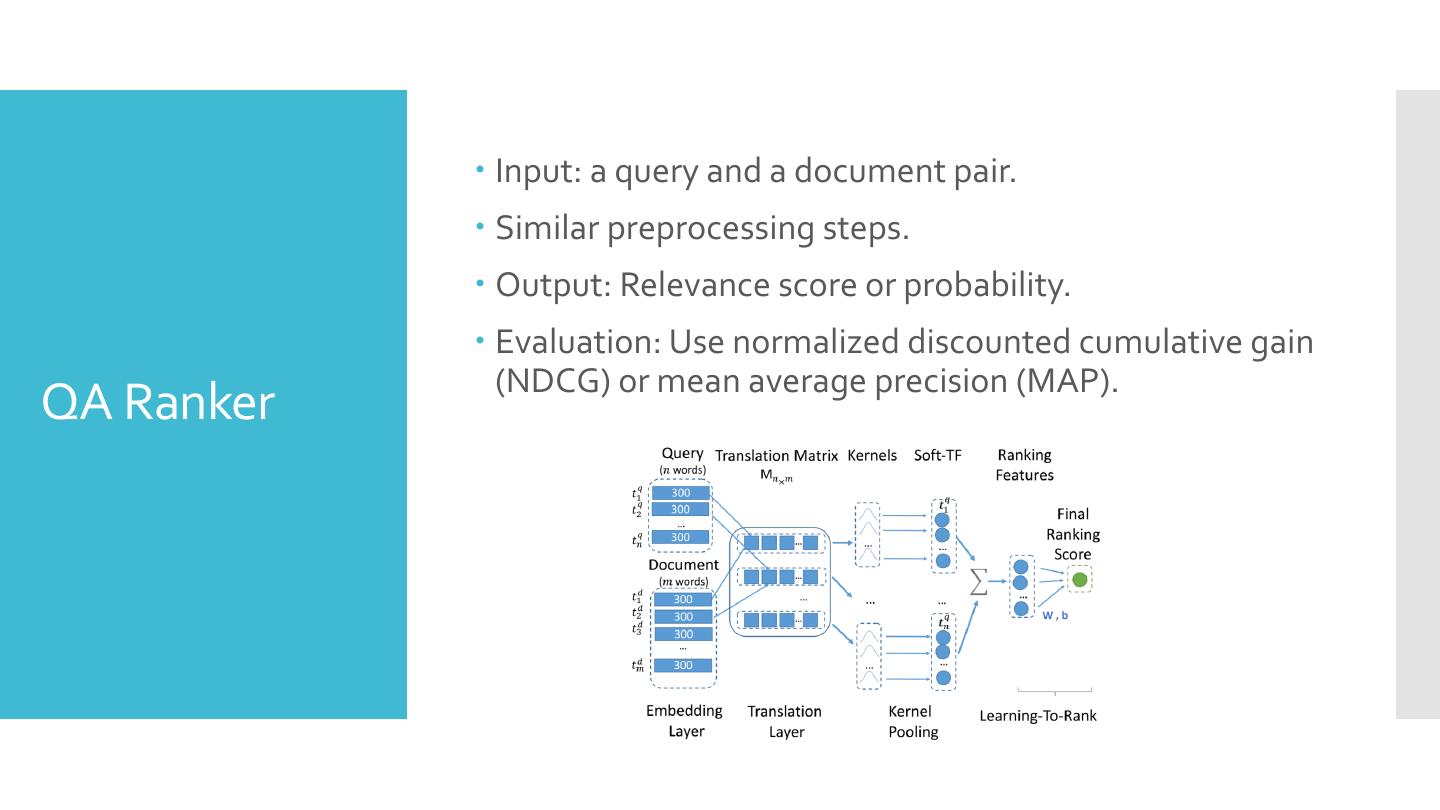
29 . Input: a query and a document pair. Similar preprocessing steps. Output: Relevance score or probability. Evaluation: Use normalized discounted cumulative gain (NDCG) or mean average precision (MAP). QA Ranker
3秒后跳转登录页面
去登陆

