























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
EMR打造高效云原生数据分析引擎
分享
点赞
6
收藏
2
9月27日【EMR打造高效云原生数据分析引擎】
主讲人:辛现银,花名辛庸,阿里巴巴计算平台事业部 EMR 技术专家。Apache Hadoop,Apache Spark contributor。对 Hadoop、Spark、Hive、Druid 等大数据组件有深入研究。目前从事大数据云化相关工作,专注于计算引擎、存储结构、数据库事务等内容。
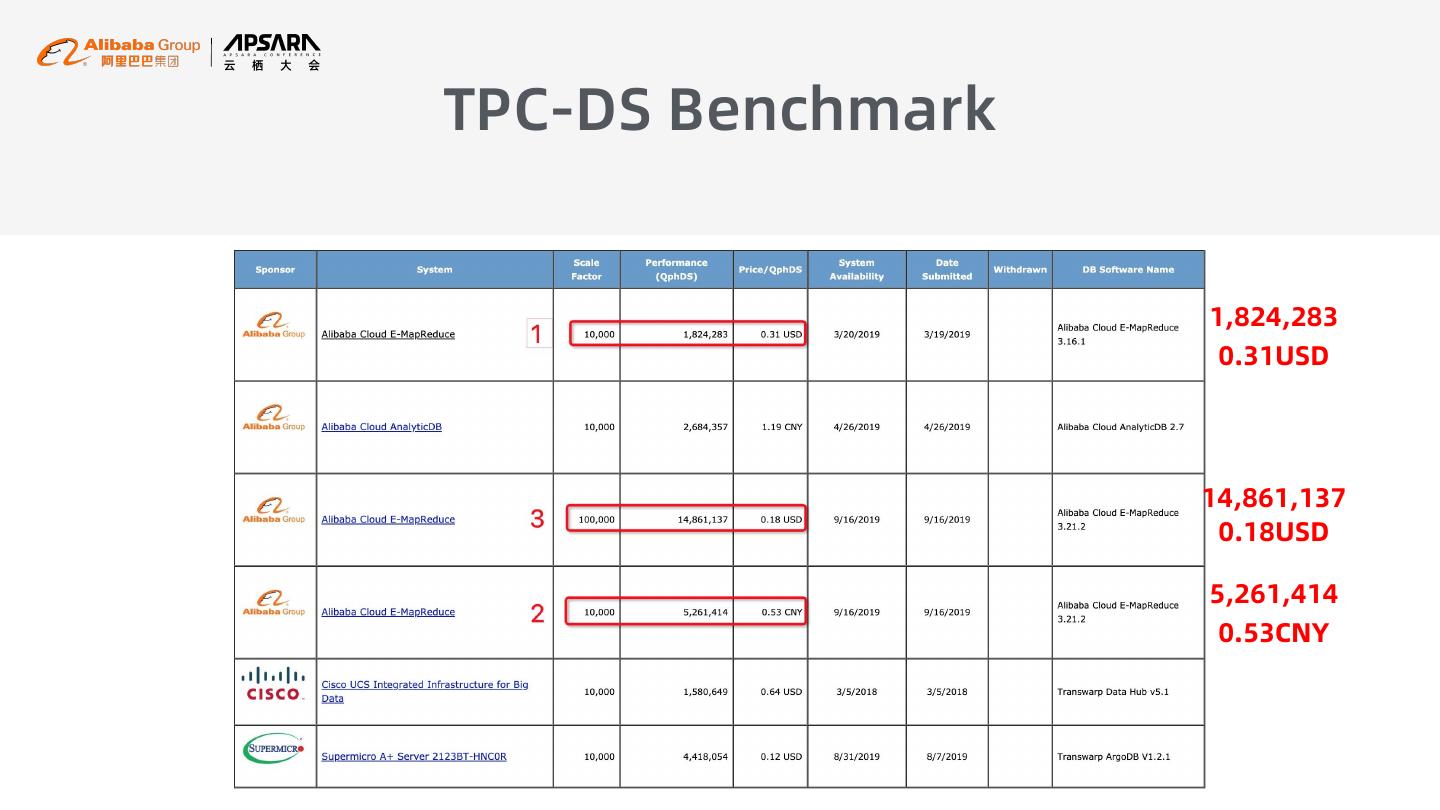
简介:EMR-Jindo 是 EMR 推出的云原生 OLAP 引擎。凭借该引擎,EMR 成为第一个云上 TPC-DS 成绩提交者。经过持续不断地内核优化,目前基于最新 EMR-Jindo 引擎的 TPC-DS 成绩又有了大幅提高,达到了3615071,成本降低到 0.76 CNY。本次分享将介绍 EMR-Jindo 引擎背后的相关技术以及以 EMR-Jindo 为核心的云上大数据架构方案。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .EMR 打造高效云原生 数据分析引擎 辛现银(辛庸) 阿里云智能计算平台事业部技术专家
2 . 01 基于开源体系打造云上数据分析平台 Contents 目录 02 EMR-Jindo: 高效云原生数据分析引擎 - Jindo-Spark - Jindo-FS
3 .基于开源体系打造云上数据分 析平台 01
4 . 为什么选择开源方案 灵活多样的业务场景 与自有系统耦合 高度定制化 自己有专业的运维能力 有充足的人才储备 丰富的网上资料与开源的强大后盾 多种业务需求 vs 成本压力 每种云上产品有自己的使用场景 购买多种云产品 vs 维护一套系统的成本考量
5 . Alibaba E-MapReduce 开发者平台 DataWorks HAS 企业级安全 平台容器化 数据加密 资源弹性伸缩 元数据管理 轻量级 PaaS 接入 管理平台 全平台作业诊断(APM) 计算引擎 Hive Jindo-Spark Flink(Blink) Tensorflow(PAI) … 资源调度 YARN K8S HAS JindoFS OTS HBase ODPS 存储接入 OSS HDFS 计算资源 ECS + Block Storage ECS D1 神龙服务器 ECS GPU gn4/gn5 基础运维 Tesla
6 . Alibaba E-MapReduce 平台化 技术社区&深度 生态 全系列VM 持续深耕技术社区 Blink 接入 容器化 打造大数据友好的云 Native 存储 PAI 接入 企业级HAS OSS 方案集成 大数据APM OTS 方案集成
7 .EMR-Jindo: 云原生高效数据分 析引擎 02
8 .TPC-DS Benchmark 1,824,283 0.31USD 14,861,137 0.18USD 5,261,414 0.53CNY
9 . EMR-Jindo Jindo-Spark Jindo-Spark DataSource API V1/V2 高效计算引擎,处理多种计算任务 Delta Lake Jindo-Fs Node1 Node2 Node… NodeN Jindo-FS 云原生存储,同时兼顾性能与价格 OSS
10 . Jindo-Spark Runtime Filter Enhanced Join Reorder RF 自适应的运行时数据裁剪 JR 遗传算法;外连接重排 TopK File Index TK 推理并下推 TopK 逻辑,运算早期过滤数据 FI 文件级别过滤,min/max/bloom/倒排等 Relational Cache Spark Transaction RC 将查询从分钟级提升为亚秒级 ST 为 Spark 引入 Full ACID 支持 More… M Smart Shuffle SS Push based, 减少 sort-merge 次数
11 . Runtime Filter No-RF/RF 加速比 12 10 8 6 35% 4 2 0 q54 q80 q40 q55 q42 q52 q32 q98 q43 q95 q71 q70 运行时动态裁剪数据,避免不必要的计算 SPARK-27227
12 . Enhanced Join Reorder Query64: 18个表 Join 1800 多表 Join 的遗传算法 1750 1400 1350 1050 900 700 450 350 0 0 DP GA 不做Reorder GA 750 外连接重排算法 600 450 300 150 0 q80 q40 SIGMOD ’90: Query graphs, implementing trees, and freely-reorderable outerjoins 遗传算法PR:SPARK-27714
13 . Relational Cache Relational Cache (RC) RC 创建/维护 RC使用 任意Spark表,视图或者Dataset等关系型 DDL Create Realtional Cache Catalyst Optimizer 数据抽象的数据实体, similar to SQL Materialized View, but more than that EXEC 使用场景 1.亚秒级响应的MOLAP引擎 OSS/HDFS/MEM Rewrite Rules based RC 2.交互式BI,Dashboard。 3.数据同步 4.数据预组织 让数据适配计算,从而大幅提升计算效率 SPARK-26764
14 . Relational Cache 创建 Relational Cache CACHE [LAZY] TABLE table_name 视图名称 [REFRESH ON (DEMAND | COMMIT)] 更新策略 [(ENABLE | DISABLE) REWRITE] 是否用于优化 [USING datasource [OPTIONS (key1=val1, key2=val2, ...)] [PARTITIONED BY (col_name1, col_name2, ...)] [CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS] Cache数据 [ZORDER BY (col_name5, col_name6, …)] 存储方式 [COMMENT table_comment] [TBLPROPERTIES (key1=val1, key2=val2, ...)]] Cache的 [AS select_statement] 视图逻辑 支持cache任意Table,View,支持cache到内存,HDFS, OSS等任意数据源,JSON,ORC,Parquet等任意数据格式 SPARK-26764
15 . Relational Cache Cache vs No-Cache Star Schema Benchmark(ms) 自动查询计划重写 218801 250 100000 30018 Query: 6014 200 10000 SELECT empid, deptname, hire_date 3261 FROM emps JOIN depts ON (emps.depno = depts.depno) 1187 824 859 1010 997 150 1000 726 WHERE hire_date >= ‘2018-01-01’ AND hire_date <= ‘2018-06-30’ 100 100 Rewritten Query: SELECT empid, deptname, hire_date 10 50 FROM mv WHERE hire_date >= ‘2018-01-01’ AND hire_date <= ‘2018-06-30’ 1 0 2 20 40 200 1000 Cache No-Cache Sppedup For More Detail:大数据生态专场: 《Spark Relational Cache实现亚秒级响应的交互式分析》 SPARK-26764
16 . Spark Transaction 场景 流程 存储 数据订正/删除 数据流导入
17 . Jindo-FS 存储贵? EMR 本地盘机型价格较高 计算存储分离 性能差? 扩展难? OSS 元数据操作 传输带宽 HDFS 元数据瓶颈 本地存储动态化伸缩 寄存器 > L1-L2-L3 Cache > Mem > SSD > HDD > Local Net > Remote Net
18 . Jindo-FS OSS directly: Instruction Flow 元数据访问 Name Service OTS Data Flow 数据本地化 Storage Storage Client Service Service File RocksDB OSS File RocksDB
19 . Jindo-FS Name Service 2800 2668 1.分布式,raft 协议,提供入口服务 2400 2126 2.多 Name Space 支持 2000 3.元数据以 kv 形式存放于高性能 kv store 中 1600 4.弹性扩展,重建 1200 800 1home (pid=1;id=2;Ftype=1;ctime=…) 400 37 45 2hadoop (pid=2;id=3;Ftype=1;ctime=…) 0 3file1.txt (pid=3;id=4;Ftype=2;ctime=…) List Du Jindo-FS OSS 3file2.txt (pid=3;id=5;Ftype=2;ctime=…) Jindo-FS VS OSS 元数据操作(s) 元数据管理:/home/Hadoop/file1.txt
20 . Jindo-FS 3 Storage Service Instruction Flow Client Storage Service 图2. 本地读 1.高性能 1 Data Flow 2 2.高可靠高可用 本地存储 3.弹性存储 Name Service 4.数据流高速通道 4 Name Service 图3. 远程读 1 Storage 5… Storage 3 Client 7 Service Service 6 Client Storage Storage 3 Service Service 2 2 1 4 2 5 图1. 写流程 本地存储 本地存储 本地存储 OSS 本地存储
21 . Jindo-FS Name Service 1.如何实现高可靠? 2.如何进行热点数据发现与缓存替换? 3.块存储模式与缓存模式? 4.… Storage Service 1.如何应对读写失败? 2.数据块如何设计并存储? 3.如何实现高速数据通道? 4.… For More Detail:大数据生态专场: 《云上大数据的高效能数据库的存储方案》
22 .欢迎关注
23 .THANKS !
6点赞
2收藏
3秒后跳转登录页面
去登陆

